一种基于特征库投影的文本分类算法
2017-09-07尹绍锋郑蕙徐少华荣辉桂张娜
尹绍锋,郑蕙,徐少华,荣辉桂,张娜
一种基于特征库投影的文本分类算法
尹绍锋1,郑蕙2,徐少华1,荣辉桂3,张娜3
(1. 湖南大学校园信息化建设与管理办公室,湖南长沙,410082;2. 湖南商学院旅游管理学院,湖南长沙,410205;3. 湖南大学信息工程与科学学院,湖南长沙,410082)
基于KNN的主流文本分类策略适合样本容量较大的自动分类,但存在时间复杂度偏高、特征降维和样本剪裁易出现信息丢失等问题,本文提出一种基于特征库投影(FLP)的分类算法。该算法首先将所有训练样本的特征按照一定的权重策略构筑特征库,通过特征库保留所有样本特征信息;然后,通过投影函数,根据待分类样本的特征集合将每个分类的特征库映射为投影样本,通过计算新样本与各分类投影样本的相似度来完成分类。采用复旦大学国际数据库中心自然语言处理小组整理的语料库对所提出的分类算法进行验证,分小量训练文本和大量训练文本2个场景进行测试,并与基于聚类的KNN算法进行对比。实验结果表明:FLP分类算法不会丢失分类特征,分类精确度较高;分类效率与样本规模的增长不直接关联,时间复杂度低。
文本分类;KNN算法;特征库投影
随着文本信息处理技术的快速发展,文本分类算法日益成熟,成为当前数据挖掘预处理过程中的重要方法。目前关于文本分类算法的研究很多, 主要可 分为3类:1) 基于统计的方法, 如朴素贝叶斯[1]、KNN[2]、支持向量机[3]、最大熵等方法;2) 基于规则的方法,如决策树(DT)[4];3) 基于连接的方法,如神经网络等[5]。其中,KNN算法是由COVER和HART于1976年提出[2],YANG等[6]以准确率、召回率、F-Score等作为评测指标,通过假设检验方法验证KNN和SVM在综合性能上高于其他的文本分类方法。同时,KNN同时能解决文本分布出现多峰值的情况,因此,KNN分类性能较稳定[6]。KNN作为一种惰性学习方法,只有在分类时才临时建立分类器,需要与所有训练样本逐个计算相似度,计算量非常大。而且因为训练样本密度不均匀也会直接影响分类效果。针对这些问题,近年来出现了不少改进算法,如VSM优化进行特征降维。这类优化基于2个途径进行,包括特征选择与特征抽取。特征选择基于特征选择函数,比较常见的有互信息(MI)[7]、文档频率(DF)、信息增益(IG)[8]等。钟将等[9]使用潜在语义分析方法对文本特征空间进行降维处理。此外,对训练样本进行优化剪裁。导致KNN算法分类效率较低的主要原因是其具有惰性学习的特点,训练样本数量越大,时间消耗越大。