云计算环境下不可靠数据恢复方法研究
2017-11-01王三虎薛艳锋武彩红
刘 凯,王三虎,薛艳锋,武彩红
(吕梁学院 计算机科学与技术系,山西 吕梁 033000)
云计算环境下不可靠数据恢复方法研究
刘 凯,王三虎,薛艳锋,武彩红
(吕梁学院 计算机科学与技术系,山西 吕梁 033000)
由于云计算环境下不可靠数据中包含有利用价值的信息,但直接使用可能会给计算机带来负担,所以需要对云计算环境下不可靠数据进行恢复;当前大多数方法对不可靠数据进行复写时,利用地址映射层分配新的写入地址,因此不可靠的数据在一段时间内仍存在于云存储中,在这样的系统上实现对其的保护,不需额外保存数据的更新信息;通过FLASH的带外区记录时间戳,在FTL的映射项中增加时间戳信息,在不跟踪映射表每次更新的情况下,达到数据快速恢复的目的;但这种方法对云存储系统性能产生不利影响;为此,提出一种基于张量Tucker阈值的云计算环境下不可靠数据恢复方法,首先利用云计算环境下节点自身的随机秘钥生成器产生随机会话密钥,并对不可靠数据HMAC报文鉴别码进行计算,从而实现保护和重构;在此基础上,将不可靠数据的阈值分解过程与奇异阈值方法相结合,从而得到Tncker阈值算子,实现动态的数据恢复,恢复过程中利用Tucker阈值算子与增广拉格朗日乘子方法相结合的方式选择n-秩相似张量,提出基于增广拉格朗日乘子方法的不可靠数据Tucker阈值恢复方法,完成云计算环境下不可靠数据恢复;实验证明,所提方法能够有效提高不可靠数据恢复的准确性,降低数据恢复的能耗和时间,具有较强的可行性,为该课题的应用研究提供理论依据。
云计算;不可靠数据;数据恢复
0 引言
随着云计算技术的不断发展产生了大量数据,称为现今社会非常重要的信息资源。然而云计算环境下,一些数据由于木马病毒等原因,变成不可靠数据[1]。但这些数据中可能蕴含非常重要的信息,直接使用会影响使用效率[2]。不可靠数据恢复包括数据保护、数据分解等内容,针对不可靠数据存储位置的不同,导致不可靠数据恢复方法的不同[3]。云环境下不可靠数据恢复的方法需要改进和创新,以满足当前环境下数据恢复的要求[4]。但目前大多数数据恢复方法利用手工重建数据链恢复不可靠数据,通过文件系统转换不可靠数据类型,完成RBM重建,根据重建后的RBM,对不可靠数据位置进行描述,完成原不可靠数据内容表的重建,从而完成不可靠数据重建[5],这种方法进行不可靠数据恢复能耗较少,称为当前不可靠数据恢复的重要方法,随着信息化和网络化的发展与应用[6],不可靠数据恢复成为当前研究的热点问题,随着研究内容的深入,产生了大量的研究成果[7]。
