基于Minhash的协同过滤技术在推荐系统中的应用
2017-11-02刘艾侠刘丹丹宝鸡职业技术学院宝鸡7203中国科学院大学北京00039中国科学院国家授时中心西安70600
刘艾侠,刘丹丹 (.宝鸡职业技术学院,宝鸡 7203; 2. 中国科学院大学,北京 00039; 3.中国科学院 国家授时中心,西安 70600)
基于Minhash的协同过滤技术在推荐系统中的应用
刘艾侠1,刘丹丹2,3
(1.宝鸡职业技术学院,宝鸡 721013; 2. 中国科学院大学,北京 100039; 3.中国科学院 国家授时中心,西安 710600)
传统协同过滤的推荐机制应用在大规模数据上时,如果在要保证推荐质量会导致占用运行时间和存储空间的增加。研究分析了Minhash在大规模数据上的降维原理,论证了将minhash应用到协同过滤,设计并实现基于Minhash算法的协同过滤模型。实验结果表明Minhash能在保证推荐质量的前提下很大程度上缩短计算时间和存储空间,能有效地扩展到大规模数据集。
协同过滤; 大规模数据集; Minhash
0 引言
协同过滤技术基于寻找相似邻居来预测目标用户将来行为,在数据集不大,并且类别数量或者称为数据维度不高的情况下,通过实验能证明算法的推荐结果的精准度比较高,质量比较好。但是该算法的运算依赖于内存,并具有平方数量级以上的复杂度,当类别数量很高的时候,即使很小数量级的数据,算法的运算时间都会远远超出能接受的范围,因此很难扩展到大规模的数据集上。本文针对协同过滤技术的这点局限性,利用基于概率的聚类方法——minhash来完成高维度数据集的降维工作,从而降低在给目标用户寻找最近邻居花费的时间,提高运算效率。
1 基于Minhash的协同过滤
