针灸古籍经验推荐平台构建方法及功能展示
2017-08-07陈楚云李伟林洪佳明李丽霞张去飞谢丽琴
陈楚云,李伟林,洪佳明,李丽霞,张去飞,谢丽琴
1.广州市中医医院针灸科,广东 广州 510130;2.中山大学新华学院信息与网络中心,广东 广州 510080;3.广州中医药大学医学信息工程学院,广东 广州 510006
针灸古籍经验推荐平台构建方法及功能展示
陈楚云1,李伟林2,洪佳明3,李丽霞1,张去飞1,谢丽琴1
1.广州市中医医院针灸科,广东 广州 510130;2.中山大学新华学院信息与网络中心,广东 广州 510080;3.广州中医药大学医学信息工程学院,广东 广州 510006
本文分析了针灸古籍数据的特点,提出根据针灸学诊治疾病的模式,采用多种数据挖掘技术提取、整合、展示散布于古籍数据中的理、法、经、穴、术知识,构建一个通过 B/S 方式提供给用户使用的针灸古籍数据库平台;阐述了针灸古籍经验平台的框架、模块的功能、实现各功能的方法,对以“中风”为检索词的检索结果作了演示,并总结归纳构建针灸古籍经验推荐平台的体会及该平台在针灸古籍数据开发中的优势。
数据挖掘技术;针灸古籍;软件开发
针灸疗效取决于中医独特的理论体系,其诊疗过程离不开传统的针灸经络理论。文献是记录历代针灸基础理论和临床经验的主要载体,是总结和继承前人学术思想的重要资料。针灸古籍是前人对针灸经络、腧穴、刺灸法等理论和临床经验的总结,据不完全统计,现存针灸专著约 180 种[1]。但传统的存在形式和使用方式已不能满足现代社会对信息获取的需求,且面对如此浩瀚的文献信息,人工获取非常有限。如何将针灸古籍蕴含的宝贵经验开发成为可供现代人随时获取的方式,实现针灸古籍有效、快捷地为临床、科研、教学服务,扩大针灸的影响成为迫在眉睫的问题。
数据挖掘技术是从大量、不完全、有噪声、模糊、随机的数据中提取隐含、无先验、对决策有用的知识,用专门算法从数据库中抽取模式,然后通过系统解释和评价模块,将模式转换成用户可以理解的知识。由于古代针灸文献数据量大,记录方式简单、术语不规范、标准不统一,造成文献中知识、经验具有明显模糊性与不确定性。用普通的数据获取方法,无法实现对复杂的模糊性与不确定性针灸古籍数据进行关联分析。为此,笔者通过开发一个按照针灸学诊治疾病的模式,以针灸古籍为分析对象,采用数据挖掘技术提取、整合、展示散布于古籍数据中的理、法、经、穴、术知识,连接现代针灸与古籍作用的平台,以供用户检索使用。兹介绍如下。
1 平台架构
该平台基于 SSH(Struts+Spring+Hibernate)架构,由 Struts 实现表示层、Spring 实现业务逻辑层、Hibernate 实现数据持久层,数据库用 Oracle10g,开发语言 JAVA,运行环境为 Windows2008 R2 Server+Tomcat6.0+JDK1.6,通过 B/S(Browser/Server,浏览器/服务器模式)的方式提供给用户和数据录入核对人员使用。针灸古籍经验推荐平台功能模块见图1。

图 1 针灸古籍经验推荐平台结构图
2 模块功能实现
2.1 系统管理模块
系统管理模块包括操作员管理、角色管理、权限管理、设置个人信息、修改密码、操作日志、访问 IP限定等子模块,具体分述如下。
