基于深度迁移学习的人脸识别方法研究
2017-07-06余化鹏
余化鹏, 张 朋, 朱 进
(成都大学 信息科学与工程学院, 四川 成都 610106)
基于深度迁移学习的人脸识别方法研究
余化鹏, 张 朋, 朱 进
(成都大学 信息科学与工程学院, 四川 成都 610106)
针对大数据集上学习的深度人脸模型在实践中的相关问题,提出一种通过迁移一个预训练的深度人脸模型到特定的任务来解决该问题的方案:将深度人脸模型学习的分层表示作为源模型,然后在一个小训练集上学习高层表示以得到一个特定于任务的目标模型;在公共的小数据集及采集的真实人脸数据集上的实验表明,所采用的迁移学习方法有效且高效;经验性地探索了一个重要的开放问题——深度模型不同层特征的特点及其可迁移能力,认为越底层的特征越局部、越通用,而越高层的特征则越全局、越特定,具有更好的类内不变性和类间区分性;无监督的特征可视化与有监督的人脸识别实验结果都能较好地支持上述观点.
深度学习;人脸识别;迁移学习;不变性;区分性
0 引 言
目前,深度人脸模型[1-3],特别是在大的非限制场景人脸数据集(Labeled Faces in the Wild,LFW)上学习的卷积神经网络(Convolutional Neural Network,CNN)在性能上已经达到前所未有的水平.但实践中,一方面,训练一个深度人脸模型需要大的数据集和强大的计算资源,这阻碍了深度人脸模型的广泛应用;另一方面,对于一个特定的人脸识别任务,往往只有非常有限的训练样本,从而无法训练一个有效的深度人脸模型.所以,将一个预训练的深度人脸模型迁移到一个特定的任务是非常有价值的.对此,本研究通过2个步骤来解决该问题:首先,将深度人脸模型学习的分层表示作为源模型;其次,在一个小的训练集上学习高层表示以得到一个特定于任务的目标模型.同时,本研究在公共的小数据集和从实际应用中采集的真实人脸数据上评估了所提出的人脸识别方法,并与一个轻量级的深度学习基线模型进行了对比.结果表明,本研究的深度迁移学习方法优势十分明显.同时,本研究也经验性地探索了一个重要的开放问题——深度模型不同层特征的特点及其可迁移能力.
1 相关工作
通常,深度人脸模型采用一个在大的人脸数据集上训练的神经网络模型来解决传统的人脸识别问题.由于能够从人脸数据中自动发现复杂的结构且自动学习一个分层的表示[4],深度人脸模型已经在困难的非限制场景人脸数据集上取得了极大的进展.例如,Parkhi等[5]在一个大的数据集(260万幅人脸图像,超过2 600人)上训练了一个CNN模型,其在LFW和YTF[6]数据集上的性能与最好的性能接近,也公开了这个好的训练模型——VGG-FACE(支持Caffe,Torch,与MatConvNet).本研究拟采用此模型作为预训练的源模型.另外,一个有趣的深度人脸模型是PCANET[7],这个模型采用2个主成分分析(Principal Component Analysis,PCA)层形成一个深度模型,已在许多典型的人脸数据集上取得了非常好的性能.尽管其性能仍不能与CNN在LFW等困难数据集上的性能相比,但是作为一个轻量级的深度人脸模型基线,PCANET容易在小数据集上训练.
迁移学习(或归纳迁移)的目的是将以前学习的知识迁移到新的任务,近年来受到越来越多研究者的关注,并取得了一系列研究成果[8-10].本研究的工作属于特征表示迁移,与文献[9]属于同一类方法.由于本研究在更为相似的任务(人脸识别)之间迁移,所以可以预期能够取得更好的性能,从而更能满足实际应用的需求.本研究与文献[10]的不同之处在于,本研究认为越底层的特征不仅越通用而且越局部,而越高层的特征不仅越特定而且越全局,具有更好的类内不变性与类间区分性.
