稀疏混合图随机跳跃Web对象多标签半监督分类*
2017-07-31汪忠国谭芳芳
汪忠国,吴 敏,谭芳芳
1.安徽信息工程学院,安徽 芜湖 241000
2.中国科学技术大学 软件学院,合肥 230051
3.安徽信息工程学院 基础教学部,安徽 芜湖 241000
稀疏混合图随机跳跃Web对象多标签半监督分类*
汪忠国1+,吴 敏2,谭芳芳3
1.安徽信息工程学院,安徽 芜湖 241000
2.中国科学技术大学 软件学院,合肥 230051
3.安徽信息工程学院 基础教学部,安徽 芜湖 241000
+Corresponding author:E-mail:wguoshzhuo@sina.com
WANG Zhongguo,WU M in,TAN Fangfang.Sparsem ixed graph random jum p transition policy forWeb objectmulti-labelclassification.Journalof Frontiersof Computer Scienceand Technology,2017,11(7):1166-1174.
针对Web对象的多标签分类的自动标注过程中,存在的标记数据耗时和不足导致分类性能不高的问题,提出了基于稀疏混合图随机跳跃变迁策略的Web对象多标签分类算法。首先,在构建Web对象亲和子图和标签相关子图基础上,通过权重自适应方式构建Web对象标签分类的混合图,实现半监督形式的自动标注,解决人工标注存在的耗时问题;其次,针对混合图求解问题,利用随机跳跃变迁策略实现混合图对象与预测标签间的概率分配,实现未标记的Web对象所属类别标签的概率估计,并获得其top-k最高相关性分数;最后,在UCI Web测试集和真实大数据上进行测试,结果显示所提算法的Rand指标要优于对比算法,验证了算法的有效性。
大数据;随机跳跃;Web对象;标签分类;自动标注
1 引言
随着互联网的迅速发展,异构网络对象大量出现,自动标注已成为搜索、排名和索引应用中越来越重要的组成部分[1-2]。Web对象的注释可利用多标签分类方式实现,一个对象可从受控词汇表分配一个或多个标签[3]。全监督学习分类过程,需要足够量的标记数据,以进行有效的训练[4]。但在现实应用中,数据的标记过程非常耗时,如何利用未标记数据[5],有效减少所需的多标签对象分类标记数据量,是研究的热点。
当前,在半监督多标签分类领域的研究主要有如下4个方向:(1)非负矩阵分解[6],该方法寻找非负矩阵,根据设定的更新法则获得满足非负矩阵相等的乘子,但其存在矩阵构建复杂和计算较为耗时的问题;(2)基于图形的方法[7],该方法将Web标签分类过程抽象为图形,分类过程更为直观;(3)基于内容的特征方法[8],此类方法需要用到标签特征,但是特征提取算法会影响标签的分类效果;(4)主题模型方式[9],即对文字隐含主题建模,克服传统信息检索存在的文档相似计算问题,效果很好,唯一缺点是不够直观。
近年来研究发现,图形方法是半监督多标签分类最为有效的方法[10],该方法将整个数据集作为一个图,其中的节点对应于标记和未标记的数据点(实例),边缘则反映了数据点之间的相似性。但是,该方法构建图的方式有许多种,例如K NN(K-nearest neighbor)图或球图,并且这些图具有一定的局限性,如对数据噪声敏感性。同时所提出的技术包括采用节点或边采样进行原始图构建的方式,但是此类方法需要一定的专业知识,会引入额外的计算成本。同时,现有图形方法在处理多标签分类时,没有充分考虑标签之间的相互依存关系[11]。虽然简化了问题设计,但会导致标签分类算法效果不理想,特别是对于依存关系多标签,分别执行标签分类,会相应增加算法实现难度,不利于标注效果提升。
