机器学习实际应用面临的问题及解决思路
2017-10-19王晓丽
王晓丽

摘 要:随着计算机技术的发展,机器学习越来越热门且应用也愈加广泛,比如语音、图像处理等诸多方面。但是,机器学习并没有达到可以简单进行实际应用的状态,文章主要介绍机器学习实际应用面临的问题及解决思路。
关键词:机器学习 特征提取自动化 架构优化
一、引言
由于大数据时代的到来以及并行计算技术的发展,机器学习得到学术界和工业界越来越多的重视及研究。然而,机器学习在实际应用时面临的问题更加复杂多变。因此,实际应用中的机器学习平台必须是一个可以扩展的系统,该系统要能够适应数据量和用户的实时变化,实现计算水平和吞吐量的智能扩展。然而,当前的机器学习还没有达到如此智能化的水平,怎样进行模型的优化训练、怎样实现参数的有效选择、怎样将特征进行高效组合等问题都需要进一步研究解决。
二、机器学习实际应用面临的难题
1.实际应用系统架构复杂
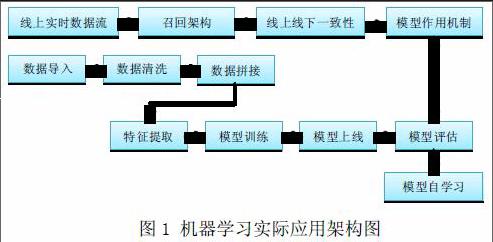
机器学习实际应用系统架构如图1所示。由图知,机器学习系统得到的数据需经过数据归集与整理、数据导入、数据清洗、数据拼接以及特征工程等之后才能进一步进行模型训练。模型训练之后得到的模型在上線时要能够保证系统工作稳定以及系统工作的时效性和吞吐量等一系列指标。与此同时,为了满足线上系统的实时性和线上线下一致性,还需要一套对应的线上系统。
2.没有成熟的人工智能平台,可迁移性差,使用门槛高
针对不同的行业,不同的企业需求又会千差万别,目前还没有成熟的机器学习平台可已满足各行各业的要求。当前应用广泛的Hadoop平台虽然本身是一个分布式系统,但其发展已相当成熟,平台的使用者不需要对分布式系统有深入的了解便可以使用该平台。然而,目前的机器学习平台则无法实现如此的智能化。当前如果要使用机器学习平台,就必须了解所有的前后组件及相关模型。并且,模型不同就需要不同的训练系统,对应的数据、框架、特征提取等一系列就会不同,处理起来尤其复杂。所以,当前机器学习平台迁移性差,使用门槛高。
三、解决思路
(一)特征提取自动化
特征提取是在某个模型下找到跟需求相关的关键属性,这也是机器学习实际应用中实现平台智能化过程中需要解决的重要难题。
本文主要介绍三种实现特征提取自动化的方法:隐式特征值组合,半显式特征值组合及显式特征值组合。
1.隐式特征值组合
隐式特征组合在语音处理和图像处理方面应用较为成功,其在处理连续特征值方面效果较好。在处理声波或者像素这些原始数据时,深度学利用神经元网络产生底层的过滤器进而产生层次化的特征值组合,其效果远超手工进行的特征提取。但是,该借助神经元网络实现的深度学习在处理高维的离散变量时复杂度会大大提高。除此之外,该方法得到的结果可解释性差,内部处理过程无法实时监督。
针对神经网络在处理离散数据时存在的问题,可以结合 Large Scale Embedding的技术加以解决。通过Embedding技术可以将单词映射到低微的空间,再通过一系列处理形成等长的底层输入,最后再用深度神经网络对模型进行训练。之后,Embedding技术在越来越多的场景中得到应用,其中,个性化推荐是一个典型的应用场景,其利用Embedding技术来实现协同过滤。
迄今为止,Large Scale Embedding技术依然是研究领域的热门,其中有一些典型的成果,比如Discrete Factorization Machine, FNN, PNN以及DeepFM等,;利用上述模型不仅可以实现特征值之间相互关系的查找,还可以记录更加细微的特征。
2.半显式特征组合
基于树的模型得到的半显示组合不仅可以实现特征值的组合,还具有一定程度的可解释性。但是由于树结构的特点,该模型还无法直接显示特征之间的相关性或特征的组合情况。该组合方式借助树模型实现,是一种非线性模型。其优点是具有较好的特征提取效果,并且相对容易理解。
3.显式特征组合
