云环境下影响数据分布并行应用执行效率的因素分析
2017-09-22马生俊陈旺虎俞茂义李金溶郏文博
马生俊,陈旺虎,俞茂义,李金溶,郏文博
(西北师范大学 计算机科学与工程学院,兰州 730070) (*通信作者电子邮箱1780761723@qq.com)
云环境下影响数据分布并行应用执行效率的因素分析
马生俊*,陈旺虎,俞茂义,李金溶,郏文博
(西北师范大学 计算机科学与工程学院,兰州 730070) (*通信作者电子邮箱1780761723@qq.com)
云环境下,类似MapReduce的数据分布并行应用被广泛运用。针对此类应用执行效率低、成本高的问题,以Hadoop为例,首先,分析该类应用的执行方式,发现数据量、节点数和任务数是影响其效率的主要因素;其次,探讨以上因素对应用效率的影响;最后,通过实验得出在数据量一定的情况下,增加节点数不会明显提高应用的执行效率,反而极大地增加执行成本;当任务数接近节点数时,应用的执行效率较高、成本较低。该结论为云环境中类似MapReduce的数据分布并行应用的效率优化提供借鉴,并为用户租用云资源提供参考。
云环境;数据分布并行应用;MapReduce;效率;成本
0 引言
随着互联网应用的蓬勃发展,大数据时代已经到来[1]。数据来源广而快,数据量庞大而多样,常规的处理方法已很难满足需求,云计算(Cloud Computing)应运而生。云计算理论上可以提供无穷的计算能力和存储能力,用户按需租用供应商提供的计算资源和存储资源[2],如Google、Amazon、IBM、百度、腾讯、阿里巴巴等拥有各自的云环境租给用户执行计算和存储等操作。在云环境中,提供给用户的计算资源和存储资源通常对应一定数量和类型的节点,节点类型限定了其处理能力、吞吐量、单位时间的费用等特性[3]。
作为用户,在任务完成的基础上,更重要的是关心如何节省费用和时间以减少租用成本保障自身的利益。比如说,如何花费最少的时间和金钱完成最多的应用。然而,用户执行应用、处理数据时,一方面,要求执行时间短,就应该租用较多的节点并发地执行,若节点数过多且数据量过小,可能造成资源利用率的降低,增加资源使用成本;另一方面,要求花费金钱少,就应该租用较少的节点,若节点数过少且数据量过大,将导致任务执行时间延长,同样增加最终执行成本[4]。可见,对用户来说,执行时间和处理费用是一对矛盾体,很难达到“既要马儿跑又叫马儿不吃草”的目标;但用户确实存在这样的需求,如何尽量满足用户的这种需求?为此,应该着眼于应用的执行效率,提高每个节点的利用率,租用适当的节点数以降低执行成本、满足用户需求。
如何提高应用的执行效率、减少执行成本已成为一大研究热点,而分析影响应用执行效率和执行成本的各类因素及其内在关系至关重要。本文以Hadoop为例,重点分析云环境中影响数据分布并行应用执行效率的因素,探讨因素间的关系及对应用执行效率产生的影响;通过实验,给出各因素间的变化规律;总结实验结果,试图发现如何确定适当个数的节点以提高应用的执行效率、降低执行成本的结论。
本文的主要贡献:1)初步探索了在云环境中影响数据分布并行应用执行效率和租用成本的数据量、节点数、任务数等因素及其相互关系。2)根据各因素的变化规律,发现数据量一定时,增加节点数不会明显提高应用的执行效率,反而极大地增加了执行成本;任务数接近节点数时,应用的执行效率较高、成本较低。
1 相关工作
云计算作为一种新的计算模式以其自身的特点和优势被广泛地应用,如何提高资源利用率、降低应用执行时间已成为一个研究的热点。针对该问题,目前已开展了许多研究,主要涉及文献[5-14]等。
文献[5]针对由物理机和虚拟机混合组成的异构云环境进行Hadoop性能测试,得出由于虚拟机的高IO开销,导致Hadoop的性能相比传统的纯物理节点集群急剧降低。该文献采用不同的数据量进行测试;但没有考虑节点数和任务数的变化对固定数据量执行时间的影响。文献[6]通过在OpenStack云平台搭建Hadoop集群测试影响应用执行性能的因素,得出数据量的大小和集群规模是影响应用性能的主要因素;该文献采用任务数的默认个数,没有考虑在数据量和节点数一定时任务数的变化对应用执行性能的影响。文献[7]通过Amazon EC2(Elastic Compute Cloud)两种不同类型的虚拟机在Hadoop集群中测试Wordcount、TeraSort、Grep等多种应用,得出集群节点数的增加可提高应用执行效率,降低执行时间;该文献考虑了节点数的变化对应用性能的影响,但没有考虑数据量和任务数的变化对应用性能的影响。