基于标签传播识别网络中的关键节点
2017-07-18鲍中奎张海峰
汪 宏,鲍中奎,张海峰
(安徽大学数学科学学院,合肥 230601)
基于标签传播识别网络中的关键节点
汪 宏,鲍中奎,张海峰
(安徽大学数学科学学院,合肥 230601)

基于标签传播动力学提出了一种识别网络关键节点的算法,主要思想是把每个节点接收到不同标签的数量作为判断节点重要性的指标。应用两种不同的传播模型,在不同网络上与其它中心性指标作比较。结果表明:基于标签传播的中心性指标比其它的中心性方法可以更好地识别网络中的关键节点。基于标签传播的中心性指标还具有以下优势:不需要利用网络的结构信息,因此可以推广到大规模网络上;揭示了一种现象——好的接收者往往也是好的传播者。
复杂网络;关键节点识别;标签传播算法
0 引言
面对大规模的网络,能否有效识别其中具有影响力的关键节点,具有重要的理论意义和实际应用价值。选择一个关键节点作为传播源可以让信息更加快速传播、产品发布范围更广等,免疫了网络中的关键节点,可以更好地防止疾病的蔓延和谣言的扩散等[1-5]。所以到目前为止已经提出许多识别关键节点的方法,如:度中心性[6]、介数中心性[7]、接近中心性[8]、特征向量中心性[6]、k-核[9]以及各种改进的算法[10-14]。
虽然在识别网络关键节点这个方向已经取得了一定的成果,但对这个方向的研究依然是方兴未艾。以前的算法都或多或少利用网络的结构信息,然后基于这些已知的结构信息对节点的重要性进行排序。然而针对真实的大规模网络,要获取网络完整的结构信息相当困难,那么如何避免利用网络的结构信息而设计一种新的算法识别网络中的关键节点是一个非常有意义的课题。在文献[15]中,Zhu等人利用标签传播时间的信息来寻找网络中的传播源,而在文献[16],Liao等人基于标签传播时间定义节点的相似性,进而进行链路预测等。受此启发,本文基于标签传播动力学提出了一种识别网络中关键节点的算法,在该算法中节点的中心性指标通过节点获取不同标签的数量来衡量。针对Susceptible-Infected-Recovery(SIR)疾病传播和谣言传播两者不同的传播模型,在真实网络和生成网络上比较我们的中心性指标与几个经典的中心性指标。通过研究发现,相对于经典的中心性指标本算法可以更好地识别网络中的关键节点。同时本算法还有两大优势:1)不需要利用网络的结构信息。因为每个节点在传播标签的时候,不需要知道哪些节点是自己的邻居。类似于流行病传播,每个感染节点即使不知道哪些人是自己的邻居也可以把疾病传播出去,因为只有邻居才有可能被感染,不是邻居不会被感染。也就是说,是否被传播成功已经蕴含着是否有可能是邻居节点;2)揭示一个现象——易感染节点往往也是有影响力节点。因为本算法是通过收到不同标签数量的多少来衡量节点的重要性,因此收到不同标签数量越多就说明该节点也越容易被感染。
1 理论基础与方法
1.1 标签传播动力学指标
假设网络是一个无权无向网络G(N,M),其中N代表网络中节点的数目,M代表网络中边的数目。从网络中随机选取比例为η(本文中η=0.1)的节点,每个被选中的节点各携带互不相同的标签(携带标签的节点数l取不大于ηN的最大整数),分别将标签以概率ε传播给它们的每个邻居。当节点i收到邻居节点j传来的一个标签时,节点i检查是否接收过该标签:如果没有,则节点i接收该标签并拥有该标签,下一步可以再以概率ε将该标签传播给它的邻居;如果节点i已经接收过标签,则不再接收该标签。每个标签之间的传播是没有关系的,不受彼此影响。同时对于每个标签,每个节点最多只接收一次,也最多只向同一个邻居传出一次(无论是否被接收)。所以对于每个标签传播过程而言,类似于SIR传播过程。等到网络中每个标签传播过程停止,记录节点i接收到不同的标签数目为m(i),把独立重复t次平均后的m(i)作为i点的中心性指标,这就是本文所说的基于标签传播的中心性指标。本文中每个标签的重复次数为t=100。
1.2 几种中心性指标[2]
度中心性(Degree Centrality,DC),被定义为节点的邻居数目,即
(1)
介数中心性(Betweenness Centrality,BC),是以经过某个节点的最短路径的数目来刻画节点的重要性指标,即
(2)

