语音端点检测在实时语音截取中的应用
2017-11-15洪奕鑫张浩川吴哲顺
洪奕鑫,张浩川,余 荣,吴哲顺
(广东工业大学 自动化学院,广东 广州 510006)
语音端点检测在实时语音截取中的应用
洪奕鑫,张浩川,余 荣,吴哲顺
(广东工业大学 自动化学院,广东 广州 510006)
语音端点检测在语音识别系统中占有重要地位.针对在噪声多变的环境中实时截取完整语音信号存在困难,文章提出一种实时语音端点检测方法.该方法首先提取每帧信号的短时平均过零率与Mel频率倒谱系数;然后利用前N帧背景噪声的Mel频率倒谱系数对当前帧进行归一化,并以该特征矢量的L2范数作为另一特征;最后根据多特征分析对有效语音信号进行截取.实验结果表明,该方法在多变的噪声环境中,截取完整语音信号具有较高准确率.
语音端点检测;Mel频率倒谱系数;短时平均过零率;多特征
随着人工智能的发展和语音处理技术的日渐成熟,自然语音交互技术也得到了快速发展.目前,云端模式逐渐兴起,终端负责简单的语音信号处理运算,将运算量较大的部分托付给云端,这样可以降低终端的运行压力,也为语音交互提供了更多选择.相应的,各大语音云服务厂商已经推出了各种语音接入方案,终端只需将实时的语音信号数据发送至语音云服务厂商的语音处理引擎中,即可对语音数据作进一步处理.在这种情况下,终端如何在实时接收到的麦克风采样数据中保证获得的语音数据的完整性,关乎整个实时语音交互系统的稳定性.
语音端点检测技术是在一段带噪的音频信号中检测出语音的有效起始与终止位置,在现有技术方案中,语音端点检测方法大致可分为基于模式识别[1-2]与基于特征判决[3-4]两大类.由于模式识别的方法相比于特征判决在信噪比较低的环境下通常能够取得较好的效果,但其前提是训练样本足以表征端点特征的统计特性,且存在训练算法繁琐、计算量大等缺点,因此很难在实时系统中使用;而基于特征的判决方法由于计算简单、响应速度快被广泛研究和应用.传统特征判决算法很多,如时域中的双门限算法[5]、频域中的倒谱距离[6]的检测算法等;目前应用较广的有基于短时过零率、谱熵与倒谱距离的检测方法.但不同特征本身在表征语音信号特性存在一定的局限,短时过零率在高信噪比中能有效区分清音帧,而在低信噪比较高的场合几乎失效;倒谱距离类似于短时对数能量特性,对声音敏感,对于实时环境中存在的诸如碰撞、敲打声极易出现误判;而谱熵由于难以区分弱摩擦音,容易错失起始音节从而导致语音数据的不完整.因此在噪声多变的环境中,使用单一特征判决的算法无法取得理想的效果.
本文提出的算法融合了短时平均过零率与Mel频率倒谱系数的L2范数各自的优势,同时利用短时过零率的局部统计特性来跟踪多变的环境噪声来自适应调整阈值,因此在实时检测过程中,极大地提高了语音有效信号截取的准确性.
1 实时语音信号截取算法
完整的实时语音截取算法包括音频信号的预处理、特征提取、端点检测与后处理4个步骤,步骤之间虽然在功能上划分相对明确,却缺一不可.如何处理好这4个步骤,关系到整个语音信号截取的效果.
1.1 预处理
在实时语音信号分析过程中,为提取更好的语音特征,通常在信号预处理阶段所采用的方法是对语音信号进行预加重、分帧、加窗等操作.由于语音信号具有短时平稳与短时相关的特性,分帧过程中通常设置每帧信号x[n]的帧长在10~40 ms之间,帧移一般取值为帧长的一半;之后通过一阶滤波器来提高语音高频部分的权重以消除低频信号的干扰;最后使用合适的窗函数来缓解短时频域分析所产生的频谱能量泄露问题[7],常见的窗函数有矩形窗、汉明窗等.
