交叉节点缓存crossbar交换结构设计
2017-10-12周延鹏张兴明
周延鹏,张兴明
(国际数字交换系统工程技术研究中心 河南 郑州450002)
交叉节点缓存crossbar交换结构设计
周延鹏,张兴明
(国际数字交换系统工程技术研究中心 河南 郑州450002)
针对传统交换结构调度复杂且时间开销大的问题,采用交叉点缓存(Buffered Crossbar)交换结构和改进的轮询调度算法,在输出端设置按一定的缓存顺序输出,并通过verilog代码实现了8*8的CICQ交换结构。极大地缓解了传统Crossbar交换结构存在的输入输出端口冲突问题,有效避免了队头阻塞问题。采用算法复杂度为O(1)的轮询调度算法,硬件实现简单。可以达到100%的吞吐效率,实现了最快3个时钟周期的高速度低延时交换。
crossbar;交换结构;调度算法;轮询
Abstract:The traditional exchange structure is complicated and time scheduling overhead problem.Using a modified round-robin scheduling algorithm,at the output buffer is set according to a certain order of output,and by verilog code to achieve the 8*8 CICQ switch fabric.Greatly reducing the conflict of input and output ports of traditional crossbar switch fabric,effectively avoiding HOL blocking problem.Using an algorithm complexity is O(1) of the round-robin scheduling algorithm,hardware implementation simple.It can achieve 100%throughput efficiency,to achieve the fastest speed three clock cycles low latency switching.
Key words:crossbar;switch fabric; scheduiingaigorithm; round-robin
当前,大容量、高性能的交换设备所采用的核心交换技术通常为交换结构(Switch Fabric)[1-3]和调度算法(Schedule Algorithm)[1,4]两个部分。 交换结构负责的是报文高速转,它的结构和性能直接决定了交换机设备的应用性能,因此,交换结构的设计对网络核心交换机的研制有着十分重要的意义。对于支持高链路带宽和多端口的交换设备而言,其调度器的仲裁时间越短越好,这就需要调度算法所使用的仲裁时间尽量的短,也就是说调度算法的实现复杂度要尽可能的低。因此,在交叉开关交换结构上寻求低复杂度、高吞吐量的调度算法具有非常重要的意义。常用的单Crossbar交换结构可以分为输入排队[5-6]、输出排队[5-6]、联合输入输出排队和交叉缓存交换结构[7,14],目前大容量高速交换通常采用联合输入输出排队和交叉缓存(CICQ)[10]交换结构。在做了理论分析的基础上,设计实现了CICQ交换结构和轮询调度算法,该结构能实现低延时的高速数据传输[15-17]。
