面向中文语音情感识别的改0进栈式自编码结构
2017-07-26朱芳枚梁瑞宇王青云邹采荣
朱芳枚 赵 力 梁瑞宇, 王青云 邹采荣
(1东南大学水声信号处理教育部重点实验室, 南京 210096)(2南京工程学院通信工程学院, 南京 211167)
面向中文语音情感识别的改0进栈式自编码结构
朱芳枚1赵 力1梁瑞宇1,2王青云2邹采荣1
(1东南大学水声信号处理教育部重点实验室, 南京 210096)(2南京工程学院通信工程学院, 南京 211167)
为进一步提高汉语语音情感识别率,基于深度学习中的自编码、降噪自编码及稀疏自编码的网络结构,提出了一种改进的栈式自编码结构.该结构第1层使用降噪自编码学习一个比输入特征维数更大的隐藏特征,第2层采用稀疏自编码学习稀疏性特征,最后使用softmax分类器进行分类识别.训练过程首先采用逐层预训练的方法,达到网络参数全面初始化的目的,然后对整个网络进行微调.在中文语音库上的情感识别实验显示,相较于单独使用栈式降噪或稀疏自编码,所提结构具有更好的识别效果.此外,基于CASIA库的对比实验显示,该结构比K近邻算法、稀疏表示方法、传统支持向量机和人工神经网络识别率分别提高了53.7%,29.8%,14.3%和1.9%.在自行录制的语音库中,该结构的识别率比人工神经网络提高了1.64%.
语音情感识别;改进的栈式自编码;降噪自编码;稀疏自编码
语音是人机交互最自然友好的方式之一,承载着说话人丰富的情感信息.但如今的人机交互并不能像人与人交流那样自由,其原因是机器不能像人一样判断对方话语中的情感.语音情感识别在人工智能领域有着非常广阔的未来,其终极目标是让机器能够像人类一样通过语音识别人类情感,实现更好的人机交互.
在语音情感识别领域,主要的研究方向是特征提取和识别算法.目前,情感识别采用的特征都是基于实践经验发现的常规特征,如图像的SIFT特征、语音的HUWSF特征[1],但所选特征是否有效很大程度上依赖于经验和运气.在识别算法方面,使用广泛的主要有K近邻[2](KNN)、支持向量机[3](SVM)、softmax[4]以及人工神经网络(ANN)[5]等.这些算法都属于监督学习方法,取得了一定成功,但识别效率不高.因此,如何提高特征提取效率、挖掘潜在特征并提高识别率,仍然亟待研究.
深度学习是基于人工神经网络概念提出的.深度学习的目的是通过组合低层特征形成更加抽象的高层特征,发现数据潜在的特征,使得学习到的特征在分类器上拥有比原始特征更好的识别率.深度学习属于半监督的学习方法,在使用人工神经网络基本结构和算法的基础上引入新的技术,解决了在使用反向传播算法训练深度神经网络时梯度消失等问题[6].
基于对深度学习网络的研究,针对汉语语音情感识别问题,本文提出了一种改进的栈式自编码结构,其结合了降噪自编码和稀疏自编码的优点,提取具有鲁棒性和稀疏性的语音情感二次特征.仿真实验基于2个中文语音库进行,即由本实验室和三星公司合作录制的普通话语音情感库和CASIA语音库[7].与KNN,SVM,softmax,稀疏表示[8](SR)以及神经网络的分类效果进行对比,结果显示本文提出的改进自编码结构识别率更高.其中,在CAISA语音库中,算法识别效果远远优于KNN与稀疏表示的方法,相较于传统分类SVM,softmax和人工神经网络,识别率分别提高了14.3%,14.7%和1.9%.在合作录制的语音库中,本文提出方法的识别率比人工神经网络提高了1.64%.
1 特征提取与去相关
在深度学习中,网络的输入通常使用原始数据,由于一条语音样本通常有几万个样本点,因此将原始语音信号直接输入到深度网络中对硬件的要求太高.为解决这一问题,算法首先提取语音信号的声学特征,然后使用深度网络对特征进行二次提取.在进行特征值提取之前,算法先对原始语音信号进行预处理,主要包括预加重、分帧、加窗、端点检测[9].常用的声学特征分为三大类:韵律特征、音质特征和频谱特征.其中,韵律特征包括基音周期、振幅和发音持续时间等;音质特征包括共振峰、能量与过零率等;频谱特征包括线性倒谱系数LPCC,MFCC以及差分MFCC等.目前,情感识别最常用的特征是基本的声学参数,加上其统计特征[9]所组成的特征向量.因此,实验采用openSMILE工具包提取每条语音的988维特征矢量.选取的特征包括语音强度、语音响度、12阶MFCC、基音周期、过零率、线谱频率等特征.此外,为了获取稳定的全局特征,算法计算了这些特征的统计参数,包括极值、均值、标准差、算数平均数、偏度、峰度等.最后,为了降低特征间的冗余度,算法使用PCA白化的方式对特征矢量进行去相关操作.
2 改进栈式自编码
2.1 栈式自编码原理
栈式自编码[6]是通过连接多个自编码器组成的深度神经网络.训练自编码器[10-11]是一种无监督的过程,它尝试学习一个恒等函数.首先,在训练阶段学习一个编码器,然后通过解码器对其进行解码,通过编码器的输入和解码器输出之间的误差,反向调节编码器参数.自编码器的工作原理如图1所示,其中f,g分别表示编码器和解码器.

