基于连续Skip-gram及深度学习的图像描述方法
2017-10-18曹刘彬张丽红
曹刘彬, 张丽红
(山西大学 物理电子工程学院, 山西 太原 030006 )
基于连续Skip-gram及深度学习的图像描述方法
曹刘彬, 张丽红
(山西大学 物理电子工程学院, 山西 太原 030006 )
图像描述生成依赖于词向量及其质量, 为了进一步提高生成图像描述的准确率, 本文将连续Skip-gram模型引入生成图像描述的框架中. 该框架首先利用连续Skip-gram学习单词的分布式表示, 产生高质量的词向量, 降低了词向量的计算复杂度, 然后利用区域卷积神经网络对图像进行目标检测及特征提取, 最后将词向量与图像特征向量分别作为循环神经网络的输入向量以及偏置向量, 进而输出图像描述. 实验结果表明: 与m-RNN模型、 Neural Image Caption模型、 多模态循环神经网络模型相比较, 采用连续Skip-gram模型的图像描述框架提高了图像描述的准确率及该框架的泛化能力.
深度学习; 图像描述生成; Skip-gram; 词向量
Abstract: Generating image caption relies on word vectors and their quality. In order to further improve the accuracy of image caption, this paper introduces continuous Skip-gram model into the frame of generating image caption. Continuous Skip-gram model is employed in the frame to learn the distributed representation of words, thus high quality word vectors are obtained and it reduces the computational complexity of word vectors. Then, Region-based Convolutional Neural Network in the frame detects image objectives and extracts features. Finally, the word vectors and image features are utilized as input and bias of Recurrent Neural Network to generate image caption. Experimental result shows that comparing with m-RNN model, Neural Image Caption model and multimodal recurrent neural network model, the frame using continuous Skip-gram model improves the caption accuracy and its generalization ability.
Keywords: deep learning; image caption generation; Skip-gram; word vector
0 引 言
视频数据挖掘是人们为了应对大量视频数据所提出的新兴技术, 图像描述生成方法研究属于视频数据挖掘的一个分支, 称之为描述性视频数据挖掘. 当前的图像描述生成方法主要有以下4类: ① 建立模型推测语义信息与视觉信息两个模态之间的对应关系, 为图像片段添加注释[1]; ② 将图像描述看作一个检索问题, 检索与图像最匹配的描述[2]; ③ 学习固定的句式模板, 根据图像内容及语法规则填充模板, 生成图像描述[3]; ④ 在循环神经网络语言模型中加入上下文窗口, 生成图像描述[4]. 这些方法中生成的词向量质量方面存在不足, 直接影响了图像描述的准确率. 连续Skip-gram模型中所有单词共享映射层, 不包含最耗时的非线性隐含层, 能够产生优质的词向量. 因此, 本文在生成图像描述的框架中引入连续Skip-gram模型, 结合区域卷积神经网络及循环神经网络生成图像描述.
1 区域卷积神经网络
区域卷积神经网络[5](Region-based Convolutional Neural Network, 简称R-CNN)在传统卷积神经网络(Convolutional Neural Network, 简称CNN)的基础上进行了两点改进: ① 将卷积神经网络与Region Proposal策略相结合, 自底向上训练, 可以进行目标物定位和图像分割; ② 当训练数据比较稀疏的时候, 可以先在有监督的数据集上训练之后, 再到特定任务的数据集上进行参数微调. R-CNN 模型结构如图 1 所示.
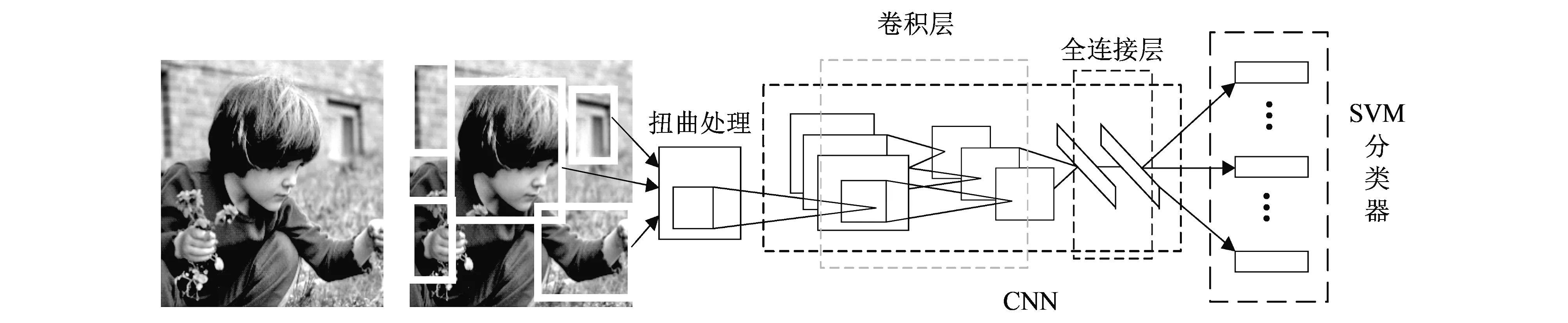
图 1 R-CNN模型结构Fig.1 Architecture of R-CNN model
R-CNN目标检测算法包括4个步骤: ① 给定输入图像. ② 在输入图像上使用Selective Search方法生成预选框. 首先基于各种颜色、 纹理特征将图像划分为多个小块, 然后自底向上地对不同的块进行合并, 合并前后的每一个块都对应于一个预选框. ③ 对每个预选框, 使用CNN网络模型提取特征. 将预选框中的图像尺寸归一化为227*227, 对每个预选框的图像进行扭曲处理, 输入到CNN网络模型中, 得到提取的特征值. ④ 将提取的特征输入到每一类的SVM分类器, 判别是否属于该类.
