概率图模型在社交网络用户相似性发现中的应用*
2017-07-31钱文华
徐 娟,张 迪,钱文华
1.云南大学 档案馆·党史校史研究室,昆明 650091
2.云南财经大学 人事处,昆明 650221
3.云南大学 信息学院,昆明 650504
概率图模型在社交网络用户相似性发现中的应用*
徐 娟1,张 迪2,钱文华3+
1.云南大学 档案馆·党史校史研究室,昆明 650091
2.云南财经大学 人事处,昆明 650221
3.云南大学 信息学院,昆明 650504
+Corresponding autho author:r:E-mail:qwhua003@sina.com
XU Juan,ZHANG Di,QIANWenhua.Application of probabilistic graphicalmodel for discovering user sim ilarity in socialnetwork.Journalof Frontiersof Computer Scienceand Technology,2017,11(7):1056-1067.
社交网络中的用户相似性发现作为社交媒体数据分析中的基础研究,可以应用于基于用户的商品推荐以及社交网络中推导用户关系演化过程等。为了有效地描述社交网络用户间复杂的相关性及不确定性,并从理论上提高海量社交网络用户相似性发现的准确度,研究了基于贝叶斯网这一重要的概率图模型,结合网络拓扑结构和用户之间的依赖程度,发现社交网络用户相似性的方法。为了提高算法的可扩展性,解决海量数据带来的存储和计算问题,提出了基于Hadoop平台的贝叶斯网分布式存储以及并行推理方法。最后通过实验结果验证了算法的高效性和正确性。
社交网络;贝叶斯网;用户相似性;并行推理;Hadoop
1 引言
随着社交网络的迅速发展,规模急剧增大,社交网络所包含的用户基本数据信息剧增,使得社交网络成为一个拥有海量数据的数据源。通过对海量社交网络数据进行分析研究可以发现数据中潜在的价值,进而可以帮助人们研究用户间的交互行为以及相似用户的共同行为。社交网络用户相似性发现作为一项基础研究,有助于理解用户之间的关系演化,同时提炼出一种寻找最优商品推荐的方法等[1-3]。近几年国内外研究者为发现社交网络中的相似用户提出了多种方法。Pirasteh等人[3]提出了一种基于矩阵因子分解的用户相似性度量方法,旨在为相似性评分数量较少的用户提供一种有效的非对称的用户相似性度量方法。Gan等人[4]首先基于用户的历史数据获得一个用户相似性矩阵用于表示用户之间的直接相似性,然后通过幂率调整、最近邻居构建、阈值过滤3种策略对相似性矩阵进行调整,降低了稀疏矩阵对算法准确度的影响。Agarwal等人[5]首先根据进化算法获得反映用户偏好的参数集合,以参数集合为数据基础得到参数相似性,同时结合用户交互强度提出了一种隐式评分模型计算用户关系的相似性。Bhattacharyya等人[6]构建了一种模型根据用户档案数据计算用户之间的语义相似性关系,在此模型的基础上定义了一种用户相似性函数计算用户之间的相似性。Nisgav等人[7]提出了基于协同过滤的方法发现社交网络中的相似性用户。Greene等人[8]提出了基于打分的相似性搜索方法进而研究社区的演化。Scott等人[9]利用链接预测的方法实现了相似性搜索。
但以上方法只考虑了用户之间直接相似性而忽略了间接相似性对用户相似性的影响,然而在实际生活中这种间接相似性具有不可忽视的影响,这就导致了以上算法准确度较低。为了提高用户相似性发现的准确度,提出一种能够同时获得直接相似性和间接相似性对用户相似性影响的模型显得尤为重要。幸运的是,贝叶斯网(Bayesian network,BN)作为概率图模型的典型代表,能够有效地表示和推理不确定知识。BN是以随机变量为节点的有向无环图(directed acyclic graph,DAG),每个节点对应一张反映变量间相互依赖关系的条件概率表(conditional probabilitytable,CPT)。通过构建BN可以有效地描述数据之间的直接相关性和相互依赖关系,同时通过BN推理可以进一步发现数据之间的间接联系,为海量社交网络数据中的用户相似性发现提供了重要的工具。因此,为了提高算法的准确度,本文以BN为模型发现社交网络中的相似用户。
近年来,BN作为一种不确定知识表示和推理的有效方法被应用于用户相似性发现领域,并取得了良好的效果。Abdo等人[10]基于BN推理提出了一种有效的用户相似性度量算法。Nillius等人[11]基于贝叶斯网推理和图约束定义了孤立目标之间的相似性度量,有效地解决了多目标追踪中的标记目标身份问题。
