相似度计算法在汽油溢油识别中的应用
2017-11-04姜慧芸刘颖荣田松柏祝馨怡
姜慧芸,刘颖荣,田松柏,祝馨怡
(中国石化石油化工科学研究院,北京100083)
相似度计算法在汽油溢油识别中的应用
姜慧芸,刘颖荣,田松柏,祝馨怡
(中国石化石油化工科学研究院,北京100083)
将相似度计算法引入到汽油的溢油识别中,将油品的谱图信息转化为二维向量,利用夹角余弦法计算二维向量间的相似度,并以此来表征谱图之间的相似度。对2个组成相似的催化裂化汽油进行了模拟溢油识别。结果表明,催化裂化汽油萃取油E-1与样品油C-1、C-2的相似度分别为0.996、0.974,前者大于后者,萃取油E-2与样品油C-1、C-2的相似度分别为0.983、0.992,前者小于后者,2个萃取油与对应原样品油的相似度结果均高于其与另外一个样品的相似度。在重复性限法和t检验法均无法完全识别的情况下,利用相似度计算法可以准确找到萃取油对应的原样品油,解决了相似油品识别、汽油识别的难题。
溢油识别 相似度计算 指纹图谱
石油是目前最重要的能源之一,为人们的生活带来了极大的便利。但是在其开采、炼制、运输、使用的过程中会不可避免地发生溢油现象,不仅带来了直接的经济损失,还会导致环境污染等一系列很严重的问题。尤其当溢油发生在水体中时,油品会随着水的流动波及更大的范围,造成更严重的后果[1-3]。因此,及时找到溢油源,在短时间内遏止溢油的进行具有非常重要的意义。目前水中溢油监测大多数采用的是指纹图谱及指纹参数比对的方法,即将油品从水体中萃取出来后利用气相色谱(GC)采取指纹图谱,气相色谱质谱(GCMS)分析烃指纹的含量并得到指纹参数,通过比对指纹参数的异同确定溢油源[4-6]。此方法对于大多数差异性较大的油品都能进行区分,但对于差别较小的油品区分能力有限,识别过程繁琐,且由于多数指纹参数是高沸点的藿烷、甾烷的质量比值,对于汽油、柴油的识别就更加困难。炼油厂循环水中轻油的泄漏概率非常大,且存在相同工艺有多套装置共同生产的情况,而这些相同工艺生产的产品差异较小,增加了识别的难度。本研究引入相似度计算的方法,对组成和性质相近、差异性较小的2个催化裂化汽油样品C-1、C-2进行模拟溢油识别。
1 实 验
1.1 样品与试剂
汽油样品来自中国石化茂名分公司及中国石化石油化工科学研究院,为研究方便,对样品进行了编号。进行模拟溢油识别的2个催化裂化汽油编号为C-1、C-2,与之对应的萃取油(即模拟溢油发生,将C-1、C-2加入到水中,再通过萃取方法得到的油)编号为E-1、E-2;样品C-3~C-8来自相同的生产装置,不同的原料,与C-1、C-2组成和性质相近;C-9~C-14为来自不同的生产装置,不同的原料,与C-1、C-2组成和性质有差别的6个催化裂化汽油;S-1~S-6为6个直馏汽油样品。二氯甲烷,分析纯,北京化工厂产品。
1.2 试验油样的制备
1.2.1模拟溢油水样在1 L自来水中加入50 μL汽油样品,摇匀后放置30 min,得到模拟溢油水样。