1 CICQ交换结构设计
CICQ是在CICQ交换结构的基础上增加了输出缓存队列设计。根据设计思路把CICQ交换结构的组成可以分为3个部分:输入端,交换单元,输出端3部分组成。
CICQ交换结构工作流程可分为4步,
第一步:包到达过程,即包进入输入端口后按照包信息缓存到对应端口的对应VOQ[1-9][11-12]缓存队列;
第二步:输入虚拟缓存队列到交叉点缓存的调度过程,采用能够用有效避免端口饿死的轮训调度算法;
第三步:交叉节点到输出缓存的调度过程,同样采用轮训调度算法[11-13]。
第四步:输出缓存读出过程,按一定优先级进行输出过程;
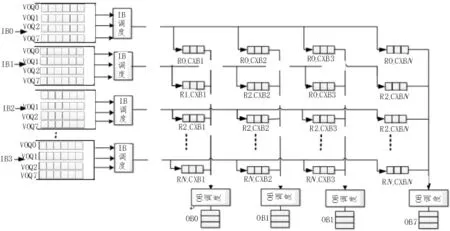
图1 CICQ结构框图
1.1 输入端口
根据8*8 CROSSBAR交换结构的需求,从上图整体设计可以看出需要8个输入端口,每个输输入端口设置8个VOQ虚拟缓存队列分贝对应8个不同的输出端口。采用VOQ虚拟缓存能有效的避免交换结构的对头阻塞(HOL,Head of Line blocking)[8]问题。VOQ缓存采用深度为16,位宽为32的同步fifo设计下面对一个输入端口进行详细介绍;
数据进入交换结构在输入端口虚拟缓存在非满状态下根据要去往的输出端口缓存至对应的VOQ队列,如图2所示,r0_bus_data_i、r0_req_i均有效。r0_dest_port=8’b10000011时,数据就缓存在 VOQ0、VOQ1、VOQ7 中。
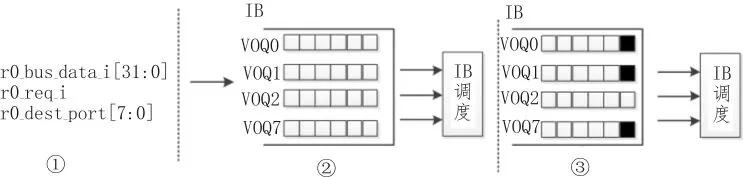
图2 输入端VOQ
1.2 交叉端
交叉端要完成的任务是从根据输入调度算法从输入端的虚拟缓存队列中读出数据并缓存到交叉点;
1)监测输入端VOQ虚拟缓存中是否有数据
2)监测交叉点缓存(RN_CXB)是否为满,即交叉点可以接受输入端数据
3)当满足以上两个条件时,根据轮训调度算法,依次从8个输入端读入数据缓存至交叉点缓存调度算法的实现将在后文详细介绍。
1.3 输出端
输出端要完成的任务是根据输出调度算法从交叉点缓存读出数据至输出缓存,在输出缓存采先到先出的原则进行读出。以要从输出端口一输出为例,做如下介绍
1) 监测 R0_CXB0、R1_CXB0、 到 RN_CXB3、中是否有数据;
2)监测对应输出端缓存是否为满,即输出是否可以接收检查点的数据;
3)当满足以上两个条件时,根据轮训调度算法,依次从8个交叉点读入数据缓存至输出端缓存;
4)当输出缓存中有数据时按先到先出原则读出数据;
2 调度算法设计
CICQ交换结构采用的分布式调度,即输入端到交叉点的输入调度算法和交叉点到输出端的输出调度算法。本文采用的输入和输出调度算法核心都是轮训调度,实现方式类似。在此只对输入调度进行详细介绍。
2.1 输入调度
输入调度流程如图3所示。
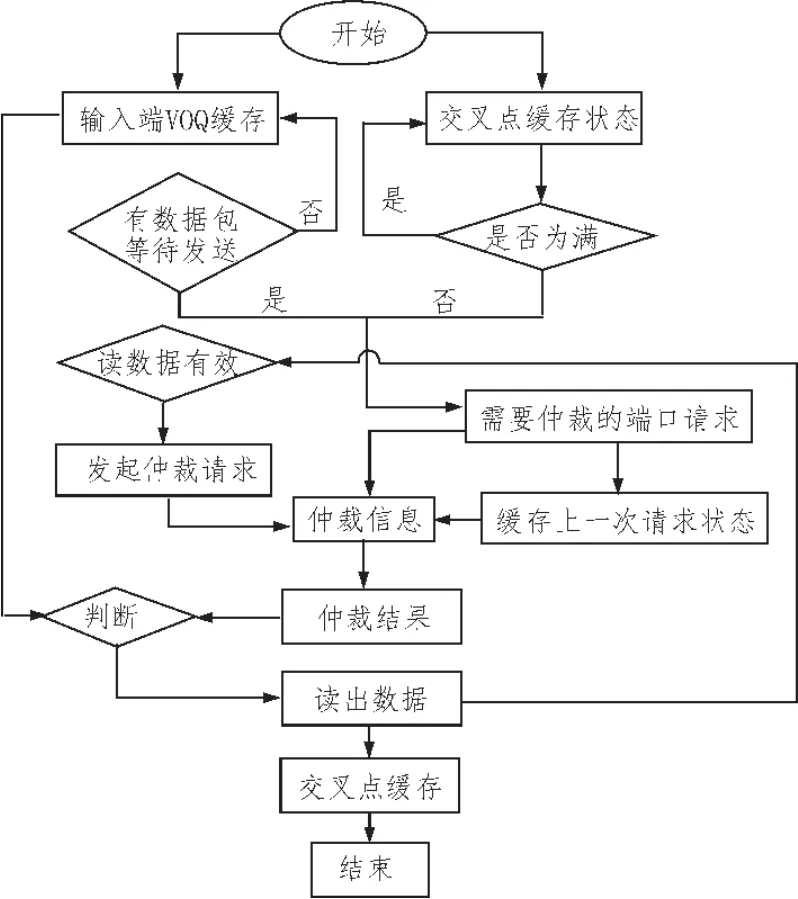
图3 输入调度流程
调度算法流程:
1)监测输入端VOQ虚拟缓存中是否有数据,、监测交叉点缓存(RN_CXB)是否为满,即交叉点可以接受输入端数据;
2)产生需要仲裁的端口请求信号备用;
