基于动态聚类的旅游线路推荐
2017-10-21肖春景夏克文乔永卫张宇翔
肖春景,夏克文,乔永卫,张宇翔
(1.河北工业大学 电子信息工程学院,天津 300300; 2.中国民航大学 计算机科学与技术学院,天津 300300;3.中国民航大学 工程技术训练中心,天津 300300)
(*通信作者电子邮箱kwxia@hebut.edu.cn)
基于动态聚类的旅游线路推荐
肖春景1,2,夏克文1*,乔永卫3,张宇翔2
(1.河北工业大学 电子信息工程学院,天津 300300; 2.中国民航大学 计算机科学与技术学院,天津 300300;3.中国民航大学 工程技术训练中心,天津 300300)
(*通信作者电子邮箱kwxia@hebut.edu.cn)
基于会话的协同过滤用固定时间窗划分交互历史并将用户兴趣表示为这些阶段的序列,但是旅游数据的高稀疏性会导致某些阶段内没有交互行为和近邻相似度计算困难的问题。为了缓解数据稀疏,有效利用数据特性,提出了基于动态聚类的旅游线路推荐算法。该方法首先分析了旅游数据不同于其他标准数据的特性;其次利用动态聚类得到的变长时间窗口对游客交互历史进行划分,利用潜在狄利克雷分布(LDA) 抽取每个阶段的概率主题分布,结合时间惩罚权值建立用户兴趣漂移模型;接着,通过反映年龄、线路季节、价格等因素的游客特征向量为目标游客选择近邻和候选线路集合;最后根据候选线路和游客的概率主题相关度完成线路推荐。该方法通过采用变长时间窗口不但缓解了数据稀疏,而且划分的阶段数目不需提前指定,而是根据数据特性自动生成;近邻选择时采用特征向量而非旅游数据进行相似度计算,避免了由于数据稀疏无法计算的问题。在实际旅游数据上的大量实验结果表明,该方法不仅很好适应了旅游数据特征,而且提高了旅游线路的推荐精度。
动态聚类;潜在狄利克雷分布; 兴趣模型; 时间惩罚; 特征向量
0 引言
随着人们生活水平的提高,旅游已经成为休闲娱乐的重要方式。据统计近几年来旅游人数和收入都在以10%以上的速度增长。为了争取客源,旅游公司需了解游客的需求,制定各式各样具有吸引力的旅游线路,但是游客从大量的线路中选出适合自己的线路是一件困难的事情。推荐系统成为解决“信息过载”的主要手段,将其应用到旅游线路的推荐将极大提升游客的体验并给旅游公司带来收益。
推荐系统已经贯穿了旅游的整个过程,包括旅游前的线路推荐[1-2],旅游中利用移动设备进行的个性化服务推荐[3-6]以及旅游结束时的信息反馈[7]。目前的线路推荐一般是根据游客的位置,利用地理信息系统(Geographic Information System,GIS)和移动设备对周边线路或地点进行推荐[3-6]。但是由于游客出游往往受到气候、时间的限制并且用户的兴趣也会随时间而变化,因此时间对于路线的选择至关重要。Liu等[8]以在一定时间段内花费最少、但是到达更多的目的地为前提进行线路推荐;Shen等[9]设计了个性化相似模型并利用用户的异构旅行信息在某一时刻的某一地点位置进行推荐;Hasuike等[10]利用时间依赖网络解决了旅游和景点次数的随机变化问题,并通过条件概率来选择下一个景点;孙焕良等[11]提出了基于动态转移图的时间敏感的旅游路线推荐方法为用户准确地推荐适合其出行时间的最佳旅游线路;She等[12]设计了两步贪心启发式算法来进行下一个目的地的预测,它不但考虑了时空冲突,而且解决了数据稀疏的问题;陆国锋等[13]提取景点的开放时间、门票、GIS坐标、景点的评价信息等提出一种基于多约束的K贪心算法,可以为游客推荐较好的旅游线路,并有效消除了推荐系统对先验知识的依赖。