1.2.2萃取油将含油水转移到分液漏斗中,加入50 mL二氯甲烷,震荡3 min,静置分层后取出下层萃取液,再向分液漏斗中加入50 mL二氯甲烷,震荡3 min,静置分层后取出下层萃取液,重复3次。将萃取液收集到一起并依次使用旋转蒸发仪、氮吹仪挥发溶剂,将样品浓缩至1 mL。
1.2.3原始油品溶液取50 μL汽油溶解到1 mL二氯甲烷中,用于后续测定。
1.3 仪器及分析条件
质谱条件:EI电离源(70 eV),离子源温度230 ℃,四极杆温度150 ℃。用SCAN模式获得油品的指纹图谱轮廓,用SIM模式检测指纹化合物的质量浓度。
1.4 方法原理
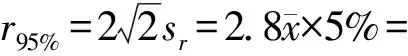
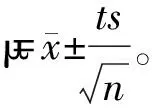
1.4.3相似度计算将色谱图看作一组与保留时间对应的峰面积(或峰高)数值,并将这组数值看作一组(二维)向量,通过二维向量间相似度表征色谱图之间的相似度。二维向量间的相似度用夹角余弦来表示,余弦值介于0~1之间,越接近1表示二者越相似,向量X、Y间的相似度为:

2 结果与讨论
2.1 两种汽油的谱图轮廓及指纹参数
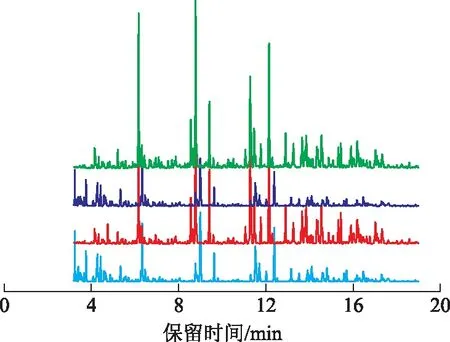
图1 C-1、C-2及其萃取油的谱图轮廓 ——C-1; —E-1; —C-2; —E-2
汽油中的烃指纹化合物为BETX(苯、乙苯、甲苯、二甲苯的合称)和C3-B(C3取代苯),用于溢油识别的指纹参数则是两种烃指纹化合物之间的质量分数比值(如BT指纹参数指油品中苯质量分数与甲苯质量分数之比)。对催化裂化汽油C-1,E-1,C-2,E-2中的BETX及C3-B烃指纹化合物进行分析,相关化合物的定性结果见图2和表1,计算出的32个指纹参数见表2和表3。

图2 BETX和C3-B的质量色谱图

序号化合物简写保留时间∕minm∕z1苯B425782甲苯T635913乙苯E878914间二甲苯+对二甲苯(m+p)⁃X900915邻二甲苯o⁃X964916异丙苯C3⁃B110521207正丙苯C3⁃B2113112083⁃乙基甲苯+4⁃乙基甲苯C3⁃B3115312091,3,5⁃三甲基苯C3⁃B41171120102⁃乙基甲苯C3⁃B51202120111,2,4⁃三甲基苯C3⁃B61239120121,2,3⁃三甲基苯C3⁃B71317120
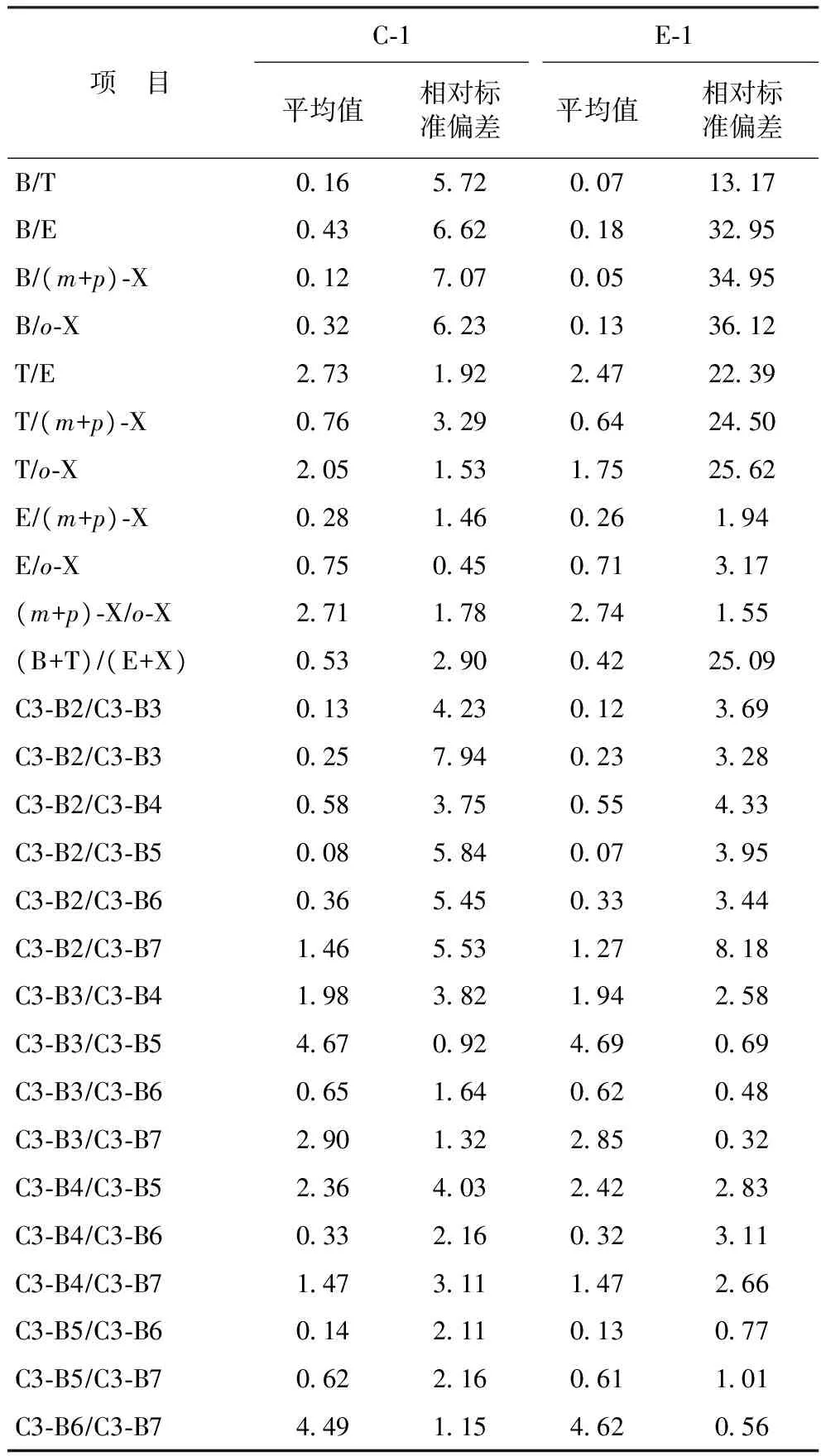
表2 催化裂化汽油C-1及其萃取油E-1指纹参数

表3 催化裂化汽油C-2及其萃取油E-2指纹参数
