基于相似度算法的英语智能问答系统设计与实现
2017-07-10王文辉吴敏华骆力明
王文辉 吴敏华 骆力明 刘 杰
(首都师范大学信息工程学院 北京 100048)
基于相似度算法的英语智能问答系统设计与实现
王文辉 吴敏华 骆力明 刘 杰
(首都师范大学信息工程学院 北京 100048)
智能问答系统是在搜索引擎的基础上融合了自然语言知识和应用的人工智能产品,相比较传统的依靠关键字匹配的搜索引擎,能够更好地满足用户的查询需求。针对现有的英语智能问答系统中知识呈现的单一化以及系统查询效率低等现状,采用基于距离的相似度算法,设计并实现了基于相似度算法的英语智能问答系统。实验结果表明该系统能够较为准确地回答小学生的英语问题,对远程教育中小学英语智能问答系统的构建起到参考和借鉴的作用。
智能问答系统 搜索引擎 关键字匹配 相似度算法
0 引 言
随着21世纪进入人们的视野,网络通信技术飞速发展,大数据时代逐渐进入人们视野,纷繁复杂的数据信息充斥着互联网,互联网承载的信息量在不断增长。这些庞大的信息逐渐成为了回答用户提问的重要来源。传统的搜索引擎信息检索方式大部分还是按照关键词进行搜索。这种检索方式虽然能方便用户查询信息,但它在一定程度上反馈给用户的是大量相关和无关的搜索结果,用户很难从中快速地找到自己想要的答案。如何从海量的信息源中准确获取到用户最需要的信息,是信息化时代研究者们共同追求的目标。
近年来,问答系统的出现逐渐引起了学者们的关注。智能问答系统是自然语言处理和信息检索领域的一个新的研究热点,它允许用户以自然语言形式的句子提问,并采用自然语言处理技术自动地将简洁、准确的答案返回给用户[1-2],它的出现体现了人们对快速、准确检索信息的探索与追求。与传统搜索引擎相比,智能问答系统不仅符合用户提问的表达形式,而且相对于搜索引擎的关键词匹配方式,在对问句理解的提问意图方面具有明显优势,并且能够直接把用户想要的答案提炼好并以结构化的方式呈现给用户。这种智能化的问答方式在远程教育答疑解惑中发挥着重要的作用。
知识本体库是用户提问的“问题-答案”库,这些问题所对应的答案都存储在数据库中。当用户提出一个问题时,该问答系统通常先对常规问题集FAQ(Frequently Asked Question)进行检索,然后搜寻出最相似的问题答案,返还给用户。如果该系统在FAQ库中找不到用户满意的答案,系统将自动切换到知识本体库中进行检索。其中,相似度算法是智能问答系统中的关键技术,用来实现知识本体库中最相似问句的查找。通过对用户提出的问题与知识本体库中存储的问题答案进行相似度计算,然后选取相似度最高的答案作为用户提出的问题答案,并将对应的答案信息返还给用户。
