基于时间序列分析的客户项目状态篡改识别算法
2017-10-19陈超凡林书新
陈超凡,林书新
(1.海南大学 信息科学技术学院,海南 海口 570228;2.海南经贸职业技术学院 工程技术学院,海南 海口 571127)
基于时间序列分析的客户项目状态篡改识别算法
陈超凡1,林书新2
(1.海南大学 信息科学技术学院,海南 海口 570228;2.海南经贸职业技术学院 工程技术学院,海南 海口 571127)
为了解决现有客户项目状态篡改识别算法中不能自适应识别篡改类型和无法同时识别出多个项目状态遭受篡改的问题,给出了基于时间序列分析的客户项目状态篡改识别算法,即先划分系统内的评分时间序列区间段,运用 PCA VarSelect算法得出项目状态篡改可疑名单,再进一步缩小识别范围,具体方法是,根据被篡改的时间段,结合评分偏差度确定被篡改状态的项目,在此基础上进一步分析被篡改时间段内的评分,以确定篡改类型,最后识别出相应的被篡改状态的项目.仿真显示,该算法识别精度较高,不仅能识别单个项目的篡改状态,还能同时识别多个项目的篡改状态.
项目状态篡改识别;时间序列分析;PCA;识别精度
随着商业竞争的日益激烈以及推荐系统其自身存在的开放性及交互式等特点,少数客户出于自身利益的考虑,极其容易利用这些特性对推荐系统进行篡改,破坏推荐系统的公平性.其中,客户状态杜撰篡改[1]或托篡改则是最常见的一种篡改方式,篡改者通过人为地杜撰虚假的客户信息来篡改推荐系统,提高自己项目被推荐的机会或降低竞争对手项目被推荐的机会.因此,如何提高推荐系统抵御这种篡改的能力对保障系统的推荐质量至关重要.
最近几年,关于客户状态篡改识别问题受到了不少国内外研究学者的关注.Chirita等[2]最早设计出了一种篡改识别算法,提出一系列识别属性来分析少数客户中的评分信息,并识别了这些属性对不同篡改模型的识别性能,该算法在篡改状态密度大的时候识别效果较好,但是当填充规模较小或者篡改状态稀疏的情况下识别效果非常差.Lee等[3-4]进一步提出了分类识别模型,采用平均项目差异和相符权重度指标识别篡改状态,但在实际验证中对于篡改规模高的篡改状态,识别效果并不理想.Mrhta等[5]提出了基于主成分分析(PCA VarSelect)的识别算法,根据篡改状态之间的高相关性特征进行识别.该算法对于几种基本篡改模型的识别效果较好,但由于需要预先设定参数方可确定篡改客户的数量,显然,在实际应用中很难准确估计参数值,自然会影响识别精度.李聪,于洪涛等[6-7]提出了一种无监督的UnRAP篡改识别算法,在为每个客户计算Hv-score值的基础上,测算出客户状态被篡改的可疑度,再设计聚类算法识别客户状态是否被篡改,该算法用于识别一般状态项目是否被篡改效果明显,但当出现有对客户项目状态施行了流行性篡改和核篡改的情形时,识别准确率明显下降,且存在一定程度的误判,还需要提前给出篡改形式,降低了算法的实用性.近几年,融合其他领域的新方法也产生了不少篡改客户项目状态的识别方法,见文献[8-12].
本文针对目前客户状态杜撰、篡改客户状态信息的识别算法在确认精度方面存在的不足,重点针对篡改类型的识别和篡改客户状态信息的多个项目2方面进行了研究,首先,采用 PCA 识别算法替代Hv-score ,可以有效识别出具有篡改意图的客户,即可以提高对那些已经实施篡改项目的客户的识别率;其次,结合时间序列分析,巧妙地避免了UnRAP算法中需要预知道篡改类型的不足;通过分析客户所篡改项目的评分偏差及评分分布,采用多项目篡改客户识别的策略,克服了UnRAP 1次只能识别1个篡改项目的弊端.
1 入侵推荐系统类型
由于推荐系统是靠在网上获取客户经营状态的相关信息的,所以其设计原则具有开放性和互动性,这也给部分不良客户以可乘之机,为达到提高自身项目评分,或者打压降低竞争对手的同类项目评分,采用各种手段,杜撰虚假评分,以低廉的成本入侵到推荐系统中,直接导致评分结构的改变.根据入侵推荐系统的方法方式,大体可分为2类:1)以提高客户自身项目评分为目的,称为推篡改(push attack),见表1中的i1;2)以降低竞争对手同类项目评分为目的,称为核篡改(nuke attack),见表1中的i5.