压缩近邻法[10]对样本中心部位样本进行剪裁,仅保留边界来进行分类决策。WILSON等[11−12]则通过边界剪裁训练集,在减少训练样本数量的同时使边界清晰。张永等[13]通过投影的方法缩减训练集的规模,同时在寻找近邻过程中对文本进行降维处理,从两方面降低算法的计算时间。KNN的另外一种优化是训练样本聚合,使用更具代表性的样本来缩小样本空间。张孝飞等[14]通过簇代表进行分类。吴春颖等[15]则结合相关反馈思想进行排类,在不降低分类精度的基础上提高分类速度。为改善搜索算法,提升样本计算过程效率,王渊等[16]通过粗糙集算法将样本空间分为核心与混合2个区域,采用差异化分类策略提高分类效率和精度。郭躬德等[17]提出基于KNN 模型的增量学习算法,而黄杰等[18]则进一步为KNN模型增量学习算法提出了模型簇修剪算法。钱强等[19]采用逐步逼近的方法,通过建立所有训练样本之间的距离排序,从而在分类过程中参考已有的距离信息,减少搜索空间。ZHANG等[20]提出超球体的思想也有效地提升了算法效率。然后,代六玲等[21−22]指出KNN的分类准确率与样本规模呈正相关性,因此,在保证KNN分类准确率的前提下,不能单纯通过剪裁样本这种损失信息的方法进行改进。为此,本文作者采用聚类的思路,将大量的训练样本通过聚合构建出分类特征库,在分类过程中针对待分类的样本通过投影函数从分类特征库提取特征项构造投影样本,在不损失样本信息的前提下,大幅度降低计算复杂度,提高分类效率。
1 基于特征库投影算法
万韩永等[23]认为不同的样本对分类的贡献是不同的。本文进一步认为不同的特征项对分类的贡献不同。单个的文本的特征总会具有局限性,而且难免出现人为的标注错误,这些都会干扰分类效果。针对这种问题,本文认为可以将不同类别训练文本聚合成一个特征库,在聚合过程中,对分类具有较大共享的特征被增强,而干扰项被削弱。

1—d1;2—d2;3—d3;4—d4;5—C。
本文为每个分类构造1个特征库(FL, feature library)。对文本进行分类时,从各FL提取与文本一致的特征项,构成1个分类投影文本,设与的相似度为:
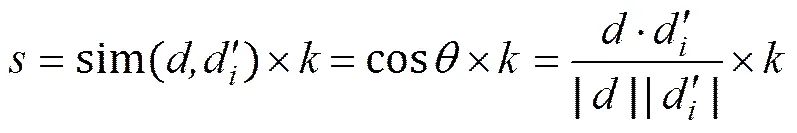
基于特征库的分类函数为
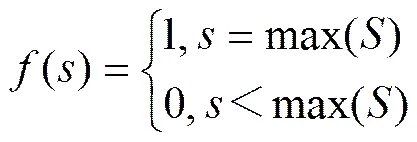
分类函数()是一个关于文本间相似度的函数,为待分类的文本与各分类的投影文本之间的相似度集合。当与之间的相似度最大时,取值为1,否则为0。
1.1 特征库投影分类算法实现流程