这些推荐模型虽然都考虑了时间因素,但是仅作为约束条件或考虑了景点间的时间依赖关系。但在实际的线路选择过程中,一条线路是否会被某用户选择,往往受线路主题和用户兴趣的共同影响。潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)概率主题模型是文本挖掘领域用来发现文本主题的重要方法,并已扩展和应用到推荐领域挖掘用户的潜在兴趣。He等[14]利用LDA从文档中挖掘隐主题并根据协同过滤得到的预测评分决定哪个线路是最适合用户的,但它没有考虑用户兴趣随时间的变化。基于会话的协同过滤(Session-based Collaborative Filtering, Session-based CF)模型利用固定的时间窗划分用户的交互历史以捕获用户兴趣模式的变化[15-16];而将基于会话的协同过滤与LDA模型相结合挖掘每个会话的概率主题分布来建立用户的动态兴趣模型[17-18],可以更好地捕获用户兴趣主题的变化。但是与商品、电影等的推荐相比,旅游数据的稀疏性更高,这使得利用固定窗口对交互历史进行划分的过程中,某些窗口的历史数据很少甚至没有历史数据,无法用来进行用户兴趣模型建立,更加剧了数据的稀疏性;而且由于数据稀疏使得选择近邻时的相似度计算变得十分困难。
为了缓解数据稀疏,通过结合LDA和时序信息提出了基于动态聚类的旅游线路推荐方法。该方法利用动态聚类采用变长时间窗口对游客交互历史进行划分,不但缓解了数据稀疏,而且聚类个数不用事先指定,而是根据游客数据自动形成,更好地适应了数据特点;结合时间惩罚权值和概率主题分布很好地描述了用户兴趣模式随时间的变化趋势;根据游客年龄、出行季节特点和线路价格建立用户特征向量解决了由于数据稀疏导致的近邻选择困难的问题。在实际旅游数据集上大量实验结果表明,该方法有效地利用了旅游数据的特点,能较准确地为游客进行线路推荐。
1 旅游数据特性分析
旅游数据来源于厦门航空旗下的某旅游公司,共包括从2009年1月到2014年10月间的732 019条旅游记录。本文抽取了4 737个游客对1 436条旅游线路的25 717条旅行记录,每个游客至少旅行过3次。每条记录包括旅客信息和线路信息,其中旅客信息包括旅游团号、姓名、性别、身份证号、出发时间、价格等;线路信息包括出发时间、价格及景点的详细介绍。
1.1 高稀疏性
游客每年旅行的次数非常有限,但是用户购物或看电影却非常普遍,因此旅游数据相比其他的推荐标准数据集稀疏度更高。将本文采集的旅游数据集与标准电影推荐数据集(Movelens_100K)进行比较,而且为了更好地进行对比,电影评分数量是旅游次数的10倍,即图1中旅游次数是横坐标数值的1/10;同时采用人数百分比(即对应横轴数值相应的人数占总人数的比例)作为稀疏性的衡量指标,旅游或电影评分数量少的人数占比越大,说明数据越稀疏。具体对比情况如图1所示,可以看出随着旅游次数的增加,游客的人数百分比快速下降,超过95%的游客的旅行次数都少于10(在横坐标在100附近);而Movielens数据集随着电影评分数量的增加用户评分的百分比也在下降,但是下降速度要明显慢于旅游数据,而且数量越大,差距越明显。