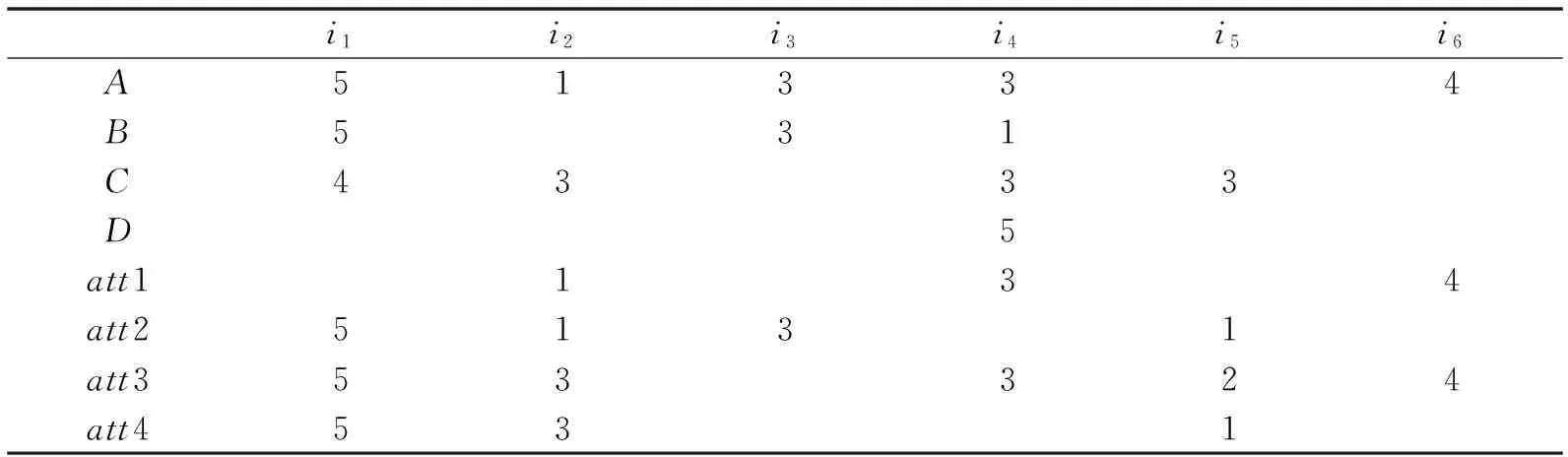
表1 客户评分矩阵Tab.1 Customer score matrix


图1 篡改状态的组成结构Fig.1 tampered state of the composition of the structure
2 识别算法与改进思路
2.1 UnRAP篡改识别算法
算法的关键是计算客户的Hv-score值,该值在一定程度上反映了篡改客户项目的可疑度,然后利用聚类算法识别篡改状态,分3个步骤完成.
1) 计算篡改客户可疑度通常用评分矩阵中客户的Hv-score值代替,以识别协同过滤推荐系统中的篡改客户状态.Hv-score值计算方法如下:
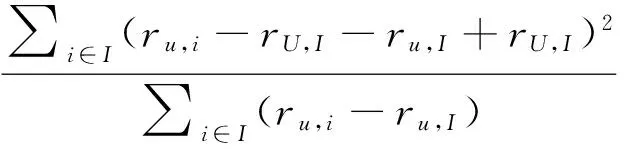
(1)
其中,客户u对项目i的评分为ru,i,rU,j表示客户u对所有项目评分的均分,项目i得到的平均分为ru,I,rU,I表示评分矩阵的平均分.
2) 计算客户项目偏离度计算篡改客户可疑度(Hv-score值)较高的客户的各个项目评分的偏离值(deviation),显然,偏离值越大,被篡改的可能性越大,项目评分的偏离值计算公式为
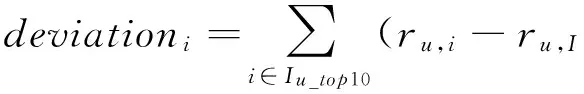
(2)
3) 确定篡改状态为确定项目篡改状态,先以可疑度前若干名的客户建立一个滑动窗口,并计算窗口中被篡改项目的偏离值,如果窗口的偏离值大于零,则属于推篡改,于是让窗口向后滑动一个客户,即去掉可疑度第一的客户,增加可疑度排名紧邻窗口更低的客户,构成新窗口,继续计算新窗口的偏离值,依此类推,直到偏离值小于等于零后窗口右端的客户为终止客户,在所有窗口中该客户可疑度最小.再从可疑度最高的客户到可疑度最小的终止客户这个窗口内,确认篡改项目的客户,很自然,如果项目评分高于窗口平均分的对应客户,就可被认定为篡改客户.运用同样的方法,从相反角度寻找核篡改客户.
UnRAP算法识别普通篡改时效果比较好,但是识别流行篡改和核篡改时效果比较差,误判情况比较严重,并且需提前获知篡改方式,大大降低了算法的实用性.
2.2 PCA VarSelect篡改识别算法
PCA VarSelect篡改识别算法是基于主成分分析方法,把客户作为变量,如果客户变量间相关性低,则说明客户正常,反之,如果客户变量间相关性高,则说明篡改项目状态的可能性高,因此,将客户变量相关度高的项目篡改状态过滤掉.