Minhash是一种概率的聚类方法,根据两个用户项目行为集合的交集,有一定概率将两个行为分到同一个组。其基本思想是随即排列一个用户Ui的行为集合Si然后计算hash值并用该值作为Ui的行为集合Cui,前面已经证明,两个用户Ui,Uj有相同的Cui的概率和它们之间的相似度一致。因此,Minhash被认为是一种概率上的聚类方法,将所有的hash结果作为一个簇(如Cui可以看成一个簇),两个用户在同一个簇内的概率和他们之间的相似度相等。为了提高精准度我们可以用p个hash-key来hash用户的Si,这样p个hash的结果连接起来作为一个Cui,这样两个用户有同一个Cui的概率,如式(1)。
Pi,j=S(ui,uj)p
(1)
这样在同一个簇C的两个用户相似度会更大。这样在一个组内寻找相似邻居,得到的结果有很高的精准度,很明显,设置Minhash 的独立运算次数p能够提高精准率,但是同时,也会在一定程度上提高相似用户的丢失率,聚类的召回率就会降低,为了提高召回率,可以为每个用户hash得到q个簇,每个簇用p个hash-key进行hash,通过q次重复hash过程,每个用户所属于的簇增加到q个。
基于Minhash 的协同过滤技术的详细推荐过程:
第一步,为方便Minhash运算,需要给所有能表示用户行为的文本或者其他形式对象分配唯一标识。一般来说,用户-项目的矩阵内容是文本内容,所能记录下的用户行为都是通过session和用户输入的query内容,或者点击的链接来表示。如果直接将这些文本导入内存再进行运算会占据很大的内存,并且在一般的计算机内存配置达不到这个要求,因此可以给用户和行为分别用十进制的id表示,这样用户-评价的矩阵可以转换成用户id-项目id的矩阵。为了完成这个过程我们建立为用户和项目分别建立一个目录,分别表示为Du和Ds如果当前用户或者评价在目录里面找不到,则将其分配一个最新的id并加入到这个目录,如果有记录则直接将对应的id替换原有的文本。这一步的输出包括3个结果,用户和评价的目录Du和Ds,另外还有用户id-评价id的对应表。
