数据中心网络TCP Incast问题研究
2017-09-18余雅君徐明伟
余雅君,刘 峥,徐明伟
清华大学 计算机科学与技术系,北京 100084
数据中心网络TCP Incast问题研究
余雅君+,刘 峥,徐明伟
清华大学 计算机科学与技术系,北京 100084
目前传统TCP协议不适用于数据中心的工作模式,因此当数据中心中出现常见的多对一流量模式时会产生TCP Incast问题,造成应用层可见吞吐量崩溃。结合数据中心特点,提出全面的解决方案是解决TCP Incast问题的研究目标。围绕TCP Incast问题,深层次剖析了该问题发生的根源,简要概述了该问题面临的挑战,介绍了基于该问题所构建的数学模型;从链路层、传输层和应用层角度分析并总结了近十年具有代表性的解决方案,从有效性、可部署性等不同角度对所列举方案进行了全面对比,发现当前方案大都基于某个具体方面缓解该问题,均存在缺陷;最后提出了可行的解决该问题的研究方向,将关注点聚焦于SDN结合机器学习以及传输新协议。
数据中心网络;TCP Incast问题;吞吐量崩溃
1 引言
随着互联网的发展,云计算服务提供商大量涌现。Amazon、Microsoft、Google等云计算服务提供商使用数据中心向用户提供网络搜索、存储、电子商务和大规模通用计算等服务。现代数据中心承载着成千上万的服务和应用程序,为了适应业务和服务的需求,数据中心已由当初的计算中心转变为数据集群中心[1]。基于集群的存储系统具有低成本、高可靠性、高可用性、可扩展性等优势,如今已被广泛部署到数据中心网络(data center networks,DCN)中。这些存储系统由一组网络化的小型存储服务器组成,数据分布在这些服务器中,以提高性能和可靠性,并通常采用分布/汇总的通信模式,实现数据可靠高效的传输。
然而,目前数据中心采用的存储和通信模式导致了被称为TCP Incast的问题。TCP Incast指的是在高带宽、低延时、有限缓冲区的数据中心环境中,当客户端向多个存储服务器同时请求数据,服务器响应并向客户端同时发送数据时,导致数据包总大小超过以太网交换机缓冲能力,出现灾难性TCP吞吐量崩溃的现象。由于在数据中心中,多对一通信的场景很普遍,例如Google提出的用于大规模数据集并行运算的软件架构MapReduce,而当前绝大多数数据中心仍使用TCP/IP协议用于节点之间的通信,这就使得TCP Incast成为一个普遍存在的问题。TCP Incast现象危害巨大,它不仅会造成链路带宽资源的浪费,还会影响网络服务的完成效率。基于Memcached架构分布式key-value存储的Facebook系统每秒要处理几十亿的请求,同时存储几万亿的数据项,给全世界超过十亿的用户提供服务,最小化易发生的TCP Incast问题带来的影响至关重要。不管是服务提供商还是客户端都希望尽力避免TCP Incast问题,TCP Incast问题已经受到了学术界和工业界的广泛关注。
TCP Incast问题产生的原因,从根本上讲是由于传统的TCP/IP协议在设计之初针对的是带宽较低、延迟较大、地理分布广泛而连接较为稀疏的互联网,而TCP协议不能很好地适应数据中心网络高带宽、低延时、地理分布集中而连接密集的特点。另一方面,由于TCP/IP技术在互联网中取得了巨大的成功,采用其他传输协议作为替代方案的过渡期较长,这使得TCP Incast问题的解决变得富有挑战性。目前国内外学者的研究重点在于:基于TCP传输协议和以太网,解决或缓解不同于传统网络的数据中心网络中TCP Incast问题带来的影响,尽可能地提高端到端通信以及大容量存储数据传输的网络性能。目前已有的方案从不同角度出发尝试解决TCP Incast问题,需要总结和比较它们之间存在的联系和差异。同时,已有解决方案尚未从根本上解决问题,在安全性、开销和通用性的问题上也需要进一步探讨。
本文对TCP Incast问题进行整理分析。首先,对TCP Incast问题发生的根源进行剖析,将其总结为同步请求、触发超时重传、参数设置不匹配等几种。在此基础上对TCP Incast问题存在的挑战进行了概括,将核心挑战总结为传输协议迁移、数据中心复杂性、部署开销等问题。接着,介绍已有的关于TCP Incast问题所构建的模型,这些模型为探究问题细节提供了理论基础。由于TCP Incast问题既属于一种特殊的链路拥塞,也涉及到传输层和应用层的性能,本文分别从链路层、传输层、应用层这三方面对目前已提出的解决TCP Incast问题的方案进行了详细分析,并总结了实现机制和优缺点。在此基础上,对这些方案的有效性、可部署性等特性进行了对比分析,从总体上总结了各类方案的优缺点。最后提出了解决TCPIncast问题的新思路。相比近几年综述类文章[2-3],本文有针对性地分析和对比了解决方案,对该问题的描述、挑战以及相关模型进行了系统性研究,同时还增加了基于SDN(software defined networking)改进方案的研究,并为后续工作提出了较可行的方案。
本文组织结构如下:第2章分析了TCP Incast问题;第3章对该问题的挑战性进行概括;第4章探究了针对该问题所构建的模型;第5章对当前方案进行了分类研究;第6章对各种方案进行全面对比;第7章进行总结与展望。
2 TCP Incast问题
2.1 问题描述
2004年,Nagle等人在研究存储集群使用分布式存取和实现线性存储带宽可扩展性时,发现在存储系统中随着目标存储设备数量的增加,数据聚合带宽开始减小,并存在吞吐量下降等问题,首先在分布式存储系统PanFS中发现并提出了网络传输的Incast问题[4]。
同步请求工作负载在如今商业集群中越来越普遍,例如在集群存储系统中,多个存储节点同时响应数据请求时;在Web搜索中,当多个站点几乎同时响应搜索查询时;在批处理作业中,如在MapReduce中的“shuffle”阶段,来自多个Mapper的键值对被传送到Reducer时。因此在许多典型的数据中心应用中都可能出现TCP Incast问题。
一般来说,TCP Incast问题指的是存在TCP传输性能下降的多对一流量模式。图1展示了典型的TCP Incast场景。在该模式下,客户端通过交换机连接到数据中心,同时该交换机与多台服务器相连。客户端向一个或多个服务器请求数据,数据从服务器发出,通过交换机,经过瓶颈链路到达客户端,形成多对一模型。该模式中,客户端一般请求较大逻辑块大小(比如1 MB)的数据,而实际上数据是以较小的数据块大小(比如32 KB)即服务请求单元(server request unit,SRU)分布式地存储在很多服务器上。客户端向存储请求数据块的服务器发送请求包,通过TCP服务请求,直到当前请求的所有SRU均成功被客户端接收,即完成当前请求,则开始下一请求。
由于数据块存储位置较为分散,并发发送者数量较多,数据传输负载可能在瓶颈交换机出现缓冲区溢出,导致包丢失,并伴随着TCP超时重传。同时由于直到所有发送方完成当前数据块的传输,才允许客户端请求下一数据块的机制(被称为barrier synchronized[5],下文称为同步阻碍模式),使网络出现长时间空闲,该低链路利用率现象也被称为吞吐量崩溃,即TCP Incast问题。
2.2 问题原因与影响
