多粒度通信优化的MPSoC调度映射策略
2017-08-02蔡田田习伟郭晓斌姚浩黄凯
蔡田田, 习伟, 郭晓斌, 姚浩, 黄凯
(1.南方电网科学研究院有限责任公司, 广东 广州 510080; 2. 浙江大学 信息与电子工程学院, 浙江 杭州 310027 )
多粒度通信优化的MPSoC调度映射策略
蔡田田1, 习伟1, 郭晓斌1, 姚浩1, 黄凯2
(1.南方电网科学研究院有限责任公司, 广东 广州 510080; 2. 浙江大学 信息与电子工程学院, 浙江 杭州 310027 )
随着嵌入式系统处理器核数的增加,映射与调度成为软件开发的关键. 为了提升系统性能,需要格外关注映射与调度过程中的通信开销.现有的粗粒度系统级或细粒度线程级通信优化虽然能提升性能,但都各有缺陷.为此,提出了基于整数线性规划的用于Simulink模型的多粒度通信优化映射与调度策略,将不同粒度的通信优化方法相结合,实现优势互补.实验结果表明,该方法能有效提高系统的整体性能.
整数线性规划;映射与调度;多粒度通信优化
0 引 言
随着高性能嵌入式软件应用需求的日益增长,多核片上系统(multi-processor system on chip, MPSoC)成为研究的热门领域.对于给定的应用,如何将任务分配至不同的线程或处理器,即映射与调度问题,对于提升系统性能尤为关键.
自多核处理器问世以来,映射与调度问题因其复杂性与关键性而备受关注. 系统运行过程中,许多影响性能的因素,诸如通信开销、负载平衡、线程切换等都需要深入研究. 随着处理器核数的增加,如何最小化多核处理器的通信开销成为其中最为关键的问题.
针对通信开销问题,一些文献提出了映射与调度过程中降低通信开销的方法. COTTON等[1]提出了通过多准则优化找到多核处理器映射的帕累托最优解,使得多核处理器之间的通信开销最小,同时保证负载平衡. FERRANDI等[2]针对映射与调度提出采用蚁群算法优化系统性能. 黄凯等[3]基于整数线性规划(ILP)提出的映射与调度策略定义了3层系统架构,其中包含处理器内部的通信优化与处理器间的通信优化. 然而,从图1(a)所示的系统层次看,以上方法仅在粗粒度通信优化条件下起作用,且都是通过控制线程或者处理器之间的通信信道进行优化,比如通过给各个处理器分配任务来减少占用的信道数量或减少每个信道的通信数据量.

图1 粗粒度系统级对比细粒度线程级通信优化Fig.1 Coarse-grained system level vs. fine-grained thread level communication optimization
另外,文献[4-5]提出线程层次的细粒度通信优化,如图1(b)所示,主要通过对有依赖关系的线程之间通信任务的控制进行优化,比如在一个线程的运算任务和通信发送任务执行之前,提前执行通信接收任务[4],并合并有着相同源线程与目标线程的通信发送与接收任务. 这些优化手段均在一定程度上降低了信道的启动与传输时间,但从全局来看,可能会影响系统的整体性能,因为这些优化手段无法在全局分配通信,可能会引入更多的系统延迟.
通过对比粗粒度与细粒度通信优化发现,粗粒度优化可以全局分配通信得到最佳性能,但缺乏对信道的局部处理;而细粒度优化能对信道进行局部优化,但没法考虑系统全局的性能. 因此,可以将一种结合全局与局部处理的多粒度通信优化应用到映射与调度过程中.
本文提出一种基于整数线性规划(integer linear programming, ILP)的多粒度静态映射与调度策略,对Simulink模型进行性能优化. 在映射阶段,根据负载平衡原理将任务分配至每个处理器的线程,并基于ILP粗粒度系统级进行通信优化. 在调度阶段,确定所有任务的执行顺序,并引入细粒度线程级通信优化,采用ILP方法分配通信流水线与消息聚合,以降低每个信道的通信开销.
本文主要描述一种结合粗粒度和细粒度通信优化的映射与调度策略,与以往大量的映射与调度策略相比,主要贡献在于引入了针对细粒度Simulink模型的面向通信的优化方法,首次引入多粒度通信优化这一概念,并将其应用于映射与调度过程中.
1 背景介绍
1.1 建 模
功能模型能够体现具体应用程序的并行性,并且容易转化成如LESCEA[6]所支持的多线程代码. 一些能够建立功能模型的高级语言如KPN (Khan Process Network)[7]、dataflow[8]、Simulink[9]已被用于系统定义与代码生成. 本文采用Simulink模型.
Simulink模型定义了目标系统的软硬件架构,文献[7,10-11]描述了其具体细节. 通常Simulink模型包括图2所示的3部分.
