基于SimHash算法的案件辅助判决系统研究
2017-11-03游景扬陈建峡
李 锐, 游景扬, 刘 稳, 王 锦, 陈建峡
(湖北工业大学计算机学院, 湖北 武汉 430068)
基于SimHash算法的案件辅助判决系统研究
李 锐, 游景扬, 刘 稳, 王 锦, 陈建峡
(湖北工业大学计算机学院, 湖北 武汉 430068)
为提高法院工作效率和判案的公正性,开发了案件辅助判决系统。将裁判文书分为刑事、民事、执行、赔偿、行政5大案件类型,便于对判决书的处理,存储和查询。系统采用SimHash算法,对用户提交的判决书提取关键信息,查找出数据库中同类型判决书中相似度最高的判决书推荐给用户。
裁判文书; SimHash算法; 辅助判决系统
法院判决书,是指法院根据案件的判决写成的文书。判决书具有既判力、确定力和执行力。从2014年1月1日起,最高人民法院发布新规定:法院生效的判决书在互联网全面公布,除涉及国家机密、个人隐私、未成年犯罪以及其他四类判决书外,公众均可随时查阅。因此,案件的审判结果越来越受关注。然而,即使对于同类型的案件,不同的法官也会有不同的衡量标准。在判决案件之前,法官往往想知道以往同类案件的判决如何,曾经引起了社会怎样的反应,从而对当前的案件判决起到重要的参考作用。
本文研究的案件辅助判决系统,对于已有的判决书文中关键信息进行机器记录学习,并为使用者提供有用的信息查询,能够让法官快速得到类似案件的裁决文书。这样不仅能够减少法院工作人员对于新的案件的审判时间,极大地提高实际工作的效率,而且便于查看到该案件的判决引发的社会效应与舆论,避免同案不同判。
本文所研究的案件辅助判决系统,是基于文本相似度模型的中文裁判文书推荐系统。在文本相似度模型中,采用了SimHash算法实现法院辅助判决系统,该算法早期运用在Google的网页去重技术,用以提高网页的查询效率。目前国内SimHash算法应用也比较广泛,主要应用在海量文档的反作弊系统,搜索引擎的爬虫系统,相似指纹检索,相似人脸检索等方面。其中,应用SimHash算法开发出的GroupLens[1]系统通过社会信息过滤系统的使用历史的相关信息,计算出用户之间的相似度并对于相似信息进行推荐。这一系统早期也是国外开发的,如今国内应用也十分普遍,豆瓣网通过记录下用户阅读过的文章、购买过的商品、听过的音乐等浏览历史痕迹,以协同过滤的方式猜测用户职业类型,喜好方向及圈子,建立用户的行为向量模型,为用户推荐可能符合需求的网页内容。
目前,国内没有出现过运用SimHash算法来检索相似度较高的裁判文书,仅有的是将裁判文书[2]做一个结构化信息的存储,然后在数据库中建立全文索引,给用户提供捜索功能。比如中国裁判文书网的搜索裁判文书功能。
本系统采用了B/S架构,采用分层的设计思想,运用了SSI框架搭建整个web系统。借鉴中国裁判文书网的分类方式,本系统将裁判文书分为刑事、民事、执行、赔偿、行政5大案件类型,在这5种类型的基础上细分为几十种小类型,便于对判决书的处理、存储和查询。系统对用户提交的判决书提取关键信息,采用SimHash算法查找出数据库中同类型判决书中相似度最高的判决书推荐给用户。
1 SimHash算法
1.1SimHash算法原理
文本相似度的研究主要是从提高查准率、查找速度等方面进行,目前已有诸如布 尔模型、概率模型、向量空间模型等文本表示模型,相似度度量及距离度量等相似度计算方法,也有关于文本分词及语义等方面的研究[3]。本系统中采用的文本相似度算法是SimHash算法,是Google工程师Charikar提出的一种计算文本相似度的算法,它将一篇文档转化为一个t位2进制的签名,如需比较两篇文档,只需要将这两篇文档生成的t位2进制签名进行比较[4]。SimHash算法对一篇文档产生一个长度为t位的二进制签名的伪代码(表1)。每篇文档产生了一个二进制签名,比较两篇文档的相似度,假如现在有两个8位二进制签名00101101,01101001。这两个八位签名中有两位不相同,则这两篇文档的海明距离为2。两篇文档的海明距离越小,则相似度越高。SimHash 算法发明人 Charikar在论文中阐述,64位签名的SimHash算法,海明距离在 3 以内的文本都可以认为是近重复文本[5].所以采用64位签名的SimHash算法。然后根据其相似度矩阵,得到两篇文档的相似度。