文献[8]以SQLite3文件格式为恢复依据,提出了一种云计算环境下不可靠数据恢复方法。通过对SQLite3数据库的文件格式的分析,分析不可靠数据记录的存储机制。通过识别SQLite3文件格式,实现不可靠数据页中的自由块和未使用空间进行寻找和收集,从而完成不可靠数据恢复方法。但这种方法仅适用于SQLite3文件格式,使用范围受到限制,难以推广使用。文献[9]提出一种基于相干函数无偏估计的不可靠数据恢复技术。首先对云计算环境下不可靠数据结构模型进行构建,针对需要进行数据恢复的不可靠数据结构进行特征分解和信息模型构建,采用相干函数特征分解算法对待恢复的不可靠数据进行筛分和残差滤除,最后采用相干函数无偏估计算法提高不可靠数据恢复的准确度,这种方法对对数据进行恢复时,花费时间较长。文献[10]提出一种基于模式识别的云环境下不可靠数据恢复方法。通过对不可靠数据进行特征量提取,并与预先设置的时序相对变化量变化趋势矩阵和时序数值矩阵进行模式匹配,实现不可靠数据的实时辨识,并使用错误出现最近时刻的正常数据进行数据快速恢复。
针对传统方法存在的不足,本文提出一种基于张量Tucker阈值的云计算环境下不可靠数据恢复方法,首先,利用节点自身的随机秘钥生成器生成随机会话密钥,并完成不可靠数据HMAC报文鉴别码计算,从而实现不可靠数据的保护和重构。采用阈值分解过程与奇异值阈值方法相结合,实现对不可靠数据的Tucker阈值算子的计算,实现不可靠数据恢复过程中动态地选择n-秩相似张量,在此基础上,以基于增广拉格朗日乘子方法为依据,结合得到的算子,实现基于张量Tucker阈值的云计算环境下不可靠数据恢复。实验证明,本文所提方法是一种准确度较高、可行性较强的方法,提高不可靠数据恢复效率,为该课题的应用研究提供理论依据。
1 基于距离的云计算环境下不可靠数据恢复
在云计算环境下,不可靠数据对象之间的相关性可以表示成以下几种:
1)在云计算环境中,与不可靠数据对象相关联的对象一直在一起。
2)与不可靠数据相关联的数据对象在开始几个连续窗口中在一起,然后,它们分离,不在一起。
3)与不可靠数据相关联的数据对象在连续窗口中,有时在一起,有时分离。
设在云计算环境中当前数据窗口的前一窗口[t-2w+1,t-w]中,项集X={T1,T2,…,Tm}的关联度为φt-w(X),则在当前数据窗口Wc中,X关联度可以表示为:
(1)
式中,exp_sup(X,Wc)表示在但钱数据窗口Wc项集X的期望支持度,f表示该窗口的衰减因子。设定Tm和Tn表示两个数据对象,则在窗口[t-w+1,t]中,存在φt(Tm,Tn)=φt(Tn,Tm)。