文献[8]针对当前对数据中心网络拓扑的研究主要集中在如何提高性能上,然而忽略了数据中心网络拓扑与云计算机制的相适应问题,设计了一种支持云计算的数据中心网络拓扑;该文献着眼于数据中心的网络拓扑,提出只有拓扑结构和云计算机制相匹配的数据中心网络才能更好地满足需求。文献[9]针对作业过程中数据传输和数据处理流程,提出了虚拟网络拓扑结构的优化机制,减少了数据传输和处理的总开销,提高了MapReduce云框架处理大数据的整体性能。文献[10]针对数据重分布,充分利用map/reduce空闲、开发新的混合路由表等方面对MapReduce进行扩展提出了“XMR”(eXtensible-MapReduce)模型,应用性能得到了提高。文献[11]针对Hadoop中处理小文件的4种方法(TextInputFormat默认输入格式、为处理小文件而设计的CombineFileInputFormat输入格式、SequenceFile和Harballing技术)通过Wordcount应用测试多种典型的数据集(信息科学方面的数据集、航空方面的数据集、图书馆科学方面的数据集等)得出四种处理方法对应用性能的影响。文献[12]根据实时作业的特性,针对Hadoop自带的调度器不能有效支持实时作业,设计了新的实时调度器,其核心是通过修改作业的优先级算法,让更多作业能在截止期前完成。文献[13]归纳Hadoop集群使用到的参数,分析云计算工作流程中的参数,使参数和流程一一对应,寻找出可以作为性能参数的参数值,通过启发式算法进一步得到最佳参数组合,以提高Hadoop云计算平台的性能。文献[14]通过分析比较Hadoop现有的排序算法,发现频繁的磁盘读写是降低数据处理效率的主要原因,为此优化现有的排序算法,提出了置换选择算法,使得效率有了一定的提升。文献[9-14]分别针对影响MapReduce应用的内部机制作了相应的处理,使得应用效率有一定的提高。
云环境中,有非常多的因素影响数据分布并行应用的执行效率。上述研究中,考虑了很多影响因素,如异构集群环境、内部处理机制、网络拓扑和带宽、集群规模及数据集类型等因素,但是没有综合考虑节点数、数据量、任务数对应用执行效率的影响。文中重点关注节点数、数据量和任务数等因素对数据分布并行应用执行效率的影响,为用户确定适当个数的节点以提高执行效率、降低执行成本提供参考。
2 影响因素分析
为满足用户使用较少的成本处理较多数据的需求,不得不考虑云环境中数据的存储和计算方式。下面从存储和计算两方面探讨用户数据在云环境中的处理方式。一般地,用户数据量会比较大,通常在TB的级别,甚至会更大,单个节点无法存储足如此大规模的数据[15],更别说进行其他操作。
显然,用户面临的首要问题是如何完成大规模的数据的安全存储,这就要求用户不得不借助数据分布存储技术将数据分布存储在云中的多个节点上。云环境中广泛使用的数据分布存储技术是Google的GFS(Google File System)[16]和Hadoop团队开发的HDFS(Hadoop Distributed File System)[17]。例如,Hadoop-HDFS将数据物理地分割成固定大小(默认是64 MB)的多个数据块(Block),采用冗余备份机制为每个Block创建多个副本(默认是3)保证数据完整性,并将这些副本尽可能分散地存储在所有节点上。完成数据的存储之后,用户面临的问题便是如何处理存储在多个节点上的数据,这就要求用户不得不借助数据并行处理技术并行地处理数据。MapReduce编程模型是云环境中被广泛使用的并行处理框架,其主要实现有Hadoop的MapReduce[17]、Google的MapReduce[18]和斯坦福大学的Phoenix[19]。以Hadoop-MapReduce为例,其采用Map-Reduce的思想即“分解归约”,将分散存储的数据逻辑地划分成多个分片(Splits),为每个Split创建一个map任务,最后通过reduce任务把所有map任务的输出作整合处理。
综上,将云环境中处理数据的过程概括为两步:第一步,借助数据分布存储技术把数据物理地分割成固定大小的多个Blocks,以Block为单位在各节点上分散地存储数据;第二步,借助数据并行编程和计算框架将数据逻辑地划分成多个Splits,以Split为单位在各节点上并行地处理数据。显然,Block是节点上存储数据的基本单位,Split是节点上处理数据的基本单位。可以发现用户处理的数据量大小、租用的节点个数和划分的任务个数等因素是影响应用执行效率的主要因素;同时,在上述两步处理过程中伴随着大量的数据移动,所以在云环境中网络拓扑和带宽是影响执行效率的另一个主要因素。用户处理数据过程如图1所示。
