基于QoS综合评价的服务选择方法
2017-09-01何干志刘茜萍
何干志,刘茜萍
(南京邮电大学 计算机学院,江苏 南京 210003)
基于QoS综合评价的服务选择方法
何干志,刘茜萍
(南京邮电大学 计算机学院,江苏 南京 210003)
从海量服务中准确选择出符合用户真实需求的服务变得日益重要,而服务质量的评定在选择服务的过程中至关重要。基于QoS的已有服务选择方法,通常假定服务提供者和使用者给出的QoS数据都是真实可信的,但这一假设实际上很难得到保证。为此,提出了基于QoS综合评价的服务选择方法。该方法针对来自服务提供者的质量属性,基于历史数据的统计对当前QoS数据进行修正;而针对来自服务使用者的质量属性,基于具有时间系数的历史评价计算推荐用户和目标用户之间的相似程度,以权衡其历史评价的可靠程度,进而得出针对该目标用户的最终QoS参考评价。同时,采用熵值法计算用户的主客观合成权重,并基于提供者修正QoS发布信息和用户可靠的QoS参考评价信息完成服务选择。实例验证结果表明,所提出的方法有效可行。
服务选择;用户相似度;熵值法;QoS综合评价
1 概 述
网络环境中服务技术的出现为组织间建立一种灵活多样的协作关系创造了前所未有的机会[1]。目前,随着服务的发展和广泛应用,服务的大量出现,提供相同功能的服务越来越多,如何准确从庞大的服务集中选择最符合要求的服务是服务技术面临的巨大挑战。因此,基于服务质量对服务进行选择已成为热点研究问题之一[2-3]。
目前提出的不少基于QoS的服务选择方法大多假定服务提供者描述的QoS数据和用户反馈的QoS评价都是真实可靠的,因而在对服务进行排序和选择时,常常直接使用服务提供者发布的QoS数据,同时采用平均值的方法处理服务使用者反馈的QoS数据[4-5]。然而在实际应用中,对于QoS数据可靠性的假设往往很难保证:一方面,服务提供者可能出于利益考虑,发布高于服务实际水平的QoS数据以吸引更多的用户[6-7];另一方面,用户反馈的QoS评价,常常受到自身因素的影响,甚至是一些恶意的虚假数据,而平均值的方法缺少能够度量这些质量属性数据有效性的标准。这些不可靠的QoS数据将直接影响QoS计算的准确性和可靠性,以及最终的服务选择结果[8-10]。
随着数据可靠性问题的日益突出,一些学者开始渐渐关注这类问题的研究。文献[11]根据用户反馈的QoS数据,从而得到可靠的QoS评价信息,当服务提供者描述不符合事实的QoS数据,该提供者这种不诚实的行为将受到处罚,但是该方法却没有提出服务使用者QoS可靠性问题的计算方法,忽略了其在服务选择过程中的作用;文献[12]同时考虑了来自服务使用者和服务提供者两方面的QoS属性,同时通过不同的计算方法来修正QoS属性值,从而得到可靠的QoS质量属性值参考信息,但是该方法却忽略了QoS质量属性值的动态变化,却将其视为了常量;文献[13]定性分析了直接经验和间接经验在服务可信性判断中的作用,考虑了服务的时效性,并提出了QoS可靠性的评估函数,但片面强调了直接经验的主导作用,忽略了当交往次数很少时间接经验的重要性;文献[14]提出了一种基于历史经验和可信概率的贝叶斯模型,给出了奖励函数,但偏重于对用户的未来行为进行约束。
然而,目前基于可靠QoS的服务选择研究大多仅根据服务提供者描述或用户反馈信息开展,难以为目标用户提供全面可靠的QoS选择依据。为此,提出了一种基于QoS综合评价的服务选择方法。对于来自服务提供者描述的QoS,基于历史数据的统计对服务提供者当前描述的QoS数据加以修正,对于来自用户反馈的QoS评价,基于用户相似度计算得到各候选服务的可靠综合QoS评价。此外,还采用了熵值法以计算得到用户的主客观合成权重。基于提供者的修正QoS发布信息和用户的可靠综合QoS评价信息完成符合用户权重的服务选择。
