基于深度学习方法的句子及语素边界划分研究
2017-09-20TolegenGulmira邬春学
Tolegen Gulmira,邬春学
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于深度学习方法的句子及语素边界划分研究
Tolegen Gulmira,邬春学
(上海理工大学 光电信息与计算机工程学院,上海 200093)
针对哈萨克语的句子、单词及语素边界检测问题,文中提出了一种基于深度学习的边界检测方法:CNN-TSS模型。通过将边界检测问题视为序列标注任务,将句子、单词及语素的边界检测合并为一种任务完成。通过对CNN-TSS模型选取最优超参数,对不同语言进行了测试。实验结果表明,该模型在不使用额外特征的情况下,在性能上超过了基于传统方法的边界检测系统。
句子边界检测;语素边界检测;黏着语;深度学习
句子、单词及语素边界划分任务是词性标注[1]、机器翻译、篇章理解等自然语言处理(Natural Language Processing,NLP)任务的基础研究之一。该任务的主要目的是自动找出文本中句子、单词、语素的左右边界,使得处理后的文本可以用于其他的NLP任务当中。虽然在NLP研究中,所采用的语料都已经经过了人工标注和划分,当语料库添加其他新领域文本时,则首先需要对源文本做分句和分词等处理,如果分句和分词模型准确率比较高,则会有利于其他后续工作的开展。而且多数NLP应用在实际使用时,通常首先就需要对原文本进行分句和分词等处理。所以实现一种准确率较为理想的分句、分词模型是NLP任务的关键之一。
句子的边界通常由句号、问号、感叹号和省略号等符号来表示,然而这些符号使用会出现歧异,例如在英语的缩写词当中就会使用与句号等符号,这对句子边界的划分带来一定困难。此外,对英语及黏着语(Agglutinative Language)来说,如哈萨克语(Kazakh),土耳其语 (Turkish),虽然这些语言的单词边界可以通过空格来识别,但是有些复杂的形态结构的单词,在实际中,需要将其分为两个标示符(token)来看待,因为黏着语的构词法是通过对词根缀加不同后缀而形成,不同的后缀有一定的语义和语法功能,所以这将会有利于语法分析、文本对齐、机器翻译等任务的进行。
针对哈萨克语的句子、单词及语素边界划分问题,本文提出了基于深度学习方法的边界划分模型。并将句子、单词及语素边界划分任务作为一种序列标注任务一次完成[2]。本文中实现了基于字符的句子及语素边界划分模型(Character Neural Networks for Token and Sentence Segmentation, CNN-TSS),简称CNN-TSS模型。为有效评估CNN-TSS模型的性能,本文首先对哈萨克的句子,语素边界划分任务进行了测试,而且在其他语言上与已有的工作进行了系统的比较。
1 相关工作
通常,句子、单词及语素边界划分任务作为独立不同的任务来完成,但为了进一步提高模型的准确率,可以共享不同任务的信息,即作为一种任务来解决。一般有两种解决方法:第一种是基于规则的方法;另一种是基于机器学习的方法。前者[3-4]需要大量的人工编写的正则表达式规则,通过匹配规则达到边界划分效果。但该类方法在性能,可扩展性及适用性上都比较弱,对新领域语料需要重新设计和编写规则。后者通常分为两种:有监督学习和无监督学习方法的边界检测模型。文献[2]提出了独立于语言特征的基于无监督学习方法的句子边界识别模型- Punkt系统。该系统主要包含了两个检测阶段,即缩写检测和标示符分类阶段。从实验结果来看,Punkt 在分句任务上得到了比较理想的结果,超过了基于规则的方法。
