基于广告联盟的虚拟身份画像方法研究
2017-07-10彭如香孔华锋王永剑
彭如香 杨 涛 孔华锋 王永剑
(公安部第三研究所 上海 201204) (信息网络安全公安部重点实验室 上海 201204)
基于广告联盟的虚拟身份画像方法研究
彭如香 杨 涛 孔华锋 王永剑
(公安部第三研究所 上海 201204) (信息网络安全公安部重点实验室 上海 201204)
目前,网络虚拟账号繁多,大多数账号无需实名认证便可使用,这样不利于网络空间的安全维护与监管。针对这一情况,提出一种以虚拟账号为属性的网络空间身份画像方法。该方法首先利用大数据预处理技术实现从无关联的http post数据提取网络虚拟账号;然后,基于广告联盟机制,利用页面标签技术中Cookie存储用户唯一ID,将虚拟身份进行关联绑定与关联分析,进而构建虚拟身份画像原型;最后通过相似度计算方法,完成相似画像原型的重组。实验结果表明,该方法能有效刻画网络空间身份。
广告联盟 虚拟身份画像 数据挖掘 相似度计算
0 引 言
随着互联网技术日新月异,各种互联网应用应运而生,通过互联网进行沟通交流、商品交易等已经成为人们生活的一部分;互联网应用的便捷性与高效性,使得人们的生活更广泛地融入的互联网环境中。然而,这些应用大多数无需实认证就可使用,一个人可以注册多个相同种类或不同种类的虚拟账号,这给网络空间安全管理提出了艰巨难题[3],如何寻找到一种有效的虚拟身份刻画方法,成为解决该问题的重要突破口。本文基于广告联盟机制,提出一种有效的虚拟身份串并关联方法,实现网络空间身份的刻画,为网络空间安全管理提供有力的支撑。
1 广告联盟机制
广告联盟,通常指网络广告联盟。网络广告联盟,又称联盟营销,指集合中小网络媒体资源(又称联盟会员,如中小网站、个人网站、WAP 站点等)组成联盟,通过联盟平台帮助广告主实现广告投放,并进行广告投放数据监测统计,广告主则按照网络广告的实际效果向联盟会员支付广告费用的网络广告组织投放形式。