1.2 特征提取
1.2.1 短时过零率
短时过零率作为语音时域分析的一种特征参数.该特征可以在一定程度上反映其频谱性质,因此可以通过短时平均过零率获得谱特性的粗略估计.在离散信号下,短时平均过零率实际就是信号采样点符号变化的次数.对于离散信号,x[n]短时平均过零率定义为:
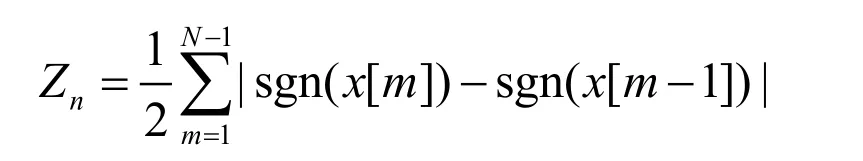
式中,N是信号的有效长度,其中符号函数定义为:

1.2.2 Mel频率倒谱系数
在内耳频率分析的人类声音感知模型的触发下,由Davis等在1989年首次提出Mel频率倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC).Mel频率倒谱系数的基本思想是,基于滤波器组的频率分析,滤波器组的带宽间隔约为临界子带的间隔[8].MFCC特征提取步骤为:
(1)将音频信号分帧加窗;
(2)利用傅里叶变换计算频谱;
(3)将频谱按照Bark的划分方式划分为N个单元,对这N个单元使用滤波器组分别计算每个滤波器对应的Bark单元中的能量;
(4)将步骤3中获取的每个能量转换为对应的对数能量;
(5)对步骤4中的结果作离散余弦变换;
(6)保留变换后的12~20个结果,该结果即为求解的MFCC特征向量.
从以上的提取过程中可以明显地看出,MFCC特征本质上是在一定的频谱范围计算该频段所持有的能量,而这个频段是基于人耳听觉,因此它拥有与短时能量相似的特性,但在语音部分表现出一种放大效应.
由于MFCC特征在不同维度上数值差异大,为了平均每一维度的贡献与减弱声学信号扭曲的影响,本文对MFCC特征作均值归一化处理,其均值归一化后的特征矢量如下:
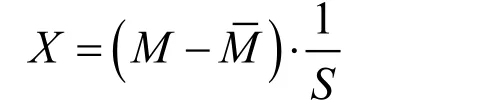
之后将归一化所得的特征矢量的L2范数作为分析特征,其定义为:
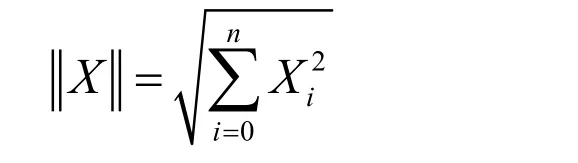
式中n代表MFCC特征的阶数.
1.3 门限估计
由于声波引入的频谱衰减,语音能量集中于3 KHz以下,而清音的大部分能量位于高频,因此清音帧对应高过零率,而浊音帧对应低过零率[9].在信噪比较高的场合中,短时平均过零率可以很好地甄别出语音的清音帧,而当信噪比较低时,浊音帧则更容易被检测到[10].因此,在实时检测过程中,为及时跟踪这种变换趋势,本文利用一个长度为N的缓存器来实时更新最近一段时间的输入信号的过零率,如下:
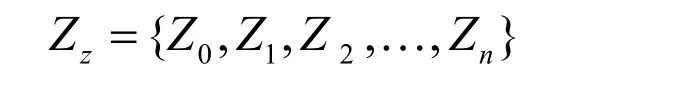
利用标准差可衡量数据波动范围的特性,短时过零率的阈值通过以下规则来自适应更新:

在实时噪声环境中,MFCC特征L2范数在静音段相对平稳,波动程度小,其特性与短时能量相似,不仅对声音敏感,而且具有较好的抗噪能力,因此定义其阈值更新规则:

其中β,η是调节因子,可通过实验调节M为前N帧背景噪声MFCC特征L2范数的均值.
