基于光流约束自编码器的动作识别
2017-07-26李亚玮金立左孙长银
李亚玮 金立左 孙长银 崔 桐
(1东南大学自动化学院, 南京 210096)(2中国电科集团28所, 南京 210007)
基于光流约束自编码器的动作识别
李亚玮1金立左1孙长银1崔 桐2
(1东南大学自动化学院, 南京 210096)(2中国电科集团28所, 南京 210007)
为了改进特征学习在提取目标运动方向及运动幅度等方面的能力,提高动作识别精度,提出一种基于光流约束自编码器的动作特征学习算法.该算法是一种基于单层正则化自编码器的无监督特征学习算法,使用神经网络重构视频像素并将对应的运动光流作为正则化项.该神经网络在学习动作外观信息的同时能够编码物体的运动信息,生成联合编码动作特征.在多个标准动作数据集上的实验结果表明,光流约束自编码器能有效提取目标的运动部分,增加动作特征的判别能力,在相同的动作识别框架下该算法超越了经典的单层动作特征学习算法.
动作识别;特征学习;正则化自编码器;光流约束自编码器
基于视频的人体动作识别[1]近年来已成为机器视觉、模式识别等领域的研究热点,在安全监控、人机交互、智能机器人等方面具有良好的应用前景.然而在实际应用中,视频内出现的背景及光照变化、观察视角及人体姿态差异等因素使动作识别变得非常困难[2].如何有效提取和表示视频中的动作特征是动作识别的关键技术[3].
传统的动作特征提取方法一般包含2个步骤:首先通过Harris3D[4],Cuboid[5]等检测器检测运动区域;然后计算梯度直方图[6](HOG)、光流直方图[7](HOF)、三维梯度[8](HOG3D)和运动边缘[9](MBH)等特征描述向量来表征动作特征.近年来,使用学习算法[10]学习动作特征是动作识别领域的研究方向之一.动作特征学习方法无需预先定义各种复杂的特征表示方式,而是使用统一的学习算法框架从视频像素中学习语义单元作为动作特征,如基于无监督特征学习算法的受限波尔兹曼机[11](RBM)、独立子空间分析[12](ISA)、慢特征分析[13-14](SFA)等,以及基于监督特征学习算法的深度学习[15]等.这类动作特征学习方法在大型动作数据集上较传统动作特征方法在识别精度上有进一步提升[16].
动作特征学习算法将视频块像素作为输入,通过统计视频块中的像素分布信息来学习动作特征.但是,这类方法不考虑像素在时间上和空间上分布的不同特性,因此仅能描述视频像素块的外观信息,忽略了目标动作本身的运动信息.为了学习具有运动信息的动作特征,本文提出了一种基于光流约束自编码器(optical flow constrained auto-encoder)的算法学习视频动作特征.该算法将视频块的像素值与对应光流同时作为学习机的输入,学习重构视频像素的同时将对应运动光流作为正则化约束项,将两者映射到统一的特征空间,这种方式能够提取携带运动信息的视频块.为了与现有动作特征学习方法进行比较,本文采用与文献[17]相同的分类流程,仅将特征算法替换为光流约束自编码器,并在KTH,UCF和Hollywood数据集上进行了对比实验.结果表明,光流约束自编码器能更好地提取动作中的运动信息,增强动作特征的分类能力,其识别精度较传统无监督动作特征学习方法有一定程度的提升.
