分布式一致性算法Yac
2017-11-15刘丹丹
张 健,汪 洋,刘丹丹
(1.武汉大学 计算机学院,武汉 430072; 2.武汉大学 软件工程国家重点实验室,武汉 430072)(*通信作者电子邮箱943629628@qq.com)
分布式一致性算法Yac
张 健1,汪 洋1*,刘丹丹2
(1.武汉大学 计算机学院,武汉 430072; 2.武汉大学 软件工程国家重点实验室,武汉 430072)(*通信作者电子邮箱943629628@qq.com)
传统静态拓扑主从模型分布式一致性算法存在严重负载不均及单点性能瓶颈效应,且崩溃节点大于集群规模的50%时算法无法正常工作。针对上述问题,提出基于动态拓扑及有限表决思想的分布式一致性算法(Yac)。算法动态生成参与一致性表决的成员子集及Leader节点并时分迁移,形成统计负载均衡;去除要求全体多数派成员参与表决的强约束,使算法具备更高的失效容忍性;并通过日志链机制重新建立算法安全性约束,同时证明了算法的正确性。实验结果表明,改进算法的单点负载集中效应显著低于主流静态拓扑主从模型分布式一致性算法Zookeeper;改进算法失效容忍性优于Zookeeper,且最坏情况下与Zookeeper算法保持持平;同等集群规模下,改进算法比Zookeeper拥有更高吞吐量上限。
分布式一致性;Paxos算法;表决团;日志链;负载均衡
0 引言
分布式计算技术的发展平衡了日益膨胀的应用计算性能需求与单机性能瓶颈之间的矛盾,一致性问题是保证分布式系统正确性与可靠性的核心问题。
Lamport等[1]于1998年首次提出拜占庭问题,并对非拜占庭模型下分布式一致性问题给出了形式化讨论与证明,同年还提出了近乎公理化的分布式一致性算法Paxos[2]。持续多年的研究和改进之后,文献[3]进一步重构和完善了Paxos的算法理论。经典Paxos算法存在活锁问题,这是由于经典Paxos算法中没有主节点,提案基于P2P模型表决,导致成员节点间可能产生无休止的竞争。针对此问题,文献[4-5]提出并完善了基于经典Paoxos的变种算法Fast-Paxos,首次引入主节点以消除活锁,并通过乐观锁降低Paxos算法延迟。2013年Google研究院发表公开了其对Paxos应用研究成果,其证实采用基于主从模型的Multi-Paxos算法工程化实现的分布式锁服务Chubby[6]支撑了Google公司全球系统基础设施的运行。
此后,斯坦福大学的Diego Ongaro等[7]提出的Raft算法,还有文献[8-10]中所描述的始于Apache基金会Hadoop项目子项目的Zookeeper分布式一致性服务,共同推动分布式一致性算法进入以主从模型为主流的发展时代。
基于主从模型的一致性系统虽然消除了活锁问题,也较P2P模型拥有更低的平均延迟,但也由于Leader节点的存在,产生了严重的单点性能瓶颈问题。此外,Leader节点如果崩溃,那么重新选举Leader节点引起的系统震荡也降低了系统的稳定性。因此,一部分学者也尝试寻找新方法提高主从分布式一致性模型的吞吐量。有研究人员尝试改良分布式一致性算法拓扑结构。文献[11]提出了Ring-Paxos算法,在成员节点间构建逻辑环执行链式表决,有效降低消息传播数量,削弱瓶颈带来的影响。文献[12]提出的HT-Paxos算法牺牲了时延性能指标,在执行分布式表决前通过被称为disseminators的节点集群完成分布式一致性请求的预处理,最大限度剥离Leader节点的职能 。文献[13]提出的S-Paxos算法在执行分布式决策的Paxos层下建立一个消息扩散层以代替主节点扩散广播消息,一定程度上抑制了Leader节点的消息传递开销。文献[14]提出了法定集(Quorum)租约机制,在牺牲部分写时延及失效容忍性基础上大幅度提高状态读取速度。上述的研究工作都取得了一定成果,但未能够完全解决Leader节点存在的单点效应问题。
本文针对主从式分布式算法特性,在Raft、Zookeeper的体系架构基础上提出了改良,采用时域哈希方法,使作为负载中心Leader节点随时间序列动态转移,实现统计上的负载均衡;同时为降低一致性表决广播数量和提高可用性,提出有限表决思想,舍弃传统一致性表决实例中的半数以上成员参加的强约束,任意一次表决仅要求有限成员子集参与,并通过Log Chain机制杜绝集群状态分支,形成了新的高性能分布式一致性框架。本文对新算法的CAP(Consistency, Availability and Partition tolerance)[15]特性进行了分析阐明,同时还对算法的负载均衡性、吞吐量、时延等关键技术指标进行了实验验证。根据实验结果,新型分布式一致性算法在克服单点性能瓶颈的负载均衡性、可用性、吞吐量、重度负载情形下请求处理时延等指标上都具备较好的表现。
1 Yac分布式一致性算法
1.1 一致性问题模型与分布式副本状态机
分布式一致性问题的数学模型描述如下:
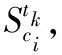

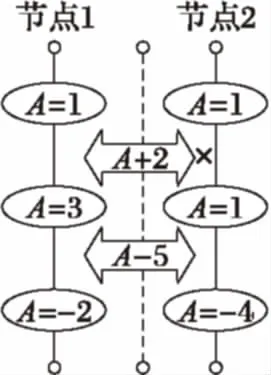