SimHash算法的伪代码如下:
Begin
Class SimHash{
Input String container;
Input BigInteger intSimHash;
Input String strSimHash;
Input int Bit<-32;
SimHash(){
Input int v[];
Input ArrayList
String Word;
while(t.hasNext()){
Word<-t.next();
BigInteger w<-this.hash();
for(int I<-0 To Bit){
BigInteger bitmask<-
newBigInteger("1").shiftLeft(i);
if(t.amd(bitmask).signum()!=0){
v[i]<-v[i] add 1;
}else{
v[i]<-v[i] substract 1;
}}}
StringBuffer tb;
for(int i<-0 To B it){
if(v[i]>=0){
tb.append(1);
}else{
tb.append(0);
}}}
Hash(String source){
if(source==null || source.length==0){
return new BigInteger("0");
}else{
char[] sourceArray<-source.toCharArray();
BigInteger hash<-new BigInteger(sourceArray[0])<<7;
BigInteger m <- new BigInteger("10000030");
BigInteger mask<- new BigInteger(2^(-32));
for(char item<-sourceArray[0] To sourceArray[source.length-1]){
BigInteger temp = new BigInteger(item);
hash<-((x multiply m)^temp)&mask;
}
if(hash == BigInteger("-1")){
hash<-BigInteger("-2");
}}
return hash;
}
GetDistance(String str1,String str2){
Input int distance;
if(str1.length()!=str2.length()){
distance<-(-1);
}else{
Distance <- 0;
for(int i<-0 To Bit){
distance++;
}}
return distance;
}}
End
1.2SimHash算法实验分析
1.2.1实验环境及配置说明测试计算机的硬件配置是第六代Inter Core i5处理器,8GB内存,1T 5400转硬盘的PC;软件配置采用了基于Windows10操作系统,Java Development Kit配置运行时环境,同时安装了Myeclipse编译器作为单个案例测试文本运行工具。Tomcat7.0作为B/S架构中的服务器,Firefox作为测试中访问的浏览器。
衡量一个相似度算法的优劣是该算法是否能从海量文本中找出最有价值的文档亦即与当前文档相似度匹配最高的一批文档。本文将测试分为单个案例测试和实际应用测试。
1.2.2SimHash算法单个案例实验本文采用了四个测试文本(表1),实验结果见表2。从表2可以看出,文本1和文本2的海明距离为2,在这四篇文本中相似度最高。文本2和文本4海明距离为11,在这四篇文本中相似度最低。

