基于DSP的语音识别系统的研究与实现
2017-09-07钟颖
钟颖

摘要:本文介绍了基于DSP TMS320VC5509A的语音识别系统,主要通过采用DTW算法,初步研究和探讨在MATLAB软件环境下实现孤立词语的语音识别。系统由 TMS320VC5509A 芯片控制和TLV320AD50对原始语音进行采样和A/D转换,内部存储器用来存放程序数据,外部存储器用来存放各种语音数据。
關键词:语音识别;DSP;Mel频率倒谱系数(MFCC);动态时间规整(DTW)
中图分类号:TN912.34 文献标识码:A 文章编号:1007-9416(2017)05-0048-02
1 概述
伴随科技进步,语音识别系统在越来越多的领域得到了广泛的应用。本文主要是研究基于DSP的特定人、小词汇量语音识别系统,提出更为优化和快速计算的算法,采用DSP芯片TMS320VC5509A 控制和TLV320AD50对原始语音进行采样和A/D转换,目的是研究出能识别人话的机器,通过接受人话口呼命令,掌握人发出的指令,从而做出指令要求的反映。
2 语音识别的实现流程
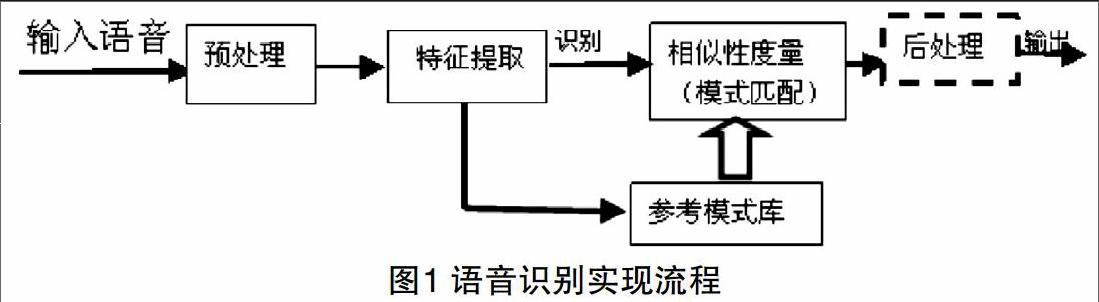
语音识别主要包括五个步骤。首先人口命令的模拟的语音信号输入,通过A/D转换后变成数字信号,但这时信号很难被直接识别,需要对信号进行特征提取,端点检测在分析处理之前把要分析的部分从语音信号中找出来,提取了指定的语音信号特征参数后进行模式匹配,最后进行后处理,也就是对匹配节后的响应。一个典型语音识别系统[1]的实现过程如图1所示。
3 系统的硬件设计
本语音识别系统以TI公司TMS320VC5509A DSP为核心用来处理各种数据和程序,对原始语音进行采样和A/D转换,程序寄存在内部存储器,语音数据寄存在外部存储器。这种基于DSP的语音识别系统比传统的语音实时性强,功能好,而重要的是可以移植到手机手持设备中,这也是本系统设计开始就选用DSP开发板的原因。
4 系统的软件实现
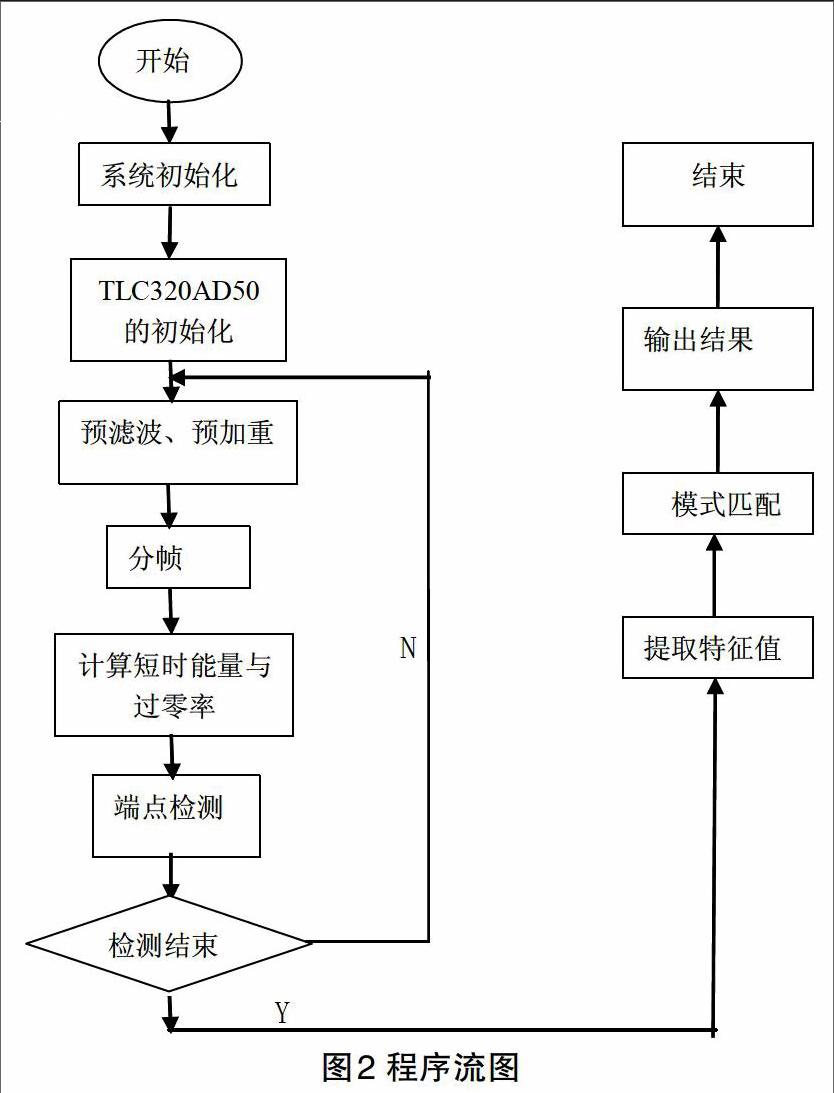
程序设计流图如图2所示。
4.1 端点检测
