一种针对多处理器片上系统的静态任务分配方法
2017-07-19吉慧,周磊
吉 慧,周 磊
(扬州大学 信息工程学院, 江苏 扬州 225000)
一种针对多处理器片上系统的静态任务分配方法
吉 慧,周 磊
(扬州大学 信息工程学院, 江苏 扬州 225000)
随着集成技术的快速发展,使得单个芯片上集成IP核数目越来越多。然而,晶体管密度和处理器工作频率的不断提升,使得功耗密度持续增加,导致芯片热量的不断上升。因此,MPSoCs面临不可避免的散热问题。提出了一种基于处理器核区域均温(Regional Mean Temperature,RMT)的初始任务分配策略,该方法充分考虑到处理器核区域温度。通过向量距离计算处理器核温度梯度,使用遗传算法进行初始任务分配。实验结果表明,该策略相比于随机任务分配策略,峰值温度降低率、热点降低率和温度梯度降低率最高分别达到4.69%、42.31%和77.49%。
多处理器片上系统(MPSoCs);任务分配;区域均温;遗传算法
Abstract With the rapid development of integration technology,more and more IP cores are integrated on a single chip.However,the improvement of the transistor density and processor working frequency results in increasing power density and heat generation.So MPSoCs are facing inevitable heat dissipation problems.In this paper,a task allocation method based on the Regional Mean Temperature(RMT) of the processor core is proposed.The method fully considers the regional temperature of processor cores by using vector distance to calculate temperature gradient and adopting genetic algorithm to assign the initial task.Experiment results indicate that,compared with the random task allocation strategy,the peak temperature reduction,hotspot reduction and temperature gradient reduction in RMT strategy can reach the maximum values of 4.69%,42.31% and 77.49%,respectively.
Key words Multiprocessor System-on-Chip(MPSoC);task allocation;regional mean temperature;genetic algorithm
0 引言
随着集成电路工艺技术的发展,芯片内部可集成的IP核数目不断增加,出于对可扩展性、连线延时和功耗等因素的考虑,片上网络(Network on Chip,NoC)逐渐成为多核间通信的主流方式[1-3]。传统全局互连方式(总线互连)已无法适应当前多处理器片上系统(MPSoCs)的通信需求。因此,结合片上网络(NoC)结构设计的新兴MPSoCs 随之涌现。然而,较大的晶体管密度及不断提高的处理器工作频率使芯片内功耗加大,导致 MPSoCs中处理器过热。过热的处理器温度,不仅降低系统的性能,同时缩短了元器件的寿命[4-6]。因此,热量分布和温度控制是设计MPSoCs的关键。
然而,系统初始运行状态下的任务初始分配对之后的热量分布和温度控制至关重要。目前,基于软件方法的散热研究分为静态任务分配和动态任务调度2种。静态任务分配又分为离线(off-line)算法和在线算法。离线算法是在系统运行前通过外部的计算,对任务进行优化分配。在线算法指在系统运行时由芯片内部处理器计算任务初始分配方法。由于在线算法可以根据下载的任务,在系统内部对任务进行自动分配处理器资源需要消耗系统本身的计算资源,因此算法的复杂性受到限制,相比于在线算法,离线算法可以充分利用外部计算资源实现复杂算法以获得更好的初始任务分配。因此,本文选择以离线算法为技术基础设计任务分配方法。
系统中的热量由2部分产生:处理器功耗和通信功耗。当系统中待分配的任务确定,系统中处理器功耗就已经确定。通信功耗与待分配任务被分配的位置有关。即使通信任务已经确定,然而在不同分配结果下,通信功耗也存在巨大差异。但该要求与系统热量分布要求相互矛盾:由于任务间通信量较大的任务往往要消耗更多的处理器功耗来获得足够的计算能力,因此,从热量分布的角度来看,任务间通信量较大的将会被分在相距较远区域,以防功率密度升高区域温度上升,产生热点。而这种分配策略却导致通信功耗上升,加剧系统过热风险。因此,均衡通信功耗与热量分布之间的关系至关重要。文献[7]中,Zhu C 等人根据离线功耗均衡算法对任务进行初始分配,该方法使用 HotSpot软件进行仿真,对任务进行分布和调整,从而降低芯片的峰值温度,提高系统可靠性。文献[8]中,Han Wang等人提出一种热管理策略,通过温度控制器管理温度,实现性能提升。文献[9]中,Lung C L 等人考虑到未分配任务对全局处理器核温度分布影响,提出热量感知在线任务分配策略,从而降低任务分配复杂度并且实现任务快速分配。文献[10]中,Cui Y和 Zhang W提出了一种有效热量感知任务图调度算法——自下而上机制。该方法首先将任务映射到3D NoC底层,然后选择调整一些任务到顶层,从而降低系统的峰值温度,减少了执行时间。
以上现有的分配策略只考虑了峰值温度,没有考虑到处理器核与其区域温度差对初始任务分配带来的影响。基于上述问题,本文提出一种基于处理器核区域均温的静态任务分配方法,该方法通过向量距离计算温度梯度,并基于遗传算法实现初始任务分配的优化,以降低系统的峰值温度,减小热点产生的几率,减小温度梯度,均匀全局热量分布。
1 区域均温方法设计
1.1 区域向量距离变化对处理核温度影响
在简化热传导模型中,根据温度与热阻、功耗之间的关系,IP核在稳定状态下的热量模型如下[11]:

(1)
式中,Thi,j,k为IP核在3D NoC中(i,j,k)处的温度;TAmb为环境温度;Ri,j,m为IP核在(i,j,m)处的热阻;A为IP核的面积;Pi,j,s和PRi,j,s分别为(i,j,s)处IP核平均功耗和路由平均功耗。可知IP核功耗对处理核的温度有一定的影响。
如式(2)所示,tcij表示根据向量距离选择区域某个处理器核,并且通过功耗变化后Cij的温度;σ为处理器核Cij温度增长率。4*4的mesh网络如图1所示,图1对应的向量图如图2所示。选择Bpred_0进行研究,选择区域处理器核向量距离为1、2和3处理器核,分别为DTB_1、Bpred_2和FPReg_1。当DTB_1、Bpred_2和FPReg_1的功耗分别都增加30 W,代入式(2),如图3所示,Bpred_0温度上升分别为5.631%、4.360%和4.135%。可见σ与向量距离形成负相关关系。本文选择影响最大的向量距离为1的处理器核作为区域处理器,并且研究处理器核与其区域温度差,使得最后达到均匀全局的热量分布的效果。
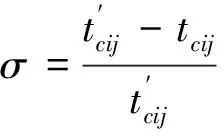
(2)
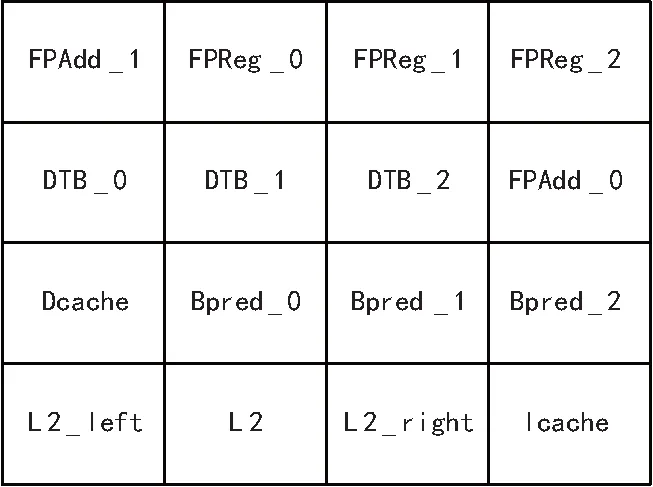
图1 4*4 mesh网络
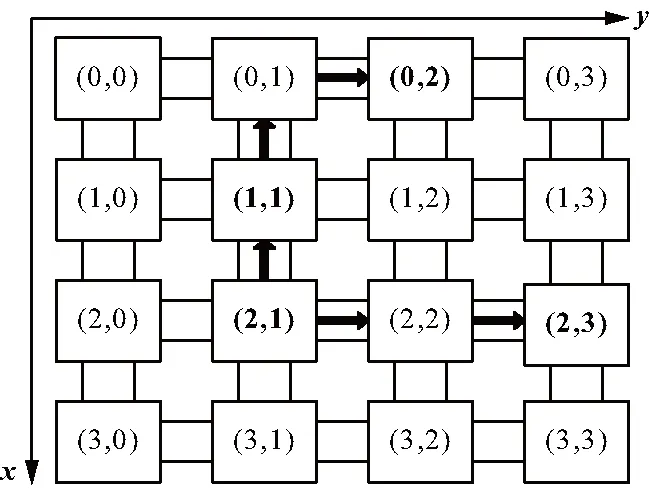
图2 向量距离
1.2 区域均温分配方法
在 2D MPSoC 中,考虑各层之间的散热能力及分配完成后的处理器核运行温度的均衡性,将相应的任务各自分配至不同层上不同位置的处理器核中是一个十分复杂的问题,假设mesh结构为N*M,对于每个核Cij(i=1,2,3……,N;j=1,2,3,…,M),同层与之向量距离为1的节点为A(i-1)j、A(i+1)j、Ai(j-1)和Ai(j+1),并且A(i-1)j、A(i+1)j、Ai(j-1)和Ai(j+1)值为0或1,根据处理器核位置的不同分别定义A(i-1)j、A(i+1)j、Ai(j-1)和Ai(j+1)的值。例如:对于FPAdd_1的A(i-1)j、A(i+1)j、Ai(j-1)和Ai(j+1)分别为0、1、0和1;对于DTB_1的A(i-1)j、A(i+1)j、Ai(j-1)和Ai(j+1)分别为1、1、1和1,如图4所示。
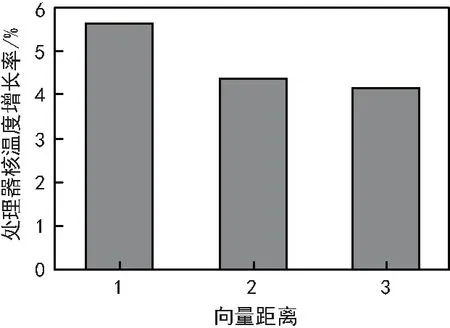
图3 区域向量距离变化对处理核温度影响

