一种改进的模糊C均值聚类算法簇数量优化研究
2017-10-23徐叶军
徐叶军
(苏州工业园区服务外包职业学院,江苏苏州 215123)
一种改进的模糊C均值聚类算法簇数量优化研究
徐叶军
(苏州工业园区服务外包职业学院,江苏苏州 215123)
聚类分析是无监督模式识别领域最重要的研究课题之一。模糊聚类由于建立了从样本到类别的不确定性描述,能够更客观地反映真实的世界。传统模糊聚类算法无法实现最优化配置的聚类个数自动计算。本文通过采纳分层聚类思想,提出了一种能自动、高效确定最佳聚类数目的新型自适应模糊C均值聚类算法——A-FCM算法。数值实验表明,与其他通过各种有效性函数来确定聚类数目的自适应模糊聚类算法相比,A-FCM算法的性能更优越。
聚类;分层聚类;模糊聚类;聚类数;有效性函数
模糊C均值算法,即FCM[1],是目前聚类分析领域应用最广泛的算法之一,但与其他聚类算法一样,该法同样要求将聚类的数目当成一个初始参数。因此,如何来确定聚类的最佳数已成为模糊聚类分析的一大研究话题。目前,用来分析聚类结果合理性的有效性函数常常被用来确定聚类的最佳数。主要的有效性函数可分为两大类:一类是通过基于数据集而进行的模糊划分;另一类是通过基于数据集而进行的几何操作。J C Bedzek提出的划分系数[2]是衡量模糊聚类有效性的首个有效性函数,用于测定聚类之间的重叠度。他认为最大指数值即是最佳聚类数。C E Shannon提出了分类熵的概念[3],他认为最小指数值即是最佳聚类数。这两种有效性函数均具有直观的几何意义和可靠的数学属性。但它们的缺陷主要在于它们的单调趋势及数据本身的某些特征之间缺乏直接关联。基于数据集的几何结构,Xie-Beni在1991年提出了Xie-Beni有效性函数[4]。Xie-Beni指数即类间距离的程度与类内距离的程度之间相比,最小指数值即是最佳聚类结果。研究表明,当c→n时,Xie-Beni指数会单调递减至0,以致丧失鲁棒性而无法确定聚类的最佳数。2006年,S H Kwon提出了一种新的有效性函数,即Vkwon[5],它是对Xie-Beni有效性函数的改进,能有效遏制指数值下降,使其永远无法为0,最小值数值是最佳聚类数。2008年,Bensaid M提出了有效性函数Vbsand[6],认为最小数值是最佳划分。2009年,Yang Li,Fusheng YU提出了L(C)这种新型的有效性函数,认为最大指数值是最佳聚类数。
为了确定最佳聚类数,目前最新的算法首先设一系列聚类数满足C∈{Cmin,…,Cmax},然后,根据数据集对{Cmin,…,Cmax}中每个可能的C执行FCM算法。最后,利用有效性函数就可以得出最佳聚类数。这一方法会导致计算工作复杂程度高。为了解决这方面的问题,本文引入分层聚类的思想并提出一种新型的自适应聚类算法,即A-FCM算法,它能自动确定最佳聚类数,而且因为分层拆分的缘故,能极大地减少计算工作量。本文对UCI机器学习库里的三组数据集进行了实验,结果表明在解决最佳聚类数的确定问题方面,A-FCM算法表现出比其他应用诸如Xie-Beni指数等有效性函数的算法更好的性能。
1 模糊C-均值算法及主要的有效性函数
1.1 FCM算法
Dunn[7-8]根据Ruspini界定的数据集的模糊划分将硬C-均值(HCM)应用到模糊情况下。Bezdek将其延用到更一般的情况下,并对模糊聚类进行一般描述。模糊C均值算法的表达公式如下:

(1)

(2)
其中,U={uik};v=(v1,v2,…,vc);m>1,m是模糊加权指数,C是目标研究的聚类数,n表示数据集大小。Bezdek利用迭代算法求得了方程式(1)的最优解。该算法的迭代公式表示为:
该算法具有收敛性,且在解点位置,目标函数获取到局部最小值。
1.2 主要的有效性函数