表1 测试文本

表2 SimHash算法实验结果
从表1的文本结构分析,文本1,文本2,文本3结构大体上相似,内容上也有很多相同,理论上来说相似度最高的两篇应该从这三篇中产生;而文本4和上面3篇文本结构并不相似,内容也相去甚远,所以相似度最低的应该从文本4和另外3篇文本比较中产生,与代码运行的结果一致。
1.3.3法院判决书测试结果及分析在实际测试中,本文预先标记部分文档作为测试中的目标文档。然后将本文的目标文档和待测试文档混合在一起。通过该文本相似度推荐后,得到推荐的文档列表衡量该算法的性能[6]。
表2中第一行表示推荐的文档排名,第二行为推荐的文档名,第三行为推荐文本效果值。如果推荐文本属于本文预先给出的目标文档,则推荐效果值为该相似值,如果属于背景噪声文档,则定义推荐效果值为0,如果属于强噪声文档,则定义为相似度的相反数。本文使用DCGp指标衡量算法的推荐性能。
式中p表示排名,rel表示推荐效果值。因为裁判文书分为5大类型,故而本文将实验分为5组,分别为刑事案件、民事案件、赔偿案件、行政案件、执行案件;将文档分为3种类型:目标文档、强噪声文档、背景噪声文档。目标文档是本文预先处理的和原文档相似度极高的文档;强噪声文档即本文在网上爬取的和本文裁判文书完全不相关的文档;背景噪声文档是某法院3年的裁判文书集,总共是16 542篇,其中行政案件705篇,民事案件12 457篇,赔偿案件8篇,刑事案件1493篇,执行案件1879篇(表4)。

表3 推荐结果列表

表4 测试数据信息

表5 测试结果
最后得到测试结果见表5。在5种案件类型的测试中,行政案件推荐的5篇文档都属于目标文档,民事案件中前3篇文档属于目标文档,后2篇属于背景噪声文档,赔偿案件中5篇文档全部属于目标文档,刑事案件中推荐的第5篇文档属于背景噪声文档,其余是目标文档,执行案件中推荐的第4篇文档为背景噪声文档。其余4篇是目标文档。在这5次实验中系统没有向本文推荐强噪声文档。本文通过DCGp公式,求出了这5种类型案件的DCGp的值(表6)。

表6 最终DCGp结果
从DCGp结果来看,行政案件的DCGp值最大,系统推荐的结果是最佳的;赔偿案件其次,但是赔偿案件的背景噪声文档的量相对于其他的类型严重偏少。可能导致此类型案件测试结果可信度低。民事案件DCGp值最小,这个和背景噪声文档的量太大有关系,因为在背景噪声文档中可能有和提交的原文档相似度很高的文档,所以推荐结果中出现了较多的背景噪声文档。本文可以看到所有的测试结果中系统没有给本文推荐强噪声文档,综上分析这个推荐结果有一定可靠性,这种情况差错率几乎为零。以上数据表示,根据SimHash算法设计出来的文本内容推荐系统是成功的。
2 系统设计与实现
2.1系统总体设计
该系统主要包含三个功能模块:系统管理、案件查询、同案同判(图1)。前端页面开发运用Html CSS JavaScript技术,后台使用Java语言,为了提高开发效率且易于维护,采用了SSI框架,MVC模式使系统开发过程更加清晰。

