融合多结构信息的中文句法分析方法*
2017-07-31赵国荣王文剑
赵国荣,王文剑
山西大学 计算机与信息技术学院,太原 030006
融合多结构信息的中文句法分析方法*
赵国荣,王文剑+
山西大学 计算机与信息技术学院,太原 030006
+Corresponding author:E-mail:w jwang@sxu.edu.cn
ZHAO Guorong,WANGWenjian.M ethod for Chinese parsing based on fusion of multiple structural information.Journalof Frontiersof Computer Scienceand Technology,2017,11(7):1114-1121.
句法分析是自然语言理解的一项基础技术,是迈向深层语言理解的基石。目前常用的句法分析方法的语法模型建立在上下文无关文法的假设上。事实上,短语结构树的节点之间具有很强的上下文相关性,充分利用结构信息,可进一步提高句法分析的准确性。融合了句法结构树中的多结构信息(在非终节点中增加父亲节点及左、右姐妹节点等标记)以加强语法规则的上下文约束,并采用结构化支持向量机的方法对句法进行了分析。实验表明,该融合多结构信息的句法分析方法可以消解结构歧义,提升句法分析精确率和F1值。
结构化支持向量机;上下文无关文法;结构上下文相关;中文句法分析
1 引言
句法分析是自然语言处理的关键性问题之一。对句法分析进行可计算化处理,句法分析算法和语法模型是两个重要的元素,其中语法模型无论是使用统计的方法,还是使用单纯的规则,在进行句法分析时都需要建立一种模型。最早的语法模型是简单的上下文无关的语法模型(context-free grammar,CFG)[1]。但是CFG是在一些非常理想化的独立性假设的基础上建立的,它的规则的建立只和其孩子节点有关,因而这些假设忽略了句法树中其他许多隐含的信息。为了得到更好的基于短语结构的句法分析效果,一些算法的研究集中在挖掘短语结构树的上下文相关的信息上,通过增加丰富的结构信息和词汇信息等来提升句法分析的效果。
最具代表性的研究就是在概率上下文无关文法[2](probabilistic context-free grammar,PCFG)中增加结构上下文相关的策略。文献[3]尝试了祖先节点相关、父亲节点相关等几种结构上文相关的策略;文献[4]尝试了加入结构下文孩子节点相关的策略,构成结构下文相关的概率语法模型;文献[5]加入了每个短语节点的父亲节点和左、右姐妹节点的结构上下文信息,这些方法都对突破上下文无关语法研究中的独立性假设进行了尝试,都是对经典PCFG模型进行的优化。文献[6]采用机器学习方法——结构化支持向量机(structural support vectormachine,SSVM)对基于短语结构的中文句法进行分析,语言模型采用的是上下文无关文法。本文的工作是尝试融合句法分析树中节点的结构信息,研究使用结构化支持向量机对中文句法进行分析时所产生的影响,实验证明它可以提高句法分析系统的精确率和F1值。
2 结构化支持向量机方法简介
在现实世界中,需要处理的大部分数据(如网状结构数据、队列结构或树形结构等)都比较复杂,而且数据之间相互依赖,具有特定的结构化关系,传统的支持向量机[7]已经不适合处理这些复杂的数据。为了解决传统支持向量机在处理复杂数据时的难题,Hofmann和Joachims等人首次提出了结构化支持向量机[8-9],它可以根据不同的应用领域设计不同的结构化特征函数去拟合数据,从而有效地处理结构化数据。
结构化支持向量机是一种基于判别式的学习模型,使用结构化支持向量机的关键是构造出样本的输入与输出对之间的一个映射函数 f:x→y。当使用结构化支持向量机进行句法分析时,f:x→y中 f表示的意思是输入句子X到输出短语结构树Y的一个映射。在构造函数 f时,关键任务是需要学习一个基于输入/输出对的判别式函数F:X×Y→ℜ,通过使输出变量最大化的方法,实现对输出结果预测的目的。结构化支持向量机的目标函数[10-11]为:

F是基于输入/输出组合特征表示ψ(x,y)的线性函数:

式(1)中带参数w的函数 f,假设它的经验风险为0,可以写成一个非线性约束的形式[8]:

式(3)可以等价转换为:

采用最大间隔法可以将式(4)转化为一个凸二次规划形式的最优化问题[10]:

为了容忍部分噪声和离群点,同时兼顾除靠近边界之外更多的训练点,在式(5)中引入松弛变量的软间隔,本文采用一阶范数ξ的形式[10]:
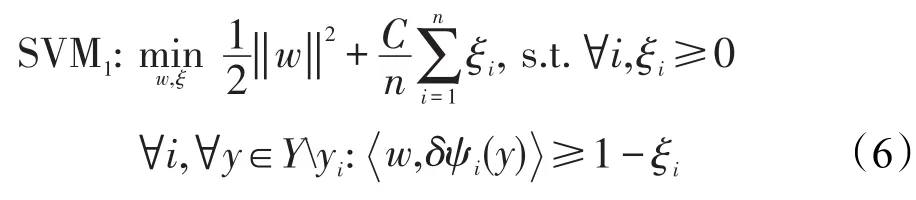
3 融合多结构信息的语法模型构造
文献[6]使用结构化支持向量机进行中文句法分析时,将文法限定为乔姆斯基范式的形式[2],其语法规则为:

这里A、B、C是非终结符,α是终结符。设x是需要进行句法分析的句子,Y是针对x分析出的若干个句法树的集合。假设最佳分析树为h(x),每棵句法树y中所有的语法规则的集合用rules(y)表示,每一个语法规则所对应的权值参数为wl,文献[6]使用的上下文无关文法模型为:

但是,在实际生活中自然语言具有很强的上下文相关性,上下文无关语法表现能力有限,当遇到结构依存的问题时就显得能力有限了。
上下文无关文法对句法树中的结构以及词汇等信息利用不足,无法描写句法树结构上隐藏的许多信息,如每个短语节点的父节点或(和)左、右姐妹节点的信息。文献[5]成功地将上下文相关信息(即父节点或(和)左、右姐妹节点的信息)加注到每个短语节点(即非终节点)上,使用概率上下文无关文法进行句法分析,并取得很好的效果。故本文也尝试将这些信息增加到使用结构化支持向量机进行句法分析的方法中,从而提升句法分析器的精度。假设将单纯地增加“父亲”、“左妹”或“右妹”信息称为一阶标注;那么增加“父亲+左妹”、“父亲+右妹”或“左妹+右妹”就是二阶标注;增加“父亲+左妹+右妹”为三阶标注。因为只是在非终节点上增加上下文相关的结构信息,所以语法规则(7)(8)的形式要发生变化。以语法规则(7)的形式变化为例,在每一个非终节点后用括号注明相关结构信息范畴。
一阶标注中增加父亲信息后,规则(7)的形式变换为:
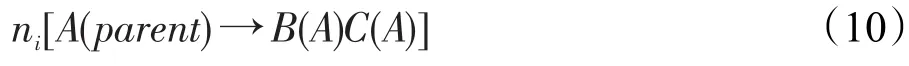
增加左妹信息后,规则(7)的形式变换为:

增加右妹信息后,规则(7)的形式变换为:
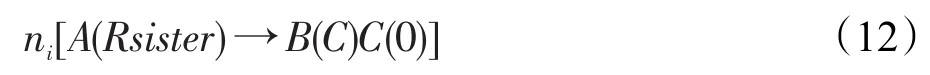
二阶标注中增加父亲+左妹信息后,规则(7)的形式变换为:
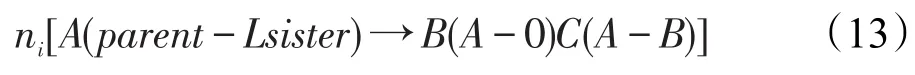
增加父亲+右妹信息后,规则(7)的形式变换为:
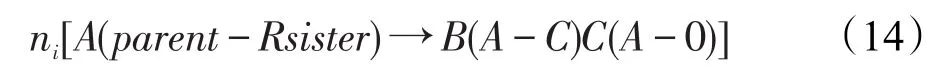
增加左妹+右妹信息后,规则(7)的形式变换为:
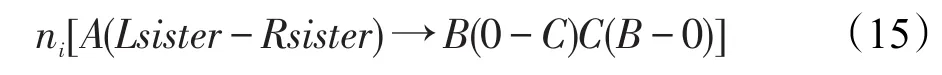
三阶标注增加父亲+左妹+右妹信息后,规则(7)的形式变换为:

语法规则(8)和规则(7)箭头左部的变化一样,因为箭头右边是终结符,所以不发生变化。简单地以增加父亲节点信息为例,短语的结构受到上层短语的制约。比如做主语的NP短语(NP位于S之下)和做宾语的NP短语(NP位于VP之下)的内部结构明显不同,这样可以快速帮助分析器抉择,减少不必要的子树生成。
4 结构化支持向量机特征函数的构建
在结构化支持向量机中,关键任务是特征函数ψ(x,y)的构造,在不同的领域需要构造不同的特征函数,从而和实际数据达到较好的拟合。因而特征函数构造合适与否会直接影响结构化支持向量机方法的有效性。图1是短语结构树的输入输出示例,图2为其在学习时构造的ψ(x,y)。
以在每个非终节点增加“父亲”、“父亲+左妹”和“父亲+左妹+右妹”节点为例,短语结构树以及构造的相对应的特征函数ψ(x,y)变换后的示例如图3所示。
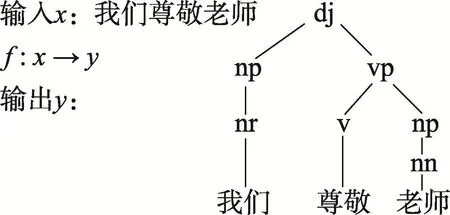
Fig.1 A sampleof inputand outputw ithout structural information图1 未增加结构信息的输入输出示例

Fig.2 Structural feature functionψ(x,y)图2 结构化特征函数ψ(x,y)
在使用结构化支持向量机进行句法分析时,在学习过程中要从树库自动抽取语法规则并进行统计,从而对模型进行分析。rj表示句子x的句法分析树y中每一个节点所对应的规则,aj表示规则rj出现的次数,wj表示每条规则相对应的权值。x表示一个句子,y表示其对应的有效句法树,wj表示每一个节点的权值,其和作为这个句法树的分值,F(x,为计算分值的函数。特征函数ψ(x,y)的构造就是由树库中出现的规则及其次数组成。对于给定的句子x,通过乔姆斯基算法[2](Cocke-Younger-Kasam i,CKY)找出符合文法的句法分析树集Y,再从句法分析树集中找出分值最大的F(x,y,w),y∈Y,即为所求句子的语法树。
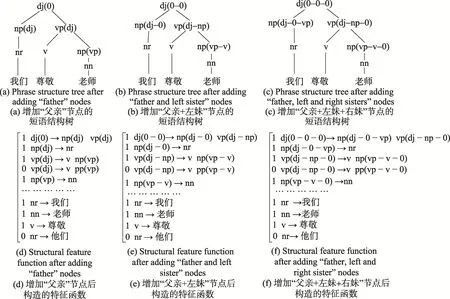
Fig.3 Structural feature function afteradding structural information in non-terminalnode图3 在每个非终节点增加结构信息后的结构化特征函数
5 实验及分析
本文为了测试结构化支持向量机在融合多结构特征后对中文句法分析精度的影响,进行了一组对比实验,并对结果进行了分析。
5.1 语料的预处理
5.1.1 语料1预处理
本文的实验语料1来自北京大学计算语言学研究所公开的北大微型树库的A语料[12]。该语料来自汉英机器翻译研究的测试题库,它句型多样,句子较短,不同短语组合的分布也很广,便于进行自动分析处理。
该语料一共有1 434句,表1是对实验语料集的情况统计[12],表2为实验语料举例。
选取表2中887句单句作为实验语料1,句长最长为19,最短为3,其平均句长为7.01;抽取其中787句作为训练语料,100句用作开放测试的语料。
在进行实验之前,需要对北大树库语料进行改写,比如:
[dj厂长/n[vp[vbar宣布/v了/u][np委员/n名单/n]]]
改写后格式为:

5.1.2 语料2预处理
本文的实验语料2采用文献[6]的语料,该语料来自PCTB宾州中文树库语料,从1 500个文档中提取2 000条(句长小于等于12词)单句,其中的1 850句用来进行训练,剩下的150句用来进行开放测试。
在进行本实验前,同样需要对从宾州中文树库选出来的2 000个单句进行预处理[13-14],将句法树上原有的空语类、指同索引和功能标记一概删除[5]。
例如,下面例句A转换成B的形式:

5.2 评价指标
本文使用PARSEVAL评价体系[2]作为句法分析模型的评价指标,选取其中的精确率(Precision,Pre)、召回率(Recall,Rec)以及F1值(Pre和Rec的调和平均值)对结果进行评价。

Table1 Statisticsofexperimentaldata表1 实验语料情况统计

Table 2 Samplesof experimentaldata表2实验语料句型举例
精确率表示所有句法分析结果中所有正确的成分比例;召回率表示句法分析结果中正确的成分占所有句法实际成分的比例;F1=2×Pre×Rec/(Pre+Rec)。
5.3 实验分析
实验使用的句法分析器是从网上公开下载的SVMstruct-cfg(http://www.cs.cornell.edu/tj/svm-light/svm_struct.htm)。使用经典结构化支持向量机SVM1方法,并与文献[6]中SVM2方法以及经典的概率上下文无关文法PCFG[2]在语料1和语料2上进行了实验对比分析。这里的PCFG采用和文献[5]相同的算法,即规则的概率估计采用最简单的相对频率法。结构化支持向量机选取的核函数为线性核,其中惩罚参数C=1.0,参数ε=0.01。在文献[6]中,在采用SVM2方法进行句法分析时,曾对选取F1损失函数和0-1损失函数进行实验对比,从实验结果中发现采用0-1损失函数要比F1损失函数的效果好,故本文在进行结构化支持向量机的实验时,都选取的是0-1损失函数。实验结果只采用开放测试的结果,结构化支持向量机的测试时间极短,可以忽略不计,故只对训练时间进行对比。对比实验结果如表3、表4所示。其中,Time表示模型在当前语料下的训练时间。
从表3、表4开放测试的实验结果可以看出:一阶标注、二阶标注、三阶标注的F1值均高于未进行标注的模型。它们之间在精确率上是三阶标注高于二阶标注,二阶标注高于一阶标注。在召回率上有高有低,出现了三阶标注的F1值低于二阶标注的情况。这是因为产生了数据稀疏的问题,当增加的结构信息越多时,句法分析的性能反而有下降的情况。同时,从表3、表4中可以看到,当增加一阶标注时,F1值有明显的升高,但是增加为二阶标注和三阶标注,F1值的增加就不太明显。另外,随着结构信息的增加F1值会提高,但是需要的训练时间也在不断增加,而且语料规模越大,训练消耗的时间也越来越多。从F1值的对比来看,总的情况是SVM2方法>SVM1方法>PCFG方法,但其中也有SVM1方法>SVM2方法的情况;从语料的训练时间对比来说,PCFG方法<SVM1方法<SVM2方法;因而从算法的F1值和训练时间双重考虑的话,增加了一阶、二阶、三阶标注后,SVM1方法要好于SVM2方法和PCFG方法。

Table3 Comparison of experimental resultsofadding structural information in Corpus1表3 北大微型树库(语料1)上增加各种结构信息的对比实验结果

