基于MFCC与CHMM的方向指令语音识别
2017-07-06林江莉
陈 科, 林江莉
(四川大学 材料科学与工程学院, 四川 成都 610065)
基于MFCC与CHMM的方向指令语音识别
陈 科, 林江莉
(四川大学 材料科学与工程学院, 四川 成都 610065)
随着科学技术尤其是计算机技术的不断发展,语音识别被广泛应用到各个领域.针对方向指令的语音,使用梅尔倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC)作为特征参数,连续马尔科夫模型(Continuous Hidden Markov Model,CHMM)作为识别模型,对语音信号进行识别处理.实验结果显示,此方法在方向指令语音识别中取得了良好的结果,有较高的识别准确率.
语音识别;连续马尔可夫模型;方向指令;梅尔频率倒谱系数
0 引 言
通常意义上,语音识别指的是将语音信号转换成文字的一个过程[1].计算机应用中,语音识别技术是指利用各种数字信号处理、模式识别以及数理统计学等技术,将人类的语音转变为可以被机器识别的数字信号,从而达到让人类利用语言来控制机器的目的.据分析,基于对语音识别技术强大的需求及其巨大的应用前景,该技术将是未来十年信息技术领域十大重要的科技发展技术之一[2].语音识别通常包含预处理、特征参数提取、声学建模及模式匹配等环节.图1展示了语音识别系统的基本构成.
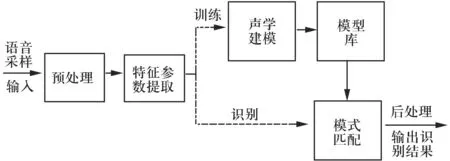
图1 语音识别系统基本构成
目前,在语音识别技术中,使用的特征参数主要有线性预测编码(Linear Predictive Coding,LPC)系数、线性预测编码倒谱(Linear Predictive Cepstral Coding,LPCC)系数及梅尔频率倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC).其中,LPC和LPCC着重发音模型,MFCC着重于人耳的听觉特征.近年来,MFCC的应用比较广泛,其识别率和鲁棒性都较前2种系数好[3].据此,本研究的方向指令语音识别系统也选用MFCC作为特征参数.此外,模型训练和识别技术主要有动态时间规整(DTW)技术、隐式马尔可夫模型(Hidden Markov Model,HMM)技术及人工神经网络(Artificial Neural Network,ANN)技术.DTW技术出现的时间较早,识别率和鲁棒性都不如HMM技术和ANN技术.ANN技术是近年来语音识别研究的热点,有较好的学习特性、鲁棒性和自适应性,但其学习训练时间偏长,短时内无法与语音信号进行最佳匹配.HMM技术是目前语音识别技术中使用最普遍的技术,其识别精度高,并且能应用于大词汇量的语音识别[4].由于本研究的语音识别方法属于小词汇量非特定人的孤立词语音识别,故本研究选取MFCC特征并使用HMM作为声学建模和模式匹配的算法来实现不同的方向语音指令的识别.
1 预处理
1.1 预滤波
预滤波,其目的在于滤除语音信号中夹杂的工频信号以及高于1/2采样频率的信号成分或噪音[3].滤除工频信号,是为了排除50 Hz的电源干扰;滤除高频部分信号,是为了将后面分析的信号控制在一定范围内,避免造成信号中的高频成分失真.
1.2 预加重
由于人类发音时受口鼻辐射的影响,在800 Hz以上频段的信号会有6 dB/oct(倍频程)的衰减[5],所以随着频率增高,语音信号的高频部分会越来越小.预加重的目的就在于将语音信号的高频部分加重,以便于其后的频谱分析.
1.3 加窗分帧
语音信号是随时间不断变换的,是一种典型的非平稳信号,但是将信号划分到非常小的时间段内,即10~20 ms,语音信号的变化就会很缓慢,可看成短时平稳,此时语音信号的物理特征参量和频谱特性可看作是不变的.基于这样的特征,将预滤波与预加重后的信号进行分帧,每1帧代表10~20 ms时间段的语音信号,1帧的信号就可看成恒定的信号,以便于进行频谱分析等操作.
1.4 端点检测
语音样本的起始点并不一定是有效语音段的真正起始点,在其始末端都有一段无用的语音段,所以需要进行端点检测,提取出有效的语音段.端点检测是语音识别中一个重要的基本操作,它可以减少系统的运算时间.
