数据挖掘技术在民生领域中的应用
2017-11-02上海市民政局信息研究中心上海200093
沈 俭(上海市民政局 信息研究中心,上海 200093)
数据挖掘技术在民生领域中的应用
沈 俭
(上海市民政局 信息研究中心,上海 200093)
近年来,科学研究、电子商务、民生保障等诸多互联网应用领域飞速发展,数据规模、数据种类正在以极快的速度增长,大数据时代已悄然来临。如何管理好、利用好、分析好这些海量数据来促进相关领域的发展,是我们当下需要亟待思索的问题。但由于行业壁垒的局限性、数据挖掘不够、数据“孤岛”、数据鸿沟等制约着大数据支撑解决民生领域问题能力的提升。因此,需要我们打破行业壁垒、突破数据“孤岛”现象、不断的探索新的数据挖掘技术,从而提高大数据支撑解决民生领域问题的能力。概述了数据挖掘技术发展现状,介绍了数据挖掘的一般过程及方法论,结合实际,以数据挖掘在养老服务领域中的应用为例,对数据挖掘应用解决扶贫帮困、救助保障、养老服务、基层治理等民生问题进行简要阐述。
民生保障; 大数据; 数据挖掘
0 引言
随着物联网、云计算等信息技术的飞速发展,许多行业如商业、企业、科研机构和政府部门等都积累了海量的、不同形式存储的数据资料。单独依靠数据库进行相关查询难以对海量数据进行分析及统计,为了探寻信息间隐藏的更深层次的关系,大数据分析应运而生。大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产[1]。目前,由于各行业、各部门之间的数据壁垒,导致数据“孤岛”现象的频现、数据利用效率低下、数据分析和数据挖掘的广度和深度不够;同时,由于人们对大数据的理解还不够全面、对数据挖掘技术的了解和运用还不够深入、数据分析模型的不够科学,使得大数据支撑解决民生领域问题能力难以得到提升。
数据分析可以分为广义数据分析和狭义数据分析。目前,我们在对数据处理上往往都停留在狭义的数据分析上,在实现方式上只是对数据进行简单的查询统计和汇总。然而,这种方式在大数据时代很难发挥数据的价值,以及促进相关应用领域的发展[2]。
数据分析是指用统计分析方法及工具,对收集来的数据进行处理与分析,对数据有目的性的进行现状、原因、预测等定量分析提取有价值的信息,发挥数据的作用[3]。数据分析先做假设,然后通过数据回归分析、对比分析等常用分析方法来验证假设是否正确,从而得到相应的结论。所谓结论一般是一个统计结果,这些指标对应相应的业务中进行分析,发挥其价值。
数据挖掘是指使用统计学、人工智能、机器学习等方法从海量数据中挖掘出未知的、且有价值的信息和知识的过程[4]。数据挖掘通过神经网络、关联规则、决策树、聚类分析等方法对数据进行分类、聚类、关联和预测,得到如流失概率值、相似度等模型得分或如高中低价值用户、信用等标签,以此挖掘未知的模式与规律[5]。