Table4 Comparison of experimental resultsofadding structural information in Corpus2表4 宾州中文树库(语料2)上增加各种结构信息的对比实验结果
6 结束语
中文句法相比较西文来说其结构更加复杂,具有较强的上下文相关性,在进行句法分析时难度更大。本文使用结构化支持向量机的方法并融合多结构信息对中文句法进行分析,丰富了结构化特征函数的形式。同时,本文使用了两种语料,并对3种句法分析方法在这两种语料库上的实验进行了对比分析,说明增加了结构信息可以在一定程度上提高句法分析的精度。由于对结构化支持向量机在中文信息处理中应用的研究还比较粗浅,在以后很多问题处理中还需要继续进行深入的探讨。
[1]Charniak E.Statistical parsing w ith a context-free grammar and word statistics[C]//Proceedings of the 14th National Conference on Artificial Intelligence and 9th Conference on Innovative Applications of Artificial Intelligence,Providence,USA,Jul27-31,1997.Menlo Park,USA:AAAI,1997:598-603.
[2]Mallning CD,Schutze H.Foundationsof statisticalnaturallanguage processing[M].Cambridge,USA:M ITPress,1999.
[3]Zhang Hao,Liu Qun,BaiShuo.Structural contextconditioned probabilistic parsing of chinese[C]//Proceedings of the 1st Students'Workshop on Computational Linguistics,Beijing,Aug 20-23,2002.Beijing:Chinese Information Processing Society of China,2002:46-51.
[4]Chen Gong,Luo Senlin,Chen Kaijiang,et al.Method for layered Chinese parsing based on subsidiary context and lexical information[J].Journalof Chinese Information Processing,2012,26(1):9-15.
[5]Huang Changning,LiYumei,Zhou Qiang.Implicit information of treebank[J].Journal of Chinese Linguistics,2012(15):149-160.
[6]Zhao Guorong,WangWenjian.AChinese parsingmethod based on interdependent and structured input and output spaes[J].Journal of Chinese Information Processing,2015,29(1):139-145.
[7]Vapnik V.Statictical learning theory[M].New York:John Wiley&Sons,Inc,1998.
[8]Joachims T,Finley T,Yu C N J.Cutting-plane training of structural SVMs[J].Machine Learning,2009,77(1):27-59.
[9]Tsochantaridis I,Hofmann T,Joachims T,etal.Supportvector machine learning for interdependent and structured output spaces[C]//Proceedings of the 21st International Conference on Machine Learning,Banff,Canada,Jul 4-8,2004.New York:ACM,2004:104-112.
[10]Tsochantaridis I,Joachims T,Hofmann T,etal.Largemargin methods for structured and interdependent output variables[J].Journal of Machine Learning Research,2005,6(2):1453-1484.
[11]Joachims T,Hofmann T,Yue Yisong,etal.Predicting structured objectsw ith support vectormachines[J].Communicationsof theACM,2009,52(11):97-104.
[12]Zhou Qiang,Zhang Wei,Yu Shiwen.Building a chinese treebank[J].Journal of Chinese Information Processing,1997,11(4):42-51.
[13]Johnson M.PCFG models of linguistic tree representations[J].Computational Linguistics,2002,24(4):613-632.
[14]CollinsM J.A new statistical parser based on bigram lexical dependencies[C]//Proceedings of the 34th Annual Meeting on Association for Computational Linguistics,Santa Cruz,USA,Jun 24-27,1996.Stroudsburg,USA:ACL,1996:184-191.
附中文参考文献:
[3]张浩,刘群,白硕.结构上下文相关的概率句法分析[C]//第一届学生计算语言学研讨会,北京,2002.北京:中国中文信息学会,2002:46-51.
[4]陈功,罗森林,陈开江,等.结合结构下文及词汇信息的汉语句法分析方法[J].中文信息学报,2012,26(1):9-15.
[5]黄昌宁,李玉梅,周强.树库的隐含信息[J].中国语言学报,2012(15):149-160.
[6]赵国荣,王文剑.一种处理结构化输入输出的中文句法分析方法[J].中文信息学报,2015,29(1):139-145.
[12]周强,张伟,俞士汶.汉语树库的构建[J].中文信息学报,1997,11(4):42-51.

ZHAO Guorong was born in 1979.She is a Ph.D.candidate and associate professor at ShanxiUniversity.Her research interests include Chinese information processing andmachine learning,etc.
赵国荣(1979—),女,山西大同人,山西大学博士研究生、副研究员,主要研究领域为中文信息处理,机器学习等。

