分布式环境下的频繁数据缓存策略
2017-08-12殷慧文张一川
易 俗 殷慧文 张一川 张 莉
1(辽宁大学创新创业学院 辽宁 沈阳 110036) 2(东北大学软件学院 辽宁 沈阳 110819)
分布式环境下的频繁数据缓存策略
易 俗1殷慧文1张一川2张 莉2
1(辽宁大学创新创业学院 辽宁 沈阳 110036)2(东北大学软件学院 辽宁 沈阳 110819)
大数据环境下利用分布式缓存技术能够提供高性能、高可用的数据查询。针对轻量级数据库应用的频繁数据缓存策略具有高效、易扩展的优点,更有利于轻型分布式数据库应用的查询优化改进。因此,通过分析用户行为和用户查询特征,研究针对近期频繁查询数据的数据缓存策略,能够预测高命中率的缓存数据,提高数据查询效率。首先分析并给出查询频繁度的定义,其次根据时间因素对缓存数据选取的影响细化用户查询操作,并通过查询数据的查询频繁度应对查询过程中不同的缓存命中情况整合节点间的缓存数据。最后,实验证明该数据缓存策略具有较高的数据命中率,能够提高数据查询的效率。实现方面可根据实际需要采用不同的缓存属性组合,具有良好的易扩展性。
数据缓存策略 查询频繁度 集群环境 分布式系统 大数据
0 引 言
随着大数据时代的到来,数据呈现出4V(Volume、Variety、Value、Velocity)[1]特性,即数据量大、类型繁多、价值密度低且处理速度快。这些特性也对数据库系统提出了高并发读写、海量数据的高效存储和访问,以及高可扩展性和可用性的需求[2]。传统的关系数据库虽然稳定性高且对于集中式存储的存储查询效率较高;但面对大数据的这些特性,关系数据库高一致性和查准率已经不存在优势,而关系数据库的扩展性以及对海量数据的响应速度都遇到了障碍,不能胜任大数据的存储管理要求,以及满足不了高性能、高可用的分布式查询处理要求。
非关系型数据库——NoSQL[3-4]的数据存储不需要固定的表结构,也不存在连接操作,虽然不遵循传统关系型数据库的ACID特性,但是对于非结构或者半结构化的分布式数据存储和管理效率较高。NoSQL对数据库事务一致性需求低,实时读写快,且对复杂的查询响应较快。因此NoSQL更适用于大数据的存储和处理。
NoSQL的数据分布式存储减少了单个服务器的存储压力,提高了数据的故障恢复能力;但是这种分布式查询处理的要求要比集中式查询变得更加复杂,需要从高性能、高可用和易扩展角度研究分布式环境下的优化技术和策略,以提高数据查询处理。
现实生活中的数据库应用多以选择、投影、连接查询为主,如银行、学校、办公管理等业务。这些数据库应用不同于科学计算、数据挖掘等分析应用,不需要协同过滤、机器学习和图等具有复杂算法的计算过程,算法的复杂特点在一定程度上将直接影响分布式系统的优化方法和目标。本文从算法角度将仅针对数据属性和元组的数据库查询应用定义为轻量级应用。对于轻量级的分布式数据库系统的查询应用尤其需要满足易扩展、针对性良好等特点。针对频繁数据特征优化目标的缓存策略研究,能够提供较为准确且快速的查询优化策略,是分布式数据库系统领域的研究热点。
