基于文献的知识发现在成矿预测领域的应用研究
2017-09-18吕鹏飞王春宁朱月琴
吕鹏飞,王春宁,周 峰,朱月琴
(1.中国地质图书馆,北京 100083;2.中国科学院大学,北京 100049;3.国土资源部地质信息技术重点实验室,北京 100037;4.中国地质调查局发展研究中心,北京 100037)
基于文献的知识发现在成矿预测领域的应用研究
吕鹏飞1,2,3,王春宁1,周 峰1,朱月琴3,4
(1.中国地质图书馆,北京 100083;2.中国科学院大学,北京 100049;3.国土资源部地质信息技术重点实验室,北京 100037;4.中国地质调查局发展研究中心,北京 100037)
基于文献的分析挖掘是发现未知新知识的有效途径,本文提出了基于文献的知识发现应用于成矿预测领域的研究思路,构建了基于文献的知识发现模型,主要包括地质实体识别、实体关系识别两个部分。
文献的知识发现;成矿预测;中文分词;关系提取
成矿预测是基于已有的成矿理论、成矿条件、成矿信息以及成矿规律,运用成矿预测方法,对未发现矿体、矿床做出推断、评价的学科[1]。成矿预测目的是利用现有成矿研究成果的指导,提高找矿的效益和效率。成矿预测的发展大体经历了三个阶段:20世纪70年代以前主要是在确立典型区域成矿条件下,使用经验类比法在未知区域发现成矿目标;20世纪70年代至80年代初,统计方法和计算机技术开始广泛应用与成矿预测,其标志是1976年在挪威的洛恩举行的国际地质对比计划98项专题提出了区域价值估计、体积估计、丰度估计、德尔菲估计法、矿床模拟法和综合方法六种资源预测的标准方法[2];进入20世纪80年代后期,GIS开始进入矿产预测领域,产生了一批成功应用的典范。如美国地质调查局实施的国土资源评价计划(CUSMAP),其对栅格、矢量和表格式数据进行处理并通过定制接口在GIS内建立应用模型及表示评价结果[3];进入新世纪,面对信息大爆炸的时代(即“大数据”时代),成矿预测也应运进入“大数据”时代。如何充分利用地质工作数十年积累的海量数据,将已有数据转化为新的认识或知识,并运到成矿预测的实践中,成为地质工作者当下必须面对与思考的问题。赵鹏大院士认为数字找矿是数据科学在矿产勘查中的应用,是用数据分析理论和方法解决矿床勘查中的实际问题[4]。王登红认为可以从地质大数据中充分挖掘有用信息及其规律,通过成矿理论的系统分析,揭示其内在规律并转化为新的认识或知识,指导未来的地质矿产工作[5]。地学文献是地质大数据的重要组成部分,也是地质科学研究成果的重要表现形式,本文旨在通过开展基于地学文献的知识发现研究,尝试发现在成矿预测领域从未发现过或验证过的新知识、新关联,为地质找矿决策服务提供文献信息服务。
1 基于文献的知识发现
知识发现(Knowledge Discovery in Database,KDD),从字面可以理解为“基于数据的知识发现”,即从原始数据中提炼出有潜在的、有价值的知识。实际上和“数据挖掘”和“数据分析”一脉相承。基于文献的知识发现就是对目标科学文献的内容(包括元数据和全文)为对象进行全分析,挖掘、发现文献关联获知新知识的过程,也即对在内容上有关联的文献进行比较和分析的基础上从中识别和抽取有价值的信息的过程[6]。20世纪80年代,芝加哥大学的DR Swanson教授第一次提出了基于文献的知识发现(Literature-Based Discovery)的概念,引起了学界的关注[7]。历经数十年的发展,基于文献的知识发现研究逐渐成熟,研究方法从传统的计量统计方法发展到人工智能、机器学习,应用领域从最初的医学、生物学扩展到情报学、工程学。总体来说从知识发现的方式上大致分为两个方向:传统的相关文献知识发现和新进兴起的非相关文献知识发现。