1 光流约束自编码器
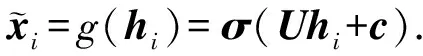
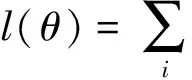
(1)
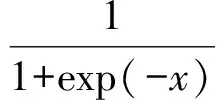
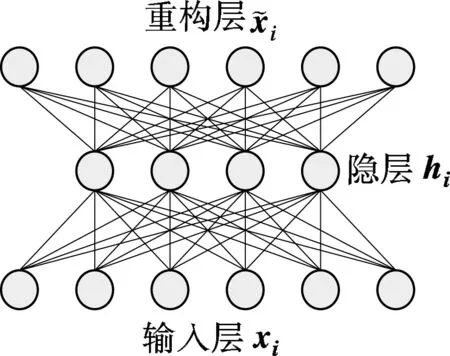
(a) 自编码器
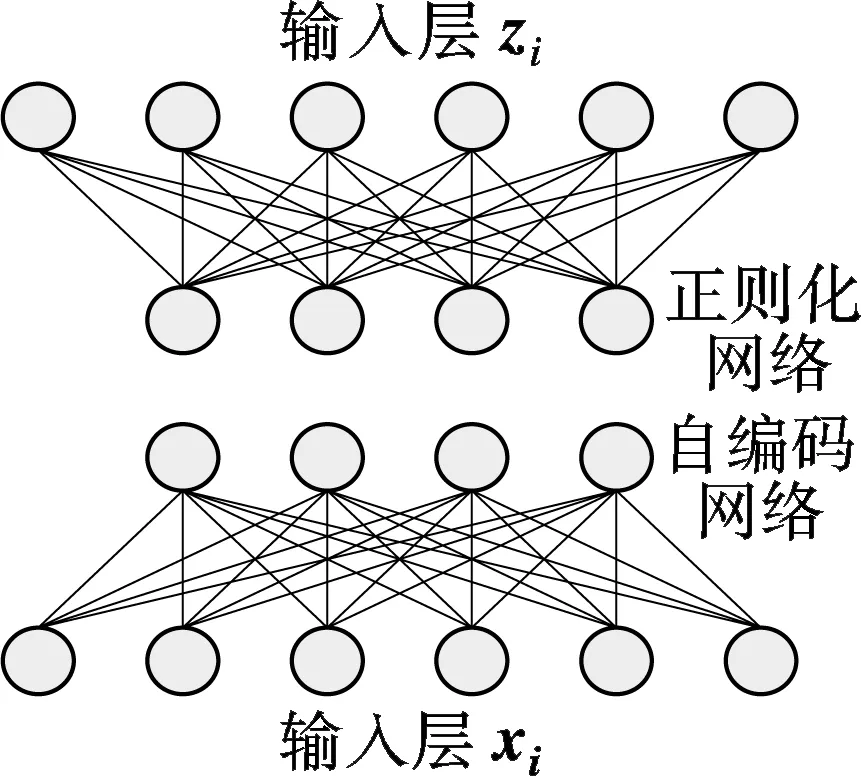
(b) 光流约束自编码器
1.1 正则化自编码器
正则化约束[19]是无监督学习中的重要手段,通过对经验风险(数据拟合误差)附加先验条件作为约束,使得特征满足一定性质.如稀疏正则化约束对隐层使用特定的范数约束,使特征向量尽可能多的分量为零,这类正则化目标函数可表示为
(2)
式中,‖·‖1为L1范数,用来控制目标的稀疏性;λ为正则化参数,通常取小于1的正数.
自编码器在贝叶斯框架下的目标似然函数可表示为
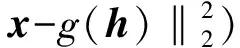
(3)
并假设h服从以0为均值的拉普拉斯分布:
p(h)=exp(-λ2‖h‖1)
(4)
则minl(θ)=-max(log(p(xh))+log(p(h)))可以写为
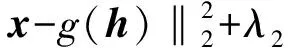
(5)
式中,λ1,λ2为系数,若令λ=λ1/λ2,则当条件满足似然函数为高斯函数且先验分布服从拉普拉斯分布时,式(2)在L1范数约束下的自编码器等价于式(5)最大后验估计问题.
1.2 光流约束
在自编码器算法中,特征hi仅与输入xi有关,即仅使用视频像素编码动作,这种编码方式缺乏运动幅度、运动方向等运动信息.为了编码运动信息,假设表示运动方向、幅度的向量z∈Z,Z∈Rdz,采用最大化联合概率p(x,z,h)来学习动作特征.目标函数定义为
minl(θ)=-maxlog(p(x,z,h))
(6)
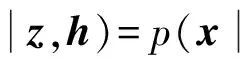
p(hz)=λ2exp(-λ2‖h-r(z)‖1)
(7)
式中,z与估计参数θ无关,故不影响最小化目标函数,则目标函数(6)可表示为
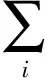
(8)
式中,r(zi)为运动编码.由式(8)可见,hi不仅受xi影响,同时也受到zi的约束,且当z为零向量时,式(8)等价于式(1).
视频分析中,使用光流来估计目标运动是常用的解决方法,本文采用Lucas-Kanade光流法[20]计算各像素点的运动信息.对任意I(x,y,t)处的光流可通过求解如下方程获得:
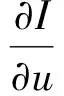
(9)
算法1 光流约束自编码器参数的求解
输入:初始θ0={W0,U0,V0,b0,c0,d0},正则化参数λ,学习率η,{(x1,z1),(x2,z2),…(xn,zn)}.
输出:目标函数l(θt),θt={Wt,Ut,Vt,bt,ct,dt}.
