分类加权的TF-IDF的网页分类算法
2017-07-25王彦焱李文超吉林大学
王彦焱 李文超 吉林大学
分类加权的TF-IDF的网页分类算法
王彦焱 李文超 吉林大学
网页分类算法是目前比较热门的研究课题,目前已经有许多网页分类算法,其中TFIDF算法是一种用于信息检索与数据挖掘的常用加权技术,本文通过TFIDF算法提取了每个分类下的具有高区分度的特征词,在网页分类时通过找出其中最能代表该网页的词素,依据该词素的类别信息即能对网页进行分类。由于TFIDF算法中词频计算未考虑网页结构信息,因此在本文中对词频计算进行了改进,通过对网页结构分类,计算词素出现在不同分类下的权重,达到对网页信息的合理利用。
TF-IDF 词频加权 特征词提取
1 引言
随着互联网的高速发展,网页规模呈指数级增长,对网页按照主题进行分类,一方面可以根据需要,滤除包含不良信息的网页,净化网络环境;另一方面可以按照主题为用户提供类别目录,这样既可以实现网页的分级管理,而且为使用户更方便的查找所需要的信息,从而提高网页浏览的效率。因此,网页分类技术的研究正在成为继文本分类技术的另一大热点。
2 网页预处理与中文分词
2.1 网页预处理
网页是信息的集合,其中包含的信息类型非常复杂,一个网页除了标题、正文之外还可能含有广告、友情链接等信息,这些信息对文本分类的帮助很小,甚至会干扰正确的结果。网页噪声处理目前已经存在许多方法有,比较常用的有java的开源项目HTMLParser设计的处理方法,它能超高速解析HTML,而且不会出错。另外,网页中一般包含有大量的网页布局信息,比如javescript和sytle标识的信息等,这样的信息只是在说明网页的表示,输入网页分类算法中的噪声,所以应该在算法之前将其删除,否则会对分类算法造成干扰。
2.2 中文分词
中文分词不同于英文,英文中每个单词之间都有空格分隔,中文书写以字为单位,一个或多个汉字组成一个词,中文分词要做的就是把句子拆分成词语,以便后续使用。目前存在的中文分词算法中,中科院计算技术研究所推出的基于隐马尔科夫模型的ICTCLAS汉语分词器分词效率达到95%以上,是目前公认的最好的汉语分词器。
3 分类加权的TF-IDF的网页分类算法
3.1 TF-IDF算法
TF-IDF是一种统计方法,用于评估一个字词在其所在文档中的重要程度。主要思想是:如果某个词素在一个文档中出现的频率TF高,并且在其他文档中很少出现,则认为该词素具有很好的区分能力。tf表征一个词素在文档中出现的频率,idf值是逆向文本频率,表征词语的普遍重要性,一个词语在越多的文档中出现,则该词的区分能力越低。其中:
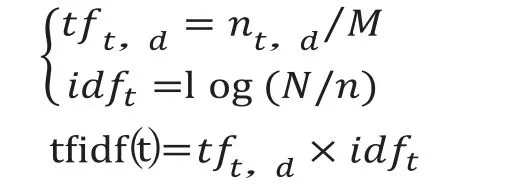
nt,d表示特征词t在文档d中出现的次数,M表示d文档总特征词数
N为文档总数,n为包含词素t的文档数。
3.2 TF-IDF算法的不足及其改进
TF-IDF算法TF值为词素的出现次数,没有考虑网页的结构信息,无论特征词出现在哪一部分,它的权重都为1。对于一个网页来说,这显然是不合理的,分析HTML文件可知,一个网页一般包含3种结构:标题、以<TITLE><TITLE>标记网页正文和其余部分。
本文采用分类加权的方法对其改进,将网页分成上述3个部分,给每个部分赋予不同的权值。权值的大小可采用机器学习中的线性回归法来确定,输入一定规模的训练集,找出使损失函数值最小的权值分配。确定权值后计算每个网页的TF值时改进的公式为
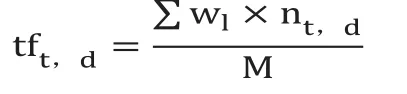
w1为词素出现在不同位置时的权重。
3.3 特征词提取
特征词的提取是整个分类算法的关键,特征词提取的效果直接影响分类的准确度,算法要保证特征词具有高区分度,由于原始TF-IDF算法求出的是词素对其所在文档的区分度,因此要提取能够区分每个类别网页集合的特征词,需要将每个类别当成一个集合看待,这样求出的具有较高TFIDF值的词即是在每个类别中具有高区分度的词,算法思想为,将每个类别中的所有网页看作一个单独的集合,在每个类别中以网页为单位计算加权分类的TF值,再以类别为单位计算总TF值与IDF值,之后算出的TFIDF值越高,则代表该词越具有区分度,流程为:①选取合适规模的已分类网页。②将每个类中的所有网页看成一个集合,计算每个类中网页的所以词素TF值,之后计算每个词素在该类别下的总TF值。以i表示类别集合,j表示每个网页,则词素t在i类别下的TF值为:

③每个类别中的词素IDF值为总分类数除以包含该词语的分类的数目,再将得到的商取对数得到计算每个类中的所有词素的TFIDF值并进行排序。④去掉平凡词后在每个类中选取排名前500的词作为该分类的特征词。
3.4 分类算法
分类算法的流程为:
对于新的网页,计算网页中所有词的TFIDF值进行排序。
取值最大的词素,若该词素属于某个类别的特征集合,则将网页设置为该类别,否则删除该词,再次取值最大的词进行比较,以此类推求出网页的类别。
[1]张祥.一个网页分类系统的研究与实现[D].北京邮电大学,2013
[2]孔令成.基于特征提取和权值计算算法的中文网页分类研究[D].安徽大学,2010
[3]彭浩,王雅琳.一个面向实时网页分类的主题特征提取算法[J].计算机与现代化,2008,(7)