1 相关工作
随着硬件技术的发展,大量研究针对分布式内存对象缓存系统,比如Memcached[5]、BigTable[6]、PACMan[7]和GridGrain[8]等。由于磁盘容量往往比内存大很多,想通过内存永久存放、读取和处理数据是不能解决的问题。因此,通常利用缓存作为内存。
在大数据环境下,数据查询效率依赖于缓存数据的设计,如何选取高命中率缓存数据,以及管理不同节点间的数据缓存是当今大数据查询的研究热点。文献[9-10]中提出了元数据缓存的解决方案,通过缓存底层存储数据的元数据以实现查询数据的快速定位。由于元数据缓存多建立在客户端,进而减轻了总控节点的工作负荷。在缓存命中的情况下,客户端可跳过总控节点,直接与存储节点建立映射,获得更佳的查询性能。但这种缓存方式可扩展性不佳,对于大规模分布式系统,很难将底层数据全部缓存至客户端。同时,由于元数据缓存在客户端内,系统中任何数据变动都有可能破坏客户端内缓存数据与底层存储数据的一致性,导致客户端“脏数据”的读取。基于共享数据缓存的分布式缓存体系[11-12]通过数据共享的方式减少服务器间的数据交换,提高缓存数据利用率。在这种缓存体系下,集群中节点的缓存数据被共享至缓存池中,每个节点可根据查询任务的不同,访问不同节点内的缓存数据,进而起到降低节点间通信开销、提高查询效率的作用。但这种缓存方式对共享缓存池的维护有较高要求,共享池资源管理易成为系统性能瓶颈,增加了系统开发、维护开销,缓存池内数据更新代价也较大,不能及时对近期频繁查询数据进行处理。此外,文献[13]从图论的角度探讨了缓存数据部署对查询效率的影响,地理位置相邻的节点间缓存数据具有更低的数据传输延迟,全局查询效率更高,但同时也承担着更高的节点故障风险。这种方法虽未解决缓存数据的选取问题,但为集群中节点缓存的设计提供了新的思路。
针对大数据查询效率问题,本文提出了条件属性查询频繁度的概念,并基于此对Apriori算法进行改进,实现了一种分布式环境下的数据缓存策略,以建立频繁查询数据的高命中缓存的方式,既解决大数据的高效查询问题,又能够针对轻量级查询应用具有易扩展的特性,强调时间因素在缓存数据选取上的重要性。
2 数据缓存策略
分布式集群中的工作节点由于内存资源有限,对于存储在本地的大量数据,可能出现被查询数据无法一次全部加载入内存的情况,而多次内存与磁盘间的数据传输又会增加查询任务的执行时间,降低查询效率。对于一些轻量级数据管理业务而言,数据库查询请求多数为其中一些关键数据属性的频繁查询处理。因此,在数据装载内存过程中,将频繁处理的属性数据尽量载入内存作为数据库查询的主要目标,能够调高频繁数据的查询机会,从而提高数据库查询处理的效率。
当前主流的NoSQL数据库多采用LIRS算法实现数据缓存机制,LIRS算法使用IRR(Inter-Reference Recency)和Recency两个参数。IRR:一个页面最近两次的访问间隔;Recency:页面上次访问至今访问了多少其他页。能够针对数据的近期更迭给出缓存策略。但是,这种与业务无关的处理方法无法对较长时间内频繁查询的业务属性数据进行更合理的统计,不能采取有针对性的策略缓存查询数据。
