基于可见/近红外光谱技术的湄潭翠芽等级判别
2017-10-19彭清维刘芸于建成魏晓楠唐延林
彭清维,刘芸,于建成,魏晓楠,唐延林
贵州大学物理学院,贵州 贵阳 550025
基于可见/近红外光谱技术的湄潭翠芽等级判别
彭清维,刘芸,于建成,魏晓楠,唐延林*
贵州大学物理学院,贵州 贵阳 550025
以湄潭翠芽为研究对象,利用可见/近红外光谱技术对其等级进行判别。首先利用卷积平滑、多元散射校正、标准正态变量变换、一阶导数法、二阶导数法、去趋势法等预处理方法对样本原始光谱数据进行处理。然后基于不同光谱预处理方法和原始光谱建立偏最小二乘回归模型,研究分析不同光谱预处理方法对模型的影响,结果表明,使用卷积平滑预处理方法的模型效果最好。然后,研究分别采用逐步回归分析、连续投影算法和竞争性自适应重加权算法3种特征波长选择方法,对卷积平滑预处理后的光谱数据进行特征波长的筛选,以基于不同特征波长选择算法筛选的特征波长和原始全波段数据进行偏最小二乘回归模型建模。结果表明,基于竞争性自适应重加权算法方法筛选的特征波长建立的模型预测效果最好,模型的预测集相关系数达到0.9739,均方根误差为0.2250,这可为湄潭翠芽等级的快速判别提供理论依据。
可见/近红外光谱;湄潭翠芽;等级;竞争性自适应重加权算法;偏最小二乘回归
研究表明,茶叶中含有许多有机化学成分、无机矿质元素、营养成分和药效成分,具有提神醒脑、降压降脂、防癌抗癌、延缓衰老、缓解核辐射损伤等众多保健和药理作用[1]。然而目前市场上商品茶质量等级混乱、售价模糊、虚标等级、以次充好的现象时有发生[2]。因此,如何区分茶叶等级已经成为消费者普遍关注的一个重要问题。目前,虽然国家有绿茶质量的标准 GB/T 14456.1—2008,从感官、理化指标、卫生指标 3个方面提出具体要求,但对于绿茶等级的划分大多是通过人为感官审评的方法来定级,这种识别方法往往受审评人员个体、经验等主观因素影响,专业性要求高,且容易产生误差,无法做到真正的标准化和客观化[3-4]。因此,如何快速、准确地对茶叶等级进行区分具有重要的理论意义和实践价值。
可见/近红外光谱作为近些年发展起来的一种快速无损检测技术,具有分析简便快速、成本低、样本无损和多组分同时测定的优点,还能充分利用全波段或多波段的光谱数据进行定性和定量分析[5],在国内外已广泛应用于食品、农产品、饲料等品质分析检测中[6-9]。马世榜等[10]通过建立线性判别分类模型,利用光谱技术成功对牛肉嫩度进行判别;朱红艳等[11]利用可见/近红外光谱技术结合便携式光纤探针对藻种类别进行鉴别,并建立了不同的藻种判别分析模型;王一丁等[12]通过对烤烟品种的可见光/近红外光谱进行研究,建立了烤烟品种鉴别的偏最小二乘模型;梁奇峰等[13]利用红外光谱多级鉴别不同种类的茶叶,但利用可见/近红外光谱技术进行贵州绿茶等级的研究还较少。本文在前人研究的基础上,利用可见/近红外光谱技术对不同等级湄潭翠芽进行判别,通过比较不同的预处理方法和特征波长选择方法建模的效果,选择最佳的翠芽等级判别模型,提高模型的预测精度,为湄潭翠芽等级的快速、无损判别提供一种新的方法,同时也为便携式茶叶等级判别仪器的开发提供理论依据。
1 材料与方法
1.1 实验仪器及参数设置
