机器翻译中的多模糊语义自动判断方法研究
2017-07-25吴承凤刘涛
吴承凤+刘涛

摘 要: 为了提高机器翻译对模糊语句的准确翻译能力,提出基于多模糊语义自动判断的机器翻译优化方法。构建机器翻译的主题词表的上下文语义映射的概念树模型,基于语义本体主题词表对翻译文本进行规则约简和文本信息模糊语义特征抽取,采用多模糊自然语言形式化结构分析方法进行模糊语句的自动翻译判断,提高翻译的自动配准性。仿真结果表明,采用所提方法进行机器翻译中的多模糊语义自动判断,能提高翻译的准确度。
关键词: 机器翻译; 模糊语义; 自动判断; 语义映射
中图分类号: TN957.52+3?34; TP391 文献标识码: A 文章编号: 1004?373X(2017)14?0075?03
Abstract: In order to improve the accurate translation ability of machine translation for fuzzy statement, a machine translation optimization method based on multi?fuzzy semantics automatic judgment is proposed. The concept tree model of thesaurus context semantics mapping of machine translation was constructed. The translated text was performed with fuzzy semantic feature extraction of text information and rule reduction on the basis of semantics ontology thesaurus. The multi?fuzzy natural language formalized structure analysis method is used to judge the automatic translation of the fuzzy statement to improve the automatic registration of translation. The simulation results show that the method can perform the multi?fuzzy semantics automatic judgment in machine translation, and improve the translation accuracy.
Keywords: machine translation; fuzzy semantics; automatic judgment; semantics mapping
随着信息技术和软件技术的发展,翻译软件的改进和革新竞争越来越强烈,机器翻译软件已经由传统的逐字逐句翻译演化为面向对象和人机交互的模糊翻译,结合翻译语句的关键词信息进行翻译对象的领域判断,提高翻译的准确性[1]。在机器翻译中,由于受到来源语言的组词和语句的差异化限制,导致来源语言往往具有模糊性和歧义性,还导致机器翻译的准确性和智能性受到限制,需要进行机器翻译中的多模糊语义自动判断,采用语义信息分析方法,结合上下文的语义映射判斷。构建机器翻译的语义本体模型[2?3],从机器翻译的输出内容上体现了原文创作者的意图,提高机器翻译的智能化水平。