综上,数据分析与数据挖掘的本质都是从数据里面挖掘、分析有价值的信息,从而更好的在生产运营中进行改进。
1 数据挖掘的前提
1、海量的数据积累,尤其是超大规模数据库的出现更加速数据的自动积累。但质量有待提高,数据规模有待进一步扩大,尤其是跨行业、跨部门之间的数据共享,促进数据挖掘的力度不断深入,这个需要突破相关行业和相关部门之间的数据壁垒,打破传统的本位主义思想,多层次采集数据,多维度分析数据。
2、随着计算机技术的发展,硬件软件都有日新月异的提高,但人类的需求不断增多,计算机技术只有跟上其发展才能持续为人类服务,融入社会发展的大环境。人类需求与计算机技术发展不离不弃,相互共存。所以,作为政府部门在硬件的基础上也完全可以实现。
3、政府部门不具备数据挖掘高端技术和精深的统计方法计算能力。政府业务人员不具备数据挖掘包含的集统计学、神经元学等学科技术。因此业务人员应积极学习专业的数据挖掘相关理论,为更好的掌控数据挖掘技术、更好的服务民众做铺垫[6]。
2 数据挖掘的层级
数据挖掘的层级主要包括:数据清洗、数据报表、临时数据需求、数据挖掘、数据产品。其中,数据清洗、数据报表和临时数据需求是基础环节,也是最重要的环节,一般占整个数据挖掘过程的80%左右的工作量[7]。如图1所示。
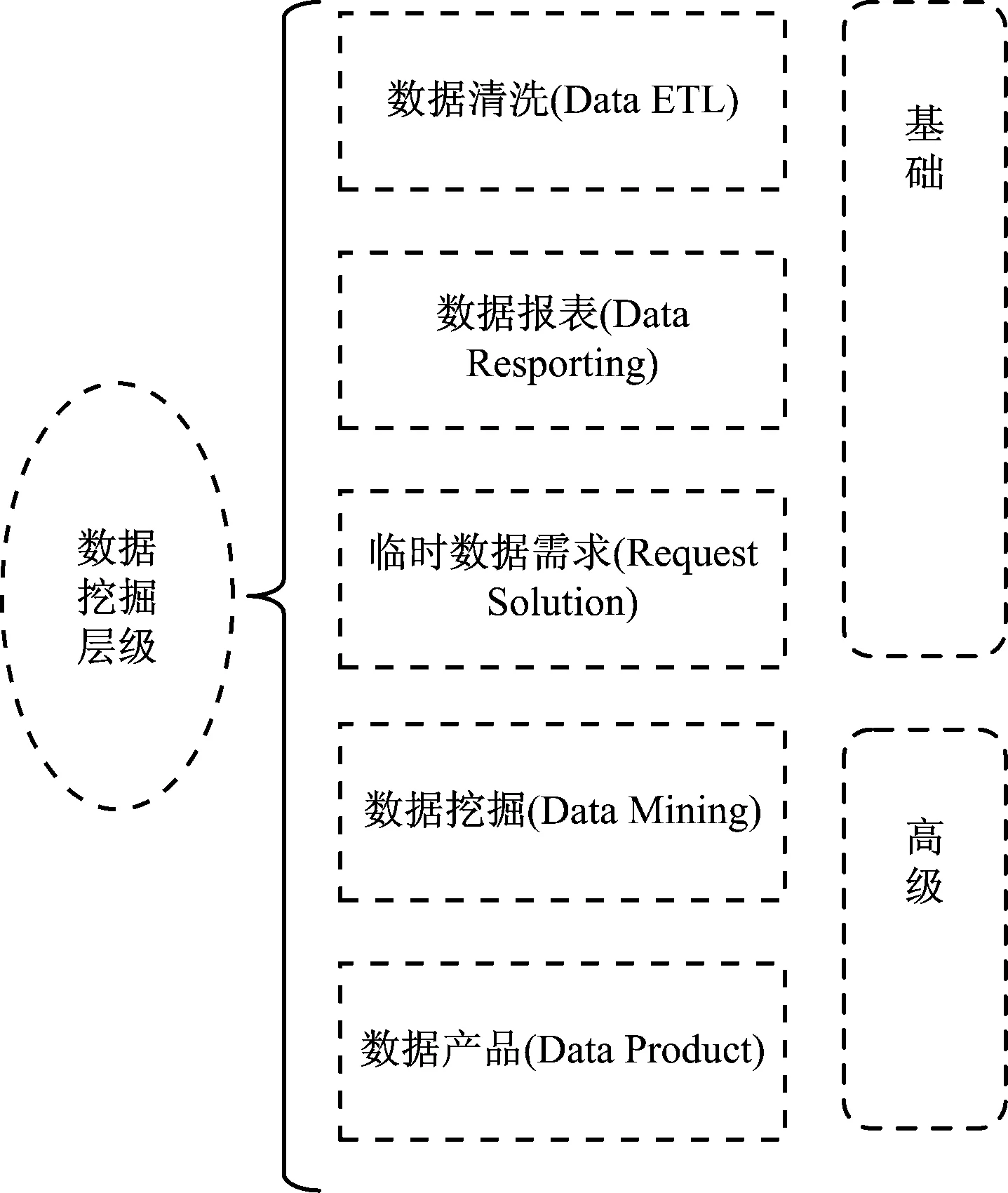
图1 视频信号与传输频率范围关系图
3 数据挖掘的方法论
数据挖掘方法论是各行业低成本、高质量地开展数据挖掘应用的行动指南。数据挖掘方法论主要包括跨行业数据标准CRISP-DM及SEMMA数据挖掘标准等不同版本。即使对数据挖掘的定义不统一,但数据挖掘的其核心观点是一致的,即数据挖掘是一个过程,是一个以数据为中心的循序渐进的螺旋式数据探索过程。具体过程,如图2所示。

图2 螺旋式数据探索过程
1、商业理解
商业理解是数据挖掘的初始阶段,主要目的是:明确本次数据挖掘要解决什么问题,评估是否具备数据挖掘的主观和客观条件。数据挖掘是服务于应用的,脱离现实问题的数据挖掘是没有意义的,不具备行业知识的数据挖掘是不可能成功的。
2、数据理解
数据理解的目的是:在业务(商业)理解的基础上,围绕业务(商业)问题收集原始数据,明确数据含义,明晰数据的各种差异,并通过技术手段实现数据的一致化和集成化。数据集成看似简单,但实现难度却极高,通常要借助现成的计算机软件或自行编写程序。另外,数据理解还包括数据质量的评估和调整、数据的多维度汇总浏览等。其目的是把握数据的总体质量,了解变量取值的大致范围[8]。
3、数据准备
在充分理解数据后,利用计算机和统计方法对数据进行预处理,数据准备步骤不可或缺,数据准备工作为后续的数据挖掘建模奠定数据基础。
4、建立模型
为得到合理的,适合于目标的数据模型、数据预测模型、评价指标及评价函数,利用各种数据分析方法对数据进行探索性分析。
