数据挖掘在计算机课程成绩分析中的应用
2017-10-19和铁行
和铁行,王 伟
(杭州医学院,浙江,杭州 310053)
·教学研究与管理·
数据挖掘在计算机课程成绩分析中的应用
和铁行,王 伟
(杭州医学院,浙江,杭州 310053)
目的:寻找教务管理系统中海量数据之间的隐性关联,以达到增强学生学习效率,促进教学水平提升,增强教学管理的有效性。方法利用数据挖掘关联规则的改进型Apriori算法和聚类算法进行数据的挖掘。结果通过对数据挖掘进行统计分析后,发现用来挖掘的2015级120名专科生和2016级60名本科生计算机课程成绩与入学基础、授课时数之间有着隐藏的关联性。结论成绩的评定指标要具有可操作性和合理性,利用挖掘结果可以指导教师教学,有利于学生更有针对性地进行计算机课程的学习。
数据挖掘;Apriori算法;成绩分析
Abstract:[Objective] To find the implicit association between the increasing amount of mass data in the education management system and to enhance students' learning efficiency, promote teaching level and improve the effectiveness of teaching management.[Method] According to Apriori algorithm, the modified form of data mining associated ruler, data miningwascarried out.[Result]Searching for the potential relationship among the data through statistical analysis, it is found that there are hidden correlations between the scores.[Conclusion] The evaluation indicators should be operational and reasonable. The results of mining could be used to guide teaching and help students in targeted computer learning.
Keywords:data mining; Apriori algorithm;analysis of the performance
高校在长期的教学过程中积累了大量的数据,这些海量的数据存放在学校的教务管理系统中。于是,将数据挖掘技术应用到成绩方面成为教学管理的一个研究方向。本文利用数据挖掘中的关联规则法和聚类算法对学生的成绩及其影响因素做了深入的分析、总结和发掘,希望能对今后教师的日常教学、学生学习以及教学管理提供帮助。
1 数据挖掘及算法介绍
1.1 数据挖掘
数据挖掘(Data Mining,DM)[1]是利用计算机这一现代化工具,从模糊的、海量的、不完整的实际应用数据中,把隐含在其中的人们事先不知道的但又可能有用的信息和知识提取的过程,试图发现隐藏在这些数据背后的关系是人们挖掘的目的,挖掘的结果是可以为人们提供更多有价值的信息。
1.2 数据挖掘算法
数据挖掘算法[2]是根据数据创建数据挖掘模型的一组试探法和计算。常用的数据挖掘算法有:分类算法、决策树算法[3]、回归算法、聚类分析算法、关联规则等,这些算法有其各自适用的场景。如对植物叶子的分类就是典型的分类算法,对根据降雨、雾霾、气温等特征将自己的行为分类为出门和不出门则是典型的决策树算法。
