基于模糊C均值聚类算法的蒙医方剂类别划分方法研究
2017-08-07张春生图雅李艳
张春生,包•图雅,李艳
内蒙古民族大学计算机科学与技术学院,内蒙古 通辽 028043
基于模糊C均值聚类算法的蒙医方剂类别划分方法研究
张春生,包•图雅,李艳
内蒙古民族大学计算机科学与技术学院,内蒙古 通辽 028043
目的 采用模糊 C 均值聚类(FCM)和硬 C 均值聚类(HCM)算法对蒙医方剂进行类别划分,探讨 2 种聚类算法的合理性。方法 选取《传统蒙药与方剂》中治疗赫依病的 27 首蒙医方剂,进行数据预处理。采用 MS Visual Studio 2010 平台,使用 C#语言进行开发,分别运用 Window From、WPF 技术实现汉、蒙文版本。采用 FCM 和 HCM 算法按 3、4、5、6 个类对数据进行聚类分析。结果 所有相异数不为零的分类都存在包含现象,2种聚类算法得到的分类结果中药物不存在交叉。与HCM算法比较,FCM 算法的分类结果中各类样本数量差较小,即分类较均匀。结论 2 种算法均正确合理,其中 FCM 算法具有更好的聚类效果,可广泛应用于蒙医方剂分析,为新药研制提供数据支持。
模糊C均值聚类;硬C均值聚类;蒙医;方剂;聚类;配伍
数据挖掘技术自产生以来,无论在算法理论还是应用研究方面均取得了丰富的研究成果,聚类分析作为数据挖掘的一种重要算法,在数据挖掘应用中起到了关键的作用。在中医方剂理论研究方面,它可按各项指标要求对方剂信息进行聚类分析,从而揭示其配伍规律,为新药研究提供数据支持。
目前,已有研究采用聚类分析方法分析中医方剂配伍规律[1-4],但在蒙医方剂聚类分析方面鲜有报道。目前该领域研究多采用一般的统计软件作为分析工具,尚未建立专门的数据库及开发通用程序,缺乏系统性、通用型、灵活性。
本研究在前期研究[5-6]基础上开发了一套通用的蒙医方剂数据挖掘系统。该系统集成了模糊C均值聚类(FCM)算法和硬 C 均值聚类(HCM)算法,可进行结果对比,同时HCM算法可为FCM算法提供初始中点服务。用户可根据需要选择合适的聚类算法,揭示蒙医方剂配伍规律,为蒙药新药研制提供参考。
1 模糊 C 均值聚类算法