2.1.1 操作员管理 是系统管理员开通、设置录入校对人员的操作员帐号、密码、权限与真实姓名的操作模块,只有在操作管理开通并授权的情况下方可进入系统进行相关的操作,每位参与古籍录入校对人员均需有针灸专业知识基础。
2.1.2 角色管理 因平台先期的古籍收集整理,以及后期的古籍库资料库、资料核对、标准库的建立工作均需大量人员参与,将参与这项工作的人员进行分工以方便管理是很有必要的,系统中将参与人员按角色区分为超级管理员、资料录入校对员、标准库录入校对员,其中超级管理员拥有最高权限。
2.1.3 权限管理 是系统管理员限定操作员分工范围的功能模块,为超级管理员、资料录入校对员、标准库录入校对员3种不同角色限定工作范围,除超级管理员外,每个操作员登录系统时只能操作本人录入校对的古籍或标准库内容,如资料录入校对员可操作本人录入校对古籍的查询、查看、新增、修改、删除、回收功能。
2.1.4 设置个人信息 所有操作人员于该功能模块下完善个人信息,包括联系方式、专业、单位、录入或校对的古籍书目等。
2.1.5 修改密码 系统管理员设置录入校对人员权限时使用初始密码,告知操作员后,操作员可于本功能模块下修改自己的登录密码。
2.1.6 操作日志 所有操作人员每次登录平台,平台自动记录来访操作员名称、IP 地址、操作时间,描述其操作内容等。
2.1.7 访问 IP 限定 为提高系统安全性,除授权访问外,还可通过 IP 地址限制哪些 IP 地址可以访问,哪些 IP 地址不能访问。
2.2 资料管理模块
该功能模块是操作员登录系统后的操作界面,操作员于此录入、修改、校对资料,包括标准库、资料库、简繁体转换、数据校对与规范、通假字处理、术语词典等子模块。
2.2.1 标准库 在数据挖掘的多个环节需要使用标准库,如分词时将标准库扩充为 IKAnalyzer2012_u6(IK)分词器的词典,在词性标注时将标准库作为ICTCLAS2015 的扩展字典,规则抽取是用标准库的术语去标注分析资料库,监督分类也需标准库作为训练语料,是进行数据挖掘的基础。标准库包括病证、症状、病症、经络、穴位、刺灸法6个子库,操作员可于各个子库下新增、查看、修改、删除每个症状、病证、病症、经络、穴位、刺灸法的名称、类别、代号、出处、别名、主症、兼症、描述等信息,并可上传图片。
2.2.2 古籍库 针灸古籍是平台进行数据挖掘的对象,包括古籍书名目录、资料列表、回收站3个子库,并有书籍管理、内容管理可供操作员按书名、作者、章、节、内容、录入人员查询。①古籍书名目录:操作员可于本子库下新增、查看、修改、删除每本古籍的书名、版本、类别(综合性、专书)、作者、朝代、备注等信息;②资料列表:操作员可于本子库下新增、查看、修改、核对、删除、回收古籍书名目录下书籍的章、节、内容、备注等,并可插入书中图片。
2.2.3 繁简转换 由于古籍存在版本年代的差异,可能存在繁体字,操作员可录入繁体字与简体字,系统采用开源包 HanLP[2]中的简转繁词典,实现繁体字与简体字的互换。2.2.4 同名穴处理 资料录入后,由针灸专业人员用交叉校对法进行校对,纠正错误数据,删除重复数据。
2.2.5 通假字处理 古籍存在大量的通假字,根据高启沃《简明通假字字典》[3]对古籍中的通假字进行识别替换,并基于二分 Trie 树的前缀查询算法实现快速的检索匹配比较。