2 基于历史数据的服务提供者QoS信息修正
对于来自服务提供者描述的质量属性数据,如服务的执行时间、价格等,这类属性通常在服务注册时会随着功能属性发布到注册中心,但一些服务提供者为了吸引服务使用者会发布高于实际性能的数值,所以,在进行服务选择时如果直接使用服务提供者发布的数据是不合适的。对于这方面数据的修正,主要通过在客户端中加入采集机制的方式收集服务提供者描述的历史数据。该机制基于历史数据的统计定期对当前描述的QoS数据进行修正,此类质量属性的修正是由提供者当前描述的数据和统计的历史数据加权决定,并引入时间因子,从而保证QoS数据的可靠性。下面给出该过程的若干相关定义。
定义1(S,R,PT):S表示所有用户使用过的服务集合,有S={s1,s2,…,sm};R表示服务描述的矩阵,有R={Ri,j|Ri,j表示服务si第j次发布的QoS数据,Ri,j=
针对服务提供者当前发布的数据,使用式(1)对其进行修正。
q=wRi,v+(1-w)f(Ri,0,Ri,1,…,Ri,v-1)
(1)
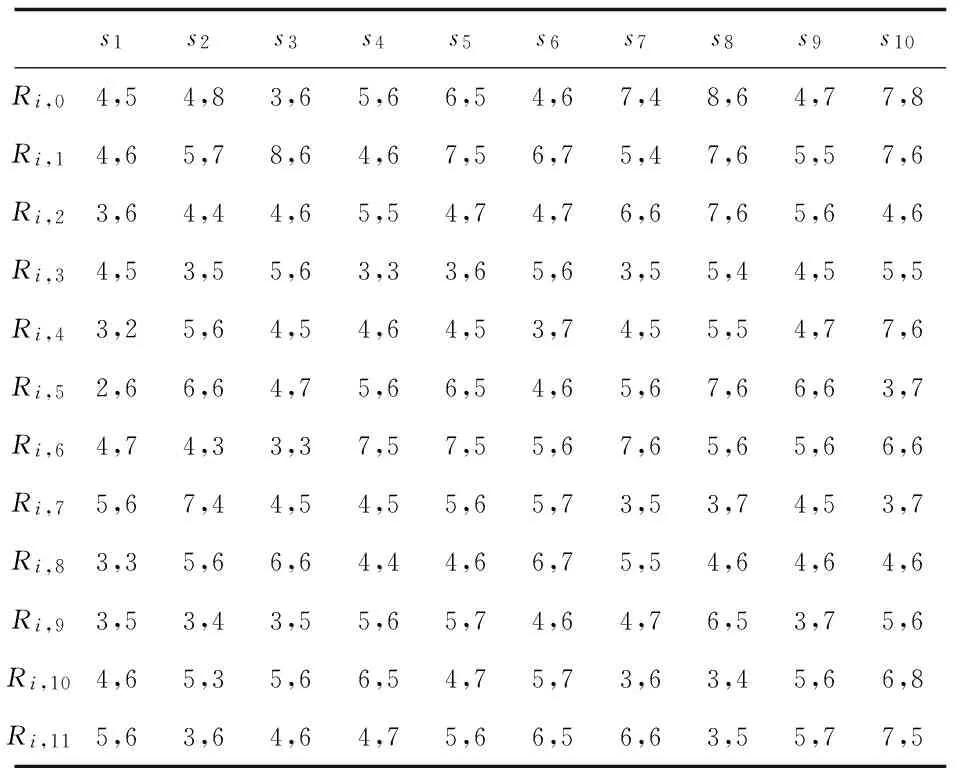
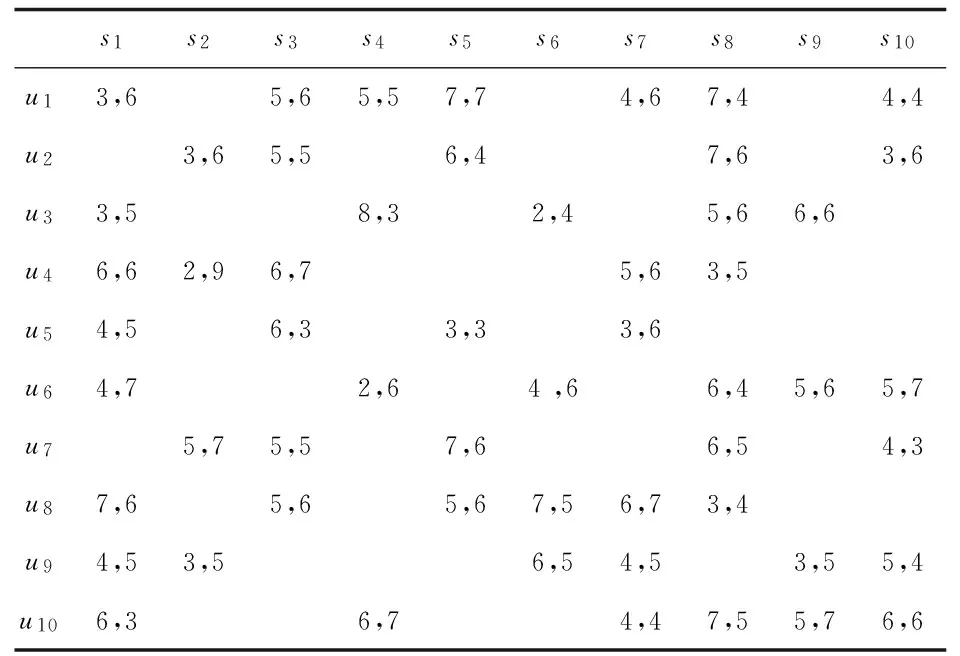
其中,Ri,0,Ri,1,…,Ri,v是从服务提供者发布了多次数据后采集到的v+1次相关质量属性向量值;w(0 另外需要说明地是,当服务无法收集历史服务质量属性数据时,则只有Ri,v这一当前发布信息,此时可设w=1,即服务提供者当前发布的数据为最终该质量属性值,具体计算方法为: q=Ri,v (2) 假设某服务si发布了多次数据后,从中采集v+1次相关质量属性向量值,分别为Ri,0,Ri,1,…,Ri,j,…,Ri,v(按时间先后),其对应的时间分别是pti,0,pti,1,…,pti,j,…,pti,v,其中pti,0为服务si最初发布该服务的时间,故pti,j-pti,0为第j次服务与最初发布服务时间间隔。一般而言,时间越近值越可靠,所以发布服务质量属性的时间距离最初发布服务的时间越长,所占的权重就越大。具体计算方法为: (3) 对于来自服务使用者反馈的服务质量属性,如满意度,由于受到服务使用者所处环境、主观想法等各种因素的影响,对于同一种服务而言,不同的使用者在使用过该服务后都可能会有截然不同的评价结果,而且不排除恶意诋毁的情形,将所有评价平等对待是不合适的。因此在QoS计算中,对所有的用户评价取平均是不合适的。为此,采用了“用户相似度”作为衡量不同用户评价所占的权重大小,以它们的加权平均求得最终评价。所谓“用户相似度”是指两个用户对于使用过相同服务所反馈评价的相似程度,即相似程度越大,其用户评价在计算中所占的权重就越大。下面给出该过程的若干相关定义。 定义2(U,EV):U表示一组使用过相关服务的用户构成的集合,有U={u1,u2,…,ul};EV表示用户对服务的评价矩阵,有EV={EVi|EVi是用户评价集合,为一个四元组,有EVi=(Ei,Ti,Ci,STi)}。其中,Ei是用户ui所访问服务的有限集合,有Ei={sj|sj为ui用过的服务,sj∈S};Ti表示用户ui使用的服务次数矩阵,有Ti={ti,j|ti,j表示用户ui使用服务sj的次数,i=1,2,…,l,j=1,2,…,m};Ci是用户ui对所访问服务评价的有限集合,有Ci={Ci,j,p|Ci,j,p为用户ui对服务sj第p次的评价向量,而Ci,j,p= 定义3(推荐用户):用户ui'和ui的评价分别是Vj=(Ei',Ti',Ci',STi')和Vi=(Ei,Ti,Ci,STi),也就是如果Ei∩Ej≠∅,且存在Sj∈Ei',Sj∉Ei,同时用户ui希望获取服务Sj的评价信息,则称用户ui'为ui关于服务Sj的推荐用户。 尽管目前有很多对用户相似度计算的相关研究,但是均未考虑到多次使用服务和使用服务的时间长短对评价的影响。