FCM 算法即众所周知的 ISODATA 模糊聚类算法,是通过隶属度即隶属于某类程度实现聚类的一种算法,1973 年由 Bezdek 提出,是一种基于划分的聚类算法。它的主旨是使被划分到同一簇的对象间相似度最大,而不同簇间相似度最小。该算法是在 HCM算法硬性数据划分的基础上改进的一种柔性模糊划分。核心思想为把 n 个一维向量 xi(i=1,2,…,n)分为C个模糊组,并求每组的聚类中心,使非相似性指标的价值函数达到最小。FCM 算法与 HCM 算法的主要区别在于其类的划分原则是模糊的,每个数据点属于哪一个类并不明确,而是用[0,1]区间的一个模糊值来确定属于各个类的程度来表示。隶属度是经过归一化的,一个数据集的隶属度总和等于1:

FCM 算法的价值函数/目标函数一般化形式为:

其中 uij属[0,1];ci为模糊组 i 的聚类中心,为第 i个聚类中心与第 j个数据点间的欧几里德距离;且是一个加权指数。
构造如下新目标函数,构建最小值的必要条件:

这里 λj(j=1,2,…,n)是公式①的 n 个约束式的拉格朗日乘子。对所有输入参量求导,使公式②达到最小的必要条件为公式④和公式⑤:
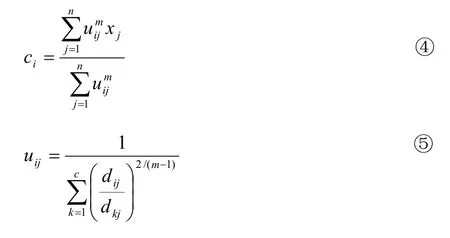
FCM 算法分析步骤:步骤 1:构建满足公式①的随机隶属度矩阵 U。步骤 2:计算每个类的中心点。步骤 3:计算价值函数。若价值函数小于给定阈值或与上次相比价值函数的变化量小于给定阈值则算法结束。步骤 4:重新生成隶属度矩阵 U,回到步骤 2。
2 数据预处理
每首蒙医方剂中包含的药物数量和种类不同,而聚类分析要求所有方剂构成一个矩阵,因此模糊聚类分析第一步是对方剂数据进行预处理操作。
设原始方剂事务集为 T={t1,t2,…,tn},ti的属性(药物组成)集为 Ui={ri1,ri2,…,rik},对应的药物重量集为 Wi={wi1,wi2,…,wik},预处理后事务的属性集应包含所有的 Ui中的属性,即预处理后的属性集为 U={r1,r2,…,rm}为所有 Ui的并集。最终形成二维矩阵 D[n,m],n 为事务数,m 为 U 的属性数。算法描述如下。
U=null
for i=1 to n //遍历所有事务(方剂)
scan r Ui
//遍历当前方剂中各个属性(药物)
if r not in U
//若当前方剂中属性 r 不在 U 中
U=U ∪ r; //U 并入 r
endif
endscan
endfor
D[n,m]=0 //二维矩阵初始化为 0
for i=1 to n //遍历所有事务(方剂)for j=1 to m //遍历 U 中的每个属性
if rjin Ui