图1 自编码器原理图
假设输入数据为x,x通过编码器f后可得编码h=f(x),再通过解码器g可得到x的重建信号z,即z=g(h)=g(f(x)).训练自编码器过程中,目标函数用重建误差L表示,本文使用均方误差作为重建误差,即L=‖z-x‖2.
通过最小化目标函数,算法实现了对自编码器的训练.当训练完成后,编码h可作为分类特征,该特征比原始数据特征具有更强的鲁棒性[12].为了防止自编码器学习到一个平凡解,即输出等于输入,在自编码器中加入一些正则项,具体包括:
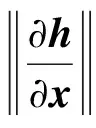
2) 针对有噪声的数据衍生出降噪自编码.
2.2 改进的栈式自编码结构
一般的深度学习网络总是使用同一种自编码器或者自编码器的变体进行深度堆叠.针对简单多层堆叠影响识别率的问题,本文提出一种结合降噪自编码和稀疏自编码的深度学习网络结构.降噪自编码最大的优势是学习到的特征维数不受输入维数的限制,从而得到比输入维数大很多的隐层特征,这也更利于降噪自编码学习得到数据本身的分布.由于本文研究的语音情感识别并不是直接通过原始数据学习特征,而是通过低维特征进行学习,直接堆叠多层降噪自编码会严重影响识别效果.为此,算法在降噪自编码后加入稀疏自编码,从而可以在不过多降低维数的情况下得到更稀疏但信息丢失更少的特征.由此可见,该结构综合了降噪自编码和稀疏自编码的优点.
改进的栈式自编码结构如图2所示.输入x∈Rd0通过降噪自编码获得一个比输入维数更大的隐藏输出h1∈Rd1(d1>d0).随后降噪自编码的输出h1进入稀疏自编码进行稀疏学习,其输出h2∈Rd2直接进入分类器.这里分类器是可选的,本文选择softmax分类器.整个训练过程分为预训练和微调2部分.预训练采用逐层对深度网络参数进行初始化的方法,该方式比随机初始化更合理有效,也极大地改善了参数对梯度传播不敏感的问题.此外,通过反向传播算法,系统可以进一步微调网络参数,获得更加强健的模型.

图2 改进的栈式自编码结构
图3 降噪自编码原理图
该结构的第2层为稀疏自编码.为了学习特征的稀疏表示,对自编码器加入某些稀疏性限制,可使其在网络学习中表现出更优的性能[12].由自编码原理可知根据隐藏层可以重建输入层,当限制隐藏层编码h2维数小于输入x的维数时,可以学习到原始数据的压缩表示.但当隐藏神经元数量较大时,通过给自编码神经网络施加稀疏性限制[14],该网络仍然可以发现数据的一些潜在特性.

(1)

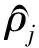

(2)

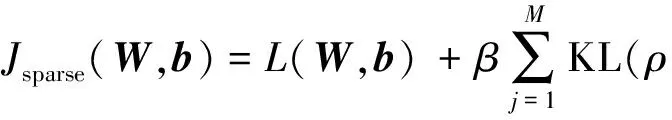
(3)
式中,L(W,b)可以是均方误差也可以是交叉熵;β控制稀疏性惩罚因子在代价函数中的权重.通过随机梯度下降算法可训练得到合适的参数(W,b).
2.3 算法流程
本文提出的改进栈式自编码结构训练和测试过程如图4所示.训练过程的第1步是预训练,预训练是一个非监督过程,首先使用语音情感特征训练降噪自编码层,来学习语音情感特征的潜在表示(LR),学习策略是使用LR重建输入信号,并使用梯度下降法最小化重建信号与输入信号的误差.当误差满足要求时,则表明一个降噪自编码训练完成.同理,使用降噪自编码的输出训练一个稀疏自编码.训练过程的第2步是微调:将预训练得到的2个自编码器级联,并在尾部加入一个softmax分类器,级联后网络实际上是一个神经网络,通过计算分类器分类结果与真实标签之间的误差,对误差求梯度,并使用反向传播算法对各层参数进行微调.测试过程如图4(b)所示,将测试集的特征输入由图4(a)训练得到的改进栈式自编码网络,可对测试集进行预测.