TCP Incast问题造成吞吐量下降的直接原因主要由以下几方面相互影响。
(1)某些流的拥塞窗口较小。由于数据中心RTT(round-trip time)量级小,当很多流在同一链路竞争时,及时反馈,拥塞控制机制迅速减小拥塞窗口。
(2)触发超时重传。当交换机队列溢出时,多条流会发生丢包,又由于拥塞窗口小,某条流可能出现整个窗口丢包,不能触发TCP快速重传,只能超时重传,导致吞吐量下降。
(3)同步阻碍模式影响。当同步请求中涉及的某个服务器处于超时阶段时,其他服务器可以完成其响应的发送,但客户端必须等待至少TCP最小超时重传RTOmin(默认为200 ms)才能接收重传响应,在此期间客户端链路可能处于完全空闲状态,网络利用率显著下降。
TCP Incast问题导致的灾难性吞吐量崩溃可能会使用户可见吞吐量低至客户端带宽容量的1%~10%,且每个请求的延迟可能高于200 ms,这将极大程度地影响延时敏感的在线应用程序,使系统响应缓慢,从而错过流完成期限,对用户体验造成负面影响。同时,Incast模式下造成网络资源的浪费,在影响用户的同时,会造成服务提供商的损失。
因此,在数据中心中避免TCP Incast问题的出现可以提高网络的传输效率,并提升用户的服务质量。目前针对TCP Incast问题的具体解决方案有很多,本文将对这些方案分层具体分析并进行对比。
3 问题挑战
由于数据中心网络的特点及其复杂性,解决TCP Incast问题具有较强的挑战性。
(1)传输协议迁移问题。如前文所说,数据中心数据的传输是基于TCP/IP传输协议,而该协议是针对传统网络特点设计,传统网络对网络拓扑、链路利用率、交换机缓存大小等特性都未知,而数据中心主要集中管理,能获取较全面的网络信息,同时数据中心网络流量模式不同于传统网络,因此当传统TCP应用于数据中心网络时存在很多弊端。
(2)应用需求差异。在数据中心网络中,各应用需求不同,有带宽饥饿的大流量,同时存在有严格完成时间期限的小流量。因此需要权衡数据中心在低延时敏感的小流量和高吞吐量敏感的大流量间的调度,尽可能满足不同应用的需求。
(3)突发流实时性要求。数据中心中存在突发流,且数据中心中80%的流持续时间小于10 s[6],即使采取相应的拥塞控制算法,可能来不及反馈就已经完成对该流的传输,因此实时性较强。
同时,现有的解决TCP Incast问题的方案很多,但仍存在问题:其一,现有方案着重点各不同,且不能从根本解决该问题。其二,现有方案在实际部署中存在各种挑战,主要表现为以下几点。
(1)硬件开销。如较大的交换机缓冲区可以延缓TCP Incast问题发生,加倍缓冲区大小可以使连接的服务器数量翻倍。但增加交换机缓冲区大小会带来巨大的成本,同时会带来更难预测的端到端延时并增加同步重传的可能性,从经济角度和扩展性方面,该方案在实际中不可取。
(2)一致性问题。如以太网流量控制可缓解队列压力,但存在队头阻塞(head-of-line blocking)问题,影响其他正常流。同时由于交换机供应商不同,交换机实现存在不一致问题。
(3)附加不确定影响。通过减少TCPRTOmin的方法可提高吞吐量。但系统时钟实现微秒级的分辨率依旧存在挑战,同时若RTO(retransmission timeout)设置过小,会导致超时误判,同样造成不利影响,因此阈值的选取也存在权衡问题。
(4)场景局限性。TCP需适用于不同网络和流量特性的多样网络,因此也使得TCP在特定网络,利用本地特性,针对某一目的提升性能具有局限性。而当前TCP Incast部分解决方案不仅存在未较全面利用网络特性问题,而且在全面考虑网络场景方面也需完善。
因此,在基于传统TCP/IP协议的数据中心网络中,兼顾不同应用的需求,结合数据中心特点,提出适合大多数网络环境而非特定网络环境的TCP Incast问题的解决方案依旧存在较大挑战,需进一步对该问题深入研究。
4 建模与分析
对于TCP Incast问题产生的原因,国内外学者从不同角度进行了建模分析。目前已有的TCP Incast模型可总结为实验数据拟合模型、理论建模分析模型和解释模型。这些模型从实验、理论等方面较全面地分析了TCP Incast问题,研究了造成吞吐量崩溃的原因,以及相应参数对该问题的量化影响。在模型基础上,相继提出了相应的解决方案。
4.1 实验数据拟合模型
2009年,文献[7]在不同环境下调节参数并用已有的两种工作负载进行多次实验的重现;通过分析实验结果,建立了简单的平均吞吐量预测模型,给定数学公式,其中比例因子是根据实验和经验设置的;最后通过分析归纳了影响TCP Incast问题的因素。
通过利用文献[8]中固定段工作负载,即服务器每次响应数据大小固定(如数据迁移),以及文献[5]中的可变段工作负载,即客户端请求数据量固定(如分布式存储应用),两种类型工作负载重现了实验,分析了RTO和Delayed ACK机制的影响,并提出了吞吐量的量化模型。模型具体核心如下:
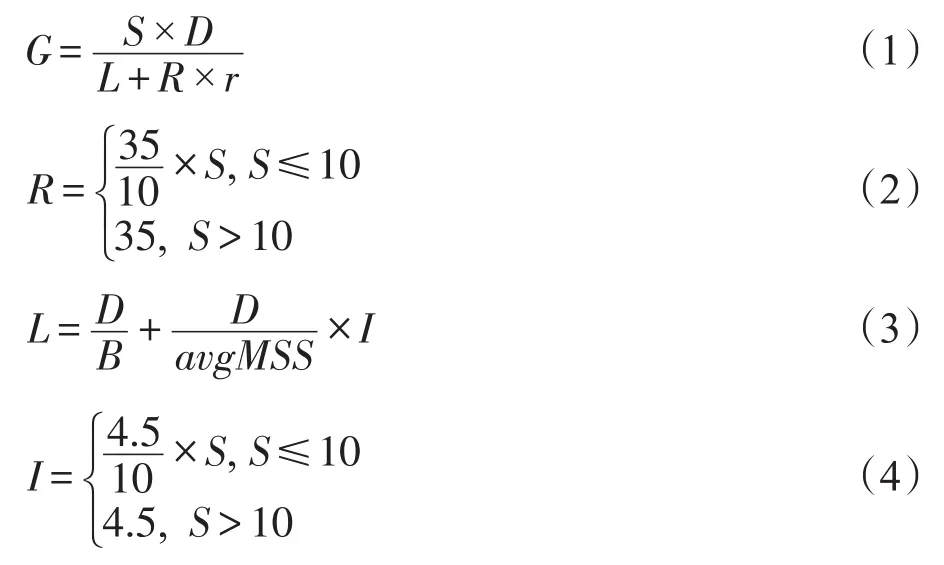
其中,目标网络吞吐量G为发送者数量S与每个发送者发送的数据量D的乘积(即发送总量)除以传输总时间;传输总时间为网络中无RTO事件发生(即无丢包)时传输所需的理想时间L与超时大约持续的时间r乘以传输过程中出现RTO时间的个数R的和;B为链路带宽;avgMSS(average maximum segment size)为平均包大小;I为发送两数据包之间的等待时间。R和L均为S的函数,函数的系数是通过实验结果拟合得出。通过将该模型计算的吞吐量与实验中实际吞吐量对比发现,该模型一定程度上可以模拟出吞吐量的变化。
通过模型分析,RTOmin值和包发送间隔时间I极大地影响了吞吐量,因此RTOmin较大时,应减小该值;RTOmin较小时,需控制发送包的间隔时间I以解决TCP Incast问题。但是,该模型建立过程中的模型参数过于依赖实验数据,不具有普适性,同时部分参数(如avgMSS)在发送数据前难以获取,且该模型未进行严格的数学证明,只是直观上的解释,实验只针对两种特定的工作负载和网络环境,对于不同的应用、网络设备、网络拓扑等的适用性有待深入分析。
4.2 理论建模分析模型
通过模拟TCP动态传输过程[9],TCP Incast问题造成吞吐量崩溃的原因可分为两种超时类型:块尾部超时(block tail timeout,BTTO)和块头部超时(block head timeout,BHTO)。
BTTO描述的是,当同步发送者较少,数据块最后3个包中出现丢包时,由于接收3个重复ACK才快速重传的机制将不会触发快速重传,而是等待RTO时长触发超时重传,因此造成吞吐量下降。
而当同步发送者数量较大时,会出现BHTO。这是由于当某些流较早完成传输,使这些流具有较大的发送窗口。每个流根据其窗口大小将分组注入网络。由于同步发送者过多,容易超出缓冲区容量,导致其中一些包被丢弃。更加不幸的是可能丢失某窗口中所有包,无ACK包反馈,进入超时重传阶段。这便是同步发送者数量增大时,超时重传主要发生在块传输的开始,导致吞吐量急剧下降的原因。
通过分别对两种类型的超时建模仿真,证明了Incast问题在发送者数量不同时,主导该问题产生的原因不同。并通过模拟实验分析了发送者数量N、缓冲区大小B和链路容量C的影响,认为增大链路容量并不能缓解TCP Incast问题,而增大缓冲区可以延迟吞吐量下降。