在并行计算中,任务的总消耗时间由计算时间和额外开销组成,进程间数据的传输时间是主要的额外开销[20]。同样,在云计算环境中应用的总消耗时间主要来源于任务计算时间和数据传输时间。用户按需租用不同数量和类型的节点,为每个节点付出一定的费用。因此,在云环境中用户租用节点处理数据所需主要的时间T和费用M可表示为:
(1)

(2)
其中:s表示平均在每个节点上处理的任务数,tmr(i)表示执行第i个任务需要的计算时间;b表示传输数据的次数,tio(j)表示第j次传输需要的时间;n表示租用的节点总数,m(k)表示第k个节点的租用费用。
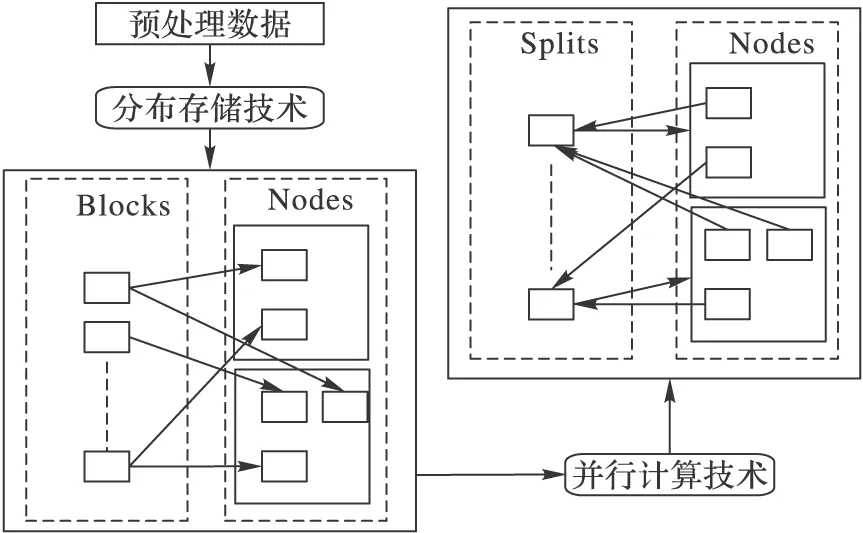
图1 云环境中数据处理过程
根据式(1)可知,用户要减少数据处理时间,就从以下几方面考虑:1)增加节点数量,提高任务的并行性;2)减少数据量,减少任务处理和数据传输的次数;3)租用较高性能的节点,减少每次任务执行的时间;4)改进网络拓扑,增加网络带宽,减少每次数据传输时间;5)提高节点利用率,以减少时间。根据式(2)可知,用户要降低租用节点费用,就该减少租用节点数量。
然而,在实际中处理的数据量是不能被缩减的;用户又不情愿增加费用租用更多的节点;每种类型的节点性能是一定的;网络拓扑和带宽是云环境中制约通信能力的瓶颈:可见,提高节点利用率增强应用执行效率是满足用户需求最为有效的途径。作为用户,如何确定适当的节点数,且最大限度地提高节点的利用率是亟待解决的问题。下面就从数据量D、节点数N、任务数S三者间的关系讨论用户该如何抉择。
1)节点数N和任务数S一定时:
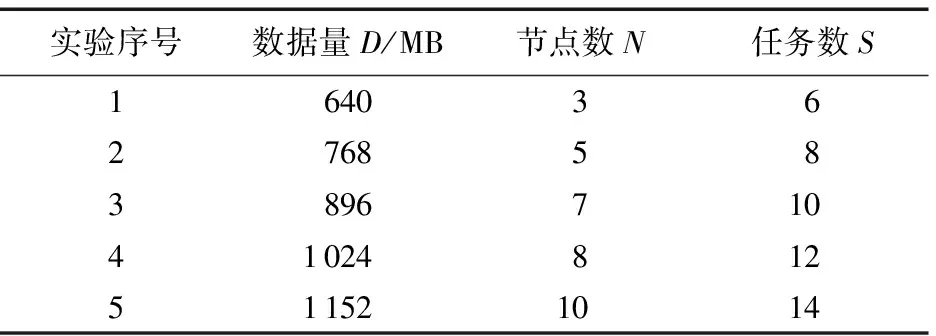
数据量D越多,根据式(1),计算次数不变,但每次tmr时间越多;传输次数不变,但每次传输内容越多,tio越多,进而消耗的总时间T越多。
数据量D越少,根据式(1),计算次数不变,但每次tmr时间越少;传输次数不变,但每次传输内容越少,tio越少,进而消耗的总时间T越少。
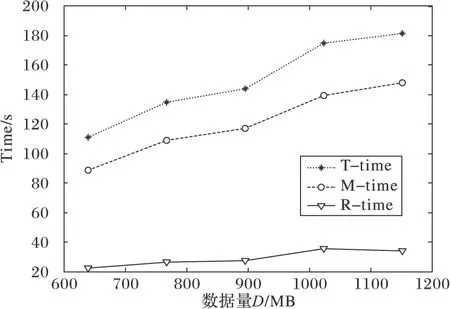
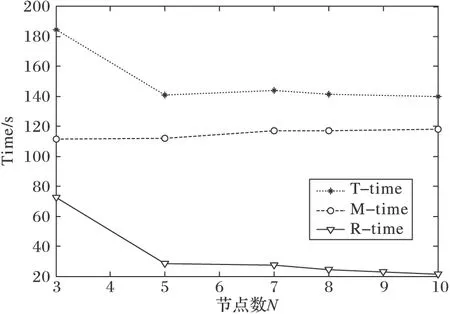
2)数据量D和任务数S一定,且节点数N满足0 节点数N越多,根据式(1),每次tmr时间一定,但每个节点计算的次数减少;传输次数越小,tio时间越少,进而消耗的总时间T就越少。 节点数N越少,根据式(1),每次tmr的时间一定,但每个节点计算的次数减多,传输次数越多,tio时间越少,进而消耗的总时间T就越多。 3)数据量D和节点数N一定时,且任务数S满足0 任务数S越多时,根据式(1),计算次数越多,tmr时间越多,传输次数越多,tio时间越多,进而消耗的总时间T就越多。 任务数S越少时,根据式(1),计算次数越少,tmr时间越少,传输次数越少,tio时间越少,进而消耗的总时间T就越少。 3.1 实验平台 实验中的硬件设备为10台联想ThinkServer RD650服务器即10个节点(Nodes),其中1个为Namenode,其余都为Datanode。所有Node的硬件配置是Genuine Intel处理器、32 GB内存、2 TB硬盘。所有节点都是CentOS 7.0操作系统,JDK 1.7.0_45 JDK环境,Hadoop 2.5.2云框架。 由于文中主要探索数据量、节点数、任务数对应用性能的影响,为了尽量降低网络拓扑和带宽对实验的影响,在实验环境中,将10台服务器连接在一台普联TL-SG1024DT千兆机架式交换机上形成一个局域网,网络带宽为1 000 Mb/s,网络拓扑如图2所示。 图2 实验环境网络拓扑 3.2 实验设计 实验用于验证数据量、节点数和任务数对应用完成时间的影响,所以实验以最简单也是最能体现MapReduce思想的单词计数Wordcount程序作为测试应用。 实验数据来源于100本英文txt类型的书籍,将所有内容拷贝到单个txt文件,通过多次复制得到实验要求的数据量D;节点数根据实验要求启动相应个数的Datanode来控制节点数N的变化,且每次重启时须重新上传数据;任务数可修改文件(mapred.site.xml)中mapred.min.split.size的大小得到实验要求的任务数S。其他都采用默认配置,如Reduce任务数为1,Block固定大小为64 MB,Block备份数为3。 实验中各个变量变化如表1所示。 表1 各因素变化 3.3 实验结果 根据3.2节实验设计,采用控制变量的方法进行实验。