k-shell方法(KS)的具体步骤如下:首先把网络中度为1的节点及其所连接的边去掉,剩下的网络中会出现一些度为1的节点,再将这些度为1的节点去掉,直到所剩的网络中没有度为1的节点,则所有被去掉的节点称为1-shell;然后继续上面的方法,去掉剩下的网络中度为2的节点及其相连的边,直至不再有度值为2的节点为止,则这一轮所有被去除的节点称为网络的2-shell。依次类推,直到所有的节点都被分到相应的k-shell。
特征向量中心性(Eigenvector Centrality,EC)的基本思想是:一个节点的重要性既取决于其邻居的数量(即该节点的度),也取决于其邻居节点的重要性。运用特征向量的性质,可得每个节点的重要性对应于邻接矩阵最大特征值对应的特征向量的分量。设λ1为网络邻接矩阵A的最大特征值,v为其对应的特征向量,则节点i的重要性EC(i)为向量v的第i个分量。
1.3 疾病传播模型和谣言传播模型
在以前的文献中,通常利用SIR疾病传播模型来反映节点的实际传播能力[17],然而如[18]所述,节点的影响力受到其上动力学的影响。文献[18]指出,由于在谣言传播中大度节点一旦被感染,它会很快导致它的邻居变为已知者,因而大度节点启动了“防火墙”的作用,如果把这些节点作为传播源反而不一定利用谣言传播。因此在本文分别考虑两种传播动力学:疾病传播的SIR模型和谣言传播模型,进而更全面地反映节点的影响力。
在疾病传播模型中,网络中的节点分成3类:易感者(S)、感染者(I)和恢复者(R)[14]。易感者是没有感染疾病且会被感染者感染到的节点,感染者是传播疾病的节点,恢复者是被感染过但不传播疾病的节点[17]。当一个感染者遇到一个易感者的时候,易感者以β的概率变为感染者,传播完自己所有的邻居后,感染者以ξ的概率变为恢复者。在本文中,我们均令ξ=1。当利用SIR疾病传播模型刻画节点i的实际传播能力σ(i)时,选择这个节点作为感染者,而其它节点都是未感染者。然后按照SIR机制进行传播,当传播过程结束,即网络中不存在感染者,计算出恢复者占整个网络节点的比例,独立重复s次试验,把s次的平均值作为节点i的实际传播能力σ(i),本文中取s=100。
在谣言传播模型中也可以把网络的节点分成3类:无知者(S),传播者(I),已知者(R)。无知者是没有听到谣言且易被传播者传播到的节点,传播者是传播谣言的节点,已知者是知道谣言且不传播谣言的节点。当一个传播者遇到一个无知者的时候无知者以β的概率变为传播者。不同于疾病传播的是:当一个传播者接触另一个传播者或已知者时,最初的传播者自身以ξ的概率变为已知者,此机制是为了反映当传播者的邻居已经已知此谣言时,传播者就会失去传播的兴趣自身变为已知者[18]。在本文中,我们也令ξ=1。当利用谣言传播模型刻画节点i的影响力时,仅i自身是传播者,而其它节点都是无知者,然后按照谣言传播机制进行传播。其它类似疾病传播模型。
1.4 肯德尔相关系数
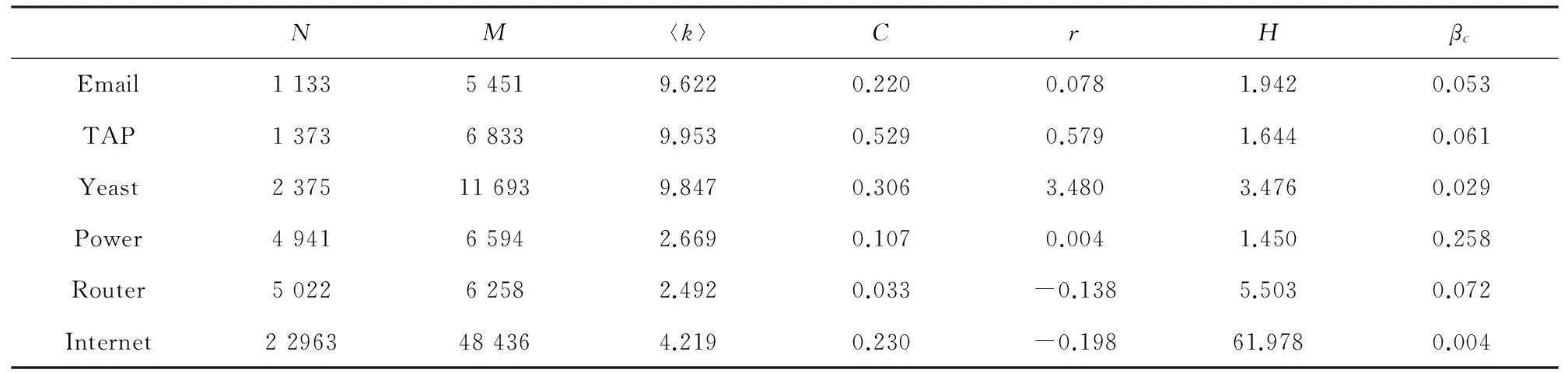
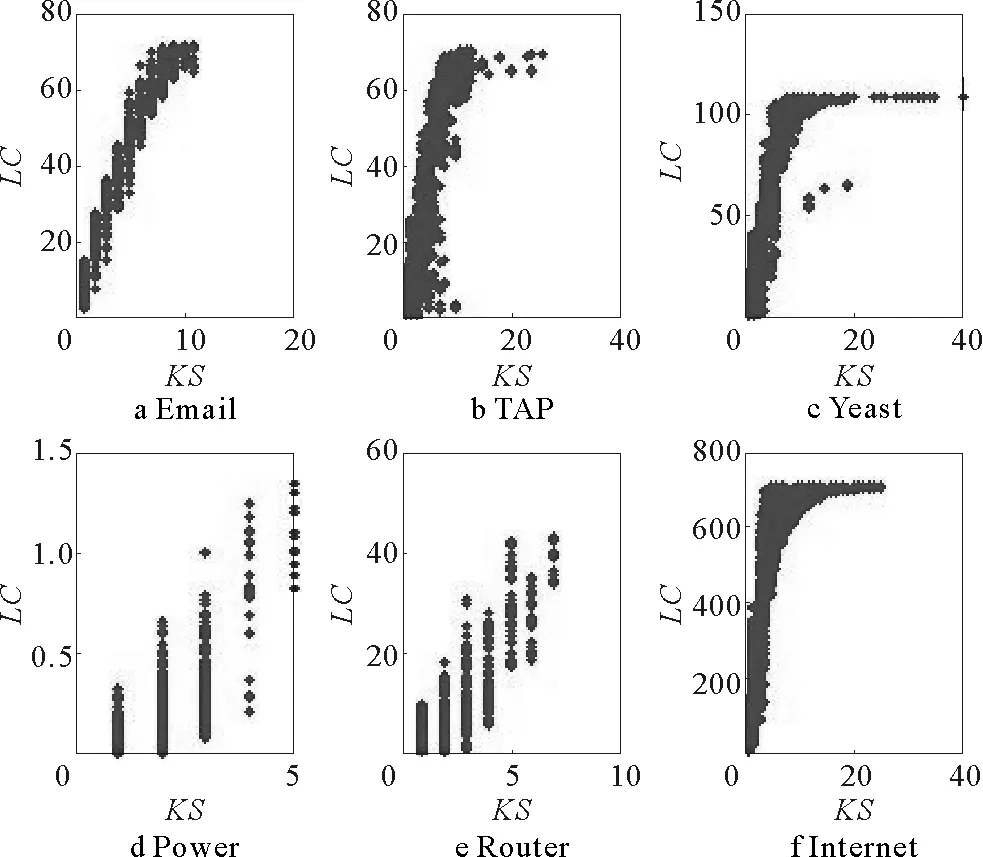
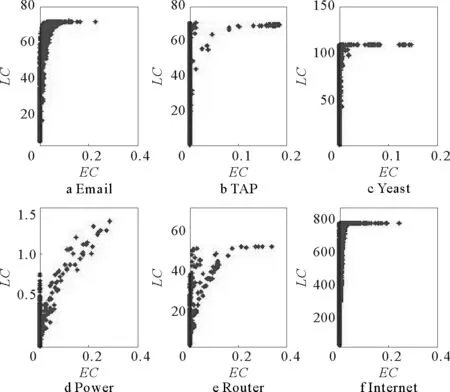
为了描述各种中心性指标识别有影响力的关键节点的能力,文中使用肯德尔相关系数来衡量。设有两个集合X和Y,任意两个节点对(xi,yi)和(xj,yj),如果满足:xi>xj且yi≥yj或者xi (3) 其中,n1为匹配一致的节点对数目,n2为匹配不一致的节点对数目,N为网络的节点数[19]。计算节点各种中心性指标与节点实际传播能力的匹配情况,τ值越大,说明匹配情况越好,进而说明该指标越能描述节点的中心性。 2.1 实验数据及相关参数 为了说明本文算法的优势,我们在6个真实网络上做了实验,包括Email,TAP,Yeast,Power,Router,Internet,表1是网络的一些参数[20]。其中,N是网络的节点总数,M是边的总数。〈k〉是网络的平均度。C和r分别是网络的聚类系数和同配系数。H=〈k2〉/〈k〉2是网络的异质性。βc=〈k〉/〈k2〉是传播阈值。 