基于优化视觉词袋模型的图像分类方法
2017-10-21张永,杨浩
张 永,杨 浩
(兰州理工大学 计算机与通信学院,兰州 730050)
(*通信作者电子邮箱kdyh123@163.com)
基于优化视觉词袋模型的图像分类方法
张 永,杨 浩*
(兰州理工大学 计算机与通信学院,兰州 730050)
(*通信作者电子邮箱kdyh123@163.com)
针对视觉词袋(BOV)模型中过大的视觉词典会导致图像分类时间代价过大的问题,提出一种加权最大相关最小相似(W-MR-MS)视觉词典优化准则。首先,提取图像的尺度不变特征转换(SIFT)特征,并用K-Means算法对特征聚类生成原始视觉词典;然后,分别计算视觉单词与图像类别间的相关性,以及各视觉单词间的语义相似性,引入一个加权系数权衡两者对图像分类的重要程度;最后,基于权衡结果,删除视觉词典中与图像类别相关性弱、与视觉单词间语义相似性大的视觉单词,从而达到优化视觉词典的目的。实验结果表明,在视觉词典规模相同的情况下,所提方法的图像分类精度比传统基于K-Means算法的图像分类精度提高了5.30%;当图像分类精度相同的情况下,所提方法的时间代价比传统K-Means算法下的时间代价降低了32.18%,因此,所提方法具有较高的分类效率,适用于图像分类。
图像分类;视觉词袋模型;特征提取;视觉词典
0 引言
近几年来,人工智能领域呈现出飞速发展的势头,图像分类技术[1-4]也得到了人们的普遍关注。早期的词袋模型被用在文本分类中,通过统计文本词典中与顺序无关的单词的频率就可以对文本进行精确的分类。然而文本分类中的文本词典是可以被确定的,而基于词袋模型下的图像分类[5-7]中的视觉词典则需要通过对图像进行特征的提取,并对特征进行相应处理才能获得,不同的特征提取方法和特征处理方式会产生差异较大的视觉词典,因此,如何得到适当的视觉词典是现今研究的热点。
传统视觉词袋(Bag-Of-Visual words, BOV)模型下的图像分类性能低下,因此大量对BOV模型的优化算法[8-9]被引入到图像分类中。Kim等[10]利用信息熵的方法去除掉那些图像类别与视觉单词间信息熵较小的视觉单词,减小了视觉词典的规模;Epshtein等[11]用平均互信息的方法来计算视觉单词与图像类别间的相关性,并去除掉那些与图像类别相关性较弱的视觉单词,从而降低视觉词典的规模;Lu等[12]应用谱聚类的思想对词袋模型中的视觉词典进行降维,提高了图像分类的效率。然而以上研究对视觉词典的优化方法只考虑了视觉词典与图像类别之间的相关性,并没有考虑单视觉词之间的冗余关系。在基于BOV模型的图像分类中,视觉词典中的视觉单词具有大小和空间分布信息,规模较大的视觉词典中含有那些大小与空间分布信息相似的视觉单词,称这种关系为视觉单词间的语义相似性,而大量这种语义相似性视觉单词的出现,导致了视觉单词间的冗余性,因此去除掉那些与其他视觉单词相似性较大的视觉单词可以有效降低视觉词典的规模,提高图像分类的性能。
在优化视觉词典的过程中,不仅要考虑视觉词典与图像类别之间的相关性,还要考虑视觉词典中视觉单词之间的冗余关系,因此,本文提出了一种基于加权最大相关最小相似(Weighted-Maximal Relevance-Minimal Semantic similarity, W-MR-MS)准则的图像分类方法。首先分别计算视觉单词与图像类别间的相关性、视觉单词与视觉单词间的语义相似性;然后引入一个加权系数对两者进行加权计算,保留那些加权结果较大的视觉单词组成本文图像分类中最终的视觉词典。该方法不仅去除掉了那些与图像类别无关的噪声单词与冗余性较大的视觉单词,而且减小了视觉词典的规模。最后在两类常见数据集上的实验结果也验证了本文方法的有效性。