实验中,数据量D、节点数N、任务数S,当其中一个因素的值从序号1的值变化到序号5的值时,其他两个因素的值取序号3的值保持不变,且每次实验都进行3遍,求其平均数得到Map和Reduce任务的执行时间即M-time(Map-time)和R-time(Reduce-time),对M-time和R-time求和得到总执行时间T-time(Tittle-time)。分别得到如下实验结果(时间单位为ms)。 1)当节点数N=7和任务数S=10时,随着数据量D的变化,得到实验结果如表2所示。 2)当数据量D=896 MB和任务数S=10时,随着节点数N的变化,得到实验结果如表2所示。 3)当数据量D=896 MB和节点数N=7时,随着任务数S的变化,得到实验结果如表2所示。 表2 不同D、N、S时的实验结果 ms 3.4 因素间关系分析 根据3.3节得到的实验结果,可以发现: 1)节点数N=7和任务数S=10时,随着数据量D的变化,应用的M-time、R-time和T-time分别呈现如图3所示的变化趋势。 图3 数据量D对执行时间的影响 根据图3明显地发现当节点数和任务数一定时,随着数据量的增大,T-time呈递增趋势,符合在第2章中对各因素的分析。特别地,随着数据量的变化,M-time变化明显,而R-time无明显的变化趋势,因此,为了降低应用的执行时间,当数据量很大时,用户应租用较多的节点。 2)数据量D=896 MB和任务数S=10,且节点数N满足0 根据图4发现当数据量和任务数一定时,随着节点数的增大,T-time呈递减的趋势,符合在第2章中对各因素的分析。特别地,随着节点数的增多,R-time的变化趋势是先骤变后缓慢地变化,而M-time无明显的变化趋势,因此,为了降低应用的执行时间,当数据量一定时,用户应租用适当个数的节点,并非节点数越多执行效率越高。 3)数据量D=896 MB和节点数N=7,且任务数S满足0 图4 节点数N对执行时间的影响 图5 任务数S对执行时间的影响 根据图5明显地发现当数据量和节点数一定时,随着任务数的增大,T-time整体呈递增趋势,符合在第2章中对各因素的分析。特别地,数据量和节点数数保持不变的情况下,随着任务数的增多,M-time和R-time都呈缓慢递增的趋势;可以发现,任务数接近节点数时应用的执行时间处于较小,因此,为了降低应用的执行时间,用户应使任务数接近节点数,以便提高资源利用率。 在云环境中影响数据分布并行应用执行效率和执行成本的因素很多。文中针对类似MapReduce数据分布并行编程模式下的数据分布存储技术和并行编程模型,详细分析了云环境中影响该类应用执行效率和执行成本的数据量、节点数和任务数等因素;探讨了数据量、节点数、任务数间的关系以及对应用执行效率和执行成本的影响;采用Hadoop云框架验证了文中对各影响应用执行效率和执行成本的因素分析符合实验结果;同时,分析实验结果总结如下:1)数据量越大时,节点数越多应用执行的效率较高;2)数据量一定时,并非节点数越多应用执行效率越高;3)任务数接近节点数时,执行应用的效率较高。 本文工作可以作为研究云环境中影响类似MapReduce的数据分布并行应用执行效率和执行成本因素的一个重要基础;为类似MapReduce的数据分布并行编程模式的研究和用户租用云资源提供一个参考。下一步,将更进一步地分析和探讨影响执行效率和成本的因素——网络拓扑和带宽,尽可能全面地分析各种因素对应用执行性能和执行成本的综合影响,通过实验总结出近似最优的解决方案。 References) [1] 冯登国,张敏,李昊.大数据安全与隐私保护[J].计算机学报,2014,37(1):246-258.(FENG D G, ZHANG M, LI H. Big data security and privacy protection [J]. Chinese Journal of Computers, 2014, 37(1): 246-258.) [2] VAQUERO L M, RODERO-MERINO L, CACERES J, et al. A break in the clouds: towards a cloud definition [J]. ACM SIGCOMM Computer Communication Review, 2008, 39(1): 50-55. [3] JIANG D, PIERRE G, CHI C H. EC2 performance analysis for resource provisioning of service-oriented applications [C]// NFPSLAM-SOC 2009: Proceedings