2 连续Skip-gram模型结构
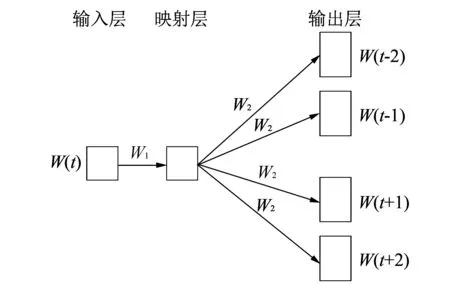
图 2 连续Skip-gram模型框架结构Fig.2 Framework of continues Skip-gram model
词向量的维度与训练语料库的大小决定了词向量的质量. 因此, 选择合适的词向量维度以及足够的训练语料成为提高图像描述准确率的关键. 连续Skip-gram模型能够在大规模的语料库上进行训练, 平衡了词向量维度与计算复杂度之间的矛盾. 该模型首先利用文本语料库构造词汇表, 然后学习词的向量表示.
连续Skip-gram模型由输入层、 映射层以及输出层构成, 其模型结构如图 2 所示.
图 2 中,W1为输入层与映射层之间的权重矩阵,W2为映射层与输出层之间的权重矩阵. 输入层单词初始化为one-hot形式. 该模型的训练目标是: 寻找一个句子或者文本文件当中任意单词的向量表示, 使得这种向量表示能够预测它周围的单词[6]. 即词向量的表示要能够反映上下文信息. 给定一个单词序列w1,w2,w3,…,wT, 通过训练使得平均对数概率最大化. 平均对数概率为

式中:wt为训练句子中任意单词, 即中心词;c为训练文本窗口的大小;wt+j为中心词wt的前j个单词与后j个单词;T为训练句子中的单词总量.
利用Softmax函数,p(wt+j||wt)定义为

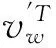
3 系统框架
图 3 为引入连续Skip-gram模型的深度学习图像描述框架.
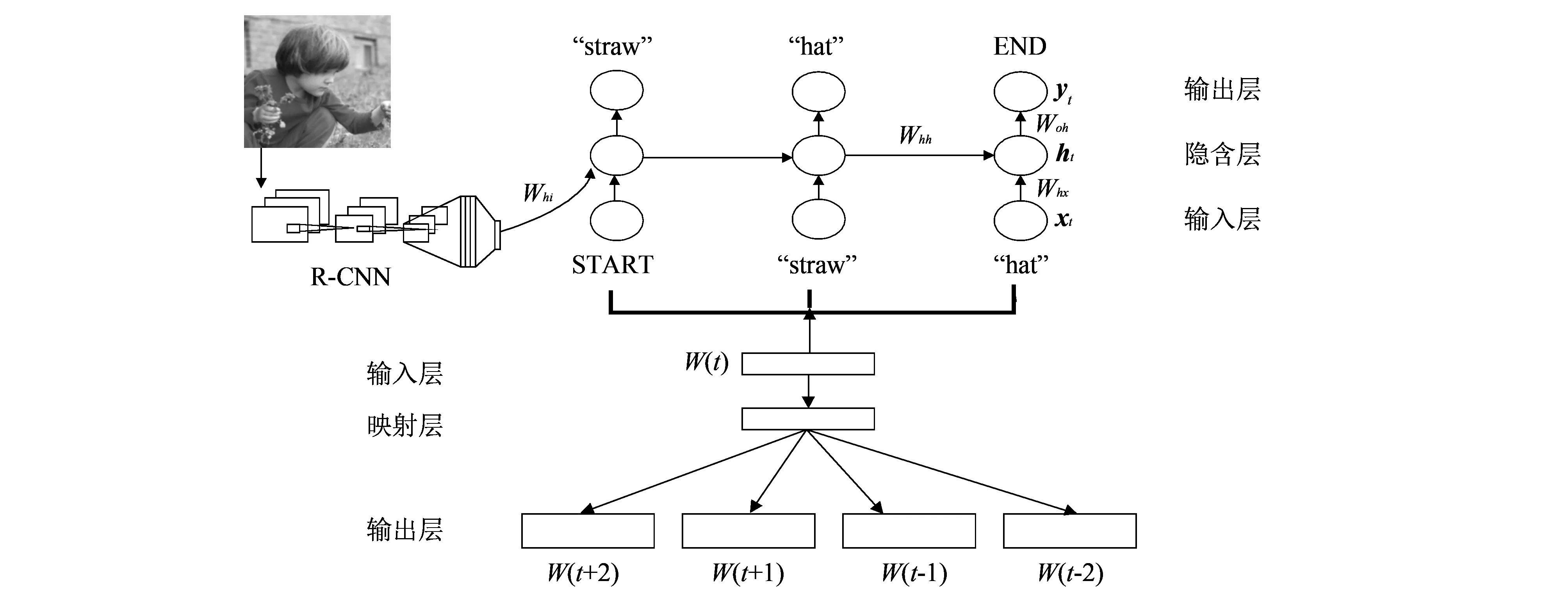
图 3 生成图像描述的框架结构Fig.3 Framework of generating image caption
框架中, R-CNN 提取的图像特征向量bv与连续S-gram计算的词向量序列(x1,…,xT)分别作为循环神经网络的偏置与输入. 其中, 向量xt表示输入文本中的单词. 然后, 计算循环神经网络的隐含层状态(h1,…,hT). 最后, 计算输出向量序列(y1,…,yT). 这是一个循环迭代的过程, 如式(3)~式(5)所示,t从 1到T进行迭代.

式中:Whi,Whx,Whh,Woh,bh,bo为要训练的参数;CNNθc(I) 为R-CNN的输出;f为隐含层激活函数RELU(Rectified Linear Units); 利用Delta函数II(t=1)仅在第一次迭代时引入图像特征向量bv; 输出向量yt表示单词在词表中相应位置出现的概率, 再利用Beam Search Decoding[8]搜索算法, 找到与yt对应的单词, 作为模型最后的输出.
