基于加权聚类的动态协同过滤推荐算法
2017-09-07赵洋刘方爱
赵洋+刘方爱

摘要:针对传统协同过滤推荐算法存在数据稀疏性及动态情景下推荐效率急剧下降的问题,提出了一种基于加权聚类的动态情景协同过滤推荐算法。该方法对提供较多评分的用户给予更多的重视,在运用SK-means聚类方法的基础上引入用户权重的概念,有效的解决了数据稀疏性的问题,在此基础上考虑增量更新的情况以便处理推荐过程中数据的频繁变化带来的影响,优化了对目标用户的偏好预测和个性化推荐建议。实验结果表明,相比于IUCF、IICF、和COCLUST算法,该算法在有效缓解用户评分数据稀疏性的同时,还以非常低的计算成本提供了高质量的推荐建议。
关键词:协同过滤;加权聚类方法;数据稀疏性;动态情景;推荐效率
中图分类号:TP391 文献标识码:A 文章编号:1007-9416(2017)05-0142-03
推荐系统[1]收集用户的历史数据和其他相关信息,利用数据挖掘方法和各种数学模型进行分析计算,准确预测用户的兴趣爱好,主动向用户推荐可能感兴趣的内容。
传统的协同过滤算法在静态情境下可以实现良好的预测精度,但随着用户数目和项目数量的持续增加以及评分的不断更新,协同过滤算法的数据稀疏性问题以及推荐效率急剧下降的问题越来越突出,这直接导致了推荐系统的推荐质量迅速下降。针对这一问题,相关研究引入了不同的算法[3]。例如,X.Yang等人[4]通过计算和分析不同情况下项目间的相似性,使用动态增量更新和本地链路预测的方式,提出一种以可扩展项目为基础的协同过滤算法。该算法提出一种基于项目相似度图的传递结构,使用本地链路预测方法来寻找隐性候选项目,以减轻预测和建议的过程中数据稀疏带来的负面影响,从而提高了传统协同过滤算法的性能和推荐效率。大多数推荐算法都不能处理动态情景,例如基于奇异值分解的协同过滤算法[5]不能处理出现新评分以及更新现有评分的情况。而基于内存的协同过滤算法普遍存在数据稀疏性以及推荐效率低的问题。
我们在SK-means聚类方法[6]的基础上引入权重的概念,并由此推导出了一种动态情景下的协同過滤推荐算法,不仅弱化了算法中数据稀疏性带来的影响,还有效的解决了数据频繁变化带来的一系列问题。
1 基于加权聚类的动态推荐算法
我们提出的基于加权聚类的动态协同过滤推荐算法可以分为三个主要步骤:训练、预测和增量训练。
1.1 训练步骤
首先将用户划分为k个聚类。为了解决这个问题,我们将一种适用于协同过滤推荐系统的SK-means聚类方法引入到WCM-DCF算法中。因此,所得到的集群将受到最有用的用户的高度影响。我们令表示第个用户的权重,SK-means聚类方法的加权目标函数可以表示为:
(1)
更新后用于加权的SK-means聚类方法的质心计算公式如下:
(2)