目前,句子相似度算法在现实中有着广泛的应用,它的研究状况影响着其他相关领域的研究进展,句子相似度算法在问答系统的各个领域都有着非常重要的作用,如在中文FAQ问答系统中[3],在本体问答系统中[4],在OTC问答系统中的使用[5]以及在基于常见问题集的机器问答系统中的使用等[6],句子相似度算法都是问答系统中的关键技术之一。基于此,本文将句子相似度算法应用于小学英语智能问答系统中,设计并实现了英语智能问答系统。句子相似度算法综合考虑了英语问句单词和语义多方面的特征,不仅提高了英语智能问答系统的运行效率,而且准确地回答了小学生的英语问题。该系统还能满足小学生英语智能问答学习的功能需求,更好地帮助小学生实现多样化英语学习。
1 系统的设计
1.1 系统模型
英语智能问答系统是自然领域的一种较高级的信息检索技术,它的目的是希望小学生通过使用该系统能够对日常生活中基本的英语句子进行提问,然后得到一个准确的答案。简单来说,英语智能问答系统就是通过分析学生提出的英语问题并理解问题含义,然后将答案返回给学生。
如图1所示,英语智能问答系统的组成有四个模块:第一个是问题分析模块,该模块的内容主要包括五个部分:单词还原、词性标注、问句类型分析、问句答案类型分析以及关键词提取。第二个模块是相似度计算,相似度计算模块是问答系统的核心内容,这部分主要是词语相似度计算和语句相似度计算。第三个模块是答案抽取,这部分主要是进行相似度排序、筛选答案以及输出答案。最后一个模块是知识推送,这部分内容主要是通过了解不同用户的知识水平等级、相关知识难度以及用户对资源类型的偏好,将答案以多样化的形式呈现给用户。
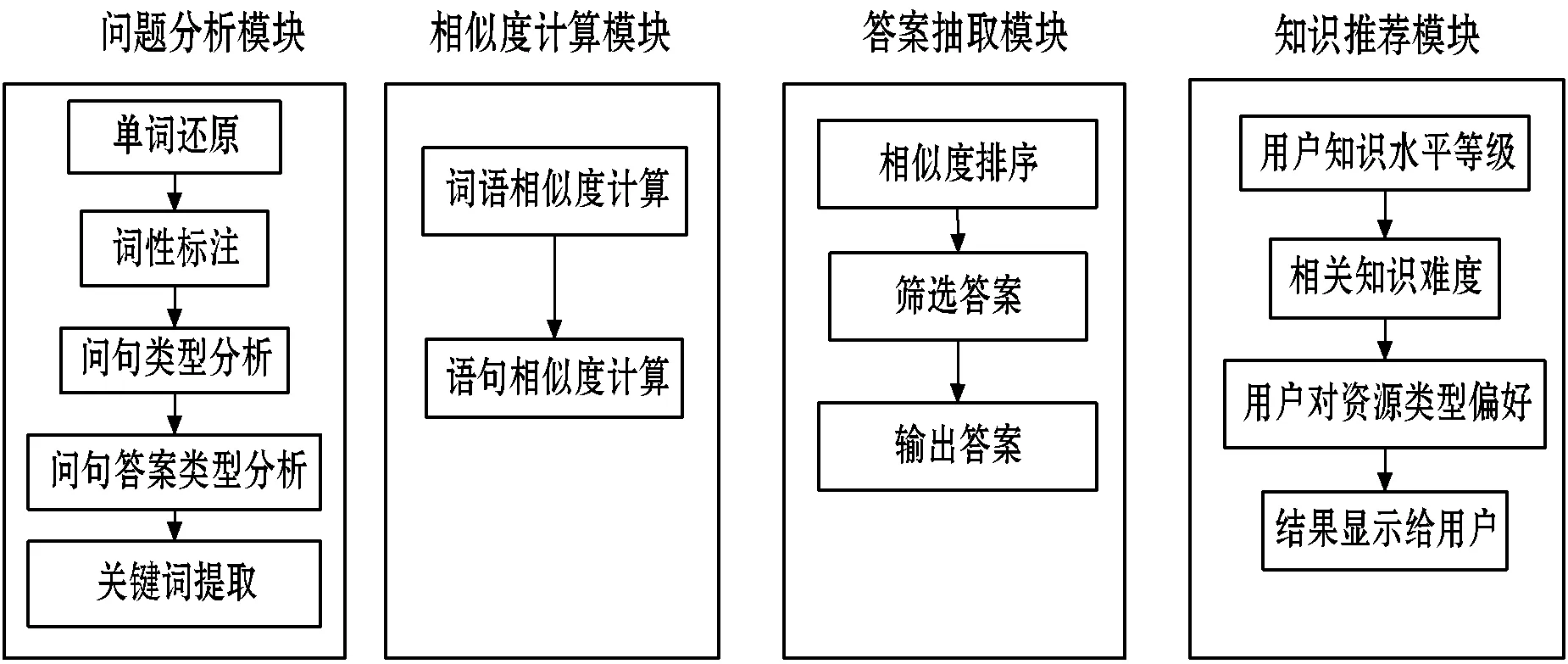
图1 英语智能问答系统模型
1.2 问题分析模块
问题分析模块是智能问答系统中不可缺少的一部分,它的目标是使计算机能够理解用户的查询语义,为后续进行的答案抽取模块工作做准备。准确的问题分析有助于系统在答案抽取模块时针对不同类别的问题使用相应的答案抽取方法和策略。当用户输入一个英语问句时,问题分析模块将对其进行分析和处理,处理程序包括:
(1) 单词还原
把问句与答案句中所有的单词变回原型。例如:助动词had、has变为have,复数单词sports变为sport,be动词变为is、was变为be。
(2) 词性标注
对还原后的每个单词进行词性标注。其中包括词性为动词的单词、词性为名词的单词词性为形容词的单词和词性为副词的单词。
(3) 问句类型分析
对用户提出的一些常用英语问句类型进行分析,如以“What kind of……”、“How do you like……?”、“Which is……?”等为代表的英语问句。
(4) 问句答案类型分析
判断用户提出的问句是属于哪一类型的事物。问句答案类型主要有回答、情境对话等多种。每个类型又包含四种媒体呈现方式:音频、视频、绘本、图片。分为难、中、易三个等级。
此外,用户还可以单独输入一个单词查询所得结果。单词答案类型包括回答、课文原句、情景段落、延伸例句等。对单词以及问句答案类型进行划分与确定,不仅丰富了英语知识呈现的形式,而且在一定程度上提高了小学生学习英语的积极性和学习兴趣。问句和单词答案具体分类如表1所示。