(a) 训练过程
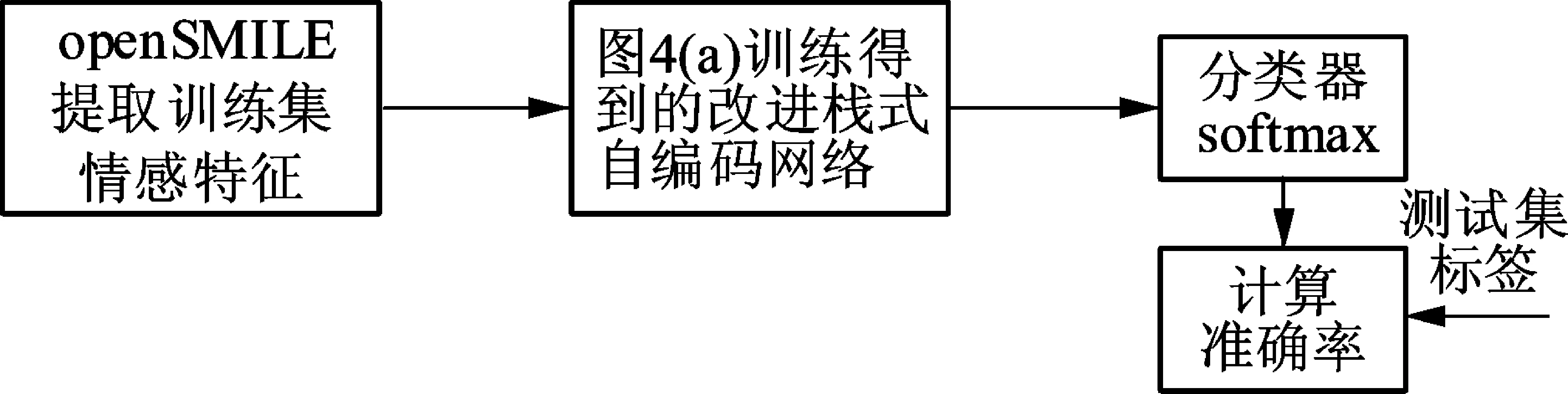
(b) 测试过程
3 实验设置
本文实验使用了2个语音情感库.一个语音数据库是CASIA,由中科院自动化所录制,由4位录音人(2男2女)在纯净的环境下录制,信噪比约为35 dB,采样率为16 kHz,以16 bit存储.共包括6种情感,分别是生气、害怕、高兴、中性、伤心、惊讶.库中一共有5句语料,由4位说话人对5句语料用6种情感分别进行演绎.共有1 200个语音样本,每种情感各包括200个样本.另一个语音库是由本实验室和三星公司合作录制的普通话语音情感库,共包括5种情感,分别为生气、烦躁、开心、伤心、中性.由16位(8男8女)说话人对20句语料用5种情感分别进行演绎.一个人对同种情感可以进行多次演绎,最后再由未参与录制的人员对每条语句情感类别进行筛选,最终生气、烦躁、高兴、中性和伤心情感各有854,1 310,1 009,1 064和1 462个样本.
为了验证本文提出的改进栈式自编码结构的有效性,选取了语音情感识别领域最常使用的一些机器学习算法进行对比实验,包括KNN,softmax,SVM,稀疏表示和神经网络.同时设计实验比较本文提出的改进栈式自编码、栈式降噪自编码及栈式稀疏自编码3种结构的性能.由于在语音情感方面中文数据库并不多且每个库中的样本量少,实验采用5折交叉验证,并取平均值作为最终的识别率.
4 结果与讨论
4.1 分类器识别率比较
表1给出了不同分类器在CASIA语音库上的识别率.可看出,分类器KNN效果较差,识别率仅为36.25%.稀疏表示方法的识别率虽有所提升,为51.15%,但也不高且训练时间较长.分类器softmax和SVM识别效果相对较好,分别为66.25%和66.67%.