我们给出用户权重的直观计算公式。令为一个二进制矩阵。第行对应的向量指示已经被第个用户评分的项目。由此我们将第个用户的权重定义为与其可用评分的数量成比例,公式如下:
(3)
其中是所有值均为1的适当维度的向量,表示用户提供的项目评分的标准差。仅从已经评价了许多项目的用户集合中选择初始质心也不是最优解决方案,因为不会检测到所有结构特征。为了避免这个问题,我们通过以下步骤进行聚类初始化:
(1)将用户随机分区生成为k个聚类,由表示,其中表示第i个用户所属的聚类。
(2)令表示第k个质心的第j个分量,估计初始质心公式如下:
(4)
根据公式(4),通过获取相应聚类内第个项目的评分总和来估计初始质心的分量。因此很少被评价的项目将会被自动弱化。2.2的算法更详细的描述了我们的训练步骤。
1.2 算法描述
输入:目标用户,大小为的用户-项目评分矩阵,聚类数量k,批处理迭代次数B
输出:聚类K的质心,分解矩阵
(1)聚类中心初始化:令,随机产生球面聚类质心;
(2)对于每一个对象,分别计算它们的聚类中心表达式
(3)通过竞争学习计算使目标函数最接近用户的球面质心:
;
(4)令,b从1循环到B,i从1循环到n,迭代以上步骤。
1.3 预测步骤
我们根据聚类结果预测未知评分。因为在矩阵中有很多未知评分,所以即使实现最好的聚类结果也难以做出最准确的预测。为了克服这方面的困难,我们采用对已知评分进行加权平均的方式来估计未知评分,方法如下:
(5)
公式(5)的核心思想是根据每个用户与其对应的质心之间的相似性利用权重对用户做出的可用评分进行加权,以便对最接近质心的用户给予更高的权重。
我们提出的预测公式(5)的另一个优点在于它给出的预测信息只取决于聚类结果,这就意味着它可以离线执行并将结果存储在大小为的矩阵中,大大缩短预测时间。
1.4 增量训练步骤
我们考虑增量更新的情况以便处理协同过滤过程中数据的频繁变化。首先区分四种主要情况:(1)提交新评分;(2)更新现有评分;(3)新用户的出现;(4)新项目的出现。下面我们给出每种情况的更新公式。
提交新评分及更新现有评分情况:为项目提交新评分的活跃用户用表示。下面的等式给出了在这种情况下执行动态更新的情况:
·更新的范数:
·对于每个聚类,更新和之间的余弦相似性:
·更新活动用户的权重:
·更新的分配:
·根据公式(3)更新相应的质心,满足条件
,
符号表示提交新的评分后的用户,和分别表示项目之前的评分和的平均评分。由于质心在训练结束时相对稳定,所以随着后续增量的不断更新,重新分配时不需要根据每个新评分加入后重新执行。endprint
出现新用户:在这种情况下只需将新用户实时合并到模型中。令表示新用户,模型的动态增量步骤如下:
·根据公式(3)计算新用户的权重;
·将新用户分配到第个聚类中;
·更新对应的质心:
出现新项目:新项目出现时没有评分,因此模型中没有需要更改的内容。当新项目开始接收新的评分时,只需针对新项目进行处理,减少处理新出现评分的过程。
2 实验设置
在模拟实验中,通过对比不同算法的接受者行为特征(Receiver Operating Characteristic , ROC)曲线、准确率(Precision)和召回率(Recall)来验证该算法的性能。实验数据集选用著名电影评分数据集,该数据及包含6040个用户对3952部电影做出的100万条评分记录。实验对比对象有基于用户的增量协同过滤(incremental user-based CF,IUCF)算法、基于项目的增量协同过滤(incremental item-based CF,IICF)算法、基于协同聚类的增量协同过滤(incremental CF based on co-clustering,COCLUST)算法。
3 实验结果和分析
我们采用以下策略评价推荐系统的质量。(1)我们从数据集中随机生成10个训练-测试(80-20%)集合。(2)在测试集中,推荐系统获取每个用户给出的个评分,其他评分被保留用于预测评价。在推荐过程中,我们在静态情况下设置=10,动态情境下设置=5。(3)在开始比较之前,我们使用ML-1M数据集上的不同参数对每个推荐系统进行多次实验,并保留对应最佳性能的参数。图1给出了WCM-DCF算法在ML-1M数据集上随着聚类数目的增多的变化情况。(4)在10个训练测试集中根据ROC曲线、等指标参数对每个推荐系统进行综合评价。
3.1 静态情景
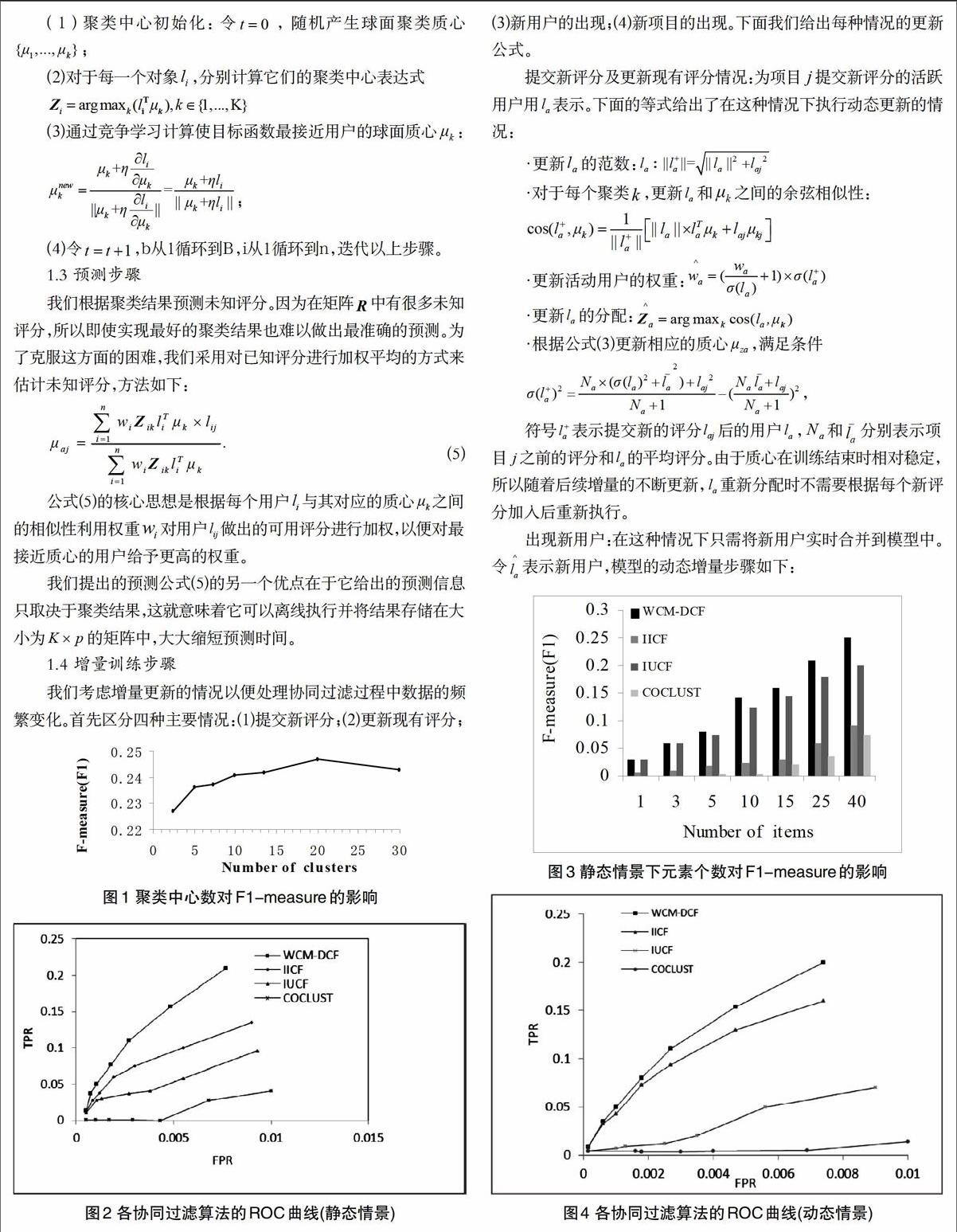
图2和图3给出了在ML-1M数据集上不同协同过滤算法的ROC曲线和参数比较。图2通过改变前N个推荐列表的大小并且用每个协同过滤算法的假正类率(false positive rate, FPR)与真正类率(true positive rate ,TPR)的线性关系来构建ROC曲线。图3中,我们假定最长的列表包含40个元素,每种方法的参数在不同的列表上各有不同。
从图2和图3中我们发现,在ML-1M数据集上,我们给出的WCM-DCF算法得出的计算结果远远优于所有其他增量方法,提供了高质量的推荐建议。我们还发现COCLUST算法给出的推荐结果质量最低。
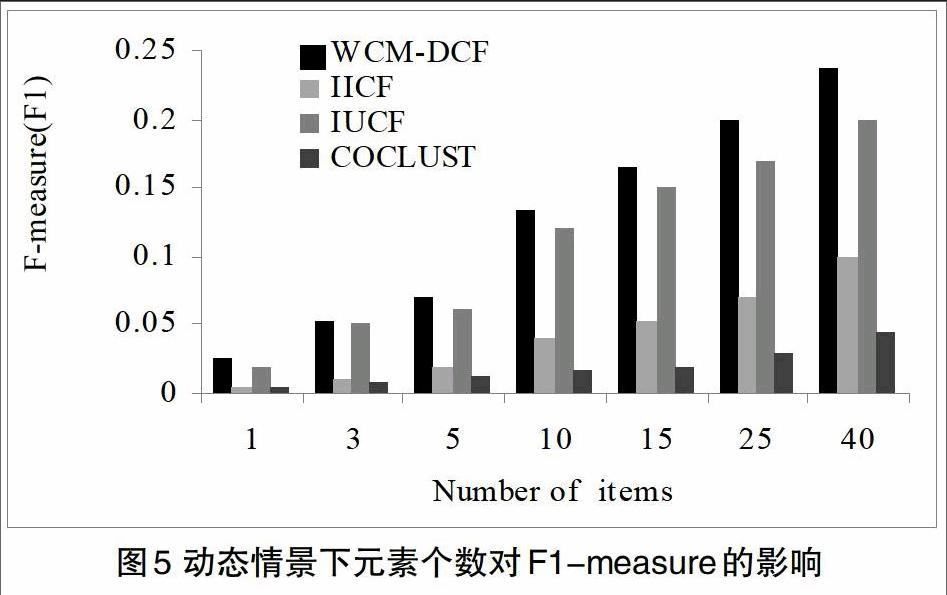
3.2 动态情景
在动态情景下,每种推荐方法的训练步骤之后递增的并入动态情景。从图5及图6中我们观察到,在动态情况下,WCM-DCF算法优于所有其他增量方法。我们还观察到COCLUST在动态情况下继续提供较差的性能,因为它仅使用部分更新来处理推荐过程中数据的变化,因此新信息不能以动态方式并入模型中。
4 结语