设η表示云计算环境下不可靠数据的不关联阈值,φt(X)表示不可靠数据项集X在云计算窗口Wc中的关联度,当满足条件:φt(X)<η时,则称云计算环境下不可靠数据的项集树所包含不可靠数据对象不具有关联性。
设定一个窗口Wc中,Ti,Tj∈X,当Tj满足公式(2),则称Tj为Ti的最大关联标签。
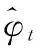
(2)
在云计算窗口W[m,n]内,以不可靠数据Ti的观测事务为元素,以观测时序为顺序惊醒汇集组成集合,将这个集合称为不可靠Ti的概率运动轨迹,表示为:
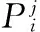
(3)
在云计算窗口W[m,n]内,将由N个不可靠数据标签的概率运动轨迹汇集组成的集合称为不可靠数据概率运动轨迹集,表示为MS={M1,M2,…,MN}。
分别用Mi和Mj对数据对象Ti和Tj的概率运动轨迹进行表述,且满足条件Mi,Mj∈MS。当Mi和Mj的前l项都表示对应的不可靠数据概率相似运动轨迹点,则称Mi和Mj为l-概率相似运动轨迹,l表示不可靠数据特征的相似度,记为l-PS(Mi,Mj)。
在不可靠数据流中,不可靠数据Ti的最相似运动轨迹表示与不可靠数据Ti概率相似运动轨迹最相似的运动轨迹。并将不可靠数据Ti的最相似运动轨迹的标签称为最相似运动轨迹标签。
多远统计分析方法是以数据对象所具有的多个观测指标规律为基础进行分析统计,从而发现数据对象指标存在的相互关联。由于云计算环境下不可靠数据对象存在多方面关联信息,为多元统计创造了条件。
利用多元统计的判别方法对计算环境下不可靠数据进行恢复,主要技术有两点:
1)确定数据恢复的指标,即预报因子;
2)各项指标在恢复过程中的权重
设定一个数据窗口Wc,标签Ti的最相关标签为TMAX_r,且最相似迹标签为TMAX_s,则Ti在云计算环境Rx∈RSi的各项指标向量可以表示为:
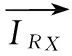
φ4exp_sup(TMAX_s,Wc)}
(4)
式中,φ1,φ2,φ3,φ4分别表示指标所占的权重,pix表示Ti的先验概率。其欧氏距离可以表示为:
(5)
根据上式,得到基于多元统计的判别方法判定规则:
在D(Ti,Rx)≥max{∀j,D(Ti,Rj)}情况下,其中1≤j≤m,则可以说明标签Ti位于云计算系统中,且其后验概率可以计算为:
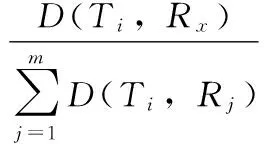
(6)
通过上述论述,基于距离的云计算环境下不可靠数据恢复方法的具体步骤:对不可靠数据进行频繁模式挖掘,从而确定不可靠数据的最大关联标签以及最相似轨迹标签。
