基于上限分析的机器学习系统最佳优化决策选择
2017-09-18房楚尧夏金杰赵家培
房楚尧++夏金杰++赵家培

摘要: 本文的重点是使用上限分析法解决在机器学习系统开发中无法判断哪部分最值得优化的问题,以便于做出最佳的优化决策。以一个简单的图像文字识别系统为实例,对其的文字侦测、字符分割、字符识别三个部分使用上限分析法进行模拟,得出各个部分的潜在上升空间,然后比较对3个部分分别进行优化对最终预测结果的影响,从而了解该系统中已经达到“最高水平”的部分,做出最佳的优化决策,避免开发中资源的浪费。
关键词: 机器学习; 上限分析; 图像文字识别; 决策优化
中图分类号:TP181
文献标志码:A
文章编号:2095-2163(2017)04-0037-02
0引言
在一个基于机器学习的预测类应用中,通常需要经历几个步骤才能得到最终的预测结果,一般来说很难凭直觉去决定优化一个机器学习流水线的某个特定部分,在这时就可以使用上限分析法(Ceiling Analysis)[1]来对一机器学习系统进行模拟以找出最佳优化的决策。上限分析法是一种评估机器学习流水线中各个部分对整个机器学习系统结果的优化影响大小的方法,根据分析所得的结果就可以知道在整个机器学习系统中对哪个部分进行优化对最后所得的结果最为有益。这一分析方法与“天花板效应”[2]的概念相关,即在一个系统中的一个独立变量在达到一定水平后就不再对因变量产生影响。在机器学习系统的优化中,这种效应可以看作是因为机器学习系统已经达到“最高水平”而不再可能通过提高某个组成部分的性能(自变量)来改善预测结果(因变量)。
1上限分析法模型
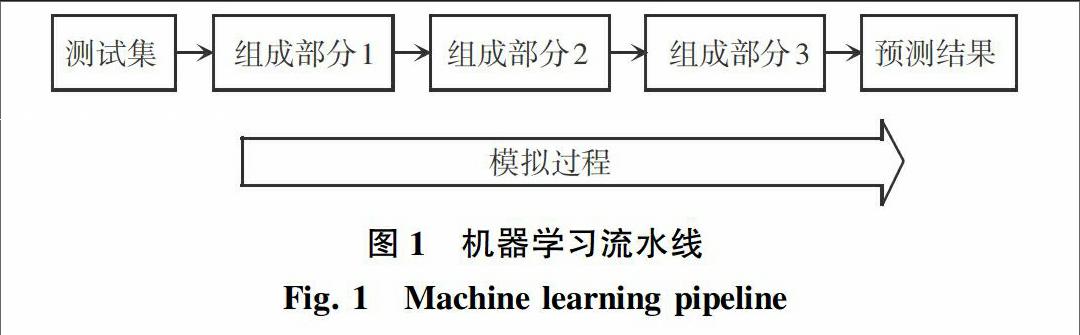
开发一个机器学习系统时,可能会花费很多资源来尝试提高某个组成部分的性能,但是却不会在整个系统中得到很好的效果,这就是要使用上限分析法的一个原因。上限分析可以减少在开发中资源的花费,明确了解要着重处理的部分,以便在预测结果的准确度上获得更为显著的改进;在提出优化方法前,就可以确定每个处理部分可能对结果提供的潜在上行空间,进行其理想性能中的每一部分的仿真分析。因此,当模拟每个部分时,就已经使用类似预测精度的度量来确定整个系统的性能的上行空间。图1即给出了一个由3个部分组成的机器学习流水线和仿真流程的示例,该过程的主要思想是分别模拟每个部分的精度为100%,从而得出每个部分对提高整个系统的性能的能力。模拟是以連续的方式设计展开的,就是开始从左到右添加模拟部分,直至最终宣告完成。
2上限分析法在图像文字识别中的应用
[JP3]本文将使用上限分析法对图像文字识别应用问题进行优化,图像文字识别的常规处理过程如图2所示。这个机器学习系统由3个部分组成:文字侦测(Text detection)、字符切分(Character segmentation)和字符分类(Character classification)[3]。[JP]第一个部分是提取更容易找到文字的较小图像,因为当图像中大部分是文字时,更容易识别文字。第二部分是将提取出的文字进行分割,为了更好地识别文字。最后一部分是字符分类,用于识别各个文字。当前一个部分结束运行后会将结果输入到下一个部分,还有一个连接到分类器的训练部分,则是使用有监督学习生成的分类器模型。[JP]
在图像文字识别这一机器学习系统中,首先要进行文字侦测,旨在选择出可能找到文字的较小图像。为了实现这一部分的功能,将训练一个模型能够区分字符与非字符,然后运用滑动窗口技术识别字符[4],继而再将识别得出的区域设计生成一定的扩展,而后将重叠的区域执行合并,最后以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(因为一般单词的长度大于高度)。第二部分训练一个多变量逻辑回归的二分类模型来研究支持将文字分割成一个个字符的处理过程,训练集是单个字符的图片和2个相连字符之间的图片[5]。在达到字符分割目的后,则把分割的字符转化为18*18像素的图片送入字符分类部分进行识别。最后一个部分是字符分类阶段,将训练一个BP神经网络 [6]来识别文字。