图4 处理器核区域模型
Cij对应处理核温度为TCij与之最相邻的节点对应温度为T(i-1)j、T(i+1)j、Ti(j-1)和Ti(j+1)。假设基于区域均温的处理器核温度为Tij,Tavg为T(i-1)j、T(i+1)j、Ti(j-1)和Ti(j+1)的均温,ΔTij为TCij与Tavg的差值,ΔTij的均值表示为ΔTavg,ΔTij的方差表示为μ,作为温度梯度。

(3)
ΔTij=TCij-Tavg,
(4)

(5)

(6)
适应度决定染色体个体的生存机会,与算法的优化目标相关。本文适应度函数定义如下:
f=min{μ}。
(7)
映射属于NP完全问题,为了优化温度梯度,遗传算法可以有效地解决该类优化问题,进行温度梯度的优化,方法如下:
① 产生n个染色体组成的初始种群。每个染色体用整数编码,染色体的基因与任务序号相对应,将任务分配到IP核上。其长度等于任务图中的任务数。染色体中的每个基因表示一个任务,生成初始种群时,基因值对应任务图中随机选取的顶点标号。
② 评估种群中每个染色体的适应度,采用式(7),保留最小μ,存入μ′中。
③ 应用3个遗传算子(选择、交换和变异)生成新一代种群。交叉操作如图5所示。根据适应度,从种群中选择2个父个体(适应度越大,被选中的机会越大)进行交叉,然后放入种群中,计算适应度,选择最小μ,并且与μ′比较,把最优值存入μ′。交叉操作后选择最优的染色体进行变异操作,如图6所示,将处理器核温度最高的点(任务2)与处理器核温度最低的点(任务9)进行位置交换。再次将染色体放入种群中,计算适应度,选择最小μ,并且与μ′比较,把最优值存入μ′。

