电子作业相似性检测技术的研究与实现
2017-10-12张海腾冷春霞
张海腾,翟 洁,冷春霞
(华东理工大学 信息科学与工程学院,上海200237)
电子作业相似性检测技术的研究与实现
张海腾,翟 洁,冷春霞
(华东理工大学 信息科学与工程学院,上海200237)
随着作业数据的电子化,为了能够更好地监督学生的抄袭行为,本文研究了电子作业相似性检测的相关技术,分析了作业检测的流程,给出了文本内容提取、中文分词、文本特征提取和文本相似性计算4个部分的关键技术和实现算法,并在此基础上开发了一个作业相似性检测系统,实现了对作业文档的对比和检测,系统的实现为将来作业电子化进一步发展提供了技术指导和理论依据。
电子作业;相似性;文本检测;作业抄袭
Abstract:With the electronic of student homework,in order to better monitor the students'copying behavior, this paper studied the related technologies of similarity detection in electronic work, analyzed the work flow of electronic homework similarity detection,and presented the key technologies of text content extraction, Chinese word segmentation, text feature extraction and text similarity calculation.On the basis of this,a homework similarity detection system was developed to implement the comparison and detection of the homework documents,the realization of the system provided the technical guidance and theoretical basis for the better development of the electronic homework in the future.
Key words:electronic homework; similarity; text detection; plagiarism
作业是老师检验学生学习效果的一种重要手段,当前随着网络的不断普及,大学教学当中,老师和学生之间作业的互动模式也产生了很大的变化,很多时候,学生的作业不再需要手工书写去完成,而是借助于各种电子写作工具去完成,学生提交作业不再是手工提交,而是借助于各种作业管理平台进行在线提交[1]。但是,随着师生之间作业互动模式发生变革的同时,也产生了一些新的问题,一些学生会以其他学生的作业文档作为模板,只做少量甚至不做修改就交给老师,这种行为严重地影响了老师的教学效果,对学生自身的学习也是有害的。
综上所述,在当今的信息时代,如何针对作业大数据进行相似性检测成为了一个重要的研究课题,也是提高高校教育教学效率和质量的一个重要课题[2]。因此,针对上述问题,设计一个电子作业相似性检测系统,实现对学生的作业相似性进行自动比对,这样一方面能够帮助教师从大量作业中找出有抄袭嫌疑的作业对象,减轻教师的工作负担,提高教师工作效率;另一方面,作业相似性检测系统的使用也可以较好地遏制学生抄袭作业的行为,促进学生去独立完成作业,对提高学生的学习成绩也有很大的帮助。
1 检测流程
实现作业相似性检测的主要目的就是针对一个作业集当中的作业进行两两比对,度量两个文档内容之间的相关程度,并用一个具体的数值量化这两个文档间的相似性。相似性越高,表示这两个作业中共同的元素越多,作业抄袭的可能性就越大,反之,相似性越低,则表示这两个作业文档的内容重复性较少,作业抄袭的可能性就越小。
实现作业相似性检测的工作流程如图1所示。首先要提取出作业文本中的主要内容,并对这些文本进行分词操作,切割出文档中的关键词语,统计出有效的关键词作为文本的特征项,然后计算出这些特征项的权重,并利用信息模型领域广泛使用的向量空间来表示文本的内容,文本就可以被看作是由一组互相独立的词项组成的向量空间集,每个文本被表示成文本特征项及相应权重所组成的一个向量,这样通过向量间距离的计算就可以求得两个文本之间的相似性。
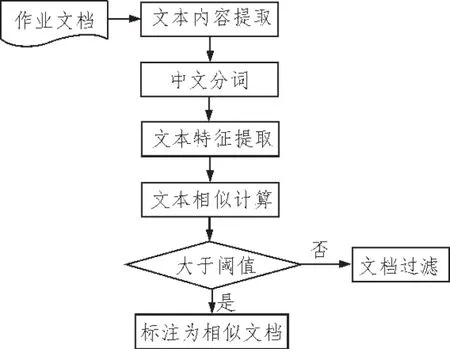
图1 作业相似性检测流程图
2 技术实现
2.1 文本内容提取