5、模型评估
在模型评估过程中,确定数据挖掘的最终分析模型至关重要。总结并回顾模型评估全过程,从数据模型的合理性、实际应用的角度,而非模型理论评价的角度,对所得数据模型的实用性进行评价。
6、方案实施
数据挖掘的最后一个环节是方案实施,通过制定实施和监管计划确保数据挖掘结论的合理运用范围。数据挖掘在经验学习的过程不断积累循环往复,每一次挖掘都会受益于上一次的挖掘,每一次挖掘都将给下一次挖掘提供宝贵的经验。一个简单的机器学习系统,如图3所示。
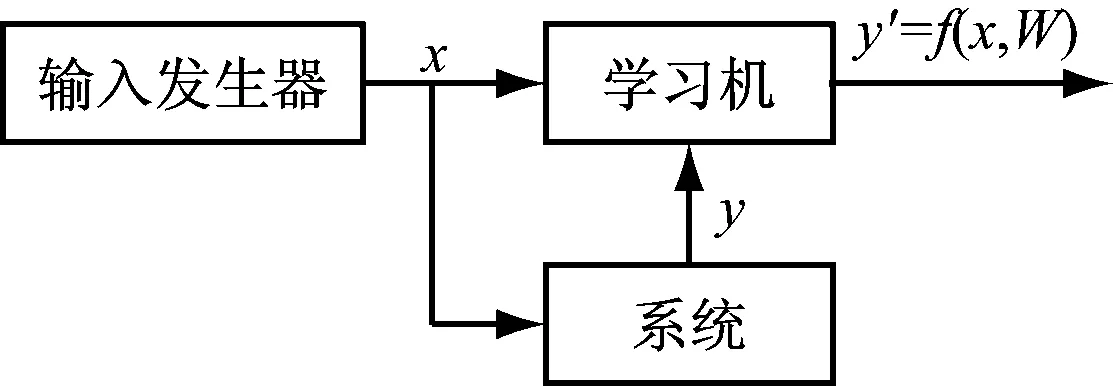
图3 一个简单的机器学习系统
4 数据挖掘在民生领域中的应用
目前数据挖掘技术已成为解决民生问题的重要技术支撑,被应用于支撑解决扶贫帮困、救助保障、养老服务、基层治理等民生问题。下面就以数据挖掘在养老服务领域中的应用为例进行简要阐述。
据上海市民政部门统计,截至2015年12月31日,全市60岁及以上老年人口435.95万人,占户籍总人口的30.2%,占比增加了1.4个百分点。100岁及以上老人1 751人,增长7.4%,上海老年人口的高龄化趋势同样明显。据预测,上海人口老龄化在“十三五”期间将进一步深化[9]。到2018年上海户籍60岁及以上老年人口总数突破500万,2020年总数将超过540万人,且随着时间推移规模将持续扩大。与之相对应,据上海民政部门统计:全市养老机构共计699家,床位数共计12.6万张;全市老年人日间服务机构共计442家,服务人数共计1.5万人;居家养老服务中心共计163家,社区助老服务社共计202家,服务人数共计30.55万人[10]。
现有的养老服务设施已经无法满足不断增长的老年人口养老服务的需求。如何才能随着老年人口的增长,提前布局和规划相应的养老服务设施,减少社会矛盾的产生、提升政府和社会的养老服务能力,值得我们认真思考和亟待解决的首要问题。现利用数据挖掘的方法论来讨论这一问题的解决。主要是根据目前已经选择养老服务老年人的数据情况进行规律性研判,通过IBM SPSS Modeler建模工具来进行建模分析,从而分析出随着老年人口的增长需要新增养老服务或养老设施的数量。为了使选取的样本数据更加科学、合理,根据区域分布的不同(内环内、内中环之间、外环外)选择六个区(黄浦、徐汇、长宁、宝山、金山、奉贤)的60周岁以上老年人口数据,养老服务设施数据,养老服务人员数据以及目前存量老年人选择养老服务类别的数据信息作为样本分析数据。
根据现有6个区2005年至2015年的老年人口数量,以及目前存量老年人的基本信息和所选择养老服务类别的信息来提前预判来五年老年人口增长情况,以及随着老年人口的增长需要新增的养老机构床位数;根据老人的基本情况预判老人会选择哪类养老服务。
