商品评论情感倾向性研究
2017-08-29杜娇钱育蓉范迎迎
杜娇,钱育蓉,范迎迎
(新疆大学软件学院,新疆乌鲁木齐830008)
商品评论情感倾向性研究
杜娇,钱育蓉⋆,范迎迎
(新疆大学软件学院,新疆乌鲁木齐830008)
为辅助消费者做购买决策,同时帮助销售商改进产品,在竞争中保持优势,对商品评论进行处理研究,设计了商品评论抓取系统。结合中科院ICTCLAS分词框架,实现了对商品评论的切割、分类,构建限定词库,据此构造了评论情感得分公式,首先算出每个分句的情感的情感倾向,进而通过加权求和法计算每条评论的总体倾向。以“淘宝网”数据为例,2017年1月6日爬取了12个商品自上架以来的16850条评论记录,经实验,提出的情感得分计算方法能够定量地判断消费者的情感倾向及产品的主要特征。
爬虫程序;商品评论;分词;情感倾向;产品特征
随着互联网的迅速发展,网上购物以价格便宜,节省时间吸引了越来越多的消费者,“用户参与网站内容制造”也随之发展起来,如新闻、博客、产品评论、论坛等等。消费者在购买商品并亲身体验之后,在网络上发表自己对该商品的评论,这些商品评论中蕴含着消费者对购买商品过程和使用商品后的主观感受,有助于辅助其他消费者做购买决策。除此之外,商品评论作为一种反馈机制,能让商家知道其商品在消费者心中的受欢迎程度,促进商家提升商品质量、服务等等,从而保持商品在竞争中处于优势地位。面对成千上万的评论信息,消费者和商家想从商品评论中获取信息,只能通过人工阅读的方式,这种方式费时费神。因此,我们迫切需要有一种有效的手段对大量评论数据进行处理,直观地看出消费者对商品的态度。
目前,针对商品评论的研究工作已经从对评论语句整体的情感分类细化到对产品特征属性的评论情感倾向性研究,因此需要从商品评论中提取出消费者评价的对象——产品特征。产品特征的提取分为人工定义和自动提取两类[1]。人工定义的方式也很多,举例子通过人工定义方式构建了个三元组进行表示
1 相关研究
情感分析又称评论挖掘或意见挖掘,它的目的是通过分析带有主观情感或者具有褒贬倾向的主观性文本,挖掘其中的观点和评论信息,以更直观和简洁的形式将其展示给用户[2]。情感分析按其分析的粒度分成词语级情感分析、句子级情感分析、篇章级情感分析;按其任务类型,可以分为情感分类,情感检索,情感抽取等子问题[3]。
1)词语级情感分析
词语级情感分析的任务是抽取句子中的各种情感词语。情感词语一般以形容词、副词、名词和动词为主,也包括人名、事件名词、产品名、机构名等命名实体。情感词具有极性特性,通常为正向、负向和中性三种,这些词的极性一般通过情感词典的方式获得。词语的极性还取决于上下文环境,例如:“我为我是软件学院一员感到骄傲”、“骄傲使人退步”这两句话中“骄傲”是两个极性,前者是褒义,后者是贬义。研究表明,无论是人工方式,还是机器自动的方式,判断词语的主观性都难于判断词语的褒贬倾向[4]。
2)句子级情感分析
句子级情感分析的任务是抽取句子中的含有主观性的词语,从中提取与情感分析相关联的各个要素。这些要素包括情感分析的观点持有者、评价对象、倾向极性和强度[5]。例如:“同事说眼镜很漂亮”,这个例子中,观点持有者是“同事”,评价对象是“眼镜”,倾向极性是“漂亮”,是正向褒义词,强度词是“很”。
3)篇章级情感分析
篇章级情感分析是指从整体上判断某个文本(一段评论语句或一篇文章)的情感倾向性,即褒贬的态度。这种方法是基于情感倾向性词典,不需要人工标注文本情感语料库。篇章级情感分析,将文章看作一个整体,笼统地进行主观性分析具有局限性。因此,近几年根据情感倾向对篇章进行褒贬态度分类的研究有减少的趋势。
4)情感分类
情感分类是指给定一段带有主观描述的文本,判断这段文本的总体情感类别。情感类别主要是指描述文本情感倾向的正向和负向两个类别。正向是指文本的总体的情感是褒义,负向是指总体的情感是贬义。情感类别分类主要分为两种方法:无监督学习方法和有监督学习方法[6-7]。
5)评价词语的抽取
评价词语又称为极性词或者情感词,是评论者对其所评价商品或特征属性的情感表达[8]。在评论语句中,评价词语起着举足轻重的作用,它是评论者情感表达的直接方式,是评论者情感的载体,正确识别评价词语是进行情感倾向性判断的前提。
目前,对于评价词的抽取主要有两种方法[9-11]:一是基于语料库的方法,使用基于语料库进行评价词语抽取,其基本思想是通过统计的方法,对大量的评论语料预处理后再进行词汇的统计,对统计结果进行分析,通过观察统计结果中存在的一些规则和频繁的特征来挖掘评论语句中的评价词语,再得到评价词语的基础上进而判断其情感极性;二是基于评价词典的方法,使用基于词典的方法时,主要是计算评价语句中的词语和构建的评价词典的词语之间的形似度,如果评论语句中某一个词语与评价词典中的词语的相似度较高,就将该词语作为候选的评价词。
2 研究过程
2.1 商品评论抓取系统
用Java程序语言编写“商品评论抓取系统”,将商品评论信息中的评论人、评论时间、评论的内容等信息抽取出来,并以文本格式存储,为后续的情感分析、数据挖掘工作做准备。所抓取的实验数据仅限于原始评论数据,不包含追加评论和商家回复的信息。“商品评论抓取系统”中评论抓取过程如图1所示。