比如用户住酒店的次数越多或者住的时间越长,则对酒店了解程度就越高,所以该评价的可靠性就越高。因此,在计算用户相似度时,引入了用户领域相关度和用户时间系数进行修正。所谓的用户领域相关度是指推荐用户对服务领域的了解程度高低,一般情况下,推荐用户使用某服务的次数占该服务总使用次数的比重越大,说明其对服务了解程度越高,那么推荐用户评价的权重系数越高。为此,使用式(4)对其进行计算: (4) 其中,α为推荐用户ui在服务si的领域相关度;l为用户总数。 所谓的用户时间系数是指用户对服务性能的熟知程度。一般情况下,用户使用该服务的平均时长占所有用户使用该服务平均时长之和的比重越大,说明其对服务了解程度越高,那么推荐用户评价的权重系数越高;同理相反。为此,使用式(5)对其进行计算: (5) 目前为止,计算服务相似度的公式有很多,例如皮尔逊相关系数、余弦相似度等。为了使服务的推荐方法更加准确,从而需要改进目前已有的相似度计算方法。因此引入了服务的个性化特征这一概念。例如,假设用户a和用户b以前都使用过服务1和服务2,给定的服务1和服务2分别为用户不敏感服务和用户敏感服务,不同用户在使用过服务1后,给出的QoS评价值大体相同,因此所对应的方差比较小,通过目前已有的计算公式计算出用户a和用户b的相似程度偏高,然而这并不能代表真实的相似程度,因为服务1对于所有的用户而言是没有差别的,这样的服务1用于用户a和用户b的相似度计算时应该贡献程度越低。相反,不同用户在使用过服务2后,给出的QoS评价值所对应方差比较大,表明服务2对不同的用户来说所产生的评价差别很大,此时,如果两个用户在使用过服务2后给出的QoS评价值相似,这两个用户才能算是真正意义上的相似。这样的服务2用于用户a和用户b的相似度计算应该贡献程度越高。 总而言之,在计算两个用户的相似度时,不能忽略这两个用户共同调用的服务个性化特征。为此,使用式(6)进行计算: (6) 因此,使用结合服务个性化特征的距离向量法来计算目标用户服务评价和参考用户服务评价的偏离大小,服务的QoS属性可以使用向量形式表达,将用户共同使用过的服务集合视为一个多维空间,用户对这些服务反馈的质量属性数据视为该空间的一个点。则两用户之间的反馈相似度可以通过它们之间的几何距离来衡量,距离越小,说明目标用户和参考用户反馈的服务评价相似度越大,则该用户的评价信息所占的权重值越大。距离越大,说明目标用户和参考用户反馈的服务评价相似度越小,则该用户的评价信息所占的权重值越小。 结合服务个性化特征的距离向量法为: dist(ui,ui')j,k= (7) 通过式(8)可以将用户ui和ui'之间的距离进行归一化,将其限制到[0,1]这个区间内,即可得到相似度。可以采用不同的归一化标准,这里采用的是分数归一化,具体的形式为: (8) 其中,ri-i',j,k为用户ui和ui'在服务sj属性k上的评价相似度;dist(ui,ui')为ui,ui'在服务sj属性k上的几何距离。 如果两个用户之间共同评分项目少,比如只有一个共同评分,而且两个用户的评分相同,用距离向量法算出的值为0,但仅仅因为两个用户对某个服务的看法相同,就认为两用户的兴趣高度一致,显然不符合现实,所以需要在用户推荐度上加上加权因子β。 则得到: (9) 采用这种方法,两个用户之间共同评分项目少会降低用户推荐度,而两个用户之间共同评分项目多会增大用户推荐度。给定用户ui'为ui关于服务sj的推荐用户。则用户ui'针对用户ui关于服务sj在属性k上的用户推荐度为: Ri-i',j,k=β×ri-i',j,k×(1+α+η) (10) 为此,引入“用户推荐度”作为不同反馈数据的权重,以它们的加权平均作为最终的质量属性值。则: (11) 其中,ei,j,k为所有推荐用户向ui推荐服务sj时第k个属性的参考值。 