表1 不同实际网络的基本结构信息Tab.1 Basic structural properties 2.2 主要结果 为了比较各种指标识别节点重要性的能力,先计算出每个节点i的实际传播能力σ(i)(也即是以这个节点作为传染源,以SIR疾病传播或者谣言传播进行,看最终传播的范围),并根据这些节点实际传播能力值进行从大到小排序。再根据各种中心性指标对网络节点也进行从大到小排序,进而计算各种指标值与实际传播能力值的肯德尔相关系数,如果某个中心性指标与实际传播值越匹配则肯德尔相关系数值就越大,因此肯德尔相关系数值的大小可以反映某种中心性指标的优劣性。标签传播率选择太小则标签很难在网络中传开,选择太大则导致每个节点都能收到每个标签,从而导致该指标的识别率不高,如图1和图2所示,本文选择标签传播率ε=0.1,0.2和0.3进行对比,总体来看,取ε=0.2效果比较明显。 首先用SIR疾病传播模型来计算节点的实际传播能力,然后在真实网络上比较了基于标签传播的中心性指标(Label Spreading Centrality,简写为LC。其中LC1,LC2和LC3分别对应ε=0.1,0.2和0.3的情况)和几个经典的中心性指标:度中心性指标,介数中心性指标,特征向量中心性以及K-shell分解,实验结果如图1所示。图中的虚线表示疾病传播阈值βc,如表1所示。对于Power网络,由于其传播阈值βc>0.2,所以插图显示了β从0到0.4的情况。 图1 对于SIR疾病传播模型,不同的中心性指标下肯德尔相关系数τ与疾病传播率β的关系Fig.1 For SIR epidemic model and different indices, the values of τ as a function of the transmission rate β are implemented in six real networks 图1给出了德尔相关系数τ与疾病传播率β的函数关系,从图1可以发现:针对SIR疾病传播模型,当传播率β大于传播阈值(图中虚线所示)的时候,不管ε=0.1,0.2或者0.3,基于标签传播的中心性指标可以更好地刻画节点的实际传播能力,即节点的重要性。当传播率β小于传播阈值的时候疾病很难传播出去,导致很多节点都没有被感染,因此节点的实际传播能力无法刻画。对于Power网络,由于它的传播阈值大于0.2,所以在插图中显示了β从0增加到0.4的情况。如插图所示,当传播率β大于传播阈值的时候,基于标签的算法又优于其他中心性指标。图中的虚线表示疾病传播阈值βc,如表1所示。对于Power网络,由于其传播阈值βc>0.2,所以插图显示了β从0到0.4的情况。 进一步在图2中以谣言传播动力学来刻画节点的实际传播能力,然后考虑德尔相关系数τ随着谣言传播率β的变化情况。通过比较发现,基于标签传播中心性指标也明显优于其它4种中心性指标。而且总体而言介数中心性指标对于识别网络关键节点的能力最不理想。图1和图2的结果也表明:基于标签传播的中心性不仅仅对于与标签传播机理类似的疾病传播模型具有很好地识别关键节点的能力,对于谣言传播模型同样可以有效地识别关键节点。 图2 对于谣言传播模型,不同的中心性指标下肯德尔相关系数τ与疾病传播率β的关系。Fig.2 For rumor spreading model and different indices, the values of τ as a function of the transmission rate β are implemented in six real networks 另外,本文也在节点数N=2 000,平均度〈k〉=8的随机ER网络[21]和BA网络[22]上进行比较,图3a和图3b分别是SIR疾病传播与谣言传播在ER网络上的结果,而图3c和图3d分别是SIR疾病传播和谣言传播在BA网络上的结果。由于K-shell分解方法在BA网络上会导致所有节点分到同一个层中,所以在生成网络上我们不和KS算法进行比较。基于真实网络中标签传播率在0.2时总体效果较好,在此将LC指标传播率ε固定为0.2。从图3可以发现:总体而言,在SIR疾病传播和谣言传播模型中,基于标签传播的中心性指标在识别关键节点能力方面要优于度中心、介数中心性以及特征向量中心性(图3d中的特征向量中心性效果更好)指标。因而进一步证实了我们算法的优越性。