该特征组合算法借助搜索和搜索优化的思路,以及配合正则化和贪心的使用,最终利用笛卡尔积明确的将那些特征值加以组合。该方法的优点是结果的可解释性,可以通过更深入的分析知道哪些特征是有关系的,是应该组合在一起的。除此之外,该方法得到的特征值还具有可叠加性。该方法产生的特征值可以进一步应用于机器学习,利用这些显示的特征值进行模型训练。现在常用的显式特征值组合算法主要有基于Boosting的算法以及基于Regularization的算法。
下面介绍一种新型的显示特征组合算法—FG。该算法基于MCTS,对特征值以及特征值的组合情况进行建模,进一步对特征组合的收益函数进行训练。在特征值组合过程中加入调优技术,最终得到的特征值组合可以达到十阶以上,并且具有更好的效果。
下面是在两个数据集(higgs、criteoDeepFM)上对FG算法进行实验,两个数据集的信息如表1所示:
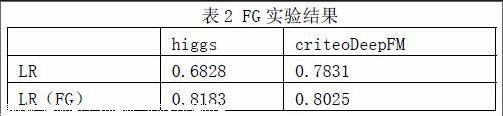
使用FG产生的特征值集,利用LR模型对这两个数据集进行训练,使用AUC作为评测指标。得到的实验结果如表2所示。
由表2知,先使用FG算法进行特征值组合之后再利用LR模型进行训练的结果比直接用LR模型训练的结果都有非常明显的提升。
(二)架构优化
近随着各类技术的飞速发展,不断涌现出新的架构实现方式。对于怎样设计出高可用性、灵活快速适应变化的、易维护的、前沿的、安全的系统架构是架构优化的目标。
没有最好的架构,只有最合适的架构。一个好的架构要综合考虑具体的需求、所具备的资源等因素。特别是当今,业务以及数据的飞速变化、无处不在等因素的影响,技术和框架也必须紧跟这些变化,不断地修正提升以适应不断变化的业务需要。endprint
四、结语
机器学习从诞生以来,理论和技术日益成熟,应用领域也不断扩大,但还不能快速的应用于实际生产之中,仍面临诸多问题。比如实际应用中如何训练出好的模型、如何去选择好的参数、如何进行特征组合等。本文介绍了解决实际应用中面临的关键问题的思路:自动化特征值工程及架构优化。通过自动化特征值工程可以自动的找出与要解决问题相关的关键属性,更加智能有效。通过架构优化可取得更高的效率。
参考文献
[1]S.Kotsiantis, Feature selection for machine learning classification problems: a recent overview[J], Artificial Intelligence Review. 2011:1-20.
[2]Q. Zhu, L. Lin, M.-L. Shyu, S.-C. Chen, Feature Selection Using Correlation and Reliability Based Scoring Metric for Video Semantic Detection[C], IEEE Fourth International Conference on Semantic Computing, 2010: 462-469.
[3]H.Ogura, H.Amano,M.Kondo, Comparison of metrics for feature selection in imbalanced text classifi- cation[J],Expert Systems with Applications. 2011, 38(5):4978-4989.
[4]Y.Saeys,I.Inza,P.Larranaga, A review of feature selection techniques in bioinformatics[J], Bioinfor- matics. 2007, 23(19):2507-2517.
[5]李國杰,程学旗. 大数据研究:未来科技及经济社会发展的重大战略领域--大数据的研究现状与科学思考.中国科学院院刊,2012,27(6),647-657endprint