王文剑(1968—),女,山西太原人,2004年于西安交通大学获得博士学位,现为山西大学计算机与信息技术学院教授、博士生导师,CCF高级会员,主要研究领域为数据挖掘,机器学习等。
《计算机工程与应用》投稿须知
中国科学引文数据库(CSCD)来源期刊、北大中文核心期刊、中国科技核心期刊、RCCSE中国核心学术期刊、《中国学术期刊文摘》首批收录源期刊、《中国学术期刊综合评价数据库》来源期刊,被收录在《中国期刊网》、《中国学术期刊(光盘版)》、英国《科学文摘》(SA/INSPEC)、俄罗斯《文摘杂志》(AJ)、美国《剑桥科学文摘》(CSA)、美国《乌利希期刊指南》(Ulrich’s PD)、《日本科学技术振兴机构中国文献数据库》(JST)、波兰《哥白尼索引》(IC),中国计算机学会会刊
《计算机工程与应用》是由中华人民共和国中国电子科技集团公司主管,华北计算技术研究所主办的面向计算机全行业的综合性学术刊物。
办刊方针 坚持走学术与实践相结合的道路,注重理论的先进性和实用技术的广泛性,在促进学术交流的同时,推进科技成果的转化。覆盖面宽、信息量大、报道及时是本刊的服务宗旨。
报导范围 行业最新研究成果与学术领域最新发展动态;具有先进性和推广价值的工程方案;有独立和创新见解的学术报告;先进、广泛、实用的开发成果。
主要栏目 理论与研发,大数据与云计算,网络、通信与安全,模式识别与人工智能,图形图像处理,工程与应用,以及其他热门专栏。
注意事项 为保护知识产权和国家机密,在校学生投稿必须事先征得导师的同意,所有稿件应保证不涉及侵犯他人知识产权和泄密问题,否则由此引起的一切后果应由作者本人负责。
论文要求 学术研究:报道最新研究成果,以及国家重点攻关项目和基础理论研究报告。要求观点新颖,创新明确,论据充实。技术报告:有独立和创新学术见解的学术报告或先进实用的开发成果,要求有方法、观点、比较和实验分析。工程应用:方案采用的技术应具有先进性和推广价值,对科研成果转化为生产力有较大的推动作用。
投稿格式 1.采用学术论文标准格式书写,要求文笔简练、流畅,文章结构严谨完整、层次清晰(包括标题、作者、单位(含电子信箱)、摘要、关键词、基金资助情况、所有作者简介、中图分类号、正文、参考文献等,其中前6项应有中、英文)。中文标题必须限制在20字内(可采用副标题形式)。正文中的图、表必须附有图题、表题,公式要求用MathType编排。论文字数根据论文内容需要,不做严格限制,对于一般论文建议7 500字以上为宜。2.请通过网站(http://www.ceaj.org)“作者投稿系统”一栏投稿(首次投稿须注册)。
M ethod for Chinese Parsing Based on Fusion ofM ultip le Structural Information*
ZHAOGuorong,WANGWenjian+
Schoolof Computerand Information Technology,ShanxiUniversity,Taiyuan 030006,China
Syntactic parsing is a basic technology of natural language understanding,and it is the cornerstone of deep language understanding.Atpresent,the parsingmethod is based on the hypothesisof context free grammar.In fact,the contexthasa strong correlation in phrase structure trees.If the structural information can be used,itcan further improve the accuracy of the parser.This paper combines themultiple structural information in syntactic structure trees,the structural information(such as father node or leftand rightsister nodes)in the non-term inalnode can strengthen grammar rules of context constraints.And then this paper uses themethod of structural support vector machines(SSVMs)for Chinese parsing.The experimental results show that themethod ofmultiple structural information fusion can resolve the structuralambiguity and improve theaccuracy and F1 value.
structuralsupportvectormachines;context-free grammar;structure contextcorrelation;Chinese parsing
an was born in 1968.She
the Ph.D.degree from Institute for Information and System Science,Xi'an Jiaotong University in 2004.Now she isa professorand Ph.D.supervisoratSchoolof Computerand Information Technology,ShanxiUniversity,and the seniormemberof CCF.Her research interests include datam ining and machine learning theory,etc.
A
:TP391
*The National Natural Science Foundation of China under GrantNos.61273291,61503229(国家自然科学基金);the Natural Science Foundation of Shanxi Province under GrantNo.2015021096(山西省自然科学基金);the Science and Technology Innovation Project of ShanxiProvinceunderGrantNo.2015110(山西省高等学校科技创新项目).
Received 2016-04,Accepted 2016-06.
CNKI网络优先出版:2016-06-23,http://www.cnki.net/kcms/detail/11.5602.TP.20160623.1139.004.htm l