然而,基于ACK包不会丢失,窗口同步变化等假设,使该建模分析具有一定的局限性,但不能否认其工作为解决TCP Incast问题提供的参考价值。
4.3 解释模型
不同于上述拟合模型依赖实验数据,分析模型依赖TCP版本,在文献[10]中并未直接计算特定场景的吞吐量,而是对流控系统参数和相关机制变量的影响进行量化分析,提出解释模型,理论分析参数对TCP Incast问题的影响,从而总结该问题产生的原因。
吞吐量Th定义为:
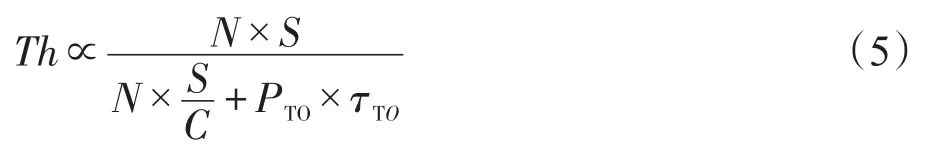
其中,N代表发送者数目;S为数据块大小;C为链路容量;PTO为发生超时的可能性;τTO为超时持续时长。
通过实验观察发现,流量较多时主要发生全损超时(full loss timeout,FLT),类似于BHTO,且窗口大小w服从正态分布。
通过理论证明,在一个轮询(round)中发生超时的可能性与平均窗口大小、标准差σw、丢包率 p有关,关系见式(6)。

假设每次轮询中发生超时可能性相等,设一次传输中轮询次数为R,得出传输超时可能性PTO,即式(7)。

从上面理论公式可以看出,关于吞吐量的定义考虑了所有关键系统参数和机制变量,如系统参数链路容量C、数据块大小S、缓冲区大小B、机制变量RTOmin、平均窗口大小和窗口大小的标准差σw,并讨论分析了它们对吞吐量的量化影响。
该模型较客观量化分析了各参数对TCP Incast问题的影响,为该问题的研究提供了理论基础。
5 TCP Incast问题解决方案
解决TCP Incast问题的方案可从不同的层面进行设计。一方面,通过数据中心网络运行机制采取一定措施可避免TCP Incast问题的发生。首先,明确限制终端请求建立连接的数目,即控制多对一模式中“多”的数量;其次,尽可能地在本地实现计算,减少瓶颈交换机出现Incast问题的可能性;最后,实现集群中应用运行时间的分散化,不至于出现数据中心吞吐量崩溃问题。另一方面,从产生吞吐量崩溃的本质,即数据包的丢失出发,主要从避免或减少丢包以及发生丢包后实现快速重传减小丢包影响两方面来缓解该问题。
以上不同层面的解决方案可更加细粒度地划分为链路层、传输层和应用层3个角度。接下来将从这3个角度,对TCP Incast问题的解决方案进行阐述以及归纳总结。
5.1 链路层
在数据中心的链路层,拥塞通知和流控是缓解TCP Incast问题的两个主要方法。
5.1.1 拥塞通知方案
互联网工程任务组(IETF)和IEEE 802.1工作组的数据中心桥接任务组致力于研究DCN中的拥塞通知方案以减少超时包数量。其中较典型的反向拥塞通知(backward congestion notification,BCN)[11]和量化拥塞通知(quantized congestion notification,QCN)[12]方案都是基于队列长度的反馈拥塞控制方案。
(1)BCN
BCN主要思想为检测核心交换机处是否发生拥塞。这些交换机配置有用于检测拥塞的硬件监视器,并且源和拥塞节点相互协作。当监视到核心交换机输出队列出现拥塞,通过BCN消息告知源,该消息包括拥塞程度。源节点利用集成的速率调节器(例如,令牌桶流量整形器)更新流传输速率响应接收的BCN消息。BCN系统模型如图2所示。

Fig.2 BCN model图2BCN系统模型
(2)QCN
QCN主要包含两个算法:交换机拥塞点(congestion point,CP)算法和速率限制器反应点(reaction point,RP)算法。CP算法的目的是将交换机缓冲占用维持在期望的水平。在当前速率非常小时,RP算法通过使用定时器收敛到高发送速率,能主动增加其速率以恢复丢失的带宽并探测额外的可用带宽。
BCN和QCN均在拥塞的交换机处对到达的包进行采样并且向发送方发送反馈,根据队列长度标识拥塞程度。BCN旨在保持高吞吐量,最小化队列延迟,并实现相对公平。而QCN的目标是在数据链路层提供稳定、有效的拥塞控制。QCN在反馈消息产生的流量方面比BCN更有效,但QCN的链路利用率和吞吐量较低。这主要是在TCP Incast场景下流之间不公平性造成的。因此在QCN的基础上针对公平性提出了两种QCN改进方案。
(3)AF-QCN
AF-QCN(approximately fair QCN)[13]对QCN进行了修改,以保证更快的公平收敛,它不同于QCN中所有流均具有相同的拥塞反馈信息,它是根据估算的发送速率区分每条流,然后根据反馈信息调节每条流的发送速率。
(4)F-QCN
F-QCN(fair QCN)[14]主要用于改善共享瓶颈链路中多个流的公平性。它将QCN消息反馈给所有流的源端,源端根据流所占共享瓶颈链路容量比例调节发送速率,从而实现共享瓶颈链路的公平性。
以上方法都是通过检测拥塞交换机,向发送方发送反馈,调节发送速率缓解拥塞。这些基于两层实现的拥塞通知方案一定程度上能缓解TCP Incast问题,但效果不显著。
5.1.2 流控机制
基于交换机实现流控也有相应方案。诸如以太网流控[8]和优先级流控[15]提供的流控机制可以有效地管理发送到单个交换机的聚合数据量,从而缓解TCP Incast问题。
(1)EFC
支持EFC(Ethernet flow control)的过载交换机可以向发送数据接口的拥塞缓冲区发送“暂停”帧,通知连接到该接口的所有设备在给定的时间内停止或转发数据。在此期间,过载交换机可以减轻其队列压力。EFC对于所有客户端和服务器连接到单个交换机时是有效的,然而由于交换机的先进先出(first in first out,FIFO)机制和队头阻塞,当拥塞缓冲区的暂停帧意图停止导致拥塞的流时,它会同时阻塞其他正常流。同时由于交换机供应商不同,会导致交换机实现存在不一致问题。
(2)PFC
针对阻碍其他流问题,PFC(priority-based flow control)方案被提出。该方案将基本的PAUSE语义扩展到多个服务等级,使需要流控的应用能够在提供流控功能的线路上表现更好,能有效地缓解Incast问题。
表1总结了链路层解决方案的本质及优缺点,这些方案主要根据交换机反馈或直接控制交换机缓解拥塞,很多研究通过改进先前方案不足实现更好的功能,其中PFC方案依旧被广泛应用。
5.2 传输层
传输层缓解或解决TCP Incast问题的解决方案主要分为三大类:
(1)参数调整。改善DCN中TCP重传的机制,使得重传尽快执行,提升吞吐量。
(2)传输机制优化。通过改进拥塞控制,尽量避免或减少瓶颈链路交换机缓存区占满的情况,减少丢包,降低TCP Incast问题发生概率。
(3)协议替换。通过采用其他传输协议,从根本上解决该问题中TCP协议带来的弊端。
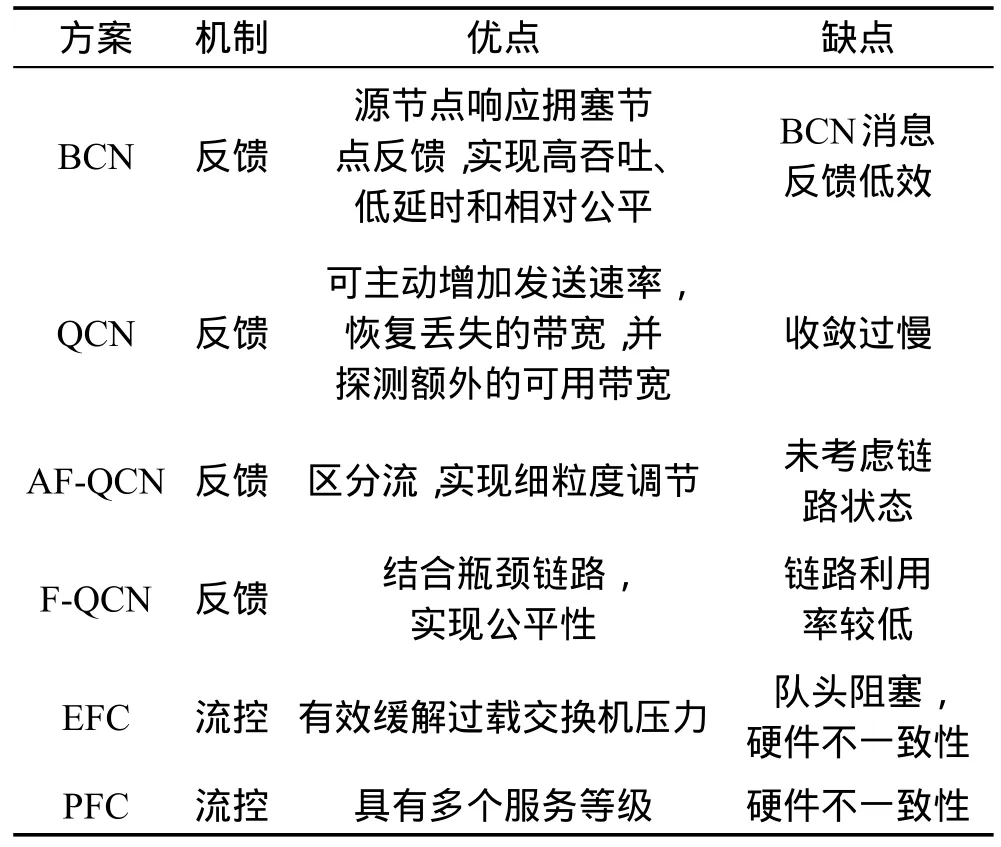
Table 1 Solutions comparison of link layer表1 链路层解决方案对比
5.2.1 参数调整
(1)减小RTOmin