图1 日志堆积与状态变更
日志视图与状态视图是等价的,如图1所演示的状态变更日志堆栈中,节点1和节点2中初始状态为A=1。节点1的状态转移日志为A+2和A-5,节点2的状态转移日志序列为A-5;则最终,节点1表征的状态视图为A=-2,而节点2表征的状态视图为A=-4。
可以根据日志视图模型进一步将分布式一致性问题描述为下列形式:
定义2 分布式集群成员节点初始状态一致。如果经过离散时间序列{Tn}后,集群中分布式副本状态机储存的日志堆栈一致,则集群状态一致,反之则集群状态不一致。
1.2 传统主从式分布式一致性算法的问题
传统主流的主从式分布式一致性算法模型如Zookeeper、Raft等,存在通用的架构形式。
本质包含如下几种主要角色。
1)Leader:全局的唯一的主节点。具备Sequencer的功能,在分布式一致性表决中裁定议案(Proposal)的偏序,并产生一致性决议。
2)Follower:一致性表决的参与者,可以针对某项决议向Leader发起投票,通常传统任何一个一致性表决都要求一半以上成员节点组成的子集(也称法定集)参加,这也是传统分布式一致性算法在半数以上成员存活时才能正常工作的强约束的由来。
3)Learner:不参加一致性表决,仅学习一致性结果。
上述Leader、Follower和Learner只是逻辑上的角色划分,有时并不一定有严格界限,许多分布式系统中,Follower和Learner会一体化实现,而也有的分布式系统中,Leader也被允许如Follwer一样参与投票。
可以抽象出这些主从分布式一致性算法的一般模式,如下。
1)选主:系统初始状态下,首先通过特定的选主算法,在全部成员节点中选出Leader,并且当Leader节点崩溃后重新执行选主过程。
2)一致性请求:客户端(Client)提交的请求(Request)首先被转发给Leader,Leader将请求转换成议案(Proposal),并选出一个法定集合(通常为全体成员集合),将议案广播给法定集合成员。
3)一致性表决:参与表决的Follower节点根据接收到的议案内容进行投票(Vote),并将投票发送给Leader。
4)提交:Leader节点统计投票,并将表决结果提交(commit)到整个网络。
5)读取:客户端节点通过Learner节点读取整个网络的一致性状态。
上述传统主流主从式分布式一致性算法的一般模式中,有两个问题制约了系统的总体性能上限。
第一个问题为固定Leader节点的存在:
传统主从分布式一致性算法中Leader节点是固定的,且担负了过多职责:包括广播议案、统计投票、决出决议、消息分发等在内,随着网络规模扩大,Leader节点承担了数倍于普通节点的流量,这对Leader节点的计算性能和网络接口带宽提出了巨大的要求;并且Leader节点一旦崩溃,集群需要重新进入选主过程,直至Leader上线,集群都会保持无服务状态,引发流量震荡。这些严重制约了传统主从分布式一致性算法网络规模和系统吞吐量上限,这些缺陷在开源系统Zookeeper的应用中表现明显。
第二个问题为法定集约束的存在:
传统分布式一致性算法,无论基于P2P模型还是主从模型,都存在必须要求半数以上节点存活并参加一致性表决的强约束,也称法定集约束。这是由于从集合论的角度,不可能存在两个多数派成员集合同时投票赞成两个不同议案,因此从数学角度确保一致性算法的正确性,这显著制约了算法的失效容忍性上限。
1.3 Yac分布式一致性算法的相应改进
Yac分布式系统针对上述传统主流分布式算法中存在的问题提出了改良方法。
对于第一个问题,Yac算法不采用固定Leader节点,而采用特定的策略动态生成决策成员集合,该集合在集群成员节点中随时域动态迁移,形成统计负载均衡,作为临时负载中心的Leader角色也采用共识机制随上述集合的产生动态生成。
对于第二个问题,Yac算法放弃采用传统分布式一致性算法中关于半数以上成员节点组成法定集参加表决的强约束,而在特定时间片内由映射的角色成员集合参与一致性表决。这破坏了Paxos算法已经提供的,对分布式一致性算法正确性的数学证明,本文建立了一种名为日志链的机制,结合算法安全性约束来重新确保Yac分布式一致性算法的正确性。
Yac分布式一致性算法中重新划分了三种角色,分别为:
1)Leader。临时Leader节点,由时域要素计算产生,统计来自一致性表决成员关于某项议案的投票结果,并生成一致性决议通知全网。
2)Elector。临时的一致性表决参与者,由时域要素计算生成特定时间段内的法定一致性表决成员集表决团中的成员,可以针对某项议案进行投票。
3)Follower。普通节点,执行请求与议案的广播操作,学习Leader节点的一致性决议。
下面分步阐述表决团和Leader的产生机制,以及如何通过日志链机制在有限表决模型下确保一致性决议的唯一性。
1.4 表决团和Leader的生成策略
Yac分布式一致性算法采用哈希方法生成与时间域映射的表决团成员集合。
对于表决团的大小,可以在大于3及小于集群节点总数m范围内的奇数中任意选取。

定义哈希函数VGen(time_param),将时域参数epoch散列映射至上述键值对序列的键空间中,计算时域要素映射时间段内表决团成员集。