然而以上提出的算法虽然对集中式单节点的运行环境具有较好的适应性,但无法很好地适应海量社交网络数据规模大及分布式存储的需求。为了解决这一问题,提高算法的可扩展性,本文基于Hadoop平台实现了相应的算法。本文的主要贡献如下:
(1)基于MapReduce编程框架从海量社交网络数据中构建得到社交用户贝叶斯网(socialuser Bayesian network,SUBN),发现社交网络用户之间的直接相似性关系,给出一种基于MapReduce的SUBN构建算法。
(2)由海量社交网络数据得到的社交用户贝叶斯网本身也是大规模数据源,为更好地支持SUBN推理以及算法的高效性,本文提出了基于HBase存储贝叶斯网的方法,基于这种合理的存储结构,准确、高效地完成SUBN数据的查询和计算工作。
(3)结合SUBN结构和SUBN推理间接相似性,提出了一种社交网络用户间接相似性发现方法。该方法有效提高了社交网络用户相似性发现算法的准确度,为海量社交网络数据中的用户相似性发现提供了必要的技术支撑。同时,基于MapReduce提出了一种在BN数据分布式存储情况下实现BN并行推理的方法。该方法可以充分利用MapReduce所具备的良好的并行计算能力,在很大程度上提高了推理效率,同时也提高了基于BN的用户相似性度量算法的可扩展性。
本文组织结构如下:第2章介绍了基于BN的社交网络用户建模方法;第3章详细讲述了基于BN的用户相似性度量方法;第4章给出了实验结果和性能分析;第5章总结全文,并对未来工作进行了展望。
2 基于贝叶斯网的社交网络用户模型构建及分布式存储实现
2.1 相关定义
BN是一个有向无环图DAG,记为G=(V,E),其中V是节点的集合,每个节点代表一个随机变量。E是有向边的集合,若存在一条边A→B,则称A是B的父节点(A,B∈V且A≠B)。每个节点对应一个CPT用来量化父节点对子节点的影响。假设U={A1,A2,…,Am},T={t1,t2,…,tn},ti={Ati1,Ati2,…,Atik},Atik∈U ,1≤k≤m分别表示社交网络中的用户集合、实体集、与实体有交互行为的用户集合,以用户集合作为DAG的节点。根据BN的定义给出了SUBN的定义如下。
定义1(社交用户贝叶斯网)用一个二元组R=(Gu,S)表示,其中:
(1)Gu=(U,E)为贝叶斯网的DAG结构,其中U={A1,A2,…,Am},每个Ai对应一个社交网络用户,任一个用户Ai的取值可以为1或0,分别表示用户Ai是否与实体ti有交互行为,E表示用户之间是否存在相似关系边。
(2)S={p(Ai|Pa(Ai)),Ai∈U)}为条件概率值的集合,Pa(Ai)是Ai的父节点。S由各用户节点对应的CPT构成,p(Ai|Pa(Ai))是指在Pa(Ai)发生的情况下Ai发生的概率。
2.2 基于MapReduce的社交用户贝叶斯网模型的构建
在SUBN的DAG构建过程中需要解决两个问题:(1)如何确定两个用户之间是否存在相似关系的边;(2)如何确定相似关系的方向,即用户之间边的指向。针对问题(1),对于任意两个用户,通过考虑同时与两个用户有交互行为的实体数占其中与任何一个用户有交互行为的实体数的比例值来确定用户之间的相似度,若该值达到某个确定的阈值,则说明两个用户之间存在相似关系,即存在边。Ai与Aj之间的直接相似度值用sim(Ai,Aj)表示:
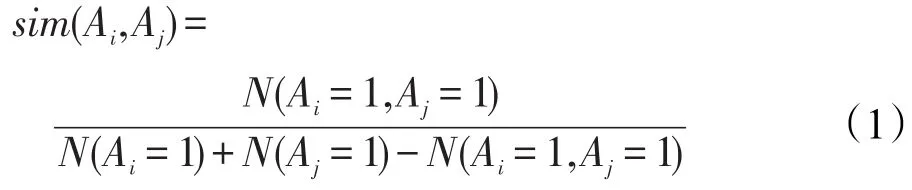
其中,Num(Ai=1,Aj=1)表示同时与用户 Ai和 Aj具有交互行为的实体的个数;分母表示与用户Ai或用户Aj具有交互行为的实体的个数。
设ε为给定的相似度阈值,则当sim(Ai,Aj)>ε时,表示用户Ai与Aj具有相似性关系,即 Ai与 Aj之间存在边。
针对问题(2),对于任意两个有边相连的用户Ai、Aj,通过比较Ai在Aj出现的情况下出现的概率与Aj在Ai出现的情况下出现的概率来确定相似性边的指向。Ai在Aj出现的情况下出现的概率用P(Ai|Aj)表示,反之用P(Aj|Ai)表示:
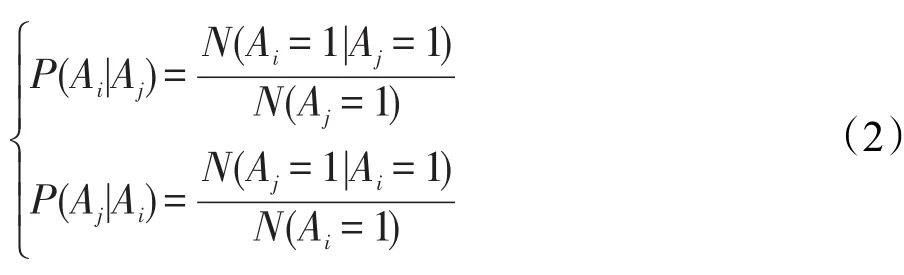
其中,N(Ai=1)、N(Aj=1)表示与Ai、Aj有交互行为的实体的个数。若P(Ai|Aj)>P(Aj|Ai),则表示Ai对Aj的影响大于Aj对Ai的影响,因此边的方向由Aj指向Ai。通过以上方法可以得到SUBN的DAG结构,接着基于MapReduce编程框架利用最大似然估计方法获得SUBN的CPT。P(Ai|Pa(Ai))的计算公式如下:
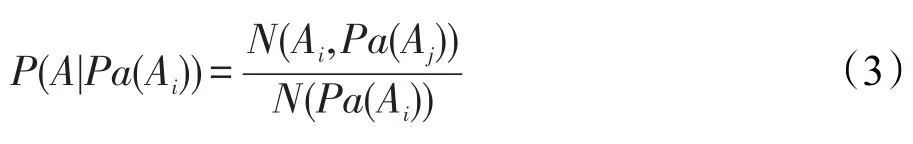
其中,N(Ai,Pa(Aj))表示同时与Ai和Pa(Aj)有交互行为的实体个数;N(Pa(Ai))表示与Pa(Ai)有交互行为的实体个数。