基于特征库的文本分类算法实现流程包括4个主要步骤:1) 根据训练文本集构建分类特征库;2) 建立待分类文本的向量空间模型(),根据()为各建立每个分类针对()的投影文件;3) 计算()与各分类投影文件向量的相似度;4) 根据相似度确定分类结果。特征库投影分类过程见图1。
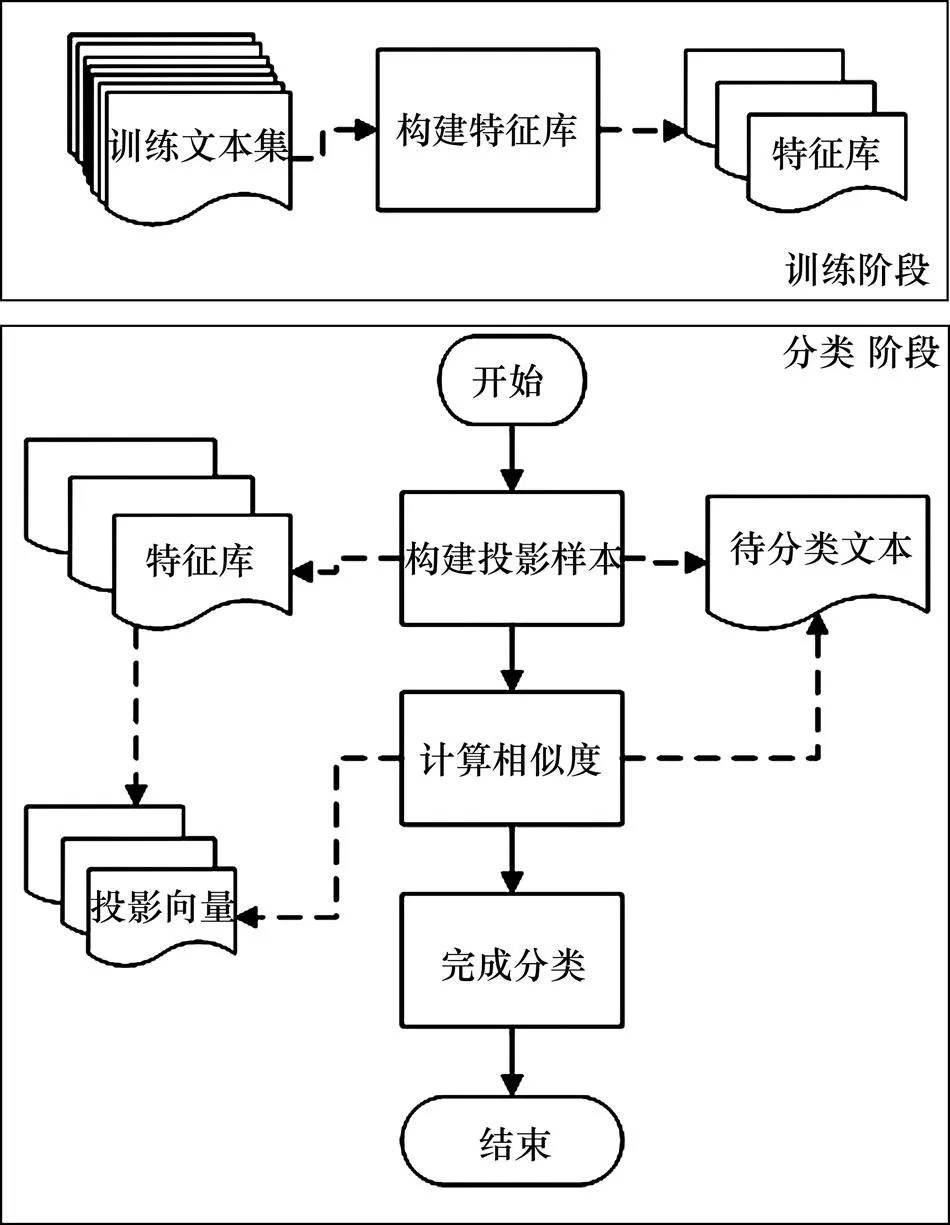
图2 特征库投影分类过程
1.2 特征库
特征库是属于同一个分类的一组特征项的集合,记为,1个特征项包含1个特征词以及该特征词出现的次数。可表示如下:
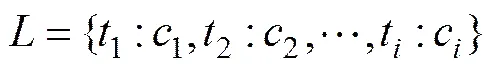
其中:t为集合中第个有效的特征词;c为第个有效特征词在特征库中的权重。中特征词为该分类中各文本特征词集合的并集:
其中:()为中特征词集合;为特征词个数;(d)为该分类中已知的第个文本的特征词集合;为该分类训练文本的数量。
c为特征词在各文档中出现词频的和,可表示为
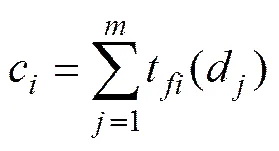
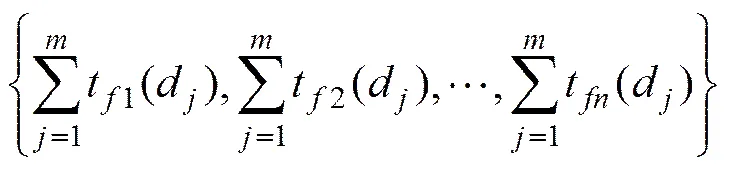
1.3 分类投影文件
分类投影(projection)是针对1个待分类文本特征项的权重映射所形成的1个特征项集合。假设待分类的文本为,投影文件为,为从关于的投影转换函数,则表示为
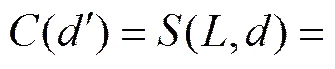
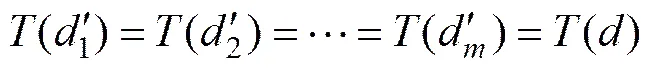
(3)
1.4 特征词权重计算
1.4.1 待分类文件特征词权重计算
待分类文件中特征词的权重为特征词的词频。对于待分类文本,通过向量空间模型表示为
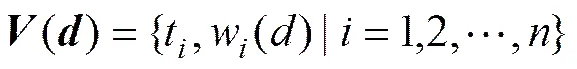
其中:()为文本的向量;t为一组不重复的特征词;w()为特征词t的权重,这里为t的词频,即
(4)
1.4.2 投影文件特征词权重计算
投影文件中特征词的权重使用词频−集中率算法(term frequency−concentration ratio, TF−CR)计算。针对1个待分类的文件,可以通过投影函数获取一组投影文件:
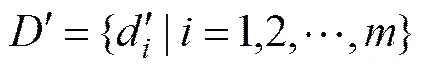
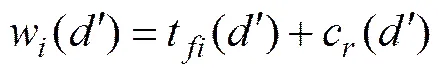
(6)
为投影文件的数量;m为包含特征词t的投影文件的数量。因为投影文本与分类一一对应,因此,m也可以是包含特征词t的分类数量。当m越小,且时,越向靠近。
2 实验过程及结果分析
2.1 测试文本集和实验环境