2.2.6 术语处理 除了标准库中的病证、症状、病症、经络、穴位、刺灸法内容是 IK 分词器的词典、ICTCLAS2015 的扩展字典,同时将搜狗输入法的词库等进行整理,包括书名、人名、朝代名词、古代区域名称等,作为术语词典之一。
2.3 数据挖掘模块
数据挖掘是平台核心部分,目的是实现对非结构化的古籍文本信息按照病症、腧穴、经络、刺灸法的关系进行抽取,并通过关联挖掘分析腧穴的配伍关系及病症、腧穴、经络、刺灸法的对应关系,最终形成知识库。
2.3.1 分词 分词是进行句子理解、语法分析及信息抽取的基础,针灸古籍经验推荐平台采用IKAnalyzer2012_u6 作为分词器,将上述术语词典作为扩展词典,对资料库进行切分并标注词性。
2.3.2 词性标注 为更好理解古籍中每个句子的含义,在分词基础上,对每个词语进行标注,区分每一个词的词性,系统采用中国科学院计算技术研究所开发的汉语词法分析系统 ICTCLAS2015[4]作为词性标注工具,将标准库作其扩展字典,对资料库进行切分并标注词性。
2.3.3 依存分析 语法树的依存关系分析有助于更好地进行人工智能的自然语言处理分析,平台采用最大熵算法实现语法树的依存关系分析。
2.3.4 规则抽取 通过词性标注,得到每个词语的词性,通过扩展词典,将病症、腧穴、经络、刺灸法标准库的术语通过自定的词性标注标签来进行分区,存在关联关系的句子用正则规则关系进行抽取。
2.3.5 监督分类 采用 Adaboost 算法[5],将规则抽取的结果根据标准库的内容进行细分分类。该算法的优点是不需预先标注的手工训练集,只需少量抽取目标的样本信息及大量的未标注语料就可自动抽取目标信息。先将标准库构建成训练模板,通过 Adaboost算法迭代进行分类。
2.3.6 相似度计算 为提高监督分类的准确率,在采用 Adaboost 算法基础上,采用基于 TF-IDF[6]和余弦[7]实现相似度分析。该算法通过词频和逆向文档,将文本信息转为多维的空间向量,通过余弦公式计算两个空间向量的夹角大小进行评估文本的相似度。
2.3.7 歧义分析 对于同一病症在不同书籍中存在不同名称的歧义,采用基于隐含语义分析(latent semantic analysis,LSA)[8]和奇异值分解(singular value decomposition,SVD)[9]来解决。
2.3.8 关联挖掘 通过以上的清理、去噪、整理,形成病症-腧穴-经络-刺灸法集,采用 Apriori 算法[10]实现多层的关联分析,通过迭代和设置最小支持度和置信度,分析项集之间的潜在关系,建立腧穴配伍关系、病症腧穴对应关系、腧穴刺灸法对应关系的知识库。
2.3.9 决策分析 在关联挖掘所建立知识库的基础上,采用决策树 C4.5 算法[11]解决疾病不同症状所选用的腧穴、刺灸法可能不同的问题,以提高分类的准确度,实现更好的分类预测。
2.4 用户检索模块
2.4.1 全文检索 用户可于该界面以检索词检索古籍全文,检索词将以不同颜色显示,用户点击任意一条记录可以查看全文。
2.4.2 词频统计 用户检索全文时,系统自动统计检索词在古籍库中每本书出现的频率。检索病症时,还将出现治疗该病症的经络、腧穴、刺灸法出现的频率,以递减的方式显示;若检索的是腧穴,还会出现该穴治疗病症、刺灸法的频率,以递减的方式显示。2.4.3 关联挖掘结果 用户检索时,平台将显示关联挖掘结果,病症与腧穴(特定穴)、病症处方中腧穴与腧穴、病症与刺灸法及腧穴与刺灸法的支持度和置信度,且病症与腧穴可以关系图的方式表示。