为了实现准确计费与广告匹配,广告联盟平台通常采用页面标签技术通过访客浏览器收集数据,并将这些数据发送到远程数据接收服务器,分析人员可以从远程服务器查看数据报告。图1展示广告联盟原理。这些信息通常通过放置在网站每个页面中的JavaScript代码进行收集[1-2]。页面标签技术使用cookie追踪访客,通常会在用户的浏览器端创建唯一用户ID,用户访问参与广告联盟加盟站点时,通过Cookie携带用户ID表明身份信息,用于计费、用户偏好刻画等。表1为通过账号jackcat111访问www.cshn.net时抓取的Cookie数据,表2为通过账号jackcat访问www.7k7k.com时抓取的数据。表中数据显示,这两次不同的网站访问,BAIDUID却是相同的。此处BAIDUID为百度广告联盟机制中追踪访客的用户ID,该用户ID存储在Cookie中。上述的BAIDUID跟设备、浏览器相关,并由这些因素决定,且在一定时间内保持不变,而且唯一。从而,我们可以认定账号jackcat111和jackcat为关联账号,进而通过有效的关联分析算法,将其他网络虚拟信息串并起来,从另一视角刻画网络用户。
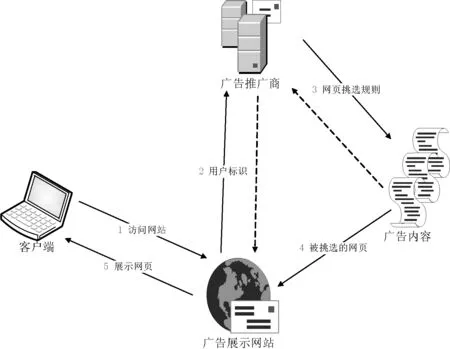
图1 广告联盟原理图

表1 访问csdn网站的Cookie数据表

续表1
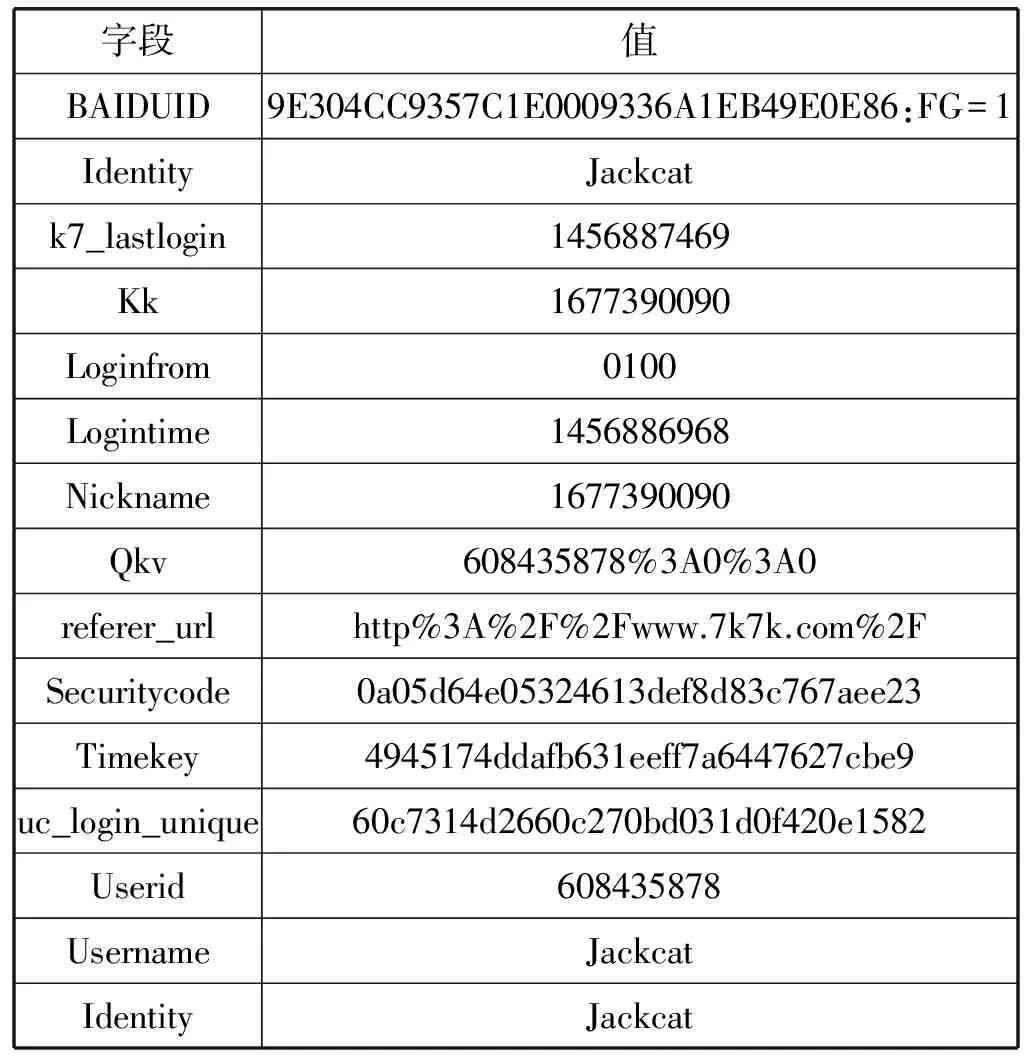
表2 访问7k7k游戏网站Cookie数据表
2 虚拟身份画像模型
通过第1节的介绍,我们可以以广告联盟用户ID为突破口,串并出关联的虚拟身份,然后通过设定的关联分析规则,归整出身份属性(虚拟账号),并通过不断的迭代更新,完善身份特征刻画模型。基于广告联盟的虚拟身份画像模型如图2所示。该模型构建过程分为两个主要过程:关联绑定、关联分析。
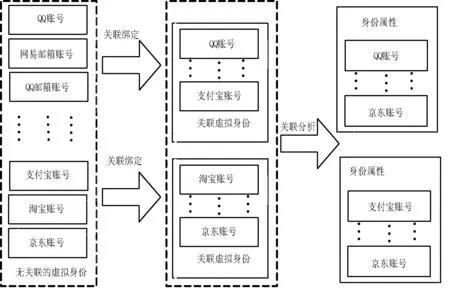
图2 基于广告联盟的虚拟身份画像模型
2.1 关联绑定
关联绑定[4-5]即通过广告联盟用户ID将无关联的虚拟身份绑定为关联虚拟身份;关联绑定分为广告联盟内虚拟身份关联绑定、广告联盟间虚拟身份关联绑定。
广告联盟内虚拟身份关联绑定规则为来自不同Cookie信息中的虚拟身份,若Cookie信息中的同一广告联盟用户ID相同,则认为这些虚拟身份为关联虚拟身份,并称为初始关联组。图3为一初始关联组,是通过百度联盟用户ID(BAIDUID)9E304CC9357C1E000 9336A1EB49E0E86:FG=1进行虚拟身份绑定的。
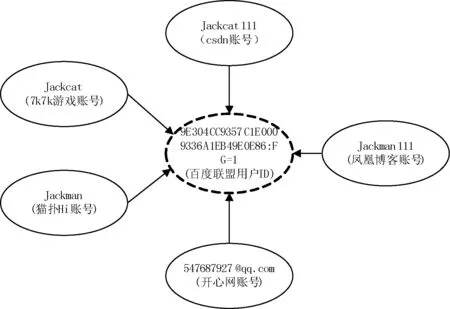