① 初始化网络参数θt=θ0
Whilet
② 计算前馈网络
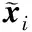
③ 使用式(8)计算目标函数l(θt)
④ 反向传播计算梯度Δθ={ΔW,ΔU,ΔV,Δb,Δc,Δd}
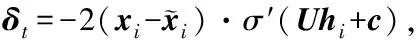
δt=δt·σ′(Whi+b)
⑤ 梯度下降更新参数θt=θt+ηΔθ
⑥ 更新计数器t=t+1
END
2 基于光流约束自编码器的动作识别
如图2所示,基于局部动作特征的识别流程一般包括4个步骤:① 动作特征提取,通过检测算法检测并设计描述向量表征特征点;② 动作特征表示,在训练集上对描述向量使用K均值聚类等方法生成动作字典并量化作为动作特征;③ 特征关系建模,使用包括词包(BoW)模型在内的方法对局部特征关系建模形成视频动作的最终表示;④ 训练分类模型并完成分类.步骤①~③又称为视频的动作编码过程,将视频映射为特征空间中的向量;步骤④称为识别过程,采用SVM分类器或模型匹配的方式预测动作类别.
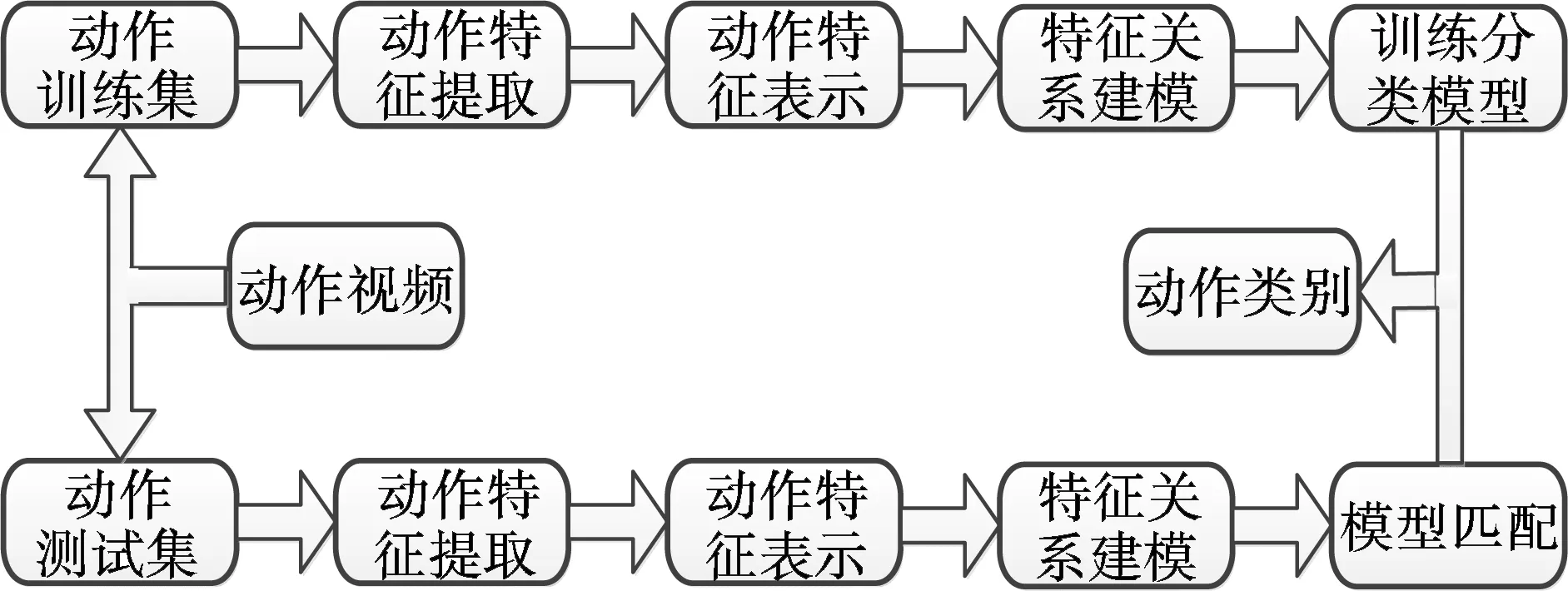
图2 基于视频的动作识别流程
光流约束自编码器使用算法1获取运动滤波器并对视频块作卷积提取特征,视频块xi对应的hi即为该点动作特征向量.由于拍摄距离的不同,动作对象的大小具有一定的差异性,为了处理动作对象的个体差异,本文首先在多个空间尺度下对视频块作卷积提取特征,然后使用Fisher向量[21]编码动作特征.基于光流约束自编码器的多尺度特征提取和动作识别流程如图3所示.