表1 不同分类器在CASIA语音库上的识别率 %
4.2 不同隐藏层数的神经网络比较
表2给出了不同隐藏层数目的神经网络(均加入L1正则项,下同)在CAISA语音库与合作录制语音库上的识别率,对包含1,2,3个隐藏层的神经网络进行了对比.从表2可看出,当隐藏层数为2时,2个语音库都达到最优识别率,分别为79.05%和76.51%.隐藏层数为1和3时神经网络的识别率相对较低,这也从侧面说明在使用神经网络时并不是层数越多越好.这主要是由于与图像识别输入的是原始像素点不同,神经网络输入的是从语音信号中提取的情感特征,将已提取的特征输入神经网络中进行识别时,网络的层数不宜过高.

表2 不同隐藏层数的神经网络在语音库上的识别率 %
4.3 不同类型自编码器的比较
表3对栈式降噪自编码、栈式稀疏自编码以及改进栈式自编码的识别率进行了比较.从表3可看出,在CASIA语音库中本文提出的方法识别率为80.95%,相比于直接使用栈式降噪自编码和栈式稀疏自编码分别提高3.81%和2.38%.在合作录制语音库中,本文提出的方法相比于直接使用栈式降噪自编码和栈式稀疏自编码,识别率分别提高2.64%和1.92%,比神经网络提高约1.64%.

表3 改进栈式自编码在语音库上的识别率 %
为了更直观地对各个分类器的效果进行对比,将各个分类器的识别率绘制在图5中,图中神经网络指的是包含2个隐藏层的神经网络.图5表明,与KNN、稀疏表示方法、SVM和softmax相比,本文提出的改进栈式自编码结构识别率分别提高了约53.7%,29.8%,14.7%和14.3%.本文方法与2层神经网络相比,识别率提高了1.9%.