1.3 Apriori算法
从所有的项目集合中找出所有频繁项目集合式Apriori算法的基本思想,找出的这些频繁项目集合的频繁性必须大于或等于预先设定好的最小支持度值(支持度表示项集{X,Y}在总项集里出现的概率,最小支持度是指出现X导致Y也出现的最小概率值。)然后由这些满足最小支持度的频繁项目集合来产生关联性较强的规则,也即是强关联规则,在满足最小支持度的同时还要满足预先设定好的最小置信度是强关联规则的基本要求(置信度表示在先决条件X发生的情况下,由关联规则”X→Y”推导出Y的概率。)。Apriori算法最开始是从最简单的候选项集C1中开始筛选,找出符合条件的L1,然后由L1与自身连接便可产生候选项集C2,接着再对C2进行筛选,找出符合条件的L2,如此循环下去直到最后为空集为止。
本文用到的数据挖掘技术就是挖掘关联规则的Apriori算法。
2 数据挖掘在学生成绩分析中的应用
2.1 挖掘流程
确定挖掘的目标,即需要挖掘的计算机课程的学生成绩,然后对这些挖掘的对象进行采集、预处理,进行初步挖掘,再逐层进行深度挖掘,最终建立数据间的关联性,挖掘分析出各指标间的类。
2.2 系统流程
根据挖掘流程,设计出如图1所示的挖掘系统流程图,应用于实际的数据挖掘。
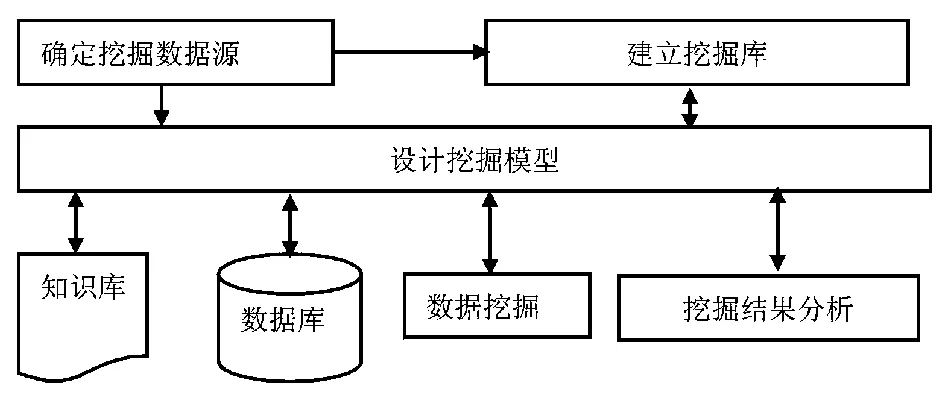
图1 挖掘系统流程图
图1中,挖掘的数据来源于正方教务管理系统、百科园通用考试管理系统(计算机课程教学互动的软件系统)和浙江省计算机等级考试数据库;数据库指的是主要存储涉及学生信息的各种数据,该系统将学生的基本信息以及学生学习计算机课程的各种信息存储在数据库中;知识库是经过数据挖掘后从中提取出来的规则,用来为决策人员作决策使用;数据挖掘是根据决策者提出的问题特点,确定挖掘的任务或目的,对数据库中的相关数据进行精简和预处理,再从精简后的数据中挖掘出新的、有效的新知识,提供给基于计算机课程成绩的有效数据挖掘,最终由它给决策者提供有效的知识;挖掘结果分析是通过分析最终的挖掘结果,找出有效数据之间的关联,提供有实际意义的报告。
2.3 数据准备
本次研究选择了我校2015级120名专科学生和2016级60名本科学生的基本信息(数据来源于校正方教务管理系统、百科园通用考试管理系统和浙江省计算机等级考试数据库)、医学计算机应用基础课程的任课教师、课时情况、出勤率等信息(来源于联创机房管理系统和百科园通用考试管理系统),以及浙江省计算机等级考试的成绩信息(来源于2016年秋浙江省计算机等级考试数据)。其基本信息如表1所示。

表1 计算机课程数据的基本信息表
2.4 数据预处理
表1中的数据中可能存在冗余、不完整、空值等情况,因此对收集到的数据在挖掘之前进行预处理,提高数据的质量,从而有助于建立高准确率的数据模型。数据预处理就是要删除对挖掘的预测结果无关联的数据,如学生的年龄、班级等信息。同时,基于数据挖掘的要求,还要将多张数据表进行合并整理,形成适合数据挖掘的数据表。
2.5 基于Apriori算法的数据挖掘
本次关联规则分析的数据由我校2015级120名专科学生和2016级60名本科学生学生、计算机课程考试成绩及相应的任课老师信息组成。共抽选出180条学生的记录。经过整理后的初始信息表如表2所示。

表2 计算机课程初始信息表
(备注:课前基础测验在第一次实验课中完成,评定按5级制;表中只列举了部分信息)