1.5 日志链机制
日志链机制的引入来源于对算法正确性的要求。本文分两步确保Yac分布式一致性算法的正确性:
1)单次一致性表决正确性:对于单次一致性表决,集群不产生或仅产生唯一一个表决结果。
2)累积一致性表决正确性:经过多轮表决后,集群能且仅能确定唯一一个表决结果序列。
针对单次一致性表决正确性,传统分布式系统采用集合论约束证明正确性;Yac算法由于特殊的表决团生成策略,对于同一个时域参数epoch,仅可能生成唯一一个表决团,并且在表决团内遵循法定集表决约束,因此同样可以证明正确性。
而针对累积一致性表决的正确性,则通过日志链机制来保证。
已知集群中任意一次表决生效产生的集群状态变更都可以采用二元组〈epochi,proposali〉唯一描述,其中epochi为时域参数,proposali为表决的议案。采用递归哈希思想,以第五代消息摘要算法(Message Digest algorithm 5th, MD5)对历史状态变更记录计算累积摘要,生成链式数据结构Log Chain,如图2所示。

图2 Log Chain数据模型
Log Chain保存了数据状态变更路径,形成可追溯的集群一致性状态变更历史轨迹,对于链中每个Log Entry节点,都存储本次状态变更记录及上一个Log Entry的MD5值,这不但包括了对上一次状态变更结果的确认,同时还隐式校验了Log Chain上之前所有状态变更记录的完整性。因此,Log Chain之间可以通过对链尾Log Entry节点的一次比较,检验出历史上所有可能出现过得版本分歧。并且,后面还将说明,Log Chain中所有可能出现的版本分支都是等长的,分支版本与主版本合并算法的复杂度等价于求取分支版本与主版本的最长公共前缀算法,具有线性复杂度。
1.6 安全性约束
为确保算法安全性,即中间不含写操作的情形下,向集群任意节点发起的任意读请求序列读取到的状态值序列都一致,Yac定义了下列安全性约束:
约束1 如果一个节点支持一个决议,那么本时间片内不再支持任何其他决议。
约束2 表决团是原子的,当且仅当半数以上的成员支持一项决议,该决议才获得通过。
约束3 一个时间片内仅执行一次表决,如果一个时间片内,节点未表决通过或被通知通过一个表决成功的议案,那么节点生成一个空的Log Entry链接到本地Log Chain副本中。
约束4 如果同一时间片内,Log Chain的对应Log Entry在集群中同时存在空和非空版本,那么非空Log Entry对应正确的主分支版本。
1.7 算法描述
至此,已可以总结出Yac分布式一致性算法的形式化描述如下。
1)
Algorithm 1: Yac
2)
/*Task for a client*/
3)
Createrequest〈request_id,request_body〉
4)
Sendrequest〈request_id,request_body〉 to serversfrom server_list randomly
5)
Upon not receivingreply〈request_id〉 from serversuntil Δttime
6)
Repeat from step 4)
7)
/*Task for Follower and ALL Server*/
8)
Uponnew_time_slotstart:
9)
Iflast_log_entry_epoch 10) Appendlog_entry〈last_log_entry_md5,epoch,null,md5〉 Intolog_chain 11) Setcurrent_epoch++ 12) Letelector_group= VGen(current_epoch) 13) Letleader=elector_group[0] 14) Ifthis==leaderThen 15) Switch to Leader 16) Else IfthisInelector_groupThen 17) Switch to Elector 18) Else 19) Switch to Follower 20) Resetcommitted=false,pre_vote_request_id=null 21) Upon receivingcommit〈epoch,request〉: 22) AssertcommitIs Validated 23) Appendlog_entry〈last_log_entry_md5,epoch,request,md5〉 Intolog_chain 24) Upon receivingrequest〈request_id,request_body〉 from Client c: 25) Letelector_group=VGen(current_epoch) 26) Multicastdisseminated_request 27) /*Task for a Elector*/ 28) Upon receivingdisseminated_request〈request_id, request_body〉 