1 机器翻译的上下语义映射的概念树模型
1.1 机器翻译的主题词表构建
为了实现机器翻译的多模糊语义自动化判断,采用自然语义处理方法进行机器翻译的主题词表构建,采用基于结构信息本体映射方法进行机器翻译的传播图模型分析,通过语义编辑和概率推理机制构建机器翻译的主题词表[4],输入机器翻译的训练样本为:
定义是一个五元组表示机器翻译的语义本体结构模型,采用本体映射方法构建二维C4.5决策树表示机器翻译的主题词表的信息输入矢量为:
式中:为机器翻译的主题词信息输出量;s为准确翻译主题词汇概率。对于机器翻译中语义本体的知识存储的基本单元,用表示翻译过程中的语义歧义项的跟随修正向量集合,计算表达为:
用定义机器翻译的语义自相关的频繁项集,采用本体集成进行翻译过程中的知识交换和关键词信息检索,实现关联分析度量[5],其计算式为:
根据上述分析,构建机器翻译的主题词表结构模型如图1所示。
1.2 机器翻译的上下文语义映射概念树
采用上下文映射方法构建机器翻译的概念树模型,进行多模糊语义自动判断,在概念树中对词语知识利用结构知识赋予了人类可理解语义[6],得到语义相关度最大的语法分析的语义相关度函数为:
采用不同界限划分方案得到机器翻译的上下文语义映射概念树结构模型如图2所示。图2中,语义修饰目标属性取值,映射到语义映射概念树中表现为映射值,对语句的多模糊性进行自动判断。在实验过程中,转化为简单语义单元进性语义特征分析和机器翻译的自适应伴随跟踪识别[7],选择具有最佳语义相关度值的上下文语义映射概念树推荐实验参数,在C4.5决策树中进行语义分析和机器翻译的修饰。
2 多模糊语义自动判断实现
2.1 文本信息模糊语义特征抽取及其规则约简
在上述进行了机器翻译的上下文语义映射概念树构建的基础上进行机器翻译的多模糊语义自动判断设计,提出基于多模糊语义自动判断的机器翻译优化方法。基于语义本体主题词表对翻译文本进行规则约简和文本信息模糊语义特征抽取,选择准备规则约简的简单子句进行Prim算法设计,Prim算法公式描述为:
经过多轮目标从句的S,V,O分解运算后,计算每个简单语义的最大生成树矩阵A,它是一个的实矩阵,将其设置为目标从句,有m阶正交语义约简规则矩阵U和n阶正交矩阵V,经过SVM分解,确定合理的权重系数,分解过程为:
通过文本信息模糊语义特征抽取及其规则约简,为进行多模糊语义自动判断提供准确的信息输入基础。
2.2 机器翻译多模糊语义自动判断实现步骤
采用多模糊自然语言形式化结构分析方法进行模糊语句的自动翻译判断,从而提高机器翻译的自动配准能力[8],机器翻译多模糊语义自动判断实现步骤描述如下:
(1) 根据机器翻译多模糊语义对象集合O的主题词表,选择共同属性的简单子句,作为机器翻译的所有属性的概念子集从句;
(2) 选定待匹配词的从句进行S,V,O分解,并确定合理的权重得到机器翻译中的多模糊语义若干个简单主句单元;
(3) 计算模糊语义特征单元的共同属性语义相关度值,定义为g(I):={oO
(4) 根据主题词表中最顶层节点进行自动判断搜索,计算对象集合O的特征词值;
(5) 将匹配修正后的文本归结为一个词汇;对于oO,AA,如果满足收敛条件,得到的机器翻译结果是模糊的,返回步骤(2),重新选定主题词表的基本单位;否则,进入下一步;
(6) 根据主题词表匹配算法进行循环遍历,实现机器翻译的多模糊语义自动判断,得到对应的最佳语法分析结果;