目前已有的基于有监督学习方法的分句模型多数都使用了额外的特征集合,如在英文中使用单词大小写,缩写词列表等。模型主要采用了最大熵模型(Maximum Entropy Model)[7]和条件随机场(Conditional Random Field, CRF)模型[8]。文献[1]提出了基于CRF的句子及单词边界自动划分模型Elephant系统。该模型将每个字符视为标注单元,采用Unicode类别,Unicode编码,神经网络模型隐含层特征以及这些特征组合作为特征,在英语、意大利语及荷兰语上的分词和分句语料上进行了测试,并取得了比较好的结果。
为避免传统方法中所需要的特征工程,本文实现了基于深度学习方法的句子,单词及语素边界划分模型(CNN-TSS),而且在该模型中,本文将句子,单词及语素边界划分作为一种任务解决,并且在没有采用额外的特征的情况下,将其与上述的Punk和Elephant系统进行了比较。
2 IOB序列标注
IOB标注方案是NLP序列标注任务,如词性标注,命名实体识别等任务中常用的一种标注方案。本文使用了IOB标注方案来识别句子,词语和语素的边界。该方案包含了I、O、S、T标签,其中,S和T分别表示句子和token的开始边界。将token内部的字符标注为I,token外部的字符标注为O。这种标注方案的有利之处在于,不仅可以划分句子的开始和结束边界,也可以将一个单词根据所需要的需求划分为几个token。比如对英语单词didn’t来说,可以将其划分为两个token: did 和 n’t。 Table 1 给出了相应的IOB序列标注的例子。 这里将句子中的每一个字符标注为IOB标签的一个标签来区分句子和token的边界。

表1 IOB序列标注举例,每个字符对应于一个标签
3 基于字符的深度网络模型
在大多数NLP序列标注任务中,基于词的深度学习模型已经得到了广泛的使用[5]。 但本文对句子、单词及语素边界划分任务引入基于字符的深度学习模型,称其为CNN-TSS模型。该模型主要由基于窗口的字符映射层非线性层和输出层组成。
3.1 基于窗口的字符映射层
定义C为从训练集中收集的字符集合。其中每个字符xi∈C可以表示为一个d维向量Mxi∈R1×d。将C中的所有字符的向量存入字符嵌入矩阵中M∈Rd×|C|,其中|C|为字符集大小。每个字符xi∈C都有一个索引系数ki,该系数为字符xi的向量在字符嵌入矩阵中的位置。对输入的字符,输入层能将相应字符的向量提取出来表示为LTM(·)
LTM(ki)=Mxi
(1)
本文中采用了滑动窗口方法,定义w为窗口大小,则对w大小窗口的字符,输入层中得到的向量可以表示为
(2)

3.2 非线性层
非线性层是将前一层的输出作为输入,经过线性层的映射,并使用激活函数从原始的向量特征上进一步提取高维非线性特征的过程,其计算过程可以表示为
(3)
其中,σ为Tanh激活函数;W1为模型参数;b1为bias项;h为隐含层的输出。
3.3 输出层
模型的输出层将隐含层的输出作为输入,对当前窗口的中心字符计算出相应标签的概率,其可以表示为
Y(x,T,θ)=softmax(W2h+b2)
(4)
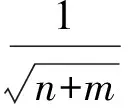
4 实验结果及分析
为测试CNN-TSS模型的性能,本文安排了两组实验:(1)分析不同超参数对模型性能的影响;(2)进行最终测试并与已有工作进行比较。实验中使用了精确率(Accuracy)作为评估模型的性能的指标。
4.1 实验数据
本文对不同语言进行了测试。对哈萨克语,本文人工标注了新闻语料,并将其作为训练和测试数据。此外,为了与已有系统进行比较,本文对英语和意大利语,分别使用了GMB[6]和PAISà[7]数据集,该数据与已有工作[1-2]所使用的数据完全一致,其数据为:训练集,验证集和测试集。验证集是用于模型和超参数的选择。表2给出了不同语言语料统计数据。