第二步,利用p*q个哈希函数进行Minhash运算,算法的输入是一个表示用户评价的一个集合,该集合是经过Du和Ds映射后的一个用户id和一个表示该用户评价的id的集合I,首先选取第1到第p个hash函数运算,选择I中能得到的最小哈希值作为一个Minhash1,经过p次运算,分别得到Minhash2,…,Minhashp,这样p个Minhash值作为一个簇号,然后再选取第p+1到第2p个hash函数进行运算,如此循环,经过q次运算,最后会得到这个用户的q个簇号,每个簇号都由p个Minhash值连接起来组成的。最后生成了uid-cid的数据,表示用户-簇的对应关系,倒排uid-cid的结果,生成cid-uid的文件,这样就能很方便的查找相似邻居。
第三步,寻找相似邻居。从第二步中的uid-cid矩阵中根据一个用户id查到其拥有的簇号cid,再根据该cid从cid-uid倒排表中查找所有的相似用户。聚集所有相似用户并给这些用户用其出现的次数进行加权,选取排行靠前的若干个用户作为相似用户。
第四步,预测。这一步骤和协同过滤基本一致,查找所有相似用户的评价的项目历史,聚集所有的项目,按项目的的出现的次数排序,选取前k个作为预测的值,这些预测结果就是给用户的推荐。
2 Minhash算法设计
基于Minhash的协同过滤工作流程,如图1所示。
包括用户数据的映射,即:用户映射到用户id,项目映射到项目id;中间Minhash模块的作用就是根据用户id-项目id的输入,运算输出用户id-簇id;最后最近邻居寻找,就是生成用户id-相似用户id。详细过程如下:
(1)在映射阶段,需要分别给用户和项目建立一个目录,由于数据集中的用户和项目个体会很多,如果在一台机器上维护这样两个列表,会占用比较大的内存,尽管占用CPU的资源不会太多,但是占用的内存限制了后来的协同过滤的寻找相似用户能利用的内存空间,为了将内存资源尽量多的留给协同过滤,可以设计一个服务,开启一个远程服务,这个服务上维护一个用户和一个项目的哈希表,每个表的内容是value-key的值,然后利用网络协议进行通信,客户端发送一个请求,内容是当前的用户或者项目,服务端接受请求后从目录表中查找,返回对应id,如果当前目录中没有包含这个记录,则为该记录新建一个id并返回,同时将该记录和新的id加入到列表中。