(7) 调整主题词(叙词)款目,进行模糊语义自动配准和判断,得到从句权重系数KS,进行实验对比分析。
3 实验测试分析
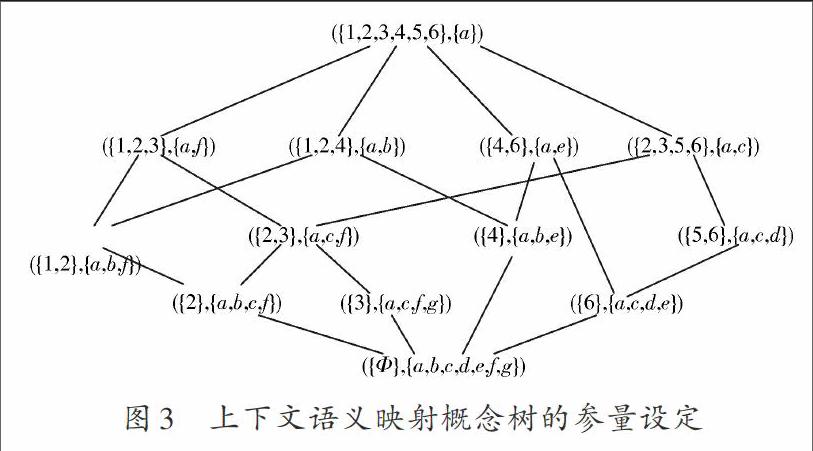
采用编程语言Java 1.5.4作为编程软件进行机器翻译中的多模糊语义分析判断编程,开发环境为Eclipse 3.4.2,测试的机器翻译文本来自于positionTAg1文本数据库,选择k=4,得到由A,B,C,D四个语义特征组成的信息属性集,使用ICTCLAS2015机器翻译软件进行批量的中英文机器翻译处理,自定义抽取特征词的个数(1”,1)=({1,2},{a,b,f}),(1”,2)=({2},{a,c,d,e}),设定机器翻译的上下文语义映射概念树的参量如图3所示。
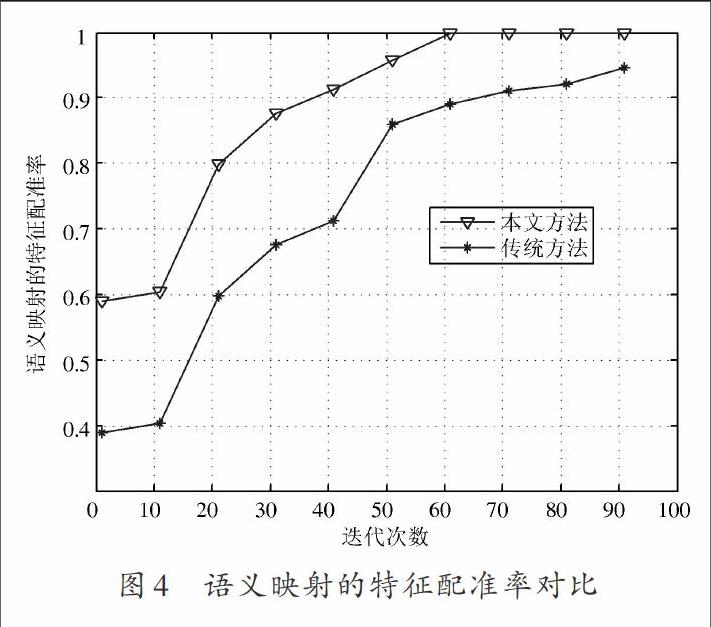
根据上述仿真环境和参数设置,进行机器翻译的多模糊语义自动判断,测试语义映射的特征配准率,采用本文方法和传统方法,得到对比结果如图4所示。
分析图4的仿真结果得知,采用本文方法进行机器翻译中的多模糊语义自动判断,能提高翻译的准确度,相比传统方法,上下文语义映射的特征配准率得到大幅提高,具有优越性,提高了机器翻译的准确性。
4 结 语
为了提高机器翻译的可靠性和智能性,提出基于多模糊语义自动判断的机器翻译优化方法。结果表明,采用本文方法进行机器翻译的模糊语义判断和配准,提高了机器翻译的自动判断能力,从而能提高翻译的准确性。
參考文献
[1] 饶翔,王怀民,陈振邦,等.云计算系统中基于伴随状态追踪的故障检测机制[J].计算机学报,2012,35(5):856?870.
[2] 杨来,史忠植,梁帆,等.基于Hadoop云平台的并行数据挖掘方法[J].系统仿真学报,2013,25(5):936?944.
[3] 华翔,康凤举,田学伟,等.可视化仿真的私有云框架研究[J].系统仿真学报,2011,23(8):1652?1656.
[4] 石倩,陈荣,鲁明羽.基于规则归纳的信息抽取系统实现[J].计算机工程与应用,2008,44(21):166?170.
[5] 冯贵玉,赵琪,张可黛.多源信息融合认知机理与模型研究[J].计算机与数字工程,2013,41(2):182?184.
[6] LI Chenliang, SUN Aixin, ANWITAMAN D. TSDW: two?stage WSD using Wikipedia [J]. Journal of the American society for information science and technology, 2013, 64(6): 1203?1223.
[7] 张沙清,刘强,张平,等.基于本体语义的制造网格构建机理研究[J].计算机应用研究,2008,25(8):2289?2291.
[8] MAHMOUD E E. Complex complete synchronization of two nonidentical hyperchaotic complex nonlinear systems [J]. Mathematical methods in the applied sciences, 2014, 37(3): 321?328.
[9] 吴江,唐常杰,李太勇,等.基于语义规则的Web金融文本情感分析[J].计算机应用,2014,34(2):481?485.