对于作业文本,相似性检测的首要工作就是要提取出相应电子文本的正文内容,这是文本相似性检测的前提。要想提取文本的主题内容就必须首先分析文本内容的语法结构。实际操作中,学生提交的作业,一般是两种类型的文档,一种是Word文档,一种是PDF文档。
Word文档中包含了一系列可操作的对象库,例如,Application对象用来表示Word应用程序,Document对象用来表示当前文档,Paragraph对象用来表示选定的内容或者段落。了解了Word文档的这些可操作对象库以后,就可以通过操作不同的对象来对文档进行相应的操作。目前针对Word文档的读取操作主要采用第三方的Apache POI[3]组件,该组件是一个Apache的开源项目,它提供了API给Java语言,以实现对Microsoft的Office文档进行读写操作。
PDF文档也是常见的作业文档提交形式,如果要抽取它的文本内容,需要解析PDF文档的格式。PDF文档包含了多种对象类型,并且将文字、格式、字型、颜色以及独立于设备和分辨率的多种图形图像元素封装起来。对于PDF文档内容的提取,可以借助PDFBox[4]完成,PDFBox也是一个开源项目,它为开发人员读取和创建PDF文档提供了纯Java类库。它具有提取PDF文档的文本内容、对PDF文档文档进行加密和解密,将一个PDF文档切割成多个文档,将PDF文档转换成文本文档或者将文本文档转换成PDF文档等多个特性。
2.2 中文分词
中文分词是作业文本处理中的一个重要环节,分词的主要目的是采用某种技术和方法将指定的文本序列切割成有一个个具有独立意义的词语[5]。除此之外,中文分词还包括去除停用词、去除标点符号等多个方面的工作。
中文分词领域里广泛采用的方法是基于词典的分词方法[6]。该方法的基本思想是以汉语词典作为基础,采用一定的匹配策略将需要分词的作业文本串与词典当中的词条进行匹配,如果能在词典中匹配到某个字符串,就把相应的字符串切割出来[7]。本文在匹配时采取了正向扫描和最大匹配的策略。首先从左至右对作业文本中的字符串逐一进行扫描,取出文本中的第一个字,将这个字与词典中的词条进行匹配,查看该字是否存在于词典当中,如果不存在,则该字被舍弃掉,如果存在,则标记这个字,继续从文本中读出下一个字,与前面的字组成新词,并与词典中的词条再次匹配,依此类推,逐字增加,直到不能匹配到为止,这些字组成的最大匹配词被分割出来,一次分词结束。继续扫描剩余的文本内容,重复上面的操作,直到文本末尾,这样,作业文本中的词条被一个个切分出来。基于词典的分词方法实现起来较为简单,分词也较为准确,与其他方法比较具有较为明显的优点,因此本文中使用该方法完成作业文本内容的分词操作。
2.3 文本特征提取
作业文本相似性检测中,如果对两个完整的作业文本中的所有词条进行完全比对,计算的复杂度比较大,因此需要从待检测文档中抽取出最具有代表性的词条组成文本的特征项集合,这些特征项集合能够反映出整篇文本的内容和特点。实际操作中,文本特征提取的常用方法是:首先通过中文分词方法得到文档中的所有词条,剔除不必要的词,并计算每个词条的权重,当某些词条被赋予了较低的权重时,表示它们在整个文档中具有较少的代表性,不适合将这些词作为特征项,需要将这些词条从原始的特征空间当中剔除。通过这种方法,可以有效地降低特征空间的维数。
目前计算文档中词条权重最为广泛使用的方法是TF-IDF (Term Frequency-Inverse Document Frequency)方法[8],TF(Term Frequency)称为词频,指某个词条在给定文本中出现的频数,频数越高,表明该词条在给定文本中的重要性越大。IDF(Inverse Document Frequency)称为反文档频度,用来表示一个特定词条在整个文本集中出现的频数,该词条在文本集中出现的频数越高,则表示该词条的区分能力越弱[9]。本文中使用TF-IDF方法计算权重的公式为wi=tfi×idfi;其中wi表示文本中第i个特征项的权重,tfi表示第i个特征项在文本中的频数,idfi表示第i个特征项的反比文本频数。TF-IDF方法表明,如果某个词条在当前文本中出现的频数较高,而在整个文本集中出现的频数较低,说明这个词条表达该文本主题内容的能力越强[10]。
将特征项和特征项的权重综合起来,一个作业文档就可以表示为:D=(t1,w1;t2,w2;…;ti,wi;…;tn,wn),其中ti表示第i个特征项,wi表示ti在文档D中的权重值。 如果把 t1,t2,…ti,…tn,看作一个 n 维坐标系中的坐标轴,w1,w2,…,wi…wn是对应的坐标值,那么由 t1,t2,…ti,…tn分解得到的正交矢量组就构成了一个文档的向量空间。应用向量空间来表示作业文档,能够较为准确地体现出文档的特征,还能方便地用它来完成对文档的分类和聚类等工作,所以本文中采用向量空间模型来表示文本是较为理想的方法。
2.4 文本相似性计算