在应用上述方法得出可靠的服务提供者QoS值和服务使用者评价的QoS值后,可基于综合QoS评价进行服务选择。由于在进行服务选择时,需要综合全面考虑服务的QoS属性值。 通常采用加权平均的方法,权重的设置可以采用如下几种方式:一是由用户完全给出每个属性的权重,即主观权重;二是根据服务的属性值,通过一定的算法求出权重,即客观权重;三是既考虑服务的主观权重又考虑服务的客观权重,通过主观权重和客观权重再加权求得。 以上三种方式均有各自的优点。对于第一种加权方式来说,用户可以根据自己真实的需求对不同QoS属性做出正确判断,从而对相应的属性赋予满足真实需求的权重;对于第二种加权方式来说,由于服务对于用户而言有可能是一种全新的服务,在使用服务时对于不同QoS属性并不知道如何关注。如果用户在不了解服务的情况下随意赋予权重值,由此选择出的服务很可能并不是最优的,针对此问题,此时就可以采用客观权重;对于第三种加权方式来说,用户对某些服务并不熟悉,虽然对某些QoS属性有要求,但是并不能确定用自己的方式设置的权重选择出来的服务是最优的,所以需要参考下属性的客观权重,使主观权重和客观权重各占一定的比例,用户自己完全可以根据个人需求设置该比例大小。如果希望用户自己设置的权重大,即将主观权重的比例调大一点,如果希望客观权重大些,即将客观权重的比例调大。综合上述可知,采用第三种方式更具优势。 服务质量矩阵可以表示为: X=(xij)m×(n1+n2) (12) 其中,m为可选服务的数量;n1+n2为服务的属性个数。 对于客观权重,即cw=(cw1,cw2,…,cwn1+n2)T,采用熵值法进行计算。由熵值法可知,某个属性信息的价值取决于1和该属性熵的差,该差影响属性权重大小,信息的价值越大,对评价结果的影响就越大,属性权重值也得到相应增大,因此,熵值法确定某个属性的权重是利用该指标属性的价值系数来计算,该值越高对评价的影响就越大,则权重越大。熵的计算方法如下: (13) 其中,τ为常数τ=1/lnm;ej为QoS矩阵Y的属性j的熵值。 因此,计算属性j客观权重cw的方法为: (14) 由于所采用的权重是主客观合成的权重,假定用户给出的主观权重为zw=(zw1,zw2,…,zwn1+n2)T,通过以上方法求得客观权重为cw=(cw1,cw2,…,cwn1+n2)T,则合成的权重,即sw=(sw1,sw2,…,swn1+n2)T,swj的计算方法为: swj=a×zwj+(1-a)cwj (15) 最终将矩阵X=(xij)m×(n1+n2)和合成权重sw=(sw1,sw2,…,swn1+n2)T相乘得到的矩阵表示为Z=(zij)m×1,通过式(16)求得: zij=swj×xij (16) 同时根据最终矩阵Z选择最优服务。 下面将给出一个具体实例以演示上述方法的有效性。以旅游服务为例,生成10个用户集合U={u1,u2,…,u10}和10个旅游商家集合S={s1,s2,…,s10},并选取旅游商家的服务费用、服务时间、服务满意度、服务可靠性4个指标作为服务的QoS属性。其中旅游商家的服务费用和服务时间这两个属性数据主要来源于服务提供者,服务满意度和服务可靠性这两个属性数据主要来源于服务使用者。所采用的是10分制。 表1中Ri,11表示服务提供者当前发布的QoS属性数据,Ri,0,Ri,1,…,Ri,10表示利用采集机制收集的11次历史数据(其中Ri,0是服务最初发布的数据,采集的数据时间间隔为1天)。 表2为用户评价矩阵,由于用户可以多次使用服务,所以每个单元格对应每次使用服务的评价信息,在单元格中前两个数字表示用户的评价值而后一个数字表示服务的使用时间(由于用户评价数据较多,所以只抽取了u1,u2,u10的数据)。 