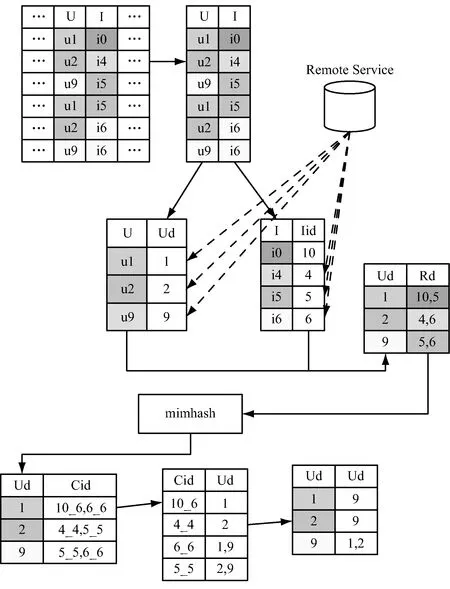
图1 基于Minhash的协同过滤工作流程
(2)原始数据里面有不少对预测的结果没有意义数据,清洗掉无用的数据并从原始数据中抽取User-Item的列表,得到用户和项目对应的ID,将原始数据转变成Uid-Rid的列表,同时根据Uid将该用户的所有Rid组成集合。
(3)利用Minhash 模块,输入Uid-List
以上就是基于Minhash 的协同过滤算法整体流程,图1中Minhash 模块的实际上就是进行循环和迭代的哈希函数,经过Minhash 模块的处理,用户在n个项目上最多可能有n维的向量空间被降维到q维的向量空间。
Minhash算法数据处理流程,如表1所示。表1中算法的输入,输出和详细处理过程如下:
表1 Minhash算法

(1)输入是Uid-List
(2)初始化Minhash的参数,p,q,随机种子m。前述说明p是Minhash的精度系数,p越大,同一个簇的用户相似度越高,但是这样一个组的用户数量会越少,必然导致预测的结果不多,致使召回率不高,q是提高召回率的一个系数,q指的是Minhash运算迭代的次数,当q越大,一个用户属于的簇的数量越多,这样会保证精准度的前提下提高召回率。m是一个随机种子,在hash运算中用来计算一个整数的hash值。
(3)设置3个中间变量,用以控制hash计算的次数和簇号生成。首先hash会迭代计算q次,每次计算会生成一个簇号,当前簇号以该次迭代的次序号开始,如0,1,等等。然后会随机生成两个随机数a和b,经过p次循环,每次循环会将List
f(x)=a+Iidib(modm)
(2)
取所有的temp 中最小的一个hash 值作为当前hash 值,p次循环后会得到一个标示,如式(3)。
(3)
然后将以迭代的次序号起始的字符与该标示合并得到这一次迭代的簇号,如式(4)。
Cidi=i_tempi=i_hash1_hashw_…_hashq