of the 3rd Workshop on Non-functional Properties and Service Level Agreements Management in Service Oriented Computing. Berlin: Springer, 2010: 197-207. [4] BYUN E K, KEE Y S, KIM J S, et al. BTS: resource capacity estimate for time-targeted science workflows [J]. Journal of Parallel & Distributed Computing, 2011, 71(6): 848-862. [5] 刘丹丹,陈俊,梁锋,等.云计算异构环境下Hadoop性能分析[J].集成技术,2012,1(4):46-51.(LIU D D, CHEN J, LIANG F, et al. A performance analysis for Hadoop under heterogeneous cloud computing environments [J]. Journal of Integration Technology, 2012, 1(4): 46-51.) [6] AHMAD N M, YAACOB A H, AMIN A H M, et al. Performance analysis of MapReduce on OpenStack-based Hadoop virtual cluster [C]// ISTT 2014: Proceedings of the 2014 IEEE 2nd International Symposium on Telecommunication Technologies. Piscataway, NJ: IEEE, 2014: 132-137. [7] GOHIL P, GARG D, PANCHAL B. A performance analysis of MapReduce applications on big data in cloud based Hadoop [C]// ICICES 2014: Proceedings of the 2014 International Conference on Information Communication and Embedded Systems. Piscataway, NJ: IEEE, 2015: 1-6. [8] 丁泽柳,郭得科,申建伟,等.面向云计算的数据中心网络拓扑研究[J].国防科技大学学报,2011,33(6):1-6.(DING Z L, GUO D K, SHEN J W, et al. Researching data center networking topology for cloud computing [J]. Journal of National University of Defense Technology, 2011, 33(6): 1-6.) [9] 李立耀,赵少卡,许华荣.基于云平台的MapReduce性能优化策略[J].兰州大学学报(自然科学版),2015,51(5):752-758.(LI L Y, ZHAO S K, XU H R. MapReduce performance optimization strategy based on a cloud platform [J]. Journal of Lanzhou University (Natural Sciences), 2015, 51(5): 752-758.) [10] PREMCHAISWADI W, ROMSAIYUD W. Optimizing and tuning MapReduce jobs to improve the large-scale data analysis process [J]. International Journal of Intelligent Systems, 2013, 28(2): 185-200. [11] 李三淼,李龙澍.Hadoop中处理小文件的四种方法的性能分析[J].计算机工程与应用,2016,52(9):44-49.(LI S M, LI L S. Performance analysis of four methods for handing small files in Hadoop [J]. Computer Engineering and Applications, 2016, 52(9): 44-49.) [12] 杨浩.Hadoop平台性能优化的研究与实现[D].