从2个催化裂化汽油及其萃取油的指纹参数来看,大多数指纹参数(与苯、甲苯相关的所有指纹参数以及与乙苯、二甲苯、C3-B相关的部分指纹参数)多次分析结果的相对标准偏差都超过了5%,而萃取油多次分析结果的相对标准偏差更大,甚至超过了30%。出现上述现象的原因除了实验误差以外,主要是汽油中的组分挥发性大导致的,苯、甲苯在所选指纹化合物中挥发性强,在实验过程(尤其是萃取过程)中极易挥发损失,造成含量的改变,从而影响指纹参数的稳定性,而指纹参数的不稳定性也是汽油馏分难以进行识别的主要原因。
2.2重复性限法识别


表4 筛选的指纹参数


图3 重复性限法评价结果 (a)—E-1与C-1识别结果; (b)—E-2与C-1识别结果; (c)—E-1与C-2识别结果; (d)—E-2与C-2识别结果
分析4个油品的重复性限结果,从图3(a)可以看出,图中所有点的纵坐标都在14%以下,表示萃取油E-1和疑似泄漏油源C-1在统计学上认为来自同一个样品。从图3(c)可以看出,图中有多个点的纵坐标超过了14%,表示萃取油E-1和疑似泄漏油源C-2在统计学上认为不是来自同一个样品。因此可以得出结论,萃取油E-1的泄漏源为油品C-1。从图3(b)可以看出,图中所有点的纵坐标都在14%以下,表示萃取油E-2和疑似泄漏油源C-1在统计学上认为来自同一个样品。从图3(d)可以看出,图中所有点的纵坐标也都在14%以下,表示萃取油E-2和疑似泄漏油源C-2在统计学上认为来自同一个样品。因此,对萃取油E-2的重复性限识别结果认为C-1 、C-2均为其泄漏源样品,但C-1 、C-2为2个不同的样品,显然结果并没有将E-2和疑似泄漏油进行很好的识别。
2.3 t检验法识别
t检验法是检验两组均值数据之间是否存在显著性差异的一种统计学方法,近年来已有很多将t检验应用于不同油样的指纹鉴别过程[9-11]。将萃取油和溢油源的指纹参数分析结果看做2次实验,则两次实验结果应符合t分布统计学规律。分别以疑似溢油源的指纹参数为x轴,萃取油的指纹参数为y轴,做x-y散点图,如果2个油品为同一个油,则图上所有点的误差棒都应跨过直线y=x。
与重复性限法类似,在识别过程中需要进行指纹参数的筛选,去掉平行样分析过程中相对标准偏差大于5%的点。利用表4筛选出的指纹参数进行分析,选取95%的置信区间,分别对2个汽油的萃取油E-1、E-2和疑似泄漏油源C-1、C-2进行了t分布检验,结果如图4所示。
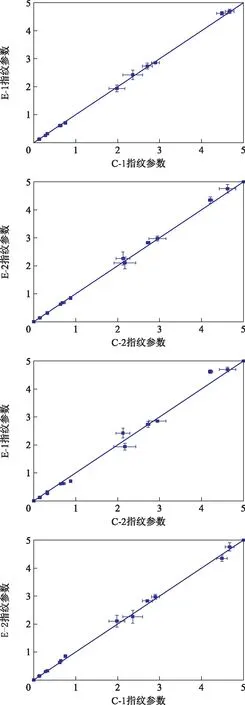
图4 t分布检验识别结果
从图4可以看出,E-1与C-1的t检验图中,所有点的误差棒都跨过了y=x线,而E-1与C-2的t检验图中,部分点的误差棒没有跨过y=x线,因此判断E-1与C-1为同一个油,E-1与C-2不是同一个油,与真实情况相符;对E-2进行溢油源查找时发现,虽然E-2与C-2的t检验图中,所有点的误差棒都跨过了y=x线,但是E-2与C-1的t检验图中,所有点的误差棒也都跨过了y=x线,由此得出的判断是E-2与C-2为同一个样品,E-2与C-1也是同一个样品,这与真实情况不符合,因而对E-2进行溢油源查找失败。