1.1相关文献知识发现
相关文献知识发现顾名思义,就是文献之间存在某种关联,从文献的结构上分有文献元数据(标题、作者、单位、关键词等)相关和文献内容(全文)相关。基于相关文献的知识发现研究就是对有直接关联的文献进行聚类、比较和分析并从中识别和抽取有价值的信息[8]。主要的分析方法包括共词分析法和共引分析法等。共词分析的原理主要是统计同一篇文献中词语出现的次数,在此基础上对这些词进行分层聚类,揭示出这些词之间的关系[9]。共引分析是将一组具有同引关系的文献作为分析对象,综合利用数学、统计学和逻辑分析方法,通过基于共引关系所形成的文献共引网络将学科之间的关联与亲疏直观的呈现出来[10]。
1.2非相关文献知识发现
相较于相关文献,非相关文献可以理解为文献之间从外部特征(包括内容和元数据)不存在关联关系。可是客观世界是普遍联系的,在海量的科学文献之间存在着各式各样的联系,这些联系有相当一部分仅通过常规的查询与阅读是不能得到的。非相关文献知识发现也是由D R Swanson教授首先提出的,他认为两组看起来没有任何关联的文献(一般理解两篇文献不存在关键词同现和共引关系即为非相关文献)可能存在隐含的关联,而这种关联是单独阅读任何一组文献都发现不了的。经过不断的深入研究,D R Swanson教授提出了“ABC理论”:R(A,B)+R(B,C)->R(A,C),R(A,B)表示实体A与实体B有某种关系R。即,如果A和B有关系,且B和C有关系,则A和C也有关系,当然我们要确定关键词A和关键词C之间是没有任何关联关系的。D R Swanson教授依据该理论发现了食用鱼油和雷诺氏病、偏头痛和镁缺乏之间的关联关系并在临床中得到了应用支持[11]。2001年,Weer等在总结和分析前人研究的基础上提出了“‘两步法’的基于非相关文献的发现模式”,认为基于非相关文献的发现应该包含两个独立的过程:构建假设的过程和验证假设的过程[12]。2012年,Kostoff在提出了关联文献知识发现与创新(Literature-Related Discovery and Innovation,LRDI),强调将知识发现和创新结合。此为关于D R Swanson 1986年研究的最新完整表述[13]。国内的非相关知识发现研究起步于2000年以后,由于起步较晚目前研究主要集中于相关理论的研究分析和Swanson算法的实现上。
1.3基于文献的知识发现的研究意义
科学文献被认为是是科学研究成果的重要表现形式,也是开展科研、获取知识的重要基础媒介。越来越多的研究人员开始认为基于文献的知识发现是发现未知的新知识的有效途径,主要是有几方面的原因。①科学文献是专家学者将科研成果或经验用规范化的科学语言精确表述,并且大多经过实验验证,由于其专业性和规范性具有较高的学术价值,为新知识发现提供了可能性。②随着信息技术的不断渗透,学科交叉、领域交迭现象日益明显,在某一领域、专注于一个方向的科学文献可能隐含着对不同领域、不同研究方向有学术价值的知识点。