目前现有的数据主要是6个区十年来的老年人口总数(2005年至2015年),当前在享受相应养老服务老年人的年龄、工资(收入)水平、文化程度、婚姻状况、身体状况、子女情况、居住情况(独居、与子女居住等)、分布区域、选择的养老服务类别等。
对现有的数据进行清洗、转化、合并等操作,剔除不合规的垃圾数据和不完整的数据,使其符合建模需求。主要涉及的数据信息:当前在享受相应养老服务的60周岁以上老年人基本情况表;抽样老年人选择的养老服务情况表;历年的老年人口数据表。
根据民政部门统计,6个区2005年至2015年期间的老年人口数量,如表1所示(单位:万人)。
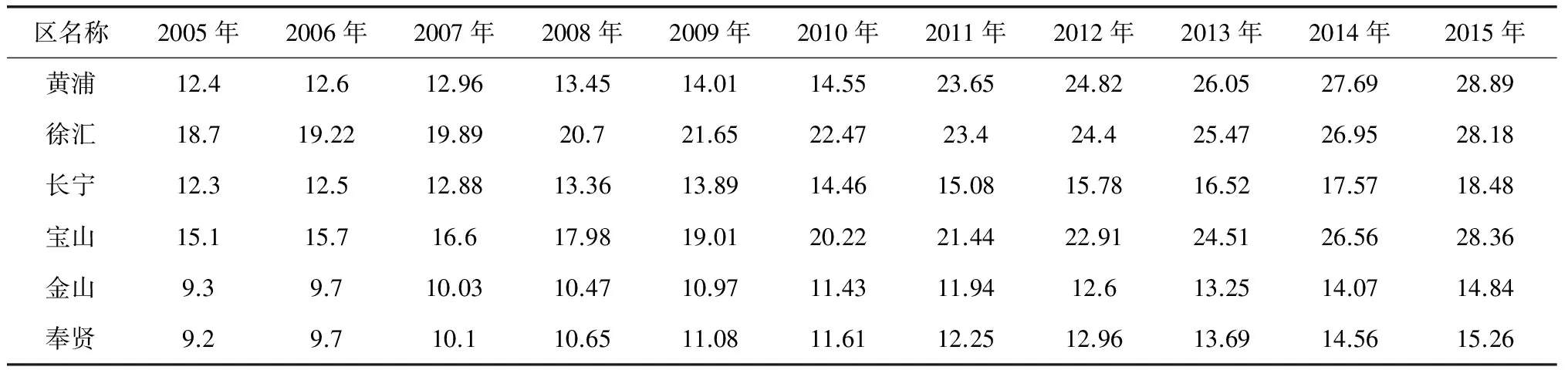
表1 2005年至2015年期间六区老年人口数量
对现有60周岁以上老年人基本情况和存量老年人选择的养老服务情况进行分析。本次样本数据量为4216个,涉及养老服务主要有:养老机构、居家养老、高龄医疗护理、护理院。主要分析的指标:未来5年老年人口增长情况,以及随着老年人口的增长需要新增的养老机构床位数;根据老人的基本情况预判老人会选择哪类养老服务。2016年度6个区中的存量老年人的基本信息和选择养老服务设施的情况,如表2所示。
4.1 模型建立
统计未来5年老年人口增长情况,以及随着老年人口的增长需要新增的养老机构床位数。
1、数据源选择,选择2006年至2015年历史老年人口数据文件,如图4所示。
表2 2016六区存量老年人基本信息及选择养老服务设施的情况
2、时间区间设定,起始年份:2006年,预估未来5年的老年人口数据,如图5所示。

图4 数据源选择

图5 时间区间设定
3、添加“类型”字段选项,读取值并设置输入、输出字段。本示例中,将黄浦、徐汇、长宁、宝山、金山、奉贤既作为历史数据的输入又作为未来预测数据的输出,如图6所示。

图6 添加“类型”字段选项
4、在模型中选择“时间序列建模器”模型进行预判,如图7所示。
5、预测数据的生成。根据时间序列预测模型,预测出了6个区未来5年的老年人口数据(单位:万人),如图8所示。

图7 选择“时间序列建模器”模型进行预判

图8 生成预测数据
6、根据上海市“9073”养老服务格局,养老机构的床位数在老年人口中的占比为3%,因此,未来五年这六个区需要新增的老年床位数,如图9所示。
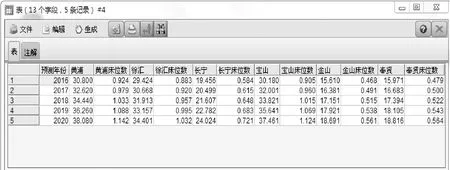
图9 未来五年六区需要新增的老年床位数
7、最终建立的时间序列SPSS Modeler模型流,如图10所示。

图10 SPSS Modeler模型流
接着,根据老人的基本情况预判老人会选择哪类养老服务。
1、数据源选择。导入选取的已经享受某类养老服务老年人的基本情况数据(样本数据4216条),包含老年人的姓名、身份证、性别、年龄、工资、文化程度、婚姻状况、子女情况、居住情况等字段信息,如图11所示。