1 词袋模型下对图像的表示
BOV模型下视觉词典的规模对图像的分类性能具有较大影响,而基于BOV模型对图像的表示就是将图像特征一一量化到视觉词典上,即用视觉单词频率直方图来表示一幅图像,视觉单词频率直方图在这里被称为视觉词汇直方图。图1为BOV下的图像表示示意图,由图1可知,视觉词汇直方图的好坏可以决定图像分类的精度,而且视觉词汇直方图的维度大小直接影响了图像分类中的时间复杂度,因此,适当的视觉词典规模能够提升图像分类的性能。

图1 BOV模型下对图像的表示Fig. 1 Image representation of BOV model
2 W-MR-MS准则的定义
2.1 视觉单词与图像类别间的相关性
本文采用信息论中平均互信息方法[13]来计算视觉单词与图像类别间的相似性。首先定义初始视觉词典为D=[d1,d2,…,dN],D为N×K维矩阵,K=128为尺度不变特征转换(Scale Invariant Feature Transform, SIFT)描述子[14]的维数,N为视觉词典的规模。如式(1)所示:AvI(dm,c)表示视觉单词dm与图像类别之间相关性的大小,其值越大表明该视觉单词对分类越重要,所以该单词在分类过程中是该被保留的;反之,那些与图像类别相关性较小的视觉单词应该被去除掉。其中:c∈(1,2,…,C)为图像的类别,C为图像类别总数;dm=0表示在分类过程中该视觉单词没有出现在对该类别分类的视觉词典中,dm=1表示该视觉单词出现在对该类别分类的视觉词典中。
(1)
(2)
假设SIFT特征点pi={ri,ui,si,θi},其中:ri为128维特征描述子,ui为特征空间位置坐标,si为特征的尺度大小,θi为特征的主方向。为了计算视觉单词之间的语义相似性,首先定义该特征点的空间语义区域为SCRpi,而且本文认为该区域包含了pi的空间语义信息,其半径为rc×si,其中rc为语义尺度系数,用来控制空间语义区域的大小,可设置为大于1的一个常数。然后定义空间语义区域中的特征点pj对pi的影响权重dij如式(3)所示:
(3)
其中:hij的计算如式(4)所示,‖·‖2为向量的2-范数。
hij=‖ui-uj‖2/(rc×si)
(4)
在BOV模型中,每个特征点都对应着一个视觉单词,定义pj对应的视觉单词为dk。对于空间语义区域中的所有对应于视觉单词dk的特征点定义一个集合,该集合为Hk={pj|pj→dk,1≤j≤K},其中,pj→dk指SIFT点pj对应的视觉单词为dk,K为对应于视觉单词dk的特征点数量。视觉单词dk在空间语义区域中对特征点pi的影响权重如式(5)所示:
(5)
再计算视觉词典中所有视觉单词对特征点的影响权重,得到pi的空间语义信息对应的直方图如式(6)所示:
通过课题研究,教师对微课从陌生到熟悉,从制作到运用,在传统的教学中运用崭新的微课元素,提高了“Photoshop平面设计”课堂教学效益。课题组成员结合研究,勤于总结,不断反思,撰写了许多有质量的课题论文,微课作品也多次获得省市一二等奖。课题组成员王子昱老师微课作品《蓝屏抠像技术》在2016年苏州市教学大赛微课项目中获得一等奖,同时获得江苏省二等奖。陈李飞老师的微课获得江苏联合职业技术学院微课制作比赛二等奖。陈李飞老师开设市区级公开课《信息图表简历制作》,将微课等信息化教学手段灵活运用课堂,呈现了一堂生动活泼的信息化课堂,受到听课领导和老师的好评[1]。
SC(pi)=[cd1(pi),cd2(pi),…,cdn(pi),…,cdN(pi)]
(6)
接下来,对于SIFT特征点pi所对应的视觉单词dm,定义所有对应为视觉单词dm的特征点集合为Rm={pi|pi→dm,1≤i≤L},将Rm中每个SIFT点的空间语义信息看作是视觉单词dm的空间语义信息的一种表现,则可定义视觉单词dm的空间语义信息为所有Rm中SIFT点的空间语义信息的均值,如式(7)所示:
(7)
其中:|Rm|为集合Rm的规模;SC(dm)为综合利用了所有量化到dm上的SIFT特征点的空间语义信息,能够较好地表征视觉单词dm的空间语义特性。
视觉单词的空间语义信息是视觉单词空间分布信息的重要体现。对于两个视觉单词dm与dn,通过式(8)来计算其语义相似性:
sim(dm,dn)=cos(SC(dm),SC(dn))=
SC(dm)/‖SC(dm)‖2·SC(dn)/‖SC(dn)‖2
(8)
通过以上思路,可以计算出视觉单词在视觉词典中的语义相似性大小,式(9)为视觉单词dm在视觉词典中的语义相似性的计算公式:
(9)
其中:N为视觉词典规模的大小,I′(dm)为视觉单词dm的语义相似性大小。
通过分别对视觉词典中所有视觉单词的语义相似性进行计算,可以去除掉那些语义相似性较大的视觉单词。
2.3 W-MR-MS准则
结合上述内容,本节给出W-MR-MS准则的具体内容如下:结合2.1节与2.2节中选择视觉单词的方法,首先分别计算视觉单词与图像类别之间的相关性和视觉单词间的语义相似性;然后引入一个加权参数α对视觉单词与图像类别之间的相关性和视觉单词间的语义相似性进行权衡,如式(10)所示;最后去除掉使加权结果I(dm)值最小的那些视觉单词,其中,dm为视觉单词,1≤m≤N。
I(dm)=(1-α)×AvI(dm,c)-α×I′(dm)
(10)
其中0≤α≤1,α的值越小,表示视觉单词与图像类别间的相关性对优化视觉词典起到了主导作用;反之,视觉单词间的语义相似性对优化视觉词典起到主导作用。
3 基于W-MR-MS准则的BOV模型
图2为本文图像分类的系统框图,它首先提取图像的局部SIFT特征点,并对该局部特征采用K-Means聚类算法生成视觉词典;然后利用W-MR-MS准则对视觉词典进行优化,具体优化步骤如算法1所示;视觉词典优化后,基于该优化后的视觉词典对训练图像进行视觉词汇直方图的构建;最后采用词袋模型表示对每个图像类别训练出分类模型,对每幅未分类的测试图像,采用该模型可以得到其分类结果。
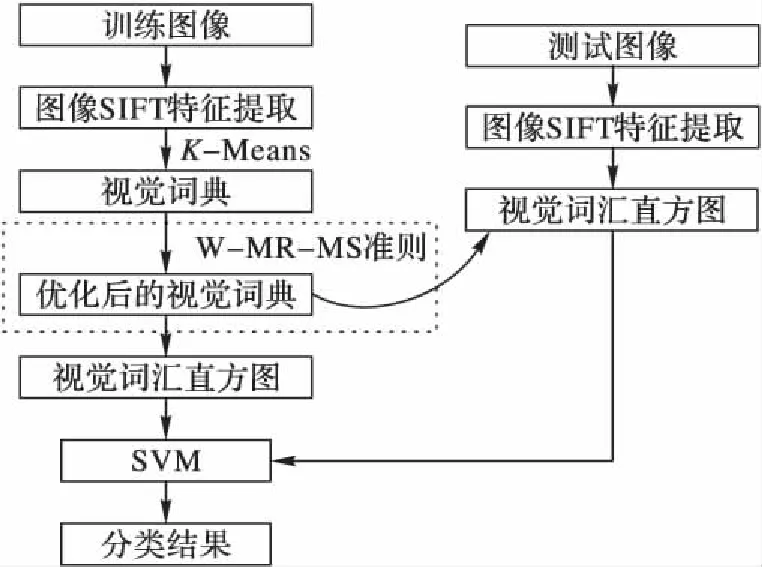
图2 基于W-MR-MS准则图像分类的系统框图Fig. 2 System diagram of image classification based on W-MR-MS criterion
算法1 视觉词典优化算法。
1)通过K-Means算法对局部特征聚类生成视觉词典D,其大小为K,本文中K=1 200。
2)用视觉词典D对训练图像进行表示与分类,得到分类精度为P。
3)用式(10)选出T个使I(dm)值最小的视觉单词,并从视觉词典中去掉这T个视觉单词,得到一个大小为K-T的视觉词典D,如果K-T大于阈值H,继续步骤2);否则,停止循环。本文中T=10,H=400。
模型训练过程中,首先通过特征提取与特征聚类可以得到一个冗余性与规模较大的视觉词典;然后利用W-MR-MS准则优化视觉词典,可以达到去冗余与降低词典规模的效果;最后基于优化视觉词典对每幅训练图像建立视觉词汇直方图,并将其作为分类器的输入。
模型测试过程中,对提取到的局部特征直接采用W-MR-MS准则优化后的视觉词典建立视觉词汇直方图,将其作为模型的输入,并得到分类结果。
4 实验结果与分析
4.1 实验设置