(4)
(4)输出Uid-List
3 Minhash模型设计
在实现基于Minhash 的协同过滤模型过程中,数据可以以文本的形式存储在磁盘上,在算法中利用I/O操作读取到内存,也有可能存储在数据库中,利用存储过程,sql查询等操作,完成算法的运算。因此图2中的原数据文件和中间等所有的文件均可能以别的存储形式存在。图2中实线箭头表示的是数据流,虚线箭头表示的是工作流,Minhash组件包含三个主要的模块:数据抽取,Minhash模块和查询语句预测。每个模块的具体功能会在下面进行详细叙述。
在具体操作中,可以利用时间的位移保证相似用户一定有行为的记录,可以描述为利用N+M天的数据,根据当前第N天到第N+M天的用户数据预测用户未来N天内的行为,可以选取的训练数据是第1天到第M天。
(1)数据抽取
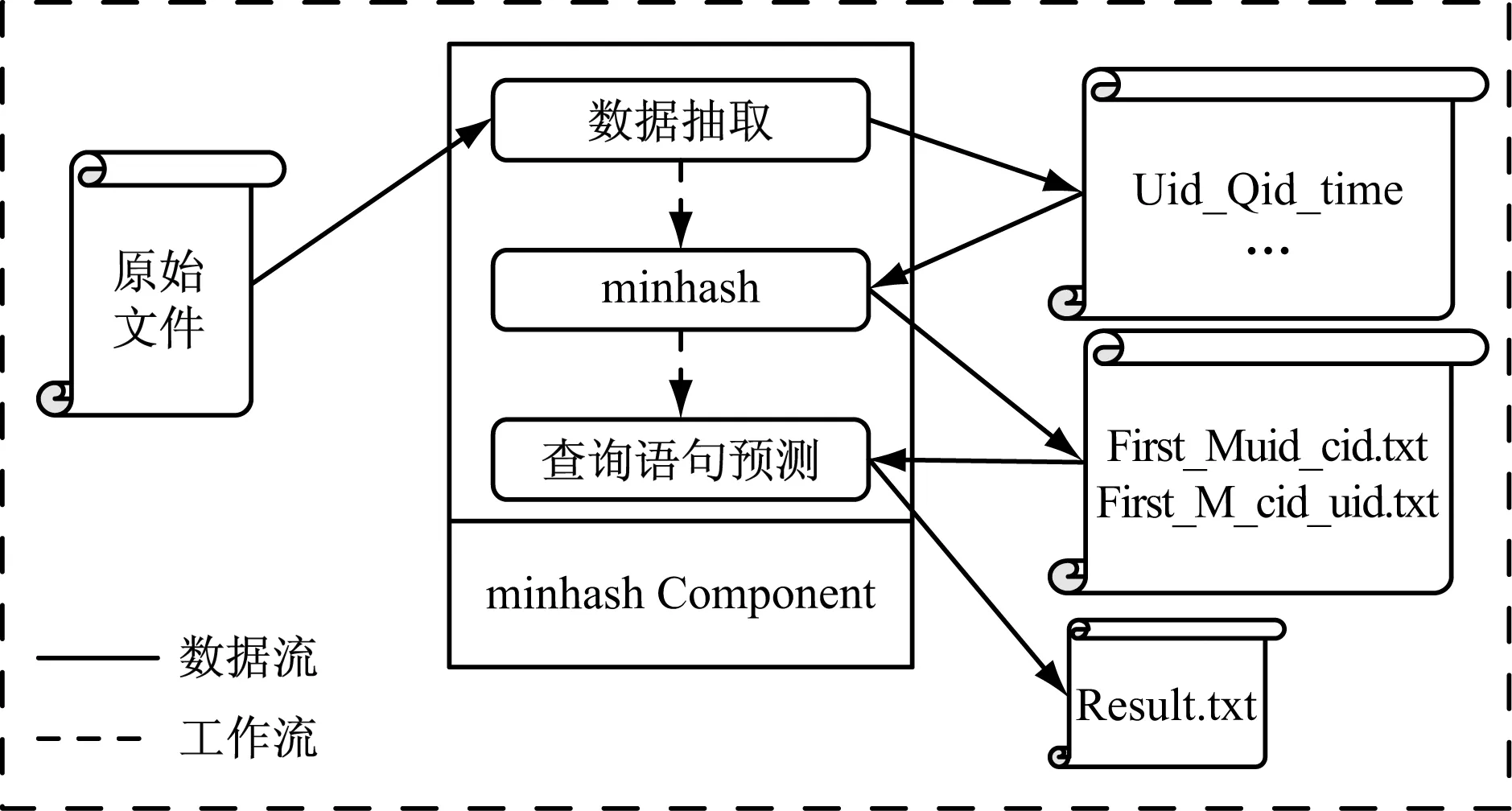
图2 基于Minhash的协同过滤模型图
主要从原始数据中抽取M+N天内的三个信息,包括用户,查询语句和查询时间,在这一步中会从远程服务器中查找用户和查询语句的hash表,同时将这三列的信息转换成Uid_Rid的数据格式。
(2)Minhash
首先聚合一个用户在前M天所有的查询语句的Qid,形成Uid_List
(3)查询语句预测
根据每个用户,在Uid_List
4 算法测试
实验数据集来源于实际采集的数据,数据内容是用户在使用搜索引擎的日志。时间跨度是30天+7天,训练数据和测试数据按用户的比例是4∶1,数据集规模和内容,如表2所示。

表2 测试和训练数据详细
经过选取不同的p,q值作为Minhash算法的参数进行实验,对比发现分别选取p=4,q=6的时候,基于Minhash的协同过滤推荐的结果精准度和召回率比较好,因此在本实验数据集的基础上选取p=4,q=6作为对比实验中的Minhash的参数。
分别在未经过数据预处理的原始数据集,经过预处理的数据集上完成传统协同过滤和基于Minhash 的协同过滤的对比实验,分别得到PR曲线,如图3和4所示。