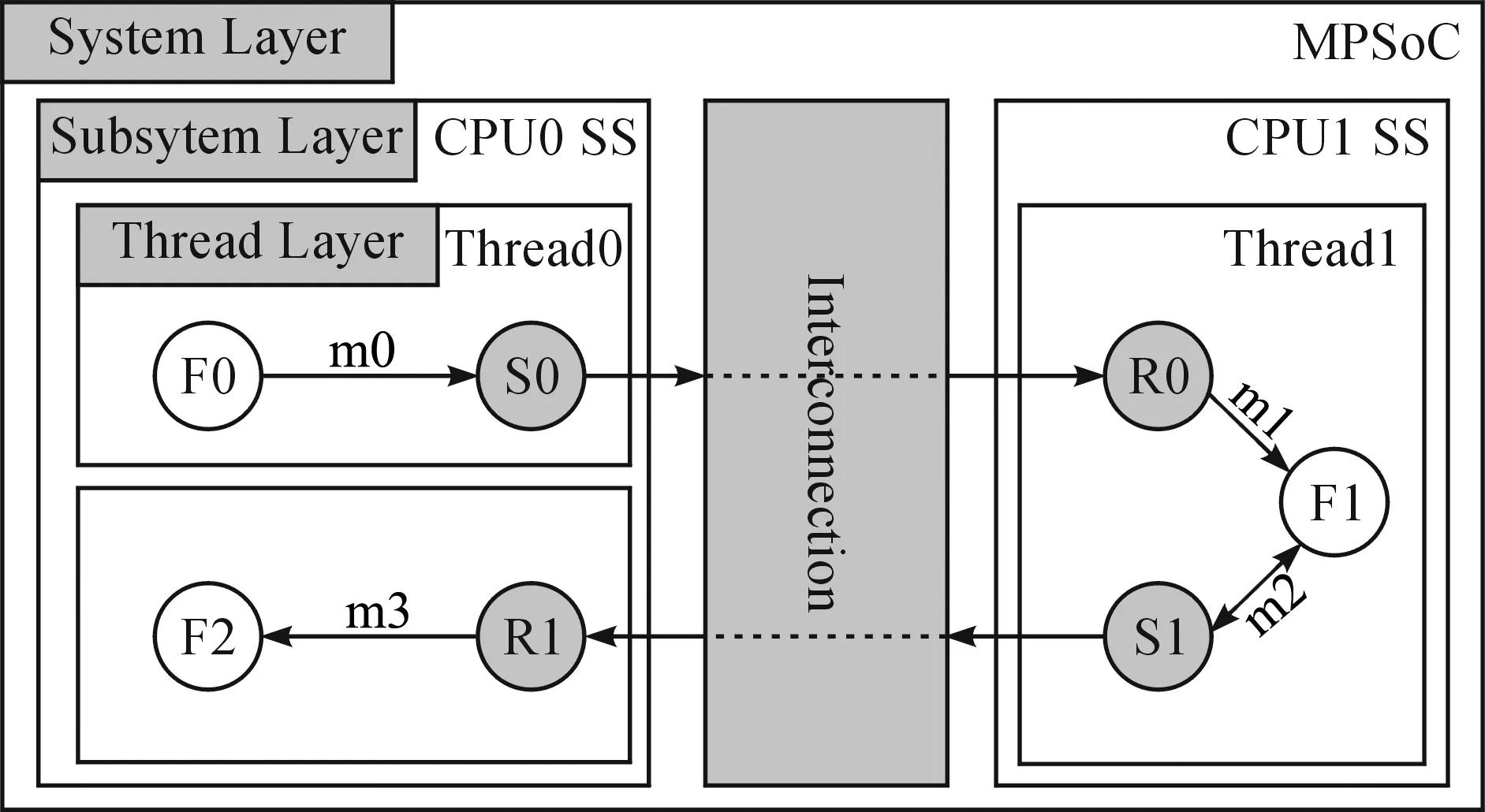
图2 Simulink体系架构Fig.2 A Simulink hierarchical structure
·Simulink模块(block)代表一个包含输入输出的功能块函数.比如用户自定义函数(S-function)、离散时间延迟、预定义块等运算操作. 本实验采用了如图2所示的功能模块,代表系统运行与收发消息的通信过程.
·Simulink链接(link)是相关模块之间一对多的链接,其中一个输出端口与多个输入端口相对应. 如果一个链接从F0到F1,则称F1依赖于F0,记作F0_>F1. 对于一个从发送模块S到接收模块R的链接,称之为通信向量,记作S_>R.
·Simulink子系统包含若干Simulink模块、Simulink链接以及其他子系统,表示层级结构和条件语句,如for循环或if-then-else结构.
本文的设计如图2所示,MPSoC Simulink模型的架构可以分为系统层、子系统层、线程层3层. 其中系统层包括多个CPU子系统以及子系统间的通信信道;子系统层为一个CPU子系统架构,包括一系列线程以及线程间的通信信道;线程层指包含Simulink模块和Simulink链接的软件线程.
1.2 通信流水线与消息聚合
分布式存储架构是一个普遍采用的处理器间通信的体系结构.其中分布式存储服务器(distributed memory server, DMS)用于处理器间通信.DMS可在初始化之后自动传输数据而无须处理器干预. 利用此特性,通信流水线能降低处理器之间数据传输的通信开销. 为实现一个线程的并行计算和通信,所需的运算数据必须在运算前就绪,即要求在当前周期(一个周期代表所有的线程均执行一次[7,10])之前完成数据的传输与缓存,以便功能模块能直接使用缓存数据进行当前周期的运算. 因此,通信流水线可以最小化DMS的传输时间.
图3直观地描述了通信流水线,(a) (b) (c)分别为应用模型、未采用通信流水线代码、采用通信流水线代码的示意图,图3(d)描述了(c)的执行顺序,其中R0、F1、S1在使用了通信流水线之后并行执行.

图3 通信流水线Fig.3 Communication pipeline
通信流水线通过将数据延迟一个周期使运算与通信并行,若使用不当,这一延迟会导致处理器阻塞,降低系统性能.
上述技术可以缩短通信的传输时间,其优化时间取决于传输的数据量,但是每次通信的启动时间无法优化. 而消息聚合是将具有相同源线程和目的线程的消息合并传输,从而有效减少通信次数,节省启动时的开销.
图4描述了一个消息聚合的例子,其中2条消息被合并传输,通信的启动时间能节省50%.但是消息聚合有可能会造成发送延迟,进而影响系统的性能.