成都:西南交通大学,2015:25-37.(YANG H. Research and implementation of Hadoop platform performance optimization [D]. Chengdu: Southwest Jiaotong University, 2015: 25-37) [13] 王春梅,胡玉平,易叶青,等.Hadoop云计算平台的参数优化算法[J].华中师范大学学报(自然科学版),2016,50(2):183-189.(WANG C M, HU Y P, YI Y Q, et al. Cross layer parameter optimization algorithm for Hadoop cloud computing platform [J]. Journal of Central China Normal University (Natural Sciences), 2016, 50(2): 183-189.) [14] 李千慧,魏海平,窦雪英.基于Hadoop的排序性能优化研究[J].电子设计工程,2016,24(2):45-47.(LI Q H, WEI H P, DOU X Y. Optimization of sorting performance based on Hadoop [J]. Electronic Design Engineering, 2016, 24(2): 45-47.) [15] PRINCE J D. Introduction to cloud computing [J]. Journal of Electronic Resources in Medical Libraries, 2011, 8(4): 449-458. [16] GHEMAWAT S, GOBIOFF H, LEUNG S T. The Google file system [J]. ACM SIGOPS Operating Systems Review, 2003, 37(5): 29-43. [17] WHITE T, CUTTING D. Hadoop: The Definitive Guide [M]. 4th ed. Sebastopol: O’Reilly Media, 2012: 1-4. [18] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(1): 107-113. [19] GORDON A W, LU P. Elastic phoenix: malleable MapReduce for shared-memory systems [C]// NPC 2011: Proceedings of the 8th IFIP International Conference on Network and Parallel Computing. Berlin: Springer, 2011: 1-16. [20] WOOD D A, HILL M D. Cost-effective parallel computing [J]. Computer, 1995, 28(2): 69-72. This work is supported by the National Natural Science Foundation of China (61462076). MAShengjun, born in 1989, M. S. candidate. His research interests include big data and cloud computing. CHENWanghu, born in 1973, Ph. D., professor. His research interests include big data and cloud computing. YUMaoyi, born in 1991, M. S. candidate. His research interests include big data and cloud computing. LIJinrong, born in 1989, M. S. candidate. Her research interests include big data and cloud computing. JIAWenbo, born