对此,提出了一种基于稀疏混合图随机跳跃变迁Web对象多标签半监督分类算法,其将对象和标签融合为单一混合图,其中包含对象亲和子图和标签相关子图,以及连接对象和标签的边缘。通过添加对象和标签的权重边缘进行混合图构建。然后,通过随机跳跃过程实现混合图对象标签关联,并对未标记对象标签连接进行概率估计。
本文贡献为:(1)提出以对象标签混合图为基础的半监督学习方法进行网络对象的自动标注,并利用稀疏表示和随机游动的混合对象标签图进行权重自适应分配。(2)探索利用参数自由最小化实现稀疏图重建,可对网络对象特征尺寸远大于样本大小的相似性进行计算。(3)利用雅虎真实数据验证所提算法的有效性。
2 问题定义
给定一组标记和未标记的Web对象及一组标签,目标是为每个未标记的Web对象自动分配k个标签。可通过执行随机跳跃变迁策略对混合Web对象标签图进行标签分配概率计算。所采用的混合图G包含两个独立子图,分别命名为Web对象亲和子图G和标签相关子图GL,子图G和GL通过一组Web对象标签边缘E(L)相连,表示Web对象和标签之间的分配关系。
定义1(Web对象亲和子图)定义G=(V,E),其为有向图,V中的每个顶点表示中的一个Web对象,每个边缘E连接权重表征Web对象间的亲和关系。
定义2(标签相关子图)定义GL=(VL,EL),其为无向图,VL中的每个顶点表示L中的一个标签,每个边缘EL连接权重表征标签间的相关性。
定义3(混合图)定义G=(V,E),其为有向图,顶点 集 为 V=V×VL,边 缘 集 为 E=E()⋃E(L)⋃E(L),E(L)中的每个边缘表征对应Web对象和节点间的关系。
形式上,自动标注任务可表示成多标签Web对象分类问题:对于给定标签和未标记Web对象集合={o1,o2,…,on},及 k个标签集 L={l1,l2,…,lk},每个Web对象oi可提取一个特征点并表征为特征向量vi∈Rm,其对应标签子集li⊆Rk。Web对象亲和子图G中,Web 对象之间的相似性测度为 W∈Rn×n,W(i,j)表示Web对象oi和oj之间的相似度;类似的,标签相关子图WL∈Rk×k,表征标签 li和 lj间的关联度。假定前r个Web对象已标记,目标是从L中选择最合适的标签对剩余n-r未标记Web对象进行标签预测。对于向量w,||w||1表示w的L1范数,I表示单位矩阵,Λ表示逆矩阵,W表示给定矩阵。
3 混合图构建
如前所述,现有图形方法,例如K NN图或球图,对数据噪声存在较大敏感性,其采用的通过节点或边采样进行原始图构建的方式,需要专业知识,会增加额外的计算成本。对此,这里针对Web对象和标签的标注问题,通过构建Web对象亲和子图和标签相关子图,将标注问题设计为两子图节点间的权重分配问题,实现对象标签的自适应概率分配。
3.1 Web对象亲和子图
在对象亲和子图中,每个顶点表示一个Web对象特征向量。加权边缘能够反映对象之间的亲和力。对象亲和子图是基于稀疏表示构造的,而不是传统的一对一的两两相似图。因此,它对数据噪声不敏感,可有效避免冗余和信息分散,并且这种稀疏重建过程能够更好地捕捉对象间的语义关系,从而改善对象的半监督分类。
给定标记Web对象矩阵,其由所有类 Α={Α1,Α2,…,Αk}构成,其中 Αk∈Rm×nk为第k个类别的训练样本。为表征训练Web对象的结构信息,需从原始Web对象 Α′={Α1′,Α2′,…,Αk′}中进行字典学习,其中Αk′∈ Rm×dk,dk≤nk。这里采用稀疏非负矩阵分解来生成字典。利用稀疏非负矩阵分解将原标签Web对象转化成压缩格式,可保留原始Web对象的结构信息。对子数据集进行矩阵因式分解:


则整个数据集可表示为V=U⋃A,其中U为未标记Web对象。对于给定Web对象可表示成特征向量集V={v1,v2,…,vn},其中vi∈Rm,可基于稀疏学习框架构建G的l1范数图,Web对象的每个特征向量都应是具有非负系数的数据集内所有其他特征向量的线性组合。稀疏表示给出了每个特征向量和其他特征向量间的关系,可以一对一方式构建Web对象的亲和力图。
虽然底层组合优化性质导致稀疏解决方案求解为NP难问题,稀疏表示仍可通过凸l1范数最小化进行修复。对于给定Web对象vi,其与其他Web对象的关系可通过vi=Viw获得,其中vi∈Rm是重建样本,w∈Rn是重建系数,其由除vi外其余Web对象的K个标签类别进行构建,可表示为如下最小化问题:

其中,||·||1为w的l1范数,趋向于最小化重建误差的l1范数。利用线性规划算法求解该方程,要求vi=Viw为确定系统的线性方程组。特征维数须小于样本空间维数,即m≪n。然而在实验中,数据集并不符合该前提条件。例如,雅虎艺术数据集包含大约5 000个样本,但其特征维度超过20 000,即m≫n。因此,式(3)无精确解。为此,可通过m×m单位矩阵将超定系统Vi转化为不确定系统,则式(3)可转换为:


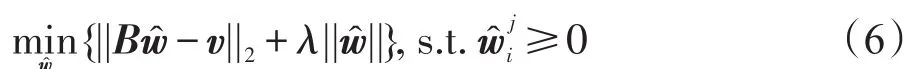
其中,λ为平衡重建误差和稀疏度的正则化标量。使用截断牛顿内点法来解决该优化问题。算法1给出基于稀疏图重建方法的Web对象亲和子图构建方法。
算法1亲和子图构建方法


3.2 标签相关子图
标签相关子图用于捕获类别标签间的相互关系,其中顶点表示成二进制向量,以此表达类别标签。通过标签共生的相似性和内核为基础的相似性计算,可对标签间的相关性进行估计。使用余弦相似性来衡量标签的相关性,构造标签矩阵C∈RK×N,其中每行表示每个训练Web对象中出现的标签,每列表示每个训练Web对象的标签分配。Ci,j∈{0,1}表示第 j个Web对象的第i个标签的出现概率。这里,标签矩阵是非常稀疏的。对此矩阵进行平滑操作,用标签小的非零概率值取代概率为0的矩阵值。平滑概率为:

其中,n(lj,O)表示Web对象分配的标签lj数量;||为训练Web对象数量。则C可表示为:

可归一化为:

其中,sli,lj评价li和lj之间的共现频率,余弦相似性为:

因此,共生的相似性为:

其中,λ是超定参数;li是二进制向量。要表现出第二直觉,采用内核相似性,令Γli和Γlj分别为包含标签li和lj的Web对象集,则基于内核的li和lj相似性为:

其中,K是给定Web对象vi的近邻数目,其联系标签为li;vi和vj分别表示对应标签li和lj的Web对象特征。子图权值矩阵可通过结合两成对标签进行相似性计算:
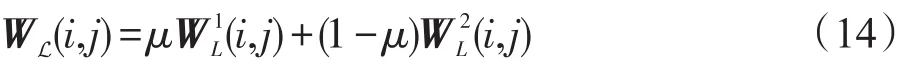
3.3 子图融合
在获得Web对象亲和子图G和标签相关子图GL后,可结合两图并通过添加Web对象标签的边缘进行混合图G构建。不同的标签对特定Web对象有不同贡献,可通过标签间的链接权重表征。与等值标签权重不同,这里自适应地计算并分配不同的权重到连接边缘中:


Fig.1 Sub graph fusion process图1 子图融合过程
子图融合过程包含两步:边缘添加和权重赋值。这里以图1为例对子图融合过程进行阐述。图1中对象17在对象的亲和图中分配有3个标签“Science”、“Food”和“Industry”。在此情形下,首先,3个对象标签的边缘被添加在混合图中,并将其连接在一起。其次,注意到不同的标签对特定对象有不同的贡献,例如对于对象17“Science”标签相对于“Food”标签更为重要,则对于“Science”标签与对象17的连接权重应赋予更大的值,这里采用的边缘权重计算公式见式(15)。
4 混合图的随机跳跃变迁策略
本章主要针对3.3节的子图融合图,在对象节点与标签节点边缘权重基础上,进行自动标注研究,特别是针对未标记对象,设计一种高效的标注策略。
4.1 概率矩阵定义
在获得混合图G后,计算每个未标记Web对象的标签相关性,高相关性表征正确标签分配具有较高的概率。利用这种相关性指导标注过程,可避免标注的盲目性,提高标注效率。首先,需要计算混合图G的亲和矩阵:

其中,W可根据算法1计算;WL可根据式(14)计算;WL可根据式(15)计算,。从权重矩阵W获得的转移概率矩阵P为:

其中,P和PLL分别是Web对象亲和子图G和标签相关子图GL的内部转移概率矩阵;PL和PL分别为G和GL间的内部转移概率矩阵。然后,设置跳跃概率α∈[0,1],表示子图间的随机跳跃变迁概率。并不是G中的所有顶点,都与Web对象标签的边缘相连接。例如,未标记Web对象不分配任何标签,则没有与任何Web对象标签边缘连接。表示Web对象oi至少与1个Web对象标签边缘连接。在随机跳跃变迁过程中,如果其位于G中一个Web对象顶点,则其至少与1个Web对象标签边缘连接,它将以概率α跳到标签相关子图GL,或以概率1-α继续停留在Web对象亲和子图G。
现在用如下公式转换矩阵对其进行描述。
(1)POO(i,j)与矩阵W成比例,可根据算法1获得:

因为W表征Web对象间的相似度,表示Web对象亲和子图G中顶点i和 j的权重边缘和。
(2)PLL(i,j)是从Web对象到标签的转换概率矩阵,其与矩阵WL成比例。

(3)PL(i,j)是从Web对象到标签的转换概率矩阵,其与矩阵WL成比例。

(4)PL(i,j)是从标签到Web对象的转换概率矩阵,等于PL(i,j)的转置。


其中,D、DL、DL和 DLT为对角矩阵,可得:

4.2 随机跳跃变迁策略
传统图形方法采用节点或边采样方式进行标记,但是Web中对象和标签的数量巨大,采样率设置及采样的无序性会降低标记效果。因此,这里通过在混合图G中Web对象和标签节点进行随机跳跃变迁,来估计一个未标记Web对象可能属于的类别标签。该方法特点是找到对于给定未标记Web对象的类别标签,其具有top-k最高相关性分数。该方式充分考虑节点间的相关性,可对标记过程进行指导,提高自动标注效果。
随机跳跃变迁思路:使用对象的亲和力稀疏图重构提取结构元文本,利用标签相关,通过线性组合捕捉标签共生的两两相关性。通过随机游走的自适应权重分配,进行混合图构造来推断标签和对象之间的概率分配关系。通过随机跳跃变迁策略沿边缘以概率1-c跳跃到邻近顶点,或者以概率c跳回到顶点i。令ui(j)表示从顶点i到顶点 j的稳定状态访问速率,可用来估计顶点i和顶点 j之间的亲和力。
相关性评分计算过程如下:对于给定的未标记测试Web对象oi,其稳态概率可计算为:

其中,πoi为重启向量,初始化πoi为零向量,第i个条目设置为1。然后执行随机跳跃变迁策略直至收敛。融合概率向量uoi表示从Web对象oi开始的混合图G中的V()和V(L)的所有顶点的稳态访问概率,主要关注点在V(L)的访问概率,利用其可计算未标记Web对象oi的分配概率。
算法2随机跳跃变迁策略
输出:等级收敛分配概率
1.for i=1:t do
3. 预计算并存储Λ=(S-1-αVU)-1;
4. 计算并输出uoi=(1-α)(voi+αU∧Vvoi);
5.end
4.3 时间复杂度分析
假定混合图稀疏矩阵中,顶点仅与k组近邻节点关联,则矩阵每行至多有k组非零特征元素。假定tmax为迭代过程的次数上限,迭代过程的时间复杂度是O((n-|T|)k|T|tmax)。因为实验过程中tmax与k均为用户所指定,且为常值,所以可直接将其移除,而不会对时间复杂度O((n-|T|)|T|)产生影响。此外,相似度矩阵计算成本为O(|T|nk)。随机跳跃过程需要O(|T|3)计算复杂度。在对真实大型数据进行处理时,会存在|T|远小于n的情形,且此情形可忽略其对算法计算复杂度的影响。因此该过程的计算复杂度简化成线性复杂度O(n)。若考虑相似度稀疏矩阵的计算复杂度O(n2),那么本文算法的计算复杂度可表示为O(n2)。
5 实验分析
5.1 实验设置
本节实验选取的对比算法为光谱学习(spectral learning,SL)[12]、高斯内核K均值(sem i-supervised kernelK-means,SSKK)[13]、谱正则化约束聚类(constrained clustering via spectral regularization,CCSR)[14]及成对度量约束K-均值(metric pairw ise constrainedK-means,MPCK)[15]4种半监督分类方法,在UCI测试集及真实测试集上进行实验验证。表1给出本文使用的8组测试集信息,共涉及4组UCIWeb测试集及4组大型Web真实测试集。