数据中心中的RTT相比于以太网小2到3个数量级,使用默认的RTO会大大降低网络的吞吐量。早在2008年之前,就已经有人提出减小TCP的RTO设置来缓解Incast造成的不利影响。该方案对于缓解Incast问题有一定的作用,但是存在两个主要的缺陷:一是系统时间精度不够,DCN中RTT往往是100 μs的量级,Linux系统难以支持这样的精度,方案实现难度很大;二是RTO设置时间太短,容易造成误判,导致误超时,同样对网络造成不利的影响。2009年,Vasudevan等人在文献[16]中提出了毫秒级别的RTO和随机RTO方案,在文献[5]中,使用高精度的系统时钟,研究了RTO对Incast场景下吞吐量的影响,证明了该方案的改进能够有效提升吞吐量。因此,可深入研究时间精度和误超时问题。
(2)关闭DelayedACK机制
修改Delayed ACK机制的出现一般都是伴随着减小RTO而产生的。Delayed ACK本来是试图通过一个ACK来确认多个数据包,以此来减少网络中ACK包的数量。但如果接收者收到一个包而没有收到其他包,就会等待一个超时时间,再最终决定反馈一个ACK,这个超时时间一般是40 ms。当RTO减小时,若小于Delayed ACK的默认超时时间,就会造成误超时,从而发生重传。在文献[5,16]中都研究了Delayed ACK对于网络吞吐量的影响,发现若关闭DelayedACK机制,可提升一定的吞吐量,因此建议数据中心应当尽量避免粗粒度的DelayedACK机制。
然而在文献[7]中,通过重现Delayed ACK修改方式,发现是否关闭DelayedACK对于RTT的均值没有太大影响。原因就是关闭DelayedACK机制后,会造成很大的RTT波动,不会对RTT均值产生太大影响。该方法对解决TCP Incast问题的有效性较差,因此对该方案的有效性有待进一步研究。
(3)基于SDN初始参数动态调整
随着SDN技术思想的提出和部署,2012年,利用SDN控制器掌握网络拓扑等全局信息的特点,Ghobadi等人提出了OpenTCP[17],其架构见图3。其主要思想即SDN控制器统计网络特性,并向ToR交换机发送拥塞更新信号(congestion update epistles,CUE),交换机再向终端反馈,作为内核模块安装在终端的拥塞控制代理(congestion control agent,CCA)根据相应信息调整TCP初始拥塞窗口(initial window,IW)以及超时重传RTO参数,降低网络丢包可能性以及丢包影响,从而缓解TCP Incast问题。2013年Jouet在文献[18]中也提出了相同的思想,并给出了明确的参数计算公式。通过完善前期工作,2016年Jouet提出了OTCP(omniscient TCP)[19],不同于之前工作,其主要着重于具体实现,明确通过SDN如何进行数据统计和反馈。
通过SDN获取全局信息,调节TCP中IW和RTO参数能一定程度缓解该问题,为解决TCP Incast问题提供了全局视角,但由于网络流量具有突发性,更新周期的确定也具有一定挑战。
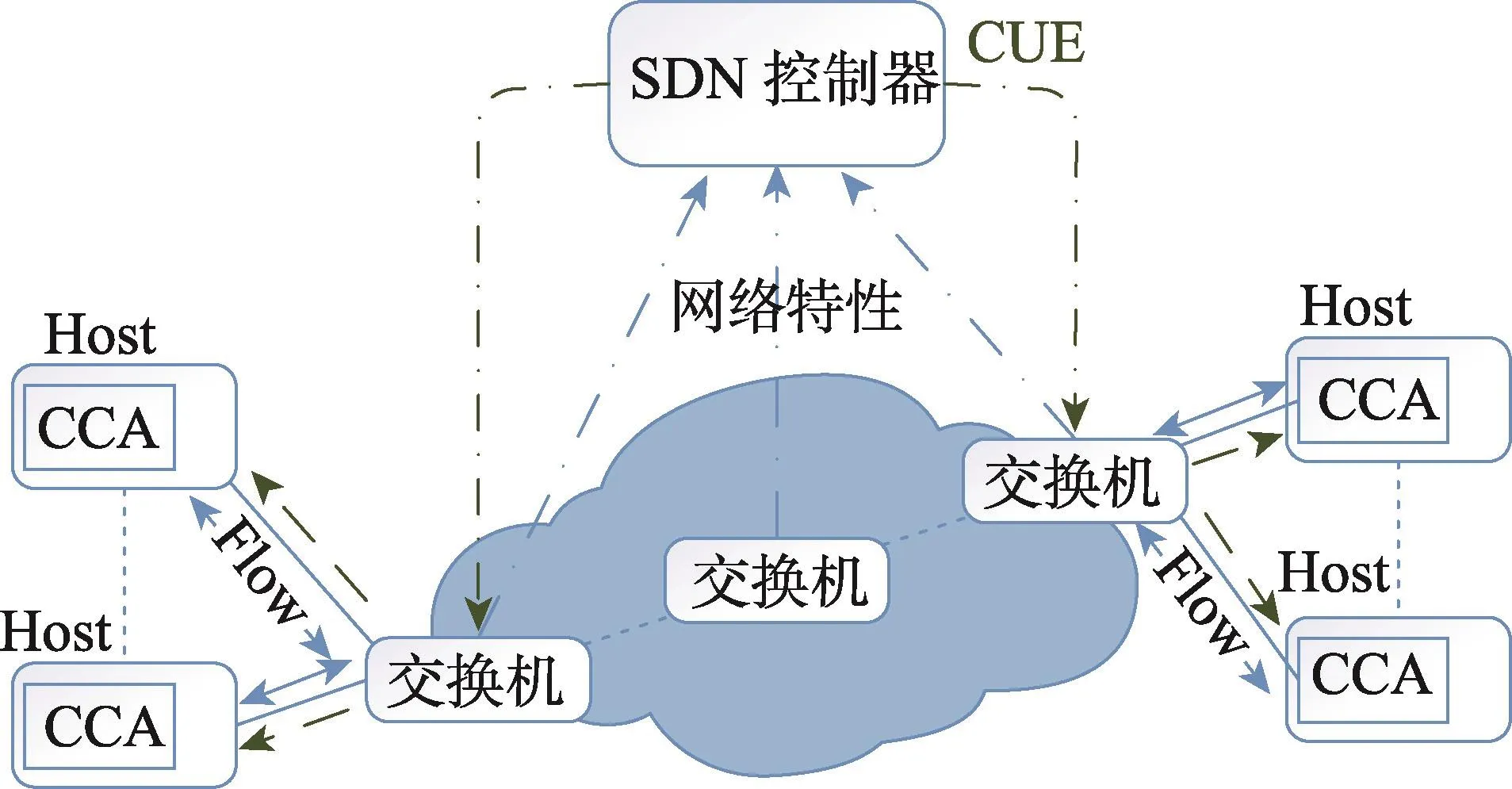
Fig.3 Frame of OpenTCP图3OpenTCP架构
5.2.2 传输机制优化
(1)DCTCP
DCTCP(data center TCP)由 Alizadeh等人 2010年在文献[1]中提出,属于TCP的变体,改善数据中心中TCP存在的缺陷。主要思想是交换机通过队列长度识别拥塞状况,间接通过显式拥塞通知(explicit congestion notification,ECN)作为反馈来调节发送端的发送速率,避免拥塞。DCTCP算法实现了突发流处理、低时延和高吞吐量,具体工作过程如下。
交换机预先被设置好一个阈值,当队列长度超过这个阈值时,就会通过CE标记告知接收端,该数据包经历了拥塞;然后接收端在ACK上打上ECN标签,告诉发送方调节发送窗口;发送方就会根据记录包中ECN标记比例数,通过相应方式调节发送窗口,控制发送速率,从而实现拥塞避免。
在传统的TCP中,出现拥塞时会将发送窗口减半,而在DCTCP中,使用式(8)调节拥塞窗口:
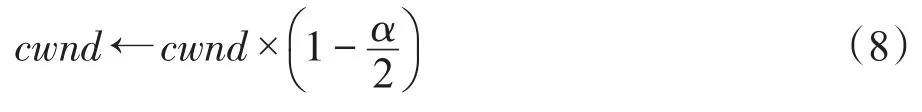
其中,α为估计队列长度的参数,范围在0到1之间,代表拥塞程度。这种发送窗口的好处是可以在队列过长时减小发送速率避免拥塞,而且将调节的幅度与拥塞程度联系,不是每次都减半,这样可以提升窗口恢复速度,从而提升吞吐量。
α依据式(9)计算:

其中,F为当前窗口内的包被标记ECN的比例;g(0~1)是当前拥塞程度占总拥塞程度的权重,可以通过调节该参数控制所需考虑当前拥塞的比重。从上面两式可见F越大,即被标记比例越大,说明队列越长,从而α越大,计算出的拥塞窗口越小。
该方案不仅对于Incast情景有很积极的作用,同时也适用于普通场景。然而DCTCP存在公平性和扩展性问题。有些服务不支持DCTCP,比如部署在文件服务器的应用。而当TCP和DCTCP共存时,DCTCP会完全占有主导地位,使用传统TCP的服务吞吐量基本为0。并且由于交换机缓冲能力有限,当发送端数量超过一定数目时,DCTCP性能急剧下降,从而和传统TCP相当。在文献[20]中,为了实现DCN中全面的DCTCP部署,通过利用IP DSCP字段区分应用是否支持DCTCP,并且令SYN和SYN-ACK支持ECT,使得DCTCP成功建立连接可能性提高,并称此方式为DCTCP+。
(2)ICTCP
与通过使用细粒度超时值(RTO)和DCTCP协议不同,ICTCP(Incast congestion control for TCP)[21]是2013年提出的基于网络剩余带宽和吞吐量来调节接收方的接收窗口的TCP Incast拥塞控制方案,该方法在丢包之前主动调整TCP接收窗口。相对于DCTCP基于每条流进行拥塞调节,ICTCP可在接收端考虑所有流占用带宽情况,实现不同流之间的耦合进行拥塞控制。该算法原理如下。
首先根据链路容量C和测量带宽BWT计算网络剩余带宽BWA:
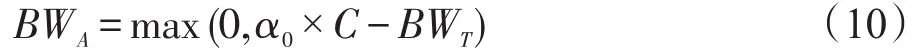
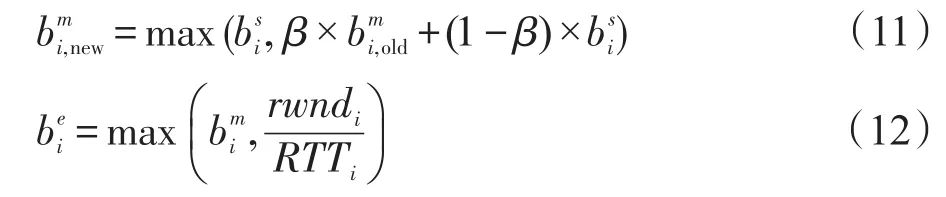
其中,rwndi是该链路的接收窗口;RTTi是该链路的往返时延。
最后定义测量吞吐量和期望吞吐量的差与期望吞吐量的比值为调节接收窗口指标:

在剩余带宽BWA足够的情况下,根据指标调节接收窗口的方法为:

其中,α0、β、γ1、γ2是可控的调节系数和阈值,在实验中均直接取固定值。实验证明,这种通过接收窗口实时控制吞吐量的方式能够有效避免拥塞,提升吞吐量。
ICTCP被设计为NDIS(network driver interface specification)驱动器,在操作系统的TCP/IP协议栈和网卡驱动器之间实现,并且只需要在接收端部署,使ICTCP不改变TCP/IP内核实现,支持更多的操作系统版本,并且支持目前在数据中心中广泛应用的虚拟机。
虽然ICTCP能实现高吞吐量和低超时率,以及支持虚拟机,但它也具有一定的局限性。该算法是针对特定的Incast场景,当在其他网络环境中或Incast场景下发送端数量较少时,吞吐量低于传统TCP。由于只部署在接收端,导致只能解决边沿Incast问题,即瓶颈链路位于接收端,而不能缓解核心交换机出现的Incast问题。