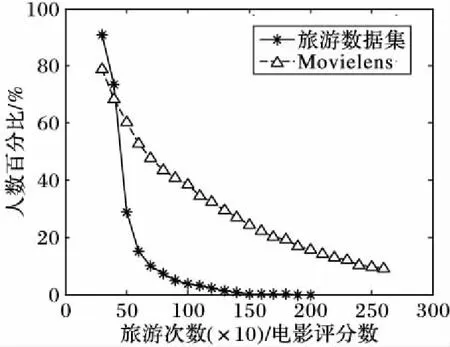
图1 旅游数据集与标准电影推荐数据集的稀疏度对比Fig. 1 Comparison of sparsity between tourism data and standard movie recommendation data
1.2 时序特性
旅游是休闲娱乐的重要方法,容易受到季节、空闲时间等因素的影响。将游客的旅游线路按照月份进行划分统计的结果如图2所示,可以看出,游客更愿意在气候宜人的春秋两季出游。就每个游客而言,选择出游的时间分布比较集中。

图2 游客出游月份统计Fig. 2 Statistics of tourist travel month
图3对每个游客的出行时间进行了统计,可以看出超过70%的游客旅行集中在4个月份以内,说明游客会在每年相对固定的时间出游。因此可以看出游客对线路的选择受到季节的影响,并且每个人出行的时间相对固定。
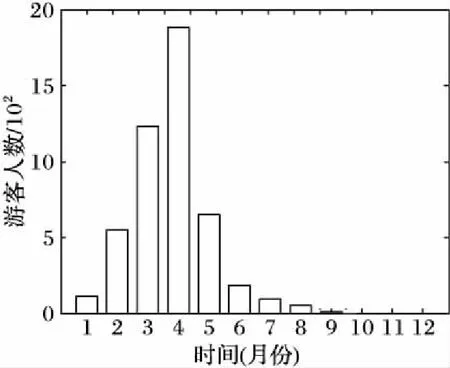
图3 旅客出游月份分布特征Fig.3 Distribution of tourist travel month
1.3 游客年龄及线路价格特征
游客的年龄分布与是否有闲暇时间和是否有较强的经济实力两个主要因素有关,根据这两个因素将年龄按6段分别进行了统计,结果如图4所示。从图4可以看出,游客的主力军集中在1~18岁,26~35和36~50岁,占比超过游客总数的70%。分析可能原因是1~18岁多为求学阶段的学生,有时间充裕的寒暑假,他们更可能会跟随父母或自己结伴去旅游;而他们的父母年龄多集中在26~50岁,并且26~35和36~50岁这两个群体经济能力相对较强,旅游成为了他们休闲娱乐的重要方式。
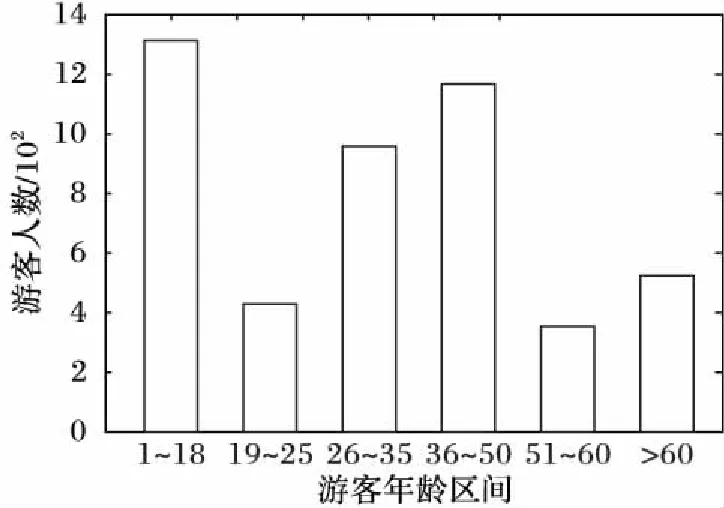
图4 游客年龄分布Fig. 4 Distribution of tourist age
电影、购物等价格往往和时间是无关的,而旅游线路价格的高低往往与旅游时长相关:旅游时间越长,价格越高;相反,旅游时间越短,价格越低。图5统计了游客选择线路的价格情况,可以看出随着价格的增长,选择的游客人数逐步减少,约70%的游客选择了价格在500元以下的线路,500~2 000元的比例基本持平,3 000及3 000元以上的百分比也较接近。因此可以认为人们更喜欢价格便宜、时间短的短途旅游线路,而线路价格达到一定数值之后,价格因素的影响变小。

图5 线路价格分布Fig. 5 Distribution of route price
从以上分析可以看出,旅游数据相比其他标准数据集有更高的稀疏性,游客选择线路受到季节、线路价格的影响,并且游客的年龄也是影响其出行的重要因素。因此,在线路推荐过程中应充分考虑到旅游数据的特点,设计合适的推荐算法,以得到更好的推荐效果。
2 游客兴趣漂移模型的建立
2.1 基于动态聚类的旅行记录的划分