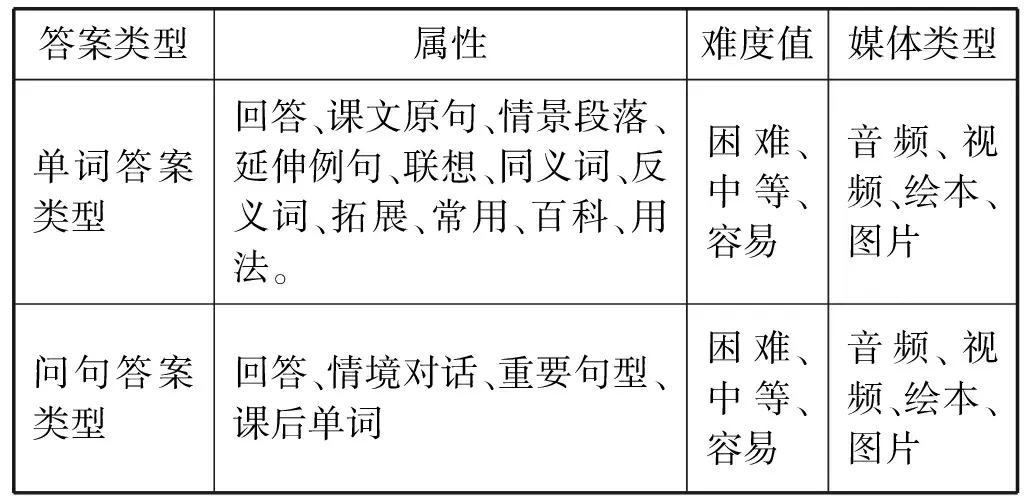
表1 问句和单词答案类型
(5) 关键词提取
英语问句中包含的关键词代表了该句子的主要含义。在检索过程中,关键词按照词性的不同被赋予不同的权重,权重从大到小依次为名词、限定性副词、形容词和动词[7]。
1.3 相似度计算模块
句子相似度计算方法主要通过计算两条语句之间的相似度来选取合适的句子。其中语句的相似度主要包含词形、句法、语义等方面,计算结果得出的相似度值越大,表明两个句子在词形、句法、语义等方面的信息越接近[8]。本研究在计算英语问句相似度时采用的是基于距离的相似度算法,该算法基于 WordNet 概念语义分类词典,计算英语单词间相似度采用概念词相似度计算方法,得到英语单词之间相似度后根据夹角余弦相似度的计算方法得出英语语句间的语义相似度。
1.4 答案抽取模块
答案抽取模块是对信息检索模块得到的备选答案问句进行词法、句法和语义等方面的分析,需要对答案进行排序。另外系统也需要设置一个阈值,只有语句相似度大于设定的阈值,才输出检索的结果,通过强制性关键词表对检索的结果进行过滤,去掉和检索结果无关的内容,然后根据查询问句所属类别提炼答案,以符合用户知识水平的方式返回给用户最合适的问题答案[9]。该模块主要通过问句相似度计算从知识本体库中得到最相似的备选答案,之后进行答案抽取,将相似度值大于0.8的备选答案依照相似度值的大小进行排序,并且根据问题分析模块获取的问题类型,将备选答案推送给知识推送模块。
1.5 知识推送模块
知识推送模块是该系统的重要组成部分,与众不同之处在于它考虑到了用户个人的兴趣爱好,每个用户都有自己独特的学习方式,该模块能够根据用户的浏览信息推送不同的知识。智能问答系统根据用户的先前知识水平、兴趣爱好以及学习方式等特征提供多种多样的答案给用户,不同的用户会得到符合自己知识水平的问题答案。在知识推送模块中,将问题答案呈现内容根据难易程度划分为三个级别,简单、中等、困难。通过不同用户的知识水平背景推荐不同难度等级的问题答案(如表2所示)。
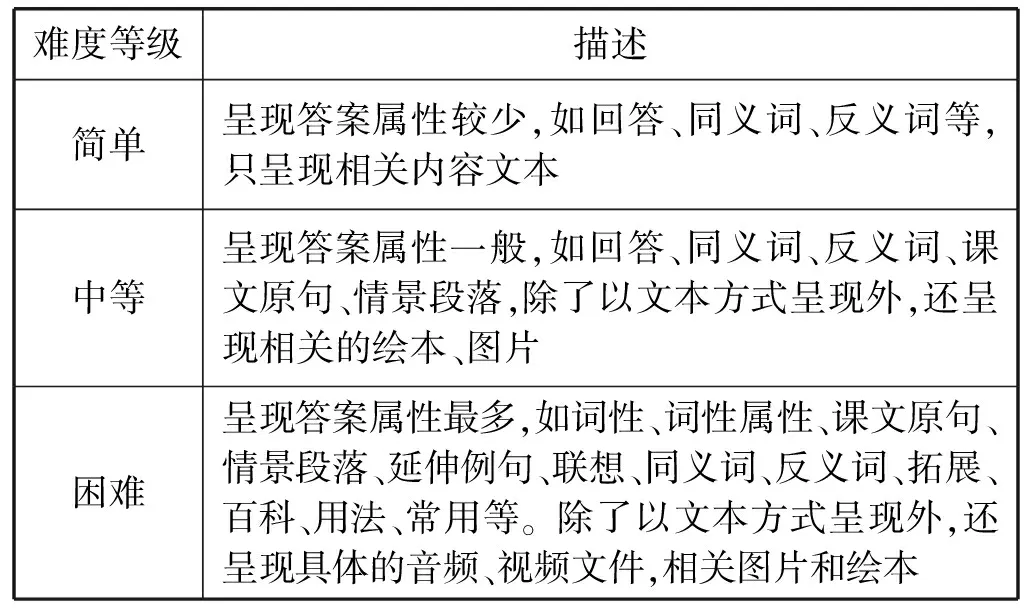
表2 问题答案难度等级
1.6 知识本体库
如图2所示,本系统的知识本体库分为三部分:知识本体、教材组织本体和资源库。知识本体包括单词本体和句子本体,具有不同的属性;每个属性由图片、音频、视频、绘本等资源组成,以满足不同学习者的个性化需求。由于相似度计算模块的算法是在相同的疑问词中查找相似度最高的句子,这就会遗漏不同疑问词中语义相似度高的句子,所以建立一个特例句子本体库,链接此类句子,以提高查找精度。单词教材组织本体和句子教材组织本体都继承教材组织本体,包含教材特征的所有属性。
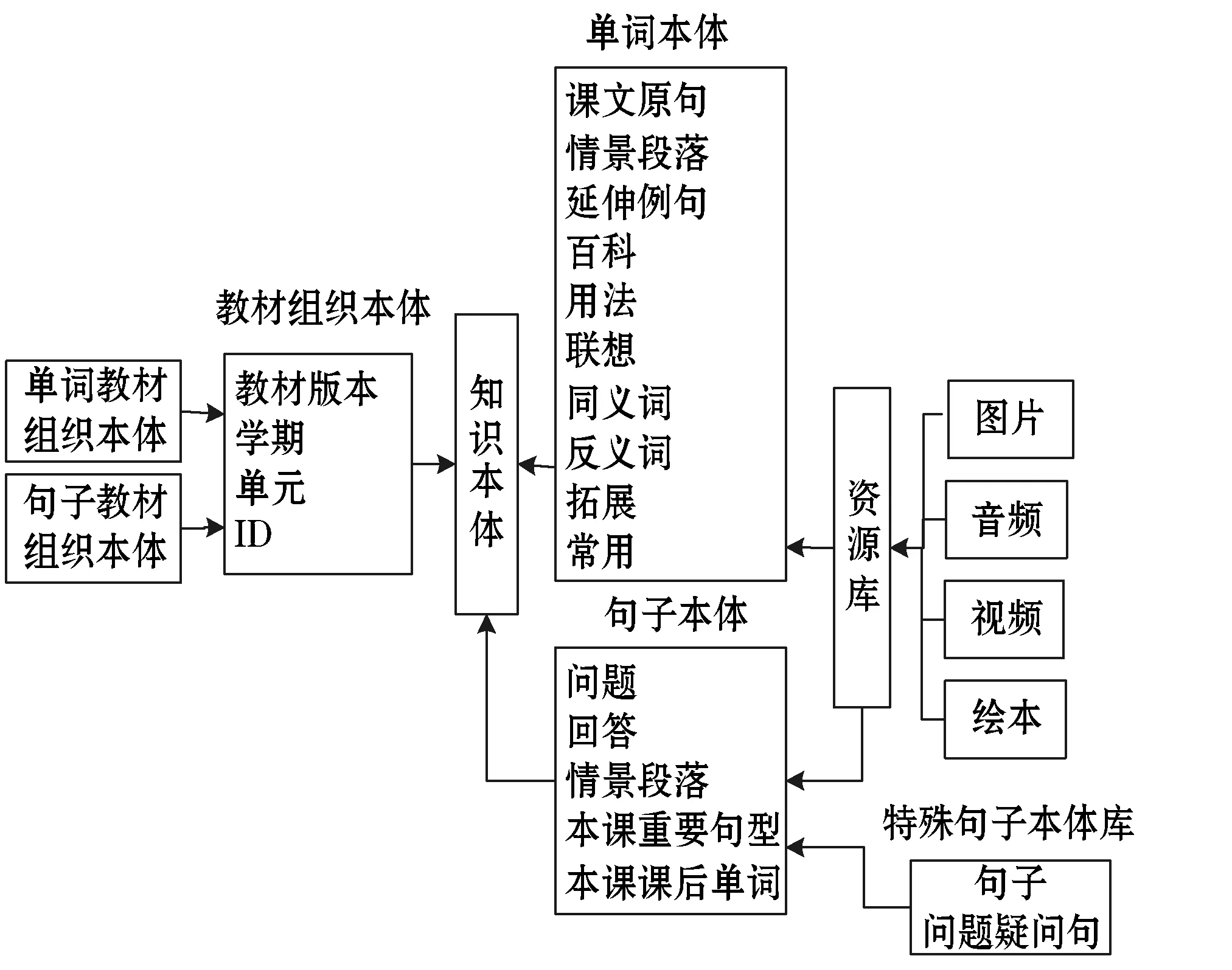
图2 知识本体结构图
2 系统关键技术
2.1 相似度算法