(3)PAC
2014年提出的PAC(proactive ACK control)[22]方案的主要思想是在接收方根据交换机缓存大小、链路状况等信息控制ACK反馈包的发送速率,从而控制瓶颈链路流量大小,解决TCP Incast问题。通过利用ACK触发发送,它能解决基于窗口方案发送端数目可扩展问题。同时由于它不改变交换机和协议栈,也不存在基于恢复方案中存在的部署、开销等问题。
PAC的主要算法思想较简单,即主动控制ACK发送速率保证in-flight流量不超过一定阈值threshold,从而避免Incast拥塞并保持较高的链路利用率。因此主要包括三方面:(1)阈值的设置;(2)in-flight流量的估计;(3)ACK包的调度。由于数据中心的低带宽延时积,初始化阈值为交换机缓存大小,其变化公式如下:其中,考虑到核心网络虽然经历拥塞可能性较小,但依旧会经历持久拥塞,因此利用ECN设置了拥塞指示参数α来调节阈值大小。
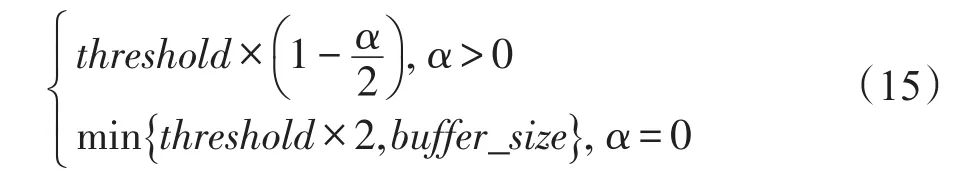
in-flight流量的估计主要分为两部分。
①发送ACK包时
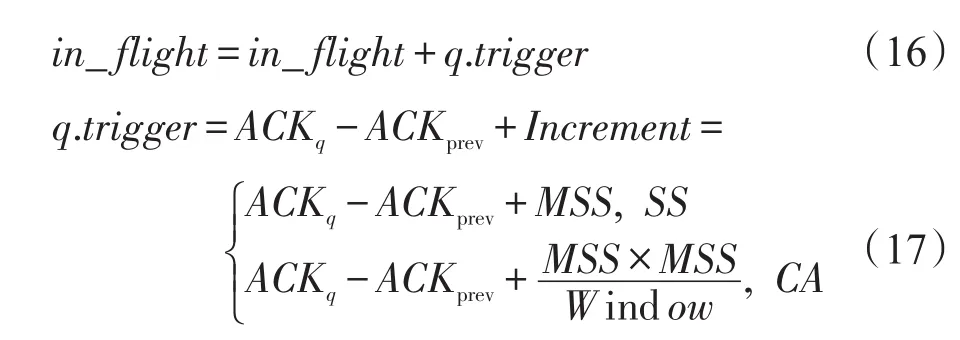
这里是以TCP Reno为例,其中ACKq、ACKprev分别代表PAC需要释放和上次释放ACK包的包序号;Increment的值与慢启动或拥塞避免阶段有关,并根据拥塞窗口改变。
②接收包时
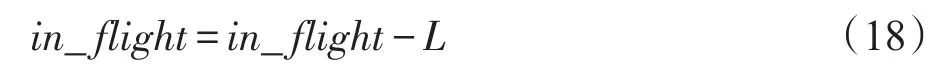
其中,L为收到包的长度。
由于数据中心网络中流量的多样性,在流量大小未知的情况下为实现自适应调度,巧妙地通过不同优先级队列执行MLFQ(multi-level feedback queue)实现了不同流的ACK自适应调度。该方案的实现类似于ICTCP的实现,在Windows平台将PAC设计为NDIS驱动,在Linux平台将PAC实现为内核模块。
通过实验,得出PAC性能优于ICTCP、DCTCP大概40多倍的结论,但同式(17)所示,该算法与慢启动、拥塞避免机制相关,因此会限制可支持的拥塞避免算法。同时由于利用ACK包触发机制,该算法需考虑DelayedACK机制的影响。
(4)PS
2015年黄家玮等人针对大量并行TCP流传输场景提出了PS(packet slicing)方案[23]。该方案结合拥塞窗口和包大小的相关性,根据实时网络状态,在交换机分析计算并通过发送ICMP(Internet control message protocol)消息告知发送方最佳包大小,以减小整个窗口包丢失的可能性。
TCP超时主要是因为整个窗口的包丢失,所以将整个窗口包丢失的概率近似为该流出现超时的概率p,有:

则发生TCP Incast的可能性P即n条流中至少一条流发生超时的概率,因此
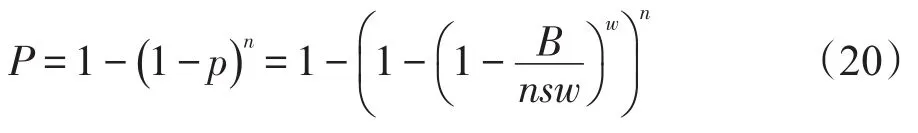
其中,B为缓存大小;n为流数;s为包大小;w为每条流的拥塞窗口大小。
通过分析可知,减小包的大小比减小窗口能更有效地缓解TCP Incast问题。由于减小包大小会带来包头开销,将实际吞吐量G进行如下量化:
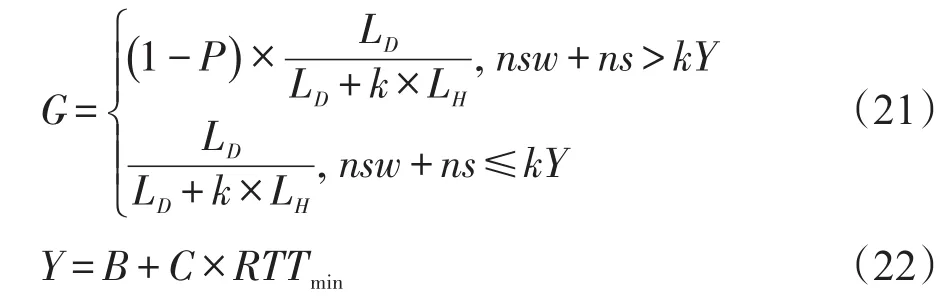
其中,LD和LH分别代表包有效负载和包头长度;k为调节的分片因子;C和RTTmin分别代表链路容量和传播时延。

通过k̂调节包大小减小了Incast发生的可能性,且只部署在ToR交换机上,兼容不同TCP版本,但该方案存在一些不可忽视的问题。首先包大小的计算是基于每条流在每个服务器的包个数为均匀分布,即窗口大小相等的假设,然而由于网络的动态性,每个服务器的窗口大小都是动态变化的;其次在当前较廉价的商用交换机上实现包大小的计算并发送消息,会增加交换机开销;同时减小包大小降低Incast可能性带来的增益与增加的包头开销难以衡量。
(5)CP机制
CP(cutting payload)机制[24]是一种丢弃负载的方式,主要在以下三方面分别实现,工作原理如图4所示。
交换机:当交换机缓冲区过载时,把包的有效负载丢弃,但保留包头部分,如图中包4和5;接收端:根据包头中五元组等信息设置PACK(precise ACK)包,明确告知发送方哪些包经历拥塞;发送端:根据PACK包选择相应的调节策略和重发机制。
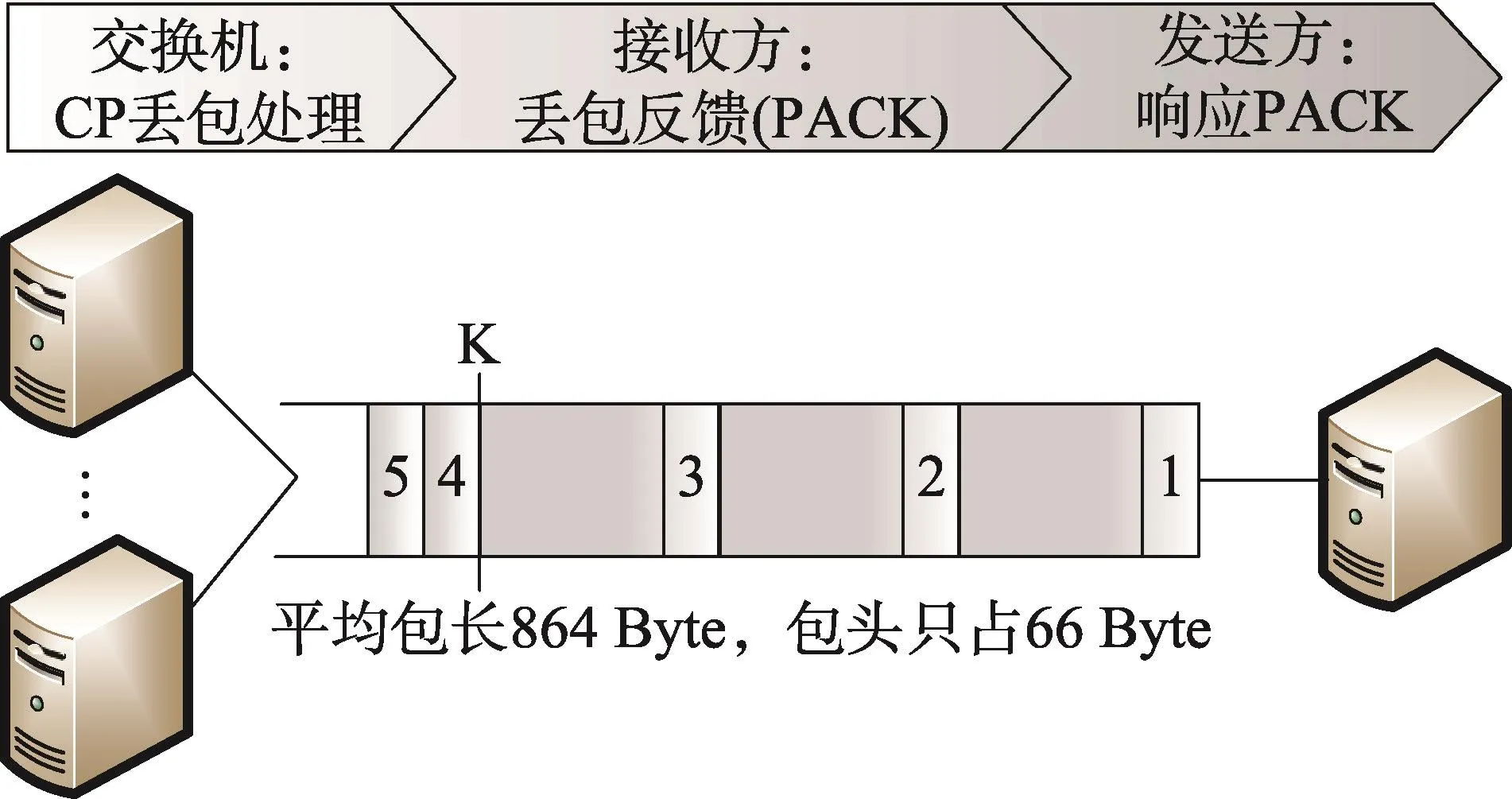
Fig.4 CP mechanism图4 CP机制示意图
由于平均包长为864 Byte,而包头只占66 Byte,因而在一定程度上通过减小包大小增加交换机中包的数量,并明确告知发送方需重传的包,能有效地改善吞吐量等问题。
(6)GIP
2013年,张娇等人在2011年的理论建模分析模型(见4.2节)的基础上提出了GIP(guaranteeing important packets)[25],一种TCP增强协议。同样认为Incast场景下造成吞吐量下降的主要原因为两种超时:FLoss-TO(full window loss timeout)和LAck-TO(lack of ACK timeout),分别对应于4.2节中的BHTO和BTTO。
GIP针对两种类型的超时提出了两种缓解机制。根据造成两种超时的根本原因,GIP机制首先在每个块单元开始发送时,减小每个发送者的拥塞窗口初始值避免FLoss-TO;另外,通过冗余传输块单元的最后一个包避免LAck-TO。
GIP在应用层和传输层间使用flags接口标识当前应用是否为Incast通信模式,在端主机上只需较小改动,且不影响其他基于TCP的应用,从而GIP具有较好的兼容性。然而当同步发送者较少时,第一个机制会导致瓶颈链路利用率不高,即GIP只适合发送者较多的Incast场景。
(7)TCP PLATO
为解决超时重传导致吞吐量下降的影响,Shukla等人于2014年提出了包标记系统PLATO(packet labelling to alleviate time-out)[26],它基于 NewReno 实现,不同之处主要为丢包检测机制。
在不考虑ECN和选择性确认(selective ACK,SACK)技术时,传统TCP有两种常用机制处理丢包重传:第一种为超时重传,第二种为快速重传。当出现丢包时,后者不需要等待RTO时长,且后者链路带宽平均利用率较高,因此PLATO的主要思想即保证系统丢包的快速重传而非超时重传。
在系统中存在3种主要的丢包不能触发快速重传:(1)阻塞丢包,窗口内所有包丢失;(2)尾部丢包,TCP流最后3个包中的某几个包丢失;(3)再次丢包,重传包丢失。PLATO主要针对以上情况提出了包标记机制,在发送端根据系统状态机决定是否发送被标记的包(核心包),接收端接收到核心包时返回被标记的ACK包,其中假设交换机不会丢弃核心包,源端有无限包需转发。该机制下可保证发生丢包时发送方会收到至少3个重复ACK包进入快速重传。
PLATO通过改变IP包头的DSCP字段实现包的标记,要求交换机支持加权随机早期检测(weighted random early detection,WRED)。该机制需要改动源端和目的端,且是出现丢包后的处理机制,网络已出现较严重拥塞,并未从根本上解决TCP Incast问题。
