KDD2010比赛中基于Mahout协同过滤算法的应用研究
2017-07-18黄鹤
黄鹤
(四川职业技术学院,四川成都,629000)
KDD2010比赛中基于Mahout协同过滤算法的应用研究
黄鹤
(四川职业技术学院,四川成都,629000)
由于在线教育的迅猛发展,个性化教育应运而生,怎样在网络教育当中存储的海量用户数据提取反映用户学习能力水平与有助于提高用户学习水平的有价值信息特别关键,为此商业推荐领域广泛应用协同过滤推荐算法,以便将个性化推荐提供给用户使用者。本文通过在KDD2010比赛当中过滤技术作用发挥,有效结合教育数据挖掘,借助Apache Mahout的Taste组件各种方法,仿真建模教育数据,根据实施的实验反馈取得良好预测效果。
KDD2010比赛;Mahout;协同过滤算法;协同过滤推荐算法
1 算法评估
为确保推荐算法有效性,应该通过对比模式进行验证,使用者评分这是一种直观的方法。当尚未拥有使用者评分条件,处理应该建立一套合理评分指标。为此,协同过滤算法的一个重要环节据说选取哪种标准评价。要想具备更为准确推荐结果,形成良性循环,必须有效契合用户需求和推荐结果,用户具备特别高满意度,那么就可以将推荐系统介绍给相似用户。本文借助计算均方根误差值实施处理,所指的就是预测值和现实评分差异,以便确立算法有效程度。首先就是获得某一项目评分值,使得确定最终推荐有效性,当计算均方根误差值越小,那么体现相对可靠的推荐算法,反之,就是算法结果不好。预先设定I为问题步骤集合,S是学生集合,I是某个问题步骤,s是某个学生,相应的计算公式为:
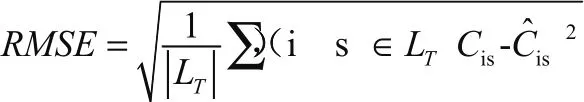
以上计算均方根误差值的公式当中,借助计算机测试集中的未知项来进行评判预测效果优劣性,然而均方根误差值属于计算数值分布在0到1范围数据误差分析,那么选择计算该数值完全和本实验数据集符合。
2 基于Apache Mahout算法实验
通过Apache Mahout仿真算法实验完成之前必须建立数据模型,确立实体信息与相互关系,有助于数据库设计与系统数据模型建立。
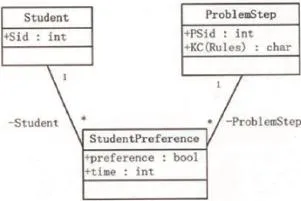
图1 学生与作答题目类模型图
本文选取的主要有表示学生类的Student类、表示问题步骤的ProblemStep类、表示某一学生作答某一问题步骤结果的StucentProference类,根据以上思路,那么具体的实现步骤如下。
第一步为建立数据库存储,通过把之前类别数据在相应数据库当中存储,而还要你管管读写文件等相关数据操作实验数据,那么在MySQL数据库当中存储转变之后的特定格式数据。Mahout引擎只接受自定义DataModel类型输入的数据,不能接受别的类型数据。
第二步做好存储推荐算法数据。本系统在JDBCDataModel数据类型读取选取的是数据库,这一数据类型有效的将DataModel类型继承,可以将相关数据在所有形式数据源当中读取,而且在这一过程当中,还存在相应的内存读取类型等别的类型操作方法。此外实验还应该扩展MySQLJDBCDataModel,从而可以让题目推荐算法当中的DataModel的实现。
第三步是实现推荐模型。在这里主要是选取基于用户、项目、SVD模型的协同过滤推荐算法的Mahout实现的介绍。
3 计算方法
余弦相似性和调整后余弦相似性则是现阶段比较高使用率的两种相似度求解模式通过两种近似度导致的均方根误差值计算与对比,在预测效果上更为准确的是修正余弦相似性,那么基于用户协调过滤选取修正余弦相似性推荐。基于item协同过滤方法进行均方根误差值计算要低于基于用户协同过滤,体现出更好推荐效果的是基于item协同过滤方法。究其原因,主要是基于用户协同过滤面临数据稀疏性,基于item协同过滤往往直接比较的是项目之间相似性,将用户之间比较跳过去。为此应该对数据稀疏性问题进行考虑。
从本文的观点来看,稀疏性就是根据ITS系统当中存在的二十一万多个不同问题,全部学生存在作答记录并不现实,那么就会导致很多空缺值。默认余弦相似性计算就是把没有作答题目作答结果预先设置成0,或者是别的学生作答评价这一题数值。当设定的是0,别的用户作答是1,在用户相似度计算的过程当中,可能明显降低两人相似程度;另外的两名学生对于某一道题目尚未作答,那么把作答结果设置成平均值或者零,那么两人拥有一致结果,极大的增加两人相似度,现实两个学生可能有不同作答结果,那么只是把作答结果设置成1并不可取。
计算相关近似性方法不同于余弦相似性,第一步就是将两个用户作答过步骤形成一个集合,基于此求出用户相似度,一些相似性进行相似度求解借助皮尔森相关系数,比较余弦相似性借助0值处理,有何更为合理结果。另外,调整之后余弦相似性和相关相似性保持一致,这种方法相应规范评价标准。本文尚未谈到评价尺度,然而借助修正余弦相似性可以将误差范围缩小,将学生作答题目平均分实施平衡评价尺度,这存在着更好效果。本文则是通过修正余弦相似性比较相似度。
虽然调整后余弦相似性能够将需求一定满足,然而受到处理期局限,那么使用者在比较低稀疏度的时候有比较多的机会回答同一问题,实际处理环节用户间特别少作答相同问题。基于小规模项目集合角度进行分析,当存在十分明显评分相似度,那么不能确定用户间特别相似。这也就显示出这种方法也有问题,如果要想结果有效性增强,必须实施相应措施,使得用户-项目评分矩阵内容增加,永辉可以作答同一问题,这也就将推荐意义提升。
4 实验描述
4.1 设定参数
进行学生-问题步骤答题矩阵的设定,在这一矩阵当中,m显示的是学生数量,n显示的是问题步骤数,Ri×j显示的是学生i作答步骤j的结果,如果学生在作答的项没有作答就通过空值显示。