根据以上分析得到基于MapReduce的SUBN模型构建流程如图1所示。
基于MapReduce的SUBN模型构建算法由两个Map函数和一个Reduce函数实现,具体算法实现如下。
算法1基于MapReduce的SUBN模型构建算法
输入:(1)实体集记录,每行记录的格式为T={t1,t2,…,tn},1≤n≤m;(2)用户集合U={A1,A2,…,Am}。
步骤1获得每行记录中的N(Ai=1,Aj=1),N(Ai=1),N(Aj=1)参数,并将其作为中间结果
Map(keyof record,record)
For each record do
Output<key,value> pairs<Ai,1> //用户Ai出现的次数
Output<key,value> pairs <AiAj,1> //用户AiAj同时出现的次数
End for
步骤2获取N(Ai=1,Aj=1),N(Ai=1),N(Aj=1)值
Reduce(Stringkey,Iteratorvalues)
//key为Ai或AiAj,迭代器values收集了所有相同key值<AiAj,1>或<Ai,1>键值对的value值
Result:=0

Fig.1 Flow chartof constructing SUBNmodel图1 SUBN模型构建流程图
Foreach<key,value> pair do
value:=Iterator.Next()//通过访问迭代器获得相应的值
result:=result+value//对应参数值累加
End for
Output<key,value> pairs <key,result> //获得所有<AiAj,1> 或<Ai,1>的值
步骤3最终计算获得DAG
Map(keyof pair,pair)
//pair为<AiAj,rij>,<Ai,ri>及<Aj,rj>的连接,其中rij是键值对<AiAj,1>的统计总数,ri是键值对<Ai,1>的统计总数
Foreach pair do
Ifsim(Ai,Aj)>εthen //式(1)
IfP(Ai|Aj)≥P(Aj|Ai)then
Output<key,value> pairs <Ai→Aj,P(Ai|Aj)>//式(2)
Else
Output <key,value> pairs <Ai→Aj,P(Ai|Aj)>//确定边的方向
End if
End if
End for
根据式(3)可知N(Ai,Pa(Aj))、N(Pa(Aj))可以通过算法步骤1和步骤2获得,进而可以计算得到SUBN的条件概率参数表。
例1假设U={A1,A2,A3,A4},T={T1={A1,A2,A5},T2={A1,A2,A4},T3={A1,A2,A3,A5},T4={A1,A2,A3,A4},T5={A2,A3,A6},T6={A3,A4},T7={A1,A4,A6}}。根据算法1中的第一个Map函数可以得到T1记录中 <A1A2,1>、<A1,1>及 <A2,1>键值对的值,类似地可以获得其他键值对的值。根据算法1中的Reduce函数可以得到 <A1A2,4>、<A1,5>、<A2,5>。根据算法1的第二个Map函数以及式(1)即可获得各用户间的相似性值。假设ε=0.30,那么 (A1,A2)、(A2,A3)、(A1,A4)、(A3,A4)4条边将被添加到E中。根据式(2)进一步确定各边的方向。例如P(A2|A3)=0.75,P(A3|A2)=0.6,因此边(A2,A3)的方向为由A2指向A3。最后根据式(3)可以计算得到每个用户对应的CPT。最终得到的SUBN如图2所示。
2.3 基于HBase的社交用户贝叶斯网模型的分布式存储
由SUBN的定义可知,它由有向无环图和条件概率表两部分组成。因此,SUBN的存储即是对SUBN中的父子关系及各用户对应的CPT进行存储。基于HBase的SUBN分布式存储就是将对应的父子关系和CPT两类数据按照HBase的存储格式要求分布式地存储到Hadoop平台对应的DataNode上,可以通过Hadoop上的namenode访问HBase中的SUBN数据完成相关的查询操作。

Fig.2 A simple SUBN obtained by Example1图2 例1获得的一个简单SUBN