图5 交叉操作

图6 变异操作
④ 重复步骤②和步骤③,直到达到最大迭代次数(1 500)或每代优化的温度梯度不再变化。如此,便得到了任务分配到IP核上的优化布局。
根据上述原则,在算法中设置种群大小为100,交换率为0.9,变异率为0.01,最大进化代数为1 500,染色体的长度等于IP核的类型数目。通过遗传算法,选择最优结果,将任务分配到相应的IP核。
2 实验结果分析
2.1 实验环境
为了验证RMT策略的有效性,采用 4*4mesh、4*6mesh、6*6mesh、6*8mesh和8*8mesh这5种拓扑结构进行实验。实验中的任务分配将基于E3S[12]基准进行实现,E3S基准中包括来自EEMBC基准的automation/industrial,officeautomation,networking,telecommunication和consumer-electronic这5个基准组。每个基准程序由一个任务图和预定的通信模式组成,E3S基准的详细信息如表1所示。

表1 E3S基准规范
2.2 实验结果
为了保证系统运行的可靠性,通常情况下处理器核的峰值温度应该保持在85 ~110 ℃,处理核温度高于85 ℃的为热点。处理器核峰值温度较高,则会导致系统运行可靠性和有效性降低。下面将区域均温分配策略与随机任务分配策略相比。用热点减少率(Hotspot reduction)、峰值降低率(Peak temperature reduction)和温度差降低率(Temperaure gradient reduction)这3个参数来计算比较RMT方案和随机任务分配(Random)方案的性能,可以分别用如下3个等式来表示。

Peaktemperaturereduction=

式中,Hotspotreduction为热点降低率;Hotspotrandom为随机分布热点平均个数;HotspotRMT为RMT分布热点个数;Peaktemperaturereduction为峰值降低率;Peaktemperaturerandom为随机分布峰值平均值;PeaktemperatureRMT为RMT峰值;Temperauregradientreduction为温度梯度降低率;μRMT为RMT任务分配处理器温度梯度;μrandom为随机任务分配处理器温度梯度。
如图7、图8和图9所示,实验选取4*4 mesh、4*6 mesh、6*6 mesh、6*8 mesh和8*8 mesh的网络,将2种任务分配策略进行比较,峰值温度降低率分别为3.66%、4.69%、3.51%、4.19%和2.95%,热点降低率分别为26.61%、15.43% 、42.31%、12.6%和23.66%,温度梯度降低 49.59%、23.13%、64.63%、77.49%和61.63%。可见经过RMT分配,系统的峰值温度、热点个数和温度梯度都得到了明显的降低,实现全局热量分布均匀,提高了系统的可靠性和有效性。