当把每个作业文本用特征项及其权重表示为一个向量空间后,作业文本相似性检测的问题就转换为了向量空间的运算问题[11]。两个文档内容间的相似性,可以借助于向量之间的距离来表示[12]。向量之间的距离通常用向量之间的内积或者夹角余弦值来度量[13]。
假设两个作业文本 D1(w11,w12,…w1i,…,w1n)和D2(w21,w22,…w2i,…,w2n),w1i表示文本 D1中特征项的权重,w2i,表示文本D2中特征项的权重,则两个文本的相似性用向量的内积来计算得到,公式为:也可以使用夹角余弦值计算得到,公式为
除此之外,还有一些采用其他的文档距离计算方法,如:数量积法、相关系数法、指数相似系数法、最大-最小法、几何平均最小法、算术平均最小法等,这些算法可以用来更好的改进文本相似度的计算结果[14]。
3 检测结果
基于以上技术的分析,本文基于JAVA EE[15]实现了一个B/S结构的电子作业相似性检测系统,当用户登录成功后,点击作业检测功能,出现作业检测页面如图2所示。用户可以在左右两侧分别提交需要进行相似性检测的两个文档,文档类型可以为Word或者PDF格式。文档提交后,系统可以自动提取出文档的内容,并显示出来。点击开始比较按钮后,系统开始进行文档的相似性检测,并显示出检测结果。如图2所示,文档中不相同的部分,用带下划线的文字在两个文档中显示出来。
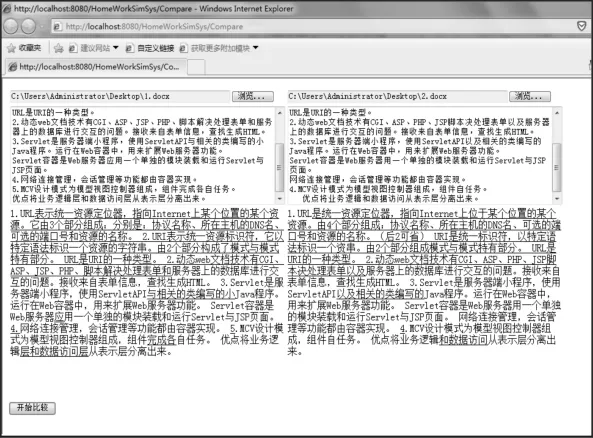
图2 作业相似性检测结果
4 结束语
本文分析了当前电子作业存在的问题,给出了电子作业相似性检测的工作流程,并对其中涉及到的关键技术,如文本内容提取、中文分词、文本特征提取和文本相似性计算方法进行了研究和探讨,最后综合运用以上技术实现了一个作业相似性检测系统,并给出了检测结果显示,为作业电子化的进一步发展提供了强有力的技术保障。
[1]冯凌凌,刘海霞.大数据环境下作业抄袭检测研究[J].考试周刊,2015(51):128-129.
[2]刘晓环,梁云,吴颖.自然语言文档复制检测技术研究[J].电信技术研究,2011(4):15-20.
[3]apache.The Apache POI project[EB/OL].http://poi.apache.org/,2012-02-01.
[4]牛永洁,薛苏琴.基于PDFBox抽取学术论文信息的实现[J].计算机技术与发展,2014,24(12):61-63.
[5]莫建文,郑阳,首照宇,等.改进的基于词典的中文分词方法[J].计算机工程与设计,2013,34(5):1802-1807.
[6]江华丽.中文分词算法研究与分析[J].物联网技术,2016,6(1):87-89.
[7]冯永,李华,钟将,等.基于自适应中文分词和近似SVM的文本分类算法[J].计算机科学,2010(1):251-254.
[8]王庆福,常广炎.基于TF-IDF优化算法在文本分类中的应用研究[J].电脑编程技巧与维护,2014(10):11-12.
[9]张瑾.基于改进TF-IDF算法的情报关键词提取方法[J].情报杂志,2014,33(4):153-155.
[10]张保富,施化吉,马素琴.基于TF-IDF文本特征加权方法的改进研究[J].计算机应用与软件,2011,2(2):17-20.
[11]赵华茗.分布式环境下的文档相似度研究与实现[J].现代图书情报技术,2011(7):14-20.
[12]薛苏琴,牛永洁.基于向量空间模型的中文文本相似度的研究 [J].电子设计工程,2016,24(10):28-31.
[13]胡伟伟,孙逊,王婷婷.基于向量空间模型的项目申报书查重系统设计[J].天津科技,2015,42(8):33-34.
[14]李连,朱爱红,苏涛.一种改进的基于向量空间文本相似度算法的研究与实现[J].计算机应用与软件,2012,29(2):282-284.
[15]王国辉.Java Web开发实战宝典[M].北京:清华大学出版社,2010.
Research and implementation on similarity detection of electronic homework
ZHANG Hai-teng, ZHAI Jie, LENG Chun-xia
(Academy of Information Science and Engineering,East China University of Science and Technology,Shanghai200237,China)
TN02
A
1674-6236(2017)19-0043-03
2016-08-03稿件编号201608026
上海市经济和信息化委员会软件集成电路专项资金(150809)
张海腾(1976—),女,山西孝义人,博士,讲师。研究方向:服务计算,智能学习。