图 1 系统总体架构图
2.2系统功能模块设计
2.2.1系统总体功能模块系统总体功能模块见图2。
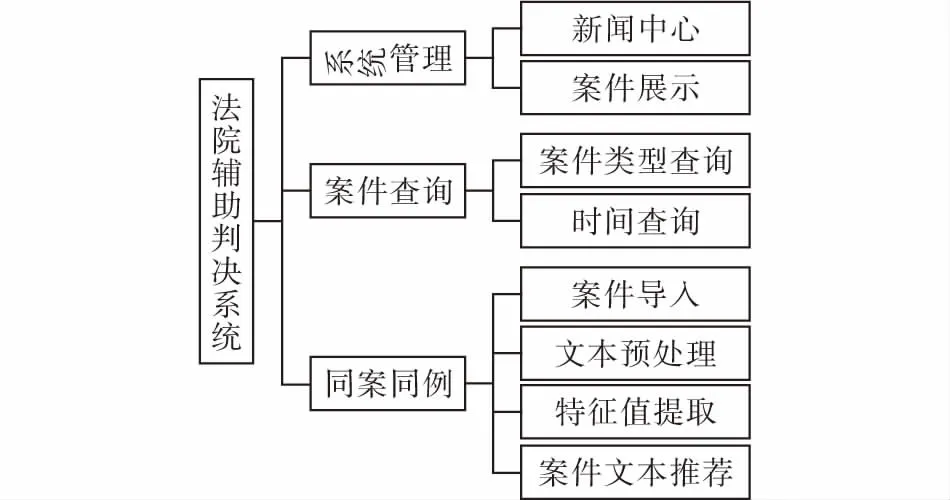
图 2 系统总体功能模块图
2.2.2系统功能子模块设计系统管理模块分为两个部分,新闻中心和案件信息。新闻中心工作流程见图3。案件查询子模块可以分为根据案件类型查询根据法院层级和案件审判时间查询。其模块工作流程见图4。
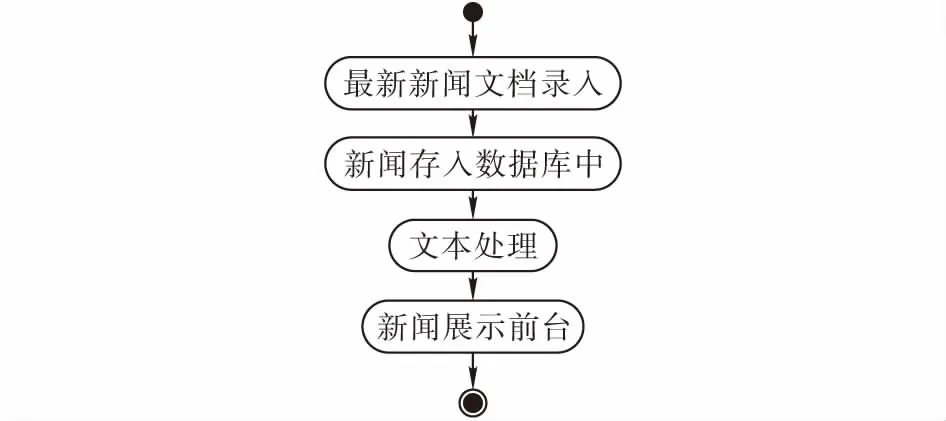
图 3 系统管理子模块流程图