//若 U 中的属性 rj在当前方剂的属性中
D[i,j]=wij;
//二维矩阵对应位置填对应的重量
endif
endscan
endfor
3 聚类分析程序设计
将 MS Visual Studio 2010 作为开发平台,采用 C#语言进行开发,同时提供汉、蒙文2种版本,分别采用 Window From、WPF 技术实现。该系统可提供 FCM、HCM 2 种聚类算法,可进行聚类结果比较,同时 HCM算法可为 FCM 算法提供初始中心点服务。
FCM 算法设置了灵活的初始中心点和反模糊方法。初始中心点生成算法包括随机中心点方法、随机隶属度矩阵算法,由HCM算法生成。反模糊方法包括最大隶属度方法、中位数法、加权平均法。灵活多样的生成算法为最终的聚类结果提供了保障。
4 案例实验
本研究以《传统蒙药与方剂》[7]中治疗“赫依病”的 27首蒙医方剂为例,讨论方剂的聚类分析方法,27 首方剂共涉及药物 87 味。
对纳入方剂进行数据预处理,得到一个 27×87的二维矩阵,可用于 FCM 算法聚类。由于各方剂间药物组成相差较大,采用随机中心点方法或随机隶属度矩阵算法产生的初始中心点,对应的聚类结果并不理想。因此,本研究的初始中心点采用HCM算法生成。应用程序界面见图1。
同时采用 FCM 和 HCM 2 种算法对聚类数为 3、4、5、6 的方剂分布情况进行分析,聚类分析结果见表 1~表 4,2 种算法聚类结果的差异情况见表 5~表8。

图 1 蒙医方剂数据挖掘系统聚类算法应用程序界面

表 1 27 首治疗赫依病蒙医方剂聚类数为 3 时分布情况
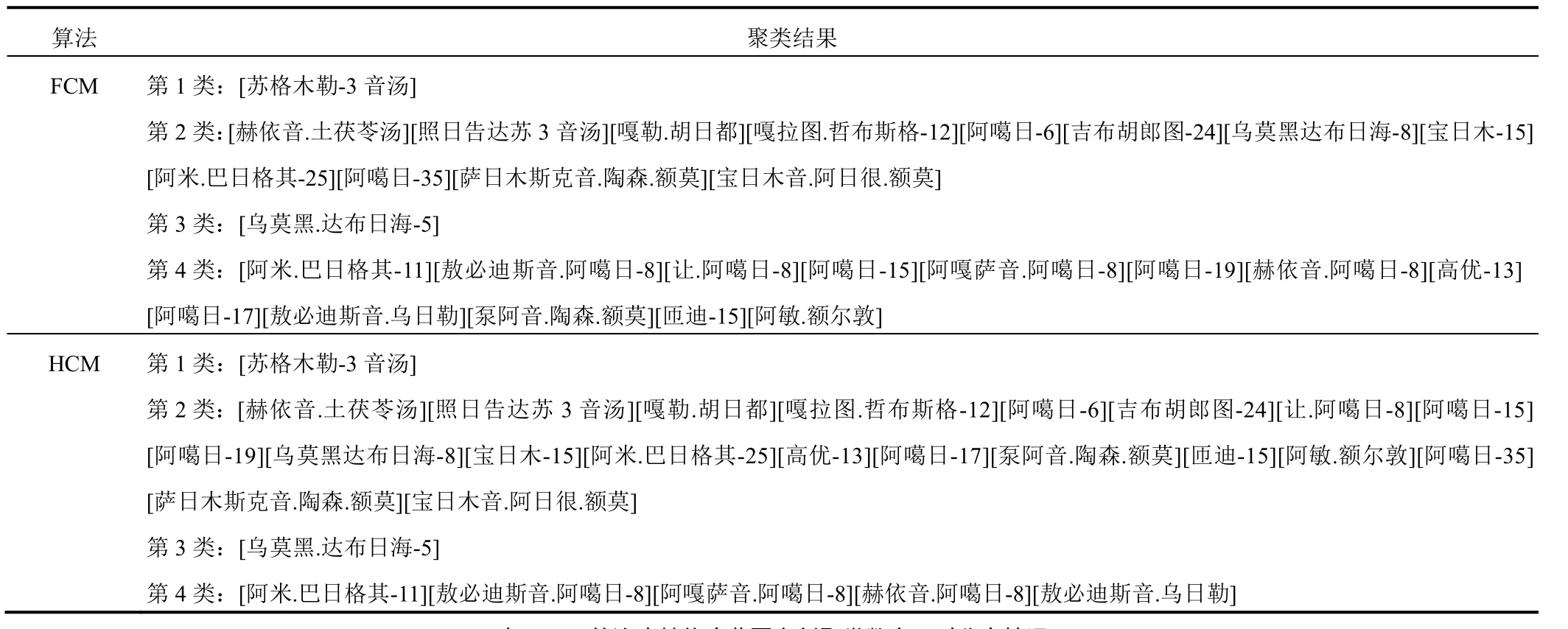
表 2 27 首治疗赫依病蒙医方剂聚类数为 4 时分布情况
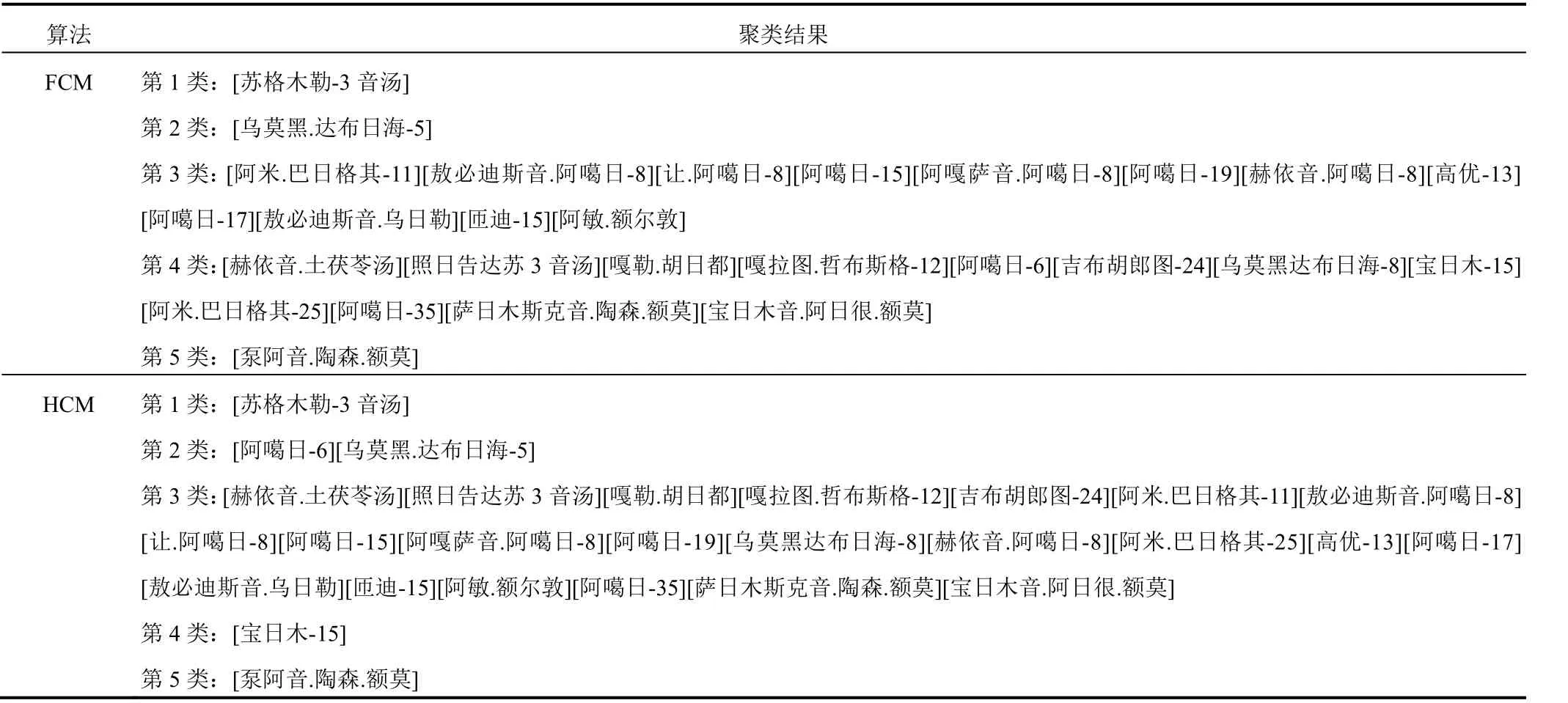
表 3 27 首治疗赫依病蒙医方剂聚类数为 5 时分布情况
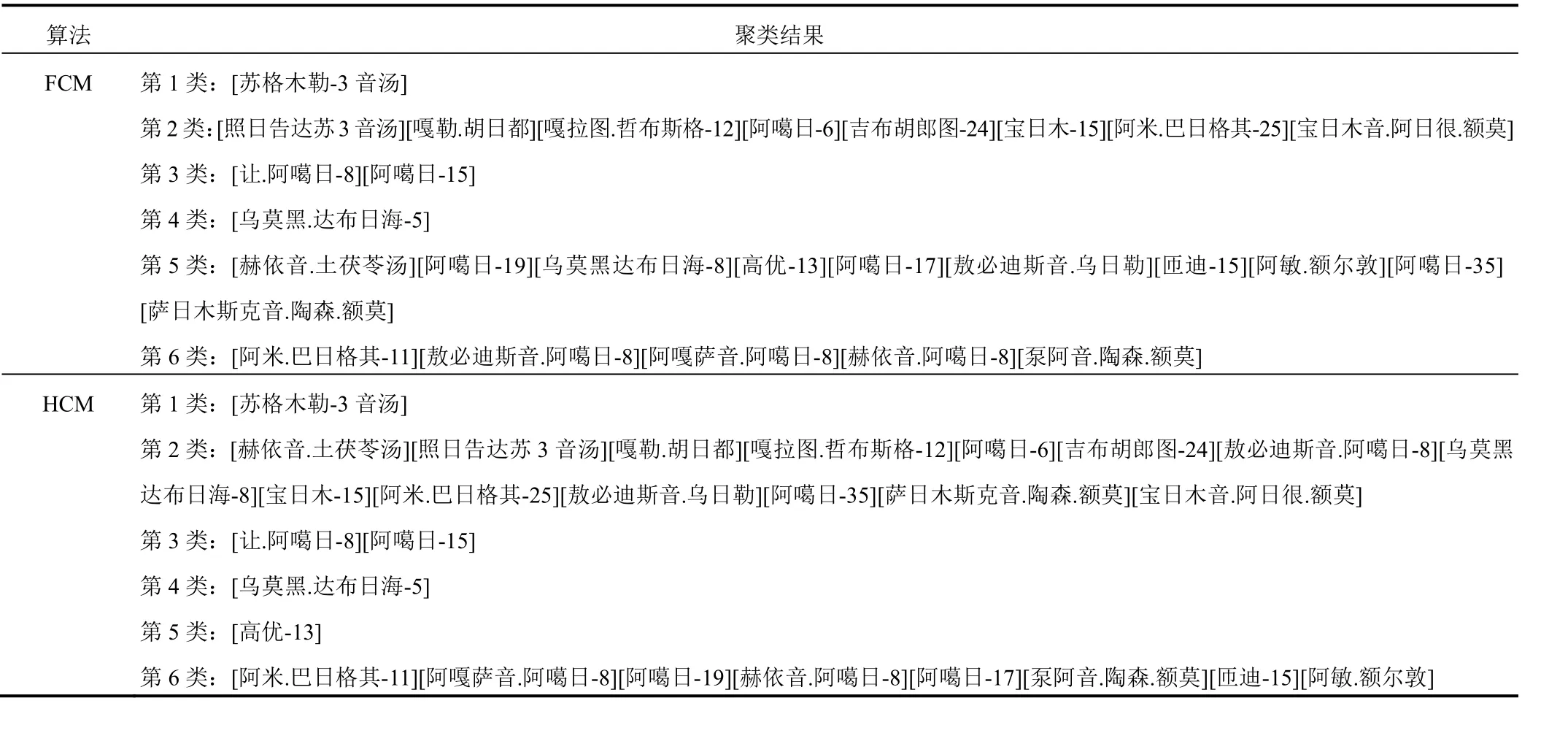
表 4 27 首治疗赫依病蒙医方剂聚类数为 6 时分布情况

表 5 聚类数为 3 时不同算法聚类结果比较
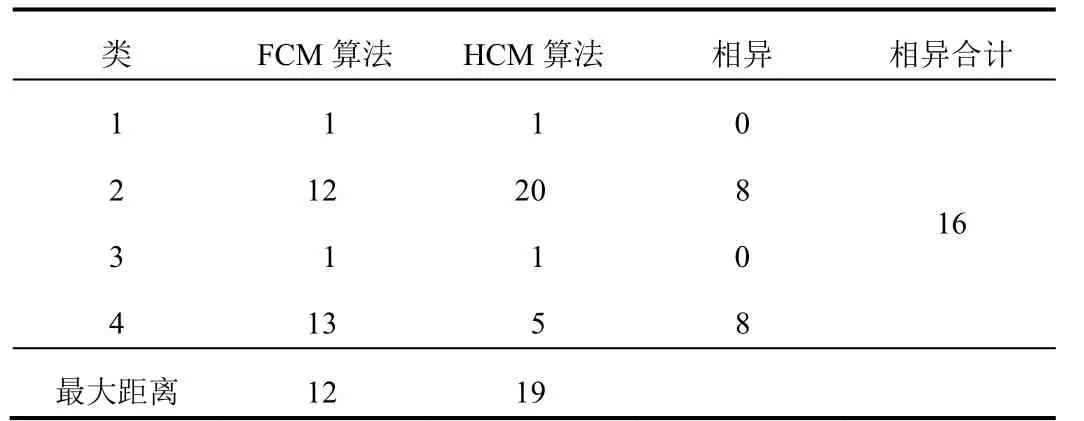
表 6 聚类数为 4 时不同算法聚类结果比较

表 7 聚类数为 5 时不同算法聚类结果比较

表 8 聚类数为 6 时不同算法聚类结果比较