图11 数据源选择
2、添加“类型”字段选项,读取值并设置输入和目标字段。将老年人的文化程度、婚姻状况等字段信息作为输入,预测的服务类别作为目标。也就是,根据老年人的基本信息预测出某类老年人会选择哪类养老服务,如图12所示。

图12 添加“类型”字段
3、模型选择。上述预测目标主要是预测某类老年人会选择哪类养老服务,所以应该采用分类预测模型,但由于分类预测模型众多,目前无法确定本次样本数据采用哪种模型更加合理。因此,我们可以先使用自动分类器来帮助我们对模型进行选择。选择:建模——>自动——>自动分类器,如图13所示。
图13 生成预测数据
4、执行自动分类后,可以看到系统自动筛选出三个准确性较高的分类预测模型。它们分别是:C5,准确率72.53%;贝叶斯网络,准确率66.72%;Logistic回归,准确率60.1。因此,选取准确率最高的C5来作为下一步分类预测的预测模型,如图14所示。

图14 分类预测模型
5、添加C5分类预测模型。勾选“使用分区数据”、“为每个分割构建模型”,输出类型选择“决策树”,模式选择“简单”,如图15所示。

图15 添加C5分类预测模型
6、执行C5分类预测模型。如图所示,系统生成了决策树,并且预测出了老年人基本信息中各个信息字段的重要性。不难看出,在样本数据中对老年人选择相应养老服务类别起到关键作用的信息字段主要有:年龄、所在区、性别、居住情况等,如图16所示。

图16 执行C5分类预测模型
当然,这只是目前样本数据的一个预测情况。一个好的大数据分析模型不是一蹴而就的,而是一个不断学习、不断完善的过程。如果选取的样本数据尽可能多,涵盖的基本信息字段尽可能全面,那么生成的预测模型准确性就会更加高。
7、最终建立的分类预测SPSS Modeler模型流,如图17所示。
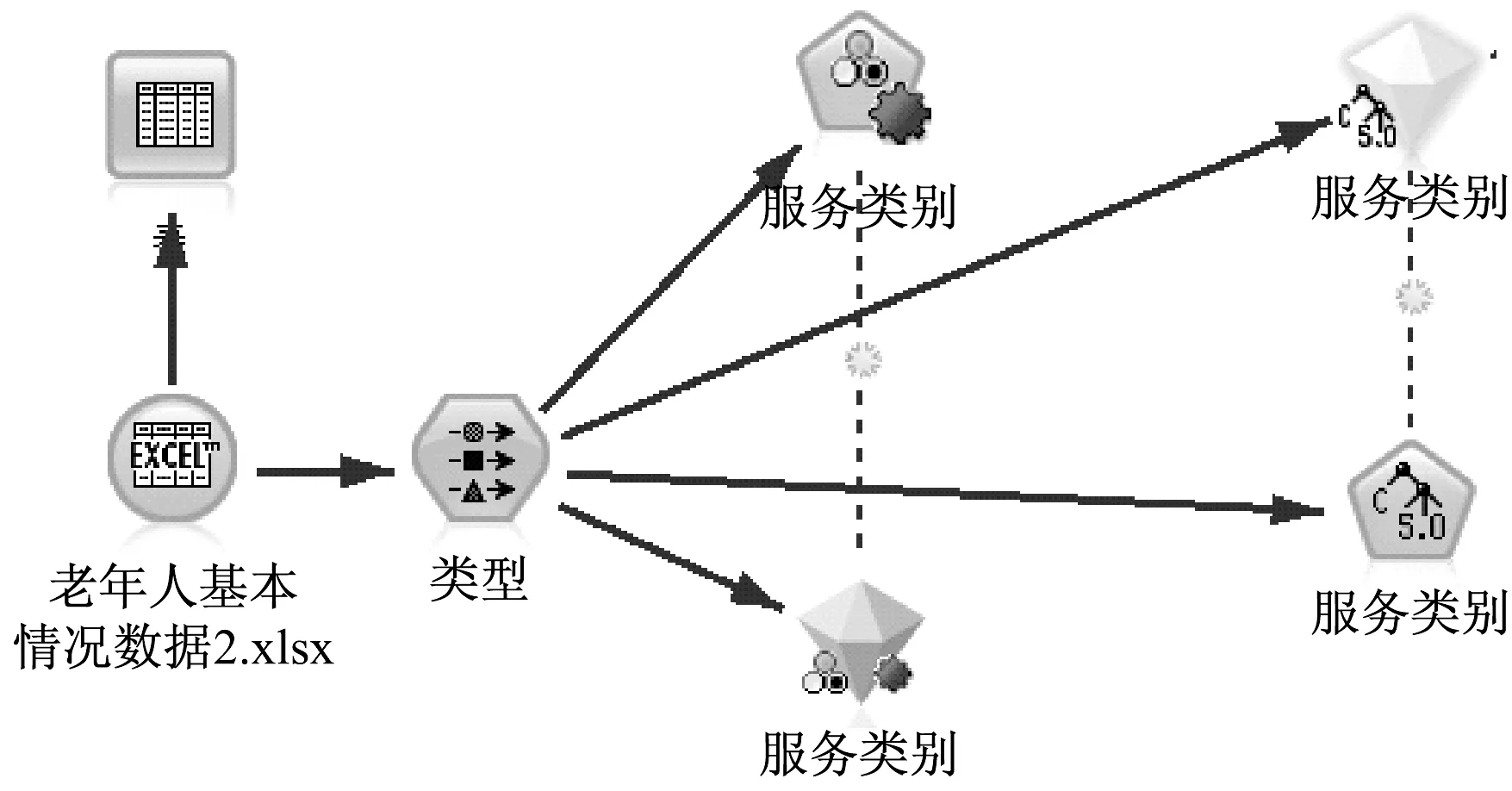
图17 分类预测SPSS Modeler模型流
根据上述模型预测的结果如下图所示,在最后两列列出了预测的服务类别以及某类老年人会选择这类服务类别的概率,如图18所示。
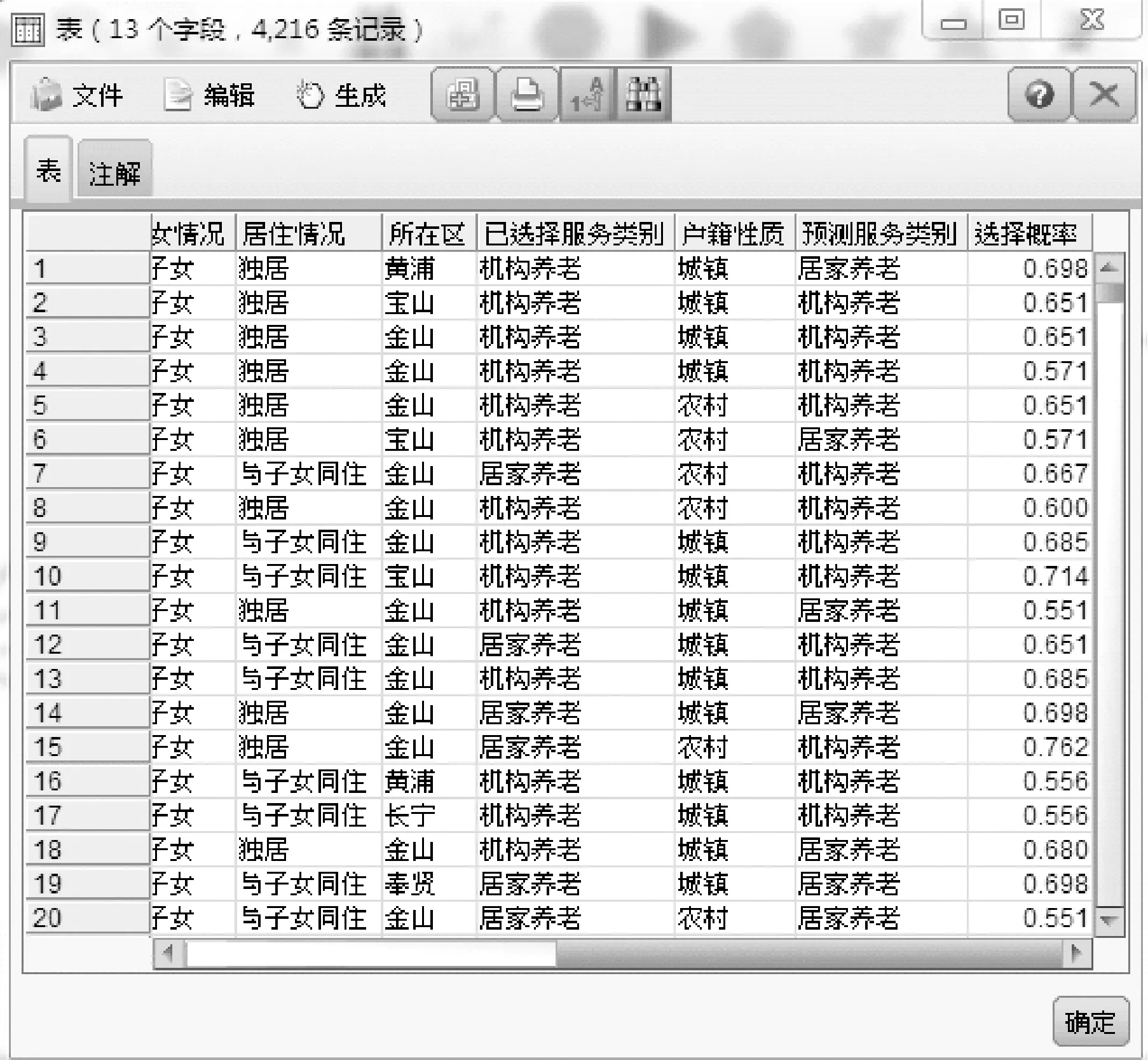
图18 模型预测结果
4.2 模型评估
模型的好坏在于模型预测的准确性,因此在模型建立好后,通过一定的方法来评判或者验证这个模型的预测准确性。使用“输出”中的“分析”工具,来生成预测模型精准度的报告。经过运行后,得出如下图所示的分析报告,该模型的准确度为:72.53%,如图19所示。

图19 服务类别分析结果
4.3 政府大数据应用的发展策略