对于SUBN的每个用户Ai,分别将Ai、Ai的父节点及Ai对应的CPT以键值对的形式作为一行存储到HBase数据库对应的TSUBN表中。其中Ai为行标识,key的值为“列族名=列族成员”,AiPa(Ai)为列族名,aiPa(ai)为列族成员,value为对应的条件概率值。对于每个用户Ai利用Map函数并行地读取其对应的CPT表中的所有P(ai|Pa(ai))值,并将其以(Ai|AiPa(Ai)=aiPa(ai)|P(aiPa(ai))的逻辑表达形式并行存储到TSUBN表中,其中行标识、key、value的值通过“|”进行分隔。最终,在进行SUBN并行推理时可以通过Hadoop上的namenode来访问HBase中SUBN数据实现高效推理。基于MapReduce实现SUBN存储的流程如图3所示。
3 基于社交用户贝叶斯网的用户相似性度量方法
3.1 基于概率推理的社交网络用户间接相似性
3.1.1 基于MapReduce的大规模贝叶斯网推理
贝叶斯推理就是以CPT数据为基础,利用贝叶斯网中存在的条件独立性来计算联合概率的过程。贝叶斯网后验概率计算是指在已知证据节点的前提下,计算获得查询节点的概率,即P(Q=q|E=e),其中E为证据节点的集合,Q为查询节点的集合。

Fig.3 Flow chartof SUBN storagebased on MapReduce图3 基于M apReduce的SUBN存储流程图
通过构建SUBN可以得到社交网络用户之间的直接相似性关系,然而现实中社交网络用户之间往往也存在大量的间接相似性关系,这种隐含的不确定关系可以通过SUBN的概率推理机制来获得。
为了支持算法的高效性,本文根据已有的方法[12-13]给出了基于MapReduce的贝叶斯网并行推理方法,具体实现步骤为:(1)分解概率推理任务,由公式P(Q=q|E=e)=P(Q=q,E=e)/P(E=e)可知,可以将推理任务转化为P(Q=q,E=e)和P(E=e)两个边缘概率值的计算。P(Q=q|E=e)是针对查询节点、证据节点以及其他隐节点所构成的所有可能组合的联合概率值之和,P(E=e)是除证据节点和E之外的隐节点所有可能组合情况的联合概率之和,根据条件独立性将联合概率的计算转化为条件概率值的乘积,将以上所形成的所有组合情况存储到HDFS中的TJDP文件中。(2)基于MapReduce查询BN数据计算联合概率。Map函数并行读取TSUBN每一行记录r,读取数据与TJDP中的每行记录进行对比,最终比较结果以键值对形式写入HDFS中的FJDP文件。Reduce函数将具有相同关键字的概率值累乘获得各联合概率值。(3)计算后验概率值。根据所涉及的各种组合情况,对相应的联合概率值累加获得边缘概率值,进而获得所求概率值。通过该方法将大规模贝叶斯网上的概率推理任务转化为海量数据之上的查询任务,有效地利用了HBase海量数据存储以及随机访问的优势,从而实现大规模贝叶斯网的高效推理。基于MapReduce的大规模BN推理实现过程如图4所示。
3.1.2 基于概率推理的间接相似性度量
对于SUBN推理的相似性计算,其中查询节点为目标用户A,证据节点为与A进行相似性比较的用户x(A∈Gu.U,x∈Gu.U)。因此,需要计算的后验概率值为P(A=1|x=1)。根据3.1.1小节介绍的基于MapReduce的贝叶斯网并行推理方法,给出了基于SUBN推理的间接相似性度量算法具体实现如下。
算法2基于SUBN推理的间接相似性度量算法
输入:(1)SUBN 的TSUBN;(2)SUBN 的TJDP;(3)SUBN推理所涉及的所有节点的集合,即V。
输出:P(A=1,x=1)和P(x=1)的值。
步骤1获得所有组合情况的概率值并将其作为中间结果
Map(Stringkey,Doublevalue)
//key为TSUBN中每一行的键值,即AiPa(Ai)=aiPa(ai)
//value为TSUBN中每一行的值,即P(ai|Pa(ai))
Foreach row do
S:={AiPa(Ai)}∩IS(A,x).V
Foreach rowrofTJDPdo
IfS.value=r.valuethen
//S.value是S在aiPa(ai)中对应值的集合,r.value是第r行对应的值
Generate<key,value> pairs<r.value,value>
End if
End for

Fig.4 Processof large scale BN inferencebased on MapReduce图4 基于M apReduce的大规模BN推理实现过程
End for
步骤2对具有相同键值的中间结果累乘,获得所有联合概率分布的值
Reduce(Stringkey,Iteratorvalues)
Result:=1
For each <key,value>pair do
value:=Iterator:Next()
result:=result×value
Generate<key,value> pairs<PQ,value>
IfA.valueinkey=1 then
Generate<key,value> pairs<PE,value>