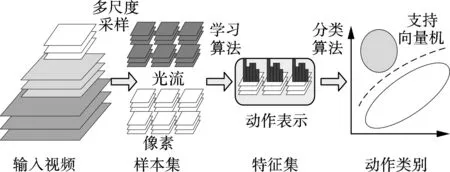
图3 多尺度特征提取和动作识别
3 实验结果与分析
3.1 动作数据集
实验所使用的动作数据集如图4所示.其中KTH是基准数据集,由预先设置的动作类型和场景组成.该数据集包含6个动作类型,每个动作由25人在4个场景(室外、室外衣着变化、室外镜头变化和室内)下完成, 共600段视频(8人为训练集,8人为验证集,9人为测试集).Hollywood2数据集从69部好莱坞电影中人工截取,包含12个动作类型,1 707段视频(823段为训练集,884段为测试集),训练集与测试集分别来自不同电影.UCF sports数据集从YouTube截取,包含16个体育运动类型,783段视频(649段为训练集,134段为测试集).
3.2 光流约束自编码器特征分析
光流约束自编码器引入运动信息(光流)作为约束条件学习动作特征.为了与传统动作特征进行比较,在KTH数据集上随机对训练视频抽取8×8×5像素的视频块,并设定100维特征作比较,分别以式(1)和式(8)为目标函数学习动作特征,采用梯度下降法优化目标函数,当目标函数值变化小于1×10-4时停止训练.将光流约束自编码器的特征滤波器和无光流约束的特征滤波器分别记为WFCAE和WCAE,如图5所示.使用光流约束的动作滤波器在空间上表现的较为集中,更加接近于方向滤波器,无光流约束滤波器则权重变化较为平缓,且存在一定比例的高频噪声.

(a) KTH数据集

(b) Hollywood2数据集

