基于FPGA的图像超分辨率的硬件化实现
2017-09-08钟雪燕夏前亮陈智军
钟雪燕+夏前亮+陈智军


摘 要: 设计基于FPGA的图像超分辨率双线性插值实现方式,提出基于单输入双输出端口RAM缓冲的二级循环调度机制,用以实现共享资源分配和并行流水处理。单输入双输出端口的RAM实现读取相邻地址的两个数据,RAM的深度为源图像一行的像素点数,宽度为像素数据宽度,实现源数据相邻两行像素的存储。根据位置分析模块得到源图像的位置,将源图像的数据写入相应RAM中进行加权运算。为了提高效率使用乒乓算法,设计了4个RAM,2个RAM为一组,一组RAM在加权运算时,另一组RAM写入数据。该设计在Kintex?7开发板上得到验证,实现图像处理速度达到25~30 f/s,同时图像插值后不仅细节更加清晰,从直方图中可以看到图像得到了均衡化。
关键词: FPGA; 超分辨率; 双线性插值; 循环调度
中图分类号: TN911.73?34; TP391 文献标识码: A 文章编号: 1004?373X(2017)17?0044?03
FPGA?based hardware implementation of image super?resolution
ZHONG Xueyan1, XIA Qianliang2, CHEN Zhijun3
(1. Nanjing Institute of Railway Technology, Nanjing 210031, China; 2. CETC Deqing Huaying Electronics Co., Ltd., Huzhou 313200, China;
3. Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China)
Abstract: An FPGA?based implementation mode of image super?resolution bilinear interpolation was designed. A two?stage round?robin scheduling mechanism based on RAM with single?input and dual?output port is proposed to realize the shared resource allocation and parallel pipeline processing. RAM with single?input and dual?output port can read two data whose address are adjacent. The quantity of pixels within a row in source image is deemed as the depth of RAM, and the width of pixel data is deemed as that of RAM to store the two rows of pixels adjacent to the source data. The position of source image is gotten according to the position analysis module. The data of source image is written into the corresponding RAM for weighting operation. In order to improve the efficiency, the ping?pong algorithm is adopted to design four RAMs which are divided into two groups (each one includes two RAMs). If one group of RAMs is performed with weighting calculation, another group of RAMs is performed with data write?in. The design was verified on Kintex?7 development board, which can process the image with the speed of 25~30 f/s. The interpolated image has clear detail. The image is equalized, which is shown in histogram.