划分系数(PC)及分类熵(PE)常被用作有效性函数,有关定义如下:
上述两个有效性函数都是单调函数,对它们的应用造成了限制。Xie-Beni有效性函数定义如下:
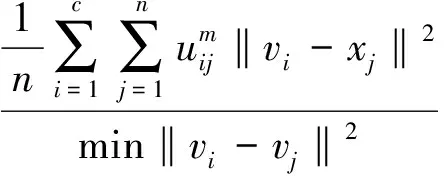
(7)
其中,xj(j=1,2,…,n)是数据集上的一个模式,vj(j=1,2,…,c)是第j个聚类的原型。
2 新型自适应模糊C均值聚类算法(A-FCM)
A-FCM算法综合了FCM算法以及分层聚类的理念。首先,调用上文提及的FCM算法将数据集划分为几个初始聚类,然后开始数据分解过程。每次分解过程中,会根据某些准则挑选出某个聚类,然后利用FCM算法将其分解成两个聚类。重复上述过程直至聚类的数目达到最大为止。
2.1 聚类分解策略
Ward最小方差法最初被用在分层聚类算法的合并过程方面,通常被称为“Ward方法”。在算法一开始,数据集的每个项目均将被认为是一个聚类,然后,其中的一些聚类合并成一个较大聚类。每次合并过程中,可以计算出从所有数据项到它们对应的聚类中心的误差平方和,对象间的距离可通过欧几里得距离法测得。目标函数即离差平方和函数。实际上,离差平方和函数反映的是聚类的紧凑性。因此,每次合并过程中,Ward方法会将在合并后能产生最小聚类方差的两个聚类进行合并。
在A-FCM算法的聚类分解过程方面,本文采用Ward方法。每次分解过程中,聚类会被分解成能产生最大减量的离差平方和(聚类方差)的两个聚类,因此,这表明这两个聚类的紧凑性最差。
聚类运算的分解过程定义如下:
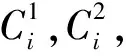

(8)
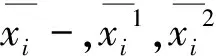
利用Ward方法挑选出聚类Ci以进行分解,通过分解可以得到最大的δ(Ci),相关命题如下:
命题1 对于两个聚类Ci、Cj,如果δ(Ci)>δ(Cj),那么较小的聚类方差由分解Ci而产生。
证明 设Ci的聚类方差为Wi,将Ci分解成两个聚类后,聚类方差之和为:
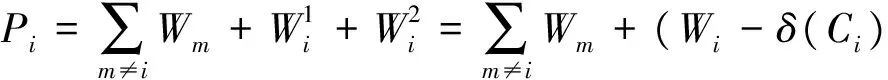
同样,设Cj的聚类方差为Wj,对Cj进行分解后,聚类方差之和为:
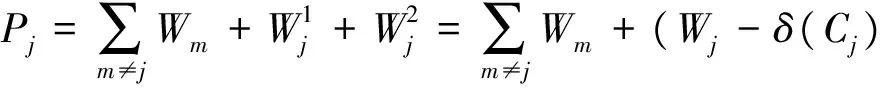
聚类方差的主和为:
由上可知,如果δ(Ci)>δ(Cj),则Pi 2.2 最佳聚类数的确定方法 衡量聚类效果的最重要准则之一是偏差和紧凑性,聚类间的距离应尽可能地大,聚类内的距离应尽可能地小。本文根据聚类方差提出了一个新标准。 (9) 2.3 算法 给出A-FCM算法的步骤定义如下: 输入:一个数据集D包含n个数据项; C最小:聚类的初始个数; C最大:聚类的最大个数; 输出:最佳聚类数及对应的聚类; ①调用FCM(D,Cmin)算法将D分解成Cmin个聚类,设Csum=Cmin; ④Csum=Csum+1,直到Csum>Cmax; ⑤对于每个Ci,根据式(9)计算出S(C); ⑥设可导致产生S(C)的最大值的数为Copt=Ci; ⑦返回Copt与Copt这两个聚类的最佳聚类数。 本文对A-FCM算法及利用有效性函数来确定最佳数的其他算法进行了比较。实验使用到的3个数据集取自UCI数据库[9]。UCI数据库是加州大学欧文分校(University of CaliforniaIrvine)提出的用于机器学习的数据库,这个数据库目前共有187个数据集,其数目还在不断增加,UCI数据集是一个常用的标准测试数据集。本实验主要选用葡萄酒数据集,鸢尾属植物数据集与玻璃数据集。 实验过程中,对初始参数进行了设定:模糊加权指数m=2,最大迭代数i=50,收敛精确度ε=0.0001,聚类数范围为C={2,…,10}。 