(c) UCF Sports数据集
图4 KTH,Hollywood2和UCF Sports动作数据集 中部分图片

(a) 光流约束自编码器

(b) 稀疏约束自编码器
为了检验运动信息在动作特征学习中的作用及其特性,采用WFCAE和WCAE分别对视频块编码,得到特征hFCAE和hCAE,并定义稀疏性s为特征h中非零元个数的占比,定义动态特性d为滤波器W沿时间轴上的方差.
计算不同正则化参数下的比值s(hFCAE)/s(hCAE)和d(WFCAE)/d(WCAE),结果如表1所示.可看出,hFCAE较hCAE稀疏性差别不大,但WFCAE较WCAE动态性能有显著提高.

表1 不同正则化参数下特征稀疏性与动态性比较
使用k=256的Fisher向量和线性SVM分类器在KTH数据集上的识别结果如图6所示.带光流约束的自编码器比不带光流约束的自编码器在动作识别效果上有所提升,当λ=0.10时取得最优结果.由此可见,在特征数目相同的情况下,将运动信息用于动作特征学习可以在一定程度上提升动作识别精度.
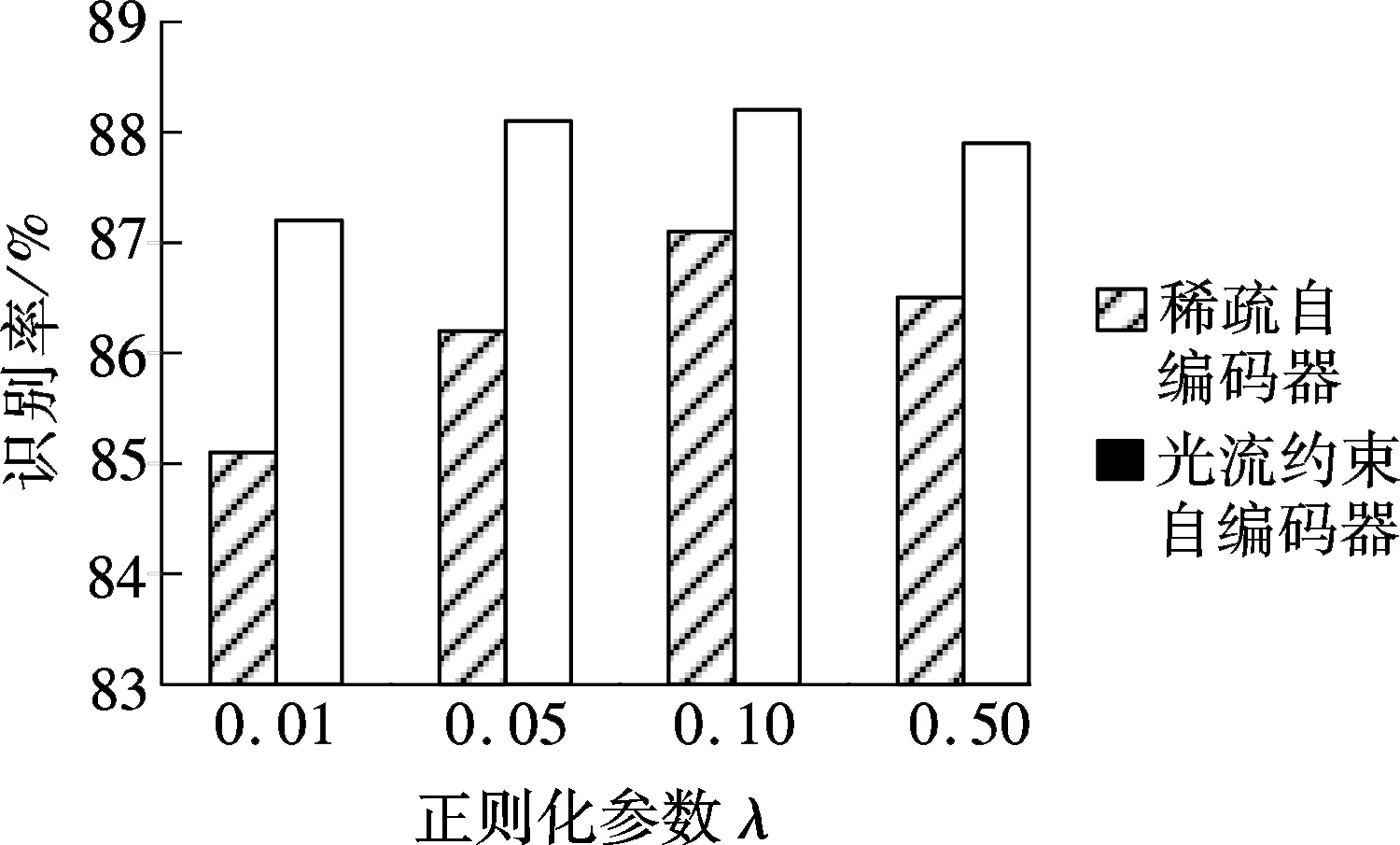
图6 不同正则化参数下动作识别结果比较
3.3 光流约束自编码器的参数设置
特征维数是影响动作识别精度的重要因素.设定特征维数分别为64,128, 256, 512,正则化因子λ分别为0.01,0.05, 0.10, 0.50,使用k=256的Fisher向量和线性SVM分类器在KTH数据集上进行动作识别实验,结果如图7所示.由图可见,特征维数低于256时,识别精度随着特征维数的增加明显提升;当特征维数大于256时,识别精度提升不明显.