数据挖掘在民生领域的应用中,将以整体性、透明性、服务性为主要发展策略。为了避免因政府内部矛盾而造成的冲突及矛盾,政府应实现各个部门机构、专业、领导层级之间的整合,这样不仅可以使业务办理更高效,同时可以更好地解决公众需求。透明化一直是政府竭力突破实现的目标,大数据应用以政府开房数据为基础,海量数据为前提,通过数据分析、数据挖掘,电子政务的效率和结果可以逐步被提升,进而实现政府日常工作的全面透明化。政府的监管方式也随着大数据的推进而不断创新,更加透明。公共服务是政府重要的工作之一,大数据的加入,可以使政府公共服务水平提升,也可以让民众更好的监督、融入政府工作,时刻关注政府信息,与政府共同决策相关政策。
4.4 政府大数据应用的误区
误区一,将大数据等同于开放数据。由于目前没有世界公认的“大数据”的定义,一些包括政府部门在内的民众对大数据的认识有不同的理解方式,简单的将大数据错误的理解为开放数据;同时开放式的数据集格式具有多样性的特点,因此难以单方向性的操作。
误区二,将大数据等同于共享数据。大数据平台不是简单的共享数据平台,目前很多地方政府在建设的大数据平台的过程中,还在仅仅翻新共享平台而不是建设多样化的大数据应用。政府大数据不仅仅是政府自身的业务数据,应逐步整合政府外部数据资源,形成更加完善的治理决策支持体系,以在数据整合的基础上实现服务整合。
误区三,将大数据等同于海量数据。目前政府的大数据中心建设,更多地还停留在“建机房、上设备、堆数据”的阶段,忽视了大数据强调的是对数据的分析和应用,要有精通数据挖掘和业务建模的专业人才队伍,从政务应用需求出发,做好潜在数据价值的挖掘和应用。
4.5 政府大数据应用的潜在问题
警惕数据权的恶意使用或过度滥用。涉及到政府大数据,难免会引发一些敏感的权利、政治利益纷争,数据所有权即权利源泉,哪一方掌握数据所有权即掌握了主动权,而掌握主动权的一方应时刻保持客观性,不能产生具有偏向性的决策意见。因此应时刻警惕围绕原始数据的占有权和发布权而产生的的斗争,并在决策过程中保持客观公正的态度。
警惕大数据带来的信息歧视。大数据技术具有预测未来事件发展趋势的特点,在数据挖掘的过程中,可能遇到比如公民隐私相关的公平性、隐私性问题。因此在信息处理过程中,应时刻保障数据的保密性,使信息不被窃取、盗取、乱用,对公民权益造成侵害。
警惕互联网公司侵害国家数据主权。中国数据产权的立法滞后,相关数据资源缺乏统一采集规划,因此要警惕大型互联网企业对政府大数据的掌控及决策影响。
5 总结
随着互联网日新月异更新迭代,数据规模、数据种类在科学研究、电子商务、民生保障等诸多应用领域飞速发展,大数据时代已悄然来临。如何管理好、利用好、分析好这些海量数据来促进相关领域的发展,是我们当下需要亟待思索的问题。但由于行业壁垒的局限性、数据挖掘不够、数据“孤岛”、数据鸿沟等制约着大数据支撑解决民生领域问题能力的提升。因此,需要我们打破行业壁垒、突破数据“孤岛”现象、不断的探索新的数据挖掘技术,从而提高大数据支撑解决民生领域问题的能力。本文介绍了数据挖掘的一般过程及方法论,结合实际,以数据挖掘在养老服务领域中的应用为例,对数据挖掘应用解决扶贫帮困、救助保障、养老服务、基层治理等民生问题进行简要阐述。