图3 初始关联组
广告联盟间虚拟身份绑定建立在广告联盟内虚拟身份关联绑定的基础上,同一时间同一IP地址上抓取的cookie信息中包含不同广告联盟用户ID,则可以将这些广告联盟用户ID对应的初始关联组合并,形成合并关联组。图4为一合并关联组,由于凤凰博客网既使用百度联盟,也使用了淘宝联盟,通过凤凰博客账号jackman111访问该网站,抓取的Cookie信息中既包含百度联盟用户ID,又包含淘宝联盟用户ID,从而可将这两个用户ID对应的初始关联组合并,进而可知淘宝账号Jackman与csdn账号jackcat111为关联账号。经过关联绑定形成的组统称为关联组。
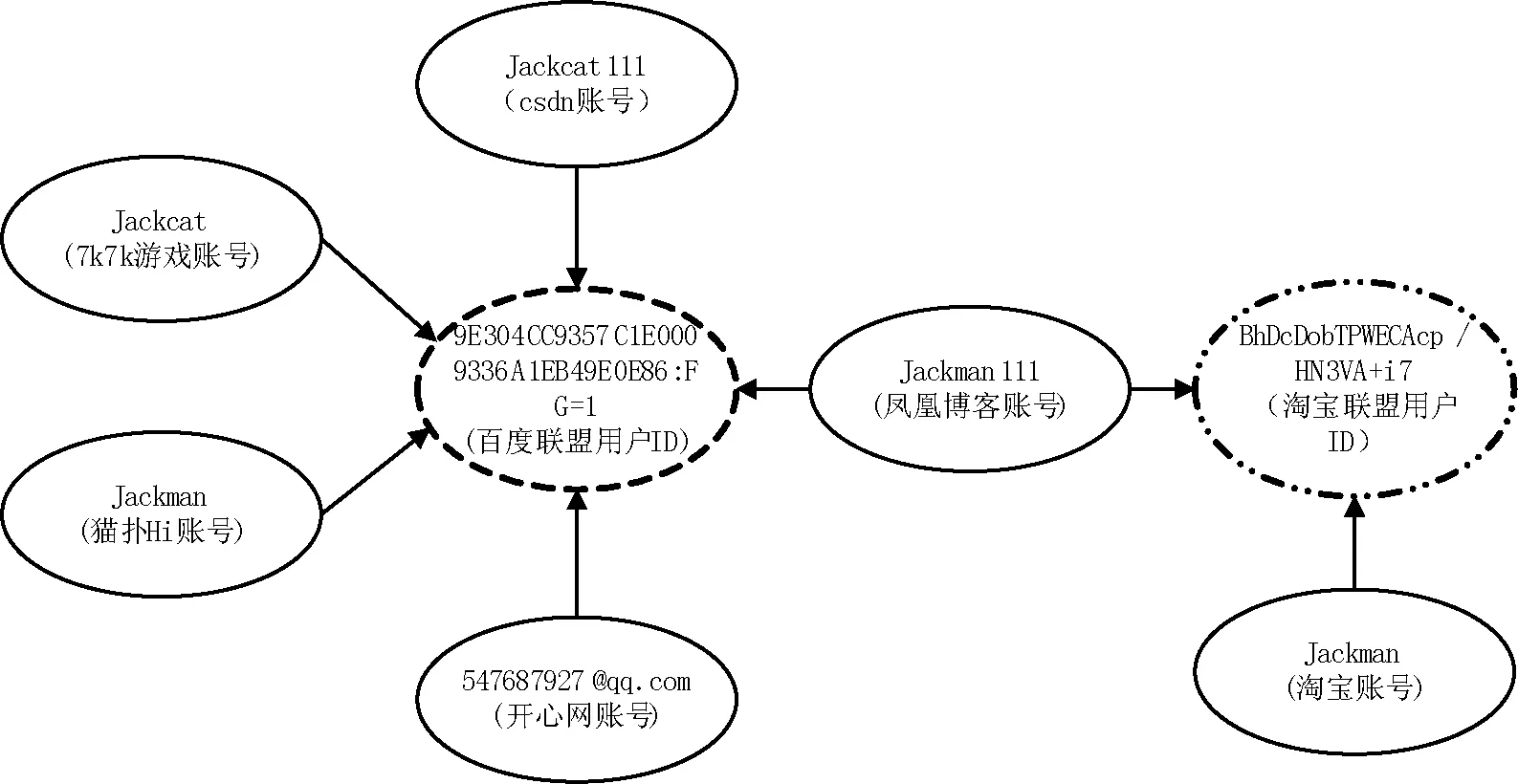
图4 合并关联组
2.2 关联分析
通过2.1节的关联绑定后,构建了一张虚拟身份关系网大图[6-7],该大图可能包含重复的信息以及不准确的信息,由此我们需要预设一些关联分析规则,进一步完善大图信息,最后对虚拟身份画像进行特征描述。
通过第1节介绍我们知道,广告联盟用户ID跟设备、浏览器相关,并由这些因素决定;当不同的用户使用同一台设备的相同浏览器时,同一关联组中将出现同一网站的不同账号。如图5所示,csdn网站的不同账号Jackcat111与tina属于同一关联组,这种情况下,将无法确定开心网账号547687927@qq.com与哪个csdn账号关联。另外同一用户使用不同的设备或不同的浏览器访问网站时,这些用户ID也会不同,这种情况可能出现某网站账号(如csdn账号tina)出现在不同的关联组。如图6所示。
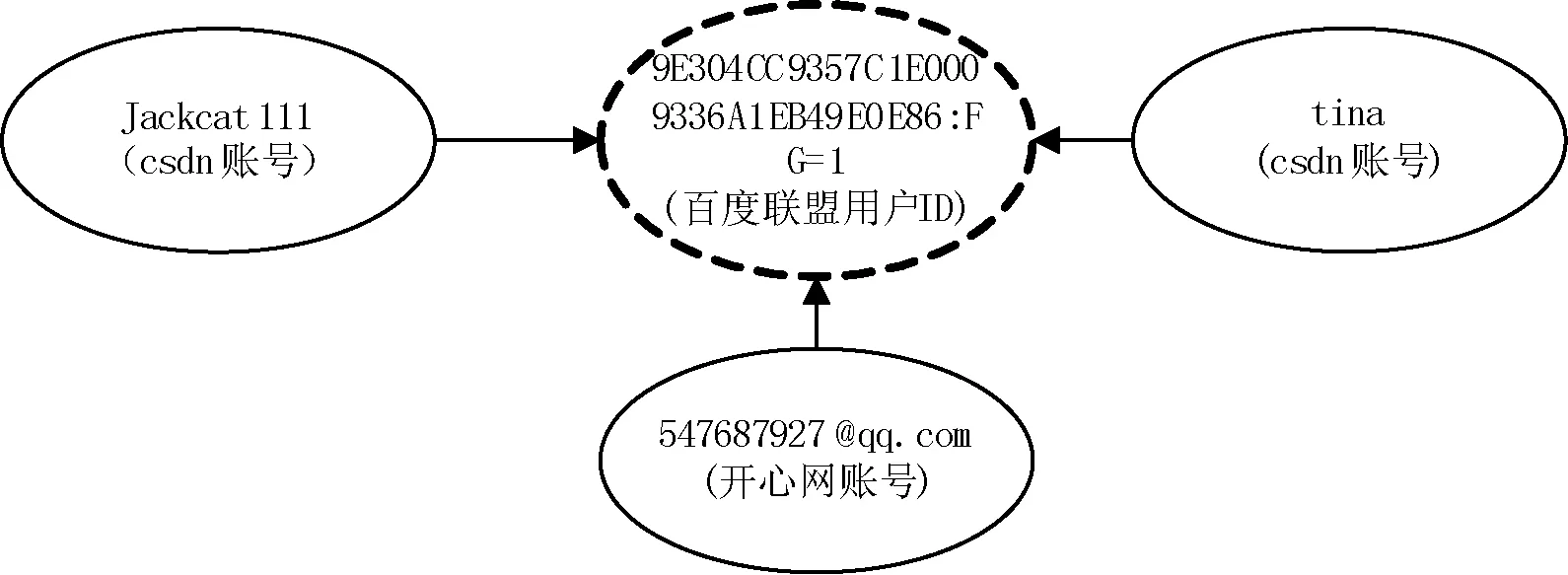
图5 出现同一网站不同账号的关联组示意图
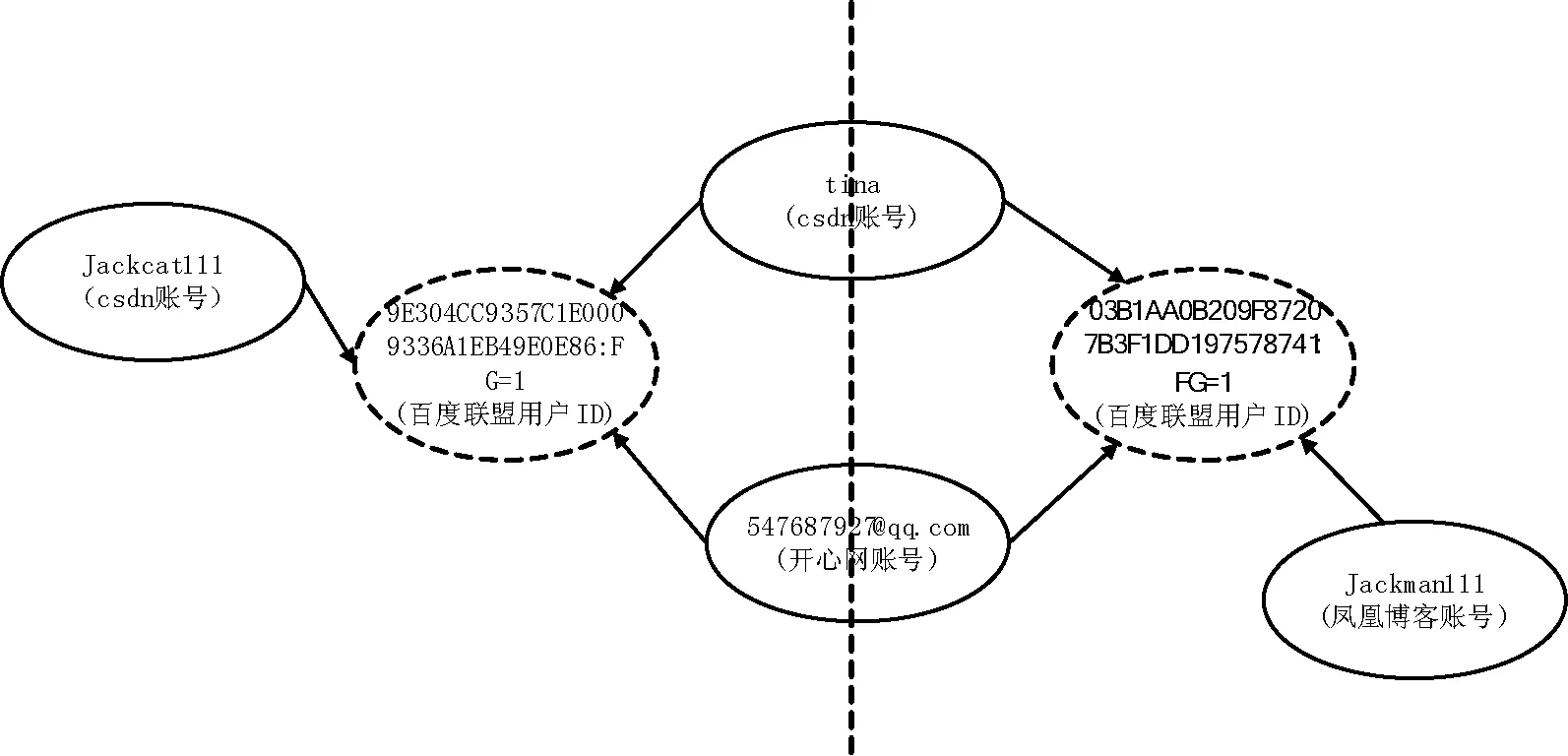
图6 同一用户不同账号被分到不同的关联组示意图
为了解决上述问题,首先我们引入关联度的定义。
定义1 关联度不同虚拟账号之间的紧密程度称为关联度。关联度的取值范围为[0,1]。不同虚拟账号之间初始的关联度为0;若两个虚拟账号关联度为1,则表示这两个虚拟账号属于同一用户;关联度为1时,具有传递性;即若虚拟账户A与虚拟账号B之间关联度为1,虚拟账户A与虚拟账号C之间关联度为1,则虚拟账号B与虚拟账号C之间的关联度也为1。