另外记录下传统协同过滤和基于Minhash的协同过滤所用的时间和存储空间,对比,如表3所示。
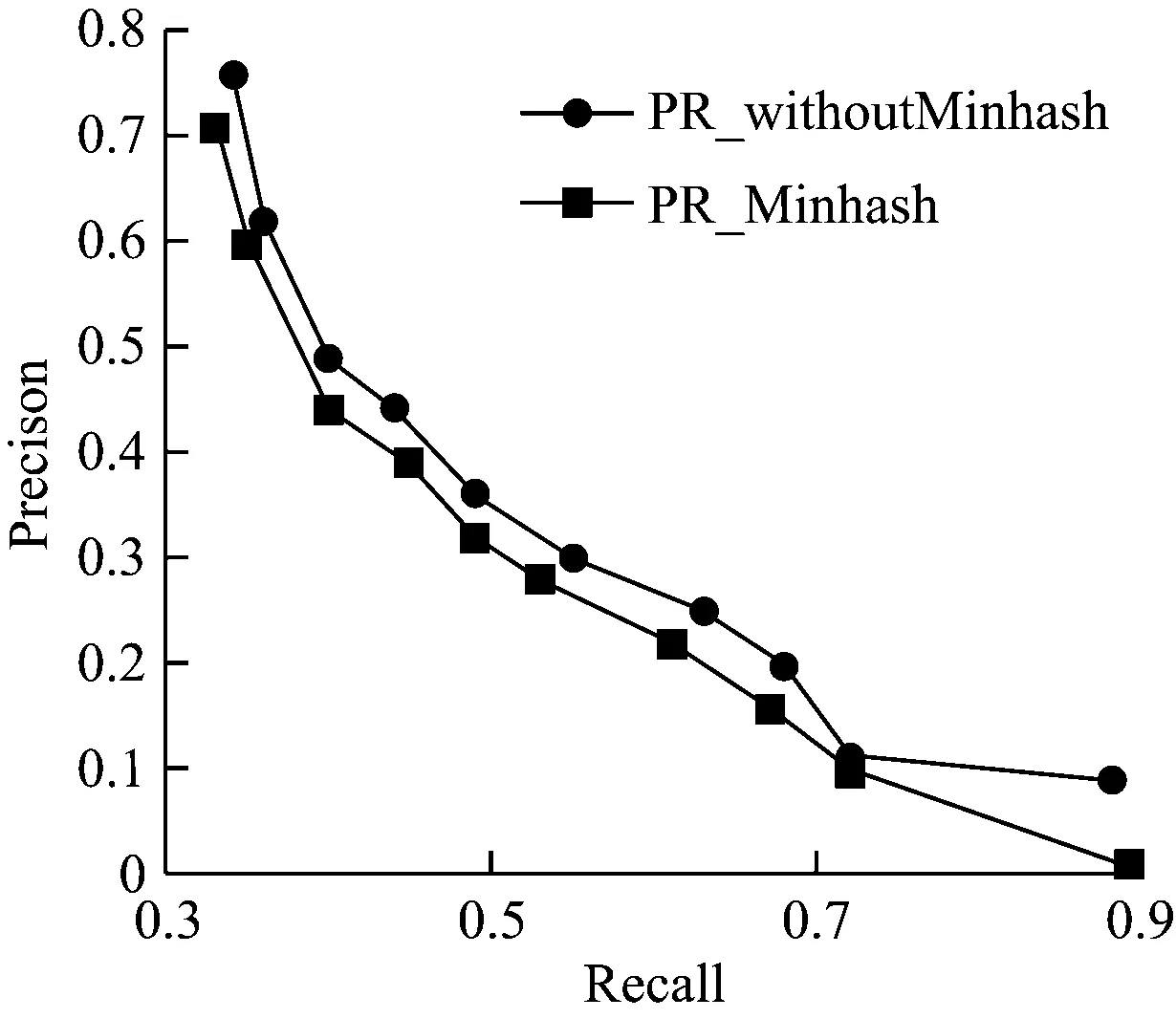
图3 未经数据预处理的对比实验
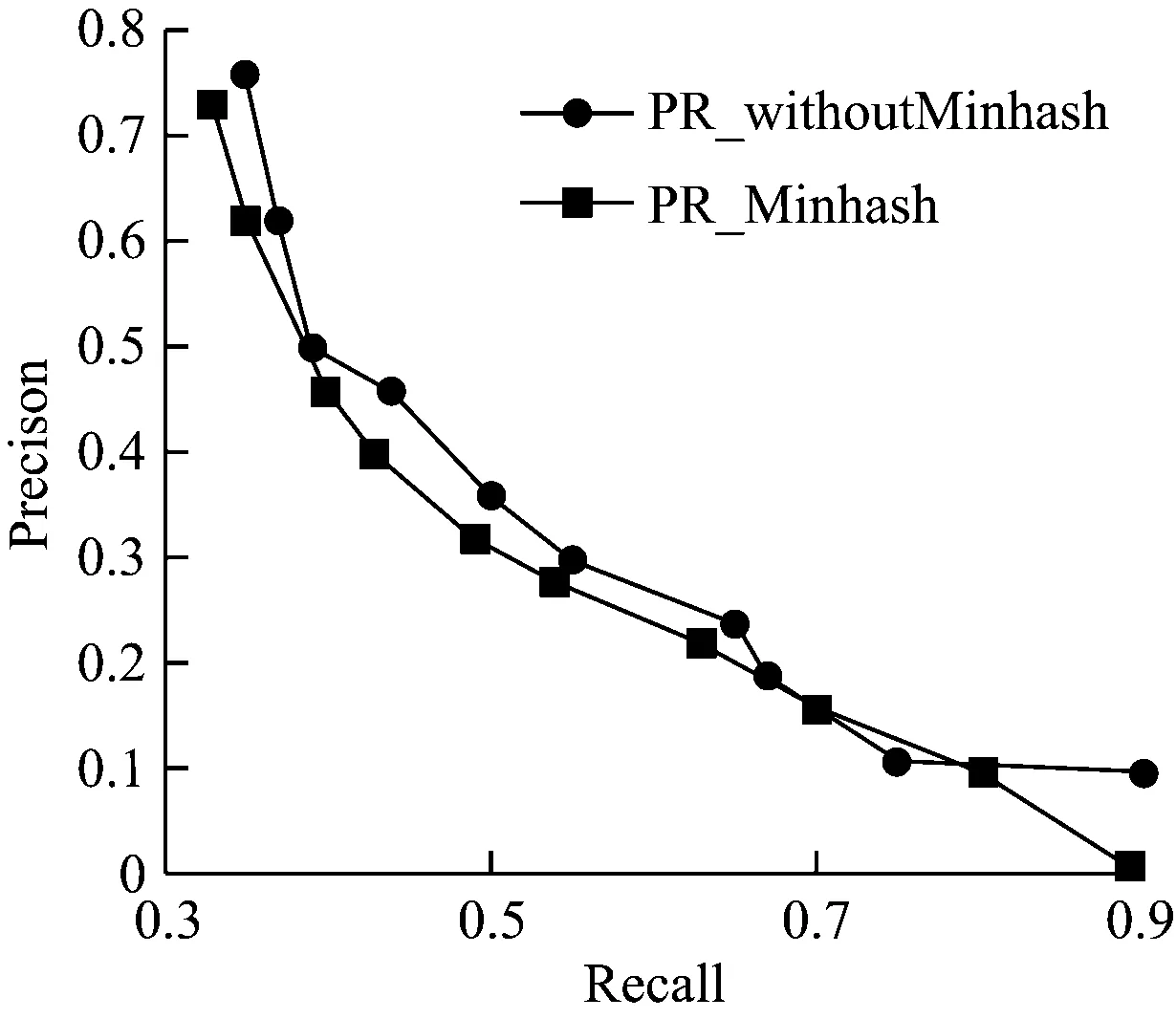
图4 经过数据预处理的对比实验
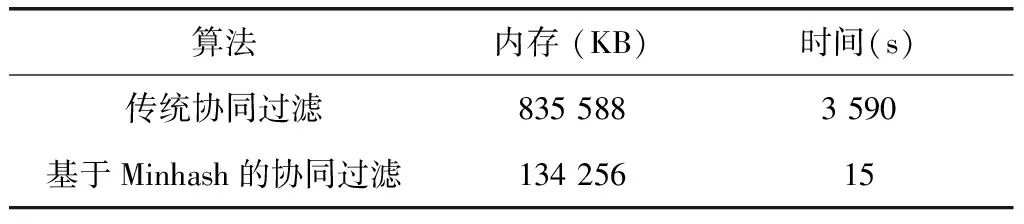
表3 传统协同过滤和Minhash性能对比
从实验结果可以看出,尽管基于Minhash的协同过滤算法在推荐质量上比传统的协同过滤要稍低一点,但是在性能上却远远优秀于传统的协同过滤算法,从表3可以看出,Minhash占用的内存仅仅为不到传统协同过滤的1/6,花费的时间不到传统协同过滤的1/200。
5 总结
推荐技术的研究是当前推荐领域的研究热点,具有巨大的商业价值。传统的协同过滤虽然在推荐系统中得到广泛的利用和验证,但是其本身面临很多的问题,例如数据稀疏的局限性,难以向大数据集扩展。本文通过利用一种概率的聚类方法——minhash方法完成给高维度的用户数据进行降维。另外针对常见的原始数据集中存在噪音数据设计并实现噪音数据过滤程序,对于常见英文文本的同义性问题利用porter stemming给英文单词的映射统一规范的文本。通过实验,本文论证了在保证推荐质量的前提下,minhash对比传统的协同过滤有着更好的性能,minhash可成为协同过滤向大规模数据扩展的一种手段。
[1] Abbattista F, Degemmis, et al. Improving the Usability of an E-commerce Web Site through Personalization [C]. Proceedings of the Workshop on Recommendation and Personalization in Ecommerce,2002.