2.4 相似度计算
重复性限法和t检验法都对E-1进行了很好的源识别,而对E-2的源识别未成功,原因为两油品的性质和组成非常接近,并且由于汽油的易挥发性,导致了萃取过程中大量组成和信息的缺失。本研究在此基础上引入相似度计算的方法对其继续进行源识别。由于低沸点段油品成分挥发严重,造成信息的缺失和变异,本研究在进行相似度计算时剪切掉了保留时间8 min以前的谱峰。E-1,C-1,E-2,C-2的色谱图匹配情况如图5所示,相似度计算结果如表5所示。
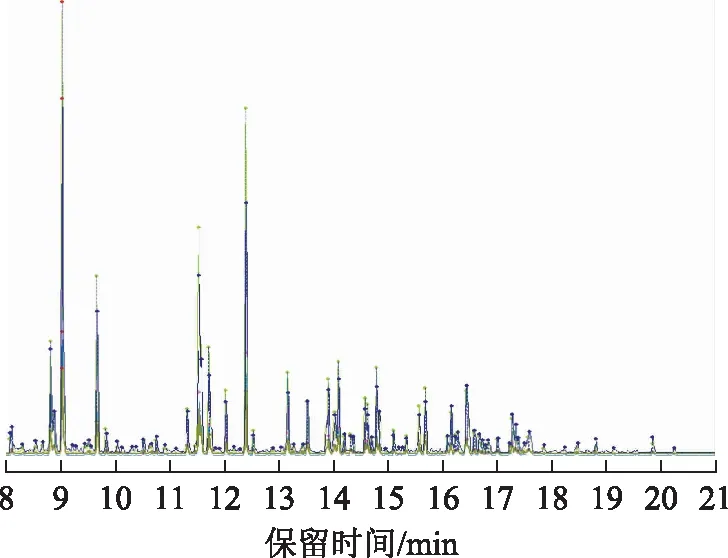
图5 E-1、E-2与C-1、C-2的峰匹配示意
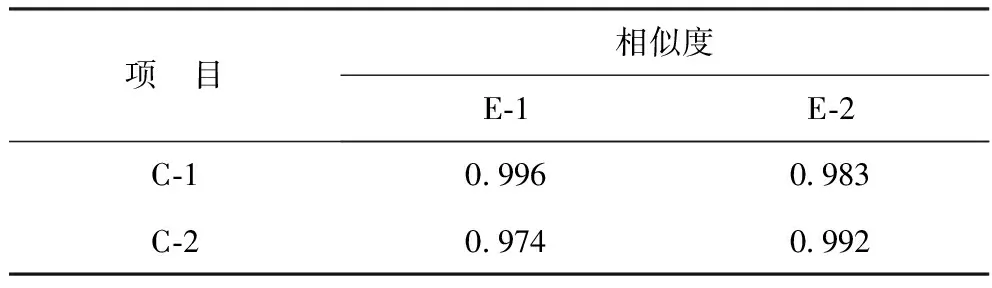
项 目相似度E⁃1E⁃2C⁃109960983C⁃209740992
由表5可知,E-1与C-1的相似度为0.996,E-1与C-2的相似度为0.974,前者高于后者,因而认为E-1与C-1的为同一个样品;同理,E-2与C-2的相似度为0.992,E-2与C-1的相似度为0.983,前者高于后者,认为E-2与C-2为同一个样品。
为了考察实验结果的准确性,在对比2个相似油品的基础上增大疑似溢油源的样本数量,将C-3~C-14加入到识别中,E-1、E-2分别与这些油进行峰匹配和相似度计算,结果见图6和表6。
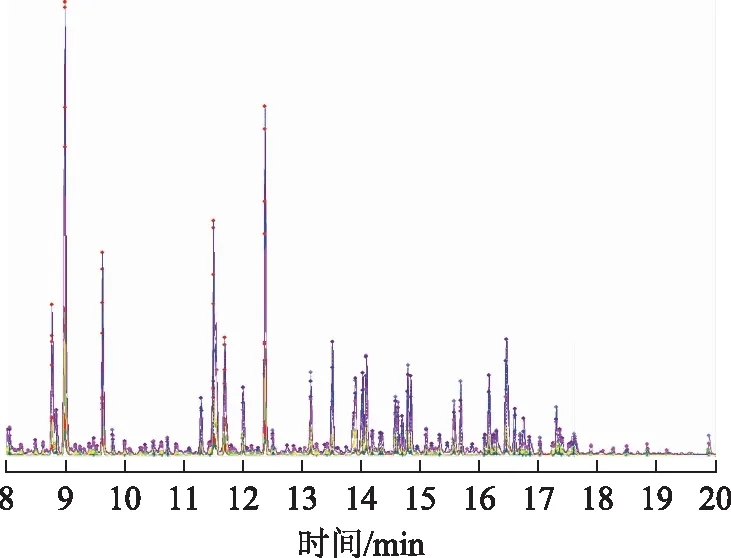
图6 E-1、E-2与C-3~C-14的峰匹配示意
从表6可以看出:E-1与C-3~C-8的相似度为0.957~0.983,与C-9~C-14的相似度为0.919~0.949,都低于E-1与C-1的相似度0.996;同样,E-2与C-3~C-8的相似度为0.967~0.984,与C-9~C-14的相似度为0.927~0.936,都低于E-2与C-2的相似度0.996。即使在增大了疑似溢油源的样本数量的情况下,也能根据相似度的大小准确识别出唯一溢油源。通过表6还可以看出,E-1、E-2与C-3~C-8的相似度都达到了0.95以上,E-1、E-2与C-9~C-14的相似度都在0.95以下0.90以上,E-1、E-2与C-3~C-8的相似度均高于 E-1、E-2与C-9~C-14的相似度,说明油品的加工条件越相近,组成和性质越相近,相似度结果越高。
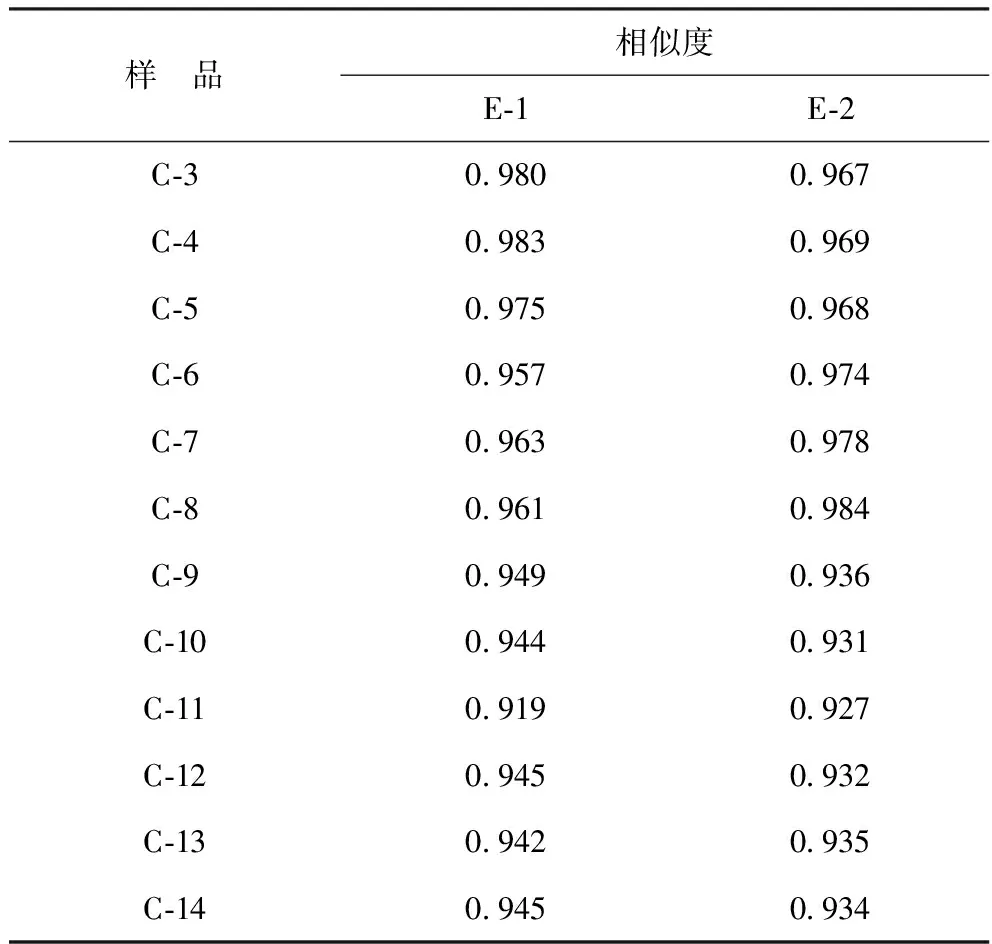
表6 E-1、E-2与C-3~C-14的相似度计算结果
为了进一步考察样品组成对相似度结果的影响,将E-1、E-2与6个不同的直馏汽油S-1~S-6进行相似度计算,其谱图匹配结果和相似度计算结果分别见图7和表7。

图7 E-1、E-2与S-1~S-6的峰匹配示意
