众核处理器的流水线紧耦合指令循环缓存设计
2017-11-07谢向辉
张 昆 过 锋 郑 方 谢向辉
(数学工程与先进计算国家重点实验室 江苏无锡 214125)
(zhang.kun@meac-skl.cn)
功耗是未来超级计算机的重大挑战.为了满足E级计算的目标,美国能源部提出了50GFLOPSW的能效比目标[1].与之相比,目前Green500[2]的第1名,日本Shoubu超级计算机的能效比仅达到7GFLOPSW.为了实现更高的能效比,需要在追求工艺进步的同时,在体系结构、特别是芯片微结构上做出更多的优化.
众核处理器是高性能计算机的重要实现手段之一.然而,由于片上集成了大量运算核心,众核处理器的设计在功耗和硬件开销上有很多限制.大量的运算核心导致众核处理器功耗较大,过高的功耗会给芯片散热和稳定性带来问题.同时,能效比是未来芯片的重要指标,甚至有可能成为比峰值性能更重要的指标,因此,需要进一步提升众核处理器的能效比.由于片上资源受限,无法采取通用多核处理器的复杂结构、大容量缓存等设计,众核处理器必须采用硬件开销较小的设计,这对提升其能效比又提出了更高的要求.
在冯·诺伊曼结构中,所有的运算均依赖于自存储器中读取的指令,指令的读取、译码这些辅助工作虽然不能直接提供计算能力,但却耗费了较多的芯片功耗[3].因此,本文提出1种面向众核处理器的L0指令缓存设计,同流水线紧耦合的低功耗指令循环缓存.通过同流水线紧耦合的L0指令缓存,可以提供较L1指令缓存更加高能效的取指访问,同时,本文的指令循环缓存位于流水线的取指和预译码站台之后,当取指命中L0缓存时,可以门控循环缓存之前的流水线站台以降低功耗.
为了降低L0缓存的硬件复杂度,以适应众核处理器紧张的硬件资源,本文的L0指令缓存采取了指令循环缓存设计.指令循环缓存技术是经过广泛研究并被数款商用处理器采用的技术,但是本文的循环缓存结合了众核处理器的实际要求,具有3个创新和特点:
1) 本文的指令缓存同流水线紧耦合,不仅作为L0级指令缓存,也作为流水线前段和后段之间的解耦合缓存,一方面减少流水线前段的功耗,另一方面流水线前段和后段的解耦合有利于缓解流水线实现的时序压力.
2) 循环缓存的1个问题是循环出口处带来的流水线气泡,本文提出了循环出口预取技术,有效解决流水气泡问题,使得循环缓存的引入对流水线性能几乎不造成影响.同时,不同于之前的设计,本文循环缓存技术可以在循环的第2次执行开始从缓存中提供指令.
3) 如前文所述,循环缓存的设计必须以较低的硬件开销为前提.本文的工作是体系结构研究同硬件可实现性紧密结合的1次尝试,不仅考虑了指令缓存的可实现性,还讨论了指令缓存同1个示例流水线的紧耦合方式.
1 相关工作
在循环缓存方面有较多的先前工作,本文同这些工作的首要区别在于本文采用了同流水线紧耦合的循环缓存设计,这就解决了几乎所有循环缓存都需要经历“检测循环、装填循环、输出循环”这3个步骤的问题,即直到第3次循环迭代,循环缓存才可以向流水线后段输出指令.
文献[4]中提出了利用指令流中的sbb(short backward branch)指令来判断指令流是否命中循环缓存,sbb指令定义为转移距离较短的回跳转移指令,当转移指令的偏移量小于循环缓存的容量时,可以认为循环体命中了循环缓存.文献[4]使用1个指令计数器来判断循环缓存是否已经输出到sbb指令,这也就意味着文献[4]的结构中只能够包含1个循环体而无法处理内嵌循环.文献[4]面向嵌入式处理器进行设计,且使用了嵌入式应用测试集进行评测,其结果表明在超过32条指令之后其设计的循环缓存命中率就基本上不再增加.
文献[5]提出了1种基于指令队列的程序循环代码动态检测技术.其设计类似于文献[4]的循环缓存实现,区别在于该设计不再使用sbb定义而是通过跳转目标PC同循环缓存存放的第1条指令PC值的关系来判断是否命中循环缓存,但是其同样需要到第3次循环迭代时才可以输出循环.
文献[6]针对DSP处理器设计了1种两路循环缓存,该设计直接存储回跳转移指令的PC值来判断循环缓存是否输出至循环尾部指令.文献[6]同样使用1个循环计数器来判断循环体是否已经输出结束,因此也导致其无法处理嵌套循环.
文献[7]利用加入新的指令以及编译器的帮助,在编译过程中插入适用于循环缓存的辅助指令,以此应对循环体内部的前向转移指令.编译器在进行程序切片时,选择执行次数多的循环插入辅助指令以提示硬件逻辑对循环进行装载.同时,该文给出了1种分层次的译码后指令存储,用以减小循环缓存的容量需求.文献[7]的设计需要编译器和指令集的支持,一定程度上限制了其兼容性和实用性,另外该技术将前向转移指令的2个方向都进行缓存,在某些应用中可能造成功耗的浪费.
文献[8]中利用BTB存储前向跳转的信息,按照BTB中的预测方向处理循环中的前向跳转.这种设计避免了对编译器和指令集的修改,但是,其对前向跳转的处理依赖于BTB的预测成功率,在众核处理器的简单核心中包含1个足够大小的BTB以及其相应控制逻辑对硬件资源的需求较高.