实验语料库采用复旦大学国际数据库中心自然语言处理小组整理的训练文本集以及测试文本集,共有17个分类,其中训练文本7 981个,测试文本7 958个。语料集又进一步分为小样本和大样本训练语料集。其中,小样本语料库选择训练样本数量小于100的分类,共计11个分类,如表1所示。
大样本语料库选择训练样本数量大于1 000的分类,共计6个分类,如表2所示。
实验环境采用如下设置:开发语言采用java1.6,Eclipse集成开发环境;操作系统为win10 professional 64bit;硬件为1.93 GHz,AMD A8-4500M CPU, 4 GB RAM。
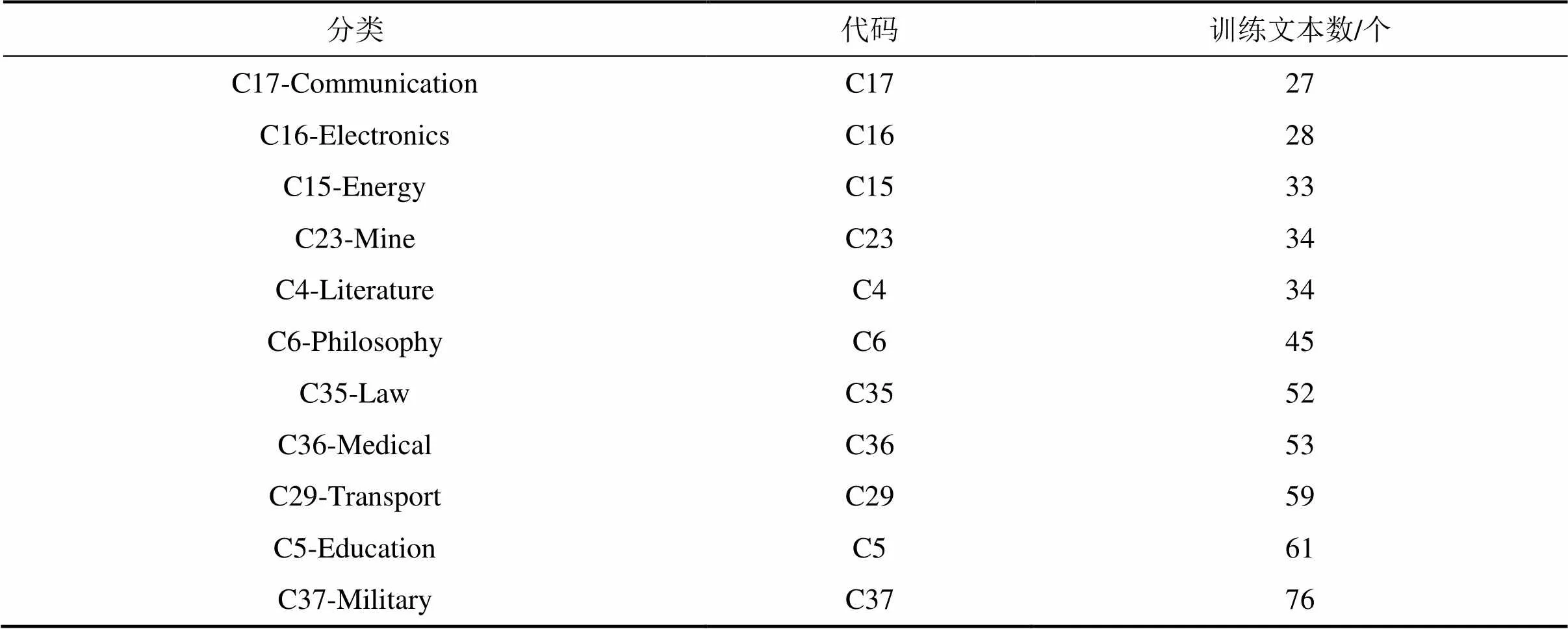
表1 小样本语料库
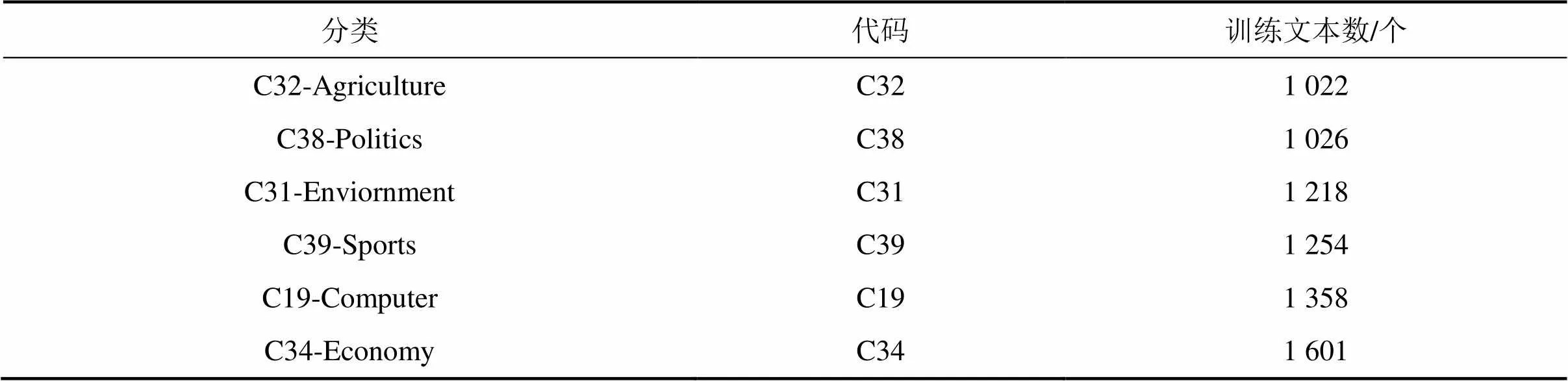
表2 大样本语料库
2.2 实验步骤及结果
本次实验主要通过对比FLP算法与基于聚类的KNN算法的分类效果来验证FLP的有效性。采用KNN算法时,经测定取值为9。
对抽取的测试文档进行分词、去停用词处理,建立测试文档的向量空间模型,并使用式(4)确定每个测试文本中每个特征的权重。
根据测试文本的空间向量,通过式(3)为每个分类建立投影文件,然后根据式(1)计算测试文本与投影文件之间的相似度,最后根据式(2)确定测试文本所属的分类。为了较全面地验证算法的有效性,实验先抽取训练样本数据量少于100个文本的分类,共11个,其中最少的样本数量为27个,最多的为76个;然后抽取训练样本数量大于1 000个文本的分类,共6个,其中最少样本数量为1 022个,最多1 601个。通过不同规模的训练样本环境验证算法的分类效果和分类效率。
2.2.1 小样本测试结果
小样本测试中,各分类的训练样本数量最小为27个,最大为76个;在基于该样本的分类测试中,分析得到FLP算法与KNN算法结果。
表3所示为FLP算法针对小样本语料库的分类结果。其中表3中的行表示样本的实际所属分类,列表示样本被识别的分类。
表3中,当行列的分类一致时,说明该样本被正确识别,否则分类失败。如C15分类共33个测试样本,其中有26个被正确识别,记为;有7个分类失败,记为;4个被分为C23类,C29类、C36和C37分别1个;同时,有5个其他分类的样本被划分为C15分类,记为,其中,C35类2个,C16,C36及C37分别1个。
通过召回率和精准率来评价分类效果。
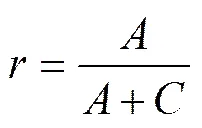
召回率表示属于某个分类的所有样本被正确识别的个数,精准率表示所有被识别为某一分类的样本中正确样本的数量。经计算,C15的召回率为 0.787 878 79,精准率为0.838 709 677。