29) Ifpre_vote_request_id==null Orrequest_id< pre_vote_request_idThen 30) Return false 31) Letelector_group= VGen(current_epoch) 32) Letleader=elector_group[0] 33) Sendvote〈current_epoch,disseminated_request〉 Toleader 34) pre_vote_request_id=request_id 35) /*Task for a Leader*/ 36) Upon receivingvote〈epoch,request〉 37) Ifepoch 38) Return false 39) Else 40) Setvote_counter[request_id] ++ 41) Setvote_cache[request_id] =request_body 42) Ifvote_counter[request_id] >e/2 Then 43) BroadCastcommit〈epoch,request〉 44) Letcommitted=true 1.8 节点崩溃恢复策略 Yac分布式一致性算法可以采用简单的崩溃恢复策略,当节点发生故障后并重新恢复后,首先计算当前epoch,并计算上一个epoch所映射的表决团成员集合,向它们发送请求同步广播,将本地Log Chain合并到集群主版本。 1.9 成员变更 Yac分布式一致性算法的将成员变更操作视为分布式一致性决策问题,并保持系统内全局状态一致。 初始成员集合采用静态加载配置文件方式获取。系统运行时态,由管理端提出成员变更请求,接入节点生成成员变更议案,提交当前epoch映射的表决团表决,表决结果由当前Leader广播至一致性网络。 1.10 CAP分析 针对可用性(A)指标,传统的分布式一致性算法,在超过半数的成员失效时系统就不能正常工作,这是基于法定集的强约束。Yac分布式一致性算法在半数以上表决团节点存活时可以提供一致性服务,因此具备比传统分布式一致性算法更宽的工作区间。 根据CAP理论[15],分区容忍性(P)与分区一致性(C)相互冲突, Yac分布式一致性算法严格强调分区一致性(C),在分区容忍性(P)上作出妥协。 当网络发生分区时,相互隔离的多个分区无法同时提供服务,因此一定不会产生冲突的值。这是因为表决团是原子的,任一时间片内存在且至多存在一个分区能够产生具备多数派的表决团。当分区恢复联通时,借助Log Chain的递归Hash特性,任意两个节点可在常数时间内检测出Log Chain之间的版本分歧,只要从树形日志链的根节点起始进行宽度优先遍历(Breadth First Search, BFS),递归剪除祖先节点决议为NULL的分支,则可快速将树形日志链重新修整成单一的主链,恢复集群的一致性。 1.11 正确性证明 分布式集群状态一致等同于各成员节点的副本日志一致。证明算法正确性,只需证明各成员节点副本Log Chain之间不会产生无法合并的分支版本。 首先依次证明三个命题: 命题1 各成员节点副本Log Chain的长度相等。 证明 根据安全性约束3,每一个时间片内,日志链产生且至多产生一个空或非空Log Entry节点,在系统初始化后,各成员节点经历相同的时间偏序,因此副本Log Chain之间长度相等。 命题2 同一时间片内不可能产生两个决议内容不同的非空Log Entry。 证明 采用反证法。假定时间片tk内生成了两个决议内容不同的Log Entry,则tk时间片所映射的表决团必定存在两个多数派同时支持了不同的提案,而已知任意两个多数派存在交集,一定存在节点在tk时间片内支持两个不同决议,这与安全性约束1矛盾,命题2得证。 命题3 任意时间片都映射一个唯一合法的Log Entry版本。 证明 根据命题2,任意时间片tk内各副本Log Chain所生成的Log Entry仅存在三种情况:①仅存在空Log Entry;②仅存在决议值相同的非空Log Entry;③既存在空Log Entry,也存在决议值相同的非空Log Entry;又根据安全性约束4,情况①可合并至空Log Entry,情况②③可合并至值唯一的非空Log Entry,因此得证。 综合上述三个命题的证明,分布式集群中各成员节点副本Log Chain可以确保版本唯一,由此可以保证分布式集群成员节点间日志版本一致,进而确保分布式集群状态一致。 本文采用Java语言实现了Yac算法,采用RPC作为底层通信技术,开展实验。为了对比与主流分布式一致性算法的性能差异,本文同时也对Zookeeper开源分布式一致性基础服务进行了对比测试。课题组采用三台Xeon E7-8830+64 GB RAM及1 000 M交换机组成的硬件平台,基于Xen-Server构建的私有云,并在云上部署Docker容器构建实验集群。分别设计测试负载生成客户端,对Yac算法集群,生成对测试状态变量的随机四则运算操作并校验正确性;对Zookeeper算法集群,向ZTree空间中固定路径中写入随机整型变量。