由表7可以看出,E-1、E-2与S-1~S-6的相似度结果都在0.5以下,其中S-3、S-5与E-1、E-2的相似度结果甚至小于0.2。相似度计算结果较小的原因是直馏汽油与催化裂化汽油在组成和性质上相差较大。将E-1、E-2与S-1~S-6的相似度结果和E-1、E-2与C1~C14的相似度计算结果对比,萃取油E-1与C-1、E-2与C-2的相似度结果达

表7 E-1、E-2与S-1~S-6相似度计算结果
到0.99以上,E-1、E-2与同类型、组成相近的C-3~C-8的相似度达到了0.95以上,E-1、E-2与同类型、组成有差别的C-3~C-8的相似度达到0.90以上,与不同类型、组成不同的S-1~S-6的相似度在0.50以下。以上结果充分说明油品组成相近时相似度结果高,组成差异大时相似度结果低。因此,根据油品的相似度计算来寻找溢油源的方法是可行的。
3 结 论
工艺类型相同、组成和性质相近的油品,其指纹参数差别较小,造成油品识别的困难,汽油样品由于易挥发,萃取过程中组成和信息变化加大了识别的难度,本课题对组成和性质相近的2个汽油样品进行了模拟溢油识别,在重复性限法和t检验法无法完全识别的基础上,引入相似度计算的方法,对2个催化裂化汽油萃取油进行了识别,成功找到溢油源。E-1、E-2与同类型、组成相近的C-3~C-8的相似度达到0.95以上,E-1、E-2与同类型、组成有差别的C-9~C-14的相似度达到了0.90以上,与不同类型、组成不同的S-1~S-6的相似度在0.50以下,说明油品组成越相近相似度结果越大,油品组成差异越大时相似度结果越小。
[1] Romero I C,Toro-Farmer G,Diercks A R,et al.Large-scale deposition of weathered oil in the Gulf of Mexico following a deep-water oil spill[J].Environmental Pollution,2017,228:179-189
[2] Peterson C T,Grubbs R D,Mickle A.An investigation of effects of the deepwater horizon oil spill on coastal fishes in the Florida big bend using fishery-independent surveys and stable isotope analysis[J].Southeastern Naturalist,2017,16(1):93-108
[3] Wilson M J,Frickel S,Nguyen D,et al.A targeted health risk assessment following the Deepwater Horizon oil spill:Polycyclic aromatic hydrocarbon exposure in Vietnamese-American shrimp consumers[J].Environmental Health Perspectives(Online),2015,123(2):152-159