2 深度迁移学习方法
形式上,迁移学习可以定义为:给定一个源域DS与源任务TS,一个目标域DT与目标任务TT,迁移学习的目标是DS与TS的知识能够帮助求解或提升TT.注意:DS≠DT或TS≠TT.域D定义为一个二元对{x,P(X)},其中x为特征空间,P(X)是X的边缘分布,X={x1,x2,…,xn}∈x.任务T也是一个二元对{y,f(x)},其中y是标签空间,y=f(x)是从训练样本{xi,yi}(xi∈X,yi∈y)学习到的目标函数.将源域中的训练样本数记为nS,目标域中的记为nT.
对于人脸识别任务,假定DS=DT,而TS≠TT(尽管紧密相关).具体来讲,TS已经从一个大的人脸数据集中学习到,现在需要在一个特定于任务的小数据集上(nS≫nT)学习TT.学习的目标是:通过TS的帮助学习一个有效的TT.
2.1 源模型
使用MatConvNet平台下预训练的VGG-FACE作为TS.如前所述,VGG-FACE是一个在2 622人的260万幅人脸图像上训练的深度CNN模型.这个模型总共40层:1个输入层(0层),1个Softmax输出层(39层),3个全连接层(32,35,38层),剩下的层是交替的conv/relu/mpool/drop层.表1给出了VGG-FACE的网络配置,这与文献[5]给出的大同小异.