基于会话的协同过滤用固定时间窗将用户的交互历史划分成不同的阶段,并将用户的兴趣模型表示成这些阶段的序列表示。但是由于旅游数据的高稀疏性及游客出行时段的相对固定,固定大小时间窗的划分不适用于旅游数据。因为采用固定时间窗进行划分不但要用非常大的时间窗,而且会导致部分阶段内完全没有旅游行为,这将加剧数据的稀疏性。因此本文考虑按照每个游客实际交互历史的特点将其动态划分成不同的阶段。
定义游客集合U={u1,u2,…,um},旅游历史记录集合H={Hu1,Hu2,…,Hum},旅游线路集合L={l1,l2,…,ln}。首先计算所有旅客的平均旅游时间并作为最小时间窗口γ,对每个游客计算每个线路的密度并按降序排序。接着选择密度最大的线路作为第一个聚类中心,并计算已有聚类中心与其他节点(按密度降序)的距离,如果它们之间的距离大于γ,则产生一个新的聚类中心;否则将两个类进行合并,产生新的聚类中心,并重新计算各类间的距离,直到类间距离和聚类数都不再变化。算法伪码如下所示。
算法1 基于动态聚类的线路划分。
输入 游客的旅游历史记录H={Hu1,Hu2,…,Hum},最小的时间窗口γ;
输出 游客划分结果S={Su1,Su2,…,Sum},聚类结果C={Cu1,Cu2,…,Cum}。
1) forui∈Udo
2) 计算小于时间窗γ的线路密度并按降序排序得到列表
5) do 计算已有聚类中心与D中其他节点的距离
6) if 距离大于γthen
7) 这个点作为一个新的聚类中心
8) else
9) do{两个类进行合并形成新的聚类中心,计算新类与其他已有类间距离}
10) until(任何两类类间距离大于γ)
11) end if
12) until (D为空)
13) 返回Sui和Cui
14) end for
15) 输出S,C

2.2 基于LDA的概率主题分布生成
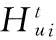

(1)
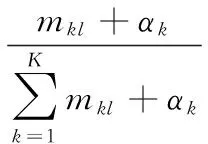
(2)
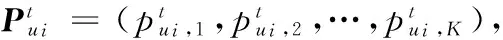
2.3 游客兴趣漂移模型的建立
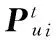
(3)
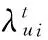
(4)
width—An example of Lijin hydrologic station of the Yellow River
3 旅游线路推荐
3.1 近邻游客选择
由于旅游数据高稀疏性的特点,游客间共同旅游线路非常少,图6给出了随着共同旅游线路的数目增加游客频次变化的情况。从图6中可以看出超过95%游客参加过的共同旅游线路少于3次,在一个月内参加过相同线路的游客随着共同线路数目的增加先增大后减小,几乎所有游客的共同次数也不多于5,这一特点为游客相似性计算带来了巨大挑战。
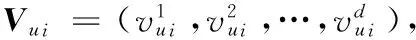
从而计算游客ui与us的相似性如式(5):
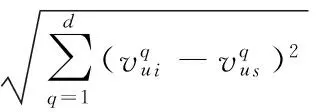
(5)