利用公式(5)对不可靠数据对应的欧氏距离进行计算,并利用公式(6)实现对不可靠数据的后验概率进行计算,并对后验概率表进行更新,从而确定不可靠数据标签之间的关联度。
2 基于张量Tucker阈值的不可靠数据恢复方法
2.1 数据保护与恢复重构
为实现数据保护,云计算环境中感知节点vi对云计算环境下不可靠数据di进行采集,然后按照以下方式对不可靠数据di进行操作。以保护数据的完整性和机密性。
首先利用云计算环境下节点自身的随机秘钥生成器产生随机会话密钥Ki,来保护不可靠数据的完整性和私密性。
然后使用节点密钥Ki对不可靠数据di的HMAC报文鉴别码进行计算:MAC=HKi(di),以保护不可靠数据的完整性,消除不可靠数据中攻击对其的篡改。
最后使用最开始生成的随机密钥对不可靠数据和鉴别码的联合信息进行对称加密,生成密文,保护数据的机密性。
2.2 基于张量Tucker阈值的不可靠数据恢复方法
为了便于计算和保证不可靠数据回复的精度,引入不可靠数据特征的初始值与不可靠数据张量相等的辅助张量M,满足辅助张量初始值与张量X相等,从而在对不可靠数据恢复进行恢复计算过程中,尽可能保留不可靠数据张量迭代的多样性,从而提高云计算环境下不可靠数据恢复精度。
(7)
公式(7)优化目标函数所要解决的不可靠数据恢复问题通过随机给定部分张量元素下标的子集,根据这些已知元素恢复缺失元素值,使得恢复后的张量为所有可能的恢复张量中的最低秩近似张量。
(矩阵奇异值分解)秩为r的矩阵X∈Rn1×n2的奇异值分解表示为:
X=U∑V*,∑=diag({σi}1≤i≤r)
(8)
其中:U、V分别表示n1×r、n2×r大小的正交矩阵,σi表示不可靠数据奇异值,且σi>0。
(奇异值收缩算子)云环境下不可靠数据矩阵X∈Rn1×n2的奇异值收缩算子或奇异值阈值算子可以表示为;
Dτ(X)=UDτ(∑)V*,Dτ(∑)=diag({max(σi-τ,0)})
(9)
通过公式(9)可知,当云环境下不可靠数据矩阵X的奇异值较数据阈值τ小时,则可认为Dτ(X)的秩要比X小。
对任意的τ≥0和不可靠数据矩阵Y∈Rn1×n2,奇异值收缩算子需要满足:
(10)
根据对云计算环境下不可靠数据矩阵奇异值收缩算子的论述,本文提出了一种基于张量分解的张量恢复算子。
张量X∈Rn1×n2×…×nX的Tucker阈值算子TDτ(X)定义如下:
X≈Γ(1:r1,1:r2,…,1:rN)×1A(1)(:,1:r1)×2A(2)
(:,1:r2)…×NA(N)(:,1:rN)
(11)
ri=sum(Dτ(∑i))=sum(diag({max(σi-τ,0)}))
(12)
式中,∑i表示张量的mode-n矩阵A(i)奇异值分解的奇异值。