为计算客户变量的相关性,首先对客户评分矩阵做主成分分析,可获得每个客户对应的前1~3个主成分数值,以该数值作为指标,进行客户项目状态篡改的识别数值,再计算他们的间隔距离,取值最小的r个客户作为客户项目篡改状态,r为可调.
算法流程如下:
UλVT=SVD(D)
PCA1←U(∶,1)
PCA2←U(∶,2)
for all columned user in D d
Distance(user)←PCA1(user)2+PCA2(user)2
end for
sort Distance
retum r users with smallest Distance values
不足之处在于算法需要预先知道篡改项目状态的客户规模r,实际应用中该规模值难以预估,预置不准将可能影响识别精度.
综合比较上述2种算法发现各有利弊,是否可以在利用他们的优势的基础上,再设法克服其弊端?比如预估,预置不准将可能影响识别精度.
1)利用PCA VarSelect算法代替HV-score,提高识别精度;
2)增加时间序列分析,通过划分推荐系统中的时间区间,初步确认客户开始实施篡改项目状态的时间,以此缩小识别范围,再对该时间段内客户的评分矩阵进行分析,进一步确定客户篡改项目的类型.通过这个环节可以弥补UnRAP算法中需预知道客户项目篡改类型的不足;
3)为实现对多个项目的篡改状态同时进行识别,在分析被篡改项目评分偏差的基础上,再分析评分的分布.
3 改进的篡改项目状态识别算法
客户篡改项目状态常带有急功近利心态,就是希望经过短时间的篡改,使得项目状态表现的评分值直线提高.这就需要在有限时间段内,篡改量要达到一定规模,否则,对项目在推荐系统中的推荐名次与影响势必达不到期望目标.特别是篡改客户在篡改项目状态的初期,或者一段时间内,没有能改变在推荐系统中的排名,那么这段时间的努力将会随着时间逐渐被淹没甚至消失.因此,篡改客户需要在一段时间加大篡改项目状态的力度,以保持篡改后项目状态变化处于上升态势,并具有连续性和紧密性,这就是说,急功近利篡改项目状态的心态会导致再短时间内项目状态评分会有一个突变并持续上升.因此,可以通过对时间序列进行的分区,分析每个时间区域的客户项目评分变化特征,以减小计算量并提高识别精度.
具体按照以下步骤操作.
1)确定客户项目篡改时间段
首先是确定时间序列,时间序列的起始时间自然定为推荐系统开始获取客户数据的某个时间,然后按照给定的时间长度分割时间序列,技巧在于使得时间分割点的间距尽可能的小,再运用UnRAP算法筛选出被篡改项目的可疑客户,最后选取被篡改项目的前10%的可疑客户,依次计算出这些客户在每个时间段篡改项目的评分与正常评分的偏离值,把评分偏离值最大的时间段对应的区间作为项目状态篡改的区间段.这样明显缩小了可疑篡改项目状态客户的范围.计算方法如下:
(3)

2)确定项目篡改类型与对应的篡改客户集
运用前述方法选定的项目篡改时间段有一个显著的特征,就是在该时间段内,推荐系统中存在较多的项目状态篡改评分,所以该时间段内的客户项目状态评分与其他时间段内的客户项目状态评分会有较大的偏差,利用这个时间段客户评分偏差的特征,可进一步确定项目状态篡改类型.在项目篡改时间段内如果某客户项目状态的评分,大于所有客户项目状态评分的平均值3分及以上的,则可认定该项目状态可能被推篡改,反之则可认为是遭到核篡改.
篡改类型确定了之后,可以通过所有客户项目状态评分的平均值确定篡改可疑客户集合.对于被推篡改类型,该时间段内,凡是项目评分大于或等于所有客户项目状态均评分的客户,均可认定为被推篡改客户;反之,项目评分值小于所有客户项目状态均评分的客户,可被认定为核篡改客户.
3)对项目状态篡改客户进行进一步筛选确认
通过前述2个步骤获得了篡改可疑客户集合,对于被推篡改类型,可疑客户集合中每个项目的评分均大于或等于所有客户项目状态评分的平均值,以此均作为可疑篡改客户难免会出错,为此,为了进一步提高识别精度,求可疑篡改客户集与识别到的篡改客户集的交集,筛选一部分被误判的正常客户
C=A∩B,
(4)
其中,A表示运用时间序列分析算法筛选出来的全部篡改客户集,B为基于时间段区间筛选出的可疑篡改客户集.C为给定时间段对应区间内项目状态篡改客户集.
4 多个项目状态篡改的识别
客户项目状态篡改识别算法是针对单一同类项目的,但客户经营项目往往是多个,此时,客户篡改项目状态也必定是多个项目同时进行篡改.但是,到目前为止,针对多个项目状态同时受到篡改的问题还未见有相关成果.虽然UnRAP算法通过分析可疑篡改客户对项目状态的评分分布,但由于该方法是将最大评分偏离值作为状态篡改项目,即1次只能筛选出1个被篡改的项目,如果有多个项目被篡改,则需在去掉筛选出的项目后,再重复前面的算法,显然,计算量明显增加.