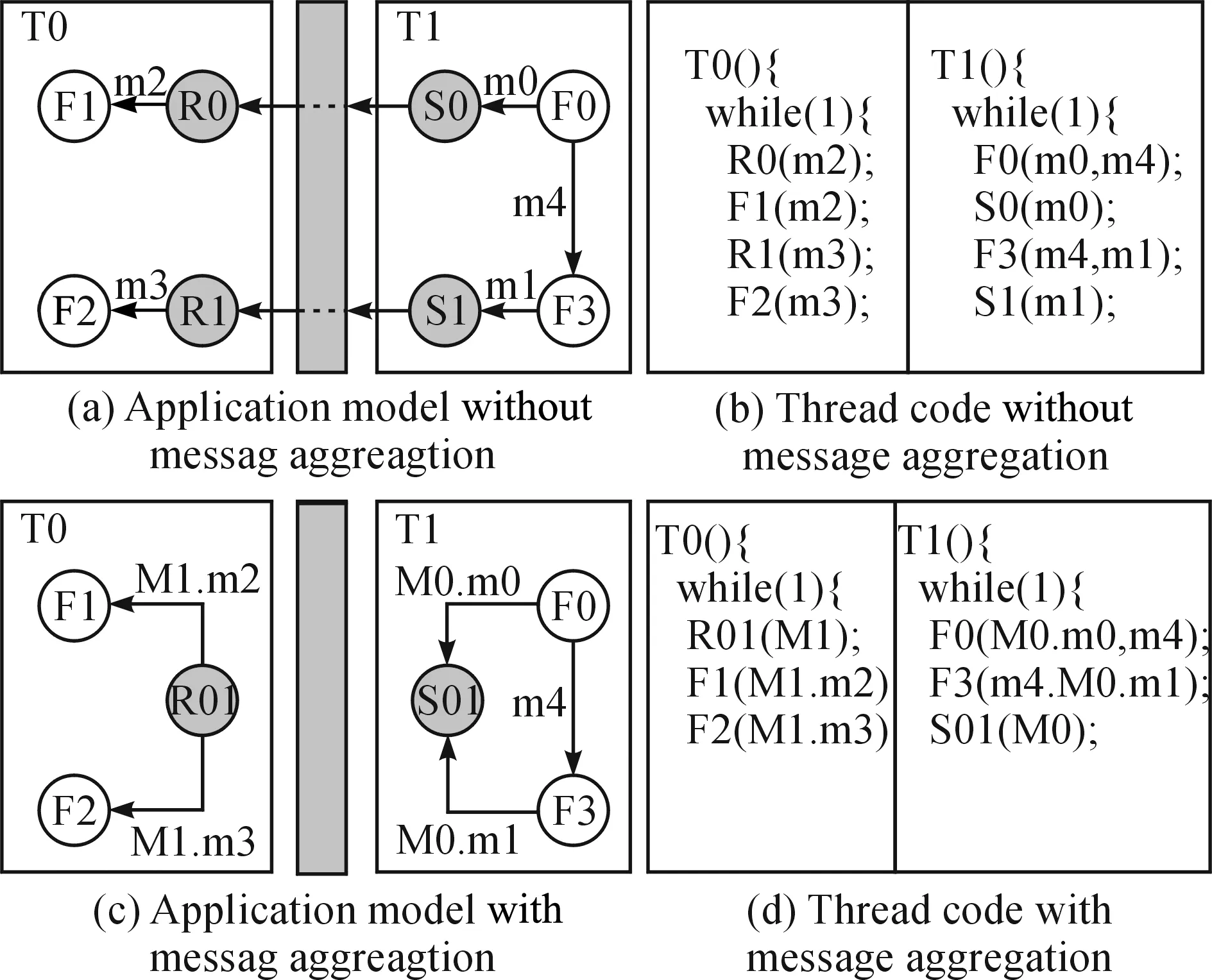
图4 消息聚合Fig.4 Message aggregation
2 基于ILP的多粒度通信优化的映射与调度策略
首先,简单起见,假定每个处理器线程数目为4,并与该处理器绑定. 映射阶段决定了各任务、线程间的关系及其划分结果,并权衡考虑了负载平衡与通信开销最小化,其中粗粒度系统级通信优化被用于最小化处理器内部与处理器之间的通信开销.
其次,基于映射的结果,利用通信流水线与消息聚合,进行线程内部与线程之间的任务调度,以降低通信开销,优化系统整体性能.
2.1 粗粒度系统级通信优化映射
系统整体性能由所有处理器中最长的执行时间决定,因此在映射过程中保持各处理器之间的负载平衡是提高性能的最基本要求,其中归一化变量负载不均衡度(WG)指各处理器的负载与系统平均负载之差的总和,表示各处理器的负载平衡状况.处理器间过多的通信将会延长其执行过程中的阻塞时间,而处理器内部过多的通信会延长处理器线程切换的时间. 处理器之间与处理器内部的通信从系统层面可看作线程间的通信,因此需将这两者的通信开销最小化. 在映射过程中,从系统层面看,任务被划分并分配到各线程,所以将粗粒度系统级通信优化整合在ILP方程中,可以最小化所分配的信道数量.
在列举ILP公式变量之前,先给出一些记号.
2.1.1 常 量
·P表示处理器数量.
·T表示任务数量.
·TH表示线程集合,线程thi∈TH与处理器pi/4∈P绑定.
·Nij为任务ti,tj之间的通信量大小.
·Dij为布尔型常量,表示任务ti与tj之间是否有依赖关系,当tj依赖于ti时,该值为1.
·ETi为任务ti的执行时间.
2.1.2 变 量
·Ai,m为布尔型变量,表示任务与线程之间的映射关系,当任务ti被映射到线程thm时,该值为1.
·Sij,m为布尔型变量,表示任务之间的映射关系,当任务ti、tj被分配至线程thm时,该值为1.
·Bij,k为布尔型变量,表示任务之间的映射关系,当任务ti、tj被分配至处理器pk时,该值为1.
·Interi,m为布尔型变量,当处理器间通信任务ti被映射至线程thm时,该值为1.
2.1.3 目 标
以下目标函数可实现线程间通信量(CS)、负载不均衡度(WG)最小化,在保证k1+k2=1的情况下通过调节目标函数中的权重k1,k2实现两者的均衡.
min(k1×CS+k2×WG),
(1)
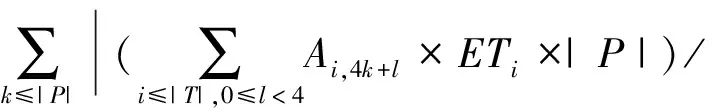
(2)
(3)
2.1.4 约束条件
·每个任务必须被分配到一个线程.