针对轻量级数据库查询系统的应用环境中数据更新频率较低,且数据具有更强的业务语义。因此从查询属性入手,深入考察查询条件属性对业务的关联程度,能够更准确地发现较长时间内的频繁属性查询数据,进一步提高缓存数据的命中率。
本文引入查询属性频繁度的概念,使用一种改进的Apriori算法—FD-Apriori确定频繁数据,并根据频繁数据处理数据缓存。该算法可根据查询记录日志文件分析获得较长时间内频繁查询的数据,并将具有高频繁度的数据进行缓存,获得相比于LIRS算法命中率更高的缓存数据。同时,该方法易于扩展,能够更有效地支持轻量级数据库系统的查询优化。
2.1 Apriori算法
Apriori算法使用频繁项集性质的先验知识,基于逐层搜索迭代方法获得不同维度的频繁项集,即通过较低维频繁项集获得较高维的频繁项集候选集,经过进一步支持度验证获得较高维频繁项集的方法实现频繁项集的挖掘[14-15]。
Apriori算法包括以下两类操作:
1) 连接步:根据已有的频繁k项集集合获得频繁项集的候选集集合Ck+1。将Lk中各项集的项按字典序排序,对于Lk集合中任意两k项集l1、l2,若有l1[1]=l2[1],l1[2]=l2[2],l1[k-1]=l2[k-1],l1[k]≠l2[k],则对l1、l2做连接∞操作,获得k+1项集Ck+1={l1[1],l1[2],…,l1[k-1],l1[k],l2[k]}。重复上述连接操作,得到的k+1项集集合即为频繁k+1项集的候选集集合Ck+1。
2) 剪枝步:筛选Ck+1中不满足频繁要求的项集,获得频繁k+1项集集合Lk+1。根据先验性质——频繁项集的所有非空子集也一定是频繁的,检验连接步操作获得的Ck+1中各项集子集支持度计数是否满足最小支持度计数min_sup,去除Ck+1中不满足先验性质的项集,进而获得频繁k+1项集Lk+1。
Apriori算法在执行过程中,通过重复迭代“连接步—剪枝步”操作进而获得记录集D中所有满足频繁要求的n项集(n≥1)。
2.2 基于Apriori算法的数据缓存策略
本文提出了基于条件属性查询频繁度的数据缓存策略。首先,该策略的核心为条件属性查询频繁度概念的提出及计算方法;其次,在此基础上通过改进现有Apriori算法,提出FD-Apriori算法以获取具有较高查询频繁度的条件属性组;最后,针对计算得到的条件属性数据集,给出缓存情况的分类,以及缓存更新步骤。具体情况如下。
首先,在数据查询过程中,查询属性分为结果属性与条件属性。而近期查询频率较高的条件属性又可分为两种:始终保持高查询频率的条件属性,以及在近期短时间内被大量检索的条件属性。对此,本文针对条件属性定义查询频繁度FD的概念,用于区分频繁查询属性、解释属性的频繁性。
定义1条件属性的查询频繁度:条件属性的频繁性度量,用于区分不同条件属性间查询热度的高低。通过设置查询计数上限以及加权函数的方式强调近期查询对属性频繁性的影响。
对于查询条件属性a,a的查询频繁度FD计算过程为:
① 根据查询日志获得属性a第t天被查询次数。其中t表示日志记录时间距离有效记录起始时间的天数,t越大,表示日志记录时间距离当前时间越近。
② 对Count(t)进行规范化处理。设置近期记录比例qrec区分近期记录与历史记录。对于第t天查询日志Dt,当t≥qrec×T时,Dt所包含记录属于近期记录;当t
(1)
③ 根据加权函数W(t),对Countstd进行加权操作。加权函数W(t)应满足以下条件:
W(t)应为增函数,以突出近期记录的重要性,获得近期短时间内被大量检索的频繁属性。
不同时间t应对应不同权值,以区分处于不同查询层次的属性。

④ 计算属性a的频繁度如式(2)所示:
FD=∑W(t)×Countstd
(2)
其次,在FD(条件属性频繁度)概念的支持下,本文以频繁度替换传统Apriori算法中的支持度,从而获得一种能够准确筛选出频繁查询条件属性的改进Apriori算法—FD-Apriori。
FD-Apriori的伪码,如算法1所示。
FD-Apriori算法使用一种逐层搜索的迭代方法,利用“K-1项集”用于搜索“K项集”。首先,找出根据条件查询频繁度的频繁“1项集”集合,该集合记作A1,如伪码中第1)步至第4)步。A1用于找频繁“2项集”的集合A2,而A2用于找A3。通过迭代的方式找到“K项集”。每个Ak都需要对整个日志数据库进行一次扫描。
算法的核心思想是伪码中的第7)步(连接步)和第11)步(剪枝步)。其中,连接步是自连接,原则是保证前k-2项相同,并按照字典顺序连接;在剪枝步中保证任一频繁项集的所有非空子集也必须是频繁的。即某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从Ck中删除。
该算法简单直观的描述就是为了根据定义的FD(条件属性查询频繁度)发现频繁项集。过程为扫描、计数、比较、产生频繁项集、连接、剪枝、产生候选项集的重复迭代处理,直到不能发现更大的频集。
算法1FD-Apriori算法
输入:查询日志D(D=∑Di,Di表示第i天查询日志) ,最小频繁度minfd
输出:A-D中各长度的频繁查询条件属性组集
方法:
1) k=1
2) A1=φ
3) if(a.fd in D≥minfd){
4) add a into A1
//检索查询日志,获得长度为1的频繁查询条件属性组集
5) }
6) while(true){
7) Ck+2=Ak∞Ak+1
//连接步操作,获得K+1长度的频繁查询条件属性组候
//选集
8) Ak+2=φ
9) for(ak+1: Ak+1){
10) if(ak+1.fd in D ≥minfd)
11) add ak+1into Ak+1
//剪枝步操作,去除候选集中非频繁的属性组
12) }
13) }
14) if(ak+1≠φ)
15) k++
16) else
17) break
//当不存在更大长度的频繁查询条件属性组集时,结束
//循环
18) return A=∪kAk
