基于Hadoop的非结构化数据管理在石油行业中的研究与实现
2017-09-07张学伟
张学伟
摘要:随着互联网及大数据时代的到来,新数据的产生以指数级的速度增长,而这大量的数据中,又以格式不确定的非结构化数据为主。主流的关系型数据库技术很难驾驭非结构化数据,本文提出基于Hadoop分布式框架的非结构化数据管理体系。采用HBase数据库技术处理多格式的大量小文件,利用Lucene检索引擎设计全文检索策略,并在此基础上搭建分层体系架构。
关键词:Hadoop;非结构化数据;Lucene
中图分类号:TP311 文献标识码:A 文章编号:1007-9416(2017)05-0054-01
1 引言
在油田开发过程中,积累了大量的信息数据,包括办公文档、地震数据、方案文档及各种图件等非结构化的数据。将这些数据进行妥善的存储和管理,进一步挖掘数据价值对油田的可持续发展有着重要意义。
2 Hadoop环境下的文档存储技术
2.1 数据库技术对比分析
以Oracle为代表的传统关系型数据库能够对结构化数据进行很好的管理,也可以通过二进制大对象(BLOB)作为容器来存储非结构化数据。Oracle在管理与检索非结构化数据时,需要额外的处理能力和内存才能获得与文件系统存储非结构化数据同样的性能。
由于对硬件性能的高要求,就使得许多针对非结构化数据的存储方案诞生,其中以開源的Hadoop分布式计算框架为代表。
Hadoop采用流式数据访问模式,并使用主/从架构模式,通过多数据副本保存和分布式处理,保证了Hadoop能够以可靠、高效、可伸缩的方式存储处理数据。
Hadoop是为存储大文件设计的,在处理大量小文件时,每个小文件都以对象的形式存储在元数据节点内存中,大量小文件会占用大量内存,这样元数据节点的内存容量会严重制约集群的扩展;Hadoop以流式访问大量小文件时,需要频繁请求数据节点以获取文件,严重影响元数据节点和数据节点的IO性能。
HBase是Hadoop中带有的分布式的、面向列的开源数据库。使用HBase存储非结构化数据,具有系统层小文件打包、全局命名空间等多种优势。
2.2 Oracle和HBase效率比较
仿照Oracle文档存储结构,设计HBase表行键结构,其中以文档代码为行键,录入时间为时间戳,列簇包括项目名称、文档名称、最后更改时间、文档内容、用户名称等,列簇字段可后期根据需要添加,保证了表格的扩展性。
使用Java语言接口分别连接Hbase数据库及Oracle数据库,在相同实验环境下,对文档上传下载效率进行测试。上传20个共130M的文档文件, Oracle耗时330秒,HBase耗时19秒;下载同样大小文档,Oracle耗时42秒,HBase耗时14秒。通过对比得知,使用HBase存储非结构化数据,文件吞吐效率明显高于传统数据库。
3 全文检索引擎Lucene
Lucene是一套开源的全文搜索框架。非结构化数据入库前需要先对文档进行分词处理,之后Lucene通过全文扫描,将解析出来的信息写入索引库,主要包括:文件名称、全文本内容、文档时间、文档大小、文档页数等。当用户查询时,Lucene根据建立的索引内容进行查找,并将索引库的匹配内容返回,类似于字典查字的使用过程。
4 体系架构搭建
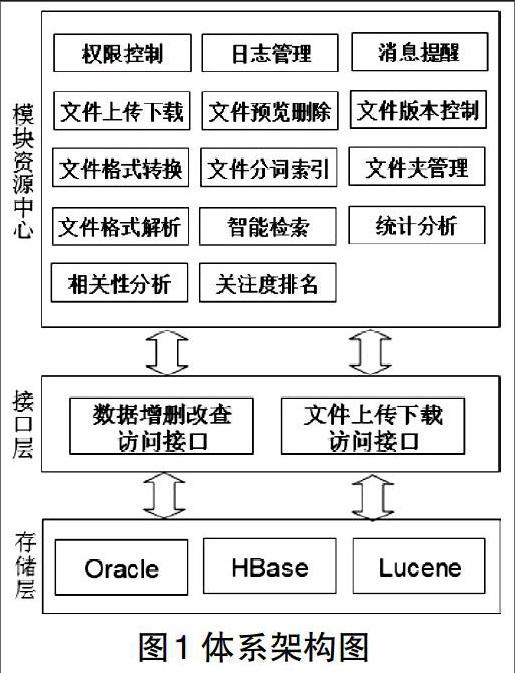
以HBase存储为基础,结合Lucene全文检索引擎设计基于Hadoop的非结构化数据管理系统。同时为保证与企业现有的管理系统集成,采用三层架构,通过访问接口和功能模块均能访问底层数据。架构图如下图1所示。
存储层使用Oracle存储结构化数据,Hbase存储非结构化数据,Lucene存储非结构化数据索引。HBase的行操作遵从事务处理模式,确保库中数据的完整性。同时提供双机热备解决方案,当服务器宕机时,其服务和数据可以迅速、完整、无缝的使用备份服务器运行。
接口层定义了标准数据处理接口,方便各模块调用,并能为不同系统提供文件数据处理、目录管理、组合查询、访问控制、站内消息等可复用功能。
按照统一开发标准,设计可扩展、可复用的模块资源中心,提供包括文件上传、下载、预览、删除等14个功能模块,并且各模块间松耦合,方便不用系统服务间调用。
5 结语
随着油田信息化工作的不断深入,企业对不同专业的综合应用要求也在不断提高。本文在对比分析传统数据库与Hadoop分布式存储系统的优劣后,提出基于HBase和Lucene的完整数据管理体系,实现文件储存管理、全库智能检索等核心功能。endprint