Avantes公司产AvaSpec-2408标准型光纤光谱仪,测定范围350~1 100 nm,光谱采样间隔为 4 cm-1,扫描次数为 10次,探头视场角为15°。微型植物粉碎机,天津市泰斯特仪器有限公司生产。
1.2 样品制备及光谱采集
5个不同等级的湄潭翠芽购自贵州省湄潭县盛兴茶叶公司,分别为一级(C1)、二级(C2)、三级(C3)、四级(C4)和高级(C5)茶样。将茶叶样本用微型植物粉碎机粉碎,然后盛放在直径 2.2 cm,高 0.4 cm的黑色培养皿中。为了使实验误差最小化,每次测量前都需进行白校正,实验中被测茶叶样本与探头间距离固定为2.6 cm,然后利用光谱仪依次进行采集所有翠芽样本。实验样本按3∶1的比例分为校正集和预测集(表1)。
1.3 偏最小二乘回归
偏最小二乘回归(PLSR)是一种新型的多元统计数据分析方法,为多因变量对自变量的回归建模方法。与其他传统多元线性回归模型相比,它不仅同时具有主成分分析、典型相关分析、多元线性回归分析方法的优点,且又有其自身独特的优势。不仅能在自变量存在严重相关性的条件下进行回归建模,还能在样本点个数少于自变量个数的条件下进行回归建模。除此之外,PLSR回归模型包含所有的自变量,更易于辨别系统信息和噪声,且更容易对每一个自变量的回归系数进行解释[14]。利用PLSR建立的回归模型如式(1)所示[15]。


表1 实验样本Table 1 The experimental samples
式中,Y为因变量矩阵(N×1,N表示样本数目),X为自变量矩阵(N×M,M表示波段数目),β为PLSR模型中的回归系数矩阵(M×1),η为PLSR模型中引入的残差矩阵(N×1)。
本文利用以下参数对模型预测效果进行评价:校正集相关系数、预测集相关系数、校正集均方根误差RMSEC(Root mean square error for calibration, RMSEC)、预测集均方根误差RMSEP(Root mean square error for prediction, RMSEP)。其中相关系数越大,均方根误差越小,模型预测性能越好。
2 结果与分析
2.1 不同等级的翠芽可见/近红外光谱特征
由于受到外部环境因素以及实验设备硬件的影响,光谱数据在350~400 nm和1 000~1 100 nm之间存在较大噪声,为了减少噪声对试验的影响,本文将噪声波段予以剔除,最终采用的波长范围为400~1 000 nm。5个不同等级的翠芽可见/近红外光谱曲线如图1所示。由图可知,不同等级的翠芽原始光谱曲线基本相似,没有明显的区别,即没有随着翠芽等级的变化而呈现出规律性的变化,难以通过原始光谱将各个等级的翠芽区分开。因此需要对光谱数据进行分析处理,从而建立翠芽等级的判别模型。

图1 5个不同等级的翠芽可见/红外光谱曲线Fig. 1 The visible near infrared spectrum curves of five different grades of Meitan cuiya
2.2 不同预处理PLSR建模比较
光谱数据主要受电噪音、光散射、基线漂移、光程变化等因素干扰[16]。本文采用 6种不同的预处理方法分别对原始光谱数据进行预处理。通过建立不同预处理下的PLSR模型来选择最佳的预处理方法,不同预处理方法建模结果如表2所示。由表可知,采用 SG smoothing预处理的模型效果最佳,其预测集决定系数最高,为0.9565,均方根误差(RMSEP)最低,为 0.2958。因此后续所用到的光谱数据建模均采用SG Smoothing预处理的数据。