在NoSQL数据库中,数据存储方式多样,如以键值对方式存储数据的Cassandra、以列族存储的HBase等。接下来仅以数据块的概念泛指NoSQL型数据库中数据存储的最小单元进行讨论。
在集群存储节点上,第一次运行FD-Apriori算法获得在当前存储节点中频繁被检索的数据块,第二次在频繁数据块上运行该算法,获得在数据查询中查询频率较高的条件属性组集合。在FD-Apriori算法返回的属性组集合中包含不同长度的条件属性集,根据系统实际需要将不同长度的满足频繁定义的条件属性组对应数据缓存至内存中,并针对查询较频繁的结果属性建立B+树索引以处理缓存中属性部分命中的情况。当用户进行查询操作时,若查询的数据块在内存中,分布式系统不再从磁盘中读取查询数据,而是直接在内存中进行查询并返回查询结果,可在一定程度上减少内存与磁盘间的数据交换次数,节省查询开销。
在应用缓存策略的节点上,对于一次实际数据查询,如图1所示的3种不同命中情况。
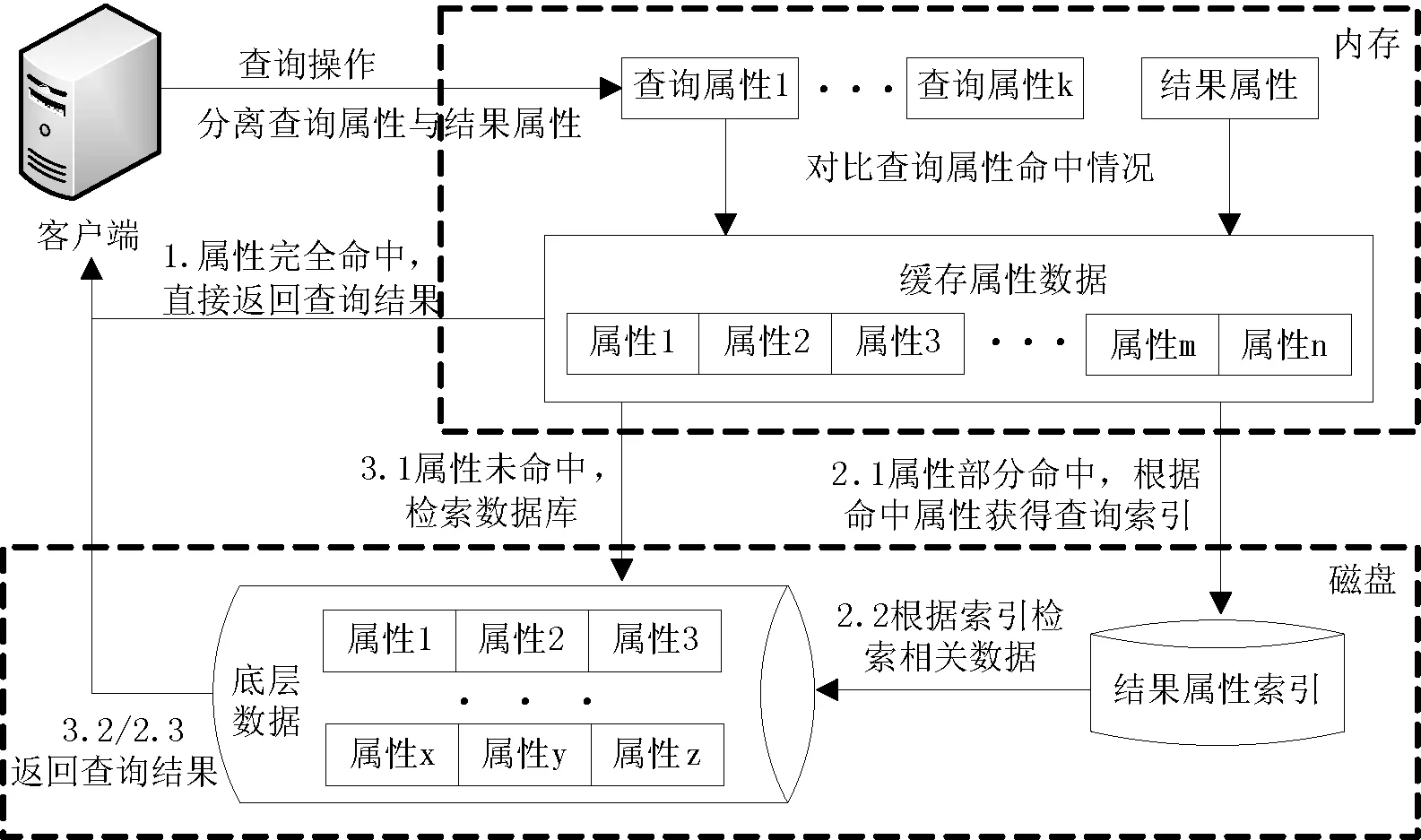
图1 查询属性不同命中情况处理流程
(1) 未命中:查询中的条件属性不在内存缓存中。此时需要重新从磁盘中加载数据块数据进行查询操作,查询速度较慢。
(2) 部分命中:查询中的条件属性仅有一部分在内存缓存中。由于查询结果属性个数较少且固定,可通过建立索引的方式提高查询效率。此时可根据内存中已有的属性数据对数据库中的记录进行筛选,减少需进一步在数据库中检索的数据量。同时,提供相应结果属性的索引值,加速数据的检索。这种情况下虽仍需从磁盘中读取数据,但因索引的建立以及查询规模较小,查询速度相比于未命中情况仍比较理想。
(3) 完全命中:查询中的条件属性全部在内存缓存中。这是最理想的情况,可直接返回查询结果。
对于同样的查询集,上述3种命中情况的出现取决于内存中的属性缓存方式。当以属性组的形式缓存数据时,属性组的长度越大,查询完全命中的可能性也就越大;但同时,部分命中情况下被筛选掉的无关数据量可能会相应减少。通常情况下,较长属性组适合查询环境中存在某一类极高频查询的情况,中等长度属性组则更适合存在多类频率较高且接近的查询的查询环境。本文将在实验模拟章节测试不同长度属性组对查询结果的影响。
由于本文采取的是一种静态的数据缓存策略,缓存数据具有固定的生命周期,相比于LIRS类数据缓存算法,需定期更新内存中的缓存数据。由于在计算条件属性的查询频繁度过程中,以天为单位进行查询次数计数,故应以天为更新频率进行缓存数据的更新。缓存更新操作应在一天中节点访问负荷最小的时间段进行。缓存更新共分为6步:
(1) 禁用内存缓存数据,出现数据查询请求时直接检索存储底层的数据块,此时缓存属性命中率为0。
(2) 根据近T天查询日志运行FD-Apriori算法,获得频繁查询数据块与频繁查询属性组集。
(3) 对频繁查询数据块加锁,限制数据块内数据的修改操作,保证缓存更新期间缓存数据与底层数据的一致性。
(4) 对比待缓存频繁查询数据与内存中已有缓存数据,保留相同的缓存数据,对于不同的缓存数据,清除旧频繁数据,加载新频繁数据。
(5) 将频繁查询数据块解锁,恢复数据块内数据的修改权限。