3)第一次仲裁按照端口优先级顺序,即0到7依次降低的顺序,假设第一次0端口有请求,就从0端口开始,仲裁结果就是0,并将请求缓存至“上一次请求寄存器”跳至步骤6);
4)第一次读出数据以后产生仲裁请求备用;
5)根据仲裁骑牛和当前仲裁端口信息以及缓存寄存器信息产生仲裁结果;
6)根据仲裁结果从冲输入VOQ缓存中读出数据;
7)读出数据缓存至交叉点缓存
8)结束。
2.2 输出调度
输出调度和输入调度均采用轮询算法,区别主有两点
1)输出调度中的进入数据时缓存在输出端口相同的交叉点缓存 (假设输出端口为0,对应的是R0_CBX0、R1_CBX0 到 R7_CBX0);
2)数据输出的缓存队列不同于输入调度的多个CBX缓存,而是多个CBX缓存至一个输出缓存。
3 仿真验证
仿真验证环境为linux下的Vivado套件,由于仿真验证工作繁琐,所以只列出输入调度、输出调度、以及整体的仿真信息。
测试激励说明:
对8个输入端口全部进行多播[7]形式数据写入,这样可以更全面地测试输入和输出调度以及数据输出是否按照预期轮询依次输出。
3.1 调度仿真
输入调度:
输入调度做作用综合考虑输入缓存和交叉点缓存以及上一次调度结果,产生ib_grant仲裁信号。从图4可以看出ib_grant能够正常移位进行轮询调度。
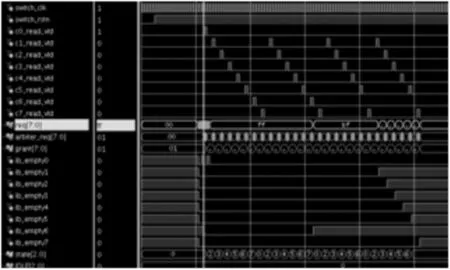
图4 输入调度仿真
输出调度:
输出调度做作用综合考虑交叉点缓存和输出缓存以及上一次调度结果,产生ob_grant仲裁信号。从图5可以看出ob_grant能够正常移位进行轮询调度。
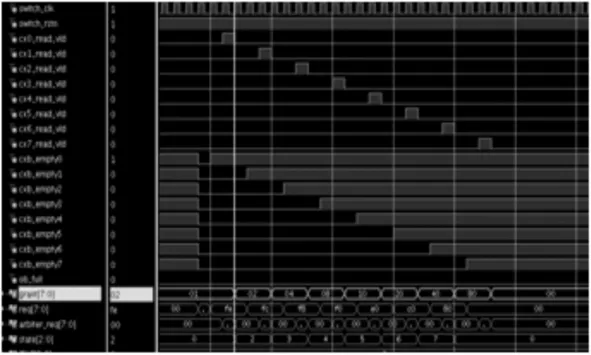
图5 输出调度仿真
3.2 系统仿真
系统及仿真主要体现输入数据能否正常到达目标端口,从图6可以看出输出信号能够依次输出,需要说明的是第一个输出信号延迟较长,后边达到流水输出后就能够达到最短3个时钟延迟的告诉输出。
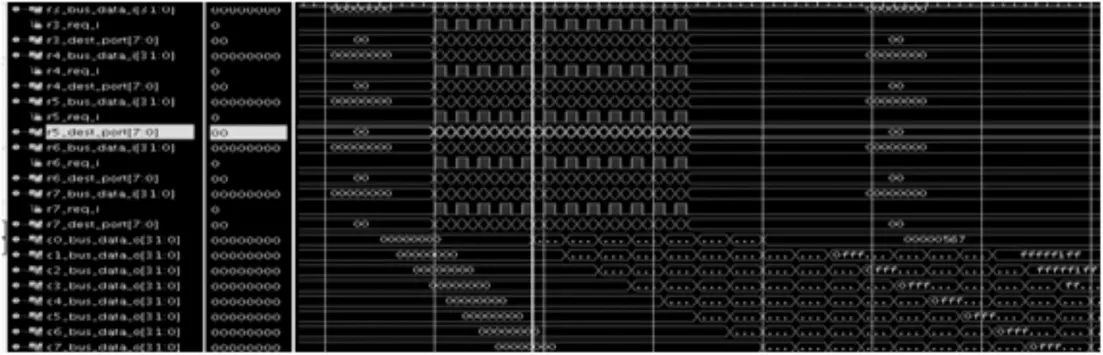
图6 系统仿真
3.3 硬件开销
硬件开销如图7所示。

图7 硬件开销
4 结 论
本文主要研究了一种基于CICQ的crossbar交换结构和基于轮训的调度算法,并通过Verilog编码实现,在vivado工具下进行了仿真和基本功能验证以及网标综合,均达到设计要求。实现了流水输出,最短输出时间延迟为3个时钟周期,该交换结构和角度算法可以应当前很多交换设备在硬件电路设计和功能验证方面具有一定的理论意义和应用价值。
[1]王俊芳,张思东.通用高速分组交换调度算法[J].电子科技大学学报,2010(1):69-73.
[2]韩永,姚念民,蔡绍滨,等.iSCSI虚拟交换机包转发调度算法 FC-WFQ[J].电子学报,2013,41 (3):587-592.
[3]蒋泳波,高速交换结构多播技术研究[D].西安:西安电子科技大学,2013.
[4]高雅,邱智亮,张茂森,等.一种支持单组播混合交换的 Clos网络及调度算法 [J].西安电子科技大学学报:自然科学版,2013,40(1):48-52.
[5]徐宁,余少华,汪学舜.一种新型的负载均衡-交叉点缓冲交换结构 [J].电子学报,2012,40(12):2360-2366.