2 MFCC提取
MFCC与LPC思路有本质的不同,相比较于LPC着重发音模型,MFCC着重的是基于人耳的听觉特征[6].由于耳蜗独特的构造,人类听到的声音频率的高低程度和声音实际的频率大小不是成正比的.因此,以Mel频率为单位来描述人类听到的频率,这样人类听到的声音频率的高低程度就和Mel频率成正比了.
要将声音的线性频率频谱转变到以Mel频率为单位的非线性频谱上来,需要先设置1个滤波器组,其由若干个三角滤波器组成,相邻三角滤波器的中心位置的差距随频率的增大而逐渐变得稀疏.具体的转换关系为,
Fmel=2 595lg((1+fHz)/700)
(1)
其中,Fmel代表Mel频率,fHz代表线性频率.
实际应用时,MFCC的计算过程如下:
1)首先对端点检测后得到的语音帧进行前述的预加重和加权明窗的操作,再对每1帧信号做快速傅里叶变换,将其转变为频域信号.
2)求出频域信号的能量谱,即计算其频谱的平方,然后用包含L个滤波器的Mel滤波器组对其滤波,得到每个Mel频带内的能量的分量,并将1个滤波器得到的能量叠加,得到L个参数Pm(m=0,1,…,L-1).
3)对每个Pm取对数,得到对应的对数功率谱Lm(m=0,1,…,L-1),然后进行离散余弦变换,将信号又变换到倒谱域,得到Dm(m=0,1,…,L-1).
4)去掉表示直流的分量D0,取D1,D2,….
5)标准的MFCC系数只反映了语音信号的静态特征,要反映动态特征,还要加上差分倒谱参数.
3 声学建模与模式匹配
模式是根据所选取的模型对语音信号的建模,是在模型的基础上经过训练得到的某语音信号的标准样式.模式识别以距离测度为准则,对于传统的语音识别系统来说,就是按一定测度算法实现特征参数与模式库中的模板进行最优模式匹配的过程[7].
3.1 HMM基本原理
HMM是一种用于描述随机过程的信号统计理论模型,由马尔可夫链理论演变而来.该理论有以下的一些假设:
1)存在一离散的时间序列t=0,t=1,…;在每个时刻t,系统只能处于惟一状态qt;下一时刻的状态是随机的;当前状态qt只与其前面相邻的qt-1有关,和其他状态无关.
2)系统从时刻0到时刻T会经过一系列的状态,这就构成了1个状态序列{q0,q1,…,qT},这个状态序列就是1个马尔可夫链.这个过程中得到的状态序列是可观测的,观测值为每一时刻系统所处的状态qt.
隐式马尔可夫模型HMM包含2个随机序列:一个是状态转移序列,其是无法被观测的;另一个是状态转移后输出符号形成的观测序列,其可用前述的特征矢量参数表示.
3.2 HMM的分类
根据HMM参数中的输出观测值概率表示方法的不同,可将HMM分为以下几类:离散型隐式马尔可夫模型(Discrete Hidden Markov Model,DHMM)、连续型隐式马尔可夫模型(Continuous Hidden Markov Model,CHMM)及半连续型隐式马尔可夫模型(Semi-Continuous Hidden Markov Model,SCHMM).
相比DHMM,CHMM系统识别率更高,这是由于在CHMM中的输入向量(即为观测值向量),不需要经过矢量量化转变.输入向量就是每1帧语音信号的特征矢量[8].
4 方向指令语音识别系统的实现
本研究将CHMM应用到方向指令语音识别系统中.方向指令语音识别系统要求能识别非特定人的“前"、“后"、“左"、“右"、“停"5个语音,采集到的语音样本分别为来自20个男性(年龄阶段20~40岁)和20个女性(年龄阶段20~40岁)的“前"、“后"、“左"、“右"、“停"总共200个语音.
方向指令语音识别系统实现的具体步骤如下:
1)提取每一个语音样本的MFCC作为特征参数,并将其作为CHMM模型的观测序列.
2)对“前"、“后"、“左"、“右"、“停"语音利用Baum-Welch算法分别进行模式训练,得到每个语音的CHMM模型最优解λ*=argmax{P(O|λ)}.
3)将测试语音样本对建立好的模型库中的每个模型进行匹配,匹配度最高的模型便是最终的识别结果.