D R Swanson教授通过对文献的分析发现了食用鱼油和雷诺氏病、偏头痛和镁缺乏这两组概念之间的关联,而这是之前任何研究从未触及的。这就为我们发现新的知识点以及现有知识点之间新的关联佐证了可行性和正确性。③科学文献是研究人员获取知识的重要途径。进入大数据时代,迎来了科学事业蓬勃发展的时期,科学文献的数量呈几何量级的增长。面对海量文献数据,研究人员有了新的需求:一方面不只希望对文献的研究利用仅仅停留在简单的信息积累、加工和传递的低层次上,而是转向了高层次的知识开发与利用。人们越来越注重对数据的分析挖掘,对于文献的需求也从单一文献信息向多元综合信息、从简单文献资源发现向细粒度知识单元以及知识发现演变[14]。
2 基于地学文献的知识发现模型
地学文献知识发现研究的目的是通过开展对地质文献大数据的特征和组织方式进行研究,构建基于地学文献的知识发现模型。通过对地质专业文献数据的挖掘,结合对中文分词、关系抽取和扩展、知识图谱构建等关键技术的研究,分析专业关键词并建立实体之间的关联关系,实现新知识发现的目标,面向成矿资源预测这个应用试点专题开展实际应用。模型主要包括地质实体识别、实体关系抽和关系图谱可视化等,结构如图1所示。
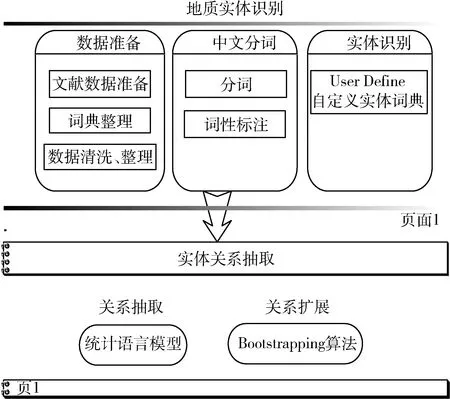
图1 知识发现模型
2.1地质实体识别
地质实体识别是指采用自然语言处理技术从地学文献中自动识别出成矿预测领域相关的实体要素,是下一步发现实体间的关联关系的基础。主要包括以下工作。
2.1.1 数据准备
1)按照资源储备和项目需求确定文献数据的范围以及文献全文数据的提取。
2)对已有词表资源进行梳理。
3)文献数据的清洗、转码。
2.1.2 中文分词
分词是将句子由连续的字序列按照一定的规范切分重新组合成词序列的过程[15]。中文表达不像英文那样有明显的词语分隔符,只有句子之间有明显的符号划分,可是词是最基本的语义表达符,所以分词是中文自然语言处理的基础。目前分词工具方法较为成熟,主要有以下几种:基于词典的字符匹配法、基于统计语言模型以及以上二者的结合。分词工具方法各有优缺点,分词工具方法的选择需要统筹考虑语料基础以及项目对分词效果、效率的要求。由于分词的结果对后续关系抽取效果有巨大影响,我们对应用范围较广的主流分词工具进行了进行选型评估。结合本项目实际,综合考虑词典基础、分词结果需求(准确性、效率、词性标注等)选择了最大逆向匹配分词算法的中科院分词器的作为本项目的分词工具。
2.1.3 实体识别
在分词的基础上,采用自定义字典user Define进行标注进行实体识别。即基于已有词典资源构建地质类实体词典,作为关系抽取中的实体。
2.2实体关系抽取模型
实体关系抽取也属于自然语言处理的一项基础工作,是在实体识别的基础上结合语义环境提取出实体之间的关系[16]。通过自然语言处理我们得到了一个个独立的实体知识点,可有价值的信息往往是通过实体间的关系来体现的,比如在基于文献的成矿预测研究中,研究的目的是发现矿种和土壤、岩石、生物等实体间的关联关系,从而为成矿预测决策提供科学数据支持。关系抽取技术路线经历了从模式、词典等简单方法到机器学习等复杂方法的演变[17],目前基于统计语言模型的机器学习关系抽取方法凭借其入手易、效率高成为研究人员的主要选择。本项目选择了基于机器学习的关系抽取方法:采用统计语言模型的关系抽取方法和Bootstrapping的关系扩展方法。
2.2.1 基于统计语言模型的关系抽取模型
