MySQL在健康相关数据清理中的应用*
2017-07-18郝舒欣徐东群陈凤格
宋 杰 郝舒欣 徐东群 陈凤格 刘 悦△
MySQL在健康相关数据清理中的应用*
宋 杰1郝舒欣2徐东群2陈凤格1刘 悦2△
目的 探讨MySQL技术在医院门诊、住院等医疗数据的快速清理和分类统计汇总中的应用。方法 根据数据特征制定清理规则,通过MySQL软件实现医疗数据的清理(删重、合并、校正)并重新匹配ICD-10编码,最终汇总计算分病种日接诊量等统计信息。结果 MySQL可以对医疗数据进行高效的数据清理,删除不符合要求的记录、校正错误信息及匹配正确ICD-10编码,自动生成统计报表。结论 该方法可以高效快捷地处理健康数据,尤其是医院门诊、急救、死因等大数量级数据,生成准确统计报表,在环境与健康研究中具有极强科学意义和使用价值。
MySQL 健康数据 数据清理 统计汇总
由于我国的信息化起步较晚、数据标准不统一以及录入不规范等问题,导致相关数据尤其是健康数据的质量参差不齐,存在大量缺失、重复、异常值及逻辑错误等问题[1-2]。数据质量是统计分析结果的重要保障,数据质量的好坏严重影响结果的科学性和准确性;因此,如何快速清理大量的医疗数据,获得高质量的数据,已成为环境与健康研究领域亟待解决的问题之一。
本研究以某儿童医院2012-2015年门诊数据为例,根据数据特征建立清洗规则,利用MySQL实现医院门诊个案数据的快速清洗、匹配标准ICD-10编码并生成分病种日门诊量统计报表,为后续环境与健康影响分析奠定基础。
资料与方法
1.数据来源
数据来自某三级甲等儿童医院2012年1月1日-2015年12月31日全部门诊个案记录,存储为excel格式文件,主要包括病人姓名、性别、年龄、家庭住址、出生日期、就诊日期、就诊科室、接诊医生、疾病诊断及ICD-10编码等内容。
2.方法
(1)制定清洗程序
根据数据特征,依据规范性、完整性、有效性及正确性四大原则,制定数据清洗程序(见图1)。①统一填写标准,删除字段前后的空格、数字或标点符号;②重复数据保留一条,其余删除;③合并不完整数据,针对本文案例中由于医院管理信息系统问题造成的同一病人一次就诊出现两条或两条以上不完全相同的记录,将不一致字段进行合并,融合成一条记录;④删除外地市前来就诊的记录,由于环境对人体健康的影响具有时空差异性,因此删除外地市病历记录;⑤计算年龄,修正记录中的异常值记录及错误记录;⑥按照ICD-10编码进行重匹配;⑦修正不一致记录。
(2)数据清洗
个案数据导入MySQL Server后,将表单命名为children_hospital,调整年龄字段的存储结构为INT(10),其余各字段调整为VARCHAR(100)。
①删除各字段前后的不标准字符,以姓名字段为例,代码如下:UPDATE children_hospital SET 姓名=REPLACE(姓名,LEFT(姓名,1),″)WHERE LEFT(姓名,1)=‘.’OR LEFT(姓名,1)=‘#’OR LEFT(姓名,1)=‘3’OR LEFT(姓名,1)=‘ ’;姓名后的字符将LEFT改为RIGHT。
②删除重复记录,在children_hospital表中增加自动增长且不为空的新字段ID(ID INT NOT NULL AUTO_INCREMENT,PRIMARY KEY(ID)),定义姓名、性别、出生时间、就诊时间、家庭地址、就诊科室、接诊医生、疾病诊断完全相同的记录为重复记录,保留ID最小的,删除其余记录:DELETE FROM children_hospital WHERE ID NOT IN(SELECT a.id FROM(SELECT MIN(ID)AS id,SUM(1)AS sums FROM children_hospital GROUP BY 姓名,性别,年龄,地址,出生时间,就诊科室,接诊医生,就诊时间,诊断码)AS a WHERE a.sums>=1)。