End if
End for
步骤3将具有相同键值的键值对的值累加最终得到P(A=1,x=1)和P(x=1)的值
Reduce(Stringkey,Iteratorvalues)
//key为PE或PQ
//values为具有相同键值的<PQ,value>或<PE,value>的<key,value>键值对
Result:=0
For each <key,value>pair do
value:=Iterator.Next()
result:=result+value
End for
Generate<key,value> pairs<key,result>
3.2 基于图结构的社交网络用户间接相似性
由McPherson等人[14]提出的同质性理论,可以得到两个重要的观点:(1)人们更倾向于与自己相似的人做出相似的行为;(2)人们更倾向于与朋友的朋友建立朋友关系。基于以上两个观点,借鉴已提出的网络相似性方法[15],通过考虑A和x的共同相似性用户(m)提出了基于SUBN结构的相似性。首先定义了两种子图SRG(sim ilarity relationship graph)和MSRG(mutualsim ilarity relationship graph)。
定义2给定一个SUBNG=(Gu,S)和两个用户A,x∈Gu.U,用户A和x的MSRG(A,x)是满足以下条件的SUBN子图:
(1)MSRG(A,x).U={A,x}∪{u∈Gu.U|u≠x,u≠A,Pa(u)=A∩Pa(x)=u或Pa(u)=A∩Pa(u)=x或Pa(A)=u∩Pa(u)=x或Pa(u)=A∩Pa(u)=x}
(2)MSRG(A,x).E={<u,u′>∈Gu.E|u,u′∈MSRG(A,x).U}
由定义可知,MSRG是同时与目标用户A和用户x具有直接相似性关系的用户及他们之间的边构成的SUBN子图,MSRG中边的数量反映了两个用户之间联系的紧密程度。可以通过比较与用户A直接相连的用户构成的子图以及与用户A、x同时相连的用户构成的子图来确定用户A、x之间的相似性。因此,给出了SRG的定义。
定义3给定一个SUBNG=(Gu,S)和一个用户A∈Gu.U,用户A的SRG(A)是满足以下条件的SUBN子图:
(1)SRG(A).U={A}∪{u∈Gu.U|u≠A,Pa(u)=A或Pa(A)=u}
(2)SRG(A).E={<A,u> ∈Gu.E|u∈SRG(A).U}∪{<u,u′> ∈Gu.E|u,u′∈SRG(A).U}
由以上定义可知,MSRG(A,x)和SRG(A)都是SUBN的子图,因此可以通过查询TSUBN来获得。基于SUBN结构的间接相似性可以通过比较MSRG(A,x)和SRG(A)边的数量来获得。具体定义如下。
定义4用户A和x的网络结构相似性定义为:
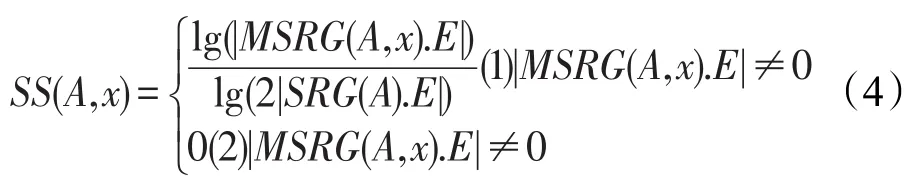
其中,|MSRG(A,x).E|和|SRG(A).E|分别表示图MSRG(A,x)及图SRG(A)中边的数量。该定义不仅考虑了用户产生的影响,同时考虑了边产生的影响。显然,当A、x之间没有共同的相似性用户时,MSRG仅包含两个用户而不包含边,此时SS(A,x)的值为0。
例3假设SUBN结构如图5所示,计算A、x1的网络相似性。SRG(A)含5个用户(A,A1,A2,A3,A4)及5条边(<A,A1>,<A,A2>,<A,A3>,<A,A4>,<A1,A2>)。MSRG(A,x1)中含有5条边,即(<A,A1>,<A,A2>,<A1,A2>,<A1,x1>,<A2,x1>)。因此,SS(A,x1)=lg(5)/lg(2×5)=0.7。
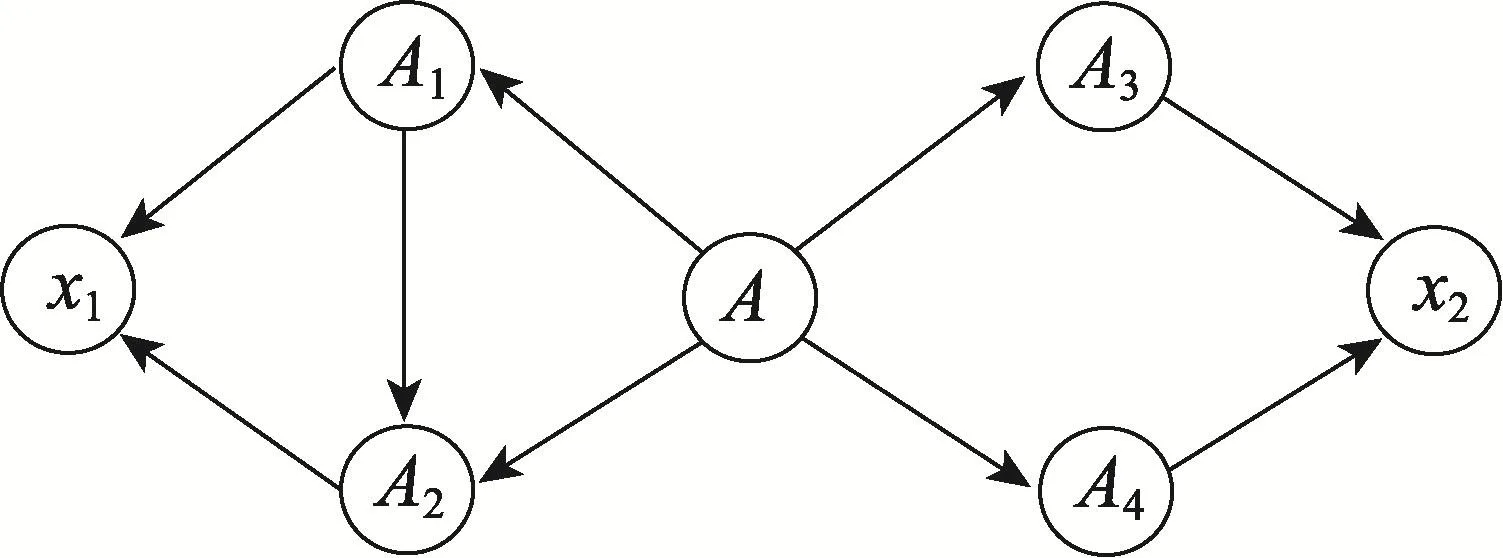
Fig.5 A SUBN structurew ith 7 users图5 含7个用户的SUBN结构
3.3 基于SUBN的社交网络用户相似性度量
结合以上基于SUBN推理的相似性及基于SUBN结构的相似性,本文给出了最终的相似性度量公式:
sim(A,x)=a×SI(A,x)+b×SS(A,x),a,b∈[0,1] (5)其中,SI(A,x)是基于SUBN推理的相似性值;SS(A,x)是基于SUBN结构的相似性值;a、b是二者所占的权重,a和b的值可以根据实际情况进行调整。
基于该度量方法发现社交网络相似性用户时,x是A的n阶马尔科夫覆盖中的用户,n由用户根据实际需要进行设置,最终返回top-k用户A的相似性用户。
4 实验结果