Table1 Experimental testsets表1 实验测试集
表 1中,Parkinsons、Tissue和 Breast均为医学Web对象集,Ionosphere为物理Web对象集,TDT2为文本Web对象集,MNIST为数字识别Web测试集,Letter为英文字母Web测试集,CMU PIE是人脸Web测试集。
为对5种算法进行公正评测,这里基于Rand标准进行评价[12]:

式(28)中,TP为同类对象正确划分数量;TN为不同类对象正确划分数量。可见Rand指标越大表明算法的分类效果越好。硬件设置:CPU i5-4510,RAM 4GB ddr3-1 600,系统Win7旗舰。
5.2 实验结果
5.2.1 UCI数据集实验
图2给出5种标签聚类方法在选取的4组UCI Web测试集上Rand指标学习过程曲线。
根据图2给出的5种对比算法在4组UCIWeb测试集上的Rand指标曲线对比情况可知,本文算法的Rand指标要整体上优于选取的对比算法。图2(a)中,在约束数量小于300时,本文算法的Rand指标要差于CCSR和SSKK算法。而图2(d)中,在约束数量小于200时,本文算法的Rand指标要差于CCSR算法。图2(b)和图2(c)中,在约束数量较低时,几种算法的Rand指标差距不大,这表明本文算法在约束数量多时性能优势更为明显。
5.2.2 真实测试集实验
图3给出5种标签聚类方法在选取的4组真实测试集上Rand指标学习过程曲线。
根据图3给出的5种对比算法在4组真实Web测试集上的Rand指标曲线对比情况可知,本文算法的Rand指标要更为明显优于对比算法。图3(a)和图3(c)显示本文算法在TDT2测试集和Letter测试集上,在选取约束数量情况下,要明显优于对比算法。图3(b)和图3(d)显示本文算法在MNIST测试集和CMU PIE测试集上,在约束数量小于60时,与SSKK算法相差不大,但是随着约束数量升高,本文算法要明显优于选取的对比算法。上述实验结果显示,本文算法在真实测试集上具有与在UCI构造测试集上相近的测试结果,显示了本文算法对于实际情况的适应性。
6 结束语

Fig.2 Comparison of UCIWeb testsets图2 UCIWeb测试集对比

Fig.3 Comparison of real testsets图3 真实测试集对比
本文提出了基于稀疏混合图随机跳跃变迁策略的Web对象多标签分类算法,有效解决了Web对象多标签分类的自动标注过程中计算性能不高的问题。算法用到了混合图概念和随机跳跃变迁策略,并通过UCIWeb测试集和真实大数据测试,验证了其有效性。下一步工作计划研究其他标签相似性计算方法,并研究其如何影响标签分类精度,以及利用过渡概率与边权重实现随机跳跃变迁策略性能提升等。
References:
[1]Chen Zezhi,Ellis T.Semi-automatic annotation samples for vehicle type classification in urban environments[J].IET IntelligentTransportSystems,2015,9(3):240-249.
[2]Khosrow-Khavar F,Tavakolian K,Blaber A P.Automatic annotation of seismocardiogram w ith high-frequency precordial accelerations[J].IEEE Journal of Biomedical and Health Informatics,2015,19(4):1428-1434.
[3]Zhang Jinzeng,Wen Jie,Meng Xiaofeng.Multi-tag route query based on order constraints in road networks[J].Journal of Computers,2012,35(11):2317-2322.
[4]He Ping,Xu Xiaohua,Lu Lin.Sem i-supervised clustering via two-level random walk[J].Journalof Software,2014,25(5):997-1013.
[5]Rad R,Jamzad M.Automatic image annotation by a loosely joint non-negative matrix factorisation[J].IET Computer Vision,2015,9(6):806-813.
[6]Cabral R,De la Torre F,Costeira JP.Matrix completion for weakly-supervised multi-label image classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(1):121-135.
[7]Passino G,Patras I,Izquierdo E.Aspect coherence forgraphbased semantic image labelling[J].IET Computer Vision,2010,4(3):183-194.
[8]Contractor D,Negi S,Popat K.Smarter learning content management using the learning content hub[J].IBM Journalof Research and Development,2015,59(6):1-9.
[9]Sabuncu M R,Yeo B T T,Van LeemputK.A generativemodel for image segmentation based on label fusion[J].IEEE Transactionson Medical Imaging,2010,29(10):1714-1729.
[10]Karasuyama M,Mam itsuka H.Multiple graph label propagation by sparse integration[J].IEEE Transactions on Neural Networksand Learning Systems,2013,24(12):1999-2012.
[11]Feng Lin,Wang Jing,Liu Shenglan.Multi-label dimensionality reduction and classification w ith extreme learningmachines[J].Journal of Systems Engineering and Electronics,2014,25(3):502-513.
[12]Kamvar SD,K lein D,Manning C D.Spectral learning[C]//Proceedings of the 18th International Joint Conference on Artificial Intelligence,Acapulco,Mexico,Aug 9-15,2003.San Francisco,USA:Morgan Kaufmann Publishers Inc,2003:561-566.
[13]Kulis B,Basu S,Dhillon I,etal.Semi-supervised graph clustering:a kernel approach[J].Machine Learning,2009,74(1):1-22.
[14]LiZhenguo,Liu Jianzhuang,Tang Xiaoou.Constrained clustering via spectral regularization[C]//Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition,M iam i,USA,Jun 20-25,2009.Washington:IEEEComputer Society,2009:421-428.
[15]CaiDeng,He Xiaofei,Han Jiawei,etal.Graph regularized non-negativematrix factorization for data representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(8):1548-1560.
附中文参考文献:
[3]张金增,文洁,孟小峰.路网环境下访问序列受限的多标签路线查询算法[J].计算机学报,2012,35(11):2317-2322.
[4]何萍,徐晓华,陆林.双层随机游走半监督聚类[J].软件学报,2014,25(5):997-1013.