③合并不完全记录,针对部分字段存在差异、其余字段一致的记录
CREATE TABLE child_temp SELECT ID,姓名,性别,年龄,GROUP_CONCAT(DISTINCT 地址)地址,GROUP_CONCAT(DISTINCT 出生时间)出生时间,就诊时间,科室,医生,诊断码,诊断名称 FROM children_hospital GROUP BY 姓名,性别,年龄,就诊时间,诊断码ORDER BY ID。
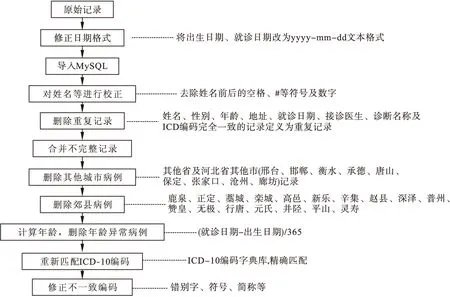
图1 医院门诊数据清洗程序
④删除外地市居民就诊记录:DELETE FROM child_temp WHERE 地址 LIKE ‘%邢台%’OR 地址 LIKE ‘%邯郸%’OR 地址 LIKE ‘%衡水%’OR 地址 LIKE ‘%张家口%’OR 地址 LIKE ‘%承德%’OR 地址 LIKE ‘%沧州%’OR 地址 LIKE ‘%唐山%’OR 地址 LIKE ‘%保定%’OR 地址 LIKE ‘%廊坊%’OR 地址 LIKE ‘%秦皇岛%’。其他区县记录更改相应区域名称。
⑤计算年龄:UPDATE child_temp SET 年龄1=DATE_FORMAT(FROM_DAYS(TO_DAYS(就诊时间)-TO_DAYS(出生时间1)),‘%Y’ )+0;根据年龄排序,观察是否有异常值及逻辑错误值:SELECT * FROM child_temp ORDER BY 年龄1 ASC;如有异常值,与年龄栏比较判断是否为录入错误,进行纠正。
⑥重新匹配ICD-10编码:UPDATE child_temp,icd10 SET newicd=icd WHERE 诊断名称=disease。由于疾病名称填写不规范(简称、错别字、拼音、缩写等)而导致的未匹配ICD-10编码的记录,需要人工查找匹配。
(3)统计汇总
根据ICD-10编码,分别计算各病种的日就诊量,以及进行性别、年龄分层汇总,生成统计报表。
①创建临时表用于存储日就诊人数:CREATE TEMPORARY TABLE temp(就诊时间 DATETIME,疾病分类 VARCHAR(50),就诊人数 INT);
②计算日就诊人数:INSERT INTO temp SELECT LEFT(就诊时间,10),‘日就诊人数’,COUNT(*)FROM child_temp GROUP BY LEFT(就诊时间,10);
INSERT INTO temp SELECT LEFT(就诊时间,10),‘总非意外疾病就诊人数’,COUNT(*)FROM child_temp WHERE LEFT(诊断码,1)REGEXP ‘[a-r]+’AND SUBSTRING(诊断码,2,2)>=‘00’AND SUBSTRING(诊断码,2,2)<=‘99’GROUP BY LEFT(就诊时间,10);
结 果
1.数据特征描述
该儿童医院2012-2015年总门诊记录为4417789条,姓名前后可能有异常字符,年龄栏描述均为“×岁×月”或“×月×天”;少量记录中缺失疾病诊断、ICD-10编码或出生日期;文件中存在大量完全重复的记录,以及仅地址和出生时间缺失的不完全重复记录(表1)。

表1 某医院不完全重复记录及不标准记录示例
2.数据清洗及ICD-10编码匹配结果
该儿童医院2012-2015年门诊总记录4417789条,去除重复记录333137条,合并不完整记录后剩余3376347条,去除其他省市及主城区外患者记录后余1806032条,去除年龄大于15岁记录80735条,余1725297条;经过三次ICD-10编码匹配,编码率达99.1%,余下15718条记录中1988条缺失疾病诊断,13730条需人工匹配。