(4)
·若任务ti或tj未被分配到线程thm,则Sij,m为0.
Sij,m≤(Ai,m+Aj,m)/2.
(5)
·若任务ti或tj未被分配到处理器pk,则Bij,k为0.
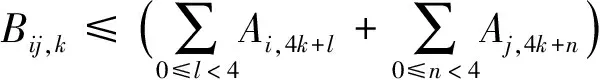
(6)
·若互相依赖的任务ti和tj被映射到不同处理器,则他们之间存在处理器间通信.
(7)
·每个线程至少包含1个跨处理器通信任务.
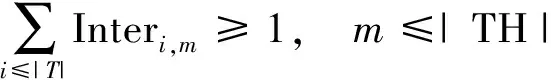
(8)
式(7)、(8)中MAX是一个足够大的正整数. 由以上公式,可得到一一对应的任务线程和负载不均衡度和通信开销最小的映射最优解.
2.2 细粒度线程级通信优化调度
调度过程决定了线程内和线程间任务的执行顺序. 不合理的调度会延长处理器同步等待时间,从而降低动态性能.
在这个阶段,建立了另一组ILP方程,并基于上述映射结果决定调度过程. 在映射阶段后,处理器内与处理器间的通信任务被添加到各个线程. 在线程与处理器内所有任务的调度过程中,通信任务将影响系统性能. 因此,需要用细粒度线程级通信优化,包括采用通信流水线和消息聚合技术来提高系统性能. 对于一个确定的映射,通信流水线仅可应用于处理器间的通信任务,而消息聚合可应用于处理器内和处理器间.
在引入基于ILP方法的通信优化之前,首先须对2项优化技术进行量化,并分析其对调度结果和性能的影响. 为便于从细粒度Simulink模型角度分析,在下文的描述中用模块代表前文提到的任务(两者属同一概念). 如图3所示,当通信流水线被应用于一对互相通信的任务中时,通信向量S_>R中的数据在当前周期被R接收并在下个周期被使用,这将导致nb_R0,F1,S1,即一个线程周期的执行时间产生延迟. 从线程T1看,通信流水线仅提前1个周期执行接收任务,不会改变此线程任务执行的顺序.
消息聚合,将相同源线程和目的线程中对应的通信任务聚合到一起,导致模块数量和执行顺序发生改变. 为保持模块间数据的相关性,由消息聚合得到的模块其执行顺序应遵守以下规则:
·在发送线程,聚合模块间的模块应先于新模块.当发送模块S0和S1被聚合成S01时,原本位于S0和S1之间的功能模块S3,应移至S01之前,如图4(d)中T1的代码所示.
·在接收线程,聚合模块间的模块应晚于新模块.当接收模块R0和R1被聚合成R01时,原本位于R0和R1之间的功能模块F1,应移至R01之后, 如图4(d)中T0的代码所示.
基于以上分析,建立了一组ILP方程来决定调度策略. 同时,为了提升性能,通信流水线和消息聚合应被合理分配到通信向量中,以最优化细粒度通信.
2.2.1ILP方程各量
2.2.1.1 常 量
·B表示模块的集合,包括功能模块和通信模块.
·T表示线程的集合.
·P表示处理器的集合.
·exei为功能模块bi∈B的执行时间.
·commi为通信模块bi∈B的传输时间.
·commstratup为任意通信模块的启动时间.
·interi为布尔型常量,当通信模块bi∈B是处理器间通信模块时,该值为1,即bi和相关的通信模块位于不同的处理器上.
·Dij为布尔型常量,表示模块bi∈B和bj∈B间的依赖关系,当bj依赖于bi时该值为1.
·switch为线程切换时间.
·cyc为每个模块总的执行周期数.
2.2.1.2 变 量
·eij为布尔型变量,表示模块间的执行顺序,当相同线程内的模块bi∈B先于bj∈B执行时该值为1.
·toverall为一个应用程序总的执行时间.
·si,k为第k周期模块bi∈B的调用时间.
·Mij为布尔型变量,表示消息聚合是否被用于包含相同源线程和目的线程的通信模块,当这种模块bi∈B和bj∈B被聚合在一起时,该值为1.
·CPi为布尔型变量,表示通信流水线是否被用于通信模块bi∈B,当bi被通信流水线化时,该值为1.
·COMMi为消息聚合后,通信模块bi∈B的传输时间.
2.2.1.3 目 标
·为了最大化提升性能,应最小化系统总执行时间:
min(toverall).
(9)
2.2.1.4 约束条件
·同一线程内模块的执行顺序应满足原始数据的相关性:
eij≥Dij,i,j≤|B|.
(10)
·消息聚合可能影响模块的执行顺序以及通信时间.
对于相同线程内的模块bi∈B和bj∈B,假设bi早于bj执行:
eik+(1-Mij)×MAX≥ejk,
eik+(Mij-1)×MAX≤ejk,k≤|B|.
(11)
其中,MAX是一个足够大的正整数.
聚合后新模块的通信传输时间为原模块时间之和:
COMMi=Mij×commj+commi,
COMMj=(1-Mij)×commj-Mij×commstartup.
(12)
·相同线程内的模块依据eij执行. 假设bi∈B和bj∈B被映射到相同的线程,并且bi先于bj执行,在第k周期bi的结束时间应该早于第k周期bj的调用时间,且第(k+1)周期bi的调用时间应该晚于第k周期bj的结束时间:
(13)
timei和timej分别表示完成bi和bj的时间. 如果bi(bj)是一个功能模块,那么
timei=exei(or timej=exej),
(14)
否则,
timei=commstartup+COMMi
or
timej=commstartup+COMMj.
(15)
考虑通信流水线的影响,
(16)
如果bi(bj)是一个通信模块,则
timei=commstartup+(1-CPi)×COMMi
or
timej=commstartup+(1-CPj)×COMMj.