为此,考虑设置一个阈值,将最大评分偏离值,改为评分偏离值超过给定阈值,则对应考察的项目就可以是多个.
多个项目状态篡改的识别想法并不复杂,这里不详细描述.
考虑同时篡改3个项目状态的篡改模型,如图2所示,利用公式(2)可求得项目偏离值的分布图,仔细观察不难发现,正常项目状态变化不是很大,与平均值的差距处在较低的区间,而项目状态受到篡改的基本上都与正常项目具有较大的偏离值.
不过,因为涉及的项目多,超过设定阈值的偏离度也不一样,为便于统一比较,需要利用下式(5)对偏离值进行归一化处理:

(5)
其中D集合为项目的偏离值,D(i)则表示项目i的偏离值,HE则为归一化后的偏离值集合.
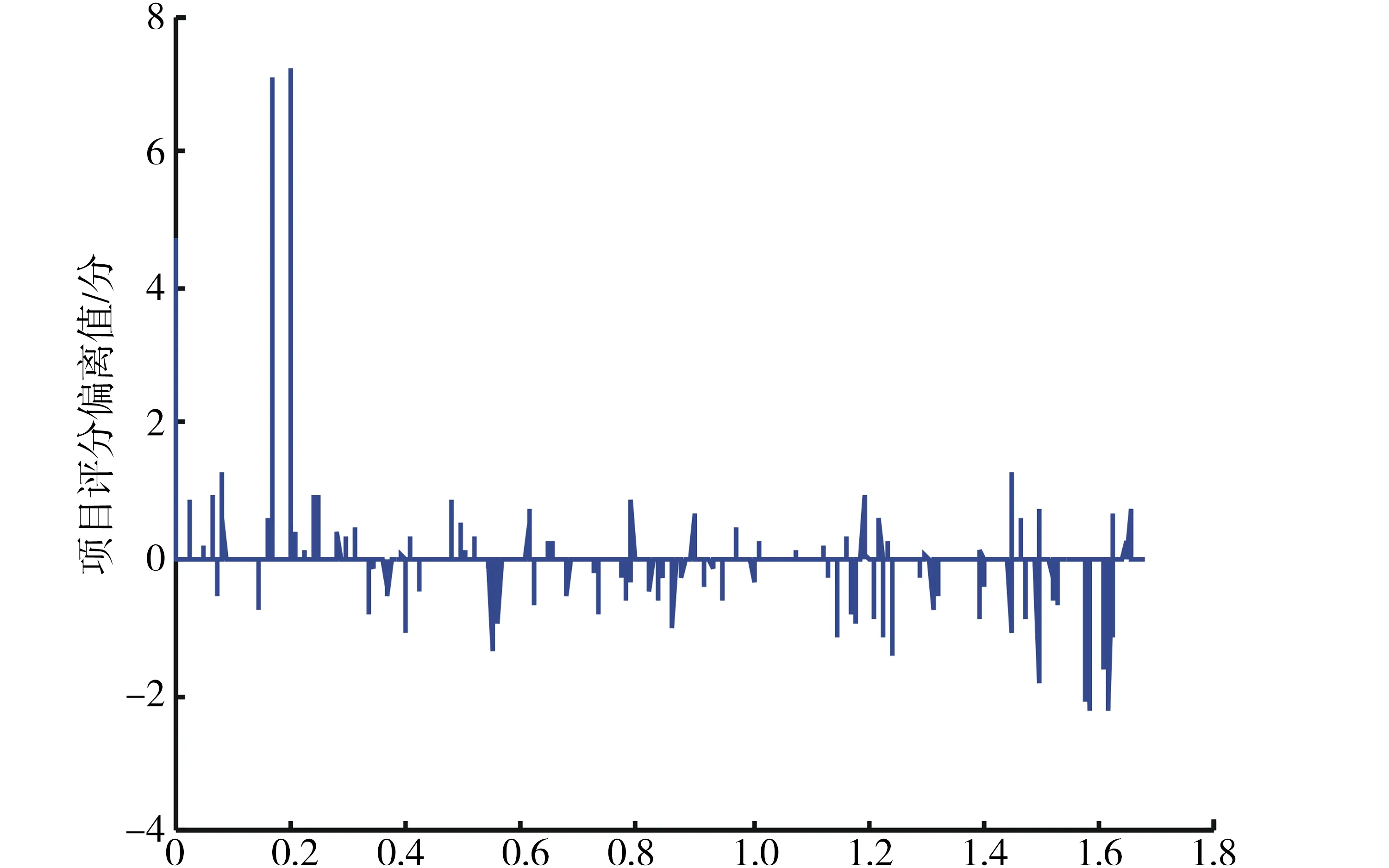
项目ID/103图2 项目偏离值分布Fig.2 Project deviation value map
随后,设置一个适当的阈值,以确定项目状态被篡改的客户名单和数量,仍运用基于时间序列分析的项目状态篡改识别算法,计算每个客户对应的篡改项目状态,最后对每个相应篡改项目状态的篡改客户取交集,筛选掉重复的客户,最终确定篡改客户状态,如图3所示.