3 平台演示
通过上述的功能模块设计和实现,完成平台的构建,根据《新编针灸大辞典》[12]、《中国针灸穴位通鉴(上、下卷)》[13],将书中的经络、穴位、刺灸法内容录入系统,建立含有经络、穴位、刺灸法信息的标准库,具体包括名称、别名、定义或描述、特性与出处等信息。根据《中国针灸荟萃·现存针灸医籍之部》[14]、《新编针灸大辞典》[12]的针灸医籍名称,收集清代以前针灸古籍并录入数据库,建立古籍库,具体包括书名、版本、作者、朝代、章、节、内容等。
3.1 全文检索结果界面
用户通过搜索界面,可对所录入的 150 本针灸古籍进行全文检索。平台根据用户的查询条件在古籍中进行全文检索,检出包含检索词的文章,同时检索检索词的别名、通假字等,且于界面以关联词语表示;全文检索界面的主体部分是含有检索词的书籍名称及部分章节,检索词于文中以红色显示,双击书目可连接书籍中所有含有该检索词的章节;界面同时以频次递减的形式列出所有含有该检索词的书目。
3.2 腧穴配伍关联分析结果界面
平台自动显示关联分析的结果,可选择疾病相关的症状、所用腧穴、腧穴配伍关系、不同朝代腧穴配伍关系、刺灸法等。不同支持度与置信度的,分析结果记录数不同,用户可根据自身需求选择支持度与置信度阈值。图2显示的是病症处方中腧穴与腧穴的配伍关系。
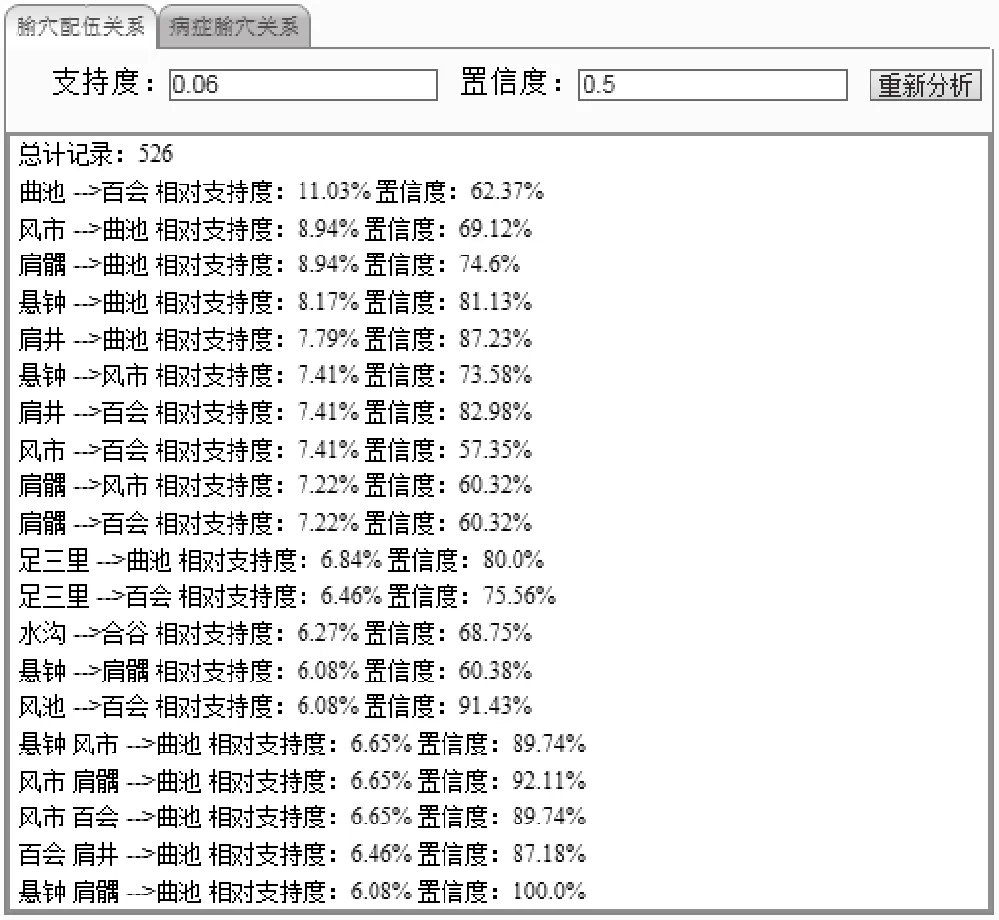
图 2 腧穴配伍关联分析结果界面示例
3.3 病症腧穴关联关系图界面
病症与腧穴的关系以复杂关系图显示,图3显示的是中风病常见症状、常用腧穴及病症与腧穴间的关系,使关联分析结果更直观。

图 3 病症腧穴关联关系图界面示例
4 小结
数据挖掘技术在海量、非线性针灸数据处理中具有明显优势,适于分析散在、庞杂的与针灸相关的经络、腧穴、疾病、医案等资料,以揭示针灸理论科学内涵。但由于在针灸古籍中,腧穴、病症术语不统一,存在同名穴、一穴多名,以及同一症状有多种描述等现象,即针灸古籍数据具有模糊性与不确定性特点,限制了信息化研究的开展。目前,数据挖掘技术在针灸文献研究中的应用大部分针对单个穴位的应用规律、某个病的选穴规律、某种刺灸法及单个名家病案的挖掘,且大多采用人工阅读抽取目的相关的记录,建立单病、单穴、单种刺灸法资料库,而非真正意义上的大数据、智能化。针灸古籍经验推荐平台旨在突破以上限制,采用数据挖掘的分词、词性标注、依存分析、规则抽取、相似度计算、隐性语义分析、监督分类技术结合标准库,实现自动古籍文本抽取,突破人工限制;建立含有经络、穴位、病证、病症对应、针灸相关术语等的标准库,采用隐性语义分析用标准库将病症、经络、腧穴库标准化,解决古籍中腧穴、病症术语不统一的问题。构建一个具有适合针灸诊疗模式及数据挖掘功能的平台,综合多种数据挖掘技术,通过“大数据”开发适合所有针灸文献的智能系统,在反映古籍中病症与腧穴、腧穴与腧穴、病症与刺灸法、病症与经络关系特点的同时,实现针灸古籍有效、快捷地为针灸临床、科研、教学服务,促进针灸的传承与发展,并架起一座通往针灸古籍的桥梁。
[1] 黄龙祥.针灸名著集成[M].北京:华夏出版社,1996:1.