表2 不同预处理PLSR建模Table 2 The PLSR model with different pretreatments
2.3 特征波长的提取
2.3.1 基于逐步回归分析的特征波长选择
逐步回归分析法(SWR)是一种有效的特征波长提取方法,其首先通过选择部分敏感波长以建立回归方程,对回归方程中每个波长进行检验,看是否对因变量影响显著,若不显著则剔除。当回归方程中包含的所有波长都对因变量显著时才考虑引入新的波长变量,检验其显著性,若显著则引入方程,不显著则不引入。直到最后再没有显著变量可以引入,也没有不显著变量需要剔除为止[17]。
本文利用SPSS软件对光谱数据进行逐步回归分析的特征波长选择,最终选取出最佳的 14个特征波长:400.886、401.475、402.654、403.244、404.423、405.012、406.191、406.780、408.548、419.147、455.560、502.328、673.744、769.103 nm。
2.3.2 基于连续投影算法的特征波长选择
连续投影算法(SPA)是通过在数据矩阵中确定最低限度冗余信息的变量组,使得变量之间的共线性最小,从而达到利用少数几列原始数据就能够概括绝大部分样本的光谱信息的目的,最大程度地减少了信息重叠[18]。
本实验通过自编MATLAB连续投影算法程序来筛选光谱数据的特征波长。将预处理后的光谱数据通过 SPA进行降维,根据压缩后的交叉验证均方根误差来确定光谱特征波长的个数,最终确定的变量数如图2所示。由图可知,最终选取了5个特征波长,图中白色方块表示筛选特征波长位置,分别为 625.623、693.708、722.707、953.404、997.753 nm。与原始光谱波段总数(1057个波段)相比,波段总数减少了99.53%,大大简化了模型。
2.3.3 基于竞争性自适应重加权算法的特征波长选择
竞争性自适应重加权算法(CARS)是一种借助蒙特卡洛采样与 PLS模型回归系数的特征波长选择方法。CARS算法中,每次通过自适应加权采样保留 PLS模型中回归系数绝对值权值较大的点作为新的子集,同时去掉权值较小的点,然后基于新的子集建立 PLS模型,经过多次计算,最后选择 PLS模型交互验证均方根误差(RMSECV)最小的子集中的波长作为特征波长[19]。

图2 SPA提取特征波长图Fig. 2 The characteristic wavelength extracted by SPA
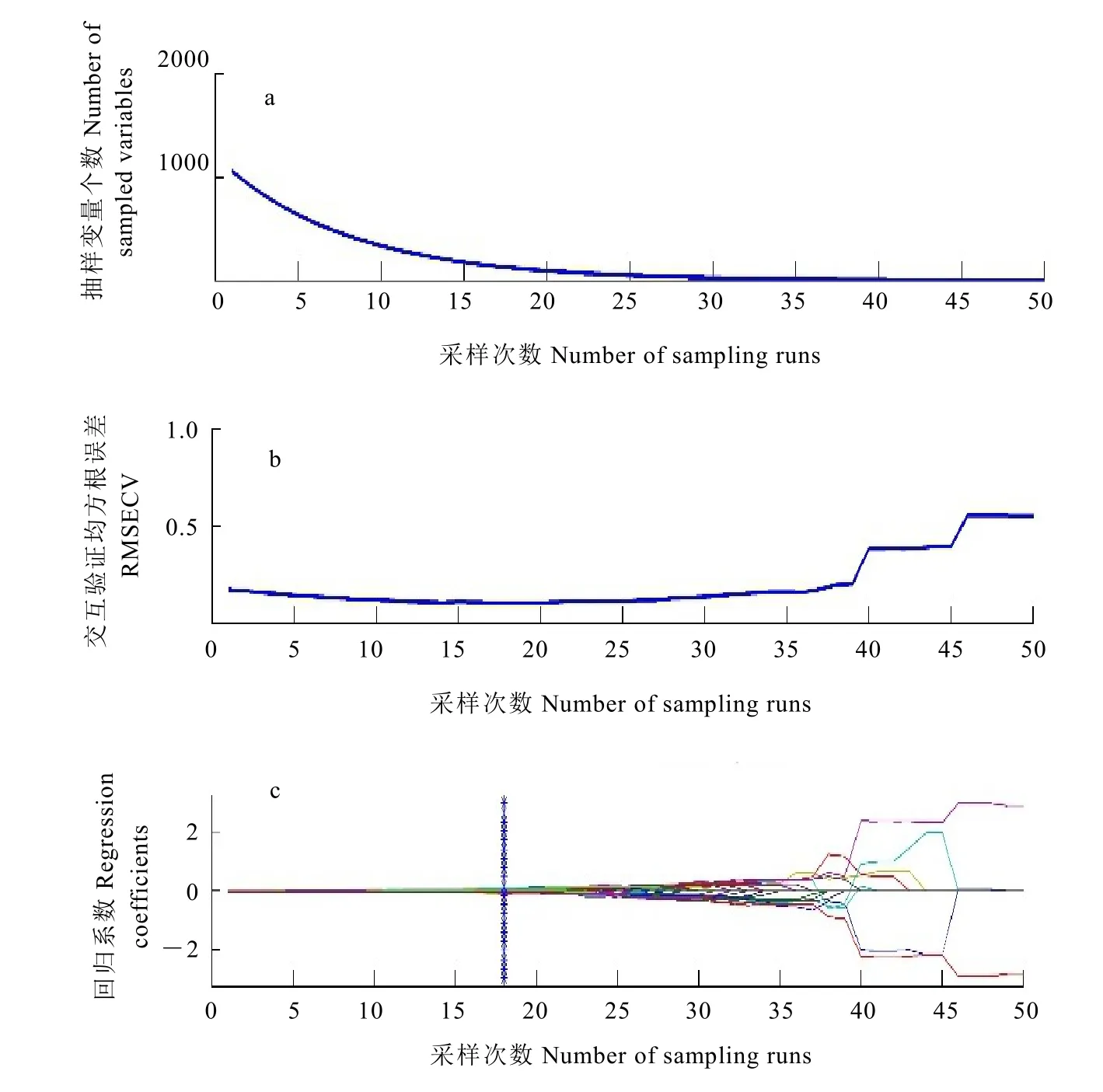
图3 CARS提取特征波长图Fig. 3 The characteristic wavelength extracted by CARS