为实现可控测试负载,采用Sleep系统调用动态调节测试请求的生成速率。通过对比实验,分别从负载均衡指标、失效容忍性、吞吐量与时延特性三个方面对两种算法进行比较。实验中的参数配置上,采用变量m表征集群节点总数,采用变量e表征Yac算法表决团大小。 2.1 负载均衡指标 1)均方差指标 2)单峰指标 其中:均方差指标衡量集群总体负载均衡度,单峰指标用来衡量集群的单点负载集中效应。 图3、图4和表1展现了不同集群配置下的两种算法负载均衡方差指标、单峰指标的对比。其中图3与图4中Zookeeper指标变化曲面均与表决团大小无关。由表1可以看出,在集群规模较小时,如m=15时,Yac算法的负载均衡方差指标较Zookeepr最少低0.2%,随着集群规模扩大,Yac的算法的负载均衡方差指标优于Zookeeper,m=65时,Yac算法的方差指标至少较Zookeeper高出4.94%;另一方面,对于负载均衡单峰指标,Yac算法显著优于Zookeeper,在集群较小,在m=15且e=7时,Yac算法单峰指标就较Zookeeper高出22.34%,随着集群规模扩大,Zookeeper的Leader节点负载急剧上升;m=65且e=7时,Yac算法的单峰指标已经比Zookeeper高出31.3%,显示出Yac算法统计负载均衡特型在抑制单点负载集中效应上具有明显优势。 图3 两种算法在不同集群配置下的均方差指标比较 图4 两种算法在不同集群配置下的单峰指标比较 表1 两种算法在不同集群配置下负载均衡指标比较 2.2 可用性及失效容忍性 可用性指标IA=(S/R)×100%是统计单位时间片内分布式服务可用率的指标,其中S及R分别是单位时间片内请求执行成功数以及请求发起总数。 通过杀死Docker容器节点进程的方式,可以模拟分布式集群中节点崩溃失效事件。Yac算法的失效容忍性与表决团在集群中占比有关,本文依此对Yac算法在不同集群配置、节点崩溃变化情形下可用性指标及失效容忍性能进行了评估,并与Zookeeper进行了对比分析。 图5和表2展现了两种算法在不同集群配置可用性指标变化的对比。图5中Zookeeper指标变化曲面与表决团在集群中占比无关。由图5和表2可知:Zookeeper在集群节点崩溃率小于50%时,可用性指标稳定维持在100%;当节点崩溃率到达50%以上时,集群停止工作,呈阶跃特性。 与之相反,Yac算法用性指标表现出与节点崩溃率的负相关关系。当表决团在集群中占比20%时,节点崩溃率由10%升高50%过程中,可用性指标由91.56%降低至73.3%;但重点在节点崩溃率超过50%时,算法仍正常工作,甚至在80%节点崩溃时,Yac算法可用性仍能保持在35.62%左右,能提供有限服务,在失效容忍上表现了比Zookeeper更大的节点失效容忍度。当表决团在集群中占比达60%时,算法在相同节点崩溃率上表现出较表决团在集群中占比20%情形时更高的可用性指标,但失效容忍范围开始收窄,节点崩溃率到达60%时仅表现出11.23%的可用性指标。当表决团在集群中占比达100%时,算法失效容忍范围开始收窄,且可用性指标随崩溃率变化趋势近似于Zookeeper表现出的阶跃曲线,这与图5中变现的规律一致。可知,Yac算法可用性表现与表决团在集群中占比呈负相关;表决团在集群中占比为100%时,Yac可用性最差,但此时也与Zookeeper拥有近似失效容忍度及可用性。 图5 两种算法在不同集群配置及节点崩溃率下可用性指标比较 表2 两种算法在不同集群配置下的可用性指标比较 2.3 时延与吞吐量性能对比分析 时延及吞吐量是分布式一致性算法的重要性能指标,本文在不同集群配置及不同测试负载下对Yac算法与Zookeeper的相关指标进行对比分析。为获取正确实验结果,所有Docker容器均绑定CPU核并配置资源限额。 图6与表3展现了两种算法在不同集群配置及不同测试负载下的请求处理时延。 图6 两种算法在不同集群配置及写测试负载下请求平均处理时延 其中表3枚举了不同集群配置及测试负载下两种算法请求平均处理时延的采样,图6(a)与图6(b)则分别针对不同集群规模下两种算法请求平均处理时延随测试负载变化趋势进行了可视化分析。从表3中的数据可知,在Yac算法测试负载在12×103req/s以下而Zookeeper测试负载在10×103req/s以下时,两种算法都拥有相对平稳的请求处理时延,其中Yac算法的时延采样均值约为73.74 ms,Zookeeper算法的时延采样均值约为61.48 ms,Yac算法的请求平均处理时延比Zookeeper高约12.26 ms。随测试负载增加,算法集群均逐渐达到性能瓶颈,到达瓶颈的节点因无法及时处理消息和求而导致集群请求处理时延增加。 