2.2.1.1 统计语言模型研究
统计语言模型可以形式化统一表示为式(1)。
p(S)=p(w1,w2,…,wn)=
(1)
p(S)就是语言模型,即用来计算一个句子S概率的模型。那么如何计算p(wi|w1,w2,…,wi-1),最简单的办法就是采用极大似然估计(Maximum Likelihood Estimate,MLE),见式(2)。
p(wi|w1,w2,…,wi-1)=fraccount(w1,w2,…,
wi-1,wi)count(w1,w2,…,wi-1)
(2)
式中,count(w1,w2,…wi)表示词序(w1,w2,…,wi)在语料库中出现的频率。但由于数据稀疏和参数空间过大,导致实际中无法得到应用。
所以,实际中通常采用N元语法模型(N-Gram),它采用马尔科夫假设:语言中每个单词只与其前面N-1的上下文有关。
假设下一个词的出现只依赖它前面的一个词,即二元语法模型(BiGram),则有式(3)。
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)
…p(wn|w1,w2,…,wn-1)
=p(w1)p(w2|w1)p(w3|w2)…p(wn|wn-1)
(3)
对于N的选择:理论上,越大越好;经验上,TriGram用的最多。原则上,能有BiGram解决的,就不用TriGram。
2.2.1.2 构建基于统计语言模型的关系抽取模型
关系抽取中采用二元语法模型,及每个词只和它前一个词有关,满足一元马尔科夫假设。操作步骤如下。
1)分词。对每个句子进行分词,过滤出名词、动词和介词。
2)关系词过滤。对关系词进行过滤,过滤出不及物动词(例如奔跑)以及以人为主语的词(例如,看见)。
3)获得关系三元组集合。找出句子中所有n-v/p-n结构的三元组(不考虑相邻关系)。并计算获得的所有三元组的联合概率作为该三元组的得分(用二元语法模型);找出得分最高的三元组作为候选的关系三元组。
4)确定关系三元组。通过规则,对关系三元组的候选集合进行过滤,得到关系三元组,目前主要通过两条规则进行过滤:对于抽取出来的n1-(v/p)-n2结构,如果n1和n2之间距离超过5,我们认为这个关系较弱而舍弃;对于抽取出来的n1-(v/p)-n2结果,如果n2后面是一个动词,我们认为这个关系抽取的不完整故舍弃。
5)关系三元组置信度计算。加入评分函数计算抽取的关系三元组的置信度。评分函数为关系三元组在语料中出现的频率。
2.2.2 构建基于Bootstrapping算法的关系扩展模型2.2.2.1 Bootstrapping算法研究
统计语言模型解决的是关系抽取的问题,而Bootstrapping解决的是关系扩展的问题。Bootstrapping的方法主要的思路是通过人工指定几个初始种子,随后系统会寻找满足人工提供种子的句式模板,利用得到的模板找到新的种子不断的迭代下去,最终达到举一反三的目的。该方法的缺点是对初始关系种子的质量要求较高。比如我们现在知道“中国-北京”,“美国-华盛顿”两个国家-首都的关系,但是还想知道所有其他的国家-首都关系,那么就可以用Bootstrapping方法,以“中国-北京”,“美国-华盛顿”为基础,可以找到语料中几乎所有的国家-首都关系。