这样按照用户的特征向量计算用户间的相似性,避免了直接用高稀疏性的旅游数据难以计算相似度的问题,解决了近邻选择困难的问题。
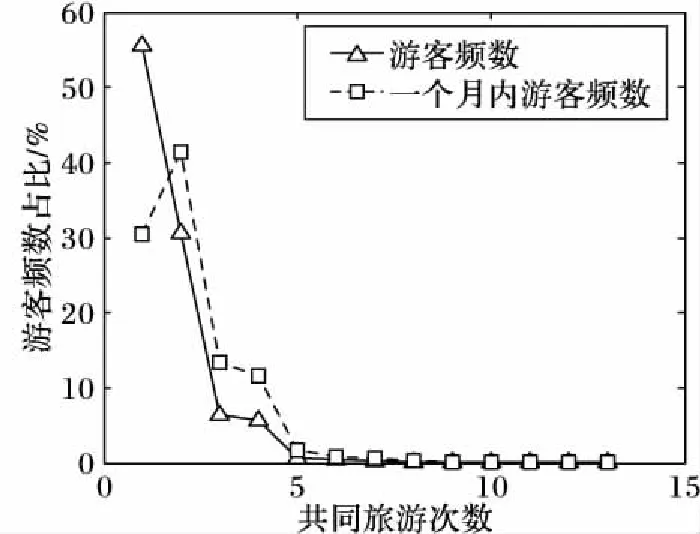
图6 相同旅游线路的游客占比Fig. 6 Proportion of tourists with common routes
3.2 候选线路集合生成
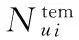
(6)
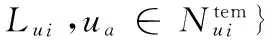
(7)
其中Nui为3.1节得到的近邻用户集合。
3.3 旅游线路推荐
对于游客ui候选线路集合Sui中的每条候选线路利用LDA得到其概率主题分布PLl,利用式(8)计算候选线路Ll与游客ui的|Hui|+1阶段的兴趣偏好的相似度:
(8)
其中Ll∈Sui。通过相似度大小对候选线路进行排序,为游客ui推荐相似度较大的Top-k线路。
4 实验结果及分析
4.1 度量标准
在Top-k推荐中常用准确率(Precision)、召回率(Recall)及有效地平衡了准确率和召回率的F评分进行结果评价。在实验过程中,将每个游客的前|Hui|-1次旅游记录作为训练集,第|Hui|次旅游线路信息作为测试数据,线路推荐成功的数量非0即1,因此准确率的值为0或1/k,召回率为0或1,它们不再适合作为评价分类质量衡量标准,因此提出准确覆盖率作为评价指标,计算如式(9)。
(9)
其中:|U|为游客总数目,ρui定义如式(10)。
(10)

4.2 实验结果及分析
4.2.1 主题数K的影响
主题是LDA的潜在变量,基于LDA的推荐中,K往往是事先设定,而不是通过数据学习获得。本文中将准确覆盖率作为评价标准来学习最佳的主题数K,并记录了随着K增加的运行时间,结果如图7所示。从图7可知,随着K的增加准确覆盖率先增大后减小,因为K太小不能发挥LDA发现潜在兴趣的能力,而K太大得到的概率主题分布又被平均化。而且由于K越大,得到概率主题分布的计算量越大,因此运行时间呈增长趋势。最佳的K是效率和精度的平衡,选取50作为主题数目。

图7 主题数K的影响Fig. 7 Influence of topic number K
4.2.2 近邻数n的选取
在所有基于邻近的方法中,近邻数目都非常重要。将近邻数从10变化到100来评估它对结果的影响,如图8所示。由图8可以看出,随着近邻数目的增加,准确覆盖率先增大后减小。这是因为游客共同旅游线路相对较少:如果近邻数目太小,近邻与目标的相似度很高,由近邻而得到的可选候选线路集合也就越小;而近邻的数目太大时,近邻间的相似度较差,候选线路集合与游客实际兴趣相差较大。因此本文后面的实验选取近邻个数为40。
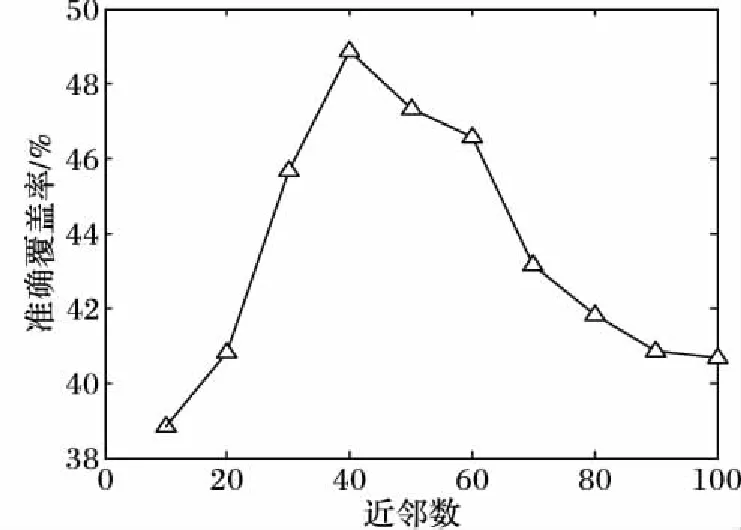
图8 近邻数目的影响Fig. 8 Influence of neighbor number
4.2.3 与其他方法对比
为了说明本文方法的效果和预测能力,将本文方法时序潜在狄利克雷分布(Temporal Latent Dirichlet Allocation, TLDA)与以下三种方法进行了对比:
1)基于用户的协同过滤(User-based Collaborative Filtering, UCF)[19],它作为基于近邻的推荐算法的代表;
2)LDA[14]:基于LDA的用户兴趣建模方法及推荐方法;
3)基于项目的随机游走(ItemRank)[20]:建立旅线路的关联图,通过随机漫步得到线路的排序。
实验中,LDA参数α=50/K,β=0.01,ItemRank的重启动概率为0.15。图9给出了不同算法的结果。从图9可以看出,TLDA、LDA和ItemRank方法都优于UCF,因为UCF仅利用共同旅游的线路寻找近邻用户,但是由于旅游数据的高稀疏性使得它很难找到相似度较高的近邻用户,影响了推荐精度。TLDA方法优于LDA与ItemRank方法,LDA与ItemRank的性能较为接近,因为TLDA针对旅游数据的高稀疏性采用了动态聚类对线路进行聚类,缓解了数据稀疏,在用户兴趣建模阶段考虑了用户的潜在兴趣及时序影响,更好地描述了用户的动态偏好,在近邻的选择过程中根据旅游数据特征建立游客特征向量,并将其作为近邻选择衡量标准,既挖掘了用户的潜在兴趣偏好,建立了其漂移模型,又避免了近邻游客选择可信度不高的问题。而LDA方法虽然利用LDA挖掘了游客潜在兴趣偏好,但是忽略了偏好随时间的变化。ItemRank尽管增加了线路选择的随机性,但是在建立线路间的转移关系时只利用了共同旅游线路,没有考虑时间、价格、游客年龄等因素。
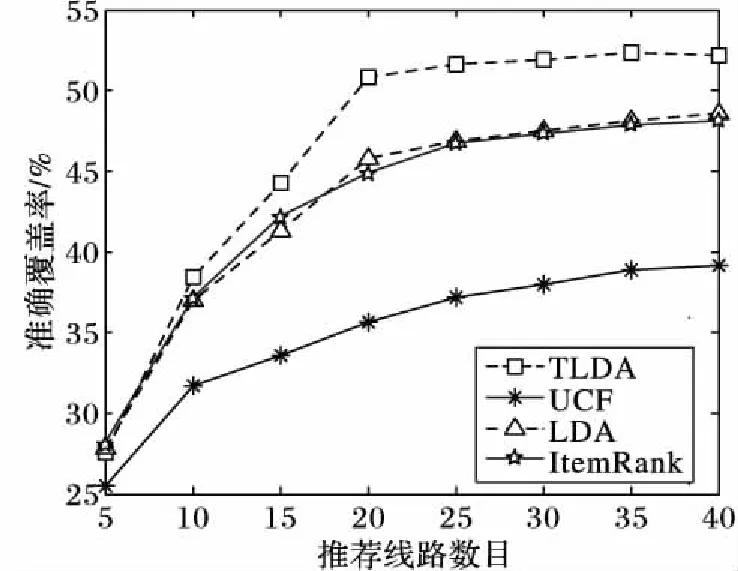
图9 旅游线路推荐结果对比Fig. 9 Comparison of recommended results of tourist routes
5 结语
本文提出了基于动态聚类的旅游线路推荐算法。通过统计分析旅游数据的特性,说明了它不同于其他数据集的特点。利用动态聚类对游客的交互历史采用变长窗口划分成不同的阶段,而且划分个数不需事先指定,通过实验说明其很好地适应了数据特性,缓解了数据的高稀疏性。在每个阶段利用LDA抽取用户的潜在兴趣主题并利用时间惩罚权值以建立游客兴趣漂移模型,更好地挖掘了游客兴趣的变化趋势。利用游客的特征向量为游客寻找近邻用户,很好地解决了用数据本身计算相似度困难的问题。通过在实际旅游数据上的实验表明,本文方法得到了较好的推荐精度。但是本文在用户兴趣建模的过程中只考虑了兴趣随时间的变化,没有考虑游客年龄、线路价格等其他因素,因此下一步将更加充分地挖掘数据特点,更准确地对游客建模。此外,在游客特征向量建立过程中可进一步挖掘游客间隐式社交关系和线路价格-时间等关系来更好地描述其近邻关系。
References)
[1] DEVASANTHIVA C, VIGNESHWARI S, VIVERK J. An enhanced tourism recommendation system with relevancy feedback mechanism and ontological specifications [C]// Proceedings of the 2016 International Conference on Soft Computing Systems, AISC 398. New Delhi: Springer-Verlag, 2016: 281-289.