5.2.3 基于编码的UDP
2012年在文献[27]中,作者另辟蹊径,没有追随前人减小RTO或增强TCP协议来解决Incast问题的方案,而是想从根本上去除Incast场景中TCP方式的弊端,缓解Incast带来的影响。UDP没有超时和重传机制,因此使用改造UDP的方式来代替TCP。
修改UDP协议代替TCP主要有两个挑战:第一个挑战是UDP没有可靠传输保障和避免乱序保障;第二个挑战是无拥塞控制。
对于前者,使用LT(Luby transform)码解决,利用数据冗余换取可靠传输,同时解决了UDP包乱序的问题;对于后者使用TFRC(TCP friendly rate control)进行拥塞控制。具体过程为:首先通过TCP建立连接,传输控制信息;然后客户端向多个服务器同时请求数据(即Incast场景),服务器对数据进行LT编码,再通过UDP发送编码后的数据;同时TFRC部署在服务器和客户端上进行拥塞控制,一旦客户端成功解码,则向服务器发送终止信息,完成数据传输。
这种方式虽能够解决Incast问题,但存在很多缺点。首先是信息冗余,编码过程会带入一些信息的冗余开销;再者是使用了新的传输层协议,而且使用新的拥塞控制算法,需要在客户端和服务器端都做相应的更改,这在真实场景中不易部署。
表2对传输层解决方案的机制本质和优缺点进行了总结。这些方案分别从减小超时影响,避免超时以及替换TCP角度出发,能一定程度缓解TCP Incast问题,其中DCTCP受到广泛认可,而其他方案暂时处于研究阶段。
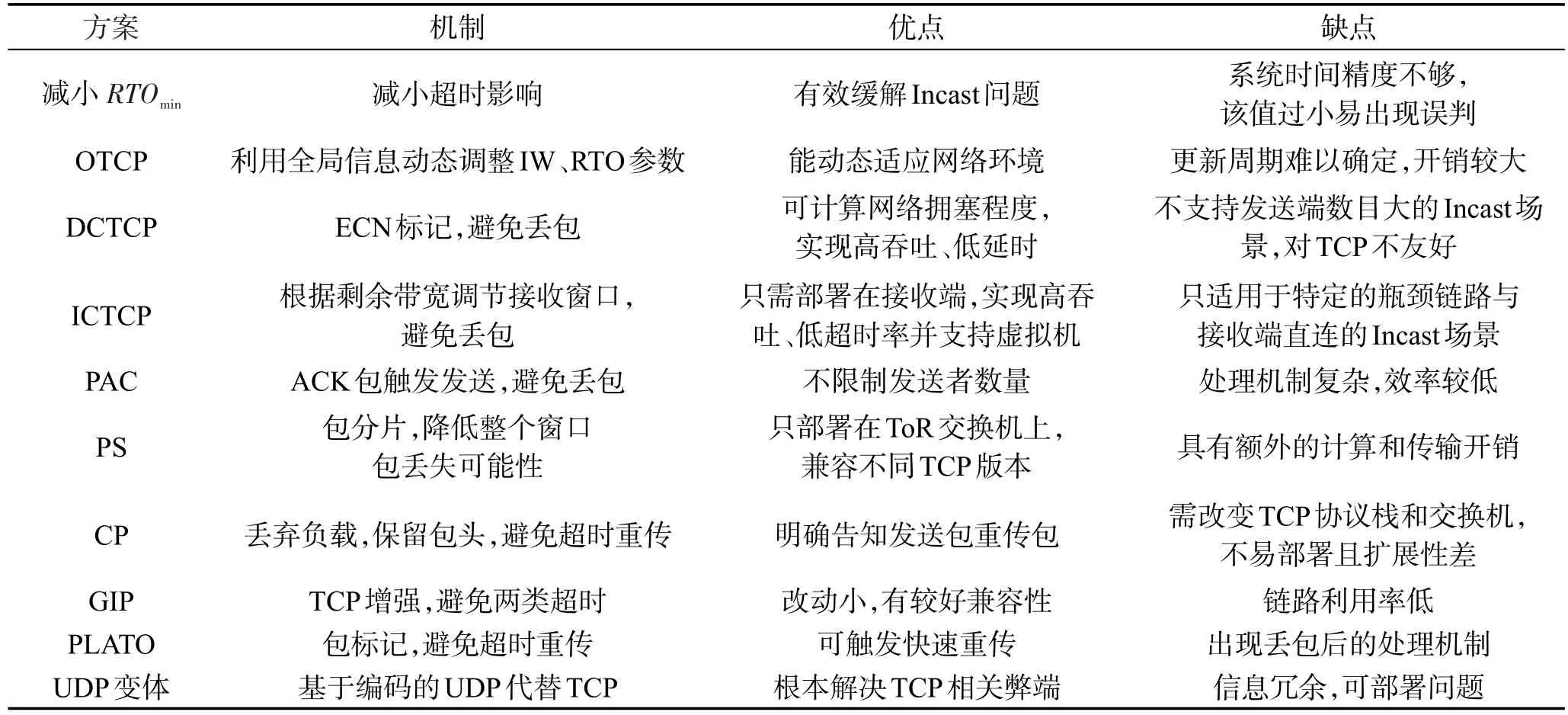
Table 2 Solutions comparison of transport layer表2 传输层解决方案对比
5.3 应用层
2007年Krevat等人在文献[28]中针对Incast问题提出了限制并发流数、交错数据传输、数据传输的全局调度等应用层解决角度的建议。近几年基于以上角度,提出了很多应用层解决方案。
(1)XCo
XCo[29]是对数据中心中广泛应用的虚拟机的网络传输进行协调,实现避免拥塞以及吞吐量崩溃问题。XCo架构思想是一个或多个控制器与网络相连,控制器掌握互联拓扑,当前流量矩阵,虚拟机的优先级、带宽、响应时间等策略需求,并周期性地给虚拟机协调器下达传输指令,协调网络中多个虚拟机的传输速率,使得提高网络利用率的同时,能保证发送的数据不会超过交换机的缓存。该方案与5.2节利用SDN技术类似,但存在本质区别。
文中利用循环掩码提出了相应的时间调度算法,控制每个时间段激活主机的数目,从而实现拥塞避免。该架构也支持其他调度策略,如速率调度。
XCo架构不改变应用、协议或网络交换机,支持任意拓扑,能从源头解决TCP Incast问题,但数据中心网络中时延特性不可忽视;同时,该架构的容错性、协调开销也是必须考虑的方面。
(2)交错流
文献[30]在应用层提出了一种可以避免Incast问题发生的可扩展方法。从网络中所有流的微观角度来看,每条流的数据包到达接收端的时间是不同的,但是由于相邻时刻的间隔非常小,使得这些流看起来是并发的。如果能使得这些流交错发生,并使得流的间隔周期足够长,那么这些流就不会出现相互冲突,从而缓解交换机队列的压力。
文中提出的方法定义了round的概念(见图5),即每个发送端完成一个SRU传输,接收端收到所请求的当前数据块的时间周期。然后,在每一个round时间内,人为地在每个相邻的数据流传输开始点之间插入一个交错时间长度(见图6),来实现流的交错传输。直观上即可推出,交错时间长度越接近一个SRU的传输时间,性能越好。
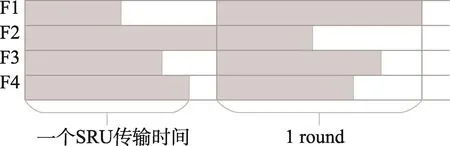
Fig.5 Pattern of concurrent flow图5 并发流传输模式示意图
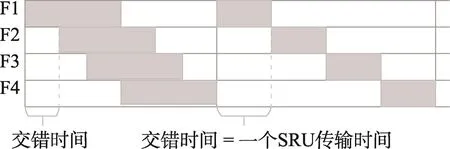
Fig.6 Pattern of asynchronous flow图6 交错流传输模式示意图
通过阻止并发流的传输可有效缓解交换机压力,然而由于网络环境的复杂性,很难对网络中的交错时间长度进行估计,且接收方向发送方逐一请求数据会带来不可忽视的请求时间开销,一定程度上会增大流完成时间。
(3)并行连接限制
文献[31]指出将网络中最大并发连接数限制到预设值的方法不适用于SRU很小的情况,且最大连接数量无法优化,可能导致即使Incast没有发生,仍出现网络吞吐量很小的情况,文中提出了一种对任意SRU大小适用且最大连接数量可优化的方法。
由于客户端利用带宽延时积BaseBDP(瓶颈链路带宽C与传播时延BaseRTT的乘积)作为其接收窗口,因此每个服务器发送窗口sendwin为:
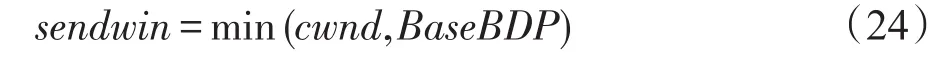
假设初始拥塞窗口设置为2,由于慢启动机制,发送窗口的初始递增阶段时长T1和到达BaseBDP开始至连接结束时长T2可由以下公式分别计算:
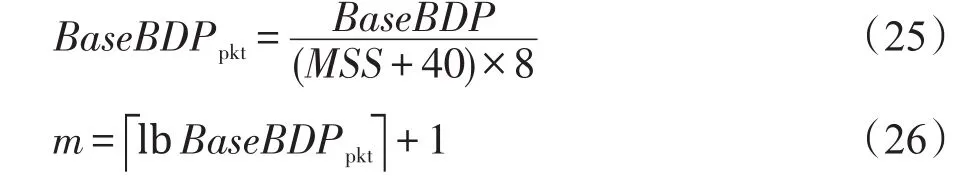
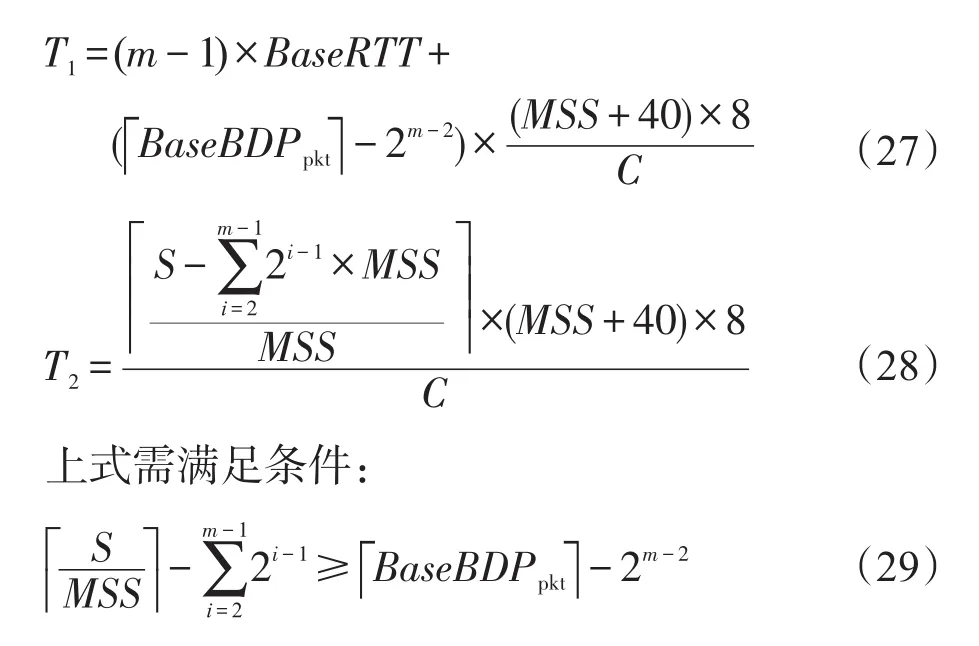
其中,S为SRU大小。
分析式(28),可发现当SRU很小时,T2很小,因此导致带宽利用率较小。于是在上述完全序列化方法(交错时间=SRU传输时间)的基础上尽可能避免未充分利用阶段提出了近似完全序列化方法,即在当前连接已发送一定数据量时,便建立新的连接,同时设置交叠参数K限制并发流交叠数。但是当SRU小于某个阈值时,由于式(30)限制,并不能采用该方法,从而又提出了最优序列化方法,当SRU小于某阈值x时,将网络中n个连接作为一个集合,视为一个连接,实现在不产生Incast问题下吞吐量的最大化。
因为近似序列化方法中限制条件为T2≥2×T1,即
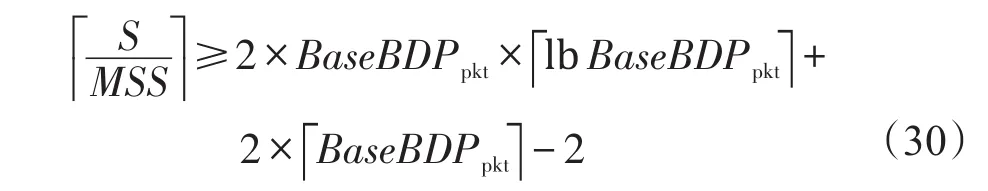
因此当S不满足式(30)时,采用最优序列化方法,通过式(31)求出耦合流数nmin:
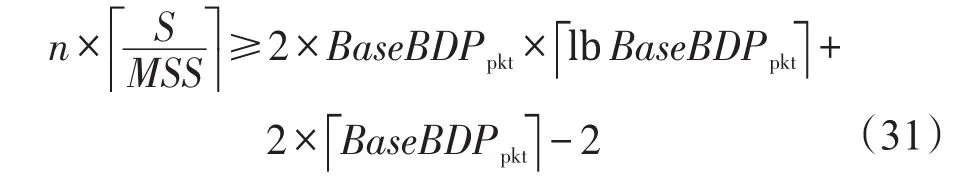
该3种方法的结合使得控制连接间隔时间是对于任意的SRU大小定义的,同时建立连接的数量是可优化的,因此通过控制连接间隔时间与并行连接数实现高吞吐量。
(4)ARS
2016年黄家玮教授等人在解释模型(见4.3节)和2015年提出的PS方案(见5.2节)基础上又提出了一种跨层(核心为应用层)的设计方案ARS[32](adaptive request schedule),实现自适应的请求调度。ARS根据从传输层获得的拥塞状态来分批处理应用层请求,采用动态调节并发的TCP流数量来解决Incast问题。
造成TCP超时的主要原因是由于整个窗口的包丢失[8],文中计算了整个窗口包丢失的可能性即超时可能性PTO:
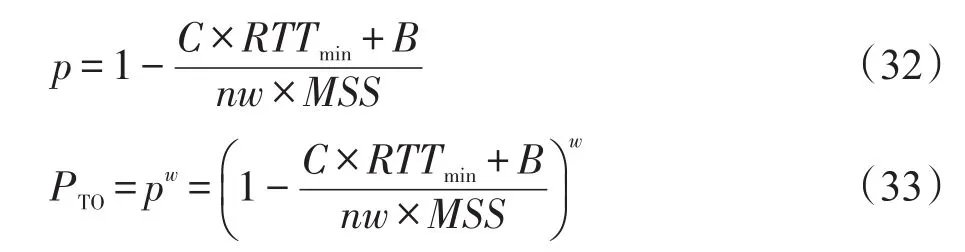
因此n条流中至少一条流经历超时,发生Incast的可能性P为:
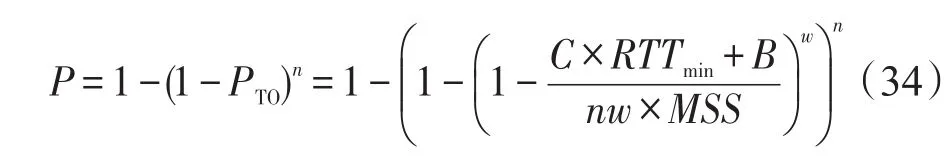
其中,C为链路容量;RTTmin为往返传播时延;B为交换机缓存大小;MSS为TCP段大小;n为流数;w为平均拥塞窗口大小。