Bootstrapping算法基本思想是:构建初始种子集;依据上下文语义环境,构建候选模式集;采用种子集训练初始分类器,并对未标注数据集进分类;把分类结果中具有高置信度的样本加入种子集中,重新训练分类器,直到没有新数据加入种子集为止;最后用训练好的分类模型对测试集进行评估,输出识别的最终结果。
2.2.2.2 基于Bootstrapping算法的关系扩展模型
依据Bootstrapping算法的基本思想,设计算法流程共分为以下几个步骤:上下文构建阶段、模板抽取阶段、候选种子抽取阶段和候选种子评分阶段。
1)上下文构建阶段。上下文构建阶段主要是利用一种前缀字典树的数据结构来存储种子的前后的文字,在抽取上下文的时候只选择在同一个分句当中的内容即任何标点符号都作为边界处理。前缀字典树是一种压缩存储的数据结构,他的特征在于父节点是子节点的前缀。
2)模板抽取阶段。模板抽取阶段主要是利用上下文构建得到的两个字典树,找到满足所有种子的最长的句式模板。
3)候选种子抽取阶段。候选种子抽取阶段主要是利用找到的句式模板,在整个语料中找到满足句式句子并利用句式抽出去对应位置的种子,作为候选种子。
4)候选种子评分阶段。候选种子评分阶段主要是利用随机游走的方法从图中进行迭代直到到达图中的任何一点的概率收敛。
3 文献知识发现实验
结合项目开展实际,经过前期充分的咨询调研,确定探索挖掘“金矿”领域知识关联图谱为试点,在目标文献中自动发现构建“金矿”的关联关系网络,实现为“金矿”成矿预测提供有价值的新知识、新关联的目标。
3.1数据准备
3.1.1 数据源确定
在文献数据准备阶段我们提取了CNKI2016年以前“金矿”相关文献的全文数据,提取标准为:在基础科学大类中选择地质,这些文献的元数据(题目、关键词、内容提要)中必须包含有“金矿”一词;在工程科技大类中选择矿业工程学文献,其文献的元数据(题目、关键词、内容提要)中也必须包含有“金矿”一词。
最终共提取金矿会议文献约1 647篇,大小约457 M;金矿期刊文献约28 740篇,大小约9.54 G。其中,元数据为XML格式,文献全文为TXT格式。
3.1.2 词表收集整理
收集整理用于自然语言处理的中文词表和其他相关规范、标准等文件。经收集整理可利用的词表及其文件格式如下:1)地质分类法(xls,doc);2)叙词表(pdf);3)2003~2014年度地质文摘库自由词(xls);4)地球科学百科全书(pdf);5)地球科学大辞典(xls);6)地球物质科学术语汇编(pdf);7)地质大辞典(pdf);8)地质图书分类法(pdf)。
3.1.3 专业词汇提取
在已有的文献数据中提取了“金矿”相关专业词汇,包括:从金矿会议文献中提取关键词2 668个,从金矿期刊文献中提取关键词26 794个、常用字典词汇677 844个,最终收录词典词目数717 819个。
3.2利用统计语言模型构建金矿领域知识图谱
3.2.1 第一轮实验
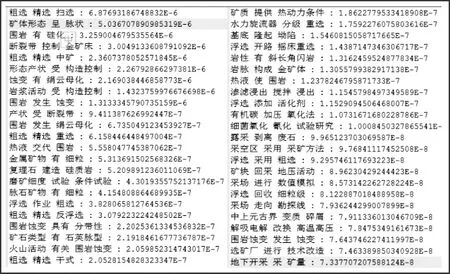
图2 统计语言模型构建知识图谱第一轮实验结果
3.2.2 第二轮实验
根据第一轮实验结果,进行了关系词(关系三元组中间的词)去除,关系词的问题有如下三类:第一类:关系词包含意义模糊,表意不清。例如“有”、“受”、“使”、“添加”、“进行”、“采”等;第二类:关系词是不及物动词,没法接宾语。例如“作业”、“发生”、“精选”、“进行”、“加压”等;第三类:关系词的主语为人,而项目抽取关系的主语为物。例如“建造”、“实验”等。