本文在Caltech- 101和COREL图像数据集上进行实验。在Caltech- 101数据集中,选取其中的12类图像作实验,分别为Airplanes、Face、Watch、Motorbikes、Car、Backpack、Ketch、Bonsai、Butterfly、Crab、Revolver和Sunflower,每个类别图像数目从47到800不等;COREL数据集共有10类图像,分别为African、Beach、Buildings、Buses、Dinosaurs、Elephants、Flowers、Food、Horses和Mountains,每一个类别含有100幅图像,共有1 000幅图像。实验中选取图像库中的一半图像作为训练图像,另一半作为测试图像进行实验。为了便于实验,将数据集图像大小调整到300×300像素;然后选择一对多方式下的多类支持向量机(Support Vector Machine, SVM)[15]分类器对数据集进行训练,提取SIFT特征的图像块大小为16×16像素,步长为8像素;接头使用K-Means算法对图像聚类生成视觉词典,K=1 200;最后在每个数据集上独立进行10次随机实验,并将平均分类准确率与分类时间代价作为最后判断标准。
4.2 实验结果
4.2.1 参数α对图像分类性能的影响
由于参数α对优化视觉词典具有较大影响,所以本节将讨论参数α对图像分类的影响。实验中α将在集合M={0,0.05,0.1,…,1}上取值,图3即为不同参数α下图像的平均分类精度。其中:在10类Caltech- 101数据集上,优化视觉词典规模取为910;在COREL数据集上,优化视觉词典规模取为850。由图3可知,当α=0.6时图像的分类精度最高,所以在COREL与Caltech- 101数据集上视觉单词间的语义相似性在优化视觉词典中占了主导地位。这是由于以上两种数据集中的类别数较少,所以影响了图像类别与视觉单词间的相关性对优化视觉词典的作用,而此时原始视觉词典中具有较多语义相似性较大的视觉单词,因此,W-MR-MS准则在优化视觉单词时,视觉单词间的语义相似性对优化视觉词典具有更大的作用。
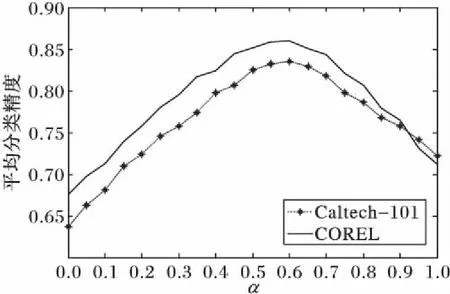
图3 参数α对图像分类性能的影响Fig. 3 Influence of α on image classification
4.2.2 视觉词典规模对图像分类性能的影响
本节将分析优化视觉词典规模对图像分类性能的影响。首先设置原始视觉词典的规模为1 200,α=0.6;然后基于W-MR-MS准则对该规模下的视觉词典进行优化。图4为在Caltech- 101与COREL数据集上视觉词典的规模与图像平均分类精度之间的关系示意图。由图4可以看出,在Caltech- 101数据集上,当视觉词典的规模被优化到910之后,图像平均分类精度会出现明显下降;而在COREL数据集上,当视觉词典的规模优化到850之后,图像分平均分类精度会出现明显下降。这是因为当视觉词典规模被缩减到一定程度时,那些对分类有用的视觉单词也会被W-MR-MS准则去除掉,这样会导致训练时对图像的表示不足,进而图像分类精度出现明显下降。所以当原始视觉词典规模取为1 200时,在Caltech- 101与COREL数据集上可优化视觉词典规模分别为910与850,而两者大小不同,主要是由于本文所取Caltech- 101数据集上的图像类别数比COREL数据集上要多,并且Caltech- 101数据集图像结构比较复杂。

图4 优化视觉词典的规模对图像分类性能的影响Fig. 4 Influence of scale of visual dictionary on image classification
4.2.3 本文方法与K-Means算法的比较