通过MATLAB自编CARS程序提取特征波长,图3为CARS提取特征波长变量的过程。图3-a为筛选波长变量过程中被选中波长变量个数的变化趋势,由图可知,随着采样次数的增加,被选中波长变量的数量由快到慢逐渐下降,体现了波长变量粗选和精选两个过程。图3-b为波长变量筛选过程中RMSECV的变化趋势,可以看出从1~18次采样过程中,RMSECV的值不断减小,表明在筛选过程中剔除的变量与翠芽等级无关;而18次采样之后RMSECV值逐渐变大,表明筛选过程中开始剔除与翠芽等级相关的重要变量,最终导致 RMSECV值升高。图3-c为波长变量筛选过程中各波长变量回归系数的变化趋势,“*”对应的位置为RMSECV最小值即18次采样。根据RMSECV最小原则,最终选择的波长变量数为120个。
2.4 基于特征波长的建模结果比较
实验对基于SWR、SPA和CARS算法选择的特征波长数据和全波段数据进行 PLSR建模,结果如表3所示。由表可知,3种特征波长选择方法的波段数均较原始波段数大大减少,降低了模型的复杂度,且预测效果都较佳,预测集相关系数都达到 0.93以上。其中基于SPA和CARS两种特征波长选择方法的建模效果都要优于原始波长,尤其是基于CARS特征波长建模的模型效果最佳,预测集的相关系数达到 0.9739,均方根误差为0.2250。预测集预测结果如表4所示,由表可知,50个预测样本的相对偏差都小于0.5,说明此方法对于茶叶等级具有很好的鉴别能力。

表3 不同特征波长选择方法PLSR建模Table 3 The PLSR model of different selection methods of characteristic wavelength

表4 PLSR模型预测集的预测结果Table 4 Prediction results of PLSR model
3 结论
利用 AvaSpec-2408标准型光纤光谱仪获得 5个不同等级湄潭翠芽的可见光/近红外光谱数据,采用6种不同的预处理方法对原始光谱数据进行处理,然后用基于 SWR、SPA、CARS 3种特征波长选择方法对预处理后的光谱数据进行降维,讨论了基于3种不同特征波长和全波段数据的4种翠芽等级判别模型。对比4种模型建模结果,得出4种模型都取得了很好的预测效果,预测集相关系数均达到0.93以上。其中CARS-PLSR模型预测效果最佳,因此可以将其作为对翠芽等级判别的预测模型。结果表明,利用可见光/近红外光谱技术能够快速、准确、无损地对湄潭翠芽等级进行区分。
[1]张建海, 冯彬彬. 茶叶主要药效成分的药理作用及应用[J].宁夏农林科技, 2012, 53(1): 84-85.
[2]程敏. 茶叶检测中近远红外分析技术研究进展[J]. 现代食品, 2016(22): 48-49.
[3]黄继轸. 论茶叶品质的构成及品质评定[J]. 茶业通报, 2000, 22(2): 19-21.
[4]赵杰文, 陈全胜, 张海东, 等. 近红外光谱分析技术在茶叶鉴别中的应用研究[J]. 光谱学与光谱分析, 2006, 26(9): 1601-1604.
[5]张鹏, 李江阔, 陈绍慧. 苹果品质近红外光谱无损检测技术研究进展[J]. 保鲜与加工, 2013, 13(3): 1-7.
[6]林涛, 于海燕, 应义斌. 可见/近红外光谱技术在液态食品检测中的应用研究进展[J]. 光谱学与光谱分析, 2008, 28(2): 285-290.
[7]孙通, 徐惠荣, 应义斌. 近红外光谱分析技术在农产品/食品品质在线无损检测中的应用研究进展[J]. 光谱学与光谱分析, 2009, 29(1): 122-126.