基于距离的相似度计算是目前使用较多的算法之一,它的基本思想是通过获得语义词典树当中两个概念词之间的路径长度来衡量它们的语义距离,语义相似度和语义距离之间呈现负相关的关系。如果两个词语之间的语义距离越大,那么相似度就越低;反之,如果两个词语之间的语义距离越小,那么相似度就越高[10]。
2.1.1 语间概念词相似度
本文参考了Li[11]提出的概念相似度算法的思想,该算法非常经典且具有代表性,并引用改进的概念词相似度计算方法[12],算法定义如下:
(1)
其中,L表示两个概念词W1与W2之间的最短路径长度,Hc表示W1和W2公共上位词集的深度,Hw1表示概念词W1的深度,Hw2表示概念词W2的深度。α为常数(根据Li的实验取值为0.2)。
式(1)需要满足如下几个约束条件:
(1) 如果两个概念词之间的最短路径越短,那么它们的语义相似度就越大;
(2) 如果两个概念词的公共上位词的深度越大,那么它们的语义相似度就越大;
(3) 如果两个概念词分别到公共上位词的距离越短,那么它们的语义相似度就越大;
(4) 两个概念词之间的语义相似度值位于区间[0,1]之内。
2.1.2 语句间语义相似度
本文在衡量语句间相似度时,使用向量空间模型来表示英文语句,向量空间模型是一种较好的文本表示方法之一。向量空间模型VSM(vector space model)的基本思想是把文本中的单词、短语等包含语义的最小单位分割开,然后将其对应的相似度值作为向量中的元素[13-14]。这种向量空间模型的表述方式能够准确而客观的表达英语文本的语义信息。在对两条英语问句和答案句进行向量化表示以后,使用向量相似度测量方法——夹角余弦来获得英语语句间的语义相似度。
1) 语句的向量化表示
在对英文语句进行向量化表示时,需要把两条英文语句表示成等长度的向量。例如两条英文语句T1和T2,将两条语句中的所有单词汇集在一起,构成一个联合词集T:
T=T1∪T2={w1,q1,…,wm,qn}
(2)
联合词集T包含了英文语句T1和T2中所有的单词,将T1和T2中相同的单词都去掉,保证联合词集T中所有元素的互异性。其中集合{w1,w2,…,wm}表示英文语句T1中的所有单词集合,集合{q1,q2,…,qn}表示英文语句T2中的所有单词集合。下面以两条英文例句来具体说明:
T1:{What is your favorite sports?}
T2:{What kind of sports do you enjoy most?}
T1和T2组成联合词集T:{ What be your favorite sport kind of do you enjoy most ?}
其中,联合词集T是由两条英文语句中的单词原形并去掉冠词、感叹词等不具有真正语义信息的单词组成的,并且两个语句中相同的单词只记录一次。将联合词集T用一个向量来表示,称这个向量为联合语义向量,记作S。同时将两条英文语句T1和T2分别都使用联合语义向量S1和S2表示。联合语义向量的长度与联合词集中单词的个数相等。向量中每个单词分量的值根据以下方法确定:
(1) 当Wi包含在语句中,Si取值为1;
(2) 当Wi不包含在语句中,那么使用式(1)计算单词间相似度。
由上述方法得到英文语句T1和T2分别对应的联合语义向量S1和S2:
S1:{1,1,1,1,1,0.8,0,0,1,0.8,0.9};
S2:{1,0,1,0.8,1,1,1,1,1,1,1 }。
其中,S1中的各个数值依次为What与What、 be与be、 your与your、favorite与favorite、 sport与sport 、kind与favorite、you与your、 enjoy与favorite、most与favorite之间的综合相似度(其中of是介词无比较单词,do与是助动词无比较单词);S2中的各个数值依次为What与What、 your与you、favorite与enjoy、 sport与sport 、kind与kind、you与you、 enjoy与enjoy、 most与most之间的综合相似度(其中of是介词无比较单词,do与是助动词无比较单词,be是系动词无比较单词)。
2) 语句间的相似度计算
确定了两条英文语句T1与T2的联合语义向量S1和S2之后,根据式(3)计算得到T1与T2语句间的相似度。最后,将语句间相似度大于预设阈值的备选答案作为最终答案。
(3)
2.2 相似度算法流程
该算法输入为用户提问的一条英语问句,输出结果为与该问句相似的所有备选答案以及相似度值,相似度取值的区间为[0,1]。以下为本算法在执行英语问句时的具体处理流程(如图3所示)。
Step1 用户输入一个英语问句,进行问句预处理操作,然后在知识本体库中检索得到备选答案;
Step2 将问句和备选答案句中的单词进行还原处理;
Step3 对还原后的每个单词进行词性标注;
Step4 将处理后的问句和答案句中的不同单词组成联合词集;
Step5 将联合词集向量化表示,构成联合语义向量集;
Step6 根据式(1)计算得出的概念词相似度给联合语义向量集中的每一个分量赋值;
Step7 根据式(3)计算问句和答案句分别对应的联合语义向量的余弦相似度得出语义相似度;
Step8 将计算出的step7中的语义相似度结果进行排序,最终选取相似度最高的句子作为问题答案。
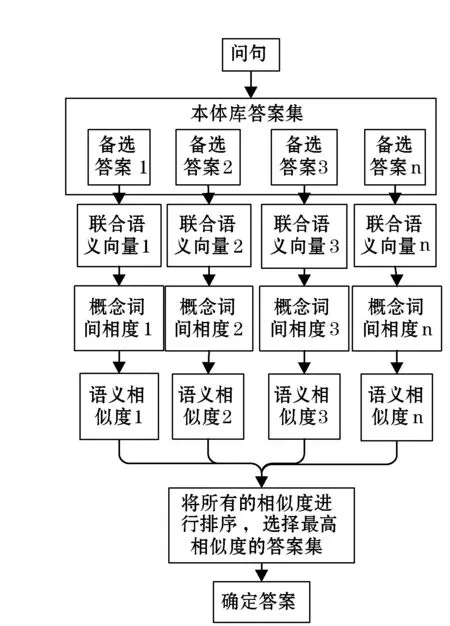
图3 算法执行流程图
3 系统的实现
该系统以MYSQL数据库和知识本体库作为后台数据库管理系统。使用到的数据表有问题表、问题答案表、答案表、学习偏好表、常用词词典以及WordNet作为语义词典。在Eclipse平台下采用(Spring MVC+ Maven+Mybatis)等架构。系统实现的具体流程如图4所示。

图4 智能问答系统执行流程图
