面向垃圾短信过滤的亚文档集成学习
2017-08-07刘伍颖
刘伍颖, 王 琳
(广东外语外贸大学 语言工程与计算实验室 广东 广州 510420)
面向垃圾短信过滤的亚文档集成学习
刘伍颖, 王 琳
(广东外语外贸大学 语言工程与计算实验室 广东 广州 510420)
针对垃圾短信过滤问题,提出了一种亚文档集成学习方法.该方法采用亚文档集成学习框架将短文本在线二值分类问题转化成若干个子分类问题,并通过线性组合多个子问题的分类结果得出最终的分类预测.利用基于串频索引的文本分类算法实现了一种有效的弱分类器.实验数据表明亚文档集成学习框架能够提高现有文本分类算法的效能,而在亚文档集成学习框架下,基于串频索引的弱分类器过滤效果最佳.
垃圾短信过滤; 亚文档集成学习; 串频索引; TREC评测
0 引言
垃圾短信(SMS spam)是指在移动通信网络中不请自来、不加选择、大批量发送的长度在140字节以内的文本文档.自2008年开始,国内12321网络不良与垃圾信息举报受理中心每年发布两次《手机短信息状况调查报告》.报告中的每周垃圾短信率和每周垃圾短信数是两项非常关键的指标.每周垃圾短信率表示用户平均每周收到的短信中垃圾短信所占的百分比.根据报告中的这两项指标数据,我们绘制的2006—2015年垃圾短信态势如图1所示.
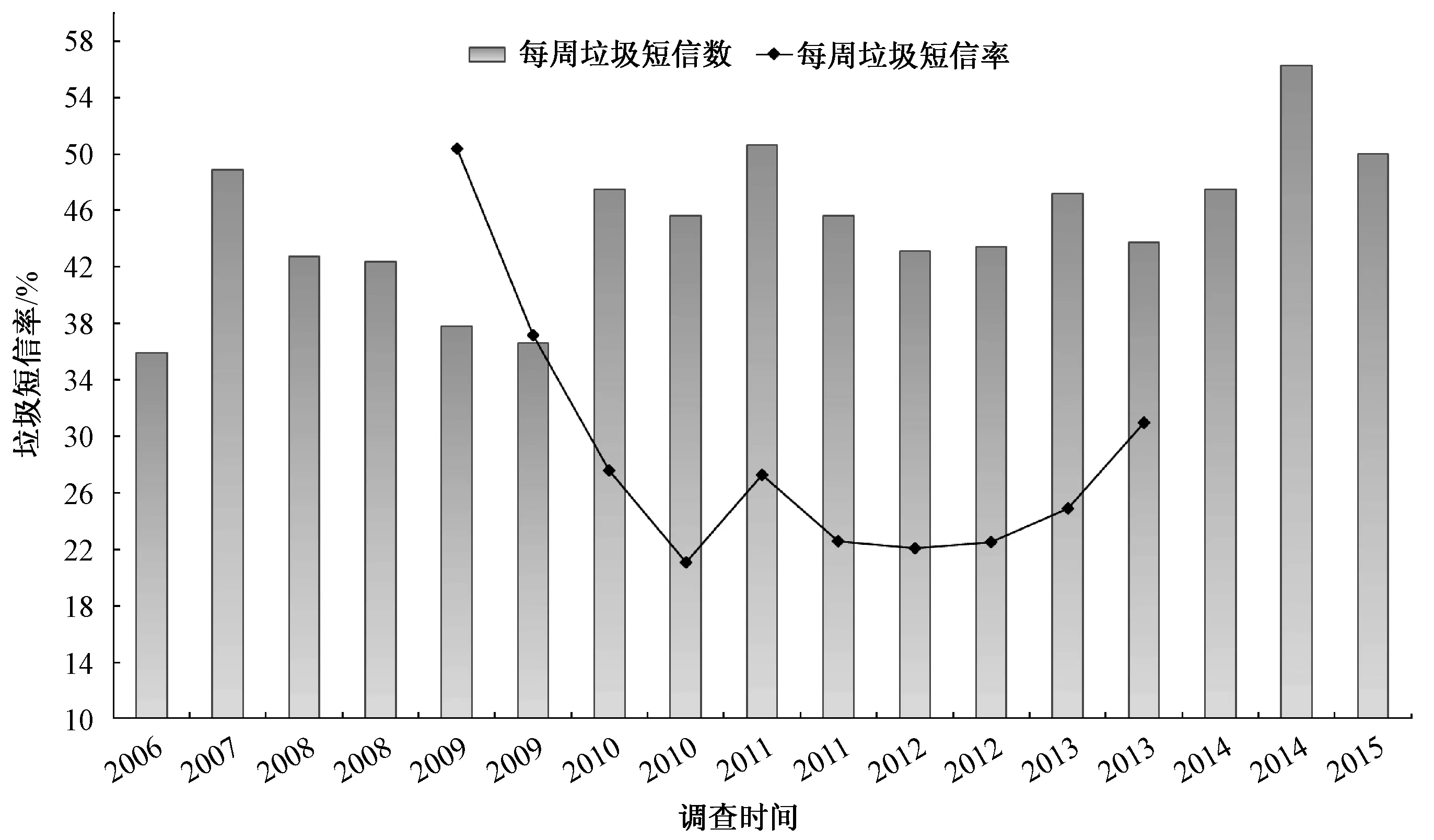
图1 垃圾短信态势
图1的态势显示从2009—2010年每周垃圾短信率从50.40%直线下降到21.10%;2011—2013年每周垃圾短信率基本稳定在23.00%.2006—2013年每周垃圾短信数约为10,虽然各个具体时段略有波动,但整体趋势变化不大.从2014年至今用户平均每周收到的垃圾短信数量又略有增加.由此可见,当前垃圾短信形势依然严峻,垃圾短信占据手机短信半边天的态势没有根本改变.