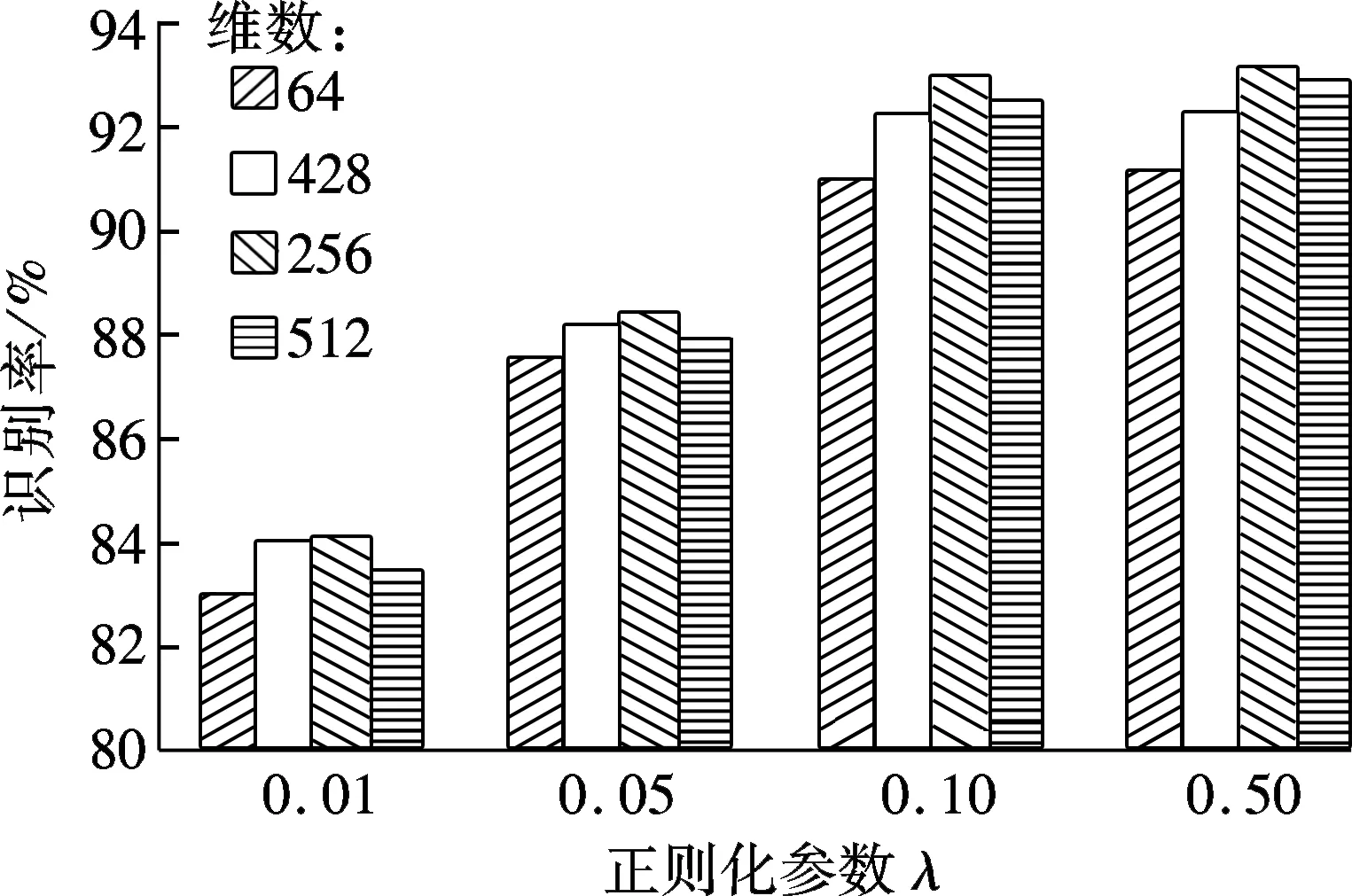
图7 特征维数对识别精度的影响
3.4 与其他算法的识别效果比较
为了与其他现有的动作特征算法进行比较,在KTH数据集上进行动作识别实验,采用8×8×5像素的局部特征点、256维特征、k=256的Fisher向量和线性SVM分类器,识别结果对比如表2所示.可见在传统动作特征中,静态特征HOG和动态特征HOF相结合的方法识别结果最优,这说明动作识别不仅要考虑静态信息,同时也要考虑运动信息.对于特征学习,基于3D CNN及基于单层SFA的识别结果与传统动作特征算法相比没有明显优势.然而光流约束自编码器取得的平均识别率为93.4%,说明在特征编码过程中同时考虑视频块中的静态信息和运动信息能够一定程度上提升动作识别精度.
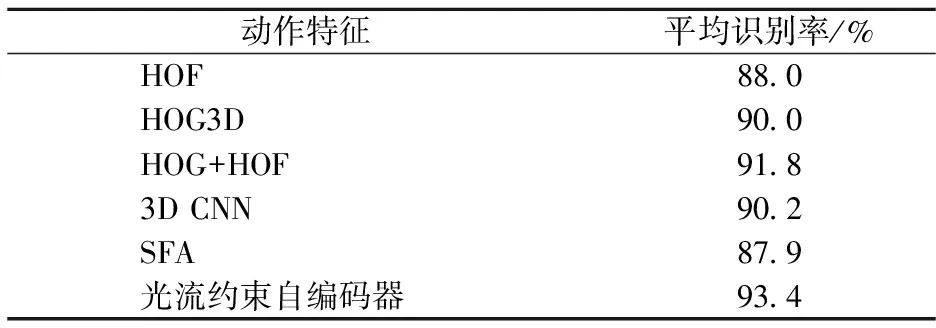
表2 KTH数据集上的识别结果
将Hollywood2数据集的视频分辨率归一化为160×20,考虑到Hollywood2数据集中人的外观变化较大,采用4层金字塔,下采样比率0.7, 8×8×5大小的局部特征点、256维特征、k=256的Fisher向量和线性SVM分类器,识别结果对比如表3所示.可见GRBM和SFA方法比传统动作特征算法在识别精度上均有一定提升,本文算法取得53.6%的平均识别率,较传统算法有明显提升.