如图4所示,用户输入问句进行提问,之后系统首先查询FAQ问题集,如果查找到了问题答案,便进行筛选,将最合适的答案返回给用户。如果在FAQ库中没有找到问题答案,便查询知识本体库。这一阶段需要经过一系列句法处理,如单词还原、词性标注等过程形成关键词集,然后将处理好的英文语句进行相似度计算,最后返回相似度最高的问题答案给用户,根据用户知识水平呈现多样化答案内容。问句答案可以在知识本体库中查询到对应的ID值,获取到与该ID值相关的若干属性值。用户本体库存储着每个学生的知识水平等级、学习风格等信息,最后通过知识推送模块推荐给学习者合适的学习内容。
3.1 数据测试结果
如表3所示,实验结果采用正确率和综合相似度进行评估,本实验总共输入432条句子、910个单词,正确率分别为82.17%和91.09%,综合相似度值均大于0.8。从测试结果可以看出该算法能够提高实验结果的正确率,并且句子综合相似度较高,提高了系统效率。

表3 系统数据测试结果
3.2 单词查询结果
当用户在搜索框输入一个英语单词时,系统会呈现与该单词相关的多种类型的答案,例如对应单词的课文原句、情景段落、延伸例句等。在查询单词的过程中,系统首先查询FAQ库,如果查到答案便直接呈现给用户;如果FAQ库没有答案,便查询知识本体库将答案呈现给用户。
例如,以输入单词“river”为例进行查询。如图5所示,用户输入单词“river”,系统呈现与该单词相关的结果。其中包含:课文原句“I see some ships and boats on the river”;情境段落“That’s the Thames.It’s a long and wide river”;延伸例句“Jimmy can swim across the river”;百科“中国的第一大河-长江长约6 300公里。”;用法“单词、句型”;联想“wide(宽的)/water(水)/long(长的)”;同义词“water”;反义词“desert”;拓展“river bed(河床)/river side(河岸)”;常用“cross the river(渡河)/mouth of the river(河口)”。

图5 单词查询结果
3.3 问句查询结果
当用户在搜索框输入一个问句时,系统会呈现与该问句相关的多种类型的答案,例如回答、情境对话、重要句型、课后单词等。在查询问句的过程中,系统首先查询FAQ库,如果查到答案便直接呈现给用户;如果FAQ库没有答案,便查询知识本体库将答案呈现给用户,在查询本体库的同时,对查到的相关语句答案进行相似度计算,选取相似度最大的问题答案作为最终答案返回给用户。
例如,以输入问句“Excuse me, What is her name?”进行查询。如图6所示,对用户所提问句预处理之后,在知识本体库一共查询到26条与问句相关的答案。ID是每条备选答案的唯一标识,与问句“Excuse me, What is her name?”最相似的句子ID为1/10/7/3的语句“What is your name”,相似度值为0.52。

图6 相似度算法查询问句结果