4 实验及结果分析
本文所用实验平台为Python2.7, 首先在ImageNet ILSVC 2012数据库上对R-CNN进行预训练, 然后在Flickr8k图像数据库上进行参数调整[5]; 利用连续Skip-gram模型计算词向量时, 利用Flickr8k文本数据库; 利用循环神经网络生成图像描述时, 将来自R-CNN与连续Skip-gram的输出结果作为其数据库.
4.1 实验参数设置
1) R-CNN: use_gpu = 1, 迭代批大小batch_size=10; 特征向量初始化为4 096维零向量, 即feats=zeros(4096, N,‘single’).
2) 连续Skip-gram: 特征向量维数size=320, 网络初始学习率alpha=0.025, 词频最小值min_count=2, 线程数workers=3, 学习率最小值min_alpha=0.000 1, 训练算法选择negative=5, 迭代次数iter=5, 上下文窗口大小window=10.
3) 循环神经网络: 网络学习率learning_rate=0.001, 迭代批大小batch_size=100, 衰减率decay_rate=0.999, 最大迭代次数max_epochs=10.
4.2 实验结果及分析
将Flickr8k数据库中的1 000幅图像作为测试集, 7 000幅图像作为训练集. 每幅图像配有5个句子描述, 连续Skip-gram利用句子中所有单词构造一个词典, 然后利用循环神经网络从中选出最佳词汇, 构成输入图像描述.
图 4, 图 5 分别为引入连续Skip-gram模型的测试结果与未引入连续Skip-gram模型[7]的测试结果. 可以看出, 引入连续Skip-gram模型的图像描述生成框架在弥补语义缺陷及消除句子歧义方面有明显的效果.

图 4 未利用连续Skip-gram模型的框架描述结果Fig.4 Captioning results of frame not using continuous Skip-gram model

图 5 利用连续Skip-gram模型的框架描述结果Fig.5 Captioning results of frame using continuous Skip-gram model
利用Microsoft Coco captions[8]计算生成的图像描述在Flickr8k数据库上的Bilingual Evaluation Understudy(BLEU)[9]得分, 与目前已经存在的几种模型进行对比, 对比结果如表 1 所示.