Keywords: FPGA; super?resolution; bilinear interpolation; round?robin scheduling
0 引 言
通常的图像显示设备具有固定的分辨率,低分辨率的图像数据需要进行超分辨率处理,获得与显示设备相匹配的分辨率才能正常显示,如High?Definition TV,HDTV,这一过程本质上就是一种图像超分辨处理。
图像超分辨率技术在各个领域中得到了广泛应用,如公共安全、医学成像、军事、地质、工业及消费电子等产业。通过该技术尽可能提高图像的分辨率,达到更好的图像识别能力和识别精度。
随着图像数据量的增大,对图像处理速度提出了更高的要求,利用硬件实现图像处理已经逐渐成为图形处理领域研究的重要课题。
FPGA由于强悍的数据处理能力得到广泛关注,其对数据采用并行流水式处理方式,加快了数据处理速度。用一般软件对图像实时处理f/s,FPGA硬件化处理能够实时达到25~30 f/s。因而图像处理的FPGA硬件化值得研究。endprint
FPGA实现图像处理算法需要在算法性能和资源使用量之间寻求平衡。传统的线性插值算法包括最近邻插值、双线性插值、四点双三次插值以及六点双三次插值,其中最近邻插值的超分辨图像效果不理想,高次插值方法复杂度高不便于硬件实现。本文选择图像效果还令人满意,算法可以硬件实现的双线性插值算法。
FPGA具有如下两个对立的性能:
(1) 具有并行处理和流水线技术,能够达到高性能处理,但倍的性能要耗费倍逻辑;
(2) 具有复用技术,能够减少逻辑,但控制复杂度上升。基于FPGA的功能特性,提出基于单输入双输出端口RAM缓冲的二级循环调度机制实现共享资源分配和并行流水处理。同时Xilinx的FPGA基于LUT结构,可以实现浮点运算以及乘法运算,但会造成资源的严重浪费。本文将所有浮点数都整数化,在整数领域进行数据运算。
1 双线性插值硬件化运算分析
双线性插值通过四点确定一个平面,是个过约束问题,所以在一个矩形栅格上的一阶插值需要用到双线性函数。令为两个变量的函数,定义为四点形成的正方形内的任意值,令双线性方程:
(1)
定义一个双曲抛物面与已知点拟合。
图像双线性插值算法的实现经过采样、水平和垂直线性插值三步来完成。设分别为源图像在上的尺寸,分别为目标图像在上的尺寸,定义两者的缩放因子则水平方向、垂直方向的缩放因子分别为:
(2)
(3)
定义源图像水平方向采样的像素点位置集合:
(4)
定义目标图像水平方向采样的像素点位置集合:
(5)
定义两者图像像素点之间的映射关系为,则根据式(2)可得:
(6)
由此可得目标图像水平方向第点位置映射到源图像的像素点位置为:
(7)
得到的是实数,该目标图像水平方向第点像素插值在源图像和之间,同时,和对应于目标图像第点与源图像第点和第点之间相对距离的归一化值。
令:
(8)
令目标图像像素值为,源图像像素值为,则: (9)
同理,在垂直方向的插值为:
(10)
将式(9)代入式(10)得到:
可以发现式(11)和式(1)是类似的。
2 单输入双输出端口RAM缓冲的二级循环调
度机制
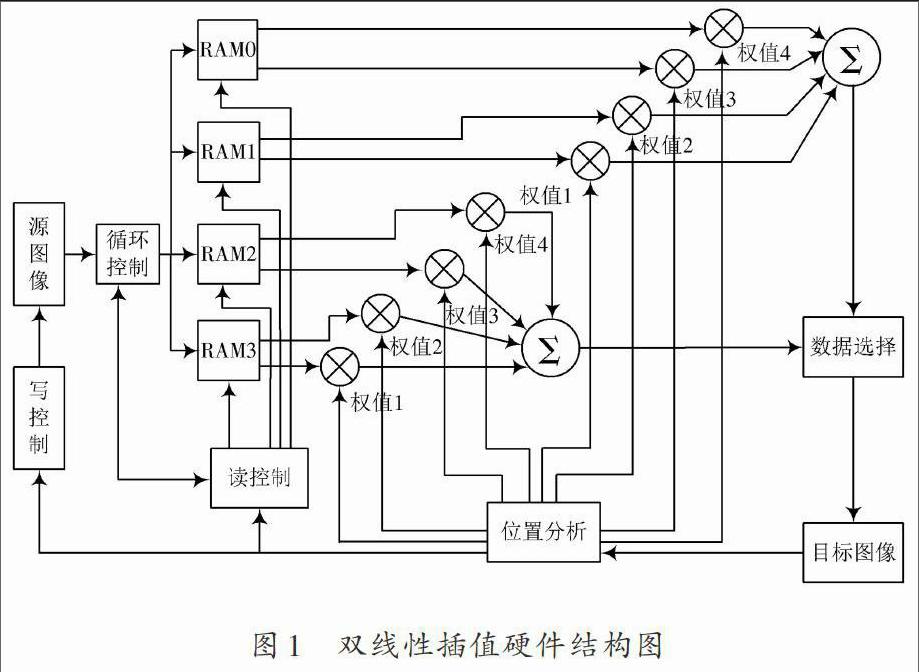
由运算分析可知,目标图像某一点的像素值由源图像相邻两行的相邻两点决定,为此设计了单输入双输出端口RAM,实现读取相邻地址的两个数据。定义该RAM的深度为源图像一行的像素点数,宽度为像素数据宽度,实现源数据相邻两行像素的存储。
根据目标图像存储像素的位置经位置分析模块得到与此像素点相关的源图像的位置以及相应位置点的权值和。寫控制模块根据位置分析模块得到源图像的位置,控制源图像的模块写入相应RAM中。