(6) 更新缓存数据索引结构,启用内存缓存数据。
3 实现及仿真实验
3.1 缓存策略在HBase上的实现
基于FD-Apriori算法的频繁数据缓存策略具有易扩展性,能够面向轻量级数据库应用给出快速解决方案。本文将针对HBase数据设计并实现上述数据缓存策略的应用范例。HBase是一个面向列的NoSQL数据库,其作为Hadoop 项目的一部分,运行于HDFS文件系统之上[16-17]。
在数据读取方面,HBase采取按列存储策略,相比于按行存储策略,减少了数据读取过程中冗余数据的读取,提高了数据读取效率,使数据检索更加迅速有效。在存储方面,HBase将规模较大的数据表分割成若干区域(region),每个区域顺序存储数据表中一定数量的记录,将多个相关区域合并操作,即可获得完整的表信息。HBase数据表分割过程,如图2所示,其中Table表示现有数据表,Region表示分割过程产生的数据区域。
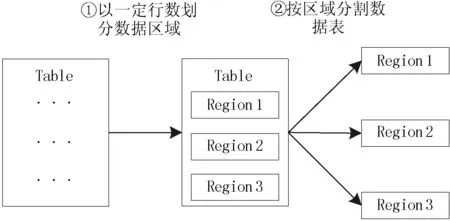
图2 HBase分割数据表过程
HBase中的区域对应上文提到的数据块概念。基于本文的数据缓存策略,根据数据查询情况筛选出查询频繁的数据表区域,将频繁度最高的若干区域中的频繁属性数据缓存至内存缓冲区中。当该区域中的数据被访问时,根据查询属性与内存中缓存属性的命中情况,进行不同的数据查询操作。在HBase环境下,改进后的数据查询过程,如图3所示。
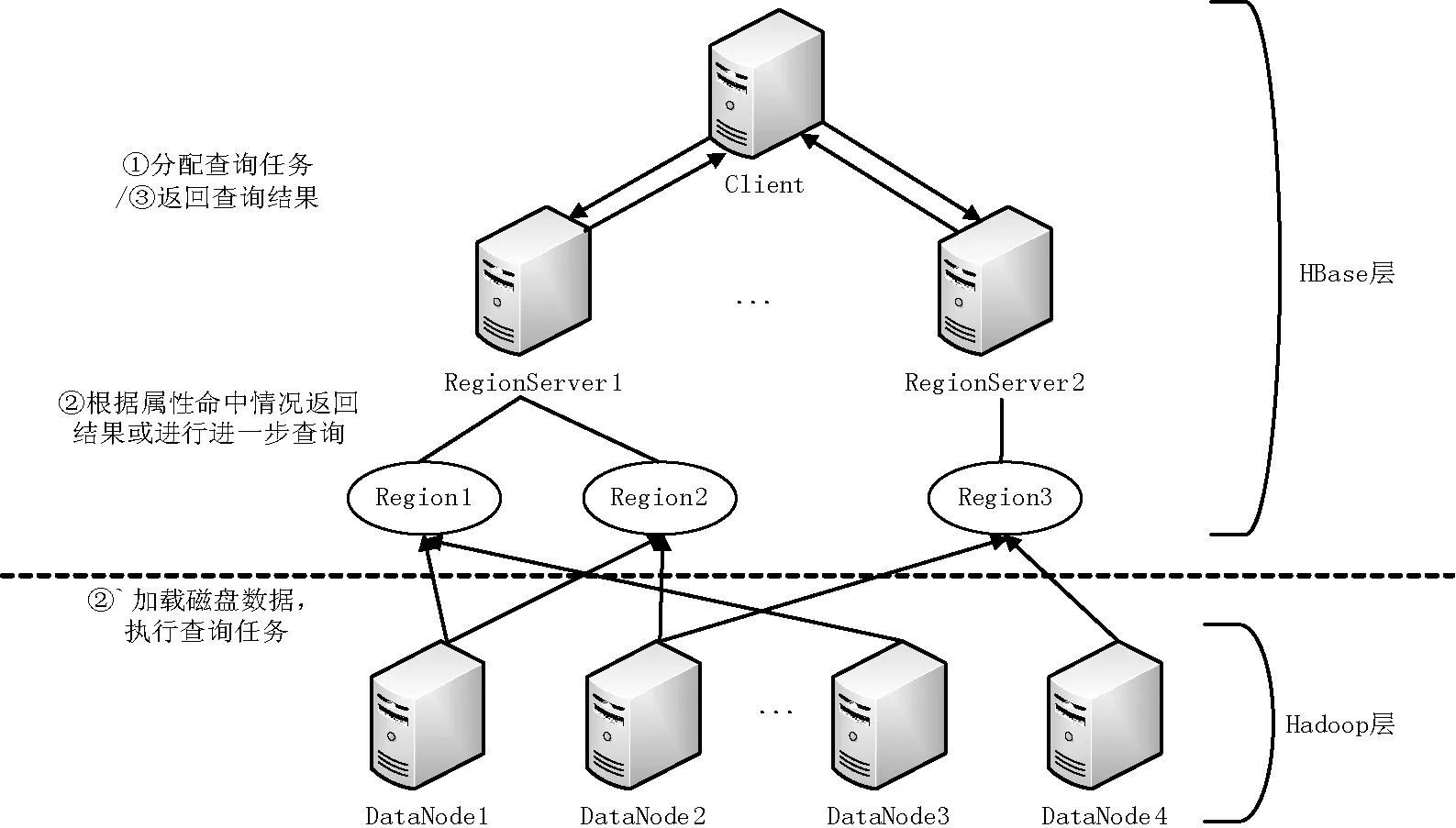
图3 HBase环境下改进的数据查询过程
由于HBase采取按列存储策略存储表数据,对于内存中的频繁属性数据,可使用列组的形式进行缓存。在列组结构中,数据以按行存储的形式进行组织,虽然在缓存建立、更新过程中会带来额外的压力。但列组结构能够加快内存中属性间的匹配速度,减少部分命中情况下记录筛选的时间开销,提高查询效率。
3.2 实验设计
为验证基于FD-Apriori算法的频繁数据缓存策略在数据库查询效率方面表现,本文采用Hadoop-HBase搭建分布式实验环境,进而考察算法的优化效果。
在实验数据选择方面,针对本文研究背景提出的轻量级分布式数据库查询应用,查询业务采用以银行个人储蓄存取、查询业务数据,以及小额贷款查询、处理业务数据。由于银行真实数据的获取涉及到一定的隐私保护问题,因此本文根据少部分基础业务数据,按照属性约束随机生成大量数据,以此作为真实场景模拟查询数据以及相应的用户查询行为。
实验构建了8节点的小型Hadoop集群环境,CPU为i7处理器,内存为16 GB。模拟数据方面在40 MB基础业务数据的基础上,通过属性规则约束随机生成数据量为100 GB的模拟数据,令T=7,将模拟数据分成7等份,以模拟不同时间的查询日志。在应用本文缓存策略前,一条正常SQL Select语句的查询时间平均约为1 500 ms。