相对于5.2节中的PS方案,ARS假设每个包的大小固定为1MSS。通过式(34)可知,发生Incast的可能性P与拥塞窗口w和流数n相关。通过理论分析和实验证明,相比于减小拥塞窗口,控制流数能更有效地解决TCP Incast问题。文中将包乱序作为拥塞的一个指标。
从应用层角度来说,ARS不需要修改下层协议和硬件,且只部署在聚合层,具有较强的适用性和兼容性,但方案针对性太强。
表3对应用层解决方案的机制本质和优缺点进行了总结。

Table 3 Solutions comparison of application layer表3 应用层解决方案对比
6 方案对比
表4从不同角度整体分析了上文涉及的方案。其中L、M、H分别代表低、中、高程度;“—”代表不予以讨论;“√”、“×”分别代表是与否。公平性代表采用不同方案的流相互竞争时带宽分配的公平性,而部分方案如应用层方案涉及系统中所有流,因此公平性不予以讨论。
从表4中可以发现,针对TCP Incast问题,链路层解决方案的有效性较低,这主要是因为链路层的主要手段是拥塞反馈。可以看出,目前较被看好的解决方案已从链路层转向传输层和应用层,其中传输层研究占较大比例。传输层方案的主要问题在于需要改变TCP协议栈或交换机。例如DCTCP和ICTCP方案,两者都能较高效地缓解TCP Incast问题,但都只适用于较小规模的同步发送者情况。DCTCP需要修改协议栈且要求终端和交换机支持ECN,而ICTCP需在接收端部署相应的驱动器。应用层方案对底层改动较小,使其可部署性整体优于传输层方案。应用层方案的问题主要在于需较全面的流信息、操作的复杂性以及开销的控制。
7 总结与展望
TCP Incast问题本质是一种特殊的拥塞现象,而这种现象在数据中心中较为常见,因此在设计较全面的拥塞控制方案时必须评估常见场景下该解决方案的性能。由于数据中心环境的复杂性,会更多地考虑解决方案的开销、适用性以及可部署性。
从全文可知,针对TCP Incast问题,在解决精度和误判情况下,减小RTOmin能有效改善吞吐量,并且控制流并发数以及包大小比控制拥塞窗口更有效。当前数据中心中DCTCP及其优化方案被广泛认可,早期提出的PFC作为路由控制方案也被广泛应用,其他方案主要处于学术界研究阶段,其部署还依赖于工业界的推进。但结合数据中心环境,有效解决TCP Incast问题更多的建议是采用应用层方案。
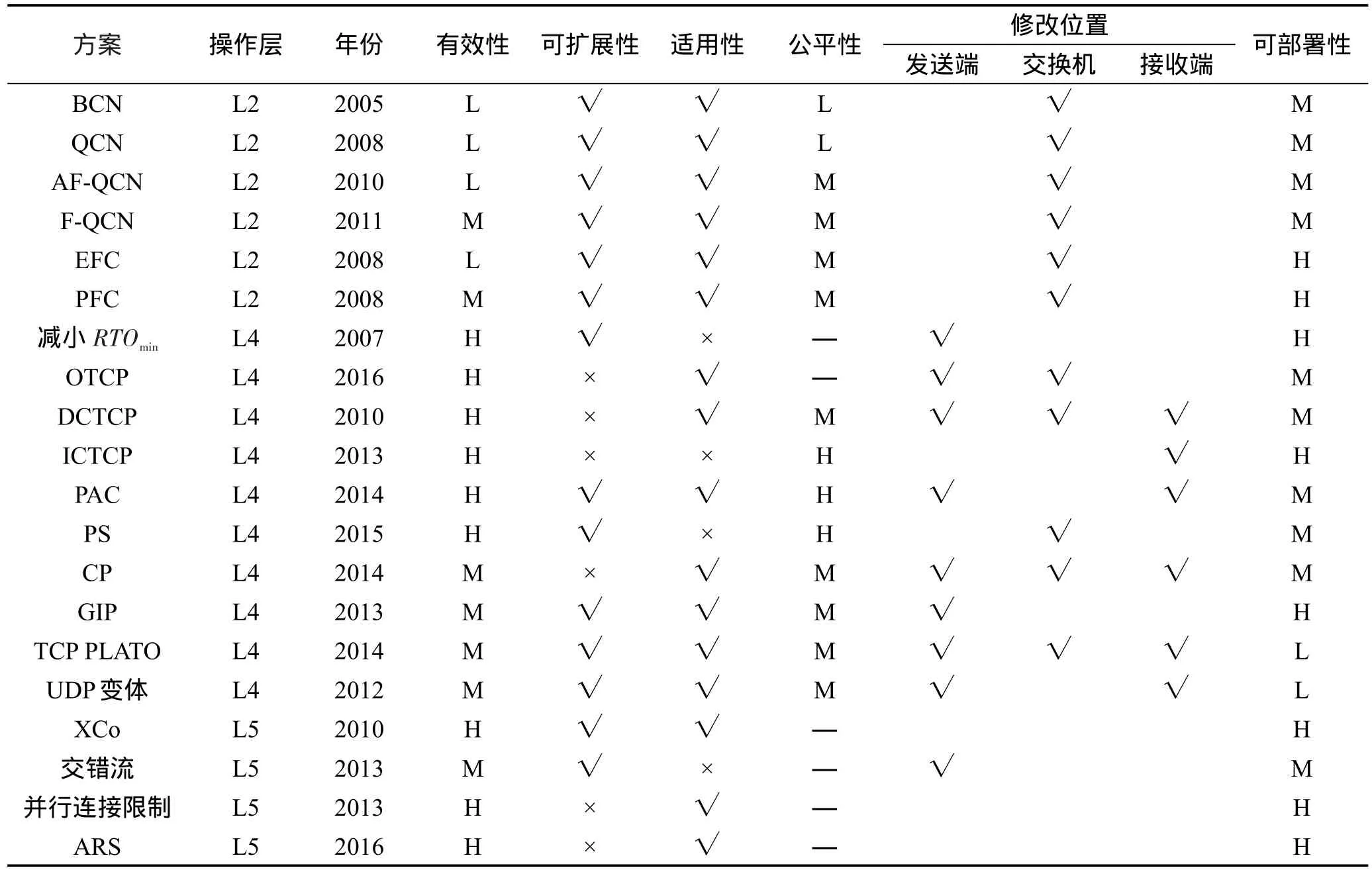
Table 4 Comparison of all solutions表4 解决方案对比表
当前解决方案或多或少都存在一些弊端:(1)可扩展性不强,如增大交换机缓存等只能一定程度缓解TCP Incast问题;(2)通用性不强,如实现细粒度RTOmin可能会造成虚假重传,与其他属性相互依赖;(3)适用场景局限性,如ICTCP等方案过于依赖系数的选取,灵活性不强,适用场景有限;(4)部署开销问题,如UDP变体存在冗余开销,预替换传统TCP协议需要较长过渡期。
鉴于对方案的分析,结合当前学术界和工业界关注的热点,总结了针对TCP Incast问题未来可能的研究方向。
(1)现有技术交叉融合
①机器学习
很多方案依赖系数的选取,人们可利用机器学习,建立参数间的相关性,在终端设计调节参数的控制模型。例如微软实现的Pingmesh[33]每天会生成超过2 000亿的探针,产生24 TB的数据,可复用这些数据,利用机器学习分析数据特征,如周期性等,更好地控制网络状态,避免TCP Incast问题。
②SDN技术+在线机器学习
5.2节中有相关方案运用SDN技术解决TCP Incast问题,使利用全局网络状态信息进行拥塞控制成为可能,可通过部署相应代理或设计接口调节TCP参数。前文方案主要是调节IW和RTO两个参数,而部分流实时性较强,系数的选取也很关键,该方案仍有较大缺陷。而单独的机器学习依赖于探针产生数据,如果结合两者,可利用机器学习分析控制器统计的网络特性进行实时反馈改善突发流性能,但处理相对更复杂。阿里巴巴基于Flink的系统Blink(https://data-artisans.com/blog/blink-flink-alibaba-search)中在线机器学习模型可将实时用户行为数据反馈到系统,该平台已经运行1年,并在去年双11中为用户提供了更好的服务,若将该技术与SDN相结合,有望有效改善TCP Incast问题。
(2)设计新的传输协议
另一种可行的思路是设计一种适合数据中心的传输层协议来替代TCP,避免TCP Incast问题。近几年Google也提出了基于UDP的QUIC协议(quick UDP Internet connection)[34],目前在Chrome浏览器和YouTube等Google服务器已支持,且正推进IETF标准化工作。重新设计传输协议能够以较小的开销有针对性地克服一些问题,例如QUIC协议采用多路复用来解决队头阻塞问题。考虑在下一步的工作中利用QUIC协议中较大范围的NACK(negative ACK,类似于TCP中SACK)以及更详细的延时反馈信息来解决TCP Incast问题。
(3)新型架构与硬件设备
从交换机硬件设施入手,通过合理的体系结构设计解决根本的阻塞等问题。例如,Samadi等人提出了在光纤网络中结合分组交换与电路交换的混合网络架构,其中采用的光交换机(optical space switches,OSS)[35]也是解决TCP Incast问题的有力补充。
[1]Alizadeh M,Greenberg A,Maltz D A,et al.Data center TCP(DCTCP)[J].ACM SIGCOMM Computer Communication Review,2010,40(4):63-74.
[2]Zhang Yan,Ansari N.On architecture design,congestion notification,TCP Incast and power consumption in data centers[J].IEEE Communications Surveys&Tutorials,2013,15(1):39-64.
[3]Rojas-Cessa R,Kaymak Y,Dong Ziqian.Schemes for fast transmission of flows in data center networks[J].IEEE Communications Surveys&Tutorials,2015,17(3):1391-1422.
[4]Nagle D,Serenyi D,Matthews A.The panasas active scale storage cluster—delivering scalable high bandwidth storage[C]//Proceedings of the 2004 Conference on Supercomputing,Pittsburgh,USA,Nov 6-12,2004.Washington:IEEE Computer Society,2004:53.