图 4 案件查询子模块流程图

图 5 同案同判流程图
同案同判子模块是从数据库中查找相同类型的案件,并从中选出三个与此案件相似程度最高的案件,然后查看三个案件的信息,根据三个案件的审判结果来裁决此案件。其模块工作流程见图5。
2.3系统数据库设计
系统数据库设计见表7~表10。
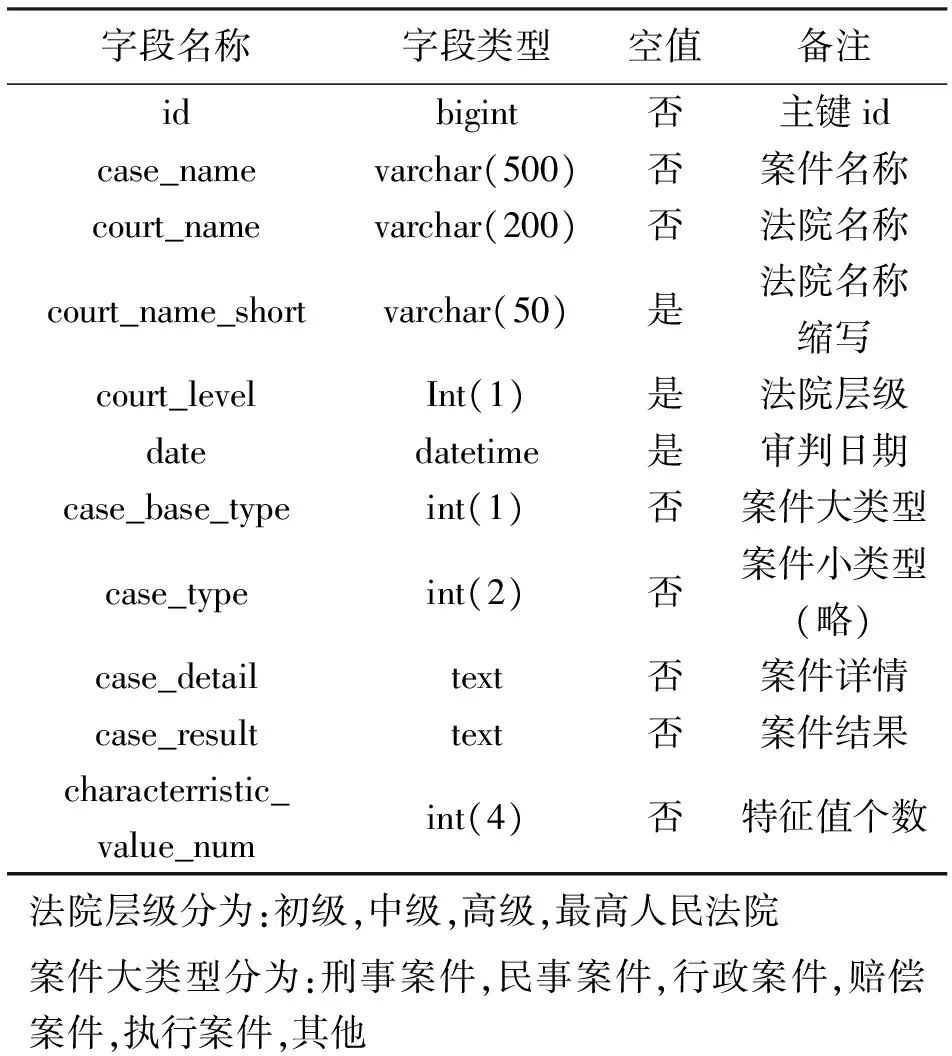
表7 案件信息表

表8 案件人员表
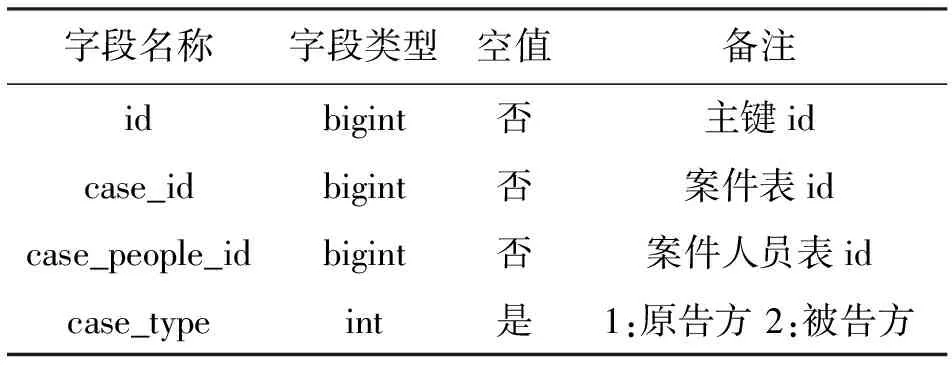
表9 案件人员关联表
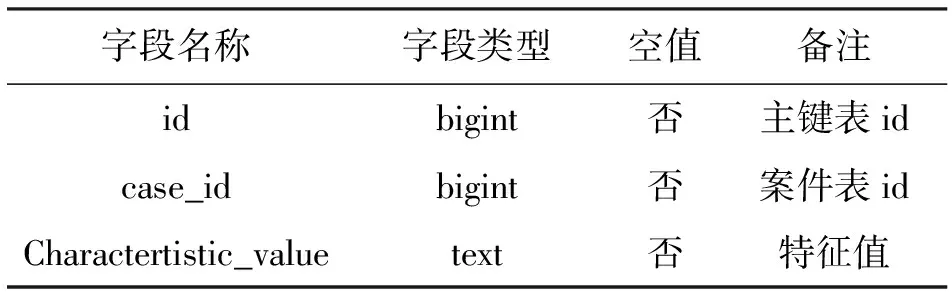
表10 特征值表
2.4系统实现
系统界面实现见图6,案件查询子模块实现见图7,同案同判子模块实现见图8。
图 6 系统首页
图 7 案件查询