in 1992, M. S.candidate. His research interests include big data and cloud computing. Analysisoffactorsaffectingefficiencyofdatadistributedparallelapplicationincloudenvironment MA Shengjun*, CHEN Wanghu, YU Maoyi, LI Jinrong, JIA Wenbo (CollegeofComputerScienceandEngineering,NorthwestNormalUniversity,LanzhouGansu730070,China) Data distributed parallel applications like MapReduce are widely used. Focusing on the issues such as low execution efficiency and high cost of such applications, a case analysis of Hadoop was given. Firstly, based on the analyses of the execution processes of such applications, it was found that the data volume, the numbers of the nodes and tasks were the main factors that affected their execution efficiency. Secondly, the impacts of the factors mentioned above on the execution efficiency of an application were explored. Finally, based on a set of experiments, two important novel rules were derived as follows. Given a specific volume of data, the execution efficiency of a data distributed parallel application could not be improved remarkably only by increasing the number of nodes, but the execution cost would raise on the contrary. However, when the number of tasks was nearly equal to that of the nodes, a higher efficiency and lower cost could be got for such an application. The conclusions are useful for users to optimize their data distributed parallel applications and to estimate the necessary computing resources to be rented in a cloud environment. cloud environment; data distributed parallel application; MapReduce; efficiency; cost TP301; TP393.027 :A 2017- 01- 16; :2017- 03- 11。 国家自然科学基金资助项目(61462076)。 马生俊(1989—),男,甘肃广河人,硕士研究生,主要研究方向:大数据与云计算; 陈旺虎(1973—),男,甘肃静宁人,教授,博士,CCF会员,主要研究方向:大数据与云计算; 俞茂义(1991—),男,安徽铜陵人,硕士研究生,主要研究方向:大数据与云计算; 李金溶(1989—),女,山东肥城人,硕士研究生,主要研究方向:大数据与云计算; 郏文博(1992—),男,江苏丰县人,硕士研究生,主要研究方向:大数据与云计算。 1001- 9081(2017)07- 1883- 05 10.11772/j.issn.1001- 9081.2017.07.18833 实验分析



4 结语