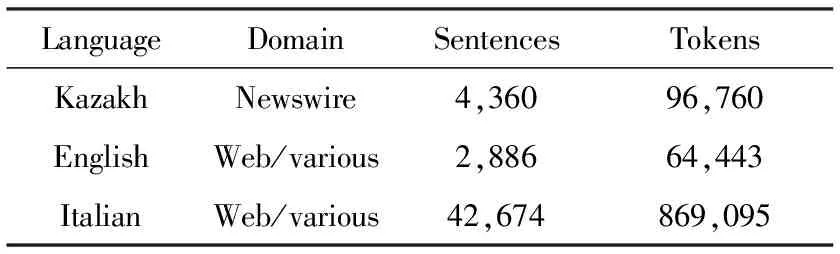
表2 IOB序列标注例子
4.2 超参数选择实验
CNN-TSS模型主要的超参数包括:学习速率,隐含层单元数量,模型窗口大小和字符向量大小。根据文献[12]实验结果表明,在深度学习模型中学习速率是比较敏感的超参数,可以将其他参数设置为较小值来调整模型的学习速率,会减少大部分调参数时间。对CNN-TSS模型,本文测试了不同的学习速率(1~0.000 1)。 表3给出了不同学习速率对模型性能的影响,并分别标签S,T及S+T+I计算了精确率,该实验中使用了哈萨克语语料。 其中,Dev和Test分别为验证集和测试集上的精确率。

表3 不同学习速率对模型性能的影响 /%
从表3中可以看出,当学习速率设为0.01时,模型的性能最高,小于或大于该值都会影响模型的性能。标签S的准确率比较低,其原因是其他超参数的值比较小的缘故。
表4给出了选择不同窗口大小对模型性能的影响,将学习速率固定为0.01,对3,5,7,9,11不同大小窗口进行了测试。
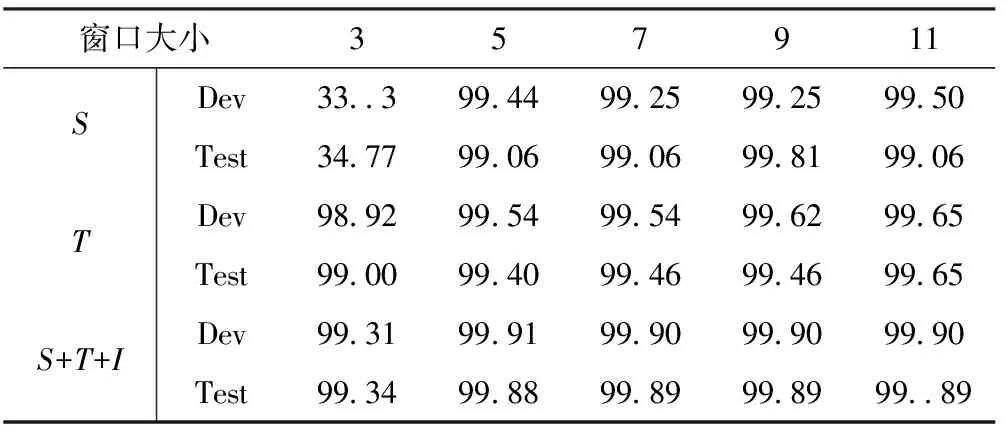
表4 不同窗口大小对模型性能的影响 /%
从表4中可以看出,模型的性能随着窗口大小的不断增大。对句子边界S标签,当取5为窗口大小时,其模型性能提升了60.05%,该结果表明,3个字符的信息量,不足以判断句子的边界,导致性能偏低。当窗口大小为9时,模型的性能相对较高。但当将窗口大小设为11时,标签S在测试集上的性能降低,结果表明,在句子边界划分上过大的窗口会将“噪声信息”也会包含进来导致错误。
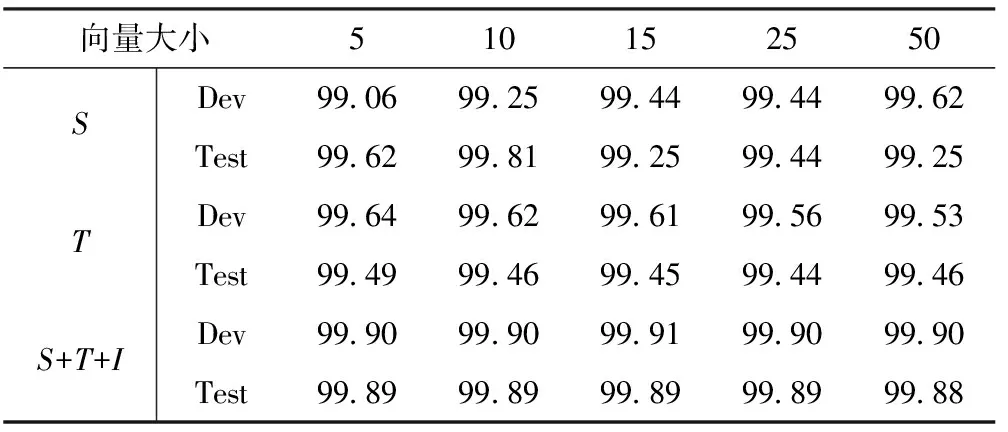
表5 不同字符向量大小对模型性能的影响 /%
表5给出了不同大小的字符嵌入向量对模型性能的影响,本文对(5~50)之间的向量大小进行了测试。可以看出,当将每个字符用10维的向量表示时,模型在测试集上的性能相对比较高。当增大字符嵌入向量大小后,没有带来明显的性能提升。
表6给出了不同大小的隐含层单元数量对模型性能的影响。可以看出,取50为隐含层单元数量时,在综合考虑S,T和S+T+I标签时性能相对较好。取太大的隐含层数量并没有对模型识别性能带来太大提升,并增加模型计算时间。
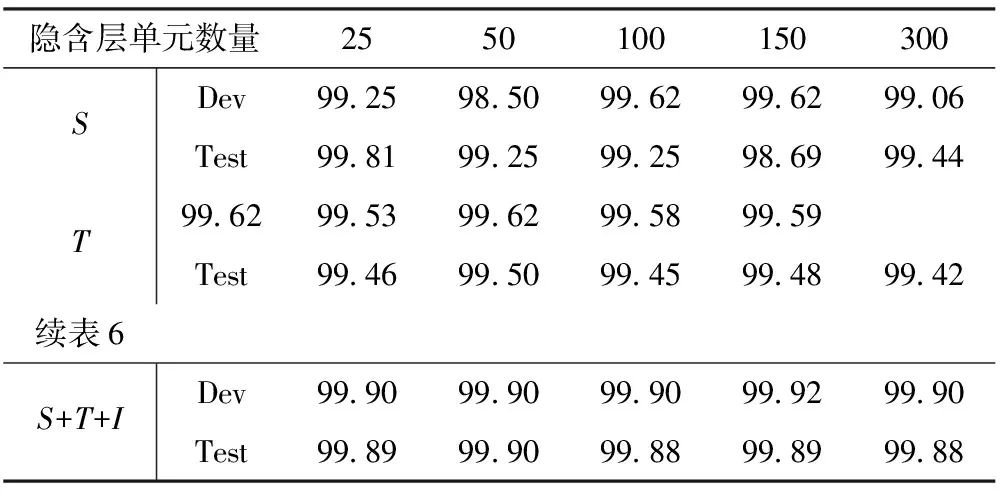
表6 隐含层单元数量对模型性能的影响 /%
通过上述实验结果,本文对CNN-TSS模型最终超参数进行了选择,如表7所示,并将其用于后续的实验中。

表7 CNN-TSS模型的超参数
4.3 实验结果
在选择超参数后,本文在哈萨克语语料上,训练了CNN-TSS模型,并进行了最终测试,其结果如表8所示。
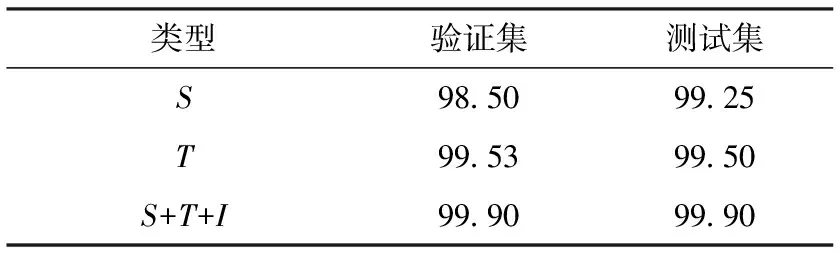
表8 CNN-TSS模型对哈萨克语的测试结果 /%
此外,为进一步验证CNN-TSS模型的性能,本文将其与已有的Punkt 和 Elephant系统进行了比较,如表9所示。实验结果表明,CNN-TSS模型均在英语和意大利语上,性能超过了已有的系统,而且该系统中使用了多种额外的特征集合。但CNN-TSS中只采用了上下文特征,实验结果表明本文提出的CNN-TSS模型对句子,单词及语素边界划分任务有较好的建模能力。
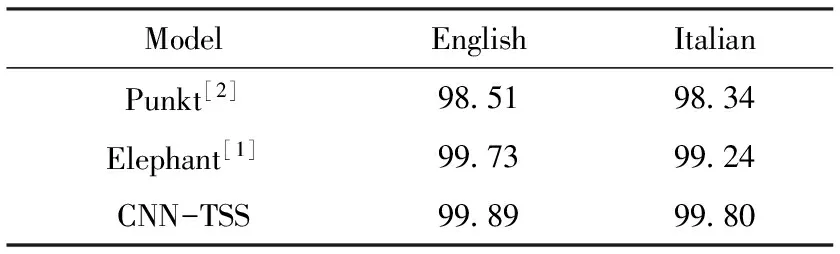
表9 CNN-TSS模型与其他系统的比较结果 /%
5 结束语