聚类结果表明,当分类数为3类和4类时效果较好,其中“苏格木勒-3 音汤”和“乌莫黑.达布日海-5”为稳定的独体类,说明这2种方剂严格不同于其他方剂;另外,所有相异数不为零的分类都存在包含现象,2种聚类算法得到的分类结果中药物不存在交叉,即某一子集要么在A类,要么在B类,是聚类算法不同造成的,反映了2种聚类算法的合理性;从分4类的结果来看,除“苏格木勒-3 音汤”和“乌莫黑.达布日海-5”2 个独体类外,另 2 个类的相异药物数均为 8,由于相互包含关系的存在,实际上就是这 8个相异药物归属哪一类的问题。
与 HCM 算法比较,FCM 算法在类的划分上引入隶属度概念,从理论上 FCM 算法的分类结果更理想。本研究结果表明,与 HCM 算法比较,FCM 算法聚类结果中各类样本数量差较小,即分类较均匀;本课题组蒙医方剂学专家分析同样认为 FCM 算法分类结果更合理。
6 小结
本研究在蒙医方剂数据挖掘平台上实现了对蒙医方剂的 FCM 和 HCM 聚类分析算法,提供了 FCM算法较灵活的生成策略。结果表明,2种算法均正确合理,其中 FCM 算法具有更好的聚类效果,可广泛应用于蒙医方剂分析,为新药研制提供数据支持。
传统医药学具有突出的民族性、地域性和历史传承性。中医药学与蒙医药学在哲学思想、药性理论及其在各自医药理论指导下的临床用药等方面,均有相通之处,但又各成体系、各具特色。目前,基于数据挖掘的中医方剂研究已较成熟,但针对蒙医方剂的研究却鲜有报道。本研究对方剂进行了简单分类以验证算法合理性,在此基础上可进一步对各类中的药物频次、功能、主治等进行分析。该方法可为保护蒙医药文化遗产、蒙医药研究提供新途径,也可为蒙药研发提供参考,具有一定的社会效益和经济价值。
[1] 刘树春,刘洋,张晓玮,等.基于方剂数据的补肾常用中药及其配伍规律的挖掘分析[J].中国实验方剂学杂志,2015,21(20):208-212.
[2] 郭栋,童元元,黄生权,等.基于数据挖掘的枸杞研究热点分析[J].中国中医药信息杂志,2016,23(9):48-51.
[3] 宋京美,吴嘉瑞,姜迪.基于数据挖掘的国家级名老中医治疗肿瘤用药规律研究[J].中国中医药信息杂志,2015,22(6):50-53.
[4] 徐晓晶,徐丽敏,沈春锋,等.孟河医派徐迪华治疗咳嗽经验用药分析研究[J].中国中药杂志,2015,40(21):4301-4305.