[2] AL-HASSAN M, LU H, LU J. A semantic enhanced hybrid recommendation approach: a case study of e-government tourism service recommendation system [J]. Decision Support Systems, 2015, 72: 97-109.
[3] XUE A Y, ZHANG R, ZHENG Y, et al. Destination prediction by sub-trajectory synthesis and privacy protection against such prediction [C]// ICDE 2013: Proceedings of the IEEE 2013 29th International Conference on Data Engineering. Washington, DC: IEEE Computer Society, 2013: 254-265.
[4] XUE A Y, QI J, XIE X, et al. Solving the data sparsity problem in destination prediction [J]. The VLDB Journal, 2015, 24(2): 219-243.
[5] ZHU L C, LI Z J, JIANG S X. LBSN-based personalized routes recommendation [J]. Applied Mechanics and Materials, 2014, 644-650: 3230-3234.
[6] 马磊.基于智能解决方案的自助旅游系统[J].计算机系统应用,2017,26(3):57-62. (MA L. Independent travel system based on intelligent solution [J]. Computer Systems Applications, 2017, 26(3): 57-62.)
[7] SU H, ZHENG K, HUAN J, et al. A crowd-based route recommendation system — CrowdPlanner [C]// Proceedings of 2014 IEEE 30th International Conference on Data Engineering. Washington, DC: IEEE Computer Society, 2014: 1178-1181.
[8] LIU H-L, LI J-H, PENG J. A novel recommendation system for the personalized smart tourism route: design and implementation [C]// Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics and Cognitive Computing. Washington, DC: IEEE Computer Society, 2015: 291-296.
[9] SHEN J, DENG C, GAO X. Attraction recommendation: towards personalized tourism via collective intelligence [J]. Neurocomputing, 2016, 173: 789-798.
[10] HASUIKE T, KATAGIRI H, TSUBAKI H, et al. A route recommendation system for sightseeing with network optimization and conditional probability [C]// Proceedings of 2015 IEEE International Conference on Systems, Man, and Cybernetics. Piscataway, NJ: IEEE, 2015: 2672-2677.
[11] 孙焕良,崔晨,刘俊岭.基于动态转移图的时间敏感的旅游路线推荐[J]. 郑州大学学报(理学版),2017,49(1):50-57. (SUN H L, CUI C, LIU J L. Time-sensitive travel route recommendation method based on dynamic transfer graph [J]. Journal of Zhengzhou University (Nature Science Edition), 2017, 49(1): 50-57.)
[12] SHE J, TONG Y, CHEN L. Utility-aware event-participant planning [C]// SIGMOD ’15: Proceedings of the 36th ACM International Conference on Management of Data. New York: ACM, 2015: 1629-1643.
[13] 陆国锋,黄晓燕,吕绍和,等.基于互联网信息的多约束多目标旅游线路推荐[J].计算机工程与科学,2016,38(1):163-170. (LU G F, HUANG X Y, LYU S H, et al. Multi-constraint and multi-objective trip recommendation based on Internet information [J]. Computer Engineering & Science, 2016, 38(1): 163-170.)
[14] HE Z, WU Z, ZHOU B, et al. Tourist routs recommendation based on latent Dirichlet allocation model [C]// Proceedings of 2015 12th Web Information System and Application Conference. Washington, DC: IEEE Computer Society, 2015: 201-206.
[15] YU J, ZHU T. Combining long- term and short-term user interest for personalized hashtag recommendation [J]. Frontiers of Computer Science, 2015, 9(4): 608-622.
[16] XIANG L, YUAN Q, ZHAO S, et al. Temporal recommendation on graphs via long- and short-term preference fusion [C]// KDD ’10: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2010: 723-732.
[17] HONG W, LI L, LI T. Product recommendation with temporal dynamics [J]. Expert Systems with Applications, 2012, 39(16): 12398-12406.