本文对哈萨克语的句子,单词及语素边界划分问题提出了基于深度学习方法的边界划分模型,称其为CNN-TSS模型。为了分析CNN-TSS模型性能,本文对超参数进行了选择,分析了不同超参数对模型性能的影响,实验结果表明,CNN-TSS模型在哈萨克语的句子、单词及语素边界划分任务上精确率达99.90%。
为进一步验证CNN-TSS模型的性能,本文与已有的模型在英语和意大利语上进行了比较。实验结果表明,CNN-TSS模型在没有使用额外任何特征的情况下,其性能均超过了传统模型,取得了较理想的结果。
[1] Evang K,Basile V,Chrupaxa G,et al.Elephant:sequence labeling for word and sentence segmentation[C].Washington,USA:In Proceedings of the Conference on Empirical Methods in Natural Language Processing,2013.
[2] Kiss T, Strunk J. Unsupervised multilingual sentence boundary detection[J]. Computational Linguistics, 2006, 32(4): 485-525.
[3] Jurafsky D, Martin J H. Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition[M]. Speech and Language Processing : Prentice Hall, 2000.
[4] Read J, Dridan R, Oepen S, et al. Sentence boundary detection: A long solved problem?[C].International Conference on Computational Linguistics,2012.
[5] Collobert R, Weston J, Bottou L, et al. Natural language processing (Almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537.
[6] Dridan R, Oepen S. Tokenization: returning to a long solved problem a survey, contrastive experiment, recommendations, and toolkit[C].India:Meeting of the Association for Computational Linguistics: Short Papers,2012.
[7] Reynar J C, Ratnaparkhi A. a maximum entropy approach to identifying sentence boundaries[C].Washington,DC,USA:In Proceedings of the Fifth Conference on Applied Natural Language Processing,Association for Computational Linguistics,1997.
[8] Lafferty J D, Mccallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C].CA,USA:In Proceeding of ICML,2001.