图7 峰值比较
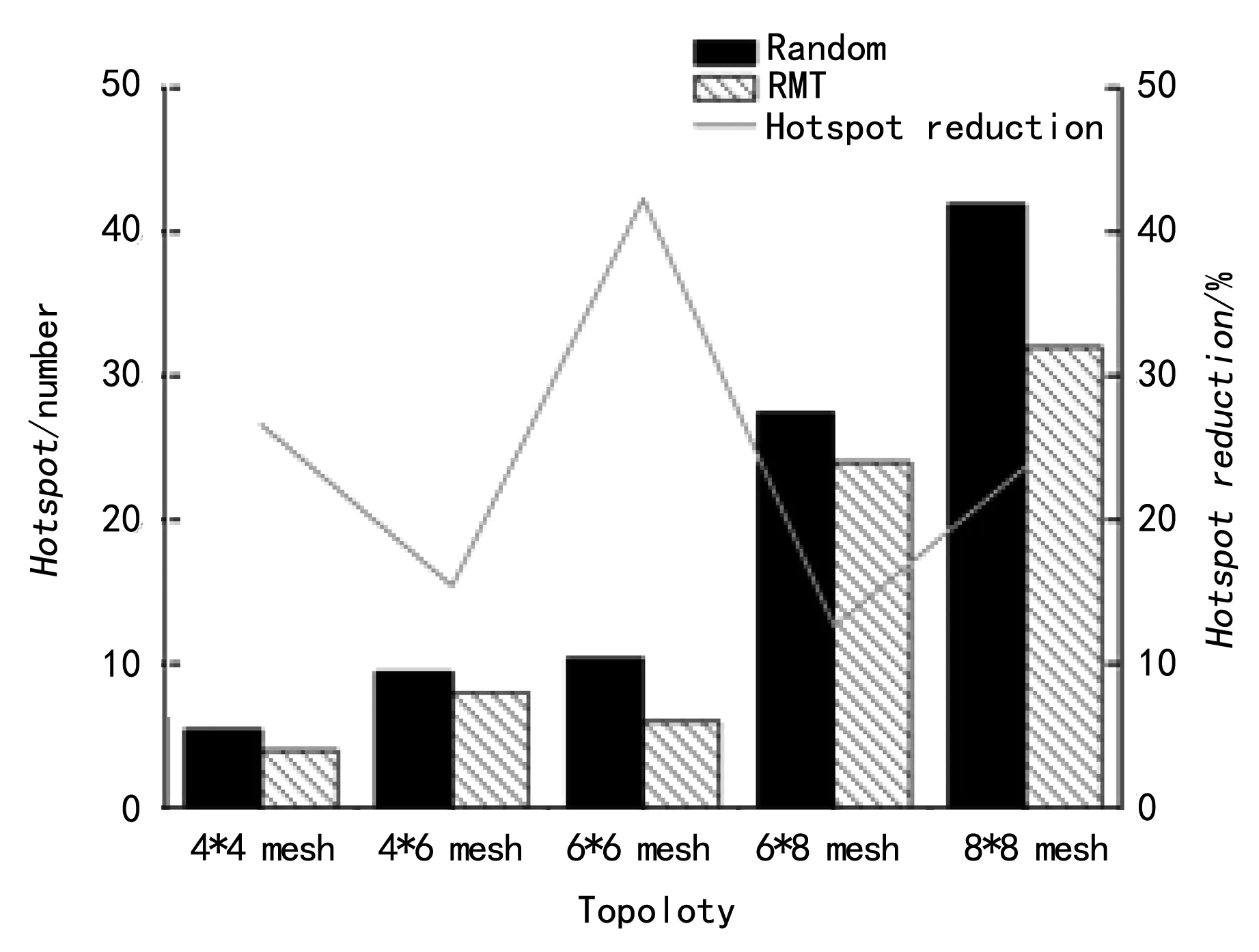
图8 热点比较

图9 温度梯度比较
3 结束语
本文针对MPSoC中的散热问题,提出了一种基于处理器核区域均温的任务分配的方法。该方法充分考虑了处理器核温度及其区域均温对其温度的影响,并通过遗传算法进行任务分配的优化。与随机任务分配策略相比,该策略降低了热点个数和峰值温度降低,同时降低了系统的温度梯度,使得全局的热量分布更加均匀。今后将针对散热问题的实时温度感知方面展开更为深入的研究。
[1] XIANG D,CHAKRABARTY K,FUJIWARA H.Multicast-Based Testing and Thermal-Aware Test Scheduling for 3D ICs with a Stacked Network-on-Chip[J].IEEE Transactions on Computers,2016,65(9):2 767-2 779.
[2] BAHREBAR P,STROOBANDT D.Adaptive Routing in MPSoCs Using an Efficient Path-based Method[C]∥ Soc Design Conference,IEEE,2013:031-034.
[3] WEI L,ZHOU L.An Equilibrium Partitioning Method for Multicast Traffic in 3D NoC Architecture[C]∥Very Large Scale Integration(VLSI-SoC),2015 IFIP/IEEE International Conference on,IEEE,2015:128-133.
[4] HAMEDANI P K,HESSABI S,Sarbazi-Azad H,et al.Exploration of Temperature Constraints for Thermal Aware Mapping of 3D Networks on Chip[C]∥ Euromicro International Conference on Parallel,Distributed and Network-Based Processing,IEEE Computer Society,2012:499-506.
[5] RAHMANI A M,VADDINA K R,LATIF K,et al.Design and Management of High-Performance,Reliable and Thermal-Aware 3D Networks-on-Chip[J].Iet Circuits Devices & Systems,2012,6(5):308-321.
[6] HUANG W,GHOSH S,VELUSAMY S,et al.Hotspot:Acompact Thermal Modeling Methodology for Early-stage VLSI Design[J].IEEE Transactions on Very Large Scale Integration Systems,2006,14(5):501-513.
[7] ZHU C,GU Z,SHANG L,et al.Three-Dimensional Chip-Multiprocessor Run-Time Thermal Anagement[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2008,27(8):1 479-1 492.