图3a和3c是SIR疾病传播模型下各种中心性指标的对比;3b和3d谣言传播模型下各种中心性指标的对比。图3a和3b的随机网络上进行实验的结果;3c和3d是BA网络上进行实验的结果。网络规模N=2 000,〈k〉=8。虚线代表传播阈值。 最后在图4、图5和图6分别比较了LC指标与DC指标、KS指标以及与EC指标的相关性,其中LC指标中的传播率ε固定为0.2。从图4、图5和图6可以看出,LC指标与DC指标、KS指标以及EC指标有正相关关系,但相关性比较弱。比如DC、KS、EC值大的节点,其LC值不一定也很大;反过来,LC相同的值可能有不同的DC值、KS值以及EC值。因此基于标签传播的中心性指标可以从另外一个角度反应节点的传播能力。 图3 各种中心性指标在生成网络上的比较Fig.3 The comparison of different indices on synthetic networks 图4 在6个真实网络中,度中心性指标 (DC)与基于标签传播指标(LC)的相关性Fig.4 The correlation between DC index andLC index is analyzed on six real networks 图5 在6个真实网络中,K-shell中心性指标 (KS)与基于标签传播指标(LC)的相关性Fig.5 The correlation between KS index andLC index is analyzed on six real networks 图6 在6个真实网络中,特征向量中心性指标 (KS)与基于标签传播指标(LC)的相关性Fig.6 The correlation between EC index andLC index is analyzed on six real networks 本文基于标签传播动力学提出了一种识别网络关键节点的方法,在该方法中,节点的重要性通过节点收到不同标签数量的多少来衡量。不同于以往的算法,该算法不需要知道网络的结构信息。通过研究表明,无论是针对SIR的疾病传播模型还是谣言传播模型,该算法都能很好地识别网络中的关键节点。因此我们的算法也表明易感染节点往往也是重要节点。本文仅仅考虑无向无权的网络,针对有权网络可以把权重引入到传播率中进而推广我们的模型,而对于有向网络,我们可以首先改变网络中所有边的方向然后进行标签传播,那么收到不同标签数目多的节点也很可能就是传播能力强的节点。 [1]Newman M E J. Networks: an Introduction[M]. Oxford: Oxford University Press, 2010. [2]吕琳媛, 陆君安, 张子柯, 等. 复杂网络观察[J]. 复杂系统与复杂性科学, 2010, 7(2): 173-186. Lü LinYuan, Lu JunAn, Zhang ZiKe, et al. Looking into complex networks[J]. Complex Systems and Complexity Science, 2010, 7(2): 173-186. [3] 刘建国,任卓明,郭强,等.复杂网络中节点重要性排序的研究进展[J]. 物理学报,2013,62(17):178901. Liu JianGuo, Ren ZhuoMing, Guo Qiang, et al. Node importance ranking of complex networks[J]. Acta Phys Sin, 2013, 62(17): 178901. [4] 任晓龙,吕琳媛.网络重要节点排序方法综述[J]. 科学通报,2014, 59(13):1175-1197. Ren XiaoLong, Lü Lin Yuan. Review of ranking nodes in complex networks[J]. Chin Sci Bull (Chin Ver), 2014, 59: 1175-1197. [5] Lü L Y, Chen D B, Ren X L, et al. Vital nodes identification in complex networks[J]. Physics Reports, 2016, 650: 1-63.