图 8 案件文本推荐
3 总结与展望
中文的文本相似度计算处理非常复杂,在具体应用中还有很多不确定性,无法统一给出解决方案。有很多难点、问题需要不断地去发现、探讨和改进。
1)对中文分词技术的研究和实现
由于时间和条件有限,考虑到中文分词在本文中只是文本预处理的一个步骤,本文使用了中文分词器来完成分词的工作。但中文分词技术是文本挖掘、信息处理的关键基础工作,它的有效计算也是非常重要的。因此,下一步可以研究建立自己的分词系统。
2)对于相似度的考虑
在实际的应用过程中,很多地方需要用到相似度,在本文的方法中,段落数比较多的情况下,会根据预先设置的关键字,把较低相似度的语句舍弃,从而减少计算量。目前关键字的设置大多是按照经验人工设置的,今后可以从这方面入手,研究自动设置关键字方法,使得系统效率得到提高。
3)文本相似度计算方法的进一步研究
本文仅对文本相似度的计算作了初步研究。未来对于文本理解的相似度计算必然成为中文文本处理的主流,因为这种方法更适合汉语语言的特点和习惯。建立一个更好的文本理解模型,并把它应用到更多的领域进行事件处理,将是进一步研究的主要目标。
[1] Sohn J S, Bae U B, Chung I J. Contents recommendation method using social network analysis[J]. Wireless Personal Communications, 2013, 73(4):1529-1546.
[2] 向李兴. 基于自然语言处理的裁判文书推荐系统设计与实现[D]. 南京:南京大学,2015.
[3] 谭静.基于向量空间模型的文本相似度研究[D]. 成都:西南石油大学,2015.
[4] 董博,郑庆华,宋凯磊,等. 基于多 SimHash指纹的近似文本检测[J]. 小型微型计算机系统, 2017,17(5):129-132.
[5] Scherbina A, Kuznetsov S. Clustering of Web sessions using levenshtein metric[C]//International Conference on Advances in Data Mining: Applications in Image Mining, Medicine and Biotechnology, Management and Environmental Control, and Telecommunications. Springer-Verlag, 2004:127-133.
[6] 伍盛. 基于词义相似度的文本推荐系统的研究与实现[D]. 成都:电子科技大学,2012.
[责任编校:张岩芳]
TheLegalDecisionSupportSystemBasedonSimHashAlgorithm
LI Rui, YOU Jingyang, LIU Wen, WANG Jin, CHEN Jianxia
(SchoolofComputerScience,HubeiUniv.ofTech.,Wuhan430068,China)
The paper proposes an decision support system for the legal case judgements, in which the system divides the cases into five categories: criminal, civil, execution, compensation, and administrative ones in order to process, preserve and query the cases easily. In particular, the system, using the SimHash algorithm, extracts the key information from the judgements that users submit, and finds the similar decision in the database with the highest similarity and then recommends it to the users. The experimental results show that the system can not only greatly improve the efficiency of the actual work, but also help to improve the impartiality of judgements.
judgements; SimHash algorithm; the decision support system
2016-12-10
湖北省教育厅青年基金(Q20141420)
李 锐(1994-), 男, 湖北嘉鱼人,湖北工业大学本科生,研究方向为机器学习
游景扬(1996-),男,河南信阳人,湖北工业大学本科生, 研究方向机器学习
1003-4684(2017)05-0067-06
TP391
A