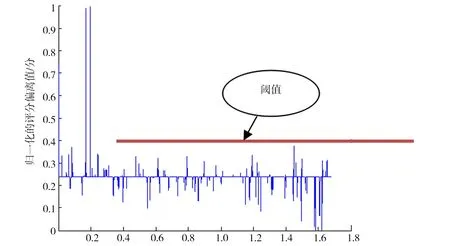
项目ID/103图3 变换后的偏离值分布Fig.3 Transformed deviation value map
算法流程见图4.
5 实验分析
5.1 数据集
采用Movie lens网站(http://movilens.umn.edu/)提供的一组客户评价项目状态的数据,数据涉及到900多个客户,1 600多个项目,评分数据更是高达10万条,数据显示,客户对项目状态评价的活跃度也较高.通常客户评分采用五级制,分别记为1、2、3、4、5分,分值越大表示客户对项目的评价越高.
5.2 评判标准
为便于统一比较,采用如下评判标准:
1)对于篡改项目项的识别,采用识别率Ti和误判率Fi作为评价指标.其计算公式为
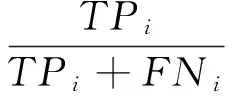
其中,TPi表示正确识别的项目总数,FNi表示未被识别的项目总数.
2)采用准确率Pu与召回率Ru作为识别项目状态是否被篡改的评价指标


其中,TPu表准确筛选出被篡改状态的总数,FGu表本属正常客户,却被筛选为篡改状态的客户数,FPu表没有被筛选出的篡改状态客户数.
5.3 实验比较
为比较算法的性能,使得实验具有一定的真实性,采用3种篡改模型生成不同的篡改项目状态,3种项目状态篡改模型分别用均值篡改、随机篡改、流行篡改方法获得.
5.3.1 1个项目状态的篡改筛选分析
仅选取1个项目的状态作为篡改对象,分别按照1%、2%、5%、7%、9%、10%的项目状态篡改规模生成篡改项目状态.
具体实验过程中,先随机抽取20个项目作为篡改状态的项目,对每个项目重复10次实验,10次实验的平均值作为项目状态的篡改识别结果.