接下来,引入以下规则:
1) 初始设置关联组内的虚拟账号之间的关联度记为0.5。
2) 关联组中同一时间同一IP获取的虚拟账号之间的关联度记为1,所有相互之间关联度为1的虚拟账号组成不同用户组。
3) 不同用户组中,存在两个及以上相同虚拟账号的,判定为同一用户组,并合并这些组。
反复运用规则1)~ 3)对大图进更新,直到不满足条件为止。至此可以得到用户组群(虚拟账号之间的关联度为1)和剩下的关联组群(虚拟账号之间的关联度为0.5)。用户组群中每个用户组内不同虚拟身份我们可以认定为同一画像,从而构建虚拟身份画像原型[8-9](以下简称原型)。
以下为关联分析算法:
算法1 关联分析算法
新建一个n*n关联度矩阵A,初始值为0;这里矩阵A为上三角矩阵;
对于初始数据列表:
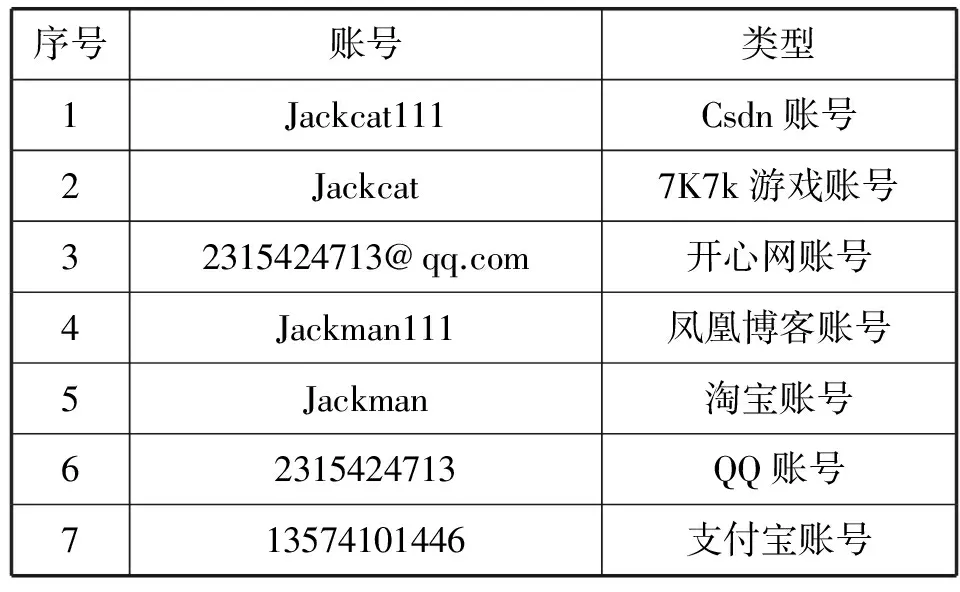
If 第k行与第m行的广告联盟类型与广告联盟值相同(0 对于所有A[k][m] = 0.5(0 If 初始数据列表中第k行与第m行的时间与IP相同,则 A[k][m] = 1; 对于所有的j,k,m (0 找出所有用户组集合A1、A2、…、Ak,每个用户组集合满足: 1) 元素由序号组成,且大于0小于n; 2) 对于任意x,y属于该集合,A[x][y]=1,(假设x 2.3 相似度计算 通过研究发现,Cookie有一定的有效期,且可以被清空,这样用户ID将重新分配;或者用户在不同的设备进行上网,这就出现同一个人将分配不同的用户ID,这样的我们也将构建的多个虚拟身份画像原型。另外,同一个人对用的用户ID所关联的虚拟身份可能不尽相同,为了使得构建的原型的更加全面,计算上一节所构建的原型之间的相似系数,计算公式采用的是改进的Jaccard相似系数,如下所示: (1) 这里的X、Y表示为不同虚拟身份画像原型。X={x1,x2,…,xn},由n个虚拟账号组成,xi表示原型X第i个虚拟账号;Y={y1,y2,…,ym},由m个虚拟账号组成,yk表示原型Y的第k个虚拟账号;当X、Y之间的IM_Jaccard相似系数超过某阈值,我们认定X、Y原型为同一原型,将X、Y原型合并,取X∪Y,组成新原型。 