4.2 项目相似性计算
通过调整后余弦相似性处理求解项目i,j相似度,具体公式为:
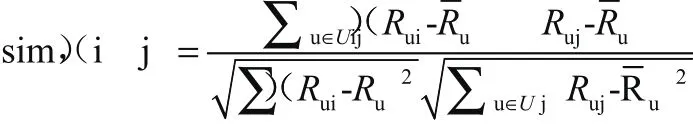
根据以上公式,Uij显示的是题目i与题目j所有答案学生集合,学生i作答问题对于集合确定为Ui,学生j作答问题对于集合确定为Uj。
4.3 稀疏矩阵填充
预测未作答题目公式为:
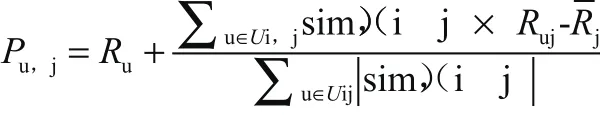
在以上公式当中,sim(i,j)所显示的为学生i和最近邻居j相似度,Pu,j取得的评分值往学生-题目作答矩阵当中回填。
4.4 计算学生用户之间相似性
两个学生相似度计算公式为:
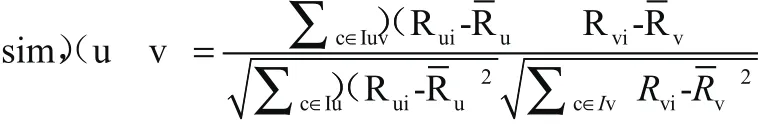
在以上公式当中,Iuv显示的是学生u与v共同作答的题目集合,Iu显示的是学生u作答题目步骤集合,Iv显示的是学生v作答的题目步骤集合,Rui显示的是学生u对于题目步骤i作答结果,Rvi显示的是学生v对于题目步骤i作答结果。
4.5 生成最近邻居集
根据对全部用户集合的有效结合,得到与目标学生u相似度明显的K个学生,确定u最近邻居集合,另外学生Uk按照相似明显性实施排列。
4.6 产生推荐结果
借助加权平均策略,产生学生u预测作答题目步骤i结果:
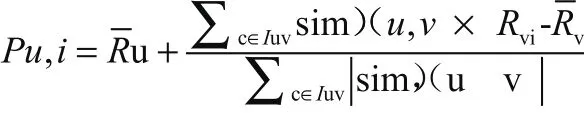
这一公式求得的就是预测回答结果值,别的负号和之前定义一致。获得最近邻居内相同问题差异化回答结果,从而让加权平均值确定下来,推荐集则是非集合当中的前面的第N项数值。
4.7 计算均方根误差值对比观察
通过比较填充之后计算预测结果和实际结果,那么就能够获得计算的均方根误差值,随后做好填充之后模型效果观察,具体的实验结果能够通过表1进行显示。

表1 均方根误差值比较列表
按照上表反馈的结果来看,填充学生-题目作答矩阵,计算获得的均方根误差值比较小,体现出比较填充之前,矩阵填充之后推荐结果更好。究其原因,这主要是用户回答同一问题矩阵规模迅速增加,这样的模式可以节省获取最近邻居用户时间,那么存在更为合理的推荐结果。此次实验获得的结果要比比赛当中得到第三名的0.3328的结果还要好,这就显示出协同过滤算法可以在挖掘教育数据集当中契合,拥有的效果更好。
5 实验结果
根据之前开展的实验结果来看,凭借着以上协同过滤推荐算法仿真实验反馈,通过推荐算法的改进,最终呈现出更加准确的预测结果,在进行相似度计算模式的分析,了解到实施调整之后余弦相似性计算方法结论更加精确,回填稀疏矩阵推荐再次进行推荐算法运用,比较之前的推荐算法,之前效果更加准确。
[1]孟卓. 基于Mahout协同过滤算法在KDD2010比赛中的探索研究[D].昆明理工大学,2016.
[2]于嘉. 基于MAHOUT的几种推荐算法的组合实现与评测[D].华中师范大学,2015.
[3]李清. 基于MovieLens数据集的协同过滤推荐系统研究[D].西安电子科技大学,2014.
[4]常江. 基于Apache Mahout的推荐算法的研究与实现[D].电子科技大学,2013.
[5]李龙飞. 基于Hadoop+Mahout的智能终端云应用推荐引擎的研究与实现[D].电子科技大学,2013.
Application Research of Mahout based collaborative filtering algorithm in KDD2010 game
Huang He
(Sichuan Vocational and Technical College,Chengdu Sichuan,629000)
with the rapid development of online education, individualized education came into being, how massive user data stored in the network education extracted user learning ability and help to improve the level of user learning valuable information is particularly critical, therefore the commercial recommended widely applied to the field of collaborative filtering algorithm, so as to provide users with personalized recommendation for users. This paper through the filtering technology role in the KDD2010 game play, the effective combination of education with the method of data mining, Apache Mahout various Taste components, modeling and Simulation of education data, according to the implementation of the feedback experiment achieved good prediction effect.
KDD2010 game; Mahout; collaborative filtering algorithm; collaborative filtering recommendation algorithm