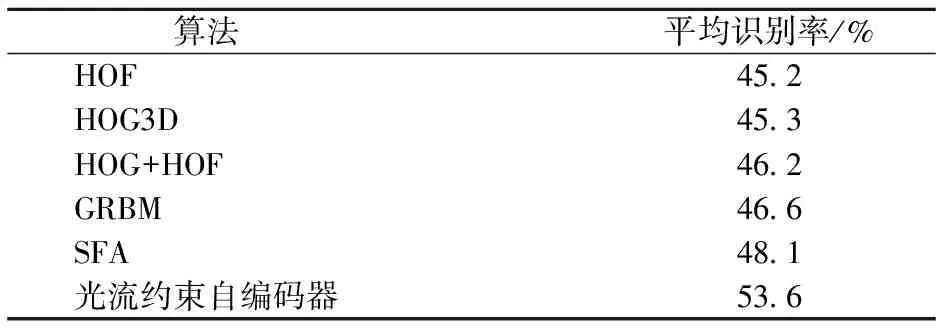
表3 Hollywood2数据集上的识别结果
将UCF sports数据集的视频分辨率也归一化为160×20,采用4层金字塔,下采样比率0.7, 8×8×5大小的局部特征点、256维特征、k=256的Fisher向量和线性SVM分类器,识别结果对比如表4所示.本文算法获得了85.2%的平均识别率.考虑到运动场景下相机运动造成的光流估计偏差,采用光流梯度作全局运动补偿后再提取光流约束自编码器学习动作特征(表中记为光流约束自编码器+Gradient方法),使用这种方式能够取得最高87.1%的平均识别率,说明某些场景下全局运动会对光流造成干扰,因此直接使用光流会造成动作特征学习不稳定,而采用运动补偿或使用光流梯度可有效提高动作特征学习的稳定性,从而提高识别精度.
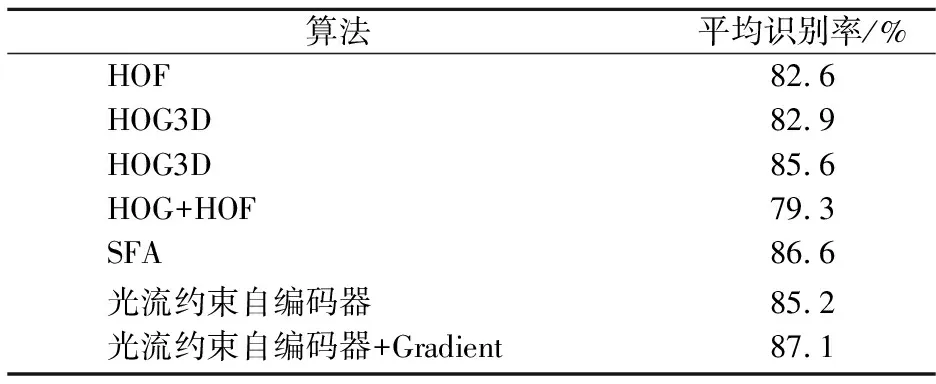
表4 UCF sports数据集上的识别结果
4 结论
1) 本文提出了基于光流约束自编码器的动作特征学习算法,该算法采用视频块中的像素灰度和对应光流作为学习机的输入,不仅可以获得视频块中像素灰度分布特性等静态信息,也可以获得视频块中像素灰度分布变化等运动信息.
2) 在公开数据集上的识别结果表明,本文提出的特征学习算法能够在不影响特征稀疏性的情况下显著提升特征的动态性,而这种动态性的提升有可能会促使识别精度的提升.
3) 在多个数据集上的识别结果对比表明,光流约束自编码器学习算法在识别精度上优于传统动作特征算法以及浅层动作特征学习算法.
References)
[1]Aggarwal J K, Ryoo M S. Human activity analysis[J].ACMComputingSurveys, 2011, 43(3): 1-43. DOI:10.1145/1922649.1922653.
[2]Poppe R. A survey on vision-based human action recognition[J].ImageandVisionComputing, 2010, 28(6): 976-990. DOI:10.1016/j.imavis.2009.11.014.
[3]Weinland D, Ronfard R, Boyer E. A survey of vision-based methods for action representation, segmentation and recognition[J].ComputerVisionandImageUnderstanding, 2011, 115(2): 224-241. DOI:10.1016/j.cviu.2010.10.002.
[4]Laptev I. On space-time interest points[J].InternationalJournalofComputerVision, 2005, 64(2): 107-123. DOI:10.1007/s11263-005-1838-7.
[5]Dollár P, Rabaud V, Cottrell G, et al. Behavior recognition via sparse spatio-temporal features [C]//IEEEInternationalWorkshoponVisualSurveillanceandPerformanceEvaluationofTrackingandSurveillance. Beijing, China, 2005: 65-72. DOI:10.1109/vspets.2005.1570899.
[6]Willems G, Tuytelaars T, van Gool L. An efficient dense and scale-invariant spatio-temporal interest point detector [C]//EuropeanConferenceonComputerVision. Marseille, France, 2008: 650-663. DOI:10.1007/978-3-540-88688-4-48.
[7]Wong S F, Cipolla R. Extracting spatiotemporal interest points using global information [C]//IEEEInternationalConferenceonComputerVision. Rio de Janeiro, Brazil, 2007: 1-8. DOI:10.1109/iccv.2007.4408923.