3.1 葡萄酒数据集 葡萄酒数据集[9]包含178个事例,每个事例具有13个属性,每个属性又有3个类别。 图1提供了S(C)的指数值。除了Vpc和Vbsand函数,大多数有效性函数均可获取到最佳聚类数。 表1 葡萄酒数据集聚类数的指数值 图1 葡萄酒数据集S(C)的指数值 3.2 鸢尾属植物数据集 鸢尾属植物数据集[9]是最为人熟知的,也是模式识别方面应用最广泛的一种数据集。它包含3个类别的事例,每个类别有50个事例。每个类别对应于一种鸢尾属植物。其中一个类别与其他两个呈线性关系分开,但后者无法呈线性关系与前者分开。 表2是从聚类数C=2到C=10的鸢尾属植物数据集方面的A-FCM算法及其他有效性函数的指数值。由此可知,由于后者的类别彼此之间无法呈线性关系分开,大多数有效性指数表明C=2便是最佳聚类数,同时,A-FCM算法可以确定正确的聚类数C=3。图2中当聚类数C=3时,A-FCM的方程式(9)的值达到最大,表明这是聚类方差发生变化的一个转折点。 表2 鸢尾属植物数据集聚类数的指数值 图2 鸢尾属植物数据集Xie-Beni和S(C)的指数值 3.3 玻璃数据集 玻璃数据集[9]包含214个事例,每个事例有10个属性,每个属性带7个类别。表3提供了从聚类数C=2到C=10的玻璃数据集方面的A-FCM算法及其他有效性函数的指数值。由此可知,A-FCM的指数可以达到最佳聚类数,而其他算法方面则存在一些偏差。图3给出了A-FCM指数值和Xie-Beni指数值。 表3 玻璃数据集聚类数的指数值 图3 玻璃数据集Xie-Beni和S(C)的指数值 本文提出了自适应聚类算法A-FCM算法,通过将FCM算法与分层聚类思想相结合,A-FCM可以自动确定最佳聚类数。实验结果表明,在确定最佳聚类数时,A-FCM算法所达到的效果比其他算法更理想。 [1]Bezdek J C.Pattern recognition with fuzzy objective functionalgorithms[M].New York:Plenum,2009:34-60. [2]Bedzek J C.Cluster validity with fuzzy sets[J].Journal of Cybernetics,2008(3):58-72. [3]Shannon C E.A mat hematical theory of communication[J].BellSyst Tech,2006(4):379-423. [4]Xie X L,Beni G.A validity measure for fuzzy clustering[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2009(12):841-847. [5]Kwon S H.Cluster validity index for fuzzy clustering[J].Electronics Letters,2006(8):2176-2177. [6]Bensaid A M.Validity-Guided(Re) clustering with applications to imgae segmentation[J].IEEE Trans on Fuzzy Systems,2008(9):112-123. [7]Dunn J C.A graph theoretic analysis of pattern classification via Tamura’s fuzzy relation[J].IEEE Trans. SMC,2005(2):310-313. [8]Yang Li,Fusheng Yu.A new validity function for fuzzy clustering[J].IEEE Computational Intelligence and Natural Computing,2009(4):462-465. [9]Asuncion A,Newman D J.UCI Machine learning repository[EB/OL].