[9] Fares M, Oepen S, Zhang Y. Machine learning for high-quality tokenization replicating variable tokenization schemes [M].Berlin Heidelberg:Springer-Verlag,2013.
[10] Basile V,Bos J,Evang K,et al.Developing a large semantically annotated corpus[C].Istanbul,Turkey:In Proceedings of the Eight International Conference on Language Resources and Evaluation,2012.
[11] Castagnoli S, Borghetti C, Brunello M. I testi del web: una proposta di classificazione sulla base del corpus PAISà[M].Russia:Formale Informale-Lavariazione Diregistro Nella Comunicazione Elettronica,2011.
[12] Greff K, Srivastava R K, Koutnik J, et al. LSTM: a search space odyssey[J]. IEEE Transactions on Neural Networks & Learning Systems,2015(3):04069-04073.
Deep Learning for Sentence and Token Boundaries Detection
Toleu Galymzhan, WU Chunxue
(School of Optical-Electronic and Computer Engineering,University of Shanghai for Science and Technology,Shanghai 200093,China)
Sentence and token boundaries detection is one of the important tasks in natural language processing. In order to avoid task-specific feature engineering, we have proposed character-level based neural network model for token and sentence segmentation (CNN-TSS). In order to share the information from these tasks, we have treated them as a combined task. The experimental results show that CNN-TSS can achieve high-accuracy without using any external features.
sentence boundaries detection;token boundaries detection;agglutinative language;deep learning
2016- 11- 15
Tolegen Gulmira (1987-),女,硕士研究生。研究方向:自然语言处理。邬春雪(1961-),男,教授。研究方向:计算机网络应用等。
10.16180/j.cnki.issn1007-7820.2017.09.006
TP391.1
A
1007-7820(2017)09-020-04