(17)
·对于一对通信模块bi∈B和bj∈B,假设bi是发送模块,bj是接收模块,第k周期bi的结束时间应该早于第k周期bj的调用时间,且第(k+1)周期bi的调用时间应该晚于第k周期bj的结束时间.进一步,如果bi和bj位于相同的处理器上,在bi执行完毕后,需要线程切换来执行bj:
si,k+commstartup+COMMi+(1-interi)×switch≤
sj,k,sj,k+commstartup+COMMj+(1-interj)×
switch≤si,k+1.
(18)
·同一处理器不能同时执行2个模块,即同一处理器上任意2个模块的执行时间不能重叠. 假设模块bi∈B和bj∈B被分配到相同处理器的不同线程,第k周期bi的执行时间不能与第k′周期bj的执行时间重叠:
(19)
在该约束下,timei和timej由式(14)和(17)定义.m是一个布尔型变量,当第k周期bi的结束时间早于第k′周期bj的调用时间时,该值为1.
·应用程序总的执行时间取决于第cyc周期每个模块的调用时间.对于任意模块bi∈B,
toverall≥si,cyc+timei,
(20)
timei由式(14)和(17)定义.
解决了上述规划问题,可得到所有任务的执行顺序,并且可在通信任务间引入通信流水线和消息聚合. 由于任务已经映射到确定的处理器线程,故线程间和线程内的调度也将确定.
纵观整个多粒度通信优化流程,在映射阶段,以粗粒度通信优化为主导,通过最小化线程间和线程内的通信开销,为细粒度通信优化构建一个更加轻量级的通信网络. 在调度阶段,加入细粒度通信优化,进一步减小信道分配开销,从而全面降低系统的通信开销.
3 实现平台与实验结果
3.1 实现平台
借助LESCEA(light and efficient simulink compiler for embedded application)多线程代码生成器,在基于Simulink的MPSoC设计平台[7,10-11]上实现. 以Simulink为模型,输入并生成一系列能被目标硬件架构执行的软件代码. 多线程代码生成的整体流程如图5所示,共包含4个步骤:1) 映射:每个任务被分配到一个处理器的一个线程,并加入粗粒度系统级通信优化,得到一个系统模型作为LESCEA的起始点. 2) 调度:在考虑细粒度线程级通信优化的同时,决定每个线程内任务的执行顺序以及每个处理器内线程的执行顺序. 3) 线程代码生成:对于每个线程,生成一组包含内存声明和一系列函数调用的C语言代码. 4) 依赖于硬件的软件库(hardware dependent software)适应:为每个处理器产生一份主代码,以及一份将线程链接到HdS库的Makefile文件.

图5 多线程代码生成流程Fig.5 Multithreaded code generation flow
实验所用的硬件平台如图6所示. 该平台是一个灵活性较高的MPSoC,其中包含用作处理器扩展的高效互联网络. 包括8个CPU子系统,1个全局内存子系统,以及1个将CPU和内存子系统桥接在一起的互联网络. 每个CPU子系统包含1个基于CK Core的32位7级流水线RISC(reduced instruction set computer)处理器[12]及本地组件,通过内存服务访问点(memory service access point, MSAP)[13]与外部互联网络连接.内存子系统包含8个CPU子系统私有的内存模块和1个全局共享内存. 在实验中,采用一个简单的MJPEG(motion joint photographic experts group)译码器和一个复杂的MPEG2(moving picture experts group 2)译码器作为应用程序模型.
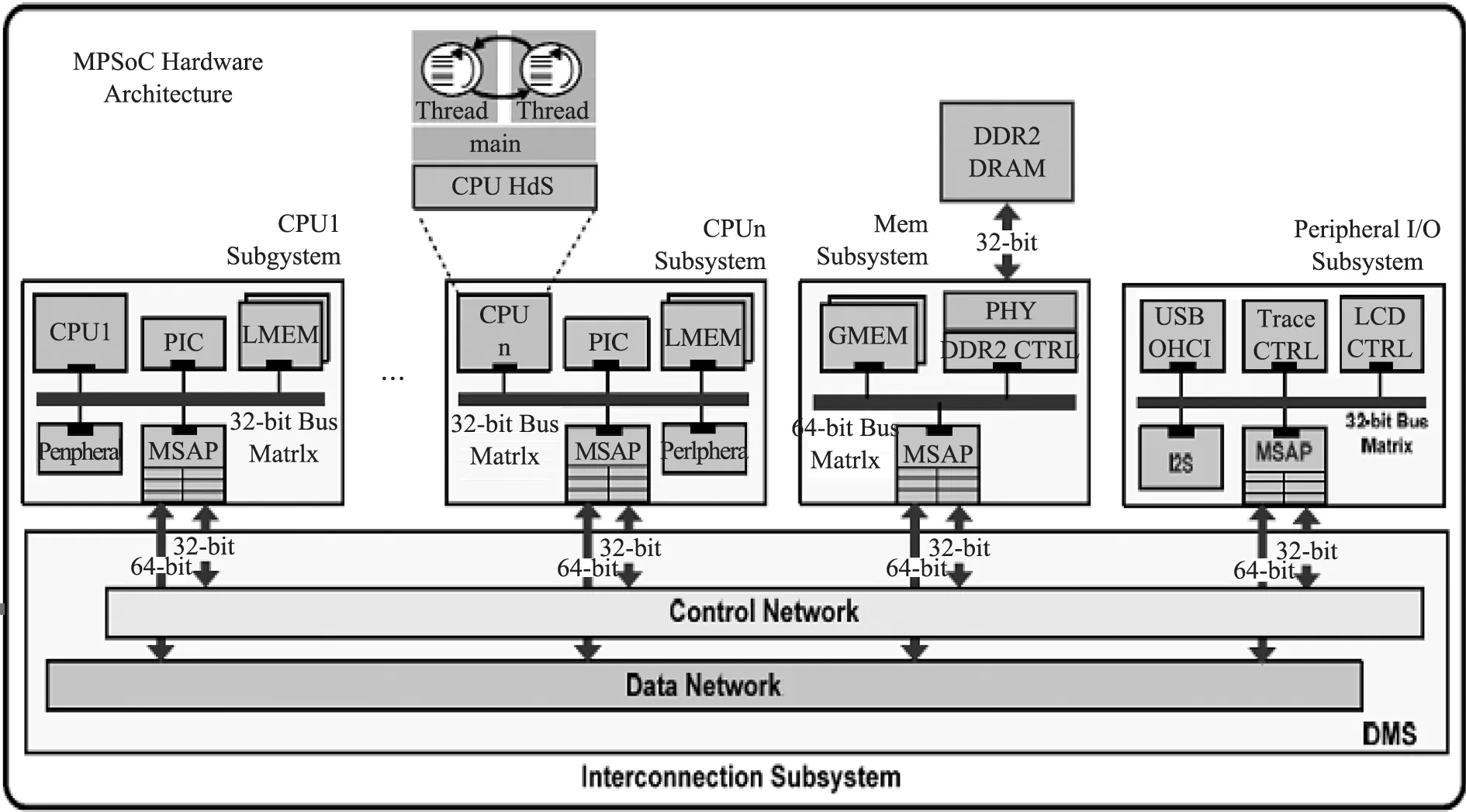
图6 MPSoC硬件平台架构Fig.6 MPSoC hardware platform architecture
为了验证所提出的多粒度通信优化方法的效果,依次使用不同的通信优化粒度进行4组对比实验,如表1所示.