迁移学习一个深度CNN模型首先是拷贝TS的头n层作为TT的头n层,然后随机初始化TT的剩下层并用目标数据训练TT.为了清楚,称TS的头n层为源模型.典型地,对于源模型有2种选择,即微调(fine-tune)或冻结(freeze).前者意味着训练TT的过程会影响到源模型,而后者则不会.正如文献[10]所指出的,选择微调或冻结源模型依赖于目标数据集的大小和源模型的参数个数.对于本研究的人脸识别任务,TT只有一个小的特定于任务的人脸数据集.而截取VGG-FACE的全连接层(比如38层)以下的层所得到的源模型仍然是深的,其中包含大量参数.所以,为了避免过拟合,可以选择冻结源模型.
深度CNN模型不同层特征的特点及其可迁移能力是重要的开放问题.Yosinski等[10]认为高层特征更特定而底层特征更通用.本研究赞同此观点,但进一步认为高层特征也更全局而底层特征也更局部.这种局部到全局的转换根植于CNN模型的局部感受野特点,即CNN模型最基本的操作——卷积.
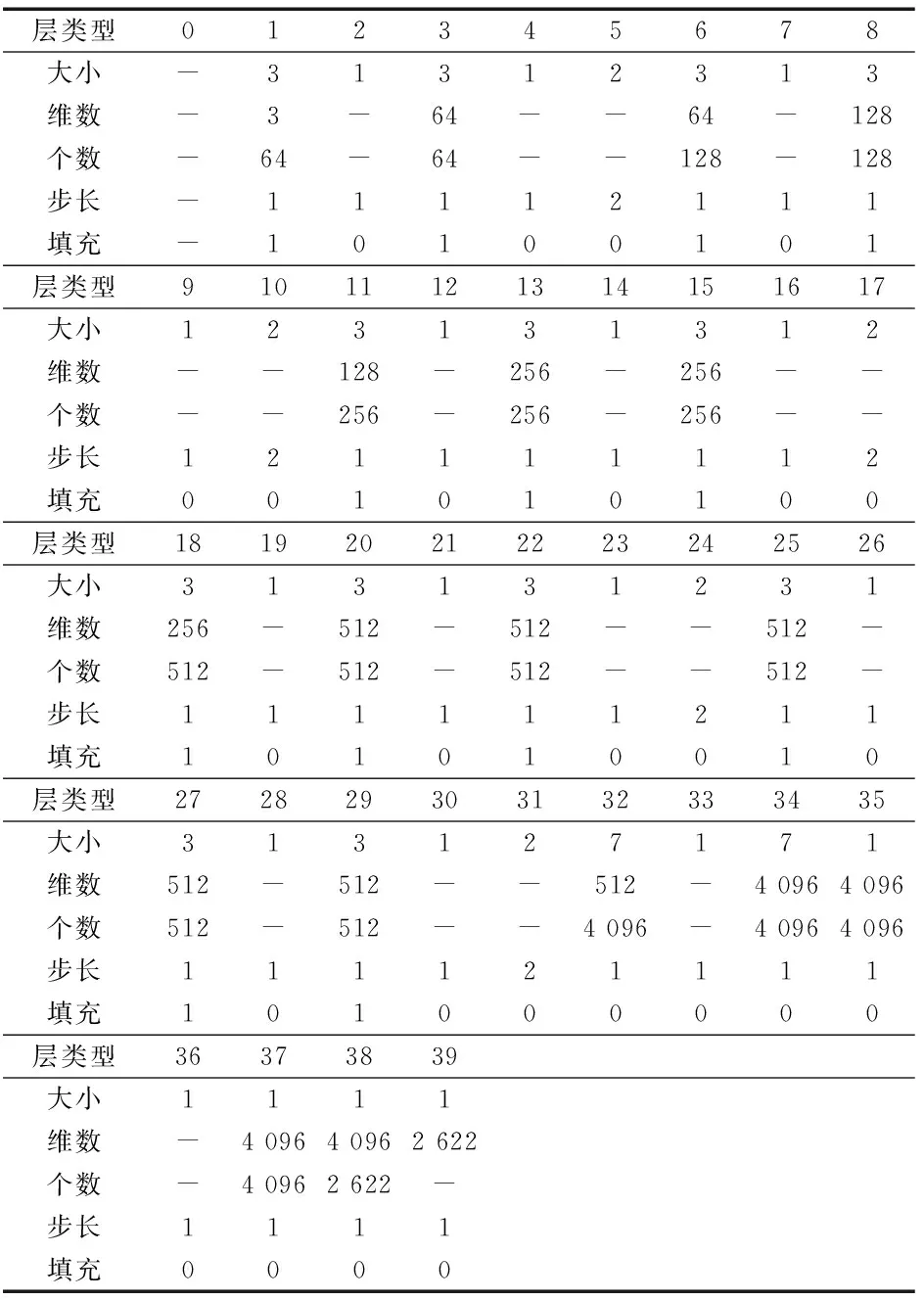
表1 VGG-FACE的网络配置(部分摘自文献[5])
此高层特征的全局特点能够解释为什么其同时具有更好的类内不变性与更好的类间区分性.从本质上讲,这也说明了为什么本研究更倾向于迁移高层的特征.本研究将通过特征的可视化来经验性地证实此观点.本研究的观点也不同于文献[8],文献[8]仅仅强调迁移不变性,但实际上,仅仅迁移不变性既不可能办得到也不足以解决实际问题.
2.2 学习一个目标模型
正如前面提到的,首先拷贝TS的头n层作为源模型,然后用目标数据训练TT得到一个最终的特定于任务的目标模型.注意在训练TT的过程中冻结源模型.图1给出了学习一个目标的整个过程.