3.1 数据获取 通过数据截取的方式获取某局域网络一段时间的全量数据,且在该段时间内不定期地使用不同计算机使用如表3所示的账号登录网络,所获取的数据采用Redies方式存储,总的数据量大小为25.6 GB。 表3 测试账号 3.2 数据预处理 首先,从redies数据抽取包含表4所示域名以及对应用户ID标识的报文。对符合要求的报文,采用UTF-8的格式存储;处理后的数据形式如表5所示。 表4 数据抽取类型 表5 报文处理后的格式 然后,抽取Cookie中含有表6中字段标识的报文。对于这些报文,按照时间、源IP、目的域名、目的网站、虚拟账号、广告联盟类型、广告联盟值获取相应的数据,并进行相应的数据格式转换,如时间格式统一转换为“yyyy-MM-dd HH:mm:ss”格式。 表6 不同网站虚拟账号字段标识 3.3 仿真实现 仿真实验在PC机上进行,PC机的基本配置为:Intel Core i5 CPU,8 GB内存,Windows 7 操作系统;采用Python 2.7语言,使用PyCharm开发环境;采用MongoDB存储数据。实验步骤如下: (1) 原型构建 按照3.2的预处理方法,抽取相关的字段插入到MongoDB数据表中,共102 356条记录。 根据3.2节的算法1实现原型的构建,这里n取值为12 356。 构建出5 356个原型,即5 356个虚拟账号集合;每个集合的长度不一,通过计算这些集合平均长度为4.78;测试账号分成3个原型,A={Jackcat,Jackman111, 2315424713, 2315424713@qq.com },B={Jackman111,Jackcat111,2315424713@qq.com, 13574101446},C={13574 101446 , 2315424713@ qq.com, 2315424713},平均长度为3.67,少于实际长度。 (2) 相似度计算 通过式(1),计算不同原型之间的相似度系数,将不同IM_Jaccard相似系数大于设定的阈值原型合并。这里的阈值取值情况如表7所示。 表7 不同阈值下的原型情况表 由表7可知,随着阈值不断减小,原型数也不断减小,原型平均长度不断增加;当减小到一定值时,这两个值趋于稳定,由此表明最后的1 897个为独立的无冗余的原型;另外,测试账号的最终原型为所有的测试虚拟账号,进一步证明本文提出方法的有效性。