2 指令循环缓存结构
指令循环缓存实现为1个先入先出的队列,存储动态指令流,当检测到包含在循环缓存中的循环时,下一次循环执行的指令将直接从指令循环缓存中读取,进而门控自流水线头部取指部件到预译码部件之间的大部分逻辑,有效减少流水线前段的动态功耗.
2.1 总体结构
包含指令循环缓存的示例流水线前段(front-end,本文指流水线的取指和预译码部分)如图1所示.示例流水线包含2级取指站台和3级译码站台,指令循环缓存位于预译码部件之后.离开预译码部件的指令全部写入指令缓存中,之后再从指令缓存中读出,送至流水线后段.

Fig. 1 Pipeline front-end with the loop cache图1 包含循环缓存的流水线前段
指令循环缓存的总体结构如图2所示.循环缓存中存放连续的顺序指令流,并维护所存顺序指令流的首条指令PC值(下文称为HeadPC).当作为循环体结尾的转移指令离开循环缓存时,将根据其跳转目标PC值判断该循环是否包含在循环缓存中,若目标PC值大于等于HeadPC时,表示循环命中缓存,当拍产生跳转目标指令的读地址,下一拍循环缓存开始从循环体头部输出指令.
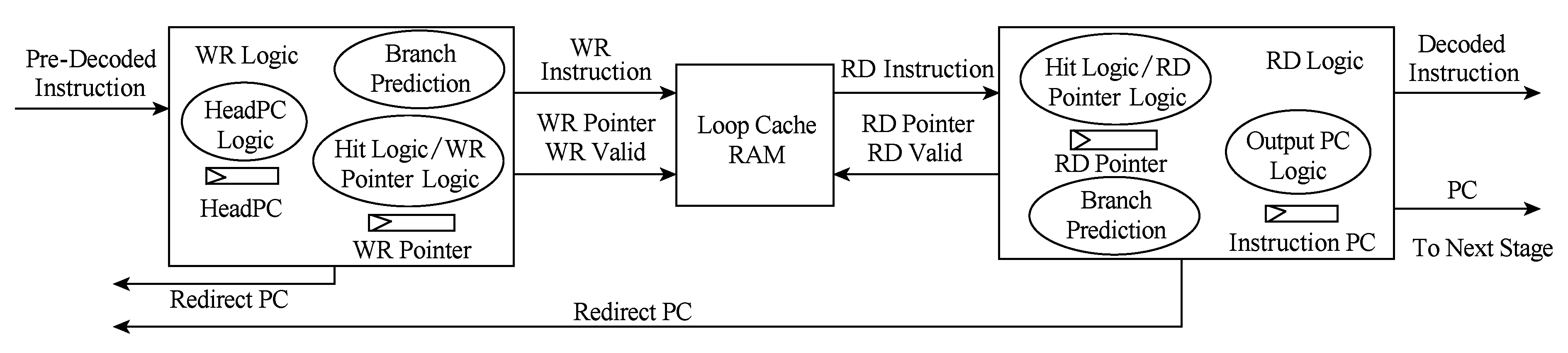
Fig. 2 The structure of the loop cache图2 指令循环缓存总体结构
循环缓存分为写入控制逻辑、读出控制逻辑和存储体3部分组成.众核处理器的运算核心一般采用简单的流水线设计,因此,不同于基于BTB转移机制的流水线中直接根据取指PC值进行下一拍取指的重定向,本文中的流水线前段重定向信号来自预译码的结果.进一步地,重定向信号来自于循环缓存的写控制逻辑,当写控制逻辑发现不命中循环缓存的转移指令时,即可发出取指重定向信号.由于命中循环缓存后,循环体的多次执行将直接由读控制逻辑从缓存存储体中取指,指令不再流经写控制逻辑,因此,在写控制逻辑和读控制逻辑中,均含有转移预测部件.
循环缓存一般设计为“检测到循环”、“装填循环体”、“读取循环体”3个步骤,这种设计的缺点是直到循环体的第3次执行才可以利用循环缓存.本文采取了同流水线紧耦合的循环缓存设计,流水线的动态指令流均需要写入循环缓存,因此当读控制逻辑发现有效命中的循环体时,循环的第2遍执行就可以从指令循环缓存中取指.
同一般的L0级指令缓存设计不同,本文的指令循环缓存不仅可以在循环命中时作为L0级指令缓存使用,由于其放置在流水线的预译码部件之后,可以有效将流水线的“生成地址、取指部分”同“译码、分派、执行部分”解耦合.解耦合有利于减少流水线站台之间的控制信号依赖,缓解流水线实现的时序压力.
本文的循环缓存设计考虑了硬件实现代价,如图2所示,循环缓存主要包括4组触发器,即首指令PC(HeadPC)、写指针、读指针和输出指令PC.逻辑电路主要基于读写指针的操作,因此硬件复杂度较低,在2.2~2.4节中将对各部分逻辑的硬件实现做简要分析.
2.2 写控制逻辑
写控制逻辑主要包含循环缓存命中判断逻辑、写指针控制逻辑和HeadPC控制逻辑.