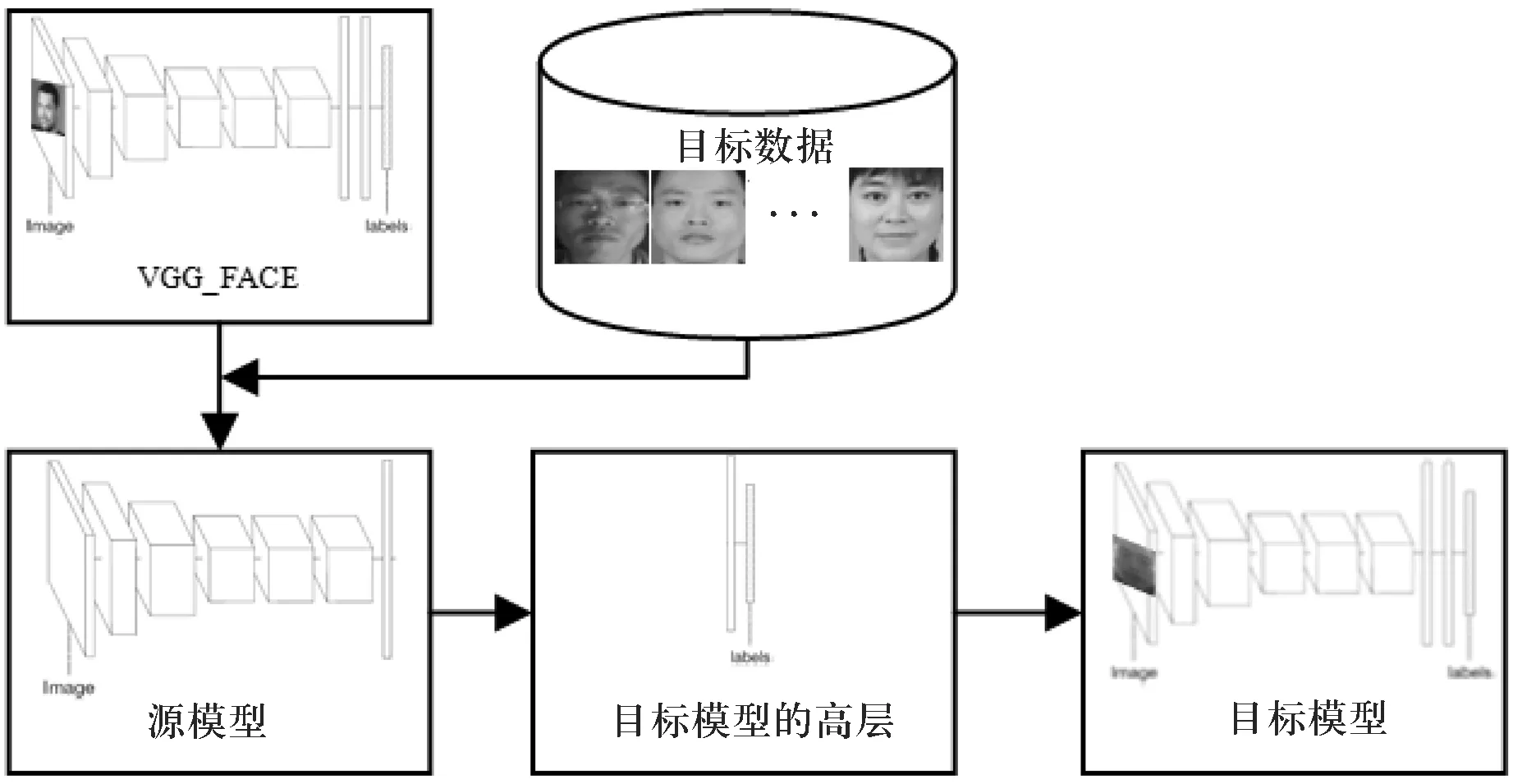
图1 学习目标模型的示意图
由图1可见,首先拷贝VGG-FACE的头n层作为源模型,然后用这个源模型提取目标数据的特征.所提取的特征用于训练目标模型的高层表示,最后冻结的源模型加上从目标数据中训练的高层表示就构成了特定于任务的目标模型.
目标模型高层表示的设计具有足够的弹性,所以可以简单地重新学习一个分类器层,比如softmax或支持向量机(Support Vector Machine,SVM),也可以重新学习最终的分类器层下面的更多层.如何选择主要取决于源任务与目标任务之间的相似程度以及目标数据集的大小.本研究假定源任务与目标任务足够相似(都是人脸识别),还假定目标数据集很小(每个类只有1到10个左右的样本).因此,选择仅仅重新学习分类器层.而对于源任务与目标任务之间不太相似的情况或者有较多的目标数据,也有必要重新学习更多的特征层以提升目标模型的性能.
3 结果与讨论
3.1 评估源模型
为了评估特征性能,本研究比较了7个不同的源模型,采用tSNE[11]进行3D特征可视化,通过这些可视化的结果可以直观地看到特征的无监督自然聚类,聚类情况的好坏可帮助洞察特征的类内不变性与类间区分性.