[6] Bonacich P. Factoring and weighting approaches to status scores and clique identification[J]. Journal of Mathematical Sociology,1972, 2(1): 113-120. [7] Freeman L C. A set of measures of centrality based on betweenness[J]. Sociometry, 1977, 40: 35-41. [8] Freeman L C. Centrality in social networks conceptual clarification[J]. Soc Netw, 1979, 1: 215-239. [9] Kitsak M, Gallos L K, Havlin S, et al. Identification of influential spreaders in complex networks[J]. Nat Phys, 2010, 6: 888-893. [10] Chen D B, Lü L, Shang M S, et al. Identifying influential nodes in complex networks[J]. Physica A, 2012, 391: 1777-1787. [11] Ma L L, Ma C, Zhang H F, et al. Identifying influential spreaders in complex networks based on gravity formula[J]. Physica A, 2016, 45: 1205-1212. [12] Liu Y, Tang M, Zhou T, et al. Improving the accuracy of the k-shell method by removing redundant links: from a perspective of spreading dynamics[J].Scientific Reports, 2015, 5: 13172. [13] Zeng A, Zhang C J. Ranking spreaders by decomposing complex networks[J].Physics Letters A, 2013, 377(14): 1031-1035. [14] 舒盼盼, 王伟, 唐明, 等. 花簇分形无标度网络中节点影响力的区分度[J]. 物理学报, 2015, 64(20): 208901. Shu Panpan, Wang Wei, Tang Ming, et al. Discriminability of node influence in flower fractal scale-free networks[J]. Acta Physica Sinica, 2015, 64(20): 208901. [15] Kai Z, Lei Y. Information source detection in the SIR model: a sample path based approach[J]. IEEE/ACM Transactions on Networking, 2016, 24(1): 408-421. [16] Liao H, Zeng A. Reconstructing propagation networks with temporal similarity[J].Scientific Reports, 2015, 5: 11404. [17] 李睿琪,王伟,舒盼盼, 等. 复杂网络上流行病传播动力学的爆发阈值解析综述[J]. 