写控制逻辑接收预译码部件送来的指令组,判断指令组中是否有转移指令且转移指令是否命中循环缓存.若命中循环缓存,则通知流水线前端暂停取指,循环体的下一次迭代可以从循环缓存中直接取指;若不命中循环缓存,则通知流水线的取指部件进行取指目标重定向.需要特别说明的是,对于向前跳转的条件转移指令,若预测其不跳转,则在本文的写控制和读控制逻辑中将其当作顺序指令处理,因此本文的结构是部分支持循环体中内嵌前向转移指令的.
写控制逻辑根据当前写入的有效指令数目,为各条指令分配其在存储体中的写入位置,同时写指针相应地增加.在本文的循环缓存中,写指针值一直取模增加,写指针增加后,指向下一拍到达的首条指令需要写入的位置.
当程序初始运行时,HeadPC设置为程序的首PC(即首次到达写控制逻辑的有效指令的PC值),一旦发生不命中循环缓存的转移,则将HeadPC置为该转移指令的目标PC,之后当取指填满循环缓存并开始覆盖最先指令时,HeadPC随之递增.
硬件开销方面,循环缓存的命中判断逻辑核心为一个比较器,比较器用于判断转移指令的跳转偏移量是否小于循环缓存的容量;写控制逻辑的核心为一个宽度为写指针宽度的加法器,按照每次写入指令的数目增加;HeadPC控制逻辑实现为多路选择器,根据不同的情况对HeadPC进行赋值.
2.3 读控制逻辑
读控制逻辑包含命中判断逻辑、读指针控制逻辑以及输出PC控制逻辑.
由于在读控制逻辑中存在转移预测部件,自循环缓存中读出指令的预测方向可能异于该条指令在写入存储体之前的预测方向,因此,转移指令需要在读控制逻辑中重新判断其是否命中循环缓存.
当循环体的结尾转移指令在写控制逻辑判断为命中且在读控制逻辑中也判断为命中时,下一次循环体执行可以直接从循环缓存中取指;当循环体的结尾转移指令在写控制逻辑中判断为命中而读控制逻辑判断为不命中,则意味着循环体到达循环出口,需要通知流水线前段从循环出口重定向取指;同时,存在在写控制逻辑中判断为不命中而在读控制逻辑中判断为命中的转移指令,这是因为对于同一条指令,其转移预测方向可能改变,这种情况属于内嵌的循环,本文的循环缓存完全支持这种内嵌循环而不需要任何软件支持.
读控制逻辑根据读写指针的关系判断缓存中是否存在未读取的指令,只要读指针位于写指针之前,则发起有效的读动作.读控制逻辑产生存储体的读地址,并根据存储体输出的指令命中循环缓存的情况,置位下一拍的读地址.对于命中循环缓存的转移指令,其目标指令在存储体中的位置可以通过转移指令偏移量计算而得.当读控制逻辑发现需要取指重定向时,直接将读指针置为写指针并等待重定向取指到达循环缓存即可.
为了减小存储体开销,指令写入存储体时,不再保存其PC值,而是通过读控制逻辑产生.对于顺序执行的指令,PC值逐条递增即可;当在读控制逻辑发现转移指令并预测为跳转时,PC值将置为跳转的目标地址;当执行部件发现转移预测失败时,PC值将设置为流水线恢复后首条到达写控制逻辑的指令PC值.
硬件开销方面,读指针逻辑的核心为一个多路选择器,用于选择递增地址或是命中后的循环首条指令地址;读控制逻辑中的命中判断逻辑包含若干种条件(在写控制逻辑中是否预测为跳转、在读控制逻辑中是否预测为跳转等)的综合;指令PC值逻辑也是一个多路选择器和加法器,用于选择加法器运算得到的顺序递增PC值或是转移指令的跳转目标地址.
2.4 循环出口预取
当循环体命中指令循环缓存时,后续的若干次迭代可以从循环缓存中取指,当循环体尾部转移指令在读控制逻辑中预测为不跳转时,意味着循环体到达循环出口,需要执行其尾部转移指令的顺序后继指令,由此产生流水线取指重定向,而重定向取指将带来自流水线头部到循环缓存站台之间若干拍的气泡.若应用中的循环体迭代次数较少,则上述的气泡将造成性能损失.
为了解决循环出口带来的性能损失,本文的循环缓存设计引入了循环出口预取机制,通过提前将循环出口的若干条指令写入循环缓存,可以有效去除循环执行到出口时的性能损失.
循环出口预取由读控制逻辑发起,当循环体尾部转移指令首次到达读控制逻辑并判断为命中时,意味着循环体即将开始第2次的迭代,此时读控制逻辑通知流水线头部取指逻辑进行循环出口地址的预取.预取取指的数目采用信用管理,读控制逻辑根据当前读写指针关系,计算出在不覆盖已命中循环体的前提下存储体能够容纳的预取指令数目,通知流水线的取指部件.流水线取指部件按照信用取指若干次后再次暂停取指.
循环出口预取不产生任何额外的开销,因为循环出口是一定会被执行的.循环出口预取机制的示意如图3所示.预取取指到达存储体后,将使写指针增长.循环迭代过程中,每次到达循环体尾部转移指令并预测为跳转,读指针移动至循环体头部位置重新开始输出循环体指令;循环体最后1次迭代,到达尾部指令并预测为不跳转时,读指针可以直接移动到顺序的下一个位置,即可正确读取预取的指令.同时,读控制逻辑通知流水线取指部件恢复取指.