本节将比较本文方法与K-Means算法下的图像分类性能,结果如表1所示。其中,K-Means算法下视觉词典的大小直接由K值决定;而本文方法是在K-Means算法基础上,K=1 200时,用W-MR-MS准则对视觉词典进行了优化降维,最后的词典规模为优化后的大小。在Caltech- 101与COREL数据集上,本文方法的视觉词典规模分别为910与850,α的值在两类数据集上均为0.6。
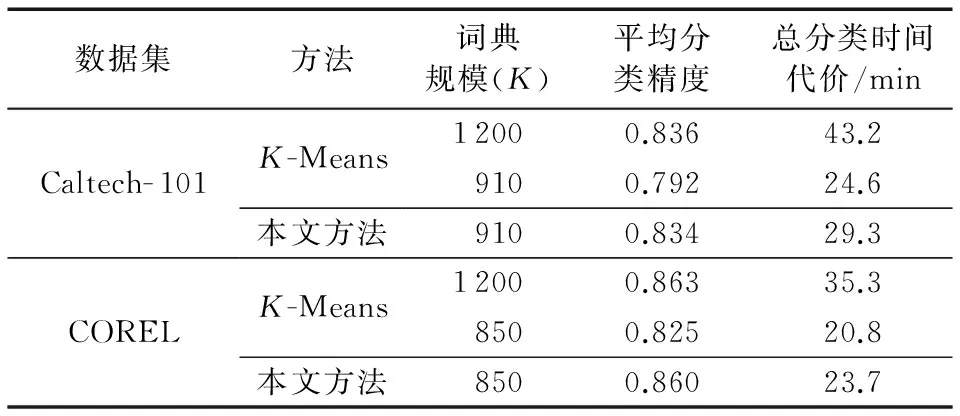
表1 两种算法在不同数据集上分类性能比较Tab. 1 Image classification performance comparison of two algorithms on different datasets
由表1可以看出,在Caltech- 101数据集上,本文方法与K-Means算法在K=1 200时的平均分类精度基本相同,但是本文方法的分类时间代价降低了32.18%;而与K-Means算法在K=910时的平均分类精度相比,本文方法的平均分类精度提高了5.30%,但是时间代价本文略高,这是由于本文优化时需要优化时间代价。在COREL数据集上的分类性能比较结果与Caltech- 101数据集的情况相似,这里不作过多的分析。
综合以上分析可知,本文方法提高了图像分类的性能。图5为本文方法在10类COREL数据集上的分类混淆矩阵,由图5可知本文方法在某些图像类别上达到了较高的分类精度,所以本文方法具有较高的有效性。

图5 本文方法在COREL数据集上的混淆矩阵Fig. 5 Confusion matrix of the proposed method on COREL dataset
5 结语
为了降低传统BOV模型下图像分类的时间复杂度,本文提出了W-MR-MS准则来优化BOV模型中的视觉词典。通过去除掉那些与图像类别无关、具有冗余的视觉单词,从而在不影响图像分类精度的前提下,降低了视觉词典的规模,提高了分类效率。在Caltech- 101和COREL图像数据集上的实验表明,本文方法比传统K-Means算法具有更好的分类性能。在以后的研究中可以在此优化视觉词典的基础上,对BOV模型作进一步改进,比如加入图像局部特征的空间分布信息、对图像预处理等,从而实现更有效的图像分类。
References)
[1] SIVIC J, ZISSERMAN A. Video Google: a text retrieval approach to object matching in videos [C]// ICCV 2003: Proceedings of the 2003 Ninth IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2003: 1470-1477.
[2] 王朔琛,汪西莉,马君亮.基于均值漂移的半监督支持向量机图像分类[J].计算机应用,2014,34(8):2399-2403.(WANG S C, WANG X L, MA J L. Semi-supervised support vector machine for image classification based on mean shift [J]. Journal of Computer Applications, 2014, 34(8): 2399-2403.)
[3] 邵忻.基于跨领域主动学习的图像分类方法[J].计算机应用,2014,34(4):1169-1171.(SHAO X. Cross-domain active learning algorithm for image classification [J]. Journal of Computer Applications, 2014, 34(4): 1169-1171.)