尽管垃圾短信泛滥,但由于隐私问题,公开的短信语料[1]比较少,主要有:SMS spam collection(http://www.dt.fee.unicamp.br/~tiago/smsspamcollection/)、NUS SMS corpus[2]、SMS Han message corpus (120 040 messages)(http://cbd.nichesite.org/CBD2013D001.htm)和我们的CSMS短信语料.CSMS数据是按时序从志愿者那里收集的真实短信,总共包含85 870个短信文档(21 099个spam和64 771个ham),其中每个短信文档包含源电话号码、目的电话号码和短信正文三个子文档,并且文档的类别标签是根据提供者的反馈进行人工标注的[3].
1 短信文本特征
垃圾短信过滤(SMS spam filtering)根据短信的各种特征,从动态变化的短信流中自动进行垃圾(spam)和非垃圾(ham)的二值分类,并据此阻止垃圾短信传播.最早的垃圾信息过滤研究可追溯到上世纪80年代[4],后逐渐分化为非基于内容的过滤方法[5]和基于内容的文本分类方法[6].在基于内容的文本分类方法中,经典Bayes算法简单、易实现,据此实现的bogo过滤器成为了常用的参照基准(http://www.paulgraham.com/spam.html).后续研究表明松弛在线支持向量机算法过滤效果很好,据此实现的tftS3F过滤器在最近的TREC垃圾过滤评测中取得了多项最优成绩[7].我们曾提出了词模型索引方法[8],并研究了两种索引粒度对标注短文本的存储效能[9].在较短的短信文本中进行有效的特征提取是传统基于内容的文本分类方法面临的主要难题.