4.1 预处理与特征提取
本研究采集到的语音样本的属性为,8 000 Hz采样率,单声道,16 bit采样精度.图2显示了1个语音“前"的信号波形图,图3是它的频谱图.

图2 “前"原始语音样本幅度谱

图3 “前"原始语音样本频谱图
样本的预处理先通过1个带通滤波器,下截止频率设置为100 Hz.由于采样率为8 000 Hz,上截止频率设置为4 000 Hz.滤波后进行预加重处理,然后将每个样本的语音信号分帧,帧长为256,也就是每帧256个点,帧移为0.3倍帧长.计算每帧的短时能量,接着用双门限法进行端点检测,截出有用的语音信号进行MFCC特征参数的提取.图4为经过端点检测“后"的语音波形图.
MFCC特征向量的维度有24维,包括12维静态MFCC参数和12维一阶差分参数.将所有语音样本的MFCC特征向量提取出来后,进行CHMM模型训练.
4.2 CHMM的训练
使用CHMM模型的语音识别, 语音信号一般设为3~6个状态,本研究采用4个状态及3个高斯概率密度函数的模型.模型的训练步骤大致如下:
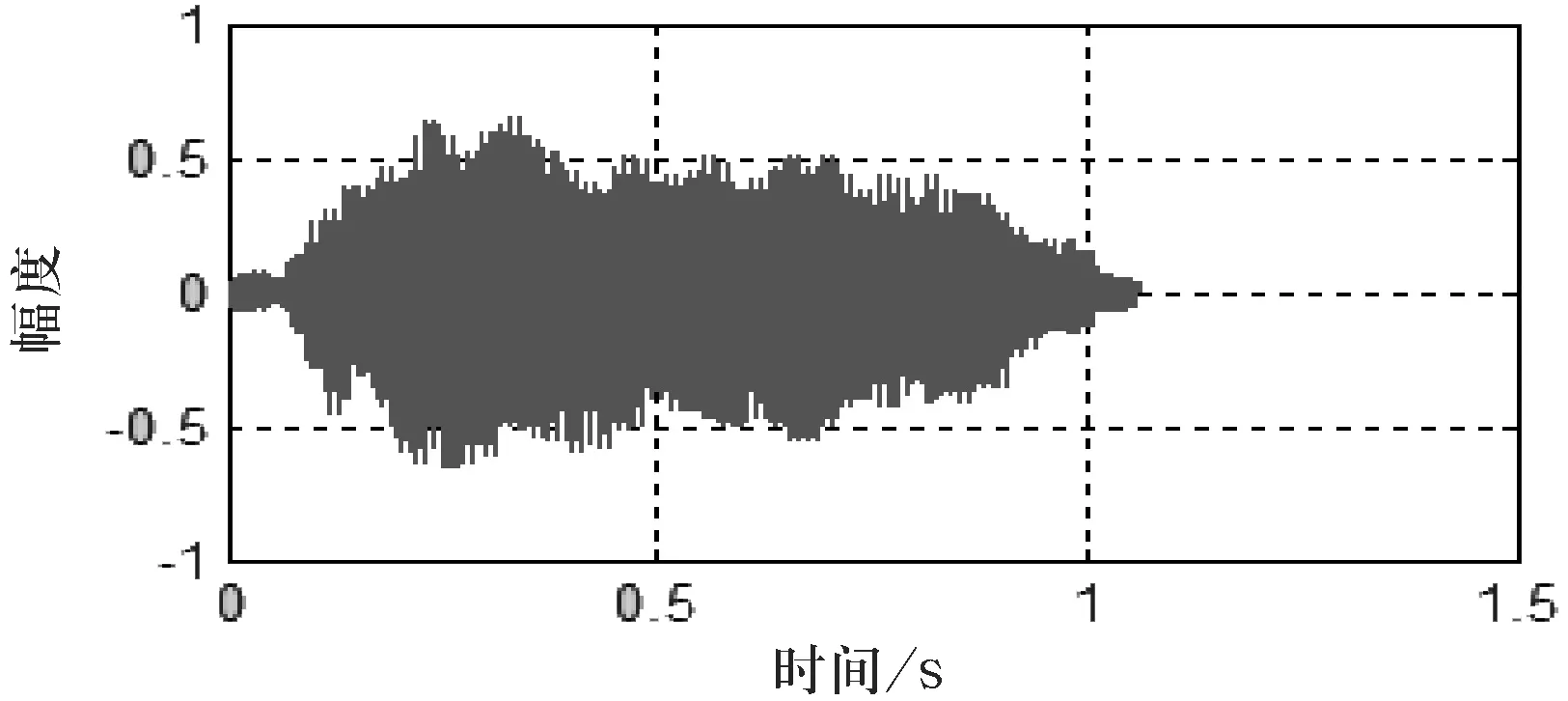
图4 端点检测后提取出的有效语音段
1)对模型参数λ=(A,B,π)进行初始化;
2)根据初始化参数进行一遍Baum-Welch训练,得到新的模型参数λ=(A',B',π');
3)根据新的模型参数λ=(A',B',π'),计算模型产生训练样本的概率P(Ok|λ'),并和上次训练的结果对比,判断是否收敛,若不满足条件,则重复步骤2),否则训练过程完毕.