[6]戴艺,苏金树,孙志刚.高性能新型交换结构综述[J].电子学报,2010,38(10):2389-2399.
[7]Divakaran D M,AnhaltF,Altman E.Size-based flow scheduling in a CICQ switch[A].Dallas,USA:IEEE 2010.
[8]Rojas-Cessa, Roberto,Dong, Ziqian.Load-Balanced Combined Input-Crosspoint Buffered Packet Switches[J].IEEE Transactions on Communications 2011,5(5).
[9]倪杰.用于三级Clos网络的一种高效自寻路交换机制研究[D].成都:电子科技大学,2013.
[10]郑若鹢.CICQ交换结构的调度算法分析[J].电脑与信息技术,2010(6):20-22.
[11]Lin D,Jiang Y,and M.Hamdi.Selective Request Round-Robin Scheduling for VOQ Packet Switch Architecture[C]//Proceedings of IEEE International Conference on Communications (ICC),2011:1-5.
[12]任涛,兰巨龙,扈红超.并行分组交换研究综述[J].计算机工程与设,2012(1):47-50.
[13]LaMaire R O,Serpanos D N.Two dimensional round-robin schedulers for packet switches with multipleinputqueues[J].IEEE/ACMTrans.Networking,Oct.2010,2(5):471-482.
[14]Jeroen Famaey,Frederic Iterbeke,Tim Wauters,et al.Towards a predictive cache replacement strategy formultimedia content [J].Journalof Network and Computer Applications 2013,1(1).
[15]张亚夫,宣二勇.高速交换矩阵调度器的FPGA设计[J].无线电工程, 2013(6):4-5.
[16]朱谦,蒋林,蔡龙.分组交换技术在光传输网中的研究与设计[J].电子科技,2013(6):1-3.
[17]邱春婷,刘红彦,齐静.一种改进的Canny边缘检测方法[J].纺织高校基础科学学报,2014,27(3):380-384.
The design of buffered crossbar switches
ZHOU Yan-peng,ZHANG Xing-ming
(National Digital Switching System Engineering and Technological R&D Center, Zhengzhou450002,China)
TN4
A
1674-6236(2017)19-0141-04
2016-08-02稿件编号201608010
周延鹏(1990—),男,河南洛阳人,硕士研究生,讲师。研究方向:芯片设计。