这样,我们可以认定每个原型即代表网络空间虚拟身份,其通过若干个虚拟身份刻画该虚拟身份。 本文介绍了一种基于广告联盟机制的网络空间身份画像方法。该方法首先采用大数据预处理、清洗技术,实现了从无关联的http post数据提取网络虚拟账号,并利用广告联盟用户ID的唯一性将虚拟账号进行关联;然后通过虚拟账号关联分析算法,实现了虚拟身份画像原型的构建;最后采用改进的Jaccard相似系数计算算法,将相似度高的原型合并,进一步完善了画像模型,实现了网络空间虚拟身份的有效全面刻画,为网络安全管理工作提供有效的手段。 [1] 克利夫顿.流量的秘密[M].人民邮电出版社,2013. [2] Brad Geddes.Advanced Google AdWords[M].3rd ed.Avinash Kaushik,2014. [3] 李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):647-657. [4] 刘中淼,王宇翔,陶小龙,等.一种面向安全领域的身份识别与关联方法[J].软件导刊,2016,15(2):170-174. [5] Li L,Zhang M.The Strategy of Mining Association Rule Based on Cloud Computing[C]//International Conference on Business Computing and Global Informatization.IEEE Computer Society,2011:475-478. [6] 贺瑶,王文庆,薛飞.基于云计算的海量数据挖掘研究[J].计算机技术与发展,2013,23(2):69-72. [7] Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[C]//Conference on Symposium on Opearting Systems Design & Implementation,2004:107-113. [8] 刘峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600. [9] 杜亚军,陈晓亮,范永全,等.微博知识图谱构建方法研究[J].