4.3 CHMM的识别
对测试语音样本的识别过程就是一个模板匹配的过程.先读取模型库,利用对数Viterbi算法,依次计算每个模型产生测试样本的输出概率,选择输出概率最大的模型作为最终结果输出.
4.4 测试结果及分析
全部模型训练完成后,开始测试过程.测试过程分为2部分:第1部分对参与训练的人重新采集的40个语音进行测试;第2部分选用另外不在训练集中的5人25个语音样本.利用这些样本对方向指令的语音识别系统进行测试,并观察最终输出结果.实验结果如表1所示.

表1 测试结果
从表1可知,训练集中的人的再采集样本作为测试样本时识别率达到100%;对不在训练集中的人,只有1个语音识别错误,识别率为96%.测试结果说明,本语音识别系统识别稳定,有较高的识别精度.
5 结 语
本研究实现了针对孤立字的方向指令的语音识别,其中特征参数向量为24维的MFCC,包括12维MFCC和12维MFCC一阶差分,且选用了CHMM技术进行声学建模和模式匹配,得到了满意的识别率,达到了预期效果.但由于实验中录制的样本数较少,因此并不能完全保证系统识别的稳定性.下一步的研究需要进一步扩充训练样本数,并且保证训练样本声音比较多样,既包含不同性别、不同年龄阶段的声音样本,也要考虑低沉的声音及高亢的声音,以此来完善本方向指令语音识别系统的稳定性.
[1]张卫清,周淑阁.语音识别算法的研究[D].南京:南京理工大学,2004.
[2]Scharenborg O.Reachingoverthegap:Areviewofeffortstolinkhumanandautomaticspeechrecognitionresearch[J].Speech Comm,2007,49(5):336-347.
[3]张延盛.孤立词语音识别算法研究及DSP实现[D].南京:南京信息工程大学,2011.
[4]李秀珍.语音识别算法及应用技术研究[D].重庆:重庆大学,2010.
[5]赵力.语音信号处理[M].北京:机械工业出版社,2003.
[6]Vergin R,O'shaughnessy D,Farhat A.Generalizedmelfrequencycepstralcoefficientsforlarge-vocabularyspeaker-independentcontinuous-speechrecognition[J].IEEE Trans Speech Audio Proc,1999,7(5):525-532.
[7]王稚慧.基于HMM建模的语音识别算法的研究[D].西安:西安建筑科技大学,2005.
[8]刘伶俐,王朝立,于震.CHMM语音识别初值选择方法的研究[J].上海理工大学学报,2012,34(4):323-326.
Speech Recognition of Direction-command Based on MFCC and CHMM
CHENKe,LINJiangli
(School of Materials Science and Engineering, Sichuan University, Chengdu 610065, China)
With the development of science and technology,especially the development computer technology,speech recognition is widely used in various fields.In this paper,targeting at direction-command speech,the MFCC(Mel-Frequency Cepstrum Coefficient) and CHMM(Continuous Hidden Markov Model) are selected as characteristic parameter and recognition model respectively for speech recognition of direction-command.Experimental results show that the characteristic parameter of MFCC and the modeling of CHMM are very effective to direction-command speech recognition with a high accuracy rate.
speech recognition;MFCC;direction-command;CHMM
1004-5422(2017)02-0157-04
2017-05-11.
国家自然科学基金(81301286)、 教育部博士点基金(20130181120001)、 四川省科技厅科技支撑计划(2014GZ0005-7)资助项目.
陈 科(1982 — ), 男, 博士, 讲师, 从事计算机图像处理相关技术研究.
TN912.34
A