随后,将KNN算法应用于小样本集中进行测试,得到其分类结果如表4所示。
从表4可知:FLP与KNN都较好地完成了分类,从分类结果的整体看,FLP略优于KNN,但FLP的计算复杂度比KNN的低,分类效率明显提高。
2.2.2 大样本测试结果
大样本测试中,各分类的训练样本数量均在1 000个以上,最大为1 600个。FLP算法与KNN实验结果分别如表5和表6所示。
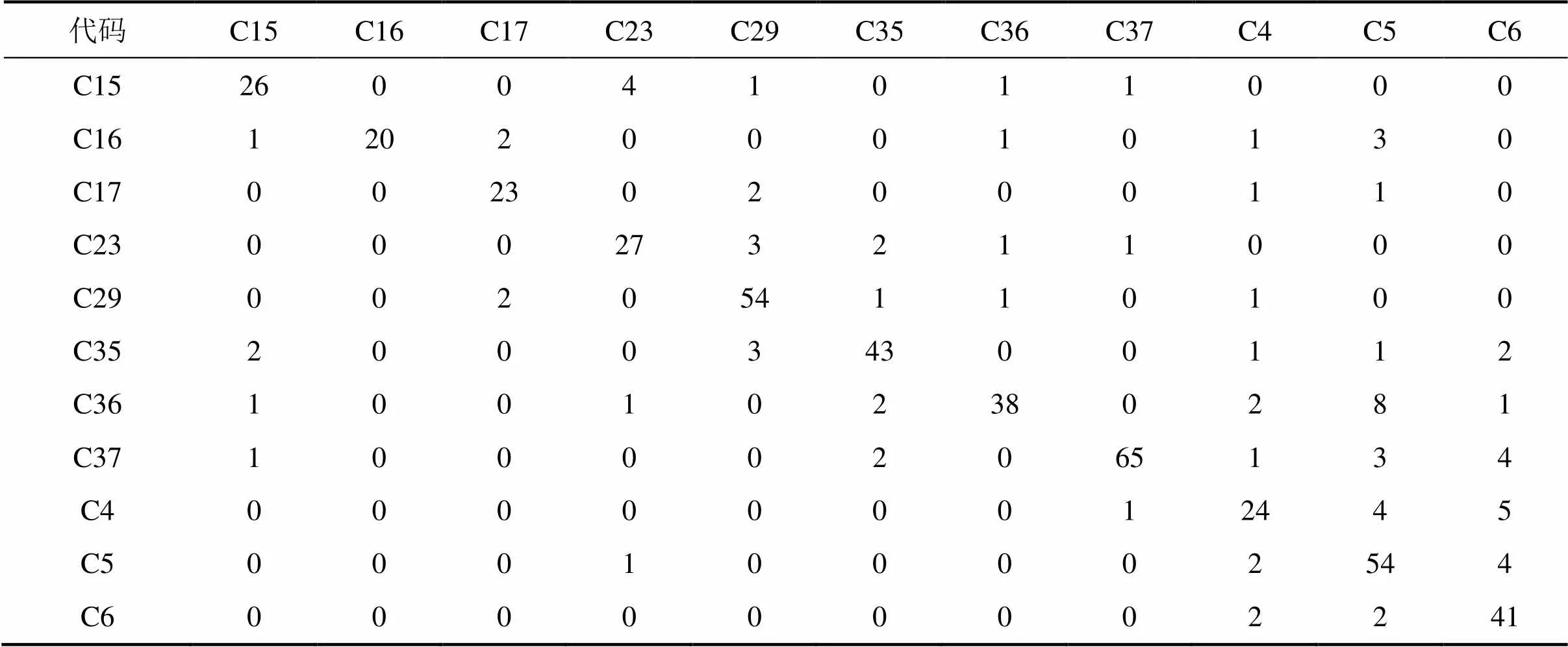
表3 FLP分类测试结果(小样本)
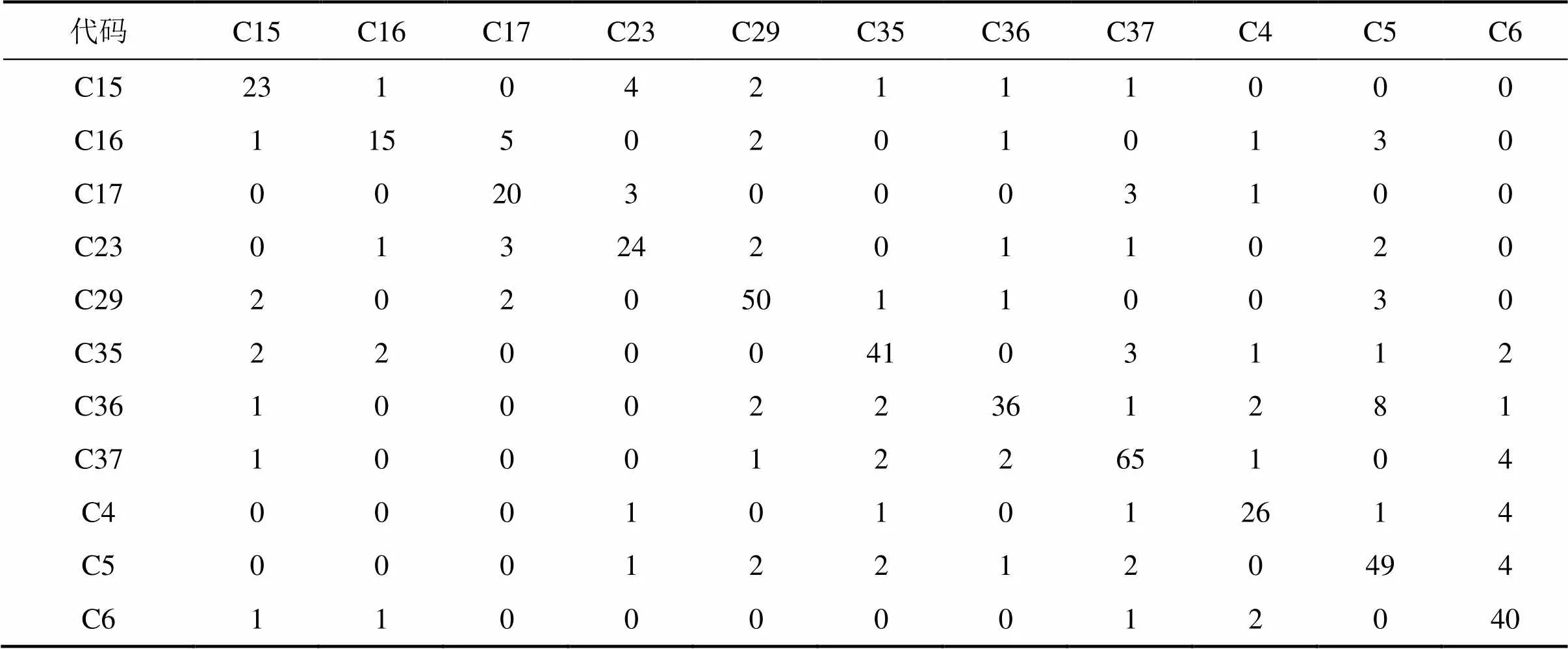
表4 KNN分类测试结果(小样本)
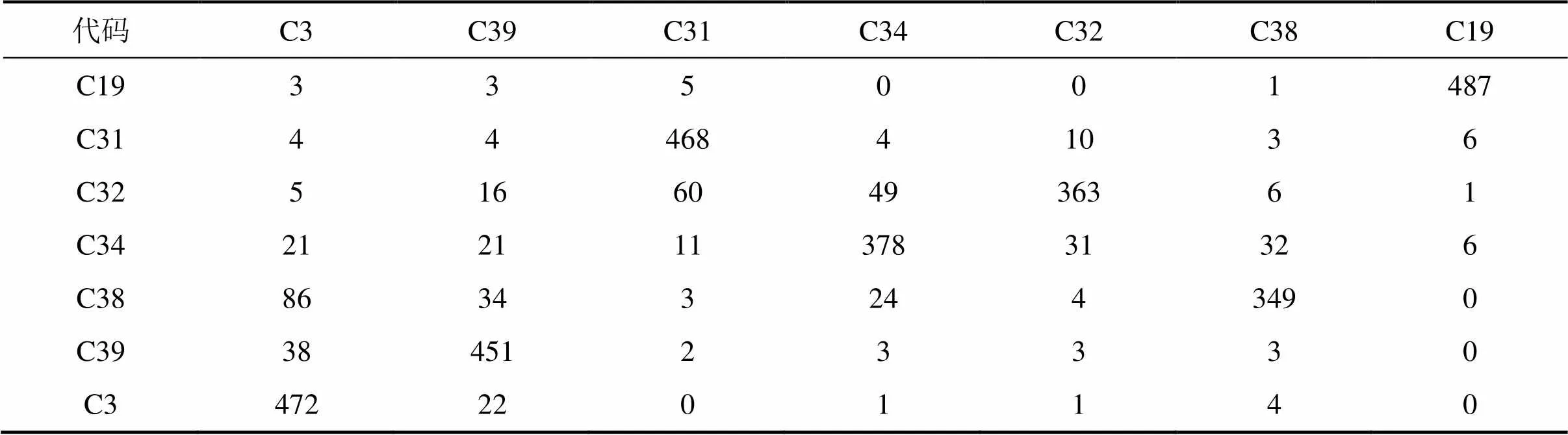
表5 FLP分类测试结果(大样本)
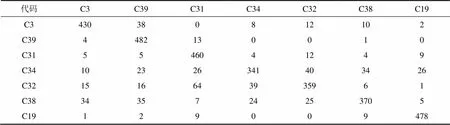
表6 KNN分类测试结果(大样本)
从表5和表6可以看出:FLP与KNN都完成了分类,从整体分类结果看,FLP略优于KNN。对比小样本测试,FLP的计算时间基本与待检测样本的数量呈线性增长,但KNN的计算时间与训练样本数和待分类样本数均有相关性,分类计算时间呈指数增大。
2.3 结果分析
2.3.1 分类效果对比分析
对上述实验结果,分别从召回率、精准率以及-测量值这3个维度进行对比评估。在分类过程中,增加召回率,则可能导致精准率降低,反之亦然。因此,用综合评估分类效果:
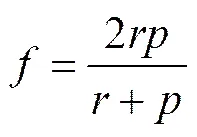
针对,和这3个指标,FLP算法与KNN算法的分类结果见表7。
从表7可以看出:FLP算法平均值为0.810 000 0,平均值为0.840 000 0,平均值为0.820 000 0,均高于KNN相对应评估指标,尤其时间消耗明显减少。其对应指标的分类结果如图3所示。

表7 FLP和KNN小样本分类结果对比
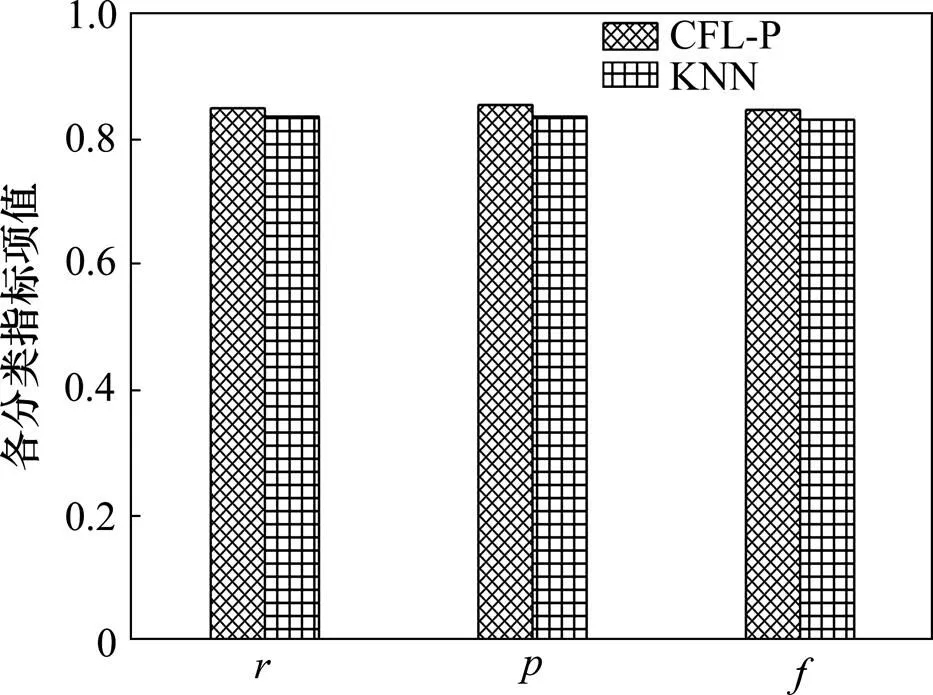
图3 FLP和KNN分类指标项对比(小样本)
从图3可以看出:FLP算法在小样本训练的结果中,整体效果优于KNN。
表8所示为FLP算法与KNN算法所得召回率、准确率以及的对比。从表8可以看出:FLP算法各项评估指标在0.840 000 0左右,比小样本测试略有提升,KNN所得结果与小样本测试结果相比也有明显提升,说明样本数量的增加对分类效果有利。而FLP算法时间消耗远比KNN算法的少。

表8 FLP和KNN大样本分类结果对比