表3两种算法在不同负载及集群配置下请求平均处理时延比较ms Tab. 3 Comparison of average request processing delay of two algorithms under different test load and cluster configuration ms 负载/(103req·s-1)参数mYace=5e=7e=9Zookeeper359101112131573.3872.5973.4261.273572.6473.2173.3162.361574.1773.5673.4461.883573.6773.3474.0161.251573.3374.7173.7661.363572.2973.3074.3160.741573.1574.6674.1285.583574.2473.9674.5390.711573.9474.2774.15132.943574.3673.6874.83146.5315101.62102.33101.74217.2835109.37108.01110.98241.1415152.61156.44157.68321.8735163.43162.52162.19350.63 图6(a)与图6(b)中,Yac算法在测试负载增加到12×103req/s及以上时,时延曲线到达拐点,平均时延开始急剧上升,可认为相应集群配置下Yac算法的吞吐量上限在11×103~12×103req/s;同时,Zookeeper在测试负载到达10×103req/s以上时,时延曲线到达拐点,可认为其吞吐量上限在9×103~10×103req/s。以上分析表明,相同集群规模下Yac算法在未到达性能瓶颈时请求平均处理时延略高于Zookeeper,但在吞吐量上限比Zookeeper更高。 本文通过分析主流静态拓扑主从模型分布式一致性算法存在的问题,提出一种具备统计负载均衡特性及高失效容忍性的分布式一致性算法Yac。通过动态生成表决成员集合改善负载均衡性能,采用共识机制生成的时分切换的Leader节点抑制单点负载集中效应,采用作用域更小的法定集约束使算法具备更高的失效容忍性,同时通过日志链机制重新确保算法安全性。实验结果表明,同等集群规模下,Yac算法在解决单点负载集中问题上显著优于Zookeeper,并拥有更高的吞吐量上限;随表决团在总体成员集中占比降低,Yac算法可拥有比Zookeeper更广的失效容忍区间。由于相对更复杂的拓扑及更多的消息传递跳数,Yac算法具有比Zookeeper更高的请求平均处理时延,下一步工作主要是对本文算法进行改进和优化,改善时延性能及降低算法复杂度。 References) [1] LAMPORT L, SHOSTAK R, PEASE M. The byzantine generals problem [J]. ACM Transactions on Programming Languages and Systems, 1982, 4(3): 382-401. [2] LAMPORT L. The part-time parliament [J]. ACM Transactions on Computer Systems, 1998, 16(2): 133-169. [3] LAMPORT L. Paxos made simple [J]. ACM SIGACT News, 2016, 32(4): 18-25. [4] LAMPORT L. Fast paxos[J]. Distributed Computing, 2006, 19(2): 79-103. [5] ZHAO W. Fast paxos made easy: theory and implementation [J]. International Journal of Distributed Systems and Technologies, 2015, 6(1): 15-33. [6] BURROWS M. The chubby lock service for loosely-coupled distributed systems [C]// Proceedings of the 7th Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2006: 335-350. [7] ONGARO D, OUSTERHOUT J. In search of an understandable consensus algorithm [C]// Proceedings of the 2014 USENIX Annual Technical Conference. Berkeley, CA: USENIX Association, 2014: 305-320. [8] JUNQUEIRA F, REED B. ZooKeeper: Distributed Process Coordination [M]. Sebastopol, CA: O’Reilly, 2013: 3-42. [9] JUNQUEIRA F P, REED B C, SERAFINI M. Zab: high-performance broadcast for primary-backup systems [C]// Proceedings of the 2011 IEEE/IFIP 41st International Conference