通过统计用户查询中各属性的查询情况,可以获得不同长度的满足频繁定义的条件属性组合。在此基础上,分别考察(1)利用LIRS算法的缓存策略的平均查询时间。以及在缓存相同个数属性的前提下,考察(2)基于FD-Apriori算法的频繁数据单一属性缓存平均查询时间。(3)基于FD-Apriori算法的频繁数据两属性组缓存平均查询时间。(4)基于FD-Apriori算法的频繁数据三属性组缓存平均查询时间,从而对比检验频繁数据缓存的执行情况以及多组属性缓存策略的变化。除此之外,还将设计实验从频繁数据的命中率角度检验FD-Apriori算法不同属性组的结果。
3.3 实验分析结果
在不同算法以及不同缓存属性组方式下,平均查询效率如图4所示,查询命中情况,如图5所示。
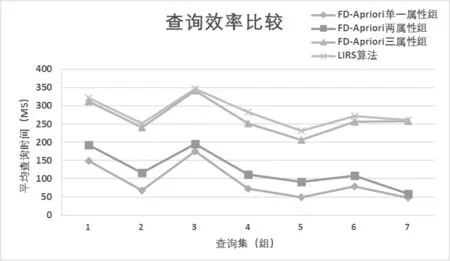
图4 不同缓存方式查询效率比较
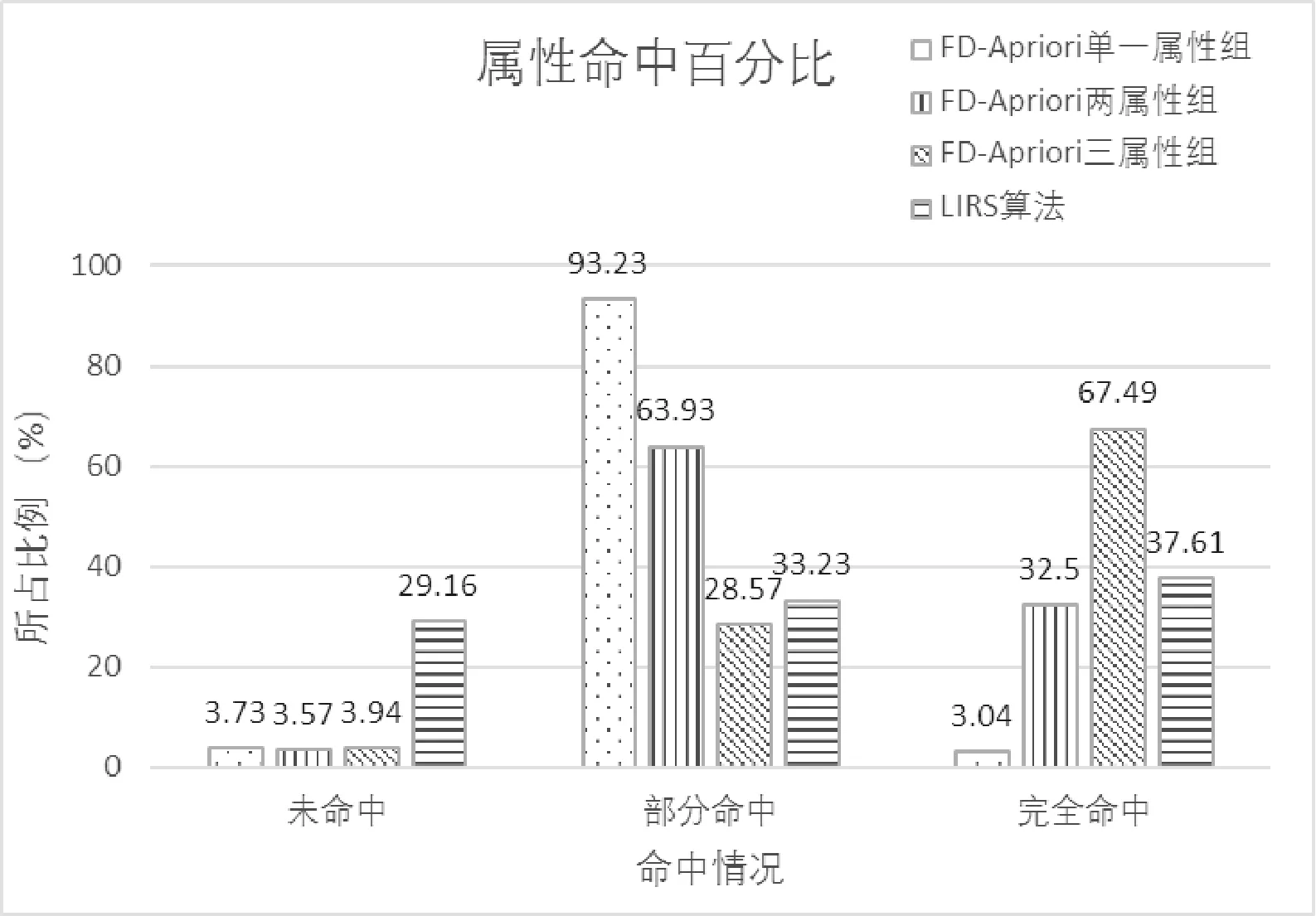
图5 不同缓存方式属性命中情况比较
由图4可知,本文的数据缓存策略在频繁区域中能够明显提高数据查询效率,而对于其他区域中的数据查询,由于未做任何处理,故不会影响其上的查询操作。在图4中可以发现,LIRS算法缓存策略执行效率低于FD-Apriori算法,当单一属性时效率差异并不明显,而当频繁属性组增多的时候,FD-Apriori算法的频繁数据特征将使得目标效率变化较大。从执行效率角度缓存两、三属性组相比单一属性具有更高的查询效率。这是由于在实际查询过程中,单一属性的条件查询频率较低,缓存完全命中率不理想,相比于多属性查询,单一属性缓存不能很好地去除不相关记录,筛选出的记录规模较大,为之后在数据库中的索引检验工作带来了巨大的时间开销。
同时,由图5可以发现,LIRS算法由于完全没有考虑到频繁属性因素,因此对于命中对比情况的比较较为平均,基本上不能够支持以数据频繁度为目标的数据缓存策略。在FD-Apriori算法的支持下,随着频繁属性的数量增多,命中情况有所提高。
此外,尽管两属性组缓存相比三属性组缓存完全命中率相差较多,但其部分命中率高达63.93%。对于属性组中属性个数处于中间规模的缓存。尽管牺牲了一部分缓存完全命中率,但该类缓存能够更出色地完成中间记录的精简工作,缩减内存中因部分属性命中而产生的中间结果集,并根据结果属性索引快速定位数据,进而减轻数据库的检索压力,取得了更高的查询效率。图4中两属性组缓存平均查询效率略高于三属性组缓存正属于这种情况。
4 结 语
本文提出了数据查询过程中查询频繁度的概念以及基于Apriori算法的频繁数据缓存策略。实验表明,本文的数据缓存策略能够明显提高频繁区域中数据的查询效率,而缓存数据中的属性个数以及属性分组情况则需要根据实际需求做出不同的调整。在进一步的工作中,本研究将对内存缓存中的存储过程进行优化,减少稀疏数据结构对有限空间的浪费。
[1] Labrinidis A,Jagadish H V.Challenges and opportunities with big data[C]//Proceedings of the VLDB 2012.Istanbul,Turkey,2012:2032-2033.