从3种篡改模型识别精确度比较图5可以看出,T-UnRAP算法识别精度比UnRAP算法要高,特别地,当项目状态是受到核篡改,或流行篡改时,筛选准确率也较高,不仅如此,算法还具有一定的自适应能力,即可以自动识别篡改项目状态的类型.
5.3.2 多项目的篡改状态识别
选取篡改项目群的项目个数分别为1、3、5、10,填充规模为1%,篡改规模为1%、2%、5%、10%.识别率为对项目的识别度的识别结果评价,精确度和召回率是对相应的篡改状态的识别结果评价.仍然采用先随机抽取若干项目作为篡改状态的项目,对每个项目重复10次实验,10次实验的平均值作为项目状态的篡改识别结果.
从表2、表3、表4可以看出,无论项目状态的篡改模型,篡改类型,和篡改规模如何改变,对项目状态是否被篡的识别率均较高,且准确度都在90%以上,召回率有时甚至达到99%.
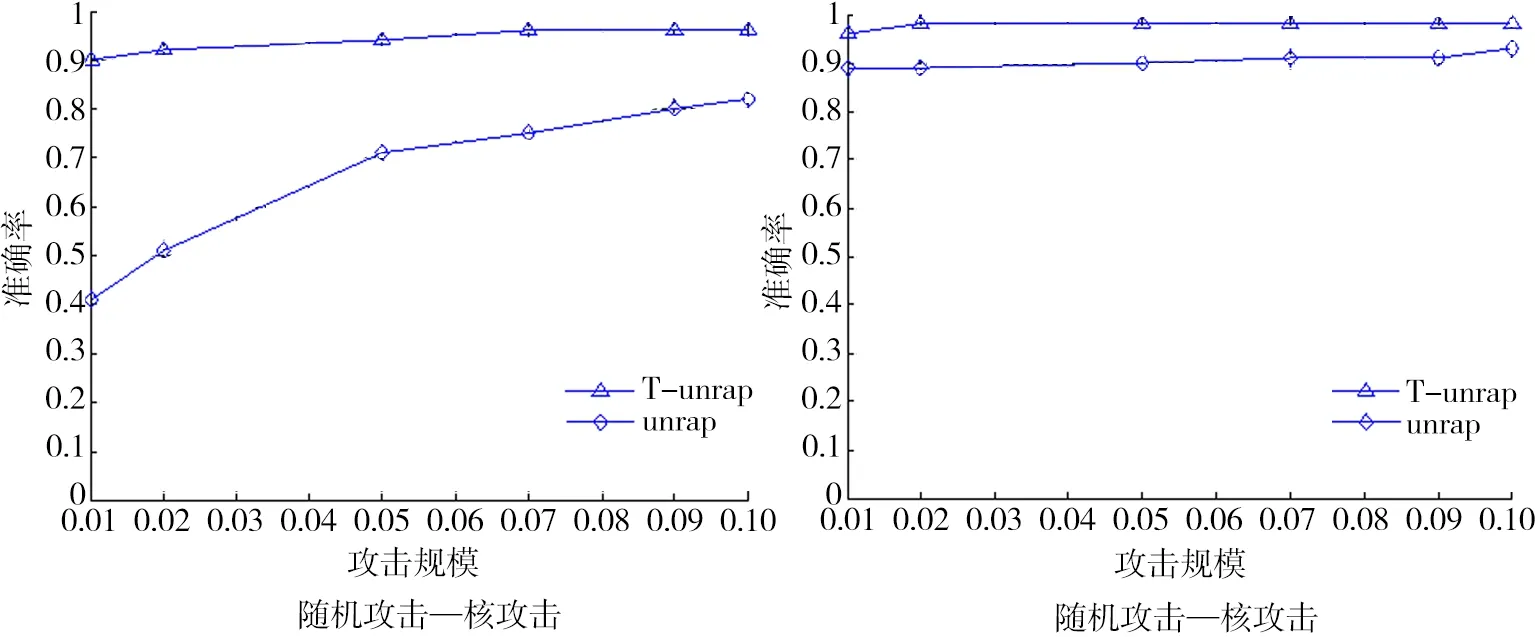

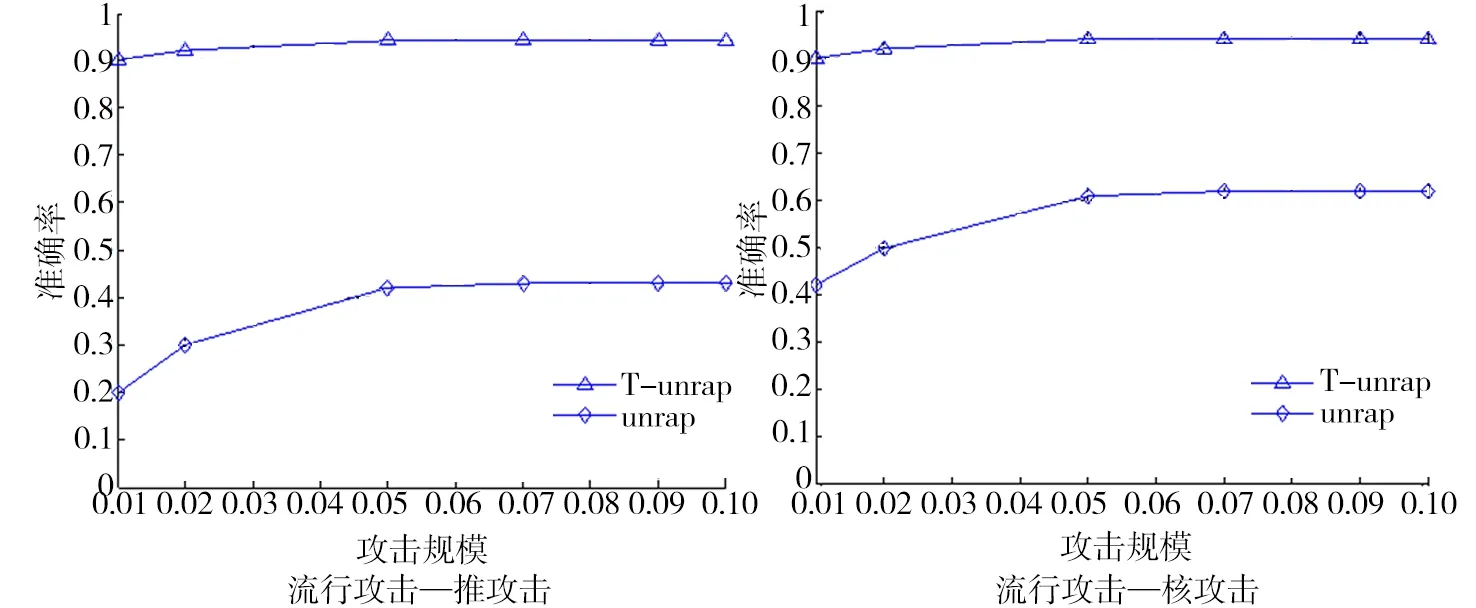
图5 3种篡改模型识别精确度比较Fig.5 Comparison of three tampering model recognition accuracy
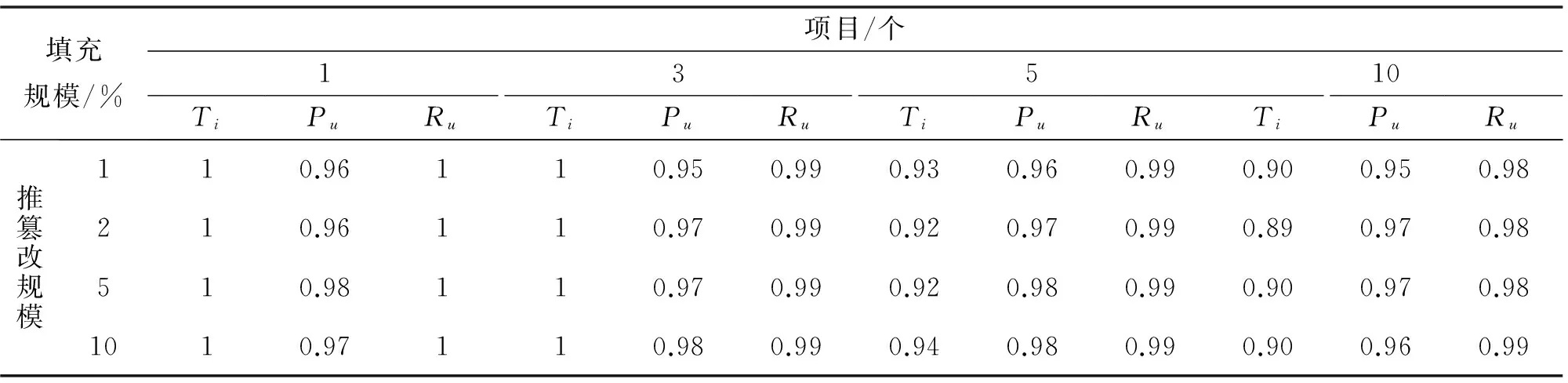
表2 不同项目个数和篡改规模的随机篡改模型的筛选准确率Tab.2 Number of different projects and tampering the size of the random tampering model of the screening accuracy
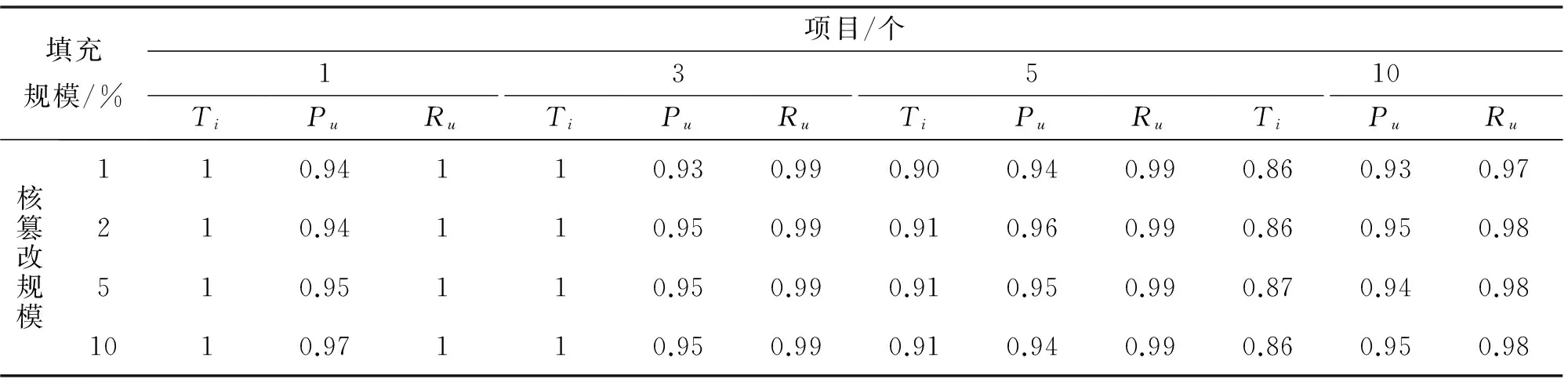
续表2Continued Tab.2

表3 不同项目个数和篡改规模的均值篡改模型的筛选准确率Tab.3 Number of different projects and tampering the scale of the mean tampering model of the screening accuracy

表4 不同项目个数和篡改规模的流行篡改模型的筛选准确率Tab.4 Number of different projects and tampering the scale of the popular tampering model screening accuracy
6 结论
准确识别客户项目状态是否被篡改是推荐系统安全性的一个热点研究方向.本文在流行篡改客户项目状态识别算法的基础之上,融入时间序列分析方法,利用客户评分分布的差异性与时间序列的关联关系,实现自动识别项目状态篡改类型,改进后的项目状态篡改算法不仅识别准确率和召回率都有明显提高,且对多项目及其所对应的项目状态篡改也可以进行有效的识别.
[1] BURKE R,MOBASHER B,WILLIAMs C,et al.Classification features for attack detection in collaborative recommender Systems[C]//Proceedings of the 12th ACM SIGKDD International Conference,ACM Press,2006:542-547.
[2] CHIRITA P A,NEJDL W,ZAMFIR C.Preventing shilling attacks in online recommender systems[C]//Proceedings of The 7th annual ACM international workshop on Web information and data management,ACM Press,2005:67-74.