针对这三类关系词,分别做出如下处理。第一类关系词包含意义模糊,采用停用词表的方式在关系抽取的时候将这类词过滤出去。实验中发先这类词比较少(由于文献的格式用语比较规范统一),所以只构建了拥有三百多个词的停用词表就达到了很好的过滤效果,人工干预工作量并不大,且为一次性工作。第二类关系词是不及物动词,在词性标注的时候将不及物动词单独标注出来,在关系抽取过程中可以直接过滤掉,过程完全自动化。第三类关系词的主语为人,这类词语和第二类不及物动词有很大的重合,所以在过滤第二类词的时候已经过滤了大量的第三类词,剩下少量的词通过停用词表来过滤,人工干预工作量小,且为一次性干预,而效果极其显著(图3)。
3.2.3 第三轮实验
在这一轮实验中主要对评分函数进行了完善:在实验中,发现评分函数存在缺陷:评分函数使用两个二元组的联合概率之和,这样的评分函数放大了关系词在抽取的关系三元组中的比重关系词对关系三元组影响占比为50%(关系词计算了两次),然而关系词的抽取在关系抽取中又是最不稳定的,所以导致抽取结果准确度较低。据此,对评分函数进行了改进:将原始计算两个二元组联合概率之和改成直接计算三元组的联合概率,使得两个实体词和关系词对关系三元组的占比都是1/3,达到平衡(图4)。
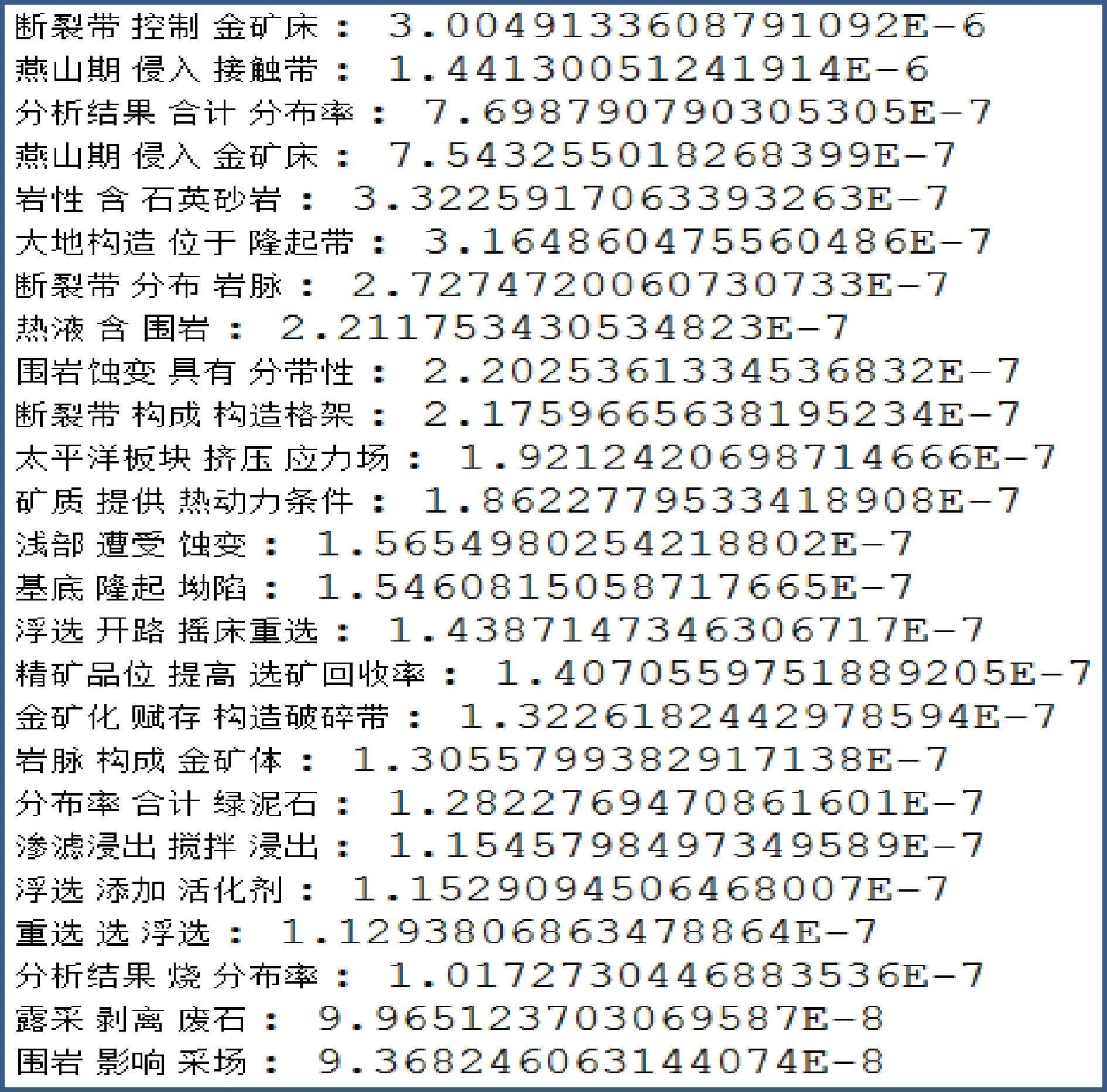
图3 统计语言模型构建知识图谱第二轮实验结果

图4 统计语言模型构建知识图谱第三轮实验结果
3.3利用Bootstrapping构建金矿领域知识图谱
3.3.1 第一轮实验
1)实验种子设置:金矿-黄金。
2)关系抽取模板,如图5所示。
3)实验结果,如图6所示。
4)结果分析。仅发现一个有效种子,经分析主要原因如下:文献数量不够、文献种子分布不均衡、汉语表达的多样性、模板太过具体、脏数据过多等。
3.3.2 第二轮实验
依据第一轮实验发现的问题进行改进,效果比较明显。
1)种子设置:矿石-磁铁矿、矿石-黄铁矿。
2)关系抽取模板,如图7所示。
3)实验结果,如图8所标。
3.4领域图谱可视化
在关系抽取实验基础上,将抽取关系对采用可视化技术,获得关金矿领域关系图谱如图9所示。

图5 Bootstrapping第一轮二元关系抽取模板

图6 Bootstrapping第一轮二元关系实验结果

图7 Bootstrapping第二轮关系抽取模板

图8 Bootstrapping第二轮二元关系实验结果
4 结 论
科学文献是记录、传播知识的重要的载体,在学科领域交叉日益深入的今天,越来越多的科研工作者认识到科学文献的挖掘分析是发现新知识的一个有效方式。本文通过对地质专业文献数据的挖掘,结合自然语言处理、机器学习等方法,验证了一套基于文献数据的知识发现解决方案,包括数据处理、分词/词性标注、关系抽取算法与模型研发(关系发现、关系扩展)等环节。下一步研究将在不断完善关系抽取模型的基础上构建可视化图谱,并进一步深入扩展图谱的应用,实现例如基于知识图谱的热点、趋势发现等功能,从而使地质文献资源内容展示的程度进一步加深、资源之间的内部联系更加一目了然,为成矿预测决策和科研提供快捷的知识获取服务。
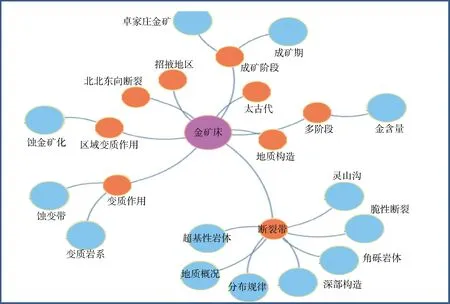
图9 金矿领域知识图谱
[1] 刘石年.成矿预测学[M].长沙:中南工业大学出版社,1993.