[2] Songhua Xu, Hao Jiang, Francis C.M. Lau. Personalized Online Document, Image and Video Recommendation via Commodity Eye-tracking [J]. Communication of the ACM, 2008,40(3):83-90.
[3] Balabanovic M, Shoham Y. Fab. Content-based, Collaborative Recommendation [J]. Communication of the ACM, 1997, 40 (3): 66-72.
[4] Konstan A, Miller B, et al. GroupLens: Applying Collaborative Filtering to USENET News [J]. Communication of the ACM, 1997, 40(3): 77-87.
[5] Lewis D D, Yang Y, et al. RCV1: A New Benchmark Collection for Text Categorization Research [J]. Journal Machine Learning Research, 2004, 5 (12): 361-397.
[6] Yu K, Xu X-W, Ester M, et al. Feature Weighting and Instance Selection for Collaborative Filtering: An Information-Theoretic Approach [J]. Knowledge and Information Systems, 2003,25(4):521-525.
[7] Sarwar B, Karypis G, Konstan J, Reidl J. Item-Based Collaborative Filtering Recommendation Algorithms [C]. Proceedings of the Tenth International World Wide Web Conference (World Wide Web), 2001:314-317.
[8] Sarwar B, Karypis G, Konstan J, Riedl J. Item-Based collaborative filtering recommendation algorithms [C]. Proceedings of the 10th International World Wide Web Conference. 2001. 285-295.
[9] Chickering D, Hecherman D. Efficient approximations for the marginal likelihood of Bayesian networks with hidden variables [J]. Machine Learning, 1997,29(2/3):181-212.
[10] Breese J, Hecherman D, Kadie C. Empirical analysis of predictive algorithms for collaborative filtering [C]. Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence (UAI’98). 1998. 43-52.
[11] Breese J, Heckerman D, Kadie C. Empirical Analysis of Predictive Algorithms for Collaborative Filtering [C]. Proc. of the 14th Conf. on Uncertainty in Artifical Intelligence, July 1998:1421-1426.
[12] Karen Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation [J]. 2004, 60(5):493-502.
CollaborativeFilteringTechnologyBasedonMinhashandItsApplicationinRecommendSystem
Liu Aixia1, Liu Dandan2,3
(1.Baoji Vocational Technology College, Baoji 721013; 2.University of Chinese Academy of Science, Beijing 10039; 3.National Time ServiceCenter, Chinese Academy of Science, Xi’an 710600)
The traditional collaborative filtering recommendation mechanism, in order to ensure the quality of recommendation for a set of lavge scale data, will lead to increase run time and memory space. This paper analyzes Minhash dimensionality reduction principles for large-scale data, argues to was Minhash for collaborative filtering, and then designs and implements collaborative filtering algorithm based on Minhash model. The results show that Minhash can largely reduce computing time and storage space under the premise of quality assurance, and can effectively extend to large data sets.
Collaborative filtering; Large data sets; Minhash
TP311
A
2017.01.28)
刘艾侠(1982-),女,周至人,汉族,硕士,讲师,研究方向:计算机技术。
刘丹丹(1983-),女,焦作人,汉族,硕士,助理研究员,研究方向:计算机软件设计。
1007-757X(2017)10-0067-04