图1 商品评论抓取过程
实现步骤如下:
1)对商品的URL进行分析研究发现商品URL主要组成部分如下:
2)分析商品评论内容组成格式。
3)编写程序,从商品链接中获得商品Id,sellerId。
4)拼接商品链接,向服务器端发送请求,解析服务器端传回的Json字符串,拿取对象结果。
5)将抽取的数据以文本的格式保存,其中保存的信息包括评论者昵称、评论时间、评论内容。
2.2 情感分析
在对前人研究进行了理论知识和相关技术学习的前提下,本文设计了情感分析流程,如图2所示。

图2 情感分析流程
将抓取的评论数据进行分割,预处理,调用ICTCLAS2015分词系统NLPIR.lib中的ParagraphProcess函数,将评论语料进行分词和词性标注,并将每条分词结果存入Oracle数据库。同时调用NLPIR_GetKeyWords函数,对评论语句的关键词进行识别,识别后的结果抽取到数据库关键词表中,以待后续数据分析模块进行数据分析。
由于中文态度一般由形容词和副词进行表达,举个例子“眼镜不喜欢”,这句话分词后的结果为“眼镜/n不/d喜欢/a”,这句话的关键词为“眼镜”,“喜欢”为形容词(情感词),“不”为限定词,本文提出一种简单的情感打分公式:

Score表示一个分句的得分,Qualifier表示一个分句中限定词的得分,Adjective表示一个分句中情感词的得分。
计算出每个分句的得分,则一条评论的得分:

情感倾向分3种:正面,负面,中性。由于目前缺乏公认的包含情感倾向程度的情感词典,而且本文主要是判断情感倾向,因此本文未考虑情感词的情感程度。
本文中,正面情感词的得分默认为1,负面情感词的默认得分为-1,中性词的默认得分为0,如式(3)所示。部分情感
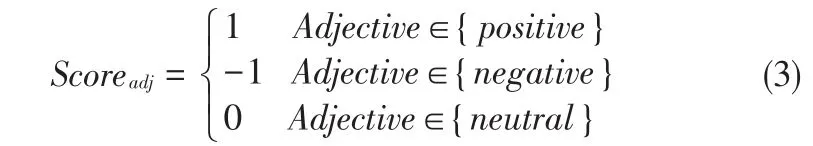
本文所用情感库是根据评论中的情感词,人工构造的情感库(表),同时构建了限定词库,目前库中包含了636条情感词汇,145条限定词汇,现例举部分内容,如表1,表2所示。因此我们需从表1中抽取情感词所对应的分数,从表2中获得限定词对应的分数。例如:“喜欢”对应的分数为1。“不”分数为-1,则:
Score=(-1)*1=1。

表1 情感词表

表2 限定词表
3 实验和分析
3.1 数据采集
系统于2017年1月6日,对“淘宝网”上暴龙、雷德蒙、帕森三个眼镜品牌的12个商品进行数据采集,除去评论内容为空的信息,共获得16850条评论记录,共计1.20M数据,包含12个文本文件,文件名均为店铺名,每个文件中包含用户名、评论时间、评论内容等信息,并将非结构化数据进行标准化处理。
3.2 系统实验
本实验的实验数据是商品评论系统抓取的数据,每一个功能测试的输出作为下一功能测试的输入,直至实验结束。首先对是“获取文本”功能进行测试,读取评论的原始数据,根据规则,获得评论的文本信息。紧接着对“分词”功能进行测试,然后对“断句”功能进行测试,最后进行“情感极性判断”功能测试。通过对数据的测试,数据抓取模块、分词模块、情感极性判断模块,系统均能够正常运行,实验结果基本达到预期目标。
3.3 结果分析

图3 情感关注点
对评论文本进行分析,并选取出现频率较高的前8个关键词,如图3所示。从图中可以看出消费者关注包装、质量、物流、款式等影响因素,销售商,可以从消费者关注的方面进行改进,获得更好的效益。
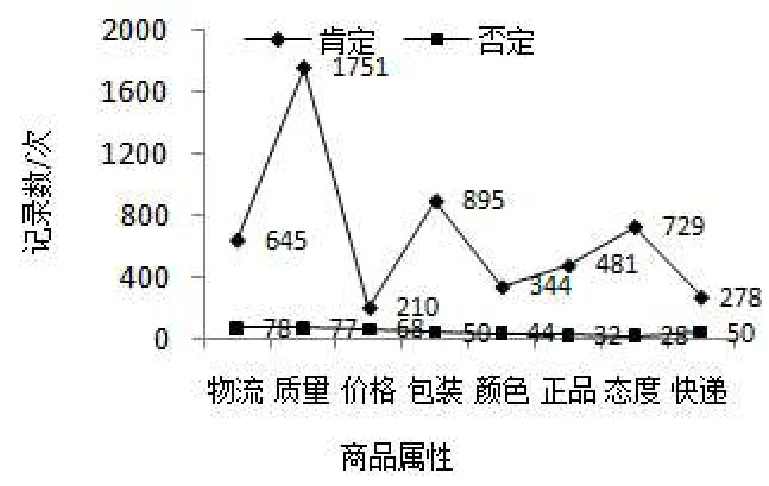
图4 消费者对商品属性的态度
图4展示了消费者对商品属性的态度,从图中可以很清楚地明白该商品的优缺点。例如:对质量满意的有11751人,对质量不满意的有77人。“质量”这个特征,对其他消费者有较好的建议性,商家也能明白自身竞争力。