本文实验所搭建的Hadoop平台包含7台机器,其中1台为主节点,其余6台为从属节点。Hadoop版本为2.4.0,HBase版本为0.20.6,JDK版本为1.60,每台机器的配置为Pentium®Dual-Core CPU E5700@3.00GHz@3.01GHz,2GB内存。
本文采用的实验数据为DBLP(http://dblp.uni-trier.de/xm l/)数据集,该数据集收录了世界上最全面的计算机科学领域相关论文或著作元数据信息。首先从DBLP数据集中提取数据获得一个以作者名为节点,以合著关系为边的合著关系社交网络。本文的实验中实体集为合著关系社交网络中的合著关系。
本文分别测试了算法1和算法2的执行时间、加速比及并行效率。最后,验证了算法的正确性和有效性。
4.1 算法执行时间
为了验证算法1的性能,分别测试了在不同从属节点情况下,随实体数据集增加SUBN的DAG构建时间的变化以及随SUBN用户数量增加CPT计算时间的变化,如图6、图7所示(实验图中的n台节点是指从属节点数)。
由图可以发现,实体数据集大小相同的情况下,随着从属节点数的增加算法执行时间递减;SUBN用户节点数相同的情况下,随着从属节点数增加CPT计算时间递减。另一方面,随着实体集的增加DAG构建算法的执行时间变化相对缓慢,然而随着SUBN用户节点数的增加CPT计算时间急剧增加,由此可知算法1的性能主要取决于CPT的计算时间。
为了测试算法2的性能,测试了不同从属节点下随着SUBN用户节点数的增加算法2执行时间的变化,如图8所示。由图可知,在不同从属节点情况下,随着SUBN用户节点数增加,算法执行时间增加越来越慢;SUBN用户节点数相同情况下,随着从属节点数的增加算法执行时间递减,这也就验证了算法2可以在Hadoop框架下高效地执行。

Fig.6 Timeof DAG constructionw ith the increaseof datasets图6 随着实体集数据量的增加SUBN的DAG构建时间变化
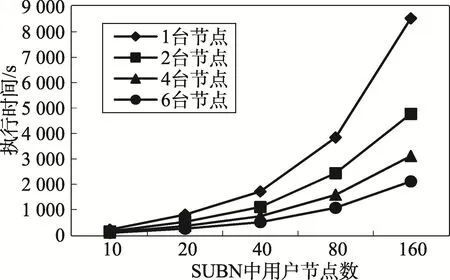
Fig.7 Time of CPT calculationw ith the increase of SUBN nodes图7 随着SUBN中用户节点数的增加CPT的计算时间变化

Fig.8 Timeof Algorithm 2w ith the increaseof SUBN nodes图8 随着SUBN中用户节点数的增加算法2的执行时间变化
4.2 算法加速比
加速比是指单个从属节点情况下的算法顺序执行时间与多个从属节点情况下的算法并行执行时间的比值,加速比能够很好地反映随从属节点的增加算法执行效率的提升程度。为了验证算法1和算法2的执行效率提升程度,测试了在不同从属节点情况下,随实体集数据量增加算法1的加速比变化,以及随SUBN用户节点数增加算法2的加速比变化,如图9、图10所示。

Fig.9 Speedup of Algorithm 1w ith the increaseof datasets图9 随着实体集数据量的增加算法1的加速比变化

Fig.10 Speedup of Algorithm 2w ith the increaseof SUBN nodes图10 随着SUBN中用户节点数的增加算法2的加速比变化
通过观察图9可以得到,在实体集较小时加速比变化幅度较小,实体集数据量增加时加速比变化幅度有了一定程度的增加。由此可知,算法1的加速比不仅取决于从属节点数,更取决于实体集大小,实体集数据量越大加速比越大。类似地,通过观察图10可以得到,SUBN用户节点数越多算法2的加速比越大。这也从某种程度上验证了本文算法的高效性和良好的可扩展性。
4.3 算法并行效率
并行效率是指加速比与处理器数量的比值,它可以很好地反映随着实验中处理器数量的增加并行算法的性能提升程度。分别测试了不同从属节点情况下,随实体集数据量增加算法1的并行效率变化情况,以及随SUBN用户节点数的增加算法2的并行效率变化情况,如图11、图12所示。

Fig.11 Parallelefficiency of A lgorithm 1 w ith the increase of datasets图11 随着实体集数据量的增加算法1的并行效率变化
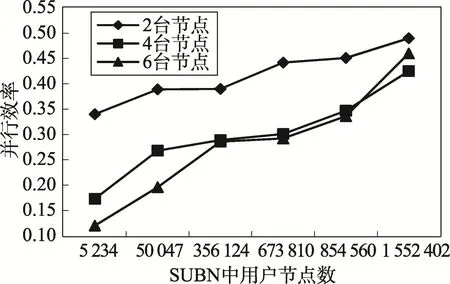
Fig.12 Parallelefficiency of Algorithm 2w ith the increaseof SUBN nodes图12 随着SUBN中用户节点数的增加算法2的并行效率变化