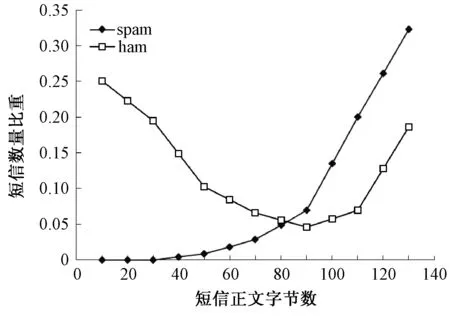
图2 CSMS短信数量分布Fig.2 SMS number distribution in CSMS
短信正文文本长度是一个重要的可计算特征.短信通常采用即时交互模式分段发送会话文本.而spam不易维继会话,为了在一条信息中传递较完整的内容,正文会比较长.但正常通信双方有相互默认的背景认知,所以大多数ham省略了上下文,正文较短.通过对CSMS语料进行正文字节数统计可以进一步量化这种特征.统计结果如图2所示,横轴为短信正文字节数,纵轴为短信数量比重.图2中两条曲线差异显著,ham曲线呈现出双峰特性,而spam曲线呈现出单峰特性,主要集中在120~140字节之间.这种显著差异证实了短信是交互式会话信息,spam正文字节数相对较大,而多数的ham正文文本长度约为20字节.
经过精确的数值计算可知,CSMS中最短的spam正文只有38字节,由此可知短信正文越短(<38字节),ham概率越高.该后验规律说明了短信正文长度的垃圾区分性,这是会话式交互信息(QQ、MSN、微信等)特有的现象.因此正文长度的垃圾区分性规律可以普遍用于会话式交互信息的垃圾过滤.
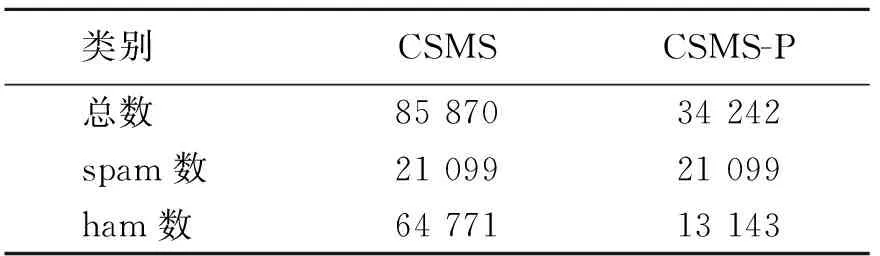
表1 短信语料
我们从CSMS全集中挑选正文文本长度大于等于38字节的短信文档组成一个CSMS-P子集,该子集包含34 242个短信文档(21 099个spam和13 143个ham).具体的短信语料数量如表1所示.据CSMS和CSMS-P中的ham数可知正文长度的垃圾区分性规律可以正确分类79.71%的ham短信.而CSMS-P子集是正文长度的垃圾区分性规律无法胜任的部分数据,需要采用更高级的方法进行过滤.本文以下部分研究和实验均采用CSMS-P子集数据.
2 亚文档集成学习垃圾短信过滤
根据最理想的用户行为假定,垃圾短信过滤应用可以建模成有监督立即全反馈在线二值文本分类问题.又由于短信文档包含多个相对独立的子文档,因此我们基于分而治之的策略利用这一结构特性提出一种亚文档集成学习方法.
2.1 亚文档集成学习
如图3所示,传统集成学习的样本粒度是文档,例如基于放回随机采样的bagging方法[10]和基于错误驱动的boosting方法[11].而亚文档集成学习的样本粒度是子文档.传统集成学习的弱分类器往往是通过部分文档学习得到的,而亚文档集成学习的弱分类器是通过全部文档的特定部分学习得到的.亚文档集成学习充分利用了短信文档包含多个相对独立子文档的结构特性,将短信在线二值分类问题转化成若干个子文档空间上的子分类问题,各个子问题有其特有的特征、模型和结果,通过综合多个子问题的结果得到最终结果[12].综上可知亚文档集成学习的基础是基于文档结构特性的特征空间划分.