各操作步骤处理记录及时间如表2所示,可见绝大多数运行时间消耗在ICD-10匹配环节;数据结构及质量对运行速度关系最大,数据结构越复杂、质量越差、电脑性能越低,则运行时间越长;数据量大小对速度的影响并不明显,如若电脑性能较差,可通过拆分为几个小量级的表单分别运行。

表2 医院门诊数据处理情况及处理时间
*:时间格式hh:mm:ss:ms分别代表小时、分钟、秒和毫秒。
3.准确率
从原始数据中随机抽取一天的记录(3571条)进行人工处理,发现重复数据查找与合并、外地市数据与不合理数据删除、ICD-10编码匹配、分系统分病种的就诊量统计结果均与MySQL的完全一致。
讨 论
由于各地经济发展水平不同、各家医院的管理信息系统不同、甚至各位医生的填写习惯也不同,导致健康数据的结构不统一、数据质量差异较大[3-4];而且交通的日益便捷,民众就诊范围扩大,导致与本地污染暴露不相关的外地患者记录大大增加。如本研究收集的某医院门诊记录,完全重复及部分重复记录占总记录的23.6%,市区外就诊病例达到总病例数的46.5%;如不进行数据清洗而直接进行污染暴露的相关性分析,其结果必然存在着极大的不准确性。因此,在环境与人群健康研究中,必须要关注健康数据的质量,进行严谨的数据清洗。
医院门诊量往往比较大,excel处理存在效率低下的问题。我国医疗系统的信息化起步较晚,相关的数据清理研究很少[5]。本文在分析数据特征、确立清洗流程后,将收集到的excel格式存储的门诊记录导入MySQL数据库,使用结构化查询语句进行快速清洗、汇总等数据管理;具有以下优点:(1)SQL语法简单易学,可以快速掌握运用;(2)根据数据特征组合不同程序,可处理各种数据结构问题;(3)高效准确,极大提高数据清理速度和质量;(4)MySQL为开源软件,方便获取利用;(5)MySQL体积小、速度快,在普通电脑即可运行且不需联网操作。需要强调的是,本研究首次尝试在科学研究中利用MySQL进行健康相关大数据的清洗和汇总等研究,仅作为数据管理的手段,不作数据存储等的应用;受控人员在不联网的电脑上处理数据,在查重操作后删除原始数据中的敏感信息,汇总目的数据后将门诊记录信息全部清空,可以在最大程度上保证信息的安全性。
数据清洗过程中,清洗流程的选择最为重要,由于大多数医院门诊数据都存在信息缺失或错配的情况,不合理的清洗流程往往导致有用信息的丢失,因此必须仔细研究数据特征,挖掘数据间的逻辑关系,查找问题环节、出错原因及规律,统观全局而不只是单纯的技术堆砌。
总之,本文所用MySQL技术不仅可以高效准确地清洗医院健康数据,而且可以将程序重新排列组合处理其他的大数量级数据,在环境与人群健康相关性研究中起到重要作用。
[1]刘悦,郝舒欣,宋杰,等.空气污染与疾病关系的时间序列分析中门急诊数据快速清洗及自动分类汇总方法的研究.卫生研究,2016,45(4):624-630.
[2]刘悦,郝舒欣,韩京秀,等.门诊个案数据快速清理及诊断疾病自动编码方法研究.中国医院管理,2015,35(9):69-71.
[3]杜艳君,陈晨,李湉湉.大规模数据清理的相关问题与探讨.环境与健康杂志,2014,31(4):353-354.
[4]刘钦普.中国医疗卫生发展水平区域差异综合评价.中国卫生统计,2016,33(2):251-253.
[5]门可,王霞.陕西省公共卫生专业人员配置及其核心能力需求调查分析,2015,32(6):952-954.
(责任编辑:郭海强)
公益性行业(卫生)科研专项(201402022),石家庄市科学技术研究与发展指导计划(161460873)
1.石家庄市疾病预防控制中心(050011)
2.中国疾病预防控制中心环境与健康相关产品安全所
△通信作者:刘悦, E-mail:liuyue@sina.com