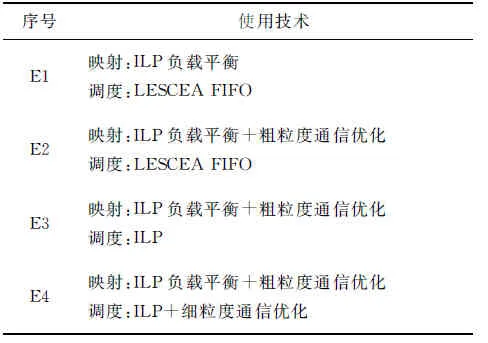
表1 实验设置
3.2 实验结果
3.2.1 MJPEG译码器
MJPEG译码器有7个S函数,7个延迟,26条数据链路和4个IAS(if-action subsystem). 由于其规模很小,在2/3-CPU平台上进行实验. 实验使用10帧QVGA(quarter video graphics array)格式的数据流作为输入.
每组实验总的执行周期数如图7所示. 相较于在映射阶段只考虑负载平衡、在调度阶段只使用先入先出(first in first out, FIFO)调度方法的基础组E1,本文方法在2-CPU平台上性能提升了10%,在3-CPU平台性能提升接近20%.由于2-CPU平台中应用程序简单,且使用了2个处理器,带粗粒度通信优化的ILP映射(E2)的结果与不带优化的ILP映射(E1)的结果相同,说明该2种条件下性能相同. 当处理器数量增加时,在3-CPU平台上,其性能提升明显,这是因为使用了一个额外的处理器并且减少了更多的通信开销.
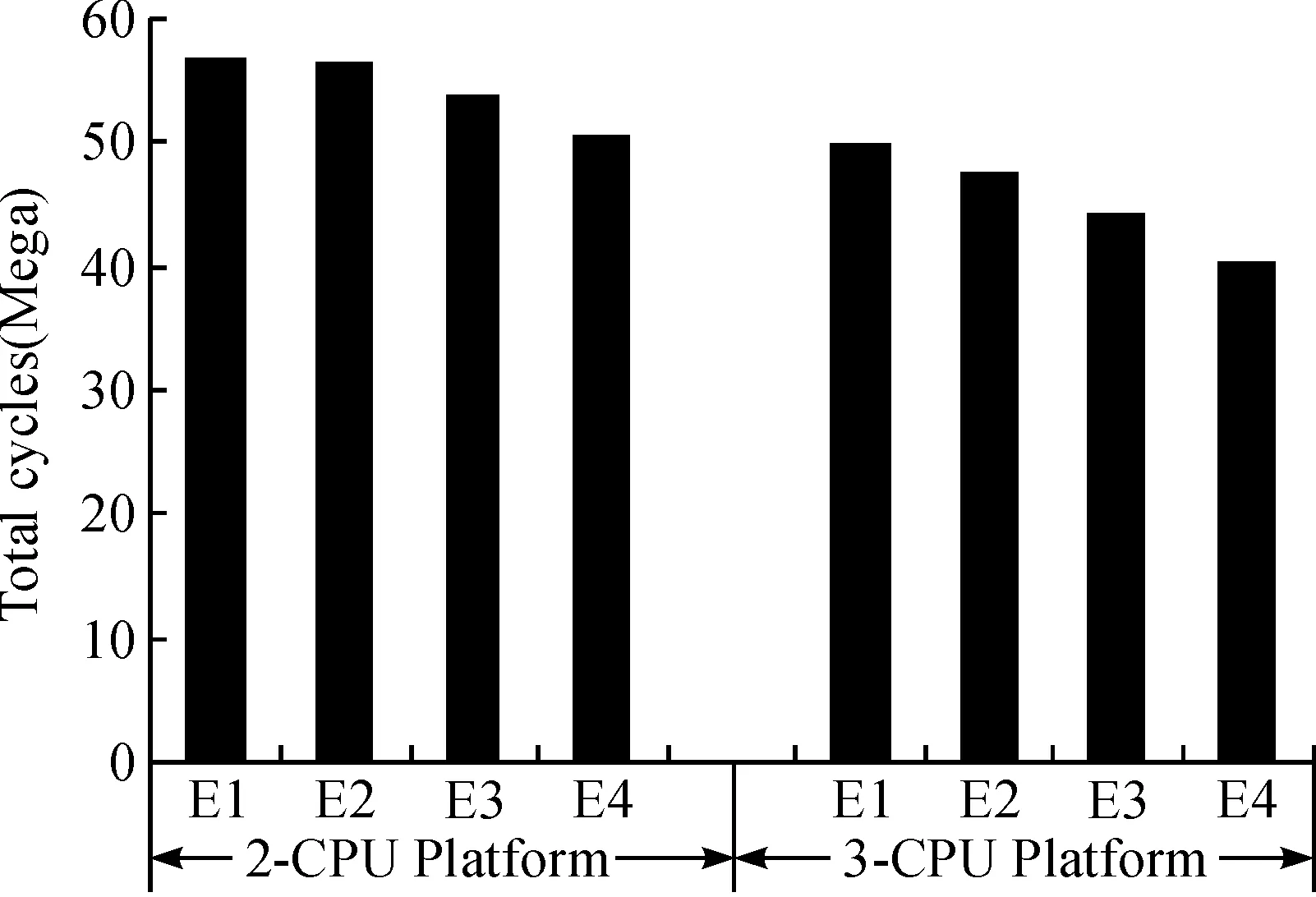
图7 各实验组的总执行周期数Fig.7 Total execution cycles of each set
为了进一步分析性能提升的原因,将处理器的状态划分成3类:计算状态(COMP)、通信状态(COMM)和空闲状态(IDLE). 计算/通信状态指处理器在执行功能模块/通信模块的状态,而空闲状态指处理器切换线程或等待线程同步的状态.