on Dependable Systems & Networks. Piscataway, NJ: IEEE, 2011: 245-256. [10] HUNT P, KONAR M, JUNQUEIRA F P, et al. ZooKeeper: wait-free coordination for internet-scale systems [C]// Proceedings of the 2010 USENIX Annual Technical Conference. Berkeley, CA: USENIX Association, 2010: 11. [11] MARANDI P J, PRIMI M, SCHIPER N, et al. Ring Paxos: a high-throughput atomic broadcast protocol [EB/OL]. [2016- 12- 09]. http://www.microsoft.com/en-us/research/wp-content/uploads/2016/06/RingPaxos.pdf. [12] KUMAR V, AGARWAL A. HT-Paxos: high throughput state-machine replication protocol for large clustered data centers [EB/OL]. [2017- 01- 04]. http://xueshu.baidu.com/s?wd=paperuri%3A%28b741b6286079366bc618b67547ec68f0%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fde.arxiv.org%2Fpdf%2F1407.1237&ie=utf-8&sc_us=11391865198545652672. [13] BIELY M, MILOSEVIC Z, SANTOS N, et al. S-Paxos: offloading the leader for high throughput state machine replication [C]// Proceedings of the 2012 IEEE 31st Symposium on Reliable Distributed Systems. Washington, DC: IEEE Computer Society, 2012: 111-120. [14] MORARU I, ANDERSEN D G, KAMINSKY M. Paxos quorum leases: fast reads without sacrificing writes [C]// Proceedings of the ACM Symposium on Cloud Computing. New York: ACM, 2014: 1-13. [15] GILBERT S, LYNCH N. Perspectives on the CAP theorem [J]. Computer, 2012, 45(2): 30-36. [16] 许子灿,吴荣泉.基于消息传递的Paxos算法研究[J].计算机工程,2011,37(21):287-290.(XU Z C, WU R Q. Research on Paxos algorithm based on messages passing [J]. Computer Engineering, 2011, 37(21): 287-290.) [17] 杨春明,杜炯.一种基于Paxos算法的高可用分布式锁服务系统[J].西南科技大学学报,2014,29(2):60-65.(YANG C M, DU J. A highly available distributed lock service system based Paxos algorithm [J]. Journal of Southwest University of Science and Technology, 2014, 29(2): 60-65.) Yac:yetanotherdistributedconsensusalgorithm ZHANG Jian1, WANG Yang1*, LIU Dandan2 (1.SchoolofComputerScience,WuhanUniversity,WuhanHubei430072,China;2.StateKeyLabofSoftwareEngineering,WuhanUniversity,WuhanHubei430072,China) There are serious load imbalance and single point performance bottleneck effect in the traditional static topology leader-based distributed consensus algorithm, and