[8]Oikonomopoulos A, Patras I, Pantic M. Spatiotemporal salient points for visual recognition of human actions [J].IEEETransactionsonSystems,Man,andCybernetics,PartB(Cybernetics), 2005, 36(3): 710-719. DOI:10.1109/tsmcb.2005.861864.
[9]Wang H,Schmid C. Action recognition with improved trajectories [C]//IEEEInternationalConferenceonComputerVision. Sydney, Australia, 2013: 3551-3558. DOI:10.1109/iccv.2013.441.
[10]Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2013, 35(8): 1798-1828. DOI:10.1109/TPAMI.2013.50.
[11]Liu L, Shao L, Li X, et al. Learning spatio-temporal representations for action recognition: A genetic programming approach [J].IEEETransactionsonCybernetics, 2016, 46(1): 158-170. DOI:10.1109/TCYB.2015.2399172.
[12]Le Q V, Zou W Y, Yeung S Y, et al. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis [C]//IEEEComputerVisionandPatternRecognition. Colorado Springs, USA, 2011: 3361-3368. DOI:10.1109/cvpr.2011.5995496.
[13]Zhang Z, Tao D. Slow feature analysis for human action recognition [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2012, 34(3): 436-450. DOI:10.1109/TPAMI.2011.157.
[14]Sun L, Jia K, Chan T H, et al. DL-SFA: Deeply-learned slow feature analysis for action recognition [C]//IEEEConferenceonComputerVisionandPatternRecognition. Columbus, USA, 2014: 2625-2632. DOI:10.1109/cvpr.2014.336.
[15]Bengio Y. Learning deep architectures for AI[J].Foundations&TrendsinMachineLearning, 2009, 2(1):1-55. DOI: 10.1561/2200000006.
[16]Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]//IEEEconferenceonComputerVisionandPatternRecognition. Columbus, USA, 2014: 1725-1732. DOI:10.1109/cvpr.2014.223.
[17]Wang X, Wang L M, Qiao Y. A comparative study of encoding, pooling and normalization methods for action recognition [C]//AsianConferenceonComputerVision. Tokyo, Japan, 2012: 572-585. DOI:10.1007/978-3-642-37431-9-44.
[18]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J].Science, 2006, 313(5786): 504-507. DOI:10.1126/science.1127647.
[19]Natarajan B K. Sparse approximate solutions to linear systems[J].SiamJournalonComputing, 1995, 24(2):227-234. DOI: 10.1137/S0097539792240406.
[20]Fortun D, Bouthemy P, Kervrann C. Optical flow modeling and computation: A survey[J].ComputerVisionandImageUnderstanding, 2015, 134: 1-21. DOI:10.1016/j.cviu.2015.02.008.
[21]Sánchez J, Perronnin F, Mensink T, et al. Image classification with the Fisher vector: Theory and practice[J].InternationalJournalofComputerVision, 2013, 105(3): 222-245. DOI:10.1007/s11263-013-0636-x.
Action recognition based on optical flow constrained auto-encoder
Li Yawei1Jin Lizuo1Sun Changyin1Cui Tong2
(1School of Automation, Southeast University, Nanjing 210096, China) (2The 28th Research Institute of CETC, Nanjing 210007, China)
To improve the capability of feature learning in extracting motion information such as amplitudes and directions and to increase the recognition accuracy, an optical flow constrained auto-encoder is proposed to learn action features. The optical flow constrained auto-encoder is an unsupervised feature learning algorithm based on single layer regularized auto-encoder. The algorithm uses the neural network to reconstruct the video pixels and use the corresponding optical flows in video blocks as a revised regularization. The neural network learns the appearances of the action and encodes the motion information simultaneously. The associated codes are used as the final action features. The experimental results on several well-known benchmark datasets show that the optical flow constrained auto-encoder can detect the motion parts efficiently. On the same recognition framework, the proposed algorithm outperforms the state-of-the-art single layer action feature learning algorithms.
action recognition; feature learning; regularized auto-encoder; optical flow constrained auto-encoder
10.3969/j.issn.1001-0505.2017.04.011
2016-11-06. 作者简介: 李亚玮(1987—),男,博士生;金立左(联系人),男,博士,副教授, jinlizuo@qq.com.
国家自然科学基金资助项目 (61402426).
李亚玮,金立左,孙长银,等.基于光流约束自编码器的动作识别[J].东南大学学报(自然科学版),2017,47(4):691-696.
10.3969/j.issn.1001-0505.2017.04.011.
TP181
A
1001-0505(2017)04-0691-06