[8] WANG H,FU Y,LIU T,et al.Thermal Management via Task Scheduling for 3D NoC Based Multi-processor[C]∥SoC Design Conference(ISOCC),2010 International,IEEE,2010:440-444.
[9] LUNG C L,HO Y L,KWAI D M,et al.Thermal-aware on-line Task Allocation for 3D Multi-core Processor Throughput Optimization[C]∥ Design,Automation & Test in Europe Conference & Exhibition(DATE),2011.IEEE,2011:1-6.
[10] CUI Y,ZHANG W,CHATURVEDI V,et al.Thermal-Aware Task Scheduling for 3D-Network-on-Chip:A Bottom to Top Scheme[J].Journal of Circuits,Systems and Computers,2016,25(1):1640003.
[11] ZHU C,GU Z,SHANG L,et al.Three-Dimensional Chip-Multiprocessor Run-Time Thermal Management[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2008,27(8):1 479-1 492.
[12] GHOSH P,SEN A,HALL A.Energy Efficient Application Mapping to NoC Processing Elements Operating at Multiple Voltage Levels[C]∥International Symposium on Networks-On-Chips,NOCS 2009,May 10-13 2009,La Jolla,Ca,Usa.Proceedings.DBLP,2009:80-85.
A Static Task Allocation Method for Multiprocessor System-on-Chip
JI Hui,ZHOU Lei
(CollegeofInformationEngineering,YangzhouUniversity,YangzhouJiangsu225000,China)
10.3969/j.issn.1003-3106.2017.08.06
吉慧,周磊.一种针对多处理器片上系统的静态任务分配方法[J].无线电工程,2017,47(8):22-26.[JI Hui,ZHOU Lei.A Static Task Allocation Method for Multiprocessor System-on-Chip[J].Radio Engineering,2017,47(8):22-26.]
2017-04-01
国家自然科学基金资助项目(61376025,61301111);江苏省高校自然科学基金资助项目(13KJB510039);扬州市自然科学青年基金资助项目(SQN20150035)。
TN919
A
1003-3106(2017)08-0022-05
吉 慧 女,(1991—) ,硕士研究生。主要研究方向:电子系统集成和专用集成电路设计。
周 磊 男,(1980—) ,博士,讲师。主要研究方向:电子系统集成和专用集成电路设计。