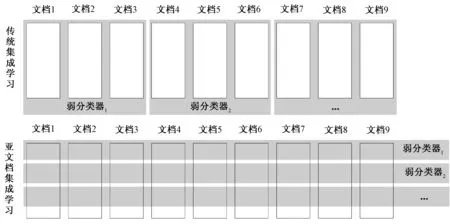
图3 传统集成学习与亚文档集成学习
根据上述亚文档集成学习思想,我们设计的用于垃圾短信过滤的亚文档集成学习框架如图4所示.该框架主要由子文档切分器、若干个弱分类器、结果合成器和反馈学习器构成,主要过滤流程是:首先子文档切分器将输入的手机短信切分成若干个子文档;其次每个弱分类器根据各自的分类模型预测输入子文档的类别,输出结果为[0, 1]区间上的垃圾信度(SS),反映样本是spam的似然度;接着结果合成器将输入的多个垃圾信度组合成最终垃圾信度;最后反馈学习器接收用户输入的类别反馈并分派给每个弱分类器,各弱分类器根据反馈增量学习更新自己的分类模型.
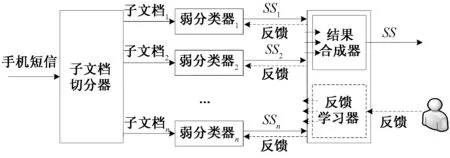
图4 亚文档集成学习框架

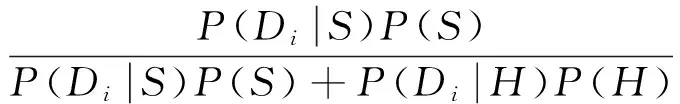
(1)
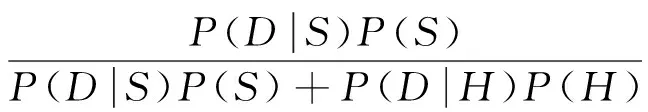
(2)
其中:S表示spam;H表示ham;Di表示第i个弱分类器涵盖的子文档;D表示短信文档.根据式(1)和(2)所示的Bayes条件概率公式,我们可以通过反馈有监督学习预测结果.
亚文档集成学习框架是一种独立于弱分类器的元框架,因此,任意的在线有监督学习二值文本分类算法均可用于实现弱分类器.但亚文档集成学习框架的有效性取决于子文档切分器采用的切分策略、结果合成器采用的合成策略以及在线有监督学习弱分类器的有效性.
2.2 切分策略和合成策略
由于短信文档至少包含源电话号码、目的电话号码、短信正文3个子文档,因此可以通过短信文档结构识别切分得到3个子文档.此外采用信息抽取方法从短信正文中抽取垃圾区分特征码也可以看成是一种切分策略.我们的子文档切分器实现了电话号码特征码和标点符号特征码抽取,因此又可以得到两个子文档.文档结构识别切分策略能够利用文档内含的子文档间的独立性,而特征码抽取切分策略则相当于特征复用和增强技术,不失为一种从短文本中提取有效特征的好方法[13].
亚文档集成学习框架是基于在线有监督学习的,其中关键的合成策略需要确定每个弱分类器各自结果的加权系数.合成策略的好坏受到两方面因素的制约:一是每个弱分类器在各自子文档空间上的历史表现;另一个是待过滤手机短信各个子文档能够提供的垃圾区分特征量.由此我们设计的合成策略综合了上述两种因素.基于弱分类器历史表现的线性组合加权系数可以采用ROC分析得出的ROC曲线下部面积占比进行估计,ROC曲线下部面积占比能够反映弱分类器在各种阈值情况下的效能累积量度.基于子文档垃圾区分特征量的线性组合加权系数可以采用文本长度字节数进行估计.我们的结果合成器实现上述这种合成策略时,需要先分别对两种估计进行归一化,再将归一化的加权系数进行算术平均合成.
3 实验
通过在CSMS 数据集上进行TREC有监督立即全反馈垃圾过滤实验[14],验证亚文档集成学习方法的有效性.