5.1 获取可靠的服务提供者发布的属性值 Step1:基于采集到的Ri,0,Ri,1,…,Ri,10数据,通过式(3)计算综合历史的QoS值。以s2中服务费用属性 表1 10个服务对各属性12次历史描述信息表 表2 3个用户对10个服务各属性的历史评价信息表 为例,有: f(Ri,0,Ri,1,…,Ri,10)= Step2:通过式(1)对服务s2发布的数据进行修正,设w=0.5。计算结果为<3.836 36,5.218 18>。同理求得s6,s9分别为<5.481 81,5.790 91>,<4.681 81,6.518 18>。 5.2 获取可靠的服务使用者反馈值 表3 10个用户对10个服务各属性的平均评价信息表 表4 用户使用服务次数和服务使用平均时长信息表 Step5:假设β=1;以服务s2为例,通过式(10)求得u2,u4,u7,u9的关于第一个属性推荐度分别为0.571 81,0.254 37,0.660 93,1.127 59;关于第二个属性推荐度为0.263 92,0.736 61,0.521 59,0.594 75。同理求得服务s6中u3,u6,u8,u9关于第一个属性推荐度分别为0.324 43,0.335 90,0.173 03,0.561 48;关于第二个属性推荐度分别为0.394 89,0.361 37,0.358 93,0.592 31。服务s9中u3,u6,u9,u10关于第一个属性推荐度分别为0.283 87,0.289 81,0.630 12,0.349 07;关于第二个属性推荐度分别为0.345 53,0.311 78,0.664 72,0.296 32。 5.3 基于QoS综合评价的服务选择 Step1:通过前两个过程得出的初始矩阵为: Step2:通过式(13),可以求得e1,e2,e3,e4分别为0.990 47,0.996 22,0.991 78,0.991 01。 Step3:通过式(14),有: cw1=(1-0.990 47)/((1-0.990 47)+(1-0.996 22)+(1-0.991 78)+(1-0.981 01))≈0.312 25,同理cw2,cw3,cw4分别为0.123 85,0.269 33,0.294 56。即cw=(0.312 25,0.123 85,0.269 33,0.294 56)T。 Step4:假设目标用户的主观权重值为zw=(zw1,zw2,…,zw4)T=(0.3,0.2,0.4,0.1)T,设a=0.5,通过式(15),有sw1=0.5×0.3+(1-0.5)×0.312 25=0.306 13,同理求得sw2=0.161 92,sw3=0.334 67,sw4=0.197 28;即sw=(0.306 13,0.161 92,0.334 67,0.197 28)T。 Step5:根据式(16),有: (0.306 13,0.161 92,0.334 67,0.197 28)T= Step6:由于5.339 28>5.175 30>4.542 79,所以服务s9最适合目标用户u1。 为了向目标用户提供全面可靠的QoS选择依据,提出了一种基于QoS综合评价的服务选择方法。对于来自服务提供者描述的QoS,基于历史数据的统计对服务提供者描述的QoS数据加以修正;对于来自用户反馈的QoS评价,通过计算用户之间以往反馈的相似程度,同时引入用户领域相关度,时间系数和服务个性化等概念对用户相似程度进行修正,得到最终推荐度,然后由用户推荐度所占的比重作为权重计算出最终评价值;在计算出所有的结果后,针对目标用户对主观给出的各QoS属性权重值可能不太确定的现状,采用熵值法计算客观权重并结合用户的主观权重加权进行整合,从而进行服务选择。通过实例验证了该方法的有效性,提高了服务选择的准确性。下一步工作中,将结合数理统计理论对相似度计算公式进行深入研究。 [1] 王海艳,杨文彬,王随昌,等.