本研究在3个小的目标数据集上进行了评估,分别是ATT[12]、IOE5与CDUStud.ATT是一个公共的小数据集,包含40人的400幅灰度人脸图像,分辨率均为92×112.IOE5与CDUStud是从实际应用中采集的真实人脸数据.其中,IOE5包含总共33人的330幅灰度人脸图像,分辨率均为100×100;CDUStud包含总共22人的220幅彩色人脸图像,平均分辨率约为300×300.3个数据集里的每个人都有10个样本.对于无监督的可视化,可输入每个人所有10个样本;对于有监督的人脸识别,可将10个样本均分为2个集,分别用于训练与测试.图2给出了3个数据集的4个典型样本,第1行到第3行依次代表的数据集是ATT、IOE5与CDUStud.ATT主要包括姿态及表情变化,IOE5增加了光照及是否戴眼镜,而CDUStud进一步引入了更多的变化,比如颜色,CDUStud更接近于非限制的真实场景下的人脸.
为了得到不同层的特征,VGG-FACE需要3通道的224×224输入图像,所以对于灰度人脸图像,本研究将3个通道设成一样,将不同分辨率的图像缩放为相同的224×224分辨率,并将不同源模型的输出特征(对应于VGG-FACE的不同层)进行L2规范化以备使用.

图2 3个数据集的部分样本图像
图3、图4与图5给出了此3个目标数据集的3D可视化结果.对于每个数据集,本研究给出了以下层的结果:18,25,32(FC6),35(FC7),38(FC8).算法软件tSNE的参数设置为:可视化维数为3,初始PCA维数为50,复杂度为30.由这些可视化结果可见,相对于更底层的特征(比如18层),更高层的特征(比如38层)具有更好的类内不变性(由相同颜色的球形成的自然聚类)与更好的类间区分性(自然聚类之间的距离).从流形学习观点来看,更高层的特征具有更好的解纠缠能力,而更底层的特征彼此之间更加纠缠不清.分层特征对这一现象有合理的解释:更底层的特征是局部的、通用的,因此类内不变性和类间区分性均较差;更高层的特征是全局的、特定的,因此具有较好的类内不变性和类间区分性.
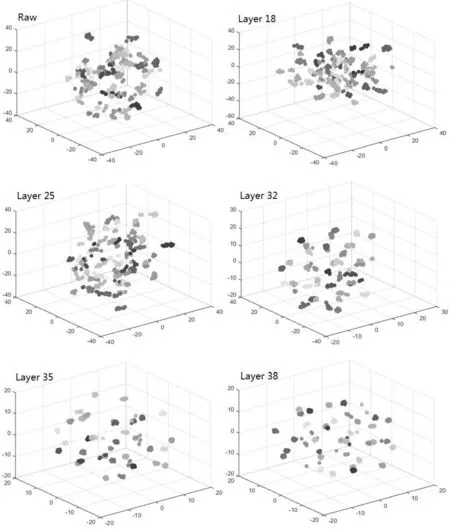
图3 ATT数据集的3D可视化结果
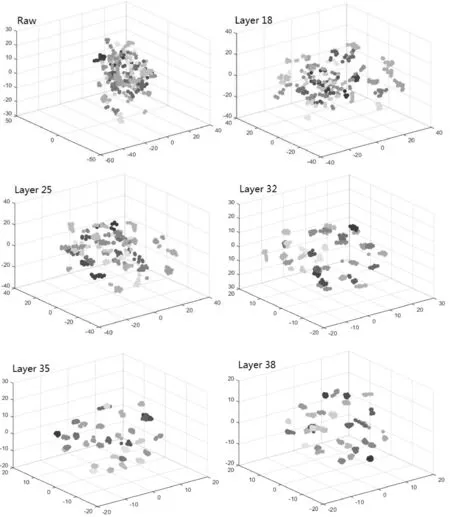
图4 IOE5数据集的3D可视化结果

图5 CDUStud数据集的3D可视化结果
特别地,图3表明3个数据集里不同人的原始图像数据高度纠缠在一起,这解释了分层解纠缠过程的必要性.实际上,文献[11]表明,对于MNIST原始图像数据(固有维数大概为10),tSNE能够粗略展示出10个不同数字的自然聚类.Nielsen[13]展示了只有单个隐层的简单神经网络更易在MNIST数据集上达到95%的分类精度.这个结果进一步验证了MNIST有较低的固有维数,但是对于人脸数据,该实验结果验证了其具有高得多的固有维数,无法通过纯粹无监督的线性或非线性映射来进行有效解纠缠,所以需要有监督的深度神经网络.