[8]陈红光, 张云鹤, 敖长林, 等. 农产品品质无损检测技术应用研究[J]. 农机化研究, 2011, 33(9): 224-226.
[9]撖淙武, 王春光. 基于近红外光谱技术的饲料混合均匀度检测[J]. 农机化研究, 2015, 37(3): 191-194.
[10]马世榜, 郭爱玲, 郭韶华, 等. 基于光谱技术的牛肉嫩度等级无损判别[J]. 南阳师范学院学报, 2015(3): 24-27.
[11]朱红艳, 邵咏妮, 蒋璐璐, 等. 浸入式可见/近红外光谱技术的藻种鉴别研究[J]. 光谱学与光谱分析, 2016, 36(1): 75-79.
[12]王一丁, 赵铭钦, 付博, 等. 基于可见光-近红外光谱技术的烤烟品种鉴别研究[J]. 山东农业科学, 2016, 48(2): 119-124.
[13]梁奇峰, 侯红娜. 红外光谱多级鉴别不同种类的茶叶[J].广州化工, 2016, 44(1): 119-120
[14]李峰, Alchanatis Victor, 赵红, 等. 基于PLSR方法的马铃薯叶片氮素含量机载高光谱遥感反演[J]. 中国农业气象, 2014, 35(3): 338-343.
[15]潘蓓, 赵庚星, 朱西存, 等. 利用高光谱植被指数估测苹果树冠层叶绿素含量[J]. 光谱学与光谱分析, 2013, 33(8): 2203-2206.
[16]贾灿潮, 卢慧娟, 林丹, 等. 近红外光谱技术快速测定何首 乌 中 水 分 的 含 量 [J]. 医 药 导 报 , 2015, 34(12): 1633-1636.
[17]何勇, 刘飞, 李晓丽, 等. 光谱及成像技术在农业中的应用[M]. 北京: 科学出版社, 2016: 130-131.
[18]刘飞, 张帆, 方慧, 等. 连续投影算法在油菜叶片氨基酸总量无损检测中的应用[J]. 光谱学与光谱分析, 2009, 29(11): 3079-3083.
[19]Fan W, Shan Y, Li G, et al. Application of competitive adaptive reweighted sampling method to determine effective wavelengths for prediction of total acid of vinegar [J]. Food Analytical Methods, 2012, 5(3): 585-590.
Identi fi cation of Meitan Cuiya Tea Grades Based on Visible-Near-Infrared Technology
PENG Qingwei, LIU Yun, YU Jiancheng, WEI Xiaonan, TANG Yanlin*
College of Physics, Guizhou University, Guiyang 550025, China
In order to distinguish tea grade by using visible-near-infrared spectroscopy technique, Meitan Cuiya tea was used as materials in this study. The spectral data of all different grades Cuiya samples were collected. Firstly, Savitzky-Golay smoothing(SG), multiple scattering correction(MSC), standard normal variable transformation (SNV), first derivative, second derivative, detrending and other pretreatment methods were used to process the original spectral data of the samples. Then, the partial least squares regression (PLSR) model was established based on different preprocessing methods and raw data. The influence of different pretreatment methods on the modeling model was also studied. The results showed that the modeling of SG smoothing pretreatment method had the best effect. In order to simplify the model, three characteristic wavelength selection methods, the stepwise regression analysis (SWR), successive projection algorithm (SPA), and competitive adaptive re-weighting (CARS) were used to select the characteristic wavelength, which would be the pretreatment before the SG smoothing. Finally, PLSR modeling was performed based on the characteristic wavelengths selected by different feature wavelength algorithms. The results showed that the model based on the CARS method had the best prediction effect, with the correlation coefficient of 0.9739 and the calibration standard deviation of 0.2250. The model greatly reduced the number of independent variables, simplified the previous model, and achieved a good prediction effect, which provided a new, quick and effective method for the classification of Cuiya grades.
visible-near-infrared spectroscopy, Meitan cuiya, grade, competitive adaptive re-weighting, partial least squares regression
TS272.5+1;O434
A
1000-369X(2017)05-458-07
2017-03-30
2017-05-04
国家自然科学基金(11164004)、贵州大学研究生创新基金(2017036)
彭清维,女,硕士研究生,主要从事光谱分析与光谱检测方面的研究。*通讯作者:tylgzu@163.com