汪忠国(1985—),男,安徽芜湖人,2010年于中国科学技术大学获得硕士学位,现为安徽信息工程学院讲师,主要研究领域为数据挖掘。

WU M in was born in 1963.He received the M.S.degree from SoutheastUniversity in 1989.Now he is a professor and Ph.D.supervisor at University of Science and Technology of China.His research interest is educational informationization.
吴敏(1963—),男,安徽蚌埠人,1989年于东南大学获得硕士学位,现为中国科学技术大学教授、博士生导师,主要研究领域为教育信息化。

TAN Fangfang was born in 1979.She received the M.S.degree from Hunan Normal University in 2010.Now she isa lectureratAnhui Instituteof Information Technology.Her research interest is fuzzymathematics.
谭芳芳(1979—),女,湖南衡阳人,2010年于湖南师范大学获得硕士学位,现为安徽信息工程学院讲师,主要研究领域为模糊数学。
Sparse M ixed Graph Random Jum p Transition Policy for Web Object M ulti-Label Classification*
WANG Zhongguo1+,WUM in2,TAN Fangfang3
1.Anhui Institute of Information Technology,Wuhu,Anhui241000,China
2.Schoolof Software Engineering,University of Science and Technology of China,Hefei230051,China
3.Foundation Teaching Department,Anhui Institute of Information Technology,Wuhu,Anhui241000,China
In order to solve the problem of time consum ing and insufficient for labeling data,which leads the low computationalefficiency inmulti-label classification ofWeb objects,this paper proposes amulti-label classification algorithm based on sparsem ixed graph random jump transition strategy forWeb object.Firstly,based on the construction of theWeb objectaffinity graph and tag correlation,weightadaptivemethod is used to constructa hybrid graph ofWeb object label classification,which realizes the automatic annotation of sem i-supervised form and solves the time consuming problem ofmanualannotation;Secondly,in order to solve the problem ofm ixed graph,the random jump transition strategy is used to get the probability distribution between them ixed graph and the prediction tag,which realizes the probability estimation of the class label of the unlabeledWeb objectand obtains the highesttop-k correlation score;Finally,through the teston UCIWeb datasetand realbig data,the results show that the Rand index of the proposed algorithm is better than the selected contrast algorithms,which verifies the effectiveness of the proposed algorithm.
big data;random jump;Web object;labelclassification;automaticmarking
gguowasborn in 1985.He
theM.S.degree in educational technology from University of Science and Technology of China in 2010.Now he is a lecturer atAnhui Institute of Information Technology.His research interest is datam ining.
A
:TP181
*The Natural Science Research Projectof Education Departmentof AnhuiProvince underGrantNo.KJ2016A075(安徽省教育厅自然科学研究项目).
Received 2016-05,Accepted 2016-08.
CNKI网络优先出版:2016-08-01,http://www.cnki.net/kcms/detail/11.5602.TP.20160801.1406.004.htm l