3.1 评价方法
由于spam和ham数量分布极不平衡,因此过滤器评价方法异于传统文本分类.采用TREC垃圾过滤评价方法和评价工具[15],包括当前性能、ROC分析[16]、全局性能、过滤耗时等.当前性能指标包括ham误率(hm%)、spam误率(sm%)和对数误率(lam%),计算公式如下:
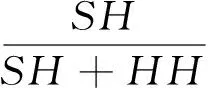
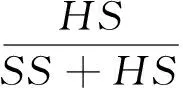
其中:SH和HH分别表示ham评测集中过滤器分错和分对的样本数;HS和SS则分别表示spam评测集中过滤器分错和分对的样本数.这3个当前性能指标数值越小过滤器性能越高.
全局性能是指过滤器在不同垃圾信度阈值条件下表现出的过滤能力,通常包括ROC曲线上部面积(1-ROCA%)指标和可接受点(h=0.1%)指标,指标数值越小,过滤器性能越高[3].在TREC垃圾过滤评价方法中,通常以ROC曲线上部面积(1-ROCA%)为主要评价指标,并根据1-ROCA%数值排序参评的过滤器[15].
3.2 结果与讨论
为了验证亚文档集成学习框架的有效性,我们在CSMS-P数据集上运行bogo分类器、tftS3F分类器以及ndtSFI分类器.其中ndtSFI分类器是根据我们提出的一种基于串频索引的文本分类算法实现的,在垃圾邮件过滤上表现优秀[17].一方面视短信文档为纯文本,分别运行上述3个分类器.另一方面根据本文提出的切分策略把短信文档切分成5个子文档,把上述3个分类器分别当成弱分类器集成进亚文档集成学习框架,并运行相同的过滤任务.其中采用亚文档集成学习框架的分类器标识增加后缀(.sel).
实验结果如表2所示,使用亚文档集成学习框架后,bogo、tftS3F、ndtSFI3个分类器的全局性能(1-ROCA%指标)分别从0.476 3、0.002 4、0.243 7优化为0.008 8、0.002 3、0.002 3.由此可知亚文档集成学习框架能够提高Bayes算法、松弛在线支持向量机算法、基于串频索引的文本分类算法的性能.
表2数据还表明在3个采用亚文档集成学习框架的过滤器当中,我们的ndtSFI.sel不仅全局性能最优,1-ROCA%指标达到0.002 3,h=0.1%指标达到0.21,同时当前性能中hm%指标达到0.03,lam%指标达到0.11,也是最优的,并且耗时(4.4分钟)也是很少的.虽然sm%指标不是最优,但垃圾过滤对于二值目标不是均等看待的,更注重低hm%条件下追求低lam%、低hm%是算法实用的前提.因此采用亚文档集成学习框架,基于串频索引的文本分类算法能够在大大降低计算时间的情况下达到最优的垃圾短信过滤效果.
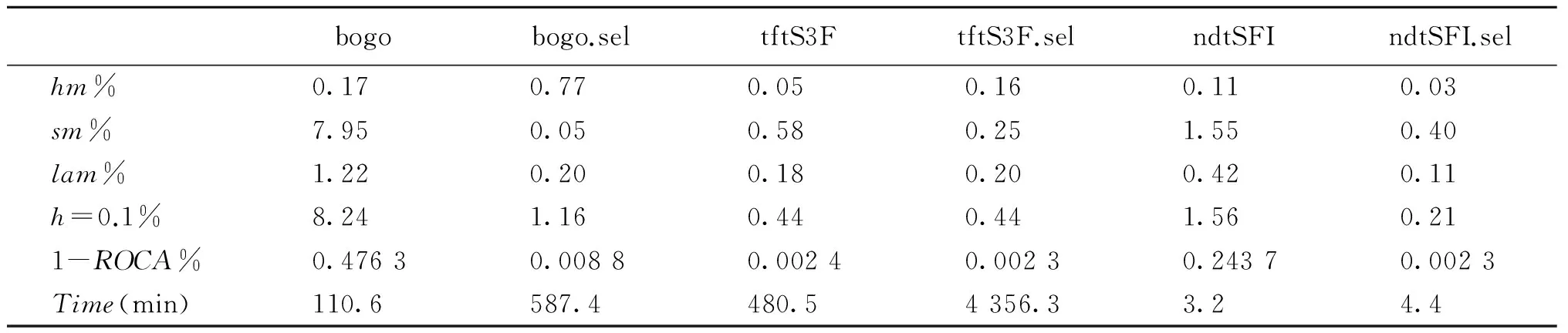
表2 实验结果
还可以通过ROC分析直观评价上述实验结果.实验ROC曲线和ROC学习曲线分别如图5、图6所示.图5中ndtSFI.sel的ROC曲线、左边框、上边框围成的面积比较小,说明ndtSFI.sel的全局过滤性能十分理想.