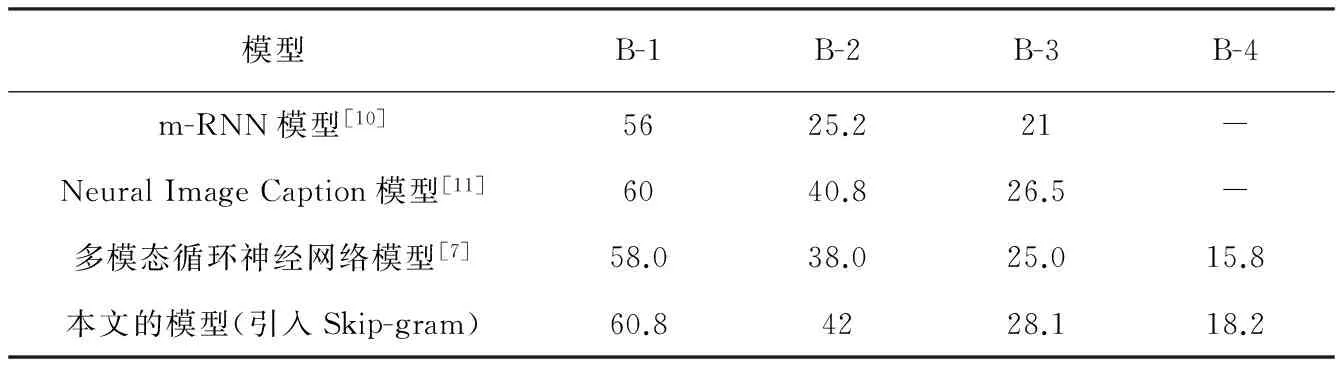
表 1 实验结果BLEU得分对比
表 1 中, B-n(n=1,2,3,4)为BLEU评价标准中各个字段对应的得分, 即生成的句子中各个字段与参考句子各个字段的匹配程度. 前两种模型结构在Flickr8k数据库上不存在B-4得分. 不同配置的机器所得仿真结果也不相同, 表中所列数据均以同一台机器为参考. 从表 1 中可以看出, 在以循环神经网络为中心的图像描述生成模型中, 引入连续Skip-gram词向量计算模型, 可以有效提高BLEU得分, 即提高生成图像描述的准确率.
表 1 中所列模型实际训练时, 处理一组图像语句数据的平均时间如表 2 所示. 表 2 中所列数据是将各个模型在同一台机器上进行仿真得到的.

表 2 训练时间结果对比
从表 2 可以看到, 与其他3种模型相比较, 引入连续Skip-gram词向量计算模型的图像描述生成框架的训练时间明显缩短了.
5 结束语
本文利用以循环神经网络为中心的网络模型生成图像描述, 在循环神经网络的输入端引入连续Skip-gram模型计算词向量. 实验结果表明: 引入连续Skip-gram模型的网络框架生成图像描述的准确率高于未引入此模型的网络框架的准确率, 该方法在提高网络的泛化能力以及降低过拟合的风险方面是有效的.
[1] Socher R, Li F. Connecting modalities: Semi-supervised segmentation and annotation of images using unaligned text corpora[C]. CVPR, 2010: 966-973.
[2] Hodosh M, Young P, Hockenmaier J. Framing image description as a ranking task: Data, models and evaluation metrics[J]. Artificial Intelligence Research, 2013, 47(3): 853-899.
[3] Kulkarni G, Premraj V, Dhar S, et al. Baby talk: Understanding and generating simple image descriptions[C]. CVPR, 2011: 1601-1608.
[4] Kiros R, Salakhutdinov R, Zemel R. Multimodal neural language models[C]. Proceedings of International Conference on Machine Learning, 2014: 595-603.
[5] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C].CVPR, 2014: 580-587.
[6] Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and their Compositionality[C]. Proceedings of Advances Neural Information Processing Systems, 2013: 3111-3119.
[7] Karpathy A, Li F. Deep Visual-Semantic Alignments for Generating Image Descriptions[J]. IEEE, 2015, 39(4): 664-676.
[8] Chen X, Fang H, Piotr D, et al. Microsoft Coco captions: Data collection and evaluation server[J]. Computer Science, 2015: 1504-1509.
[9] Papineni K, Roukos S, Ward T, et al. BLEU: A method for automatic evaluation of machine translation[C]. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 2002: 311-318.
[10] Mao J, Xu W, Yang Y, et al. Explain Images with Multimodal Recurrent Neural Networks[J]. Computer Science, 2014: 1410-1417.
[11] Vinyals O, Bengio S. Show and Tell: A Neural Image Caption Generator[C].CVPR, 2015: 3156-3164.
ImageCaptionMethodBasedonContinuousSkip-GramandDeepLearning
CAO Liubin, ZHANG Lihong
(College of Physics and Electronic Engineering, Shanxi University, Taiyuan 030006, China)
1671-7449(2017)05-0423-05
TP391.4
A
10.3969/j.issn.1671-7449.2017.05.009
2017-03-15
山西省科技攻关计划(工业)资助项目(2015031003-1)
曹刘彬(1993-), 男, 硕士生, 主要从事图像处理的研究.