the algorithm is unable to work properly when the number of breakdown nodes is larger than 50% of the cluster size. To solve the above problems, a distributed consensus algorithm (Yac) based on dynamic topology and limited voting was proposed. The algorithm dynamically generated the membership subset and Leader nodes to participate in the consensus voting, and varied with time, achieving statistical load balance. With removal of the strong constraints of all the majority of members to participate in voting, the algorithm had a higher degree of failure tolerance. The security constraints of the algorithm were reestablished by the log chain mechanism, and the correctness of the algorithm was proved. The experimental results show that the load concentration effect of single point in the improved algorithm is significantly lower than that of the mainstream static topology leader-based distributed consensus algorithm Zookeeper. The improved algorithm has better fault tolerance than Zookeeper in most cases and maintains the same as Zookeeper in the worst case. Under the same cluster size, the improved algorithm has higher throughput upper limit than Zookeeper. distributed consensus; Paxos algorithm; voting group; log chain; load balance 2017- 03- 13; 2017- 05- 07。 国家自然科学基金资助项目(61103216)。 张健(1976—),男,安徽铜陵人,教授,博士,主要研究方向:云计算、物联网; 汪洋(1990—),男,湖北武汉人,硕士研究生,主要研究方向:云计算、分布式计算; 刘丹丹(1980—),女,湖北武汉人,副教授,博士,CCF会员,主要研究方向:无线网络、移动计算。 1001- 9081(2017)09- 2524- 07 10.11772/j.issn.1001- 9081.2017.09.2524 TP301.6 A This work is partially supported by the National Natural Science Foundation of China (61103216). ZHANGJian, born in 1976, Ph. D., professor. His research interests include cloud computing, Internet of things. WANGYang, born in 1990, M. S. candidate. His research interests include cloud computing, distributed computing. LIUDandan, born in 1980, Ph. D., associate professor. Her research interests include wireless network, mobile computing.2 实验与分析


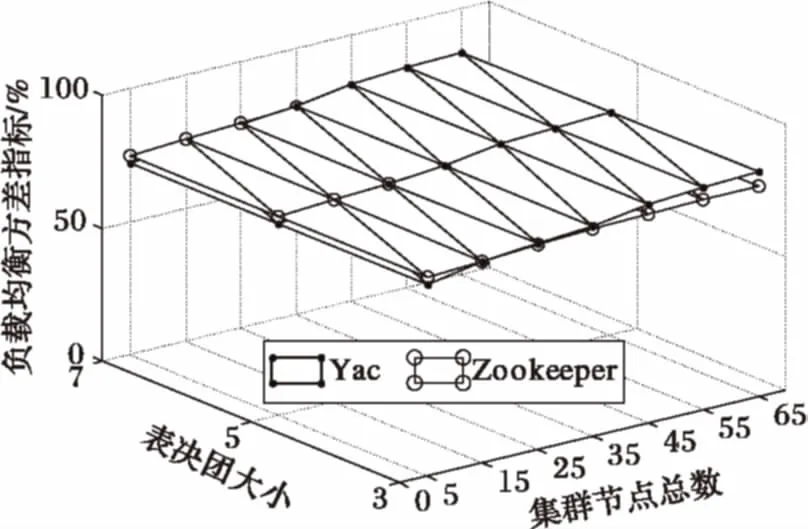
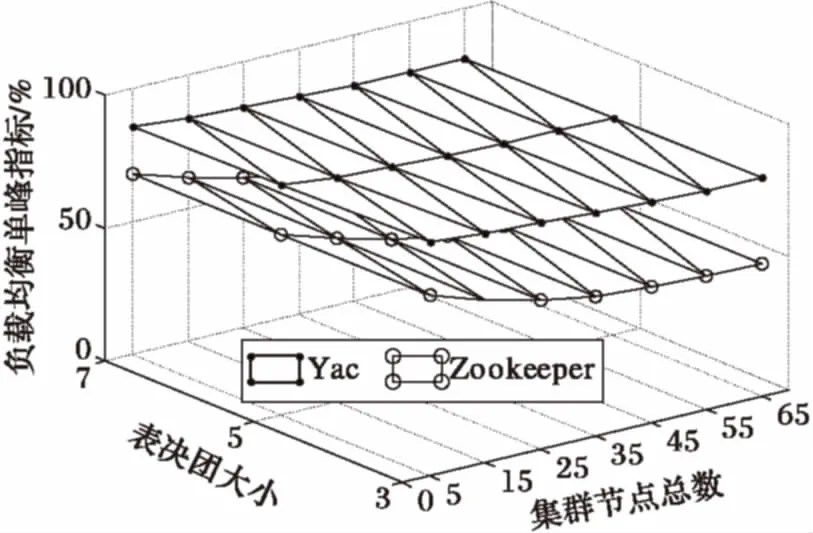

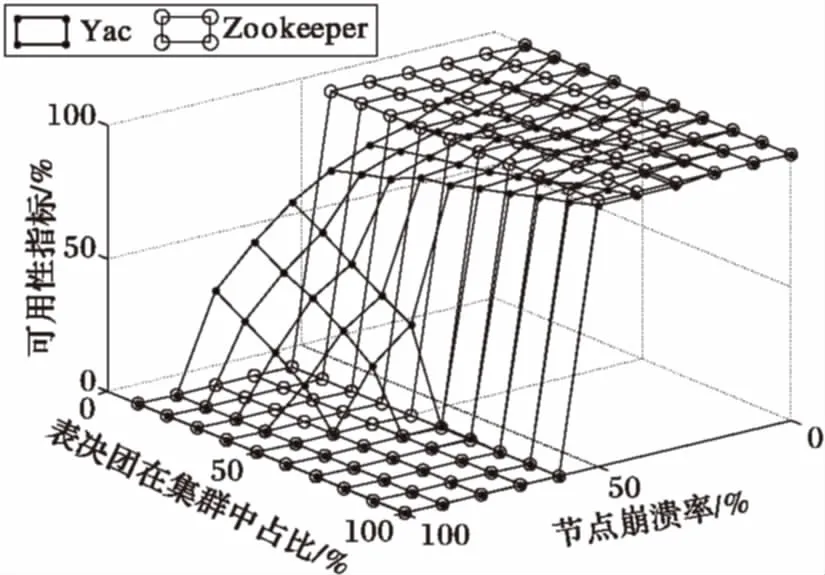

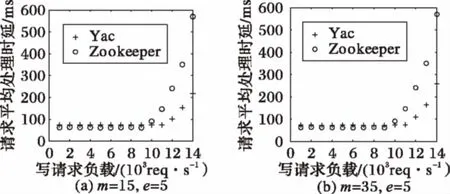
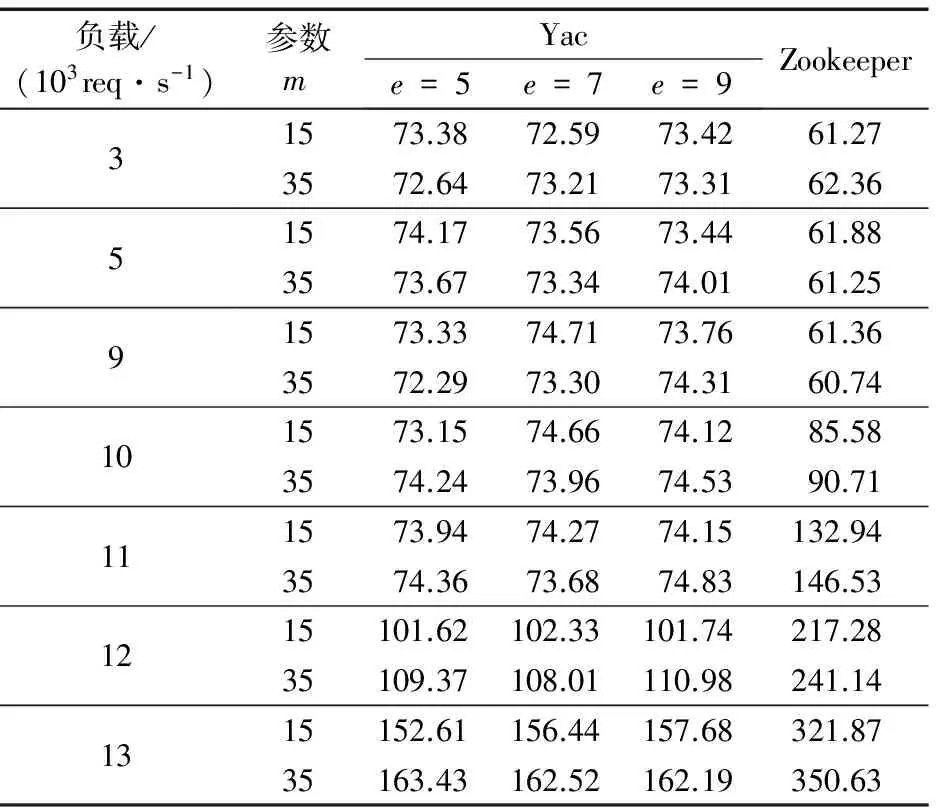
3 结语