[2] 上海林原信息科技有限公司.HanLP 汉语处理包:HanLP v1.2.8[EB/OL]. [2017-03-23].ht tp://hanlp.linrunsof t.com/.
[3] 高启沃.简明通假字字典[M].2 版.合肥:安徽教育出版社,1999.
[4] 张华平.NLPIR 汉语分词系统:ICTCLAS2015[EB/OL].[2015-08-23]. http://ictclas.nlpir.org.
[5] 许剑,张洪伟.Adaboost 算法分类器设计及其应用[J].四川理工学院学报:自然科学版,2014,27(1):28-31.
[6] 黄承慧,印鉴,侯昉.一种结合词项语义信息和 TF-IDF 方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.
[7] 张振亚,王进,程红梅,等.基于余弦相似度的文本空间索引方法研究[J].计算机科学,2005,32(9):160-163.
[8] 盖杰,王怡,武港山.潜在语义分析理论及其应用[J].计算机应用研究,2004,21(3):9-12.
[9] 李金岭.SVD 算法简介与模拟数据检验[J].中国科学院上海天文台年刊,1998,19:16-21.
[10] HAN J W, KAMBER M.数据挖掘概念与技术[M].范明,孟小峰,译.3 版.北京:机械工业出版社,2012:148.
[11] 黄文.决策树的经典算法:ID3 与 C4.5[J].四川文理学院学报,2007, 17(5):16-18.
[12] 程宝书.新编针灸大辞典[M].北京:华夏出版社,1995.
[13] 王德深.中国针灸穴位通鉴[M].青岛:青岛出版社,2004.
[14] 郭霭春.中国针灸荟萃:现存针灸医籍之部[M].长沙:湖南科学技术出版社,1993.
Construction Method and Function Disp lay of Recommendation Platform for Acupuncture Ancient Books
CHEN Chu-yun1, LI Wei-lin2, HONG Jia-m ing3, LI Li-xia1, ZHANG Qu-fei1, XIE Li-qin1(1. Department of Acupuncture, Guangzhou Hospital of Chinese Medicine, Guangzhou 510130, China; 2. Information and Network Center, Xinhua College, Zhongshan University, Guangzhou 510080, China; 3. College of Medical Information Engineering, Guangzhou University of Chinese Medicine, Guangzhou 510006, China)
This article analyzed the characteristics of data of acupuncture and moxibustion in ancient books, and put forward to a mode of diagnosis and treatments according to acupuncture and moxibustion. A variety of data mining techniques were used to extract, integrate and display the theory, methods, meridians, acupoints and techniques in ancient books to establish a database platform of ancient books based on B/S architecture, which can be used by users. Also, this article described the framework, the function of the module, and the method of realizing each function of the experience platform of acupuncture ancient books, and demonstrated an interface of the results searched by key words“stroke”, and summarized the experience of building this platform and the advantages of the platform in the research and development of data of acupuncture ancient books.
data m ining technology; acupuncture ancient books; software development
10.3969/j.issn.1005-5304.2017.08.002
R2-05
A
1005-5304(2017)08-0004-05
2016-12-16)
(
2017-01-26;编辑:梅智胜)
广东省科技计划项目(2012B060500015);广东省自然科学基金(2014A030309013);广东省第二批名中医师承项目(CS2015030)
李伟林,E-mai l:lwl_tech@126.com