从图4可以直观看出FLP算法在大样本训练的结果中,其分类效果依然优于KNN。
同时对比FLP在2个不同分类场景的结果,当训练样本增加时,FLP的分类召回率、准确率均有提高,说明训练样本的数量对分类结果有直接影响。
2.3.2 分类效率对比分析
FLP算法相对于KNN算法最大的优势是时间复杂度的降低。FLP的时间复杂度是关于分类数量的函数,而KNN是关于训练样本数量的函数,在正常情况下,FLP分类效率比KNN的高。表9所示为500个测试样本在不同训练样本规模时2种算法的耗时。
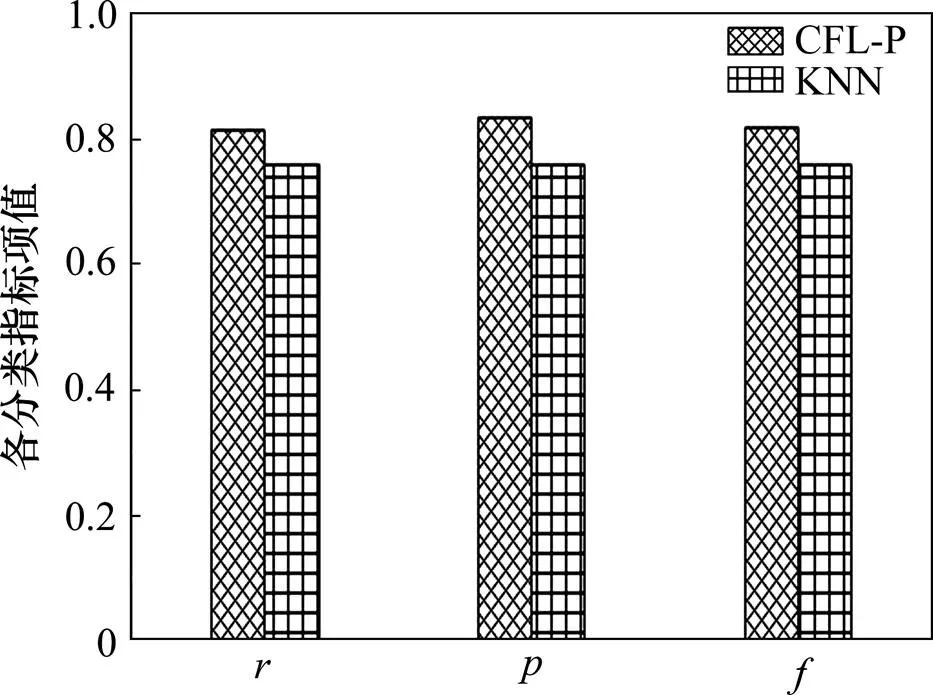
图4 FLP和KNN分类指标项对比(大样本)

表9 FLP与KNN分类效率对比
由表9可以看出:FLP比KNN算法在分类效率上有明显提升;随着训练样本增加,KNN用时呈线性增加,而FLP用时增加缓慢。
FLP算法在训练样本超过一定范围后,分类用时增加率减缓。出现这种现象的原因可能是特征库文件的规模不再随训练样本的增加而增加,因此,构建投影文件的耗时趋于稳定,如图5所示。
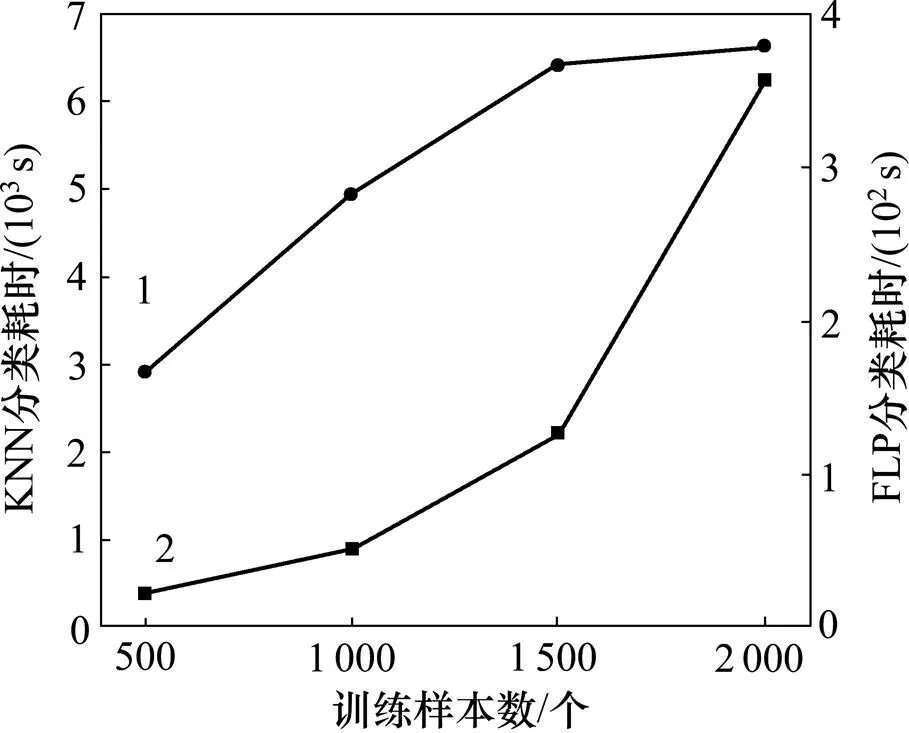
1—FLP分类耗时;2—KNN分类耗时。
3 结论
1) FLP算法在优化过程中,一方面没有丢失特征,同时在聚合过程中有效抑制了噪声,而且KNN的分类效率也提高5%左右,提出的算法较KNN算法的分类精度高。
2) FLP算法分类耗时与训练样本规模的增长没有直接关联,增加训练样本数、提升分类精度对分类效率影响较小;而KNN算法则受样本规模约束较大,随样本规模增大,分类耗时迅速增大。可见FLP算法相比KNN算法的另一个优势是分类效率大幅度提高。
对于特征库的构建、投影实例的生成以及投影实例与待分类样本之间相似度的计算还有待进一步 优化。
[1] LEWIS D D. Naive (Bayes) at forty: the independence assumption in information retrieval[C]// European Conference on Machine Leaning. Heidelberg, Berlin: Springer, 1998: 4−15.
[2] COVER T M, HART P E. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1): 21−27.
[3] CHANG C C, LIN C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1−27.