[4] Wang Zhendi,Stout S A,Fingas M.Forensic fingerprinting of biomarkers for oil spill characterization and source identification[J].Environmental Forensics,2006,7(2):105-146
[5] Fingas M.Oil spill science and technology[M].London:Gulf Professional Publishing,2016:209-296
[6] Yang Chun,Yang Zeyu,Zhang Gong,et al.Characterization and differentiation of chemical fingerprints of virgin and used lubricating oils for identification of contamination or adulteration sources[J].Fuel,2016,163:271-281
[7] 孙培艳,赵玉慧,曹丽歆,等.油指纹鉴别中诊断比值的重复性限比较法[J].海洋环境科学,2011,30(1):110- 117
[8] 王巧敏,文密,严志宇,等.溢油分散剂对原油指纹影响的重复性限法分析[J].环境科学与技术,2015,38(10):74-77
[9] Sun Peiyan,Bao Mutai,Li Guangmei,et al.Fingerprinting and source identification of an oil spill in China Bohai Sea by gas chromatography-flame ionization detection and gas chromatography-mass spectrometry coupled with multi-statistical analyses[J].Journal of Chromatography A,2009,1216(5):830-836
[10] 孙培艳,王鑫平,包木太.油指纹鉴别中特征比值的t检验比较法[J].湖南大学学报(自然科学版),2010,37(9):79-82
[11] 张大伟,马永安,姚子伟,等.典型生物标志物诊断值t检验在溢油鉴别中的评价应用[J].海洋环境科学,2009,28(1):41-44
简 讯
美国加州批准的新添加剂将使B20生物柴油成为美国最清洁的燃料
2017年7月20日,美国加州空气资源委员会(CARB)宣布已认证了一种生物柴油添加剂,经测试和验证,这种添加剂可以使加州的B20混合燃料成为最清洁的柴油燃料,可在美国任何地方实现最低的排放。