(2007-12-20)[2016-10-01]. http://www.ics.uci.edu/~mlearn/MLRepository.html. OptimizationoftheClustersNumberofanImprovedFuzzyC-meansClusteringAlgorithm XU Ye-jun (Suzhou Industrial Park Institute of Services Outsourcing,Suzhou Jiangsu 215123,China) Clustering analysis is one of the most important research topics in the field of unsupervised pattern recognition. Because fuzzy clustering has established the uncertainty description from samples to category, it is able to response to the real world more objectively. Traditional fuzzy clustering algorithm is unable to realize the clustering number automatic calculation with optimization configuration. Through adopting hierarchical clustering method, this article puts forward a kind of new adaptive fuzzy c-means clustering algorithm-A- FCM algorithm, which determines the best clustering number automatically and efficiently. Numerical experiments have shown that being compared to other adaptive fuzzy clustering algorithms which determine the clustering number through a variety of effectiveness functions, this method is superior in performance. clustering; hierarchical clustering; fuzzy clustering; number of clusters; validity function TP301.6 A 2095-7602(2017)10-0022-06 2017-04-18 徐叶军(1980- ),男,讲师,硕士研究生,从事计算机应用与软件工程研究。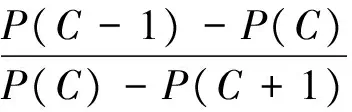

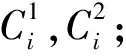
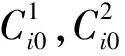
3 实验分析与结果

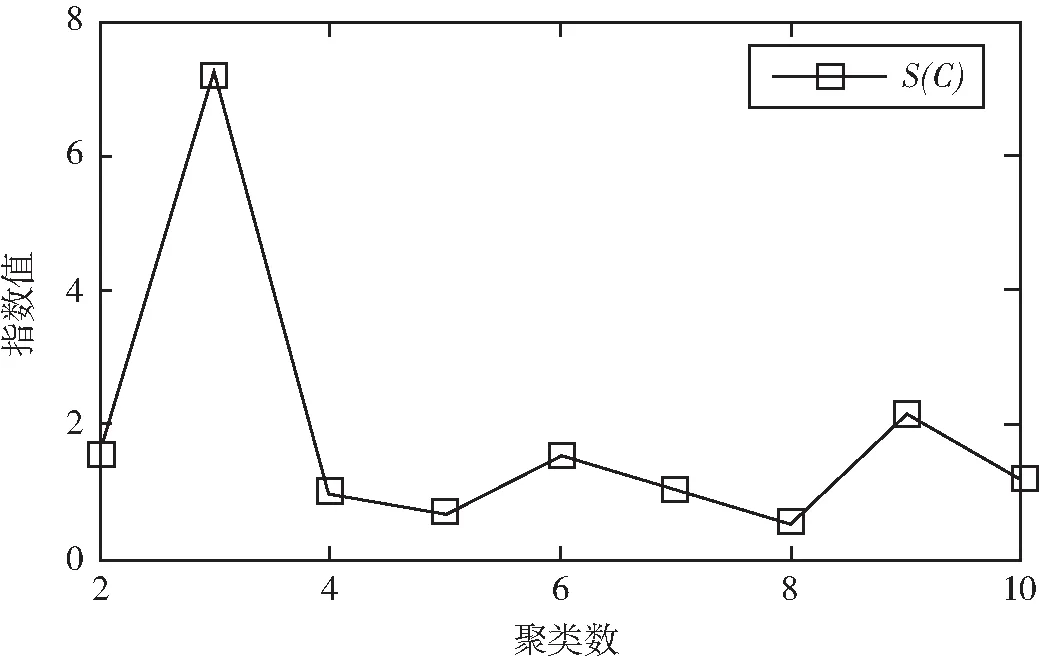




4 结语