图7为问句查询结果,其中包含:问题“What’s your name?”,回答“His name is Mocky”。情景对话“A:Is this yours? B:Yes,it’s mine.A:Are there any gift in your bag? B:Well,open it and see.C:Dad,this bag isn’t yours.There are woman’s clothes.D:Maybe it’s hers.A:This bag isn’t his.Is it yours? E:Yes,it’s mine.What’s your name? B: His name is Mocky.”;本课重要句型:无;本课课后单词:“1. hers 她的(所有物)2.his 他的(所有物)3.yours 你(们)的(所有物)”。
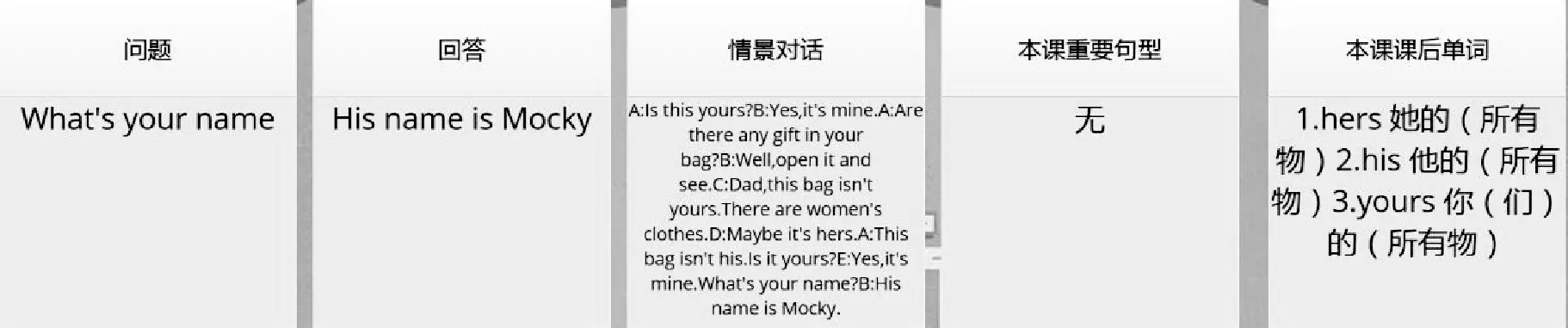
图7 问句查询结果
3.4 系统运行效果分析
本系统收集与整理了众多小学生在使用问答系统过程中常见问题和普遍性问题2 000多个,问题答案使用批量导入方式,通过教材收集问题答案然后存入知识本体库中。系统运行三个月以来,接受各学校小学生使用累计3 058次,并对此进行了统计分析如表4所示,其中λ(0≤λ≤1)为系统设定的相似度阈值,在这里λ分别取0.7/0/8/0.9三个数值来衡量句子相似度。
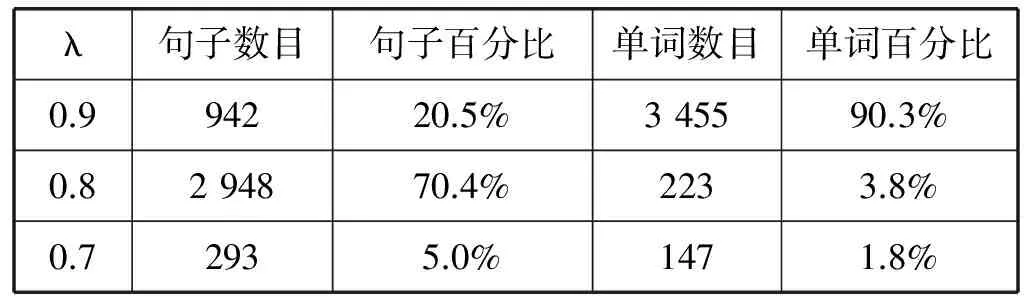
表4 句子相似度结果所占比例
由表4可以看出:(1)对于λ取不同的值时,出现相似问句的数量并不相同,其中当λ=0.8时相似句子出现数量最高,占总体比例的70.4%,说明本系统在采用基于距离的相似度算法有较高的准确性。(2)当λ=0.9时相似单词出现数量最高,达到了90%以上。由此可见,无论是在查询单词还是句子方面,系统已经较好地满足了实际应用的需求。
4 结 语
小学英语问答系统能否实现智能化,最直接的体现就是能否准确地回答用户提出的问题。本文通过研究英语句子相似度算法,介绍了英语智能问答系统的模型以及模型每个模块的功能和作用,并给出了具体的系统设计和开发过程,并在此基础上编码实现了基于相似度算法的小学英语智能问答系统。经过实际体验与使用,该系统不仅可以智能、准确地回答用户提出的问题,还可以提供一些与用户所提问题相关的知识答案,而且该系统查找速度快,基于距离的相似度算法提高了英语智能问答系统的查准效率。后续研究将对相似度算法进行改进,以便更加准确、快速地查询用户所需要的内容,进一步提高系统的效率。同时在系统实际使用的过程中,将继续搜集用户点击页面资源次数、浏览时间等内容获取用户的偏好信息,自适应推荐给用户学习资源,实现个性化学习。
[1] 张江涛, 杜永萍. 基于语义链的检索在 QA 系统中的应用[J]. 计算机科学, 2013, 40(2): 257-260.