为了简化分析,接下来需要将数据进行抽象和离散化处理。学生专业信息处理为:药学(A1),护理(A2),影像(A3)…学生课前基础测验在第一次实验课中完成评定,分别用优秀(B1),良好(B2),中等(B3),合格(B4),不合格(B5)表示。教师职称分别用正高(C1),副高(C2),中级(C3),初级(C4)表示。学生上课课时数离散化为:>=8周(D1),7周(D2),6周(D3),5周(D4),<=4周(D5)。实验作业根据得分情况离散化为:90~100为优秀(E1),80~89为良好(E2),70~79为中等(E3),60~69为合格(E4),低于60分为不合格(E5)。计算机课程考试成绩离散化为:90~100为优秀(F1),80~89为良好(F2),70~79为中等(F3),60~69为合格(F4),低于60分为不合格(F5)。经过处理的信息表如表3所示。

表3数据预处理、离散化后的信息表
数据分析过程采用SPSS Clementine12.0中文版,以Apriori算法为基础,设置最小支持度为0.35,取最小置信度为0.65,使用加权支持度计算函数(支持度公式为Support(X→Y)=P(X,Y)P(I)。由于考试分数的特性,设定λ为6,其他权值为3进行挖掘分析,生成频繁项集(也称为项集,如果项集的相对支持度满足预定义的最小支持度阈值,则称之为频繁项集)和关联规则(关联规则是形如X→Y的蕴涵式,其中X和Y分别称为关联规则的先导和后继,关联规则XY,存在支持度和信任度。)。共获得387条频繁项集,296条关联规则。部分关联规则见表4。
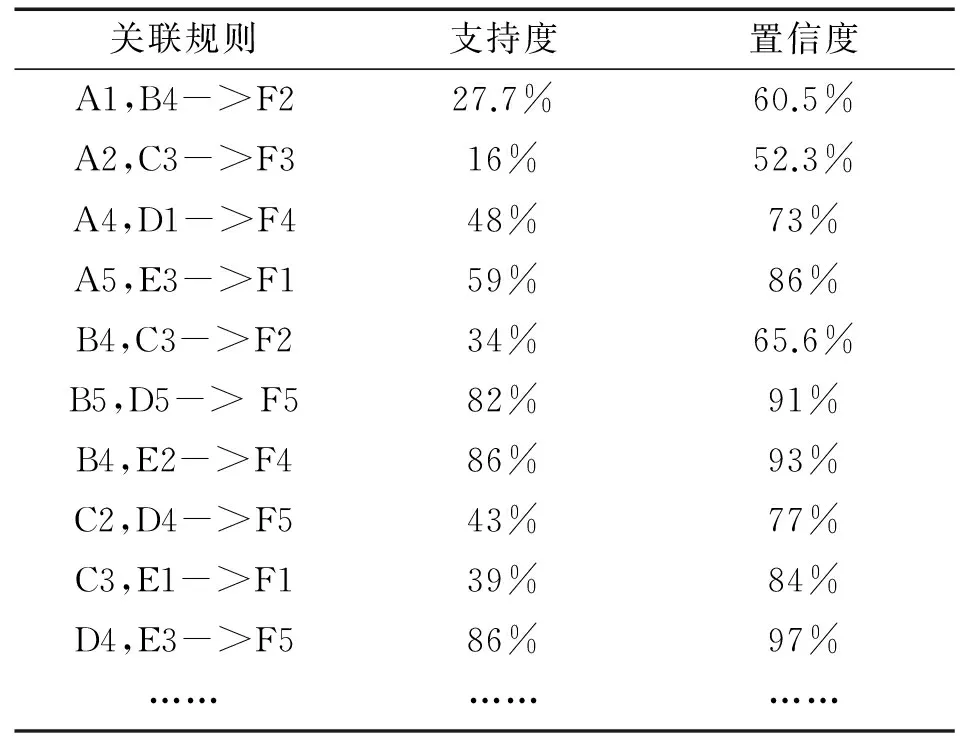
表4 关联规则表
根据前面设置最小支持度为0.35和最小置信度为0.65的阈值,从表4中A2,C3->F3的关联规则可以推导出专业和教师的职称对于学生成绩的并没有什么直接影响,从B5,D5-> F5、B4,E2->F4、D4,E3->F5这些关联规则中我们可以推导出最终的成绩和前面数据存在着很强的关联性,入学基础差、授课时数少、实验作业情况中等以下的学生的课程通过率较低;而入学基础好、授课课时数8周以上、平时作业完成良好的学生,课程考试成绩就较高。因此,应当适当增加课时,对课时少的专业中实验作业成绩较差的学生教师应在课堂上给予更多关注,以利于提高课程的考试成绩。
3 结论
本文利用数据挖掘技术中的关联规则分析对计算机课程的成绩进行了分析,分析的结果和课程结束后学生成绩的分布结构相类似。学生所在专业以及教师的职称对课程成绩影响不明显,两者之间基本上不存在符合设定阈值的关联。而学生课前的基础、授课时数、实验作业和最终成绩存在着很强的关联性。其分析结果可以帮助学生发现自己的薄弱环节,对于以后学习提供针对性的帮助。同时对教师教学方法的改进和学院对课程学时分配也有一定的指导意义。
[1]赵艳.Apriori算法在高职院校课程关联性分析中的应用研究[J].河北企业,2015.(9):10-11.
[2]娄岩.医学大数据挖掘与应用.北京:科学出版社,2015.47-48.
[3]曾斯.数据挖掘技术在计算机等级考试成绩中的分析研究[J].电脑知识与技术,2015,(13):14-15.
Applicationofdatamininginachievementanalysisofcomputercourses
HETiexing,WANGWei
(Hangzhou Medical College,Hangzhou 310053,China)
B
1672-0024(2017)05-0004-04
和铁行(1980-),男,河南周口人,本科,讲师。研究方向:计算机基础教学与科研
杭州医学院校级课题(编号:2013XZA05)