[1] 程学旗, 靳小龙, 王元卓,等. 大数据系统和分析技术综述[J]. 软件学报, 2014(9):1889-1908.
[2] 郭理桥. 数据挖掘在政府信息系统设计中的应用研究[J]. 中国建设信息, 2010(4):6-11.
[3] 盛宇, 刘俊熙. 数据挖掘在政府电子化公共服务中的应用[J]. 情报杂志, 2007, 26(7):88-90.
[4] 杨越. 数据挖掘在政府部门决策管理系统中的数据与应用[D]. 北京:解放军信息工程大学, 2012.
[5] 徐栋. 数据挖掘在政府部门决策管理系统的设计与实现[D]. 成都:电子科技大学, 2012.
[6] 赵慧. 浅析数据挖掘在政府统计中的应用[J]. 教育:文摘版, 2016(8):97-98.
[7] 丁伟, 李政, 于昕. 数据挖掘在政府采购中的应用研究[J]. 中国政府采购, 2014(7):72-73.
[8] Cohen E, Datar M, Fujiwara S, et al. Finding interesting associations without support pruning[J]. IEEE Transactions on Knowledge & Data Engineering, 2001, 13(1):64-78.
[9] Han J, Chee S, Chiang J Y. Issues for On-Line Analytical Mining of Data Warehouses[C]// Sigmod'98 Workshop on Research Issues on Data Mining and Knowledge Discovery. 1998.
[10] Goil S, Choudhary A. High Performance OLAP and Data Mining on Parallel Computers[J]. Data Mining and Knowledge Discovery, 1997, 1(4):391-417.
TheBigDataApplicationforLivelihoodAreas
Shen Jian
(Information Research Center, Shanghai Municipal Bureau of Civil Affairs, Shanghai 200093)
In recent years, the application of the Internet technology develops rapidly in scientific research, e-commerce, livelihood security and many other fields. Data size, data types are growing with a rapid rate, big data era has quietly come. How to manage and make good use of these massive data to promote the development of related fields, is the problem we need to think about now. However, due to the limitations of industry barriers, data mining is not enough, the data island, data gap and other constraints do not support large data to solve the problem of improving the people's livelihood. Therefore, we need to break the barriers, break the data island phenomenon, and constantly explore new data mining technology, so as to improve the ability of solving the problem of people's livelihood by uzing big data. This paper summarizes the current situation of data mining technoloies, introduces the general process and methodology of data mining. According to actual application of data mining in the pension service, the author discusses the application of data mining to solve the poverty relief, rescue protection, pension services, grassroots governance and other livelihood issues.
Livelihood security; Big data; Date mining
TP311
A
2017.07.11)
沈 俭(1979-),男,本科,工程师,研究方向:数据挖掘。
1007-757X(2017)10-0071-07