[4] TSANG S, KAO B, YIP K Y, et al. Decision trees for uncertain data[J]. IEEE Transactions on Knowledge and Data Engineering, 2011, 23(1): 64−78.
[5] GHIASSI M, OLSCHIMKE M, MOON B, et al. Automated text classification using a dynamic artificial neural network model[J]. Expert Systems with Applications, 2012, 39(12): 10967−10976.
[6] YANG Yiming, LIU Xia. A re-examination of text categorization methods[C]// Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM, 1999: 42−49.
[7] 范雪莉, 冯海泓, 原猛. 基于互信息的主成分分析特征选择算法[J]. 控制与决策, 2013, 28(6): 915−919. FAN Xueli, FENG Haihong, YUAN Meng. PCA based on mutual information for feature selection[J]. Control and Decision, 2013, 28(6): 915−919.
[8] 石慧, 贾代平, 苗培. 基于词频信息的改进信息增益文本特征选择算法[J]. 计算机应用, 2014, 34(11): 3279−3282. SHI Hui, JIA Daiping, MIAO Pei. Improved information gain text feature selection algorithm based on word frequency information[J]. Journal of Computer Applications, 2014, 34(11): 3279−3282.
[9] 钟将, 刘荣辉. 一种改进的KNN文本分类[J]. 计算机工程与应用, 2012, 48(2): 142−144. ZHONG Jiang, LIU Ronghui. Improved KNN text categorization[J]. Computer Engineering and Applications, 2012, 48(2): 142−144.