西华大学学报自然科学版,2015(1):27-35. [10] Wang Yuanzhuo,Jia Yantao,Liu Dawei,et al.Open Web knowledge aided information search and data mining[J].Journal of Computer Research and Development,2014,52(2):456-474 (in Chinese). [11] Zhao Jun,Liu kang,Zhou Guangyou,et al.Open information extraction[J].Journal of Chinese Information Processing,2011,25(6):98-110(in Chinese). [12] Guo Jianyi,Li Zhen,Yu Zhengtao,et al.Extraction and relation prediction of domain ontology concept instance,atribute and atribute[J].Journal of Nanjing University:Natural Sciences,2012,48(4):383-389 (in Chinese). RESEARCH ON VIRTUAL IDENTITY PORTRAIT METHOD BASED ON ADVERTISEMENT ALLIANCE Peng Ruxiang Yang Tao Kong Huafeng Wang Yongjian (ThirdResearchInstituteofMinistryofPublicSecurity,Shanghai201204,China) (KeyLabofInformationNetworkSecurity,Shanghai201204,China) At present, the network virtual account is too numerous, most accounts do not need real-name authentication can be used. This is not conducive to the safety of network space maintenance and supervision. Aiming at this situation, this paper presents a network space identity portrait method with virtual account as attribute. The method first uses the big data preprocessing technique to extract the network virtual account from unrelated http post data; then, based on the mechanism of advertising alliance, this paper uses the cookie ID of the page tag technology to store the user unique ID, and the virtual identity is correlated with the binding analysis and then the virtual identity prototype is constructed; finally, the portrait of similar prototype is completed by the similarity calculation. The experimental results show that the method can effectively depict the identity of network space. Advertisement alliance Portraits of virtual identity Data mining Similarity computation 2016-06-27。广州市科技计划项目(2014Y2-00022)。彭如香,助理研究员,主研领域:信息安全,数据挖掘。杨涛,副研究员。孔华锋,研究员。王永剑,副研究员。 TP301.6 A 10.3969/j.issn.1000-386x.2017.06.0183 虚拟身份画像方法实现与分析




4 结 语