针对动态情景下协同过滤算法存在的数据稀疏性问题和数据频繁变化带来的一系列影响,本文提出了一种基于加权聚类的动态情景协同过滤推荐算法。实验对比表明,WCM-DCF算法相比于现有的推荐算法具有更好的有效性,同时需要更少的计算时间。
參考文献
[1]HERLOCKER J L, KONSTAN J A, Terveen L G, et al. Evaluating collaborative filtering recommender systems [J]. ACM Transactions on Information Systems (TOIS), 2004, 22(1): 5-53.
[2]B. Sarwar, G. Karypis, J. Konstan, J. Riedl, et al. Incremental singular value decomposition algorithms for highly scalable recommender systems, In: Fifth International Conference on Computer and Information Science, 2002, pp. 27-28.
[3]X. Yang, Z. Zhang, K. Wang, Scalable collaborative filtering using incremental update and local link prediction, In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management, ACM, 2012, pp. 2371-2374.
[4]B. Sarwar, G. Karypis, J. Konstan, J. Riedl, Incremental singular value decomposition algorithms for highly scalable recommender systems, In: Fifth International Conference on Computer and Information Science, 2002, pp. 27-28.
[5]I.S. Dhillon, D.S. Modha, Concept decompositions for large sparse text data using clustering, Mach. Learn. 42 (1-2) (2001) 143-175.
[6]Hornik K, Feinerer I, Kober M, et al. Spherical k-Means Clustering[J]. Journal of Statistical Software, 2016, 50(10):1-22.endprint