[4] TIMOFTE R, GOOL L V. Adaptive and weighted collaborative representations for image classification [J]. Pattern Recognition Letters, 2014, 43(1): 127-135.
[5] ALQASRAWI Y, NEAGU D, COWLING P I. Fusing integrated visual vocabularies-based bag of visual words and weighted colour moments on spatial pyramid layout for natural scene image classification [J]. Signal Image & Video Processing, 2013, 7(4): 759-775.
[6] LU Y, XIE F, LIU T, et al. No reference quality assessment for multiply-distorted images based on an improved bag-of-words model [J]. IEEE Signal Processing Letters, 2015, 22(10): 1811-1815.
[7] QU Y, WU S, LIU H, et al. Evaluation of local features and classifiers in BOW model for image classification [J]. Multimedia Tools and Applications, 2014, 70(2): 605-624.
[8] YANG X, ZHANG T, XU C. A new discriminative coding method for image classification [J]. Multimedia Systems, 2015, 21(2): 133-145.
[9] GAO S, TSANG W H, MA Y. Learning category-specific dictionary and shared dictionary for fine-grained image categorization [J]. IEEE Transactions on Image Processing, 2014, 23(2): 623-634.
[10] KIM S, KWEON I S, LEE C W. Visual categorization robust to large intra-class variations using entropy-guided codebook [C]// ICRA 2007: Proceedings of the 2007 IEEE International Conference on Robotics & Automation. Piscataway, NJ: IEEE, 2007: 3793-3798.
[11] EPSHTEIN B, ULLMAN S. Feature hierarchies for object classification [C]// ICCV 2005: Proceedings of the 2005 Tenth IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2005: 220-227.
[12] LU Z, WANG L, WEN J R. Image classification by visual bag-of-words refinement and reduction [J]. Neurocomputing, 2016, 173: 373-384.
[13] KELBERT M, SUHOV Y. Information Theory and Coding by Example [M]. Oxford: Cambridge University Press, 2013: 18-86.
[14] LOWE D G. Distinctive image features from scale-invariant keypoints [J]. International Journal of Computer Vision, 2004, 60(60): 91-110.
[15] TUIA D, VOLPI M, DALLA MURA M, et al. Automatic feature learning for spatio-spectral image classification with sparse SVM [J]. IEEE Transactions on Geoscience & Remote Sensing, 2014, 52(10): 6062-6074.
ZHANGYong, born in 1963, professor. His research interests include intelligent information processing, data mining.
YANGHao, born in 1991, M. S. candidate. His research interests include image classification, machine learning.
Imageclassificationmethodbasedonoptimizedbag-of-visualwordsmodel
ZHANG Yong, YANG Hao*
(SchoolofComputerandCommunication,LanzhouUniversityofTechnology,LanzhouGansu730050,China)
Concerning the problem that too large visual dictionary may increase the time cost of image classification in the Bag-Of-Visual words (BOV) model, a Weighted-Maximal Relevance-Minimal Semantic similarity (W-MR-MS) criterion was proposed to optimize visual dictionary. Firstly, the Scale Invariant Feature Transform (SIFT) features of images were extracted, and theK-Means algorithm was used to generate an original visual dictionary. Secondly, the correlation between visual words and image categories and semantic similarity among visual words were calculated, and a weighted parameter was introduced to measure the importance of the correlation and the semantic similarity in image classification. Finally, based on the weighing result, the visual word which correlation with image categories was weak and semantic similarity among visual words was high was removed, which achieved the purpose of optimizing the visual dictionary. The experimental results show that the classification precision of the proposed method is 5.30% higher than that of the traditionalK-Means algorithm under the same visual dictionary scale; the time cost of the proposed method is reduced by 32.18% compared with the traditionalK-Means algorithm under the same classification precision. Therefore, the proposed method has high classification efficiency and it is suitable for image classification.
image classification; Bag-Of-Visual words (BOV) model; feature extraction; visual dictionary
TP181
A
2016- 12- 13;
2017- 03- 11。
张永(1963—),男,甘肃兰州人,教授,主要研究方向:智能信息处理、数据挖掘; 杨浩(1991—),男,甘肃陇南人,硕士研究生,主要研究方向:图像分类、机器学习。
1001- 9081(2017)08- 2244- 04
10.11772/j.issn.1001- 9081.2017.08.2244