通过观察图11、图12可以发现,不同从属节点情况下,算法1的并行效率随着实体集数据量的增加而提高,算法2的并行效率随着SUBN用户节点数的增加而提高。这表明本文算法随着数据量的增加可以获得更好的并行效率。另外,通过观察图12还可以发现,当SUBN用户节点数小于854 560时,从属节点数越多算法的并行效率反而下降,而当SUBN用户节点数超过854 560后,6台从属节点情况下的并行效率超过4台从属节点情况下的并行效率。这表明要使本文算法在并行效率上达到最优需要在SUBN用户节点数、从属节点数以及用户需求上做适当的折中。
4.4 算法的正确性
为了测试算法的正确性,将本文算法与现有的L1Norm、Cosine两种常用的用户相似性度量方法进行比较,二者定义如下:
其中,SA是SUBN中与用户A直接相连的用户集合;Sx是SUBN中与用户x直接相连的用户集合。
从SUBN中随机地选取了一个目标用户A和6个潜在的相似用户Axs1、Axs2、Axs3、Axs4、Axs5、Axs6。分别用基于SUBN的相似性度量方法、L1 Norm及Cosine计算相应的相似性度量值,并根据得到的相似性度量值对用户进行相似性排序,如表1所示。

Table 1 Resultcomparison by 3 different sim ilaritymeasuresof 6 strangers表1 不同的相似性度量方法得到的结果比较
由以上结果可以得到,本文方法与其他两种方法得到的结果基本一致。同时注意到对于用户Axs3、Axs4,由其他两种方法得到的两个用户相似度值相同,因此依据其他两种方法无法确定两个用户的精确相似性排序,基于本文方法可以明确二者相似度排序,这也在一定程度上验证了本文方法的正确性和准确性。
5 总结与展望
基于贝叶斯网的用户相似性发现方法较好地将社交网络中的用户行为分析与概率图模型结合在一起,不仅可以发现用户之间的直接相似性关系,还可以发现用户之间的间接相似性关系,提高了用户相似性发现算法的精确度。同时本文将算法扩展到Hadoop平台,提出了基于MapReduce的贝叶斯网构建算法、基于MapReduce的贝叶斯网并行推理算法以及基于HBase的贝叶斯网分布式存储方法,有效提高了算法的执行效率,同时增强了算法的可扩展性,为社交网络数据分析提供了有力的技术支撑。考虑到社交网络中用户行为数据不断增长以及信息的时效性,实时数据处理以及在原有模型基础上的模型增量处理将会是接下来重点研究的工作。
[1]Han Xiao,Wang Leye,Farahbakhshb R,etal.CSD:amultiuser sim ilarity metric for community recommendation in online social networks[J].Journal of Expert Systems w ith Applications,2016,53(1):14-26.
[2]Wang Wei,Zhang Guangquan,Lu Jie.Collaborative filtering w ith entropy-driven user similarity in recommender systems[J].International Journal of Intelligent Systems,2015,30(8):854-870.
[3]Pirasteh P,Hwang D,Jung JJ.Exploitingmatrix factorization to asymmetric user sim ilarities in recommendation systems[J].Know ledge-Based Systems,2015,83(1):51-57.
[4]Gan M ingxin.Walking on a user sim ilarity network towards personalized recommendations[J].PLoS One,2014,9(12):e114662.
[5]Agarwal V,Bharadwaj K K.A collaborative filtering framework for friends recommendation in social networks based on interaction intensity and adaptive user similarity[J].SocialNetwork Analysisand M ining,2013,3(3):359-379.
[6]Bhattacharyya P,Grag A,Wu SF.Analysis of user keyword sim ilarity in online social networks[J].Social Network Analysisand M ining,2011,1(3):143-158.