如图1所示,在双线性插值硬件结构图中定义了4个单输入双输出端口的RAM。其中RAM0,RAM1加权运算对应目标图像的插值像素值时,RAM2,RAM3写入目标图像下一行运算所需的源图像的像素值;RAM0,RAM1运算结束后,RAM2,RAM3进行加权运算,RAM0,RAM1开始写入源图像像素值,在时间上实现数据连续运算输出,空间上实现RAM空间的并行复用,提高运算效率。
循环控制模块控制4个RAM模块的循环调度实现数据写入,如图2所示,循环调度分为两级:分别为RAM0,RAM1和RAM2,RAM3之间以及RAM0和RAM1之间,RAM2和RAM3之间。RAM0,RAM1和RAM2,RAM3之间在运算目标图像像素值和写入源图像像素值功能间循环切换;RAM0和RAM1之间,RAM2和RAM3之间实现源图像像素值循环写入。这样的结构设计充分利用了FPGA并行流水复用的特征,既保证了数据带宽的充分利用,又节省了FPGA的空间资源。
根据运算分析可知,由位置分析模块得到的4个权值是归一化的小数,FPGA虽然能够支持浮点数运算,但需要大量逻辑和布线资源,性能比较差,不利于FPGA的运算,因此将权值映射到整数范围内运算。整个运算过程中,是浮点数,权值基于运算得到,将整数化,即可将运算都整数化。浮点数的整数化是将对应的浮点数左移相应的位数,在乘法运算结束后右移相应的位数。
3 测试分析及结论
本文在Xilinx公司的Kintex?7开发板上进行实验验证,如图3所示是该算法占用的FPGA资源,包括645个触发器、2个RAM以及11个DSP等,资源占用率不高。
如图4所示是双线性插值硬件化实现的建立保持时间图,从图4中可以看出,数据最少只要保持传输即可,意味着时钟频率可以达到190 MHz,插值到1 024×1 024像素的时间是5.5 ms,实际使用过程中不采用理想最高频率,选择低些的频率来避免数据丢失或错乱。一般选择实现25~30 f/s即可。
如图5所示是插值前后的Lena图,源图像的分辨率为512×512,插值后分辨率为1 024×1 024,可以大致看到图5(b)比图5(a)细节方面更加清晰。
图6是插值前后Lena图的直方图比较,从直方图中可以更直观地分析图像的细节连续性问题。比较图6(a)和图6(b)可以看到,插值后的Lena直方图比插值前更平滑,说明图像的连续过渡性更好,实现了直方图的均衡化。
4 结 语
本文基于FPGA的图像超分辨率双线性插值实现方式,提出基于单输入双输出端口RAM缓冲的二级循环调度机制。通过在kintex?7开发板上进行实验验证,实现了图像处理速度达到25~30 f/s,在图像插值后不仅细节更加清晰,而且从直方图中可以看到图像得到了均衡化。
参考文献
[1] XIAO J P, ZOU X C, LIU Z L, et al. Adaptive interpolation algorithm for real?time image resizing [C]// Proceedings of 2006 IEEE International Conference on Innovative Computing, Information and Control. Beijing, China: IEEE, 2006: 221?224.
[2] WANG Jianzhuang, CHEN Youping, XIE Jingming, et al. Model?based lane detection and lane following for intelligent vehicles [C]// Proceedings of 2010 the 2nd International Confe? rence on Intelligent Human?Machine Systems and Cybernetics. Washington, DC: IEEE, 2010: 170? 175.
[3] 肖建平.图像超分辨率算法与硬件实现研究[D].武汉:华中科技大学,2006.
[4] 王建庄.基于FPGA的高速图像处理算法研究及系统实现[D].武汉:华中科技大学,2011.
[5] 马思博.基于Scaling算法的FPGA验证[D].北京:北京交通大学,2013.
[6] 卢德贞,范松涛,王新伟,等.距离选通超分辨率三维成像同步控制的研究[J].计算机仿真,2016,33(2):22?26.endprint