在每一部分均将分别手工提供百分之百正确的数据给下一部分使用,实际上不需要模拟最后一个部分,因为最后的上限为100%。在上限分析中,还需要创建一个表格,即如表1所示。其中指定了当前处理部分在每个阶段的上升空间。第一行显示了没有加入任何模拟的系统精度,计算出整个系统上升空间的起点,上升空间是用当前部分加入模拟后的精度减去前一个部分加入模拟后的精度。最后,整个模拟过程将显示哪个部分会提供最大的上升空间,更值得投入精力和时间去实施优化,所以上限分析将可看作是以一种可靠的方式来决定哪个部分应该进行更多的优化,哪个部分已经不需要优化,因为这一过程显示了改进该要素是否会提高整个系统的精度以及最终将具体提高了多少。
用于此次分析的图片是来自imagenet上的1 000张彩色照片,图片中包括了各种大小不一的字体,天气状态也有所不同。1 000张照片被分为3个部分,即训练集、交叉验证集和测试集,[JP2]分别占总数量的60%、20%、20%[7]。[JP2]训练设定了文字[JP]
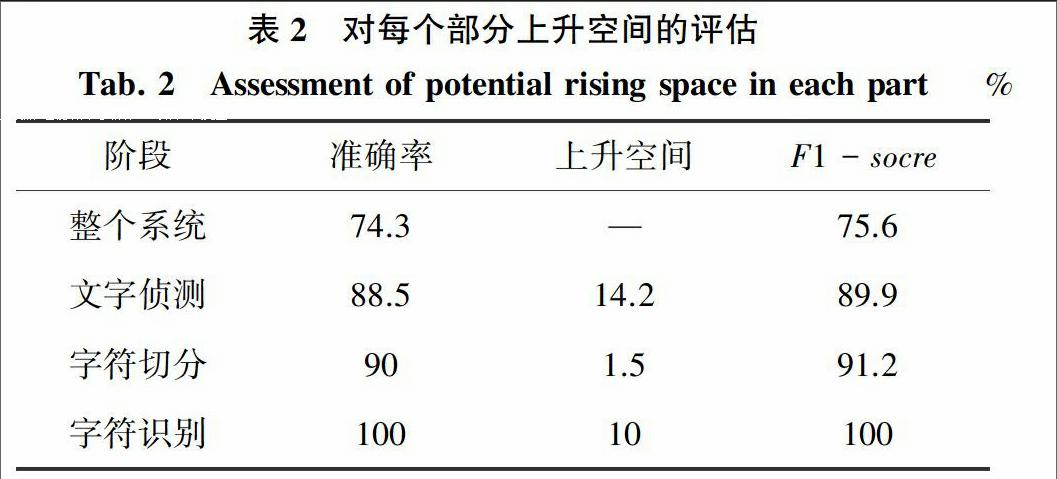
[LL]侦测、字符切分、字符识别三个模型后输入验证集,得出未加入模拟时整个机器学习系统的结果,然后对3个部分分别进行模拟,得出表2。为了更好地衡量系统的精度,在这里引入F1-socre(可看作是模型准确率和召回率的一种加权平均)。理论上,上限分析时不需要对字符识别部分进行模拟,因为当手工提供100%正确率的字符识别部分预测结果时,准确率就是100%。
根据上限分析表中所得出的结果,可以看出这个图像文字识别系统中,优化文字侦测和字符识别部分对整个系统预测结果的提高有很大帮助,上升空间分别达到了14.2%和10%,而字符切分的部分的水平已经接近到上限,上升空间仅有1.5%,如果花费大量时间来对字符切分进行优化,对整个系统的预测精度也不会有很大的提升。
3结束语
本文提出了一种使用上限分析法开发和分析图像文字识别的方法,探索了优化过程中在研究上应该着重推进的部分,结果说明在开发这个图像文字识别应用时文字侦测部分和字符识别部分的潜在上升空间更大,这意味更应该投入精力去优化这2部分,对字符切分部分进行优化几乎不能提高整个系统的预测精度。
参考文献:
[1] WANG Lijuan, ZHANG Zhiyong, MCARDLE J J, et al. Investigating[JP] ceiling effects in longitudinal data analysis[J]. Multivariate Behavioral Research,2008,43(3):476-496.
[2] 卢璟,磨玉峰. “玻璃天花板”效应研究综述[J]. 商业时代,2008(34):58-59.
[3] 蒋东玉,田英鑫. 印刷体英文OCR系统的研究与实现[J]. 智能计算机与应用,2014,4(4):111-112,117.
[4] 柴子峰. 基于滑动窗口的弱标记物体检测方法研究[D]. 哈尔滨:哈尔滨工业大学,2016.
[5] LI Lianhuan. Research on character segmentation method in image text recognition[J]. Advanced Materials Research,2012,1909(546):1345-1350.
[6] LI Wenjie, ZHANG Jie, TIAN Kelun,et al. The design of the BP neural network character recognition in Matlab environment[J]. Advanced Materials Research,2014,3382(1006):1117-1120.
[7] 范永东. 模型选择中的交叉验证方法综述[D]. 太原:山西大学,2013.[ZK)][FL)]endprint