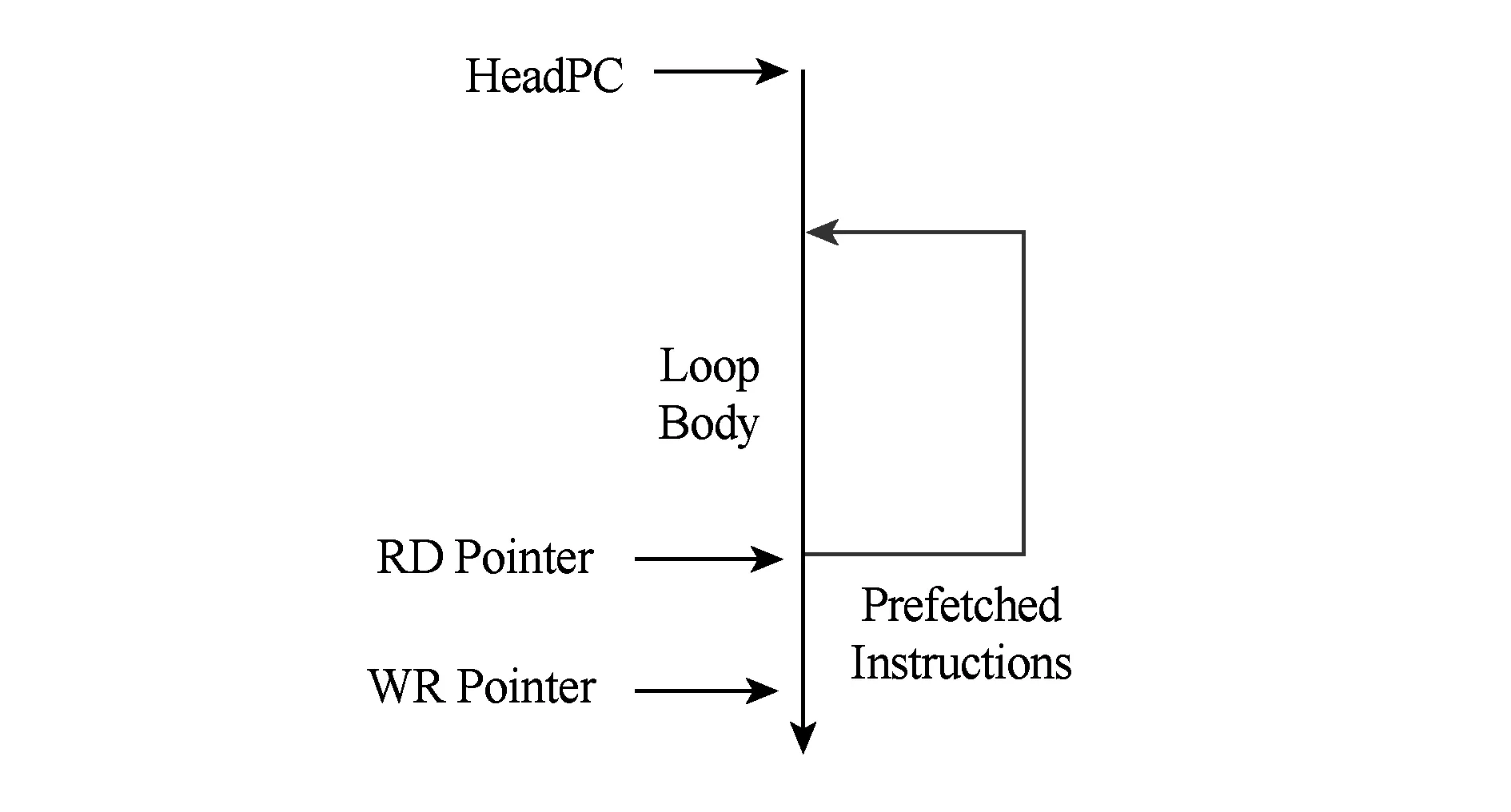
Fig. 3 The prefetching of the loop exit图3 循环出口预取示意图
硬件开销方面,循环出口预取逻辑需要计算预取信用值,通过计算读指针同循环体头部指令位置之间的相对关系,可以得到是否有足够的空间进行出口预取.
3 实 验
3.1 实验方法
本文使用gem5[9]模拟器对指令循环缓存结构进行建模.众核处理器一般采用大量精简计算核心,因此本文在双发射顺序流水线上实现循环缓存结构.循环缓存的命中判断取决于循环体最后1条转移指令在流水线中的转移预测结果,因此,转移预测机制的准确度对循环缓存的性能测试有所影响.由于不同的众核处理器采用不同的转移预测实现思路,为了消除转移预测对测试带来的影响,本文采用理想的转移预测器,即保证每次的转移预测结果都是正确的.