[10] ANGIULLI F. Fast condensed nearest neighbor rule[C]// Proceedings of the 22nd International Conference on Machine Learning. New York: ACM, 2005: 25−32.
[11] WILSON D L. Asymptotic properties of nearest neighbor rules using edited data[J]. IEEE Transactions on Systems, Man and Cybernetics, 1972, 2(3): 408−421.
[12] DEVIJVER P A, KITTLER J. Pattern recognition:a statistical approach[M]. London: Prentice-Hall, 1982: 1−50.
[13] 张永, 孟晓飞. 基于投影寻踪的KNN文本分类算法的加速策略[J]. 科学技术与工程, 2014, 36(14): 92−96. ZHANG Yong, MENG Xiaofei. Accelerated k-nearest neighbors text classification algorithm based on projection pursuit[J]. Science Technology and Engineering, 2014, 36(14): 92−96.
[14] 张孝飞, 黄河燕. 一种采用聚类技术改进的 KNN 文本分类方法[J]. 模式识别与人工智能, 2009, 22(6): 936−940. ZHANG Xiaofei, HUANG Heyan. An improved KNN text categorization algorithm by adopting cluster technology[J]. Pattern Recognition and Artificial Intelligence, 2009, 22(6): 936−940.
[15] 吴春颖, 王士同. 一种改进的KNN Web文本分类方法[J]. 计算机应用研究, 2008, 25(11): 3275−3277. WU Chunyin, WANG Shitong. Improved KNN web text classification method[J]. Application Research of Computers, 2008, 25(11): 3275−3277.
[16] 王渊, 刘业政, 姜元春. 基于粗糙KNN算法的文本分类方法[J]. 合肥工业大学学报(自然科学版), 2014, 37(12): 1513−1517. WANG Yuan, LIU Yezheng, JIANG Yuanchun. Method of text classification based on rough k-nearest neighbor algorithm[J]. Journal of Hefei University of Technology (Natural Science), 2014, 37(12): 1513−1517.
[17] 郭躬德, 黄杰, 陈黎飞. 基于KNN 模型的增量学习算法[J].模式识别与人工智能, 2010, 23(5): 701−707. GUO Gongde, HUANG Jie, CHEN Lifei. KNN model based incremental learning algorithm[J]. Pattern Recognition and Artificial Intelligence, 2010, 23(5): 701−707.
[18] 黄杰, 郭躬德, 陈黎飞. 增量KNN模型的修剪策略研究[J]. 小型微型计算机系统, 2011, 32(5): 845−849. HUANG Jie, GUO Gongde, CHEN Lifei. Research on pruning strategy of incremental KNN model[J]. Journal of Chinese Computer Systems, 2011, 32(5): 845−849.
[19] 钱强, 庞林斌, 高尚. 一种基于改进型KNN算法的文本分类方法[J]. 江苏科技大学学报(自然科学版), 2013, 27(4): 381−385. QIAN Qiang, PANG Linbin, GAO Shang. A text classification method based on improved KNN algorithm[J]. Journal of Jiangsu University of Science and Technology, 2013, 27(4): 381−385.
[20] ZHANG Bin, SRIHARI S N. Fast k-nearest neighbor classification using cluster-based trees[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(4): 525−528.
[21] 代六玲, 黄河燕, 陈肇雄. 中文文本分类中特征抽取方法的比较研究[J]. 中文信息学报, 2004, 18(1): 27−33. DAI Liuling, HUANG Heyan, CHEN Zhaoxiong. A comparative study on feature selection in Chinese text categorization[J]. Journal of Chinese Information Processing, 2004, 18(1): 26−32.
[22] RONG Huigui, ZHOU Xun, YANG Chang, et al. The rich and the poor: a Markov decision process approach to optimizing taxi driver revenue efficiency[C]// Proceedings of the 25th ACM International Conference on Information and Knowledge Management. Indianapolis , USA, 2016: 2329−2334.
[23] 万韩永, 左家莉, 万剑怡, 等. 基于样本重要性原理的KNN文本分类算法[J]. 江西师范大学学报(自然科学版), 2015, 39(3): 297−303. WAN Hanyong, ZUO Jiali, WAN Jianyi, et al. The KNN text classification based on sample importance principals[J]. Journal of Jiangxi Normal University (Natural Sciences Edition), 2015, 39(3): 297−303.
(编辑 陈灿华)
A text classification algorithm based on feature library projection
YIN Shaofeng1, ZHENG Hui2, XU Shaohua1, RONG Huigui3, ZHANG Na3
(1. Department of Campus Informatization and Management, Hunan University, Changsha 410082, China;2. School of Tourism Management, Hunan University of Commerce, Changsha 410205, China;3. School of Information Science and Engineering, Hunan University, Changsha 410082, China)
Considering that KNN algorithm has some disadvantages such as high time complexity, feature reduction, sample clipping and information loss, a feature library projection (FLP) classification algorithm was proposed. Firstly, the algorithm reserved all the features and characteristics of the training sample weight in the feature library. The data in this library were changed into new projection samples through the projection functions. By calculating the similarity of the new sample with the projection samples, data classification could be achieved. Based on the text classification, the effectiveness of the algorithm and texts, the data were validated under two conditions, i.e. small training texts and large training texts, and it was compared with KNN algorithm. The results show that the FLP algorithm does not lose the classification feature, and the classification accuracy is higher than that of other ones. The classification efficiency is not directly related to the sample size growth, and the time complexity is low.
text classification; KNN algorithm; feature library projection
10.11817/j.issn.1672-7207.2017.07.014
TP391
A
1672−7207(2017)07−1782−08
2016−09−20;
2016−11−12
国家自然科学基金资助项目(61672221,61304184,61672156) (Projects(61672221, 61304184, 61672156) supported by the National Natural Science Foundation of China)
郑蕙,讲师,从事旅游大数据挖掘与电子商务研究;E-mail: zhdilly@163.com