对于有监督的人脸识别,目标数据集的人脸样本首先输入到源模型以得到特征,然后用这些特征训练目标模型的SVM层.每个人的5个样本训练一个SVM层,然后用剩下的5个样本测试目标模型(源模型加SVM层).注意,此过程并未进行人脸对齐操作以及应用任何样本增扩.本研究选用了一个流行的SVM实现——LIBLINEAR[14],采用L2-正则化L2-代价线性SVM,惩罚项设置为10.表2给出了3个目标数据集上的有监督人脸识别测试结果.
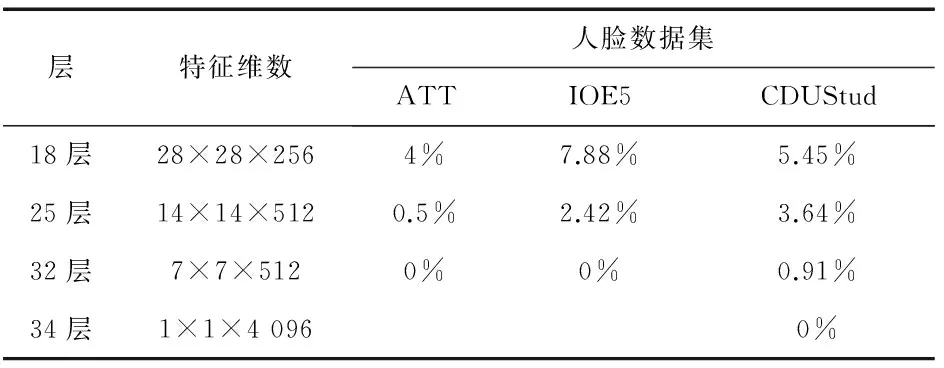
表2 有监督人脸识别测试结果
如表2所示,对于每个目标数据集,本研究给出了不同源模型的错误率,同时给出了每个源模型输出层的维数,并没有对每个目标数据集测试所有7个源模型.实际上,本研究依次增加了源模型的层数直到0%的错误率,比如,在表2里,ATT与IOE5用32层的源模型即达到了0%的错误率,而CDUStud需要34层才达到0%的错误率.对于更复杂的数据集,可以确信需要更多层次的源模型.从表2还可知,错误率随着源模型层数的增加而持续下降,这一结果再次确认了前面特征可视化的分析结论,即底层特征是局部的、通用的,因此类内不变性与类间区分性较差;而高层特征是全局的、特定的,因此类内不变性与类间区分性更好.
从表2还可以看出,更底层的特征具有更高的维数而更高层的特征具有更低的维数,这反映了深度学习的分层特征提取的另一个重要方面——降维,降维是局部到全局与通用到特定这个特征提取过程的自然结果.
3.2 与模型PCANET的比较
本研究从特征质量与人脸识别性能2方面对这2种模型进行比较.
模型PCANET采用2个相连的PCA层,容易用小的数据集进行训练.本研究使用PCANET的原始MATLAB实现,将PCANET作为一个特征学习器和一个特征提取器,提取出的PCANET特征用于训练一个SVM层,所以本研究的目标模型具有和PCANET一样的分类器层,差别仅在于特征学习和特征提取过程.目标模型里,从40层的CNN模型迁移过来的源模型扮演着特征学习与特征提取的角色,而PCANET里2个相连的PCA层扮演这个角色.