[18] RICARDO D, FONSECA M J. Improving music recommendation in session-based collaborative filtering by using temporal context [C]// ICTAI ’13: Proceeding of IEEE 25th International on Tools with Artificial Intelligence. Washington, DC: IEEE Computer Society, 2013: 783-788.
[19] RESNICK P, IACOVOU N, SUCHAK M, et al. GroupLens: an open architecture for collaborative filtering of netnews [C]// CSCW ’94: Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work. New York, ACM, 1994: 175-186.
[20] GORI M, PUCCI A. ItemRank: a random-walk based scoring algorithm for recommender engines [C]// IJCAI ’07: Proceedings of the 20th International Joint Conference on Artifical Intelligence. San Francisco, CA: Morgan Kaufmann Publishers Inc., 2007: 2766-2771.
This work is partially supported by the National Natural Science Foundation of China (U1533104), the Natural Science Foundation of Hebei Province (E2016202341), the Natural Science Foundation of Tianjin (14JCZDJC32500), the Fundamental Research Funds for the Central Universities (ZXH2012P009).
XIAOChunjing, born in 1978, Ph. D. candidate, lecturer. Her research interests include recommendation system, data mining.
XIAKewen, born in 1964, Ph. D., professor. His research interests include intelligent information processing, data mining.
QIAOYongwei, born in 1976, M. S., lecturer. His research interests include machine learning, intelligent information processing.
ZHANGYuxiang, born in 1975, Ph. D., associate professor. His research interests include machine learning, data mining, artificial intelligence.
Tourismrouterecommendationbasedondynamicclustering
XIAO Chunjing1,2, XIA Kewen1*, QIAO Yongwei3, ZHANG Yuxiang2
(1.SchoolofElectronicsandInformationEngineering,HebeiUniversityofTechnology,Tianjin300300,China;2.SchoolofComputerScienceandTechnology,CivilAviationUniversityofChina,Tianjin300300,China;3.EngineeringandTechnicalTrainingCenter,CivilAviationUniversityofChina,Tianjin300300,China)
In session-based Collaborative Filtering (CF), a user interaction history is divided into sessions using fixed time window and user preference is expressed by sequences of them.But in tourism data, there is no interaction in some sessions and it is difficult to select neighbors because of high sparsity. To alleviate data sparsity and better use the characteristics of the tourism data, a new tourism route recommendation method based on dynamic clustering was proposed. Firstly, the different characteristics of tourism data and other standard data were analyzed. Secondly, a user interaction history was divided into sessions by variable time window using dynamic clustering and user preference model was built by combining probabilistic topic distribution obtained by Latent Dirichlet Allocation (LDA) from each session and time penalty weights. Then, the set of neighbors and candidate routes were obtained through the feature vector of users, which reflected the characteristics of tourist age, route season and price. Finally, routes were recommended according to the relevance of probabilistic topic distribution between candidate routes and tourists. It not only alleviates data sparsity by using variable time window, but also generates the optimal number of time windows which is automatically obtained from data. User feature vector was used instead of similarity of tourism data to select neighbors, so as to the avoid the computational difficulty caused by data sparsity. The experimental results on real tourism data indicate that the proposed method not only adapts to the characteristics of tourism data, but also improves the recommendation accuracy.
dynamic clustering; Latent Dirichlet Allocation (LDA); preference model; time penalty; feature vector
TP391; TP181
A
2017- 02- 08;
2017- 04- 10。
国家自然科学基金资助项目(U1533104);河北省自然科学基金资助项目(E2016202341);天津市自然科学基金资助项目(14JCZDJC32500);中央高校基本科研业务费资助项目(ZXH2012P009)。
肖春景(1978—),女,河北唐山人,讲师,博士研究生,主要研究方向:推荐系统、数据挖掘; 夏克文(1965—),男,湖南武冈人,教授,博士,主要研究方向:智能信息处理、数据挖掘; 乔永卫(1976—),男,山西祁县人,讲师,硕士,主要研究方向:机器学习、智能信息处理;张宇翔(1975—),男,山西大同人,副教授,博士,主要研究方向:机器学习、数据挖掘、人工智能。
1001- 9081(2017)08- 2395- 06
10.11772/j.issn.1001- 9081.2017.08.2395