图8显示了处理器内IDLE和COMM状态组件的百分比,并以各处理器的平均值为衡量依据.其中E4的通信开销减小至只有2%~3%,并且IDLE状态也减至7%内. 说明性能提升的主要原因是通信开销的减少. 此外,如图8所示,调度的结果也同步缩短了时间.
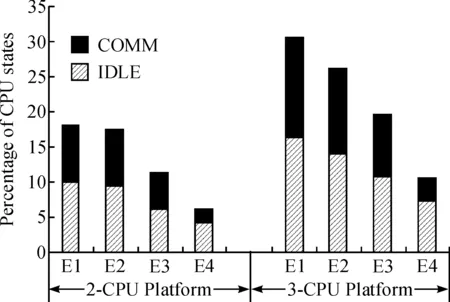
图8 IDLE和COMM CPU状态组件的百分比Fig.8 Percentage of IDLE and COMM CPU state component
3.2.2 MPEG2译码器
MPEG2视频译码器的Simulink功能模型更加复杂,包含49个S函数,18个延迟,186条数据链路,28个IAS,4个FIS(for-iteration subsystems),以及72个预定义Simulink模块. 实验基于不同的CPU平台进行,并采用一个10帧CIF MPEG2(common intermediate format MPEG2)视频比特流作为输入.
如图9所示,在4、5、6、8-CPU平台上,性能提升18.4%~26%,同时发现,性能的提升量随着处理器数量的增加而增加. 为了进一步分析结果,统计了不同平台上通信和空闲状态的处理器利用率.相较于E1,在采用粗粒度通信优化后,E2平均减少了30.4%的通信状态和18.5%的空闲状态.同时由于调度策略优化,E3分别减少了36.5%的通信状态及34.2%的空闲状态. 相较于E3,在使用细粒度通信优化后,E4减少了85.4%的通信状态和48.8%的空闲状态. 说明每一种通信优化粒度都能通过减少通信和空闲状态提高处理器的利用率,有效提升性能. 更重要的是,本文提出的基于ILP方法的多粒度通信优化的映射与调度策略(E4),能够同时利用粗粒度和细粒度通信优化,减少通信开销及空闲时间,从而显著提升系统性能.
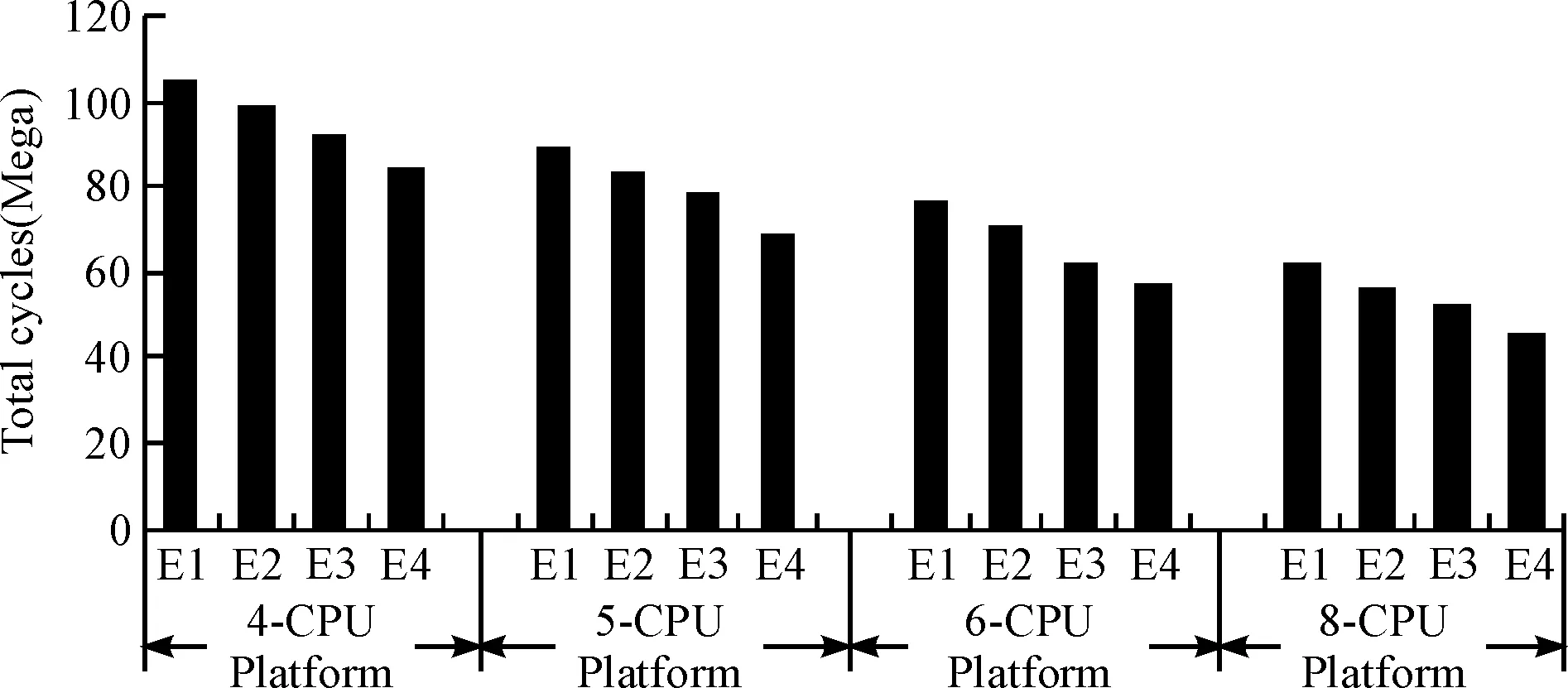
图9 MPEG2各实验组的总执行周期数Fig.9 Total execution cycles of each set in experiment of MPEG2
4 结束语
为了提升MPSoC应用程序的性能,提出了一种新颖的映射和调度策略,实现Simulink模型的最小化通信开销. 该策略采用ILP方法,结合不同粒度的通信优化特点,减少了通信时间和空闲时间的通信开销. 基于MJEPG和MPEG2解码器的实验结果,验证了该策略的有效性.在未来的工作中,将探索更为复杂的环图应用模型的高效通信优化技术.