[5] 张春生,图雅,翁慧,等.基于关联规则的条件函数依赖发现及数据修复[J].计算机应用研究,2016,33(2):384-387.
[6] ZHANG C S, TU Y. The design and real ization of mongolian medicine prescription data mining system[C]//2016 3rd International Conference on Information Science and Cont rol Engineering,2016.
[7] 奥•乌力吉,布和巴特尔.传统蒙药与方剂[M].赤峰:内蒙古科学技术出版社,2013:12.
Study on M ongolian M edicine Prescription Classification Method Based on Fuzzy C-means Algorithm
ZHANG Chun-sheng, BAO Tu-ya, LI Yan (College of Computer Science and Technology, Inner Mongolia University for Nationalities, Tongliao 028043, China)
Objective To classify Mongolian medicine prescription by using fuzzy c-means algorithm (FCM) and hard c-means algorithm (HCM); To explore the rationality of two kinds of clustering algorithm. Methods 27 Mongolian medicine prescriptions for treating Heiyi disease from Chuan Tong Meng Yao Yu Fang Ji were set as experimental data, and the data were preprocessed first. MS Visual Studio 2010 platform was used, and C# language was used for research and development. Chinese version and Mogolian version were implemented With Window From and WPF technology, respectively. The medicine prescriptions were classified into 3, 4, 5, and 6 types by using FCM and HCM. Results All categorization With zero classification showed the existence of inclusion phenomena. The medicine in the classification results obtained by the two kinds of clustering algorithm did not exist cross. FCM could produce clustering results With smaller quantity difference and the more uniform classification compared With HCM. Conclusion The two algorithms are correct and reasonable, in which FCM algorithm has better clustering effect, and can be w idely used in Mongolian prescription analysis, With a purpose to provide data supports for the research and development of new medicine.
fuzzy c-means algorithm; hard c-means algorithm; Mongolian medicine; prescription; clustering; compatibility
10.3969/j.issn.1005-5304.2017.08.022
R2-05;R291.2
A
1005-5304(2017)08-0099-05
2016-08-31)
(
2016-09-09;编辑:向宇雁)
国家自然科学基金(81460656)
包•图雅,E-mai l:baotuya1978@163.com