[2] 薛顺荣,胡光道,丁俊.成矿预测研究现状及发展趋[J].云南地质,2001,20(4):411-416.
[3] 刘林,芮会超.成矿预测的发展现状及趋势[J].地质力学学报,2016,22(2):223-231.
[4] 赵鹏大.找矿理念:从定性到定量[J].地质通报,2011,30(5):625-629.
[5] 王登红,刘新星,刘丽君.地质大数据的特点及其在成矿规律、成矿系列研究中的应用[J].矿床地质,34(6):1143-1154.
[6] 张树良,冷伏海.基于文献的知识发现的应用进展研究[J].情报学报,2006(6):700-712.
[7] Swanson D R.Online Search for Logically Related Non—interactive Medical Literatures:a Systematic Trial and Error Strategy[J].Journal of American Society for Information Science,1989,40(5):356-358.
[8] 黄水清.非相关知识发现方法及在农业经济学中的应用[D].南京:南京农业大学,2010.
[9] 冯璐,冷伏海.共词分析方法理论进展[J].中国图书馆学报,2006,32(2):88-92.
[10] 王建芳,冷伏海.共引分析理论与实践进展[J].中国图书馆学报,2006,32(1):85-88.
[11] Swanson D R,Smalheiser N R.Aninteractivesystemforfinding complementary literatures:a Stimulus to scientific discovery[J].Artificial Intelligence,1997,91:183-203.
[12] Weeber M,Klein H,Lolkjc T W,et a1.Using Concepts in Literature-Based Discovery:Simulating Swanson’S Baynaud-Fish Oil and Migraine-Magnesium Discoveries[J].Journal of the American Society for Information Science and Technology,2001,52(7):548-557.
[13] 田瑞强,姚长青,潘云涛.关联文献的知识发现与创新研究进展[J].情报理论与实践,2013(8):117-123.
[14] 赵瑞雪,鲜国建,寇远涛,等.大数据环境下的农业知识发现服务探索[J].数字图书馆论坛,2016(9):28-33.
[15] 刘迁,贾惠波.中文信息处理中自动分词技术的研究与展望.计算机工程与应用[J],2006(3):175-182.
[16] 冯志伟.当前自然语言处理发展的几个特点[J].暨南大学华文学院学报,2006(1):34-40.
[17] 徐健,张智雄.典型关系抽取系统的技术方法解析[J].数字图书馆论坛,2008(9):13-18.
Theapplicationstudyonmetallogenicprognosisofliterature-basedknowledgediscovery
LYU Pengfei1,2,3,WANG Chunning1,ZHOU Feng1,ZHU Yueqin3,4
(1.National Geological Library of China,Beijing100083,China;2.University of Chinese Academy of Sciences,Beijing100049,China;3.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing100037,China;4.Development and Research Center,China Geological Survey,Beijing100037,China)
The analysis and data mining of literature is an effective way to find unknown knowledge.This essay put forward research ideas of literature-based knowledge discovery applied in metallogenic prognosis,and building model of Literature-based Knowledge Discovery consisted of geological entity recognition,entity relation recognition and extraction.
literature-based knowledge discovery;metallogenic prognosis;Chinese segmentation;entity relation recognition and extraction
2017-06-27责任编辑:赵奎涛
国土资源部公益性行业科研专项项目资助(编号:201511079)
吕鹏飞(1978-),男,硕士研究生,高级工程师,主要从事地质文献数据分析与挖掘方面的研究工作,E-mail:23690271@qq.com。
朱月琴(1975-),女,博士,高级工程师,主要从事地质大数据、地图综合与可视化研究工作,E-mail:yueqinzhu@163.com。
P208
:A
:1004-4051(2017)09-0085-07