[7]Nisgav A,Patt-Shamir B.Finding similarusers in socialnetworks:extended abstract[C]//Proceedings of the 21st Annual Symposium on Parallelism in A lgorithms and Architectures,Calgary,Canada,Aug 11-13,2009.New York:ACM,2009:169-177.
[8]Greene D,Doyle D,Cunningham P.Tracking the evolution of communities in dynamic social networks[C]//Proceedings of the 2010 International Conference on Advances in Social Networks Analysis and M ining,Odense,Denmark,Aug 9-11,2010.Washington:IEEEComputer Society,2010:176-183.
[9]Scott J.Social network analysis:developments,advances,and prospects[J].Social Network Analysis and M ining,2011,1(1):21-26.
[10]Abdo A,Salim N.Inference networks formolecular database sim ilarity searching international[J].Journal of Biometric and Bioinformatics,2008,2(1):1-16.
[11]Nillius P,Sullivan J,Carlsson S.Multi-target tracking-linking identities using Bayesian network inference[C]//Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,New York,Jun 17-22,2006.Washington:IEEEComputer Society,2006:2187-2194.
[12]Yue Kun,Xu Juan,Fang Qiyu,etal.A large-scale Bayesian network parallel reasoning method based on MapReduce:China,CN201310709499.9[P].2014-04-23.
[13]Xu Juan.An approach for discovering user sim ilarity in social network based on Bayesian network[D].Kunm ing:Yunnan University,2015.
[14]McPherson M,Sm ith-Lovin L,Cook JM.Birds of a feather:homophily in social networks[J].Annual Review of Sociology,2001,27(8):415-444.
[15]Akcora CG,CarminatiB,FerrariE.User sim ilaritieson socialnetworks[J].Social Network Analysisand M ining,2013,3(3):475-495.
附中文参考文献:
[12]岳昆,徐娟,方启宇,等.一种基于MapReduce的大规模贝叶斯网并行推理方法:中国,CN201310709499.9[P].2014-04-23.
[13]徐娟.基于贝叶斯网的社交网络用户相似性发现[D].昆明:云南大学,2015.

徐娟(1989—),女,山东菏泽人,2015年于云南大学获得硕士学位,现为云南大学档案馆助理馆员,主要研究领域为数据挖掘,高校档案数字化等。主持云南省档案馆科技项目等。

ZHANG Diwasborn in 1990.He received theM.S.degree in computer sciences from Yunnan University in 2015.Now he is a teaching assistant at Yunnan University of Finance and Econom ics.His research interest is secure multi-party computation.
张迪(1990—),男,山西运城人,2015年于云南大学获得硕士学位,现为云南财经大学人事处初级职员,主要研究领域为安全多方计算。

QIANWenhuawas born in 1980.He received the Ph.D.degree in computer sciences from Yunnan University in 2010.Now he is an associate professor at School of Information,Yunnan University.His research interests include non-photorealistic rendering and virtual reality,etc.
钱文华(1980—),男,云南曲靖人,2010年于云南大学获得博士学位,现为云南大学信息学院副教授,主要研究领域为非真实感渲染,虚拟现实等。主持国家自然科学基金,云南省应用基础研究计划等项目。
App lication of Probabilistic Graphical M odel for Discovering User Sim ilarity in SocialNetwork*
XU Juan1,ZHANG Di2,QIANWenhua3+
1.Archives·Party and University History Research Office,Yunnan University,Kunm ing 650091,China
2.PersonnalDepartment,Yunnan University of Finance and Econom ics,Kunm ing 650221,China
3.Schoolof Information,Yunnan University,Kunm ing 650504,China
Discovering user sim ilarity in socialnetwork asa basic research of socialmedia data analysis can be used in product recommendation and socialnetwork user relationship evolution effectively.To representcomplex correlations and their uncertainties among social network users and improve the accuracy of user sim ilarity inmass social network theoretically,this paper proposes an effectivemethod for discovering user sim ilarity in socialnetwork combining network topological structure and dependence between usersbased on Bayesian network,an importantprobabilistic graphicalmodel.To improve the scalability of the proposedmethod and solve the storage and computation problem ofmass data,this paper proposes Bayesian network distributed storage and parallel reasoning algorithm based on Hadoop platform.Theexperimental resultsverify that the proposedmethod iseffective and correct.
as born in 1989.She
the M.S.degree in computer sciences from Yunnan University in 2015.Now she is an assistant archivistat Yunnan University.Her research interests include datam ining and digital construction of university archives,etc.
A
:TP311
*The National Natural Science Foundation of China under GrantNos.61462093,61662087(国家自然科学基金);the Applied Basic Research Program of Yunnan Province under GrantNo.2014FB113(云南省应用基础研究计划项目);the Key Program of Departmentof Education of Yunnan ProvinceunderGrantNo.2012Z012(云南省教育厅重点项目).
Received 2016-07,Accepted 2016-10.
CNKI网络优先出版:2016-10-18,http://www.cnki.net/kcms/detail/11.5602.TP.20161018.1622.008.htm l
Keywords:socialnetwork;Bayesian network;user sim ilarity;parallel reasoning;Hadoop