基于可信联盟的服务推荐方法[J].计算机学报,2014,37(2):301-311. [2] 曹利培,李爱玲,刘 静.基于QoS的两阶段Web服务选择方法[J].计算机工程与设计,2009,30(3):747-751. [3] Zheng Z,Ma H,Lyu M R,et al.Wsrec:a collaborative filtering based web service recommender system[C]//IEEE international conference on web services.[s.l.]:IEEE,2009:437-444. [4] 邵凌霜,李 田,赵俊峰,等.一种可扩展的Web Service QoS管理框架[J].计算机学报,2008,31(8):1458-1470. [5] 郭得科,任 彦,陈洪辉,等.一种基于QoS约束的Web服务选择和排序模型[J].上海交通大学学报,2007,41(6):870-875. [6] 杨胜文,史美林.一种支持QoS约束的Web服务发现模型[J].计算机学报,2005,28(4):589-594. [7] 巫 茜,周 庆.基于QoS与可信度融合的Web服务选择机制研究[J].计算机科学,2012,39(7):108-111. [8] Mehdi M,Bouguila N,Bentahar J.A QoS-based trust approach for service selection and composition via Bayesian networks[C]//Proceedings of ICWS’13.[s.l.]:[s.n.],2013:211-218. [9] 马 友,王尚广,孙其博,等.一种综合考虑主客观权重的Web服务QoS度量算法[J].软件学报,2014,25(11):2473-2485. [10] 宋海霞,严 馨,余正涛,等.基于自适应聚类的虚假评论检测[J].南京大学学报:自然科学版,2013,49(4):433-438. [11] Bellare M,Namprempre C,Pointcheval D,et al.The power of RSA inversion oracles and the security of Chaum’s RSA-based blind signature scheme[C]//Lecture notes in computer science.Berlin:Springer,2002:319-338. [12] Okamoto T.Efficient blind and partially blind signatures without random oracles[C]//Lecture notes in computer science.Berlin:Springer,2006:80-99. [13] Camenisch J,Koprowski M,Warinschi B.Efficient blind signatures without random oracles[C]//Lecture notes in computer science.Berlin:Springer,2005:134-148. [14] Boneh D, Boyen X. Efficient selective-ID secure identity based encryption without random oracles [C]//Lecture notes in computer science.Berlin:Springer,2004:223-238. A Service Selection Method with QoS