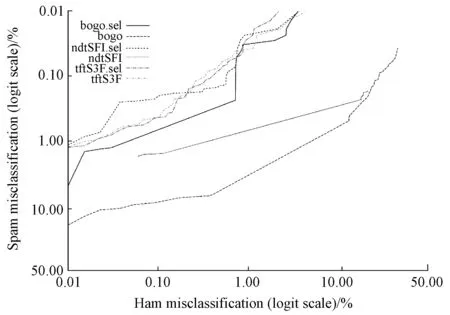
图5 ROC曲线
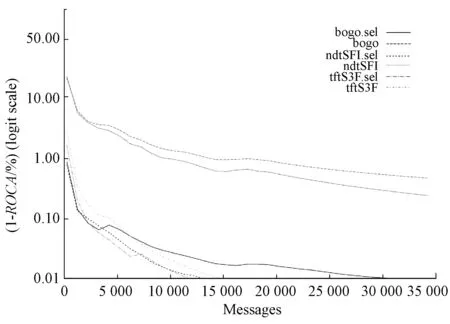
图6 ROC学习曲线
如图6所示.在训练样本达到约12 500时,ndtSFI.sel学习曲线达到理想的1-ROCA%性能(0.01),平均1-ROCA%值能达到0.002 3,这说明采用亚文档集成学习框架能够使基于串频索引的文本分类算法具有很强的在线学习能力.
亚文档集成学习框架的有效性是因为:1) 通过划分子文档空间,文本特征粒度更细,减少文本特征混淆,提高表示的独立性;2) 在子文档空间上采用统计机器学习得到的分类模型更加适合该子文档分类,增强统计的针对性;3) 在子文档空间上进行特征抽取和分类模型更新更简洁,提升计算的高效性[18].又由于弱分类器之间相互独立,因此亚文档集成学习框架具备较强的并行计算潜力.通过硬件重复多个弱分类器,理论上亚文档集成学习框架过滤一条短信的耗时接近最慢弱分类器耗时.
4 结论
本文回顾了国内垃圾短信态势,统计分析了短信文本特征,提出一种亚文档集成学习框架.该框架打破文档级特征粒度,通过附加结构信息将文本特征进行了细粒度区分,将结构特性转变为可计算特征.实验结果表明亚文档集成学习框架能够显著提升Bayes算法、松弛在线支持向量机算法、基于串频索引的文本分类算法的过滤效能,特别是集成我们的基于串频索引的文本分类算法能够在大大降低计算时间的条件下达到最优的垃圾短信过滤效果.
下一步研究将关注面向垃圾手机短信过滤的半监督学习、主动学习、个性化学习,在已有的机器学习算法中引入亚文档集成学习框架,通过加入巨量未标注短信,通过挖掘多个弱分类器之间的差异,发现有价值的未标注短信,通过构建全局分类模型和个性化分类模型以提升过滤方法的效果.
[1] SARAH J D, MARK B, DEREK G. SMS spam filtering: methods and data[J]. Expert systems with applications, 2012, 39(10): 9899-9908.
[2] CHEN T, KAN M Y. Creating a live, public short message service corpus: the NUS SMS corpus[J]. Language resources and evaluation, 2013, 47(2): 299-335.