939 Application and development of artificial intelligence technology in nursing
1.4 语音帧提取步骤
在实时检测过程中,假设前N帧信号为背景噪声,并以此估计MFCC的L2范数门限,记为Tm;同理估算短时平均过零率门限,记为Tz.为说明方便,记当前帧MFCC的L2范数为Mc,当前帧的短时平均过零率为Zc,算法执行过程如下.
(1)实时采集音频数据并预处理;
(2)提取Mc与Zc;
(3)判断是否连续N帧Mc过门限,否则更新短时平均过零率的历史缓存,同时更新Tm和Tz,重复步骤1和2,是则进入步骤4;
(4)同时缓存音频帧和Zc,直到Mc回落到门限以下;
(5)判断步骤4缓存的短时平均过零率是否存在连续M帧越过Tz的帧,判决方式为:
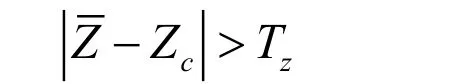
Z为缓存中数据的均值;
(6)若步骤5条件成立,则缓存的音频段为有效语音,否则丢弃;
(7)重复以上步骤.
以上算法关键步骤为4与5,步骤4成立则确认声音出现,而步骤5用于进一步确定该声音是否为语音.同时步骤5中采用绝对值的比较方法,其目的在于解决短时平均过零率在不同信噪比条件下所表现出的不同波形形态问题,该问题在实验中将详细阐述.
2 实验
2.1 实验环境及数据来源
本实验在普通的办公环境下进行,为模拟实时过程,通过单通道、采样率16 kHz采集50组包含撞击、拍打等办公噪声的语音信号,每组信号时长10 min.实验中以30 ms对语音信号进行分帧,帧移15 ms;在计算Mel频率倒谱系数时使用汉明窗与26个三角滤波器,采用12阶MFCC.
2.2 实验分析
一段在办公环境下实时采集的包含语音"学习手语动作"与敲打声的原始音频信号如图1所示,红色标记线为有效语音片段,而蓝色标记线为敲打噪声信号.图中可以明显看出,在信噪比较高的情况下,短时过平均过零率对摩擦音节帧敏感,而对于弱摩擦如"语""动"不敏感,但对于敲打声却能够有效过滤.相比于短时对数能量,MFCC的L2范数在同等条件下,后者在有声段具有较高的增益效果,而在静音段波动较为平稳.
如图2所示,对该信号加入SNR=5 dB的高斯白噪声,比较了图1中带噪语音信号的短时对数能量特征曲线、短时过零特征曲线、MFCC的L2范数特征曲线.可以看出,在信噪比较低的情况下,从特征曲线的波动程度可以看出,对于短时平均过零率,反而能够更有效地检测出浊音帧,但过滤噪声帧的能力却被削弱了,这种现象是由于高斯白噪声存在更多的高频成分,而由声带发出的语音在浊音段具有更低的频率;短时对数能量与MFCC的L2范数依旧保持原有的特性.

图1 在办公环境下实时采集的包含语音"学习手语动作"与敲打声的原始音频信号

图2 短时对数能量特征曲线、短时过零特征曲线、MFCC的L2范数特征曲线
结合图1与图2的分析,只要是有声段,MFCC的L2范数都能够很好地检测出来,但是否是有效语音,可以结合短时平均过零率作出进一步的判断.因此,结合MFCC的L2范数对声音的敏感度与短时过零率对语音帧的甄别能力,这种策略可有效地降低误判率,从而提升系统性能.
为比较算法之间的性能,在不同样本和信噪比条件下,对传统双门限算法、常规倒谱距离检测算法与本文提出的检测算法做大量仿真实验,算法准确率以截取到的完整语音信号文件数为评判标准,即:正确截取率 = 完整语音信号文件数/人工标定有效语音段总数.