[1] COTTON S, MALER O, LEGRIEL J, et al. Multi-criteria optimization for mapping programs to multi-processors[C]∥IEEE International Symposium on Industrial&Embedded Systems.Vasteras: IEEE Computer Society, 2011:9-17.
[2] FERRANDI F, LANZI P L, PILATO C, et al. Ant colony heuristic for mapping and scheduling tasks and communications on heterogeneous embedded systems[J]. IEEE Trans Comput-Aided Des Integ Circuits & Syst,2010,29(6):911-924.
[3] HUANG K, YU M, ZHANG X M, et al. ILP based multithreaded code generation for Simulink model[J]. IEICE Trans Inf & Syst,2014,97(12):3072-3082.
[4] YAN R J, HUANG K, YU M, et al. Communication pipelining for code generation from Simulink models[C]∥IEEE International Conference on Trust. Melbourne: IEEE Computer Society,2013,8(1):1893-1900.
[5] BRISOLARA L, HAN S, GUERIN X L,et al. Reducing finegrain communication overhead in multithread code generation for heterogeneous MPSoC[C]∥SCOPES’07. Nice:ACM,2007,11(1):81-89.
[6] HAN S, CHAE S, BRISOLARA L, et al. Memory-efficient multithreaded code generation from Simulink for heterogeneous MPSoC[J]. Des Autom Embed Syst,2007,11(4):249-283.
[7] KAHN G, MACQUEEEN D. Coroutines and networks of parallel processors[C]∥Proceedings of the IFIP Congress 77. Toronto: North-Holland Publishing Company,1977:993-998.
[8] LEE E A, PARKS T M. Dataflow Process Networks[M]. Norwell: Kluwer Academic Publishers,2001,83(5):59-85.
[9] MATHWORKS. Math works 发布包含MATLAB和Simulink 产品系列的Release2016b[ER/OL].http://www.mathworks.com/products/simulink.html.
[10] HAN S I, CHAE S I, JERRAYA A A. Functional modeling techniques for efficient SW code generation of video codec applications[C]∥ASP-DAC’06. Yokohama:ACM,2006,13(13):935-940.
[11] HAN S I, CHAE S I, BRISOLARA L, et al. Simulink®-based heterogeneous multiprocessor SoC design flow for mixed hardware/software refinement and simulation[J].Integ VLSI J, 2009,42(2):227-245.
[12] C-SKY, Inc. C-Sky IP authorization,2016[EB/OL] http:∥www.csky.com/solution/CPU-IP-shou-quan.htm.
[13] HAN S I, BAGHDADI A, BONACIU M, et al. An efficient scalable and flexible data transfer architecture for multiprocessor SoC with massive distributed memory[C]∥DAC’04.SanDiego:IEEE,2004:250-255.
MPSoC mapping and scheduling approach with multi-grained communication optimizations.
CAI Tiantian1, XI Wei1, GUO Xiaobin1, YAO Hao1, HUANG Kai2
(1.ElectricPowerResearchInstitute,CSG,Guangzhou510080,China; 2.CollegeofInformationScience&ElectronicEngineering,ZhejiangUniversity,Hangzhou310027,China)
As the number of processors in an embedded system increases, mapping and scheduling become key challenges of system software designers. To achieve high performance, communication overheads should be addressed during mapping and scheduling process. Most existing mapping and scheduling approaches exploit coarse-grained system level communication optimizations from a global view, and standalone communication optimization techniques adopt fine-grained thread level communication optimizations from a local view. While these communication optimization techniques can improve performance, they still face problems. In this work, an integer linear programming (ILP)-based mapping and scheduling approach is proposed with multi-grained communication optimizations for Simulink models, which can efficiently exploit the advantages of different granularities of communication optimizations and complement their disadvantages. It conducts coarse-grained communication optimization during the mapping process and fine-grained communication optimization during the scheduling process. Experimental results show that the proposed approach can improve the overall system performance significantly.
integer linear programming; mapping and scheduling; multi-grained communication optimizations

2016-10-24.
南方电网科学研究院“电力二次设备芯片研制方案研究项目”.
蔡田田(1982-),ORCID:http//orcid.org/0000-0001-9475-1654,女,硕士,高级工程师,主要从事智能电网技术、电力电子技术及SoC芯片相关技术研究,E-mail:caitt@csg.cn.
10.3785/j.issn.1008-9497.2017.04.008
TP 36
A
1008-9497(2017)04-429-08
Journal of Zhejiang University(Science Edition), 2017,44(4):429-436