图5 评论时间
对2016年12个月份的评论数据进行统计分析,结果如图5所示,虽然仅仅是评论时间,但一般消费者都是收到商品后便会进行评论,所有“评论时间—评论数”,可以在一定程度上反映出“时间—销量”之间的关系,通过时间走向,销售商可以根据这一信息对是否进货,进多少货进行判断,同时也可以根据季节变化进行促销活动、价格调整等。
4 结束语
为了有效收集整理商品评论信息,本研究针对淘宝商品编写了商品评论抓取系统,对商品的网站页面进行了分析,设计数据抓取算法,依据正则表达式筛选所需信息并实现程序的编写。有效地实现了商品评论抓取功能。通过ICTCLAS的框架进行分词,人工构建情感词表和限定词表,构造了评论情感得分公式,并依据该公式计算了每句商品的得分,经测定该公式可以有效地判断评论的极性。最后从消费者和商家两个不同角度对结果进行分析研究。消费者可以较快地客观的了解商品,商家也可以较清晰地发现自己的优缺点和消费者的关注点,具有一定的应用价值。
[1]杜思奇,李红莲,吕学强.汉语组块分析在产品特征提取中的应用研究[J].现代图书情报技术,2015,31(9):26-30.
[2]陆文星,王燕飞.中文文本情感分析研究综述[J].计算机应用研究,2012,29(6):2014-2017.
[3]王伟,孟祥福,肖春娇.基于耦合关系的情感词语义分析方法[J].计算机科学与探索,2014,8(9):1146-1152.
[4]李方涛.基于产品评论的情感分析研究[D].清华大学,2011: 13-18.
[5]黄萱菁,赵军.中文文本情感倾向性分析[J].中国计算机学会通讯,2008,4(2):41-46.
[6]门昌骞,王文剑.一种基于多学习器标记的半监督SVM学习方法[J].广西师范大学学报:自然科学版,2008,26(1):186-189.
[7]阳爱民,周咏梅,周剑峰.中文微博语料情感类别自动标注方法[J].计算机应用,2014,34(8):2188-2191.
[8]朱征宇,李存青,张鹏.基于语法模式的产品评论主题词和极性词提取[J].重庆理工大学学报:自然科学版,2010,24(5):86-90.
[9]RAOD,RAVICHANDRAN D.Semi-supervised Polarity Lwxi⁃con Induction[C].In:Procee-dings of EACL,2009.675-682.
[10]张铎,朱征宇.基于句法分析的评价搭配抽取及其倾向性分析[J].世界科技研究与发展,2013,35(4):477r480.
[11]RAOD,RAVICHANDRAN D.Semi-supervised Polarity Lwxi⁃con Induction[C].In:Procee-dingso.
The Study of Product Reviews Sentiment and Features
DU Jiao,QIAN Yu-rong,FAN Ying-ying
(School of Software,Xinjiang University,Urumqi 830000,China)
To assist consumers to make buying decisions,while helping vendors to improve products and maintain competitive advantage,processing studies for product reviews,product reviews crawling system was designed.combined with the CAS ICT⁃CLAS segmentation framework to achieve a cut of product reviews,classification,building Restricted thesaurus,Based on this, constructs the emotional score formula and then get a weighted summation sentiment evaluation for each micro blog sentence for⁃mula,To"Taobao"data,for example,May 30,2015 the 12 commodity crawling from the shelves since the 16,850 comments re⁃corded,by experimenting,This paper presents the emotional score calculation method can quantitatively determine the main char⁃acteristics of consumer sentiment and products.
crawlers;product reviews;segmentation;sentiment;Product Features
TP311
A
1009-3044(2017)21-0241-03
2017-06-15
国家自然科学基金资助项目(61562086,61462079,61363083、61262088);新疆“万人计划”后备项目(wr2015bj01)
杜娇(1992—),女,四川绵阳人,硕士,主要研究领域为内存计算与数据挖掘;通讯作者:钱育蓉(1980—),女,山东德州人,博士,教授,主要研究领域为研究方向为网络计算和遥感图像处理;范迎迎(1991—),女,河南周口人,硕士研究生,CCF会员,研究方向为软件理论与服务计算。