[3] LEE J S,ZHU D.Shilling attack detection-A new approach for a trustworthy recommender system[J].Informs Journal on Computing,2011,3(10): 1-15.
[4] SHI Z W,YANG S,JIANG Z G,et al.Hyperspectral target detection using regularized high-order matched filter[J].Optical Engineering,2011,50(5):057201-1-057201-10.
[5] MRHTA B,HOFMANN T,FANKHAUSER P.Lies and propaganda: detecting spam users in collaborative filtering[C]//Proceedings of The 12th international Conference on Intelligentuer Interfaces,ACM Press,2007:14-21.
[6] 李聪,骆志刚,石金龙.一种探测推荐系统托篡改的无监督算法[J].自动化学报,2013.39(10):1681-1690.DOI:10.3724/sp.J.1004.2013.01681.
LI C,LUO Z G,SHI J L.Detecting shilling attacks in recommender systems based on Non-random-missing Mechanism [J].ACTA AUTOAMTICA SINICA,2013.39(10):1681-1690.DOI:10.3724/sp.J..1004.2013.01681.
[7] 于洪涛,魏莎,张付志,等.基于多项目项目检索的无监督客户状态篡改识别算法[J].小型微型计算机系统,2013,34(9):2120-2124.DOI:10.3969/j.issn.1000-1220.2013.09.031.
YU H T,WEI S,ZHANG F Z ,et al.An unsupervised algorithm for detecting user profile attack based on multi-target items retrieval[J].Journal of Chinese Computer Systems,2013,34(9):2120-2124.DOI:10.3969/j.issn.1000-1220.2013.09.031.
[8] TAN Z,JAMDAGNI A,HE X,et al.A system for denial-of-service attack detection based on multivariate correlation analysis[J].Parallel and Distributed Systems IEEE Transactions on,2014,25(2):447-456.
[9] DACER M C,KARGL F,KONIGH,et al.Network attack detection and defense:securing industrial control systems for critical infrastructures(Dagstuhl Seminar 14292)[J].Dagstuhl Report,2014,4(7):62-79.
[10] 于洪涛,李鹏,张付志.基于多维风险因子的推荐篡改识别方法[J].小型微型计算机系统,2015,36(5):971-975.
YU H T,LI P,ZHANG F Z.Method for detecting recommendation attack based on multiple risk factors [J].Journal of Chinese Computer Systems,2015,36(5):971-975.
[11] 郝志峰,牛晓龙,蔡瑞初,等.融合信息熵与信任机制的防篡改推荐算法研究[J].计算机应用与软件,2015,32(3):284-288.DOI:3969/j.issn.1000-386x.2015.03.067.
HAO Z F,NIU X L,CAI R C,et al.Research compiter applications and sortware anti-attack recommendation algorithm with fusion of information entropy and trust mechanism[J].Computer Application and Software,2015,32(3):284-288.DOI:3969/j.issn.1000-386x.2015.03.067.
[12] 岳猛,吴志军,姜军.云计算中基于可用带宽欧式距离的LDoS篡改识别方法[J].山东大学学报(理学版),2016,51(9):92-100.DOI:10.6040/j.issn.1671-9352.3.20.090.
YUE M,WU Z J,JIANG J.An approach of detecting LDOS attacks based on the euclidean distance of available bandwidth in cloud computing[J].Journal of Shandong Universty(Natural Science),2016,51(9):92-100.DOI:10.6040/j.issn.1671-9352.3.20.090.
(责任编辑:孟素兰)
Customerprojectstatustamperingalgorithmbasedontimeseriesanalysis
CHENChaofan1,LINShuxin2
(1.College of Information Science and Technology,Hainan University,Haikou 570228,China;2.Collegeof Engineering and Technology,Hainan College of Economics and Business,Haikou 571127,China)
The existing customer project status recognition algorithm can not adaptively identify the tampering type and can not simultaneously identify the tampering of multiple project states,the algorithm of tampering recognition based on time series analysis is given.The PCA VarSelect algorithm is used to derive the suspicious list of project status and further reduce the recognition range.The method is to determine the tampering state according to the tampering time period and the score deviation degree.On this basis,this method can further analyze the tampering period of time to determine the type of tampering and finally identify the corresponding tampered state of the project.Simulation shows that the algorithm has high recognition accuracy.It not only can identify the tampering state of a single project,but also can identify the tampering state of multiple projects at the same time.
project status tampering algorithm;time series analysis;PCA;recognition accuracy
TP391
A
1000-1565(2017)05-0545-10
10.3969/j.issn.1000-1565.2017.05.015
2016-12-01
国家自然科学基金资助项目(71361008)
陈超凡 (1993—),男,江苏南京人,海南大学在读硕士研究生,主要从事算法理论与软件工程研究.E-mail:75181146@qq.com
林书新(1973—),男,海南海口人,海南经贸职业技术学院副教授,主要从事算法理论与计算机应用研究.E-mail:38860058@qq.com