[2] Bizer C,Boncz P,Brodie M L,et al.The meaningful use of big data:four perspectives-four challenges[J].Acm Sigmod Record,2011,40(4):56-60.
[3] Han J,Haihong E,Le G,et al.Survey on NoSQL database[C]//International Conference on Pervasive Computing and Applications.IEEE,2011:363-366.
[4] 申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013,24(8):1786-1803.
[5] Memcached Team.Memcached:A distributed memory object caching system[OL].[2015].http://memcached. org/.
[6] Chang F,Dean J,Ghemawat S,et al.Bigtable:a distributed storage system for structured data[J].Acm Transactions on Computer Systems,2008,26(2):205-218.
[7] Ananthanarayanan G,Ghodsi A,Wang A,et al.PACMan:coordinated memory caching for parallel jobs[C]//Usenix Conference on Networked Systems Design and Implementation.USENIX Association,2012:20-20.
[8] GridGain Team.Gridgain:In-memory computing platform[OL].[2015].http://gridgain.com/.
[9] 许祥,罗宇.一种SAN环境下集群文件系统的元数据缓存研究[J].计算机研究与发展,2012,49(S1):240-244.
[10] 周功业,吴伟杰,陈进才.一种基于对象存储系统的元数据缓存实现方法[J].计算机科学,2007,34(10):146-148.
[11] 秦秀磊,张文博,魏峻,等.云计算环境下分布式缓存技术的现状与挑战[J].软件学报,2013,24(1):50-66.
[12] 刘祖云,胡进德.分布式共享存储研究[J].成都大学学报(自然科学版),2008,27(1):45-47.
[13] 李文中,陈道蓄,陆桑璐.分布式缓存系统中一种优化缓存部署的图算法[J].软件学报,2010,21(7):1524-1535.
[14] Agrawal R,Imielinski T,Swami A N.Mining Association Rules Between Sets of Items in Large Databases[C]//Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data,1993:207-216.
[15] Agrawal R,Srikant R.Fast alg orithms for mining asso-ciation rules[C]//Proceedings of the 20th VLDB Conference Santiago,Chile,1994:487-499.
[16] HBase:bigtablelike structured storage for hadoop hdfs[EB/OL].2010.http://Hadoop.apache.org/hbase/.
[17] Fan Chang,Jeffrey Dean,Sanjay Chemawat,et al.Bigtable:a distributed storage system for structured data[C]//Proceedings of 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI’06),Seattle,WA,USA:USENIX Association,2006:205-218.
FREQUENTDATACACHINGSTRATEGIESINDISTRIBUTEDENVIRONMENT
Yi Su1Yin Huiwen1Zhang Yichuan2Zhang Li2
1(InnovationandEntrepreneurshipCollege,LiaoningUniversity,Shenyang110036,Liaoning,China)2(CollegeofSoftware,NortheasternUniversity,Shenyang110819,Liaoning,China)
Using distributed caching technology can provide high performance and high availability data query in large data environment. The frequent data caching strategies for lightweight applications have the advantages of high efficiency and easy extension. Especially, it is beneficial to improve the query optimization for lightweight distributed database system. Therefore, this research studies the data caching strategies for the recent frequent query data by analyzing the characteristics of user behavior and user query. It can predict the high hit rate of the cache data and improve the efficiency of data query. Firstly, the definition of the frequency of the query was analyzed and given. Secondly, we refined the operation of the user's query according to the influence of the time factor for the cache data. And we dealt with the different cache hits in query process through the data query frequency. Then, we integrated the cached data between nodes. Finally, the experimental results showed that the data caching strategy has a high data hit rate. It also can improve the efficiency of data query. According to the actual needs, the implementation can use different combination of cache attributes, and possesses a good scalability.
Data caching strategy Query frequency Cluster environment Distributed system Big data
2016-11-23。国家自然科学基金项目(61202088);中央高校基本科研业务费专项资金项目(51704003);辽宁省档案局科技项目(L-2017-X-24);辽宁省高校健康管理协同创新中心资助项目。易俗,实验师,主研领域:云计算,分布式计算。殷慧文,讲师。张一川,讲师。张莉,讲师。
TP3
A
10.3969/j.issn.1000-386x.2017.08.003