对任意的τ≥0和不可靠数据矩阵Y∈Rn1×n2×nN,奇异值收缩算子需要满足:
(13)
增广拉格朗日乘子方法主要对如下限制优化问题求解。
minf(X),s.t.h(X)=0
(14)
将上述优化问题通过拉格朗日函数形式进行表示为:
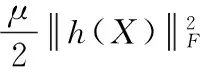
(15)
式中,Y表示不可靠数据的拉格朗日乘子,μ表示正实数。利用交替方向乘子方法对不可靠数据进行分裂并迭代更新从而对不可靠数据进行求解。
(16)
为解决云计算环境下不可靠数据恢复问题,本文通过增广拉格朗日乘子方法确定不可靠数据的优化目标,并将优化目标函数利用拉格朗日函数进行表示为:
s.t.XΩ=TΩ
(17)
其中:β为一正常数,为了加快本文方法的收敛速度,在迭代中令βk+1=tβk,其中t∈[1,2]。根据增广拉格朗日乘子方法,得到如下三个子问题的求解形式:
(18)
利用公式(15),对X和Y进行求解,则有:
(19)
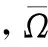
可利用张量Tucker阈值方法对不可靠数据M进行求解,实现不可靠数据恢复,需要对公式(17)进行等价变形:
(20)
设定N=X(1/β)Y,则:
(21)
通过上述论述,完成云计算环境下不可靠数据恢复。
3 实验结果与分析
为证明本文提出的基于张量Tucker阈值的云计算环境下不可靠数据恢复方法的有效性和实用性,以Intel P4 2G处理器为硬件环境,Matlab2008a为平台,以云计算环境下不可靠数据为实验数据,运用对比法将本文提出的基于张量Tucker阈值的云计算环境下不可靠数据恢复方法与文献[8]和文献[9]所提云云计算环境下不可靠数据恢复方法进行比较,完成本次实验。
首先对不可靠数据恢复的准确度进行实验,实验通过在云环境下不可靠数据中随机抽取50组不可靠数据,观察恢复后数据的原始性。通过实验,得到三种不可靠数据恢复方法的恢复准确度对比,对比结果如图1所示。
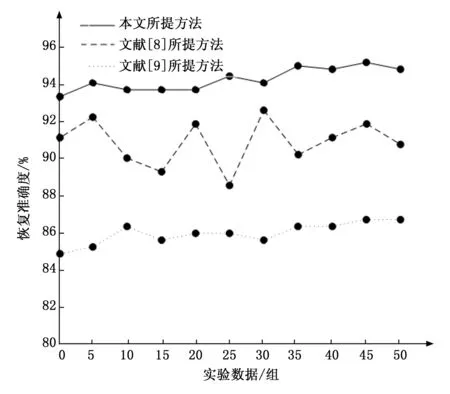
图1 三种恢复方法的恢复准确度对比
通过图1可以看出,本文所提不可靠数据恢复方法数据恢复的准确度较高,且准确度较稳定,由于本文在进行数据恢复过程中,首先对数据进行保护和恢复重构,保证了数据的完整性,从而提高不可靠数据恢复的准确度。
表1是云计算环境下不可靠数据恢复方法的恢复时间(s)对比。实验分别次利用三种不可靠数据恢复方法对相同数据进行恢复,得到恢复时间对比,对比结果如表1所示。
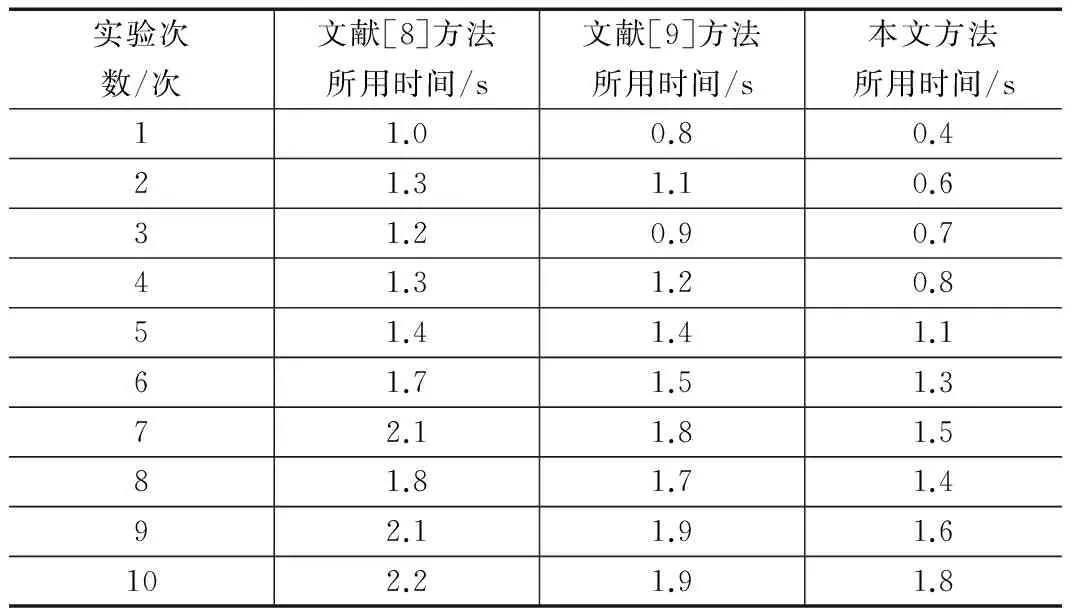