[2] 钱强, 庞林斌, 高尚. 一种基于词共现图的受限领域自动问答系统[J]. 计算机应用研究, 2013, 30(3): 841-843.
[3] 叶正, 林鸿飞, 杨志豪. 基于问句相似度的中文 FAQ 问答系统[J]. 计算机工程与应用, 2007, 43(9): 161-163.
[4] 刘汉兴, 刘财兴, 林旭东. 基于问句相似度的本体问答系统[J]. 广西师范大学学报自然科学版, 2010, 28(1):88-91.
[5] 樊康新. 基于常见问题集的 OTC 问答系统的设计与实现[J]. 计算机系统应用, 2008 (12): 30-34.
[6] 刘晓义, 王培东, 周洪玉. 基于知识处理重型切削数据库的设计与实现[J]. 哈尔滨理工大学学报, 2004,9(1):11-13.
[7] 马莉. 基于动态本体知识库的问答系统的研究与实现[D]. 广西师范大学, 2009.
[8] 周法国, 杨炳儒. 句子相似度计算新方法及在问答系统中的应用[J]. 计算机工程与应用, 2008, 44(1): 165-167.
[9] 刘里, 曾庆田. 自动问答系统研究综述[J]. 山东科技大学学报(自然科学版), 2007, 26(4): 73-76.
[10] 王赫宁. 基于 WordNet 的英文语句相似度算法的研究[D]. 东北师范大学, 2014.
[11] Li Y, McLean D, Bandar Z A, et al. Sentence similarity based on semantic nets and corpus statistics[J]. Knowledge and Data Engineering, IEEE Transactions on, 2006, 18(8): 1138-1150.
[12] 王赫宁. 基于 WordNet 的英文语句相似度算法的研究[D]. 东北师范大学, 2014.
[13] Lee D L, Chuang H, Seamons K. Document ranking and the vector-space model[J]. Software, IEEE, 1997, 14(2): 67-75.
[14] 张剑, 李春平. 基于 WordNet 概念向量空间模型的文本分类[J]. 计算机工程与应用, 2006, 42(4): 174-178.
DESIGN AND IMPLEMENTATION OF ENGLISH INTELLIGENT QUESTION-ANSWERING SYSTEM BASED ON SIMILIARITY ALGORITHM
Wang Wenhui Wu Minhua Luo Liming Liu Jie
(CollegeofInformationEngineering,CapitalNormalUniversity,Beijing100048,China)
Compared with the traditional search engine which is rely on the keyword matching, intelligent question-answering system integrates with the knowledge and application of natural language on the basis of the search engine, so as to satisfy users’ information retrieval requirement. Aiming at current simplified knowledge and inefficient system query of English intelligent question answering system, the research adopts the similarity algorithm based on distance , designing and implementing English intelligent question answering system based on similarity algorithm. The results show that the system can answer students’ questions accurately. The conclusion of this research can be used as references to the construction of English intelligent question answering system in distance education.
Intelligent question-answering system Search engine Keyword matching Similarity algorithm
2016-08-09。国家社会科学基金重大委托项目(14&ZH0036);北京市教育科学十二五规划重点课题(AJA12132)。王文辉,硕士生,主研领域:自然语言处理和语义网。吴敏华,教授。骆力明,教授。刘杰,副教授。
TP311
A
10.3969/j.issn.1000-386x.2017.06.013