[5]Vasudevan V,Phanishayee A,Shah H,et al.Safe and effective fine-grained TCP retransmissions for datacenter communication[J].ACM SIGCOMM Computer Communication Review,2009,39(4):303-314.
[6]Kandula S,Sengupta S,Greenberg A,et al.The nature of data center traffic:measurements&analysis[C]//Proceedings of the 9th ACM SIGCOMM Internet Measurement Conference,Chicago,USA,Nov 4-6,2009.New York:ACM,2009:202-208.
[7]Chen Yanpei,Griffith R,Liu Junda,et al.Understanding TCP Incast throughput collapse in data center networks[C]//Proceedings of the 1st ACM SIGCOMM 2009 Workshop on Research on Enterprise Networking,Barcelona,Spain,Aug 21,2009.New York:ACM,2009:73-82.
[8]Phanishayee A,Krevat E,Vasudevan V,et al.Measurement and analysis of TCP throughput collapse in cluster-based storage systems[C]//Proceedings of the 6th USENIX Conference on File and Storage Technologies,San Jose,USA,Feb 26-29,2008.Berkeley,USA:USENIX Association,2008:175-188.
[9]Zhang Jiao,Ren Fengyuan,Lin Chuang.Modeling and understanding TCP incast in data center networks[C]//Proceedings of the 30th International Conference on Computer Communications,Joint Conference of the IEEE Computer and Communications Societies,Shanghai,Apr 10-11,2011.Piscataway,USA:IEEE,2011:1377-1385.
[10]Chen Wen,Ren Fengyuan,Xie Jing,et al.Comprehensive understanding of TCP Incast problem[C]//Proceedings of the 2015 Conference on Computer Communications,Hong Kong,China,Apr 26-May 1,2015.Piscataway,USA:IEEE,2015:1688-1696.
[11]Bergamasco D.Data center Ethernet congestion management:backward congestion notification[C]//IEEE 802.1 Interim Meeting,Berlin,Germany,May 12,2005.Piscataway,USA:IEEE,2015:1-25.
[12]Alizadeh M,Atikoglu B,Kabbani A,et al.Data center transport mechanisms:congestion control theory and IEEE standardization[C]//Proceedings of the 46th Annual Allerton Conference on Communication,Control,and Computing,Urbana-Champaign,USA,Sep 23-26,2008.Piscataway,USA:IEEE,2008:1270-1277.
[13]KabbaniA,Alizadeh M,Yasuda M,et al.AF-QCN:approximate fairness with quantized congestion notification for multi-tenanted data centers[C]//Proceedings of the 18th Annual Symposium on High Performance Interconnects,Moun-tain View,USA,Aug 18-20,2010.Washington:IEEE Computer Society,2010:58-65.
[14]Zhang Yan,Ansari N.On mitigating TCP Incast in data center networks[C]//Proceedings of the 30th International Conference on Computer Communications,Joint Conference of the IEEE Computer and Communications Societies,Shanghai,Apr 10-15,2011.Piscataway,USA:IEEE,2011:51-55.
[15]Priority flow control:build reliable layer 2 infrastructure[EB/OL].San Jose:Cisco Systems,Inc.(2009-06-15)[2017-03-20].http://www.cisco.com/c/en/us/products/collateral/switches/nexus-7000-series-switches/white_paper_c11-542809.html.
[16]Vasudevan V,Phanishayee A,Shah H,et al.A(In)cast of thousands:scaling datacenter TCP to kiloservers and gigabits,CMU-PDL-09-101[R].Pittsburgh:Carnegie Mellon University,2009.
[17]Ghobadi M,Yeganeh S H,Ganjali Y.Rethinking end-to-end congestion control in software-defined networks[C]//Proceedings of the 11th Workshop on Hot Topics in Networks,Redmond,USA,Oct 29-30,2012.New York:ACM,2012:61-66.
[18]Jouet S,Pezaros D P.Measurement-based TCP parameter tuning in cloud data centers[C]//Proceedings of the 21st IEEE International Conference on Network Protocols,Göttingen,Germany,Oct 7-10,2013.Piscataway,USA:IEEE,2013:1-3.
[19]Jouet S,Perkins C,Pezaros D.OTCP:SDN-managed congestion control for data center networks[C]//Proceedings of the 2016 Network Operations and Management Symposium,Istanbul,Turkey,Apr 25-29,2016.Piscataway,USA:IEEE,2016:171-179.
[20]Judd G.Attaining the promise and avoiding the pitfalls of TCP in the datacenter[C]//Proceedings of the 12th Symposium on Networked Systems Design and Implementation,Oakland,USA,May 4-6,2015.Berkeley,USA:USENIX Association,2015:145-157.
[21]Wu Haitao,Feng Zhenqian,Guo Chuanxiong,et al.ICTCP:Incast congestion control for TCP in data-center networks[J].IEEE/ACMTransactions on Networking,2013,21(2):345-358.
[22]Bai Wei,Chen Kai,Wu Haitao,et al.PAC:taming TCP Incast congestion using proactive ACK control[C]//Proceedings of the 22nd International Conference on Network Protocols,Raleigh,USA,Oct 21-24,2014.Washington:IEEE Computer Society,2014:385-396.
[23]Huang Jiawei,Huang Yi,Wang Jianxin,et al.Packet slicing for highly concurrent TCPs in data center networks with COTS switches[C]//Proceedings of the 23rd International Conference on Network Protocols,San Francisco,USA,Nov 10-13,2015.Washington:IEEE Computer Society,2015:22-31.
[24]Cheng Peng,Ren Fengyuan,Shu Ran,et al.Catch the whole lot in an action:rapid precise packet loss notification in data center[C]//Proceedings of the 11th Symposium on Networked Systems Design and Implementation,Seattle,USA,Apr 2-4,2014.Berkeley,USA:USENIX Association,2014:17-28.
[25]Zhang Jiao,Ren Fengyuan,Tang Li,et al.Taming TCP Incast throughput collapse in data center networks[C]//Proceedings of the 21st International Conference on Network Protocols,Göttingen,Germany,Oct 7-10,2013.Piscataway,USA:IEEE,2013:1-10.
[26]Shukla S,Chan S,TamAS W,et al.TCP PLATO:packet labelling to alleviate time-out[J].IEEE Journal on Selected Areas in Communications,2014,32(1):65-76.
[27]Jiang Changlin,Li Dan,Xu Mingwei,et al.A coding-based approach to mitigate TCP Incast in data center networks[C]//Proceedings of the 32nd Conference on Distributed Computing Systems Workshops,Macau,China,Jun 18-21,2012.Washington:IEEE Computer Society,2012:29-34.
[28]Krevat E,Vasudevan V,Phanishayee A,et al.On applicationlevel approaches to avoiding TCP throughput collapse in cluster-based storage systems[C]//Proceedings of the 2nd International Petascale Data Storage Workshop,Reno,USA,Nov 11,2007.New York:ACM,2007:1-4.
[29]Rajanna V S,Shah S,Jahagirdar A,et al.XCo:explicit coordination for preventing congestion in data center ethernet[C]//Proceedings of the International Workshop on Storage Network Architecture 2010 and Parallel I/Os,Incline Village,USA,May 3,2010.Washington:IEEE Computer Society,2010:81-89.
[30]Yang Yukai,Abe H,Baba K,et al.A scalable approach to avoid Incast poblem from application layer[C]//Proceedings of the 37th Annual Computer Software and Applications Conference,Kyoto,Jul 22-26,2013.Washington:IEEE Computer Society,2013:713-718.
[31]Kajita K,Osada S,Fukushima Y,et al.Improvement of a TCP Incast avoidance method for data center networks[C]//Proceedings of the 2013 International Conference on ICT Convergence,Jeju,Korea,Oct 14-16,2013.Piscataway,USA:IEEE,2013:459-464.
[32]Huang Jiawei,He Tian,Huang Yi,et al.ARS:cross-layer adaptive request scheduling to mitigate TCP Incast in data center networks[C]//Proceedings of the 35th Annual IEEE International Conference on Computer Communications,San Francisco,USA,Apr 10-14,2016.Piscataway,USA:IEEE,2016:1-9.
[33]Guo Chuanxiong,Yuan Lihua,Xiang Dong,et al.Pingmesh:a large-scale system for data center network latency measurement and analysis[J].ACM SIGCOMM Computer Communication Review,2015,45(4):139-152.
[34]Hamilton R,Iyengar J,Swett I,et al.QUIC:a UDP-based secure and reliable transport for HTTP/2,draft-tsvwg-quicprotocol-02[R].The Internet Engineering Task Force,2016.
[35]Samadi P,Gupta V,Birand B,et al.Accelerating incast and multicast traffic delivery for data-intensive applications using physical layer optics[J].ACM SIGCOMM Computer Communication Review,2014,44(4):373-374.

YU Yajun was born in 1994.She is an M.S.candidate at Tsinghua University.Her research interests include transport protocol and congestion control,etc.
余雅君(1994—),女,安徽安庆人,清华大学计算机系硕士研究生,主要研究领域为传输协议,拥塞控制算法等。

LIU Zheng was born in 1989.He is a Ph.D.candidate at Tsinghua University.His research interests include Internet architecture,routing protocol and space network,etc.
刘峥(1989—),黑龙江哈尔滨人,清华大学计算机系博士研究生,主要研究领域为互联网体系结构,路由协议,空间网络路由机制等。
Research on TCPIncast in Data Center Networks
YU Yajun+,LIU Zheng,XU Mingwei
Department of Computer Science and Technology,Tsinghua University,Beijing 100084,China
Because the traditional TCP protocol does not apply to the operating mode of data center,the TCP Incast problem occurs when there are common many-to-one traffic patterns in the data center,causing a visible throughput collapse of the application layer.Considering the characteristics of the data center,putting forward a comprehensive solution is the research objective of TCP Incast problem.This paper analyzes the root causes of the problem,enumerates the challenges of the problem,introduces the mathematical model based on the problem,analyzes and summarizes the recent solutions which are classified into link layer,transport layer and application layer,then from the effectiveness,deployment and other different aspects,makes a comprehensive comparison,finding that current solutions based on some specific points almost have drawbacks in different degree.Finally,this paper puts forward some feasible solutions to study the problem,and focuses on combining the technology of SDN and machine learning and designing a new transport protocol.
data center network;TCP Incast problem;throughput collapse
the Ph.D.degree in computer science from Tsinghua University in 1998.Now he is a professor and Ph.D.supervisor at Tsinghua University.His research interests include Internet architecture,large-scale network routing and space network,etc.
2017-05, Accepted 2017-07.

A
TP393
+Corresponding author:E-mail:13261706337@163.com
YU Yajun,LIU Zheng,XU Mingwei.Research on TCP Incast in data center networks.Journal of Frontiers of Computer Science and Technology,2017,11(9):1361-1378.
10.3778/j.issn.1673-9418.1706034
CNKI网络优先出版: 2017-07-20, http://kns.cnki.net/kcms/detail/11.5602.TP.20170720.1019.002.html
徐明伟(1971—),男,辽宁朝阳人,1998年于清华大学获得博士学位,现为清华大学教授、博士生导师,主要研究领域为互联网体系结构,大规模路由,空间网络等。