本语音系统采用双门限法来检测端点,清音过零率检测,浊音用短时能量。首先分别确定一个较低的、数值小的门限,和另一个较高的、数值大的门限。静音段,如果连续几个帧的过零率超过低门限,表示信号进入过渡区,信号开始。当两个参数值低于低门限以下,则表示信号进入静音区,信号结束。当两个参数值高于高门限,则进入到语音段。当降低到门限以下,则认为是噪音,继续扫描,标记好结束端点。
(1)短时平均能量和幅度。分别比较矩形窗和hamming窗长的短时能量函数,得出如下结论:不同的窗函数以及相应窗的长短均有影响。矩形窗的效果比hamming窗要差一些。如图3图4所示。
(2)短时平均过零率。实验中用某一语音在矩形窗条件下求得的短时能量和短时平均过零率。由此看出:清音的短时能量较低,过零率高,浊音的短时能量较高,过零率低。如图5所示。
4.2 特征提取
本系统选择MFCC(Mel倒谱参)作为基本识别参数。Mel刻度根据主观音高均匀划分,与线性频率关系[2]为:
(4-1)
在实际语音信号处理中,MFCC的计算过程较复杂,具体的计算过程:
(1)首先确定一帧语音信号的样点数N,本系统N=212点。
(2)计算S(n)通过每一个三角形滤波器的输出,得到M个参数h(m)。
m=1,2......M (4-2)
(3)对所有滤波器输出进行对数运算,再进一步进行离散余弦变换(DCT)。i=1……16。
(4-3)
5 结语
系统最终在编程上实现了个别个体的特定语音的识别,基本上达到了预定的目标,识别所用各种算法经过验证并且得到预想的结果。整个语音系统在硬件平台DSP上实现,由此可以根据各个硬件的特点和社会的需要,设计出多种多样的语音识别设备。
参考文献
[1]蔡莲红,黄德智,蔡锐编著.现代语音技术基础与应用[M].北京:清华大学出版社,2003.
[2]林坤辉,息晓静,周昌乐.基于HMM与神经网络的声学模型研究[M].厦门:厦门大学学报(自然科学版),2006.
[3]陈立万.基于语音识别系统中DTW算法改进技术研究[D].微计算机信息,2006.
[4]安镇宙,杨鉴,王红,余映.一种新的基于并行分段剪裁的DTW算法[C].计算机工程与应用,2007.endprint