本文测试中使用的主要配置情况如表1所示:
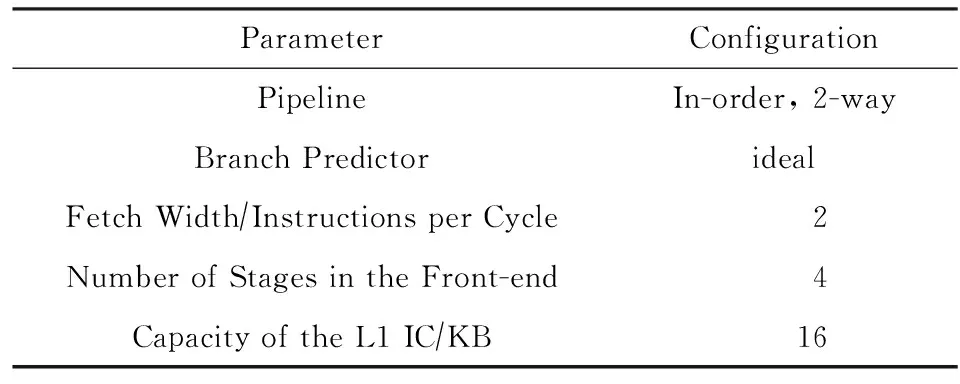
Table 1 The Configuration of the Simulator表1 模拟器配置
表1中流水线前段级数指流水线首部到指令循环缓存之间的站台数,实验中按图1所示结构的数据,该级数将影响循环出口预取的性能,因此特别列出.
本文使用SPEC2006测试集[10]对指令循环缓存结构进行性能测试.gem5模拟器无法正确运行SPEC2006测试集中所有的程序[9].虽然其中部分程序经过对模拟器的修改可以完成运行,为了保证测试结果的一致性,本文选用了SPEC2006中的12道程序进行测试,具体程序如表2所示.测试包括引入循环缓存之后的流水线性能、循环缓存的命中率、循环缓存带来的功耗降低以及循环出口预取等测试.
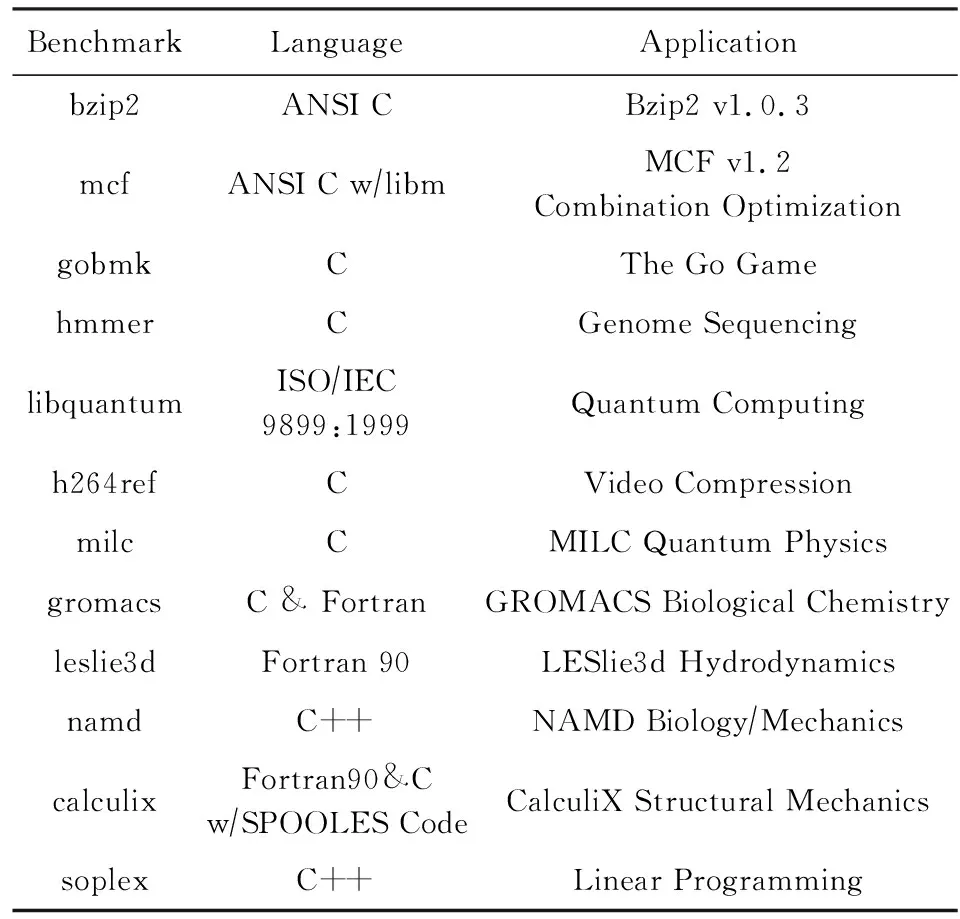
Table 2 Benchmark List表2 测试程序列表
本文采用CACTI存储器功耗模型[11]对指令缓存的访问功耗进行评估.本文对32条指令、64条指令、128条指令、256条指令这4种配置的循环缓存进行测试,实验中流水线的L1指令缓存容量设为16 KB.上述5种容量的存储器访问功耗如表3所示:
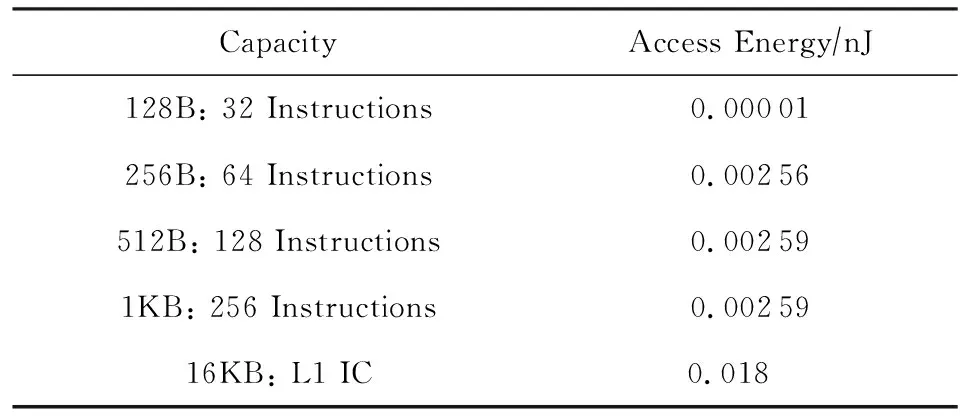
Table 3 The Energy of Memory Accesses表3 存储器访问功耗
表3中128 B到1 KB存储器数据使用单体RAM,行宽度为8 B;16 KB存储器数据使用4体RAM,行宽度为64 B.表3中数据基于32 nm工艺.