复杂系统与复杂性科学, 2016, 13(1): 1-39. Li RuiQi, Wang Wei, Shu PanPan, et al. Review of threshold theoretical analysis about epidemic spreading dynamics on complex networks[J]. Complex Systems and Complexity Science, 2016, 13(1): 1-39. [18] Borge-Holthoefer Y, Moreno Y. Absence of influential spreaders in rumor dynamics[J]. Physical Review E, 2012, 85(2): 026116. [19] Zhou T, Lü L Y, Zhang Y C. Predicting missing links via local Information[J].The European Physical Journal B, 2009, 71(4): 623-630. [20] 吕琳媛,周涛. 链路预测[M]. 上海:高等教育出版社,2014. [21] Erdos P, Renyi A. On the evolution of random graphs[J]. Publications of the Mathematical Institute of the Hungarian Academy of Sciences. 1960, 5: 17-61. [22] Barabasi A L, Albert R. Emergence of scaling in random networks[J]. Science, 1999, 286(5439): 509-512. (责任编辑 耿金花) Identifying Influential Nodes in Complex Networks Based on the Label Spreading Dynamics WANG Hong, BAO Zhongkui, ZHANG Haifeng (School of Mathematical Science, Anhui University, Hefei 230601, China) In this paper, based on the label spreading dynamics, we propose a centrality index to identify influential nodes in complex networks, where the influence of a node is measured by how many different labels who have . Under different spreading models, we compare our index with several traditional centrality indices in different networks, our results indicate that the performance of our index is better than others. Moreover, there are two typical advantages: 1), our algorithm does not use the structure information of networks, so which can be generalized to large-scale networks; 2), our algorithm implies a conclusion-a good receiver is also a good spreader. complex networks; influential nodes; label spreading dynamics 1672-3813(2017)02-0019-07; 10.13306/j.1672-3813.2017.02.003 2016-08-29; 2016-10-11 国家自然科学基金(61473001), 博士启动资金(01001951) 汪宏(1990-),男,安徽池州人,硕士研究生,主要研究方向为复杂网络上的关键点识别。 鲍中奎(1982-),男,安徽合肥人,博士,讲师,主要研究方向为复杂网络科学。 N94 A2 数值仿真




3 结语