表1 三种不可靠数据恢复方法恢复时间对比
通过表1可知,本文所提不可靠数据恢复方法的恢复耗时较短,由于张量Tucker分解算法复杂度较低,运行较快,从而提高不可靠数据恢复方法的恢复速度。进行三种不可靠数据恢复方法进行数据恢复时所占存储空间(MB)对比,实验通过对不同大小不可靠数据进行恢复,对比恢复后数据大小,对比结果如表2所示。
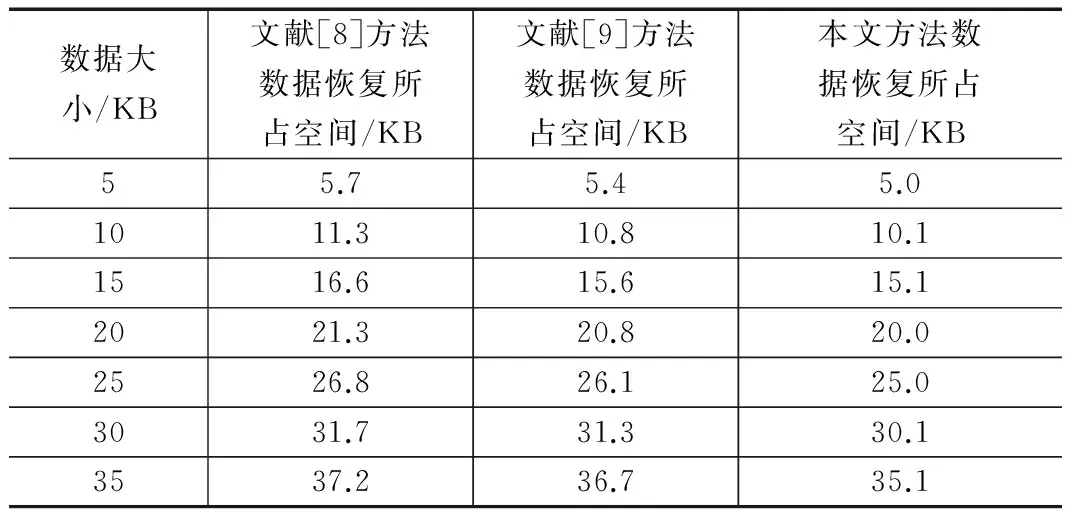
表2 三种方法进行不可靠数据恢复所占存储空间对比
通过表2可知,本文所提方法进行数据恢复后,数据的大小变化较小,由于本文针对张量Tucker分解算法存在的不足,将Tucker分解算法与奇异值阈值函数相结合,降低了不可靠数据分解的存储空间,从而降低不可靠数据恢复所占空间。
对比三种云计算环境下不可靠数据恢复方法的可行性,设可行性单位为%,实验通过对不同事件类型的不可靠数据进行恢复,对比恢复的准确度,为保证实验的准确度,对每种事件类型分别进行500次实验,计算每种事件类型不可靠数据恢复的平均准确度作为可行性,从而得到三种方法的可行性对比,对比结果如表3所示。
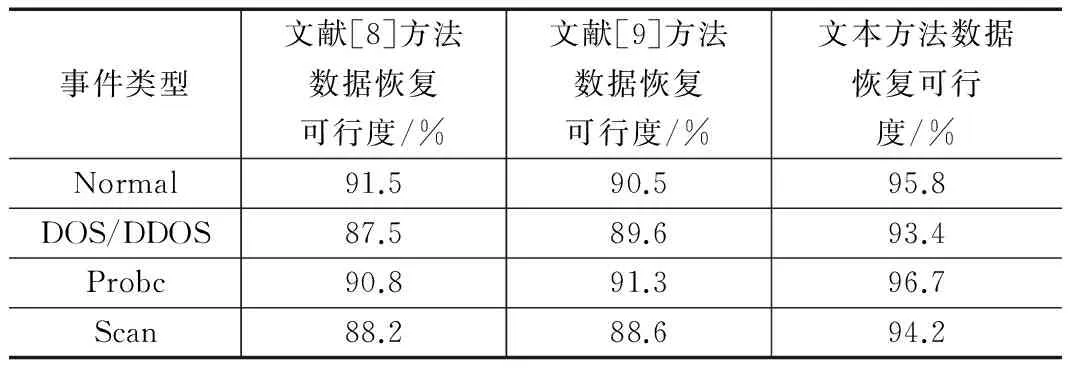
表3 三种方法的可行性对比
通过表3可知,本文所提不可靠数据恢复方法对不同事件类型的不可靠数据进行恢复,可行性都达到93%以上,说明本文所提方法适用于不同事件类型的不可靠数据恢复,具有较强的可行性。
最后对三种云计算环境下不可靠数据恢复方法的能耗(焦)进行对比,通过实验,得到三种云计算环境下不可靠数据恢复方法的运行能耗对比,对比结果如图2所示。
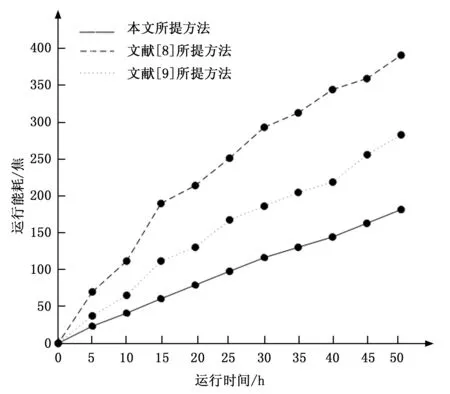
图2 三种方法的运行能耗对比
通过图2可知,本文所提不可靠数据恢复方法的运行能耗较少,且本文所提方法能耗较均匀说明本文所提方法运行较为稳定。
综上所述,本文所提云计算环境下不看可靠数据恢复方法能够有效提高不可靠数据恢复的准确度,降低不可靠数据恢复时间和能耗,且数据恢复占用的内存较少,具有良好的使用价值。
4 结束语
云计算环境下存在大量的不可靠数据,但这些数据中可能含有重要信息,不可以删除,这就需要对云计算环境下不可靠数据进行恢复。采用当前的不可靠数据恢复方法进行数据恢复时过程较复杂,并且难以保证恢复后数据的准确度。提出一种基于张量Tucker阈值的云计算环境下不可靠数据恢复方法,通过实验证明,所提方法的准确度较高,具有较强的可行性。
[1] 张 露,尚艳玲.云计算环境下资源调度系统设计与实现[J].计算机测量与控制,2017,25(1):131-134.