3.2 实验结果
本文分别对容量为32条指令、64条指令、128条指令、256条指令这4种配置的循环缓存进行了命中率测试.图4展示了4种配置下的命中率结果,横着给出了12道测试程序,纵轴为各程序在循环缓存中的命中率,不同色块表示不同容量的指令循环缓存.从图4可以看出,循环缓存容量的翻倍能够带来5%左右的命中率提升,当缓存容量到达256条指令时,其平均命中率达到37%.文献[4]中的平均命中率在循环缓冲容量到达32条指令之后就不再有效增长,本文的结果同文献[4]结果的差异主要在于2点:1)同文献[4]中给出的结果相比,本文使用的是SPEC2006的测试集,由于文献[4]是面向嵌入式处理器而设计的循环缓存,因此其使用的是针对嵌入式系统的PowerStone[12]测试集,因此在命中率的绝对值上有差异;2)本文的循环缓冲支持内嵌的循环和内嵌的预测为不跳转的前跳转移指令,当容量扩大时,满足该条件的大循环可以被装载入循环缓冲,因此本文缓存命中率随着缓存容量的增大而持续增加.为了降低实现复杂度,本文的循环缓存没有完全支持循环中内嵌前向跳转的转移指令,因此本文的循环缓存命中率在某些应用中不足10%.但是后续实验表明,由于采用了循环出口预取,本文的循环缓存对流水线性能不会带来影响,因此循环缓存带来的能效收益始终是存在的.
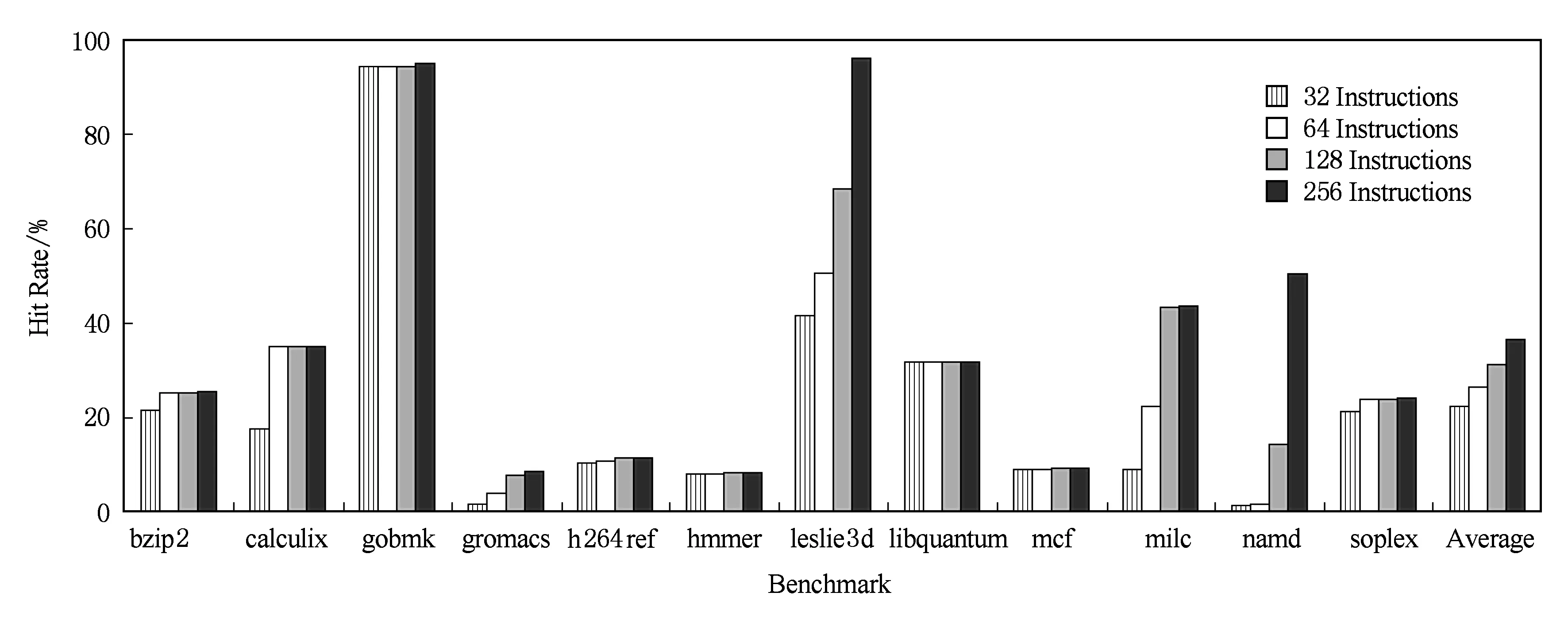
Fig. 4 Hit rate of the loop cache图4 指令循环缓存命中率
本文采用同流水线紧耦合的循环缓存设计,并通过循环出口预取来消除循环退出时的流水线气泡,对循环出口预取的测试如图5所示.图5中给出了使用或不使用预取机制时循环缓存对流水线性能带来的影响,例如,在没有预取机制且缓存容量为32条指令时,循环缓存会造成流水线性能1.48%的损失.没有预取机制时,循环缓存容量的增大会导致性能损失略微增加.这是因为更大的循环缓存将带来更高的命中率,而使得更多的循环体在循环缓存中被读出,因此遇到循环出口的次数也会增加,如2.4节所述,更多的循环出口会带来更大的性能损失.由图5可以看出,采用循环出口预取可以有效地减少循环出口退出时的性能损失.当循环缓存容量达到64条指令或以上时,采用循环出口预取技术可以认为循环缓存不再对流水线性能带来影响.