采用类似前面同样的3个数据集及同样的SVM参数设置,PCANET的MATLAB实现同样支持灰度与彩色图像,并支持不同的图像分辨率,所以只需将3个数据集的原始图像简单输入到PCANET.PCANET的参数设置如下:分片大小5×5;第一层滤波器数量为25,第二层为8;直方图分块大小8×8,直方图分块覆盖比为0.5.最终的输出特征维数为13 440,这个值介于本研究源模型的18层与25层之间.图6给出了3个数据集的PCANET特征的3D可视化结果.
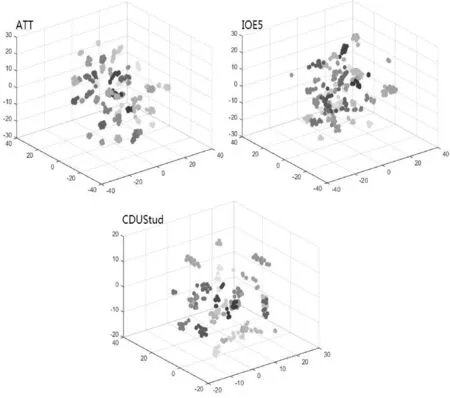
图6 PCANET特征的3D可视化结果
与图3~图5比较可知,PCANET特征总是比源模型的高层特征(如38层)更加纠缠不清.实际上,对于ATT,PCANET特征仅仅比25层及以下的特征稍好,但是比32层及以上差.对于IOE5,PCANET特征仅仅比18层好,而比25层及以上差.类似地,对于CDUStud,PCANET特征仅仅比25层及以下的特征稍好,但是比32层及以上差.这些结果解释了“深度”的重要性.
表3给出了PCANET在3个有监督的人脸识别任务上的错误率.

表3 PCANET测试结果
与表2比较可知,性能上PCANET总是比具有更多层次(>32)的目标模型要差.对于ATT与IOE5,PCANET的性能处于目标模型的18层与25层之间.注意PCANET特征的维数(134 400)也处于18层(200 704)与25层(100 352)之间.对于CDUStud,PCANET表现稍微好一些,处于25层与32层之间.奇怪的是PCANET在IOE5上具有最高错误率(7.27%)而不是CDUStud.图6的特征可视化结果也验证了这一点:IOE5的PCANET特征相比ATT与CDUStud更加纠缠不清.如前所述,IOE5的PCANET特征仅仅比18层好但是比25层及以上差,而ATT与CDUStud的PCANET特征比25层还好些.PCANET在IOE5上具有最高错误率而不是在更困难的CDUStud数据集上,这个现象也许表明PCANET模型自身的不一致性.而本研究的目标模型具有一致的性能表现,即更困难的数据集需要更多的特征层.
4 结 论
本研究探讨了深度CNN模型的迁移学习问题,特别关注了经典的分类应用——人脸识别,并经验性地探索了迁移学习的不同源模型.在3个小数据集上的评估结果表明了本研究所采用方法的有效与高效:对于非常有限的训练样本,目标模型在所有3个数据集上取得了0%的错误率.由于已经在大的数据集上预训练了源模型,小的目标数据集上的迁移学习就变得非常高效——只需在源模型上学习一层或少量更多的层.
同时,本研究还探索了源模型不同层特征的3D可视化.通过这些可视化结果得出,深度CNN模型的底层特征是局部、通用的,而高层特征是全局、特定的,因此高层特征具有更好的类内不变性与更好的类间区分性,更适合有监督的分类任务.实验结果验证了该观点.进一步通过与深度基线模型——PCANET比较表明,本研究的目标模型的优势表现在更低的分类错误率及更好的模型一致性上.
[1]Sun Y,Liang D,Wang X,et al.Deepid3:facerecognitionwithverydeepneuralnetworks[EB/OL].[2015-02-03].https://arxiv.org/abs/1502.00873.