如表1所示,传统双门限算法在信噪比较低的情况下已经无法正常工作,虽然倒谱距离相比于双门限算法在性能方面有一定的提升,但依旧无法满足实际应用的需求.而本文提出的算法,相比于前两种算法在准确率上有了较大的改善.

表1 不同噪声环境不同信噪比下语音信号截取准确率比较(%)
3 结语
在现实环境中,噪声变化多样,采用单一特征很难对实时变化的信号做出准确的判断,而本文通过观察实时信号中各个特征之间的变化规律,并结合不同特征的优势对传统算法进行改进.实验结果表明,该方法能够有效避免环境中存在的如碰撞、敲打等噪声的影响,并且在低信噪比的条件下准确率有较大的提升,在信噪比较高的诸如办公室、客厅、卧室等环境下进行实时的语音截取均能达到良好的效果.
实验过程中观察到另一个有趣的现象是:当参考噪声缓存不断更新时,MFCC的L2范数在语音结束后将在一段时间内持续在较低的水平,之后才回升到噪声的相对平稳状态区间.在后端点的后处理中,利用这个特征可以用于改善后端点判决的常定时方案.
[1]JUANG C F,CHENG C N,CHEN T M.Speech detection in noisy environments by wavelet energy-based recurrent neural fuzzy network[J].Expert Systems with Applications,2009(1):321-332.
[2]WU J,ZHANG X L.Efficient multiple kernel support vector machine based voice activity detection[J].IEEE Signal Processing Letters,2011(8):466-469.
[3]WANG L,LI C R.An improved speech endpoint detection method based on adaptive band-paritition spectral entropy[J].Computer Simulation,2010(27):373-375.
[4]LU Y,ZHOU N,XIAO K,et al.Improved speech endpoint detection algorithm in strong noise environment[J].Journal of Computer Applications,2014(5):40.
[5]LI X,LI G,LI X.Improved voice activity detection based on iterative spectral subtraction and double thresholds for CVR[C].Australia:Workshop on Power Electronics and Intelligent Transportation System,2008:153-156.
[6]WANG H Z,XU Y C,LI M J.Voice activity detection algorithm based on Mel frequency cepstrum coefficient(MFCC)similarity[J].Journal of Jilin University(Engineering and Technology Edition),2012(5):1331-1335.
[7]王智国.嵌入式人机语音交互系统关键技术研究[D].合肥:中国科学技术大学,2014.
[8]陈振锋,吴蔚澜,刘加,等.基于 Mel 倒谱特征顺序统计滤波的语音端点检测算法[J].中国科学院大学学报,2014(4):524-529.
[9]周明忠,吉立新.基于平均幅度和加权过零率的VAD算法及其FPGA实现[J].信息工程大学学报,2010(6):713-718.
[10]薛胜尧.基于改进型双门限语音端点检测算法的研究[J].电子设计工程,2015(4):78-81.
Application of speech endpoint detection in real-time voice interception
Hong Yixin, Zhang Haochuan, Yu Rong, Wu Zheshun
(Automation School of Guangdong University of Technology, Guangzhou 510006, China)
The speech endpoint detection plays an important role in speech recognition system. It is difficult to intercept the complete speech signal in real-time environment in noisy environment. This paper presents a real-time speech endpoint detection method. Firstly extracts the short-term average zero-crossing rate and Mel frequency cepstrum coefficient(MFCC)of each frame signal. Then, MFCC of the headmost N-frame background noise normalizes the current frame, a feature vector whose L2 norm as another feature. Finally, the effective speech signal was intercepted according to the multi-feature analysis. The experimental results show that the method has higher accuracy in intercepting the complete speech signal in the variable noise environment.
speech endpoint detection; Mel frequency cepstrum coefficient; short-term average zero-crossing rate; multi-feature
国家自然科学基金;项目编号:61422201.
洪奕鑫(1992- ),男,广东潮州人,硕士研究生;研究方向:嵌入式人工智能.