[2] 周 虹, 陈 锋. 一种云计算共享数据完整性公开审计方案[J]. 电子设计工程, 2016, 24(9):60-62.
[3] 崔立鲁,朱贵发.利用重力卫星数据恢复地球质量迁移方法的研究[J].科学技术与工程,2015,15(14):106-109.
[4] 向劲松,王 举,吴 涛,等.基于脉冲展宽波形的光脉冲位置调制异步采样信号的数据恢复技术[J].光学学报,2017(1):74-81.
[5] 韩利华,程 聪.遮挡物体的图像恢复方法研究与仿真[J].计算机仿真,2016,33(11):345-348.
[6] 刘金明,谢秋菊,王 雪,等.基于GSA-SVM的畜禽舍废气监测缺失数据恢复方法[J].东北农业大学学报,2015,46(5):95-101.
[7] 杨立东,王 晶,谢 湘,等.基于低秩张量补全的多声道音频信号恢复方法[J].电子与信息学报,2016,38(2):394-399.
[8] 白晋国,孙红胜,胡泽明.一种基于SQLite3文件格式的删除数据恢复方法[J].小型微型计算机系统,2016,37(3):505-509.
[9] 陈红玉,孟彩霞.基于相干函数无偏估计的数据恢复技术[J].科技通报,2016,32(3):105-108.
[10] 陈亦平,陈伟彪,姚 伟,等.WAMS错误数据的快速辨识及恢复方法[J].电力自动化设备,2016,36(12):95-101.
Research on Unreliable Data Recovery Method in Cloud Computing Environment
Liu Kai,Wang Sanhu,Xue Yanfeng,Wu Caihong
(Department of Computer Science and Technology,Lüliang University,Lüliang 033000,China)
Because the cloud computing environment is unreliable and the data contain valuable information, the direct use may lead to the burden on the computer, so it is necessary to recover the unreliable data in the cloud computing environment. Most of the current methods of copying unreliable data, use the address mapping layer assignment write new address, so unreliable data in a period of time still exists in the cloud storage, the protection is achieved in such a system, do not need to update the channel additional data storage information. The timestamp information is added to the mapping term of FTL through the outer zone record timestamp of FLASH, and the fast recovery of data is achieved without updating the mapping table each time. But this approach has a detrimental effect on the performance of cloud storage systems. Therefore, this paper proposes a method to calculate environment unreliable data recovery method based on tensor Tucker threshold cloud, first calculate the random secret key generator node environment generates a random session key using the cloud, and the unreliable data HMAC message authentication code is calculated, so as to realize the protection and reconstruction. On this basis, combining the unreliable data threshold decomposition process and singular threshold method, in order to get the threshold of Tncker operator, to achieve dynamic data recovery, similar n- rank tensor combined with Tucker threshold operator and the recovery process using augmented Lagrange multiplier method is chosen, no reliable data recovery method of Tucker threshold augmented Lagrange multiplier based on the proposed, completed under the cloud computing environment is not reliable data recovery. Experimental results show that the proposed method can effectively improve the accuracy of unreliable data recovery, reduce the energy consumption and time of data restoration, and has a strong feasibility. It provides a theoretical basis for the application of this topic.
cloud computing; unreliable data; data recovery
2017-01-05;
2017-02-11。
吕梁学院校内自然科学基金项目(ZRXN201506);吕梁学院校级重点大学生创新创业训练项目(CXCYZD201625)。
刘 凯(1985-),男,山东临沂人,硕士研究生,助教,主要从事计算机软件、数据挖掘、人工智能方向的研究。
1671-4598(2017)08-0028-04
10.16526/j.cnki.11-4762/tp.2017.08.008
TP309
A