[2]Schroff F,Kalenichenko D,Philbin J.FaceNet:aunifiedembeddingforfacerecognitionandclustering[C]//2015IEEEConferenceonComputerVisionandPatternRecognition(CVPR).Boston,MA,USA:IEEE Press,2015:815-823.
[3]Huang G B,Mattar M,Berg T,et al.LabeledfacesintheWild:adatabaseforstudyingfacerecognitioninunconstrainedenvironments[R].Amherst,MA,USA:University of Massachusetts,Amherst,2007:7-49.
[4]LeCun Y,Bengio Y,Hinton G.Deeplearning[J].Nature,2015,521:436-444.
[5]Parkhi O M,Vedaldi A,Zisserman A.Deepfacerecognition[C]//ProceedingsoftheBritishMachineVisionConference,2015.Swansea,UK:BMVC Press,2015.
[6]Wolf L,Hassner T,Maoz I.Facerecognitioninunconstrainedvideoswithmatchedbackgroundsimilarity[C]//2011IEEEconferenceonComputerVisionandPatternRecognition(CVPR).Colorado Springs,CO,USA:IEEE Press,2011.
[7]Chan Tsung-Han,Jia Kui,Gao Shenghua,et al.PCANet:AsimpledeepLearningbaselineforimageclassification?[J].IEEE Trans Image Proc,2015,24(12):5017-5032.
[8]Thrun S.Islearningthen-ththinganyeasierthanlearningthefirst?[C]//AdvancesinNeuralInformationProcessingSystems8,NIPS1995.Denver,CO,USA:MIT Press,1995:640-646.
[9]Shie C K,Chuang C H,Chou C N,et al.Transferrepresentationlearningformedicalimageanalysis[C]//EngineeringinMedicineandBiologySociety(EMBC),2015 37thAnnualInternationalConferenceoftheIEEE.Milan,Italy:IEEE Press,2015:711-714.
[10]Yosinski J,Clune J,Bengio Y,et al.Howtransferablearefeaturesindeepneuralnetworks?[C]//NIPS'14Proceedingsofthe27thInternationalConferenceonNeuralInformationPrecessingSystems.Montreal,Canada:MIT Press,2014:3320-3328.
[11]Van der Maaten L J P,Hinton G E.Visualizinghigh-dimensionaldatausingt-SNE[J].J Mach Learn Res,2008,9:2579-2605.
[12]Samaria F S,Harter A C.Parameterisationofastochasticmodelforhumanfacecdentification[C]//PrceedingsoftheSecondIEEEWorkshoponApplicationsofComputerVision,1994.Sarasota,FL,USA:IEEE Press,1994.
[13]Nielsen M.Neuralnetworksanddeeplearning[EB/Ol].[2017-01-01].http://neuralnetworksanddeeplearning.com/index.html.
[14]Fan R E,Chang K W,Hsieh C J,et al.LIBLINEAR:alibraryforlargelinearclassification[J].J Mach Learn Res,2008,9(9):1871-1874.
Study on Face Recognition Method Based on Deep Transfer Learning
YUHuapeng,ZHANGPeng,ZHUJin
(School of Information Science and Engineering, Chengdu University, Chengdu 610106, China)
Aiming at relevant problems of deep face model for learning based on big dataset in practice,we put forward a scheme to deal with these problems through transferring a pre-training deep face model to specific tasks on hand.We empirically transfer hierarchical representations of deep face model as a source model and then learn higher layer representations on a specific small training set to obtain a final task-specific target model.Experiments on face identification tasks with public small data set and practical real face data set verify the effectiveness and efficiency of our approach for transfer learning.We also empirically explore an important open problem—attributes and transferability of different layer features of deep model.We argue that lower layer features are both local and general,while higher layer ones are both global and specific which embraces both intra-class invariance and inter-class discrimination.The results of unsupervised feature visualization and supervised face identification strongly support our view.
deep learning;face recognition;transfer learning;invariance;discrimination
1004-5422(2017)02-0151-06
2017-03-16.
余化鹏(1973 — ), 男, 博士, 讲师, 从事计算机视觉与机器学习研究.
TP391.41
A