图5 各个分类器在CASIA语音库上的识别率
降噪自编码结构可以从被损坏的数据中学习到鲁棒性较好的特征,稀疏自编码结构通过限制神经元被激活的阈值可以学习到较稀疏的特征.改进栈式自编码结构首先对加入一定噪声的语音情感特征使用降噪自编码进行学习,得到一个维数较高的特征潜在表示h1,然后使用稀疏自编码对h1进行稀疏自编码学习得到潜在表示h2.这使得该网络结构结合了降噪自编码和稀疏自编码的优势,比一般的神经网络直接输入特征进行训练的模式具有更强的对抗噪声的能力以及稀疏化特征的能力,通过微调网络后,可以达到比现有神经网络更好的效果.
5 结语
针对目前情感识别效率不高的问题,本文结合稀疏自编码和降噪自编码结构的优点,提出了一种改进的两层栈式自编码结构.该结构可利用降噪自编码与稀疏自编码的优势,其学习得到的二次特征具有鲁棒性和稀疏性.由实验结果可知,本文提出的改进栈式自编码结构在中文语音情感识别库中具有较好的识别率,比单独使用栈式降噪自编码和栈式稀疏自编码效果更好.在CASIA语音库的仿真实验中,识别率比SVM提高约14.3%,相较于softmax分类器识别率提高了14.7%,比添加L1范数正则项的神经网络提高了1.9%.在合作录制的语音库中,本文提出的结构识别率比神经网络提高约1.64%.
未来拟在其他语种数据库上进行实验,尝试设计一种跨库的情感识别模型;设计合适的卷积神经网络结构和LSTM网络结构对语音情感进行识别.
References)
[1]Sun Y X, Wen G H, Wang J B. Weighted spectral features based on local Hu moments for speech emotion recognition[J].BiomedicalSignalProcessingandControl, 2015, 18: 80-90. DOI:10.1016/j.bspc.2014.10.008.
[2]张昕然, 查诚, 徐新洲,等. 基于LDA+kernel+KNNFLC的语音情感识别方法[J]. 东南大学学报(自然科学版), 2015, 45(1):5-11. DOI: 10.3969/j.issn.1001-0505.2015.01.002. Zhang Xinran, Zha Cheng, Xu Xinzhou, et al.Speech emotion recognition based on LDA+kernel+KNNFLC[J].JournalofSoutheastUniversity(NaturalScienceEdition), 2015, 45(1):5-11.DOI: 10.3969/j.issn.1001-0505.2015.01.002.(in Chinese)
[3]Burges C J C. A tutorial on support vector machines for pattern recognition[J].DataMining&KnowledgeDiscovery, 1998, 2(2):121-167.
[4]UFL DL. Softmax regression [EB/OL].(2013-04-07)[2016-11-10].http://deeplearning.stanford.edu/wiki/index.php/Softmax-Regression.
[5]Hassoun M H. Fundamentals of artificial neural networks[J].ProceedingsoftheIEEE, 1996, 84(6): 906. DOI:10.1109/jproc.1996.503146.
[6]Bengio Y, Courville A. Deep learning of representations[M]//HandbookonNeuralInformationProcessing. Berlin:Springer, 2013:1-28.
[7]韩文静, 李海峰. 情感语音数据库综述[J]. 智能计算机与应用, 2013, 3(1): 5-7. DOI:10.3969/j.issn.2095-2163.2013.01.002. Han Wenjing, Li Haifeng. A brief review on emotional speech databases[J].IntelligentComputerandApplications, 2013, 3(1): 5-7. DOI:10.3969/j.issn.2095-2163.2013.01.002.(in Chinese)
[8]Aharon M, Elad M, Bruckstein A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation[J].IEEETransactionsonSignalProcessing, 2006, 54(11):4311-4322. DOI:10.1109/tsp.2006.881199.
[9]蒋丹宁, 蔡莲红. 基于语音声学特征的情感信息识别[J]. 清华大学学报(自然科学版), 2006, 46(1): 86-89. DOI:10.3321/j.issn:1000-0054.2006.01.023. Jiang Danning, Cai Lianhong. Speech emotion recognition using acoustic features[J].JournalofTsinghuaUniversity(ScienceandTechnology), 2006, 46(1): 86-89. DOI:10.3321/j.issn:1000-0054.2006.01.023.(in Chinese)
[10]Bengio Y. Learning deep architectures for AI[J].FoundationsandTrends®inMachineLearning, 2009, 2(1):1-127. DOI:10.1561/2200000006.
[11]Deng J, Zhang Z, Eyben F, et al. Autoencoder-based unsupervised domain adaptation for speech emotion recognition[J].IEEESignalProcessingLetters, 2014, 21(9):1068-1072.
[12]Chen X, Li M, Yang X Q. Stacked denoise autoencoder based feature extraction and classification for hyperspectral images[J].JournalofSensors, 2016, 2016: 3632943. DOI:10.1155/2016/3632943.
[13]Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C]//Proceedingsofthe25thInternationalConferenceonMachineLearning. Helsinki, Finland, 2008. DOI:10.1145/1390156.1390294.
[14]Deng J, Zhang Z X, Marchi E, et al. Sparse autoencoder-based feature transfer learning for speech emotion recognition[C]//HumaineAssociationConferenceonAffectiveComputingandIntelligentInteraction. Geneva,Switzerland, 2013:511-516. DOI:10.1109/acii.2013.90.
Improved stacked autoencoder for Chinese speech emotion recognition
Zhu Fangmei1Zhao Li1Liang Ruiyu1,2Wang Qingyun2Zou Cairong1
(1Key Laboratory of Underwater Acoustic signal Processing of Ministry of Education,Southeast University, Nanjing 210096, China)
(2School of Communication Engineering, Nanjing Institute of Technology, Nanjing 211167, China)
An improved stacked autoencoder based on autoencoder, denoising autoencoder and sparse autoencoder is proposed to improve the Chinese speech emotion recognition. The first layer of the structure uses a denoising autoencoder to learn a hidden feature with a larger dimension than the dimension of the input features, and the second layer employs a sparse autoencoder to learn sparse features.Finally, a softmax classifer is applied to classify the features. In the training process, the layer-wise pre-training is used to achieve the purpose of initializing all parameters of the network, and then the whole network is fine-tuned. The experiments on Chinese databases show that the improved stacked autoencoders achieve a better recognition rate than the stacked denoising autoencoders or stacked sparse autoencoders. In addition, the comparative experiments based on CASIA database show that the recognition rate of the structure is improved by 53.7%, 29.8%, 14.3% and 1.9%, respectively, compared with the K-nearest neighbor algorithm, the sparse representation method, the traditional support vector machine and the artificial neural network. The recognition rate of this structure is 1.64% higher than the artificial neural network on the self-recording database.
speech emotion recognition; enhanced stacked autoencoder; denoising autoencoder; sparse autoencoder
10.3969/j.issn.1001-0505.2017.04.001
2016-12-10. 作者简介: 朱芳枚(1992—),女,硕士生;赵力(联系人),男,博士,教授,博士生导师,zhaoli@seu.edu.cn.
国家自然科学基金资助项目(61375028,61571106,61673108)、江苏省青蓝工程资助项目、江苏省博士后科研资助计划资助项目(1601011B)、江苏省“六大人才高峰”资助项目(2016-DZXX-023)、中国博士后科学基金资助项目(2016M601695).
朱芳枚,赵力,梁瑞宇,等.面向中文语音情感识别的改进栈式自编码结构[J].东南大学学报(自然科学版),2017,47(4):631-636.
10.3969/j.issn.1001-0505.2017.04.001.
TP391.42
A
1001-0505(2017)04-0631-06