Synthetic Evaluation HE Gan-zhi,LIU Xi-ping (College of Computer Science & Technology,Nanjing University of Posts and Telecommunications,Nanjing 210003,China) It is increasingly important for users to exactly select a service meeting their requirements from the mass services.Assessment on the quality of service is crucial in the process of service selection.Existed QoS-based service selection methods generally assume that QoS data from service providers and users are trustable.However,it is not realistic.Therefore,a service selection method based on comprehensive evaluation of QoS is proposed,by which the values of quality attributes provided have been adjusted based on historical statistical data and that from user reviews have been integrated into a comprehensive QoS evaluation for a target user based on the user similarity computed through reviews on time factors.Moreover,entropy method is adopted to calculate the user’s subjective and objective synthesis weights with further operation of service selection based on the adjusted publishing QoS from providers and the reliable reviewing QoS from users.The experimental results show that it is effective and feasible. service selection;user similarity;entropy method;QoS synthetic evaluation 2016-09-30 2017-01-04 网络出版时间:2017-07-05 国家自然科学基金资助项目(61402241) 何干志(1992-),男,硕士研究生,研究方向为服务计算;刘茜萍,副教授,硕士生导师,研究方向为服务计算、工作流。 http://kns.cnki.net/kcms/detail/61.1450.TP.20170705.1652.074.html TP301 A 1673-629X(2017)08-0164-07 10.3969/j.issn.1673-629X.2017.08.035
3 可靠的用户评价获取



4 基于综合QoS评价的加权服务选择


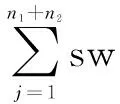
5 实例分析










6 结束语