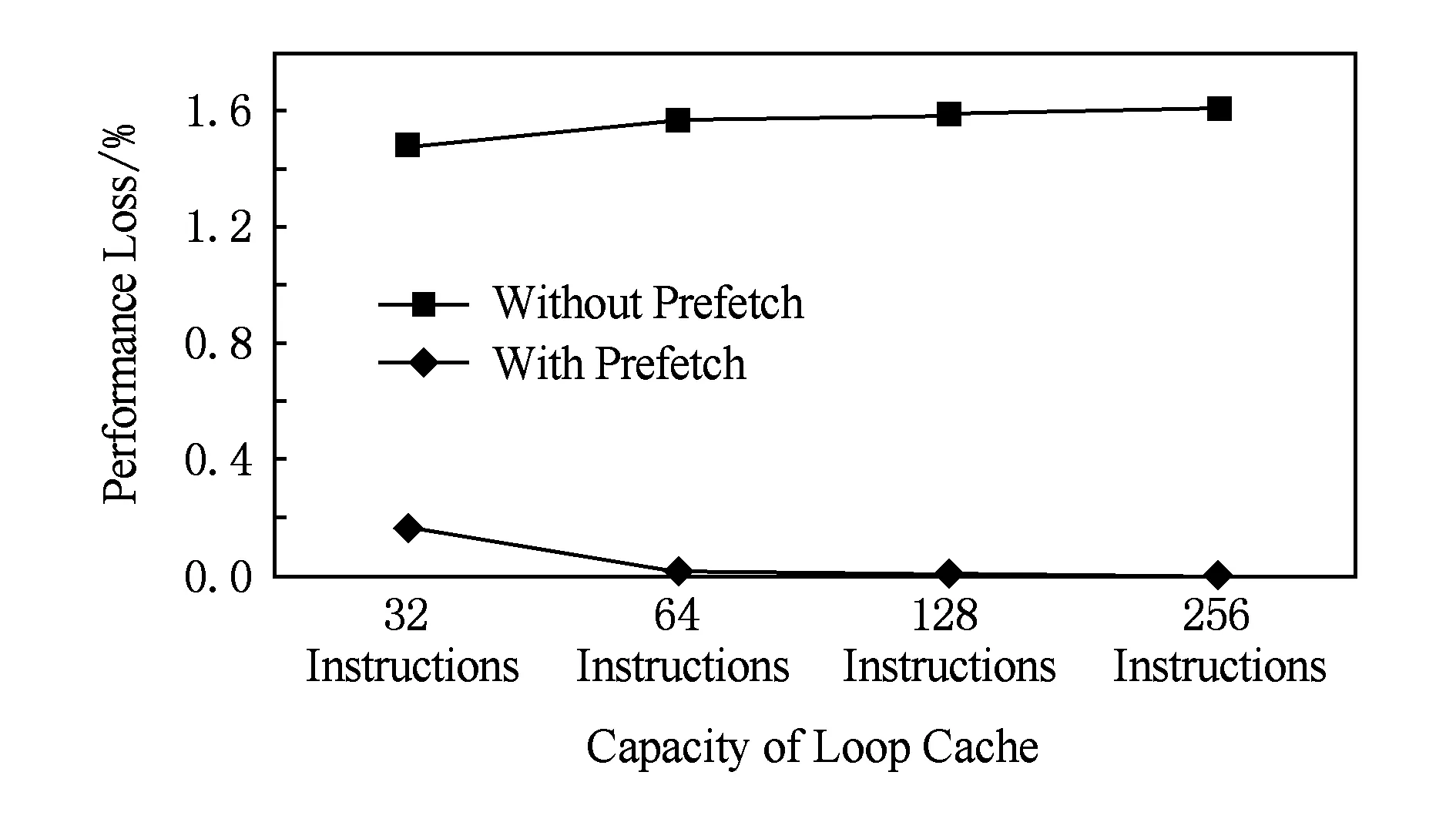
Fig. 5 The effect of loop exit prefetching图5 循环出口预取机制的效果
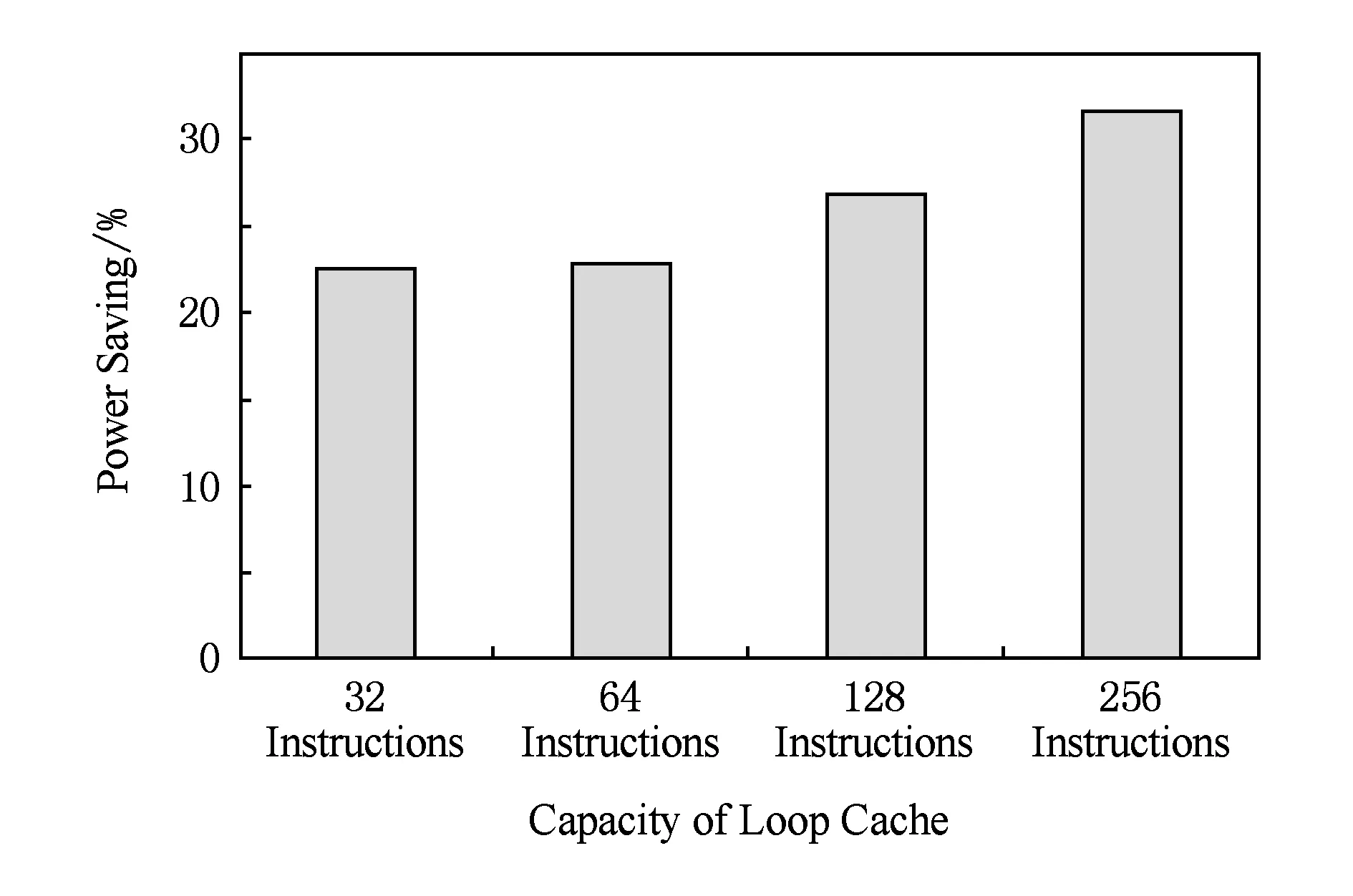
Fig. 6 The power reduction of pipeline’s instruction unit from the loop cache图6 循环缓存对流水线指令部件功耗的降低
利用循环缓存的命中率结果以及表3中的数据,可以对循环缓存带来的存储器访问功耗降低进行计算,如图6所示.如表3所示,不同容量的存储器访问功耗不同,当一部分指令取指命中在循环缓存中时,其访问功耗将显著降低,按照式(1)可以计算得出1次指令缓存访问的平均耗能.其中E*表示指令访问的耗能,P*表示取指在循环缓存或者L1指令缓存中的命中率.利用式(1),可以计算出循环缓存技术可以降低30%左右的指令缓存访问功耗.
Eave=PL0×EL0+PL1×EL1.
(1)
由于在循环缓存中命中后,可以对流水线前段站台进行门控,进而节省流水线前段站台的功耗.显然,门控前段站台的比例等于取指命中循环缓存的比例(如图4中Average所示),因此循环缓存可以进一步降低22%~37%的流水线前段站台功耗.
4 结束语
本文作为体系结构研究同硬件可实现性紧密结合的一次尝试,提出了一种同流水线紧耦合的指令循环缓存设计.指令循环缓存不仅充当流水线前段与后段之间的一个解耦合指令队列,也可以作为L0指令缓存以提供高能效的指令取指.实验结果表明,在不牺牲流水线性能的前提下,以容量为128条指令的循环缓存为例,指令循环缓存可以降低27%的指令取指存储器功耗和31.5%的流水线前段逻辑动态功耗.
未来工作可以在考虑有效控制实现复杂度的同时,增加循环缓存对内嵌有前向跳转指令循环的全面支持,由此可以带来更大的能效收益.同时,本文的循环缓存实现在流水线的译码部件之前,存放的是译码前的指令,后续的工作可以考虑将循环缓存放置在译码部件之后,但是译码部件后的指令循环缓存同流水线的耦合方式将需要重新考虑.