[3] 刘伍颖. 面向垃圾信息过滤的主动多域学习文本分类方法研究[D]. 长沙:国防科学技术大学, 2011.
[4] DENNING P J. Electronic junk[J]. Communications of the ACM, 1981, 25(3): 163-165.
[5] HU Y, GUO C, NGAI E W T, et al. A scalable intelligent non-content-based spam-filtering framework[J]. Expert systems with applications, 2010, 37(12): 8557-8565.
[6] KHORSI A. An overview of content-based spam filtering techniques[J]. Informatica, 2007, 31(3): 269-277.
[7] SCULLEY D, WACHMAN G M. Relaxed online SVMs for spam filtering[C]//The 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2007) Proceedings. Amsterdam, 2007: 415-422.
[8] 刘伍颖, 王挺. 基于词模型索引的短文本在线过滤方法[J]. 华中科技大学学报(自然科学版), 2010, 38(4): 42-45.
[9] LIU W Y, WANG T. Index-based online text classification for SMS spam filtering[J]. Journal of computers, 2010, 5(6): 844-851.
[10]唐伟, 周志华. 基于Bagging的选择性聚类集成[J]. 软件学报, 2005, 16(4): 496-502.
[11]刁力力, 胡可云, 陆玉昌, 等. 用 Boosting方法组合增强Stumps进行文本分类[J]. 软件学报, 2002, 13(8): 1361-1367.
[12]李欣雨, 袁方, 刘宇, 等. 面向中文新闻话题检测的多向量文本聚类方法[J]. 郑州大学学报(理学版), 2016, 48(2): 47-52.
[13]邓冰娜, 王煜, 刘宇. 一种应用于博客的垃圾评论识别方法[J]. 郑州大学学报(理学版), 2011, 43(1): 65-69.
[14]CORMACK G V. Email spam filtering: a systematic review[J]. Foundations and trends in information retrieval, 2008, 1(4): 335-455.
[15]CORMACK G V. TREC 2007 spam track overview[C]// Proceedings of the Sixteenth Text Retrieval Conference, TREC 2007. Maryland: Gaithersburg, 2007: 500-274.
[16]FAWCETT T. An introduction to ROC analysis[J]. Pattern recognition letters, 2006, 27(8): 861-874.
[17]刘伍颖, 王挺. 结构化集成学习垃圾邮件过滤[J]. 计算机研究与发展, 2012, 49(3): 628-635.
[18]DIETTERICH T G. Ensemble methods in machine learning[J]. International workshop on multiple classifier systems, 2000,1857(1):1-15.
(责任编辑:王海科)
Sub-document Ensemble Learning for SMS Spam Filtering
LIU Wuying, WANG Lin
(LaboratoryofLanguageEngineeringandComputing,GuangdongUniversityofForeignStudies,Guangzhou510420,China)
A sub-document ensemble learning (SEL) method was proposed to solve the problem of SMS spam filtering. The method used the SEL framework to break the online binary classification issue of short texts into several sub-issues, and made the final category prediction by a linear combination of several sub-results. Moreover, an effective weak classifier was implemented according to the string-frequency-index-based text classification algorithm. The experimental results showed that performances of previous text classification algorithms could be improved by the SEL framework, and the string-frequency-index-based weak classifier could achieve the state-of-the-art performance within the SEL framework.
SMS spam filtering;subdocument ensemble learning;string-frequency index;TREC evaluation
2016-10-30
国家语言文字工作委员会重点项目(ZDI 135-26);广东省高校特色创新项目(2015KTSCX035).
刘伍颖(1980—),男,江西九江人,副研究员,主要从事计算语言学和自然语言处理研究,E-mail:wyliu@gdufs.edu.cn;通信作者:王琳(1983—),女,山东威海人,讲师,主要从事应用语言学研究,E-mail:wanglin@nudt.edu.cn.
TP391.1
A
1671-6841(2017)03-0059-06
10.13705/j.issn.1671-6841.2016306