这种添加剂能保证清洁燃烧的生物柴油与加州独特配方柴油(称为CARB柴油)调合后,降低包括氮氧化物在内的各项在测排放指标。这项研究初期由NBB(美国生物柴油委员会)主导,该添加剂使得生物柴油在国家低碳燃料标准下保持了竞争优势。
这种添加剂品牌为VESTATM1000,加入后,柴油能满足2018年1月1日实施的CARB替代柴油燃料法规。在CARB柴油中掺入20%添加了VESTATM1000的生物柴油后,NOx和颗粒物的排放量分别降低了1.9%和18%。加州加油有限责任公司负责生产这种添加剂,而太平洋燃料资源有限责任公司则负责销售。两家公司将配合NBB成员以及一些加州燃料团体成员共同支持推广B20生物柴油。
[许建耘摘译自Biofuels Digest,2017-07-26]
德国慕尼黑工业大学开发的分子筛催化剂降低了生物燃料生产过程的能耗
德国慕尼黑工业大学(TUM)的研究人员引入一种新的催化剂概念,正设法使化学过程中一个关键步骤所需的温度和能量显著降低,其诀窍是:反应发生在沸石晶体内非常狭窄的空间内。
在实验室研究中,科学家们证明,使用沸石晶体可以大大降低碳-氧键在酸性水溶液中断裂所需的温度。这个过程的反应速率也比不加沸石的催化剂快得多。
[许建耘摘译自Biofuels Digest,2017-07-04]
世界首套甲烷二氧化碳制合成气日产万方级装置稳定运行
在山西潞安集团煤制油基地建成的世界首套甲烷二氧化碳自热重整制合成气万方级工业化侧线装置2017年8月2日通过了中国石油和化学工业联合会组织的72 h现场标定。目前,该装置已稳定运行1 000 h以上,日产低H2CO摩尔比产品气高达2×105m3以上,日转化利用二氧化碳60 t。
该技术由中国科学院上海高等研究院、山西潞安矿业(集团)有限责任公司和荷兰壳牌石油工业公司联合开发。标定专家认为,该技术成功开发了性能优越的高效纳米镍基催化剂和专用反应器,优化了工艺系统,建成了世界首套万方级规模的甲烷二氧化碳自热重整制合成气工业侧线装置并稳定运行,实现了二氧化碳的高效资源化利用以及产品气H2CO比例的灵活可调,建议尽快开展工业化应用推广。
据称,该技术可以拓展至水蒸气重整和多重整应用,实现合成气H2CO比例(0.7~2.0)的灵活调变。因此,该技术适用于常规或非常规天然气(如富含二氧化碳的海上天然气、页岩气)的转化利用,也适用于煤化工和冶金行业弛放气的利用。目前,合作三方正在进行该技术的商业评估。
[中国石化有机原料科技情报中心站供稿]
APPLICATIONOFSIMILARITYCALCULATIONMETHODINIDENTIFICATIONOFSPILLEDGASOLINE
Jiang Huiyun, Liu Yingrong, Tian Songbai, Zhu Xinyi
(SINOPECResearchInstituteofPetroleumProcessing,Beijing100083))
Similarity algorithm was used for the gasoline oil spill identification.The chromatogram information was first converted to a two-dimensional vector,and the similarity between two-dimensional vectors was then calculated by the angle cosine method,by which the similarity of oil spill fingerprint chromatograms can be measured.The extracted oils referring as E-1,E-2 from two gasoline+water samples(C-1,C-2)from different FCC units were used as simulated oil spills.The results showed that the similarity between E-1 and C-1,E-1 and C-2 is 0.996,0.974 respectively,The similarity between E-2 and C-1,E-2 and C-2 is 0.983,0.992 respectively.It is clear that the similarities difference between extracted oils and its corresponding original gasoline(E-1 and C-1,E-2 and C-2)can clearly distinguish two different gasoline samples.In the case of the repeatability limit method andttest method invalid,the original oil corresponding to extracted oil can be recognized accurately by similarity calculation method.
oil spill identification; similarity calculation; fingerprint chromatography
2017-04-11;修改稿收到日期2017-06-31。
姜慧芸,博士研究生,主要从事石油色谱质谱分析技术及石油分子组成表征方面的研究工作。
田松柏,E-mail:tiansb.ripp@sinopec.com。
